

NeurIPS()是全球最大的機器學習和人工智慧會議,也是深度學習領域的頂級盛會。
在新的十年裡,我們DS工程師也會掌握生物學、語言學和心理學嗎?我們將在評論中告訴你。

今年,來自 13500 個國家的 80 多名代表齊聚加拿大溫哥華。俄羅斯聯邦儲蓄銀行 (Sberbank) 多年來一直代表俄羅斯參加此次會議——其數據科學團隊介紹了機器學習在銀行流程中的應用、機器學習競賽以及 Sberbank 數據科學平台的功能。 2019 年機器學習社群的主要趨勢是什麼?與會者告訴我們: и .
今年,NeurIPS 接受了超過 1400 篇論文——演算法、新模型以及新數據的新應用。
內容:
- 趨勢
- 模型的可解釋性
- 多學科性
- 推理
- RL
- 甘
- 主要特邀報告
- “社會智能”,Blaise Aguera y Arcas(Google)
- “真實數據科學”,Bin Yu(伯克利)
- “利用機器學習進行人類行為建模:機會與挑戰”,Nuria M Oliver、Albert Ali Salah
- Yoshua Bengio 的“從系統 1 到系統 2 深度學習”
2019 年的趨勢
1. 模型的可解釋性和新的機器學習方法
會議的主題是解釋和證明我們為何會得到某些結果。我們可以就解釋「黑盒子」的哲學意義進行長篇大論,但在這一領域,還有更多實際的方法和技術發展。
模型的可重複性及其知識提取方法論是科學的全新工具。模型可以作為獲取新知識及其驗證的工具,模型的預處理、訓練和應用的每個階段都必須具有可重複性。
相當一部分出版物並非致力於模型和工具的構建,而是致力於確保結果的安全性、透明度和可驗證性。特別是,出現了一個關於模型攻擊(對抗性攻擊)的獨立研究流,其中既考慮了訓練攻擊,也考慮了應用攻擊。
文章:
- ——一篇關於模型驗證方法論的綱領性文章。文中概述了用於解釋模型的現代工具,特別是——如何利用注意力機制,以及如何透過「提煉」線性模型的神經網路來獲取特徵重要性。
- 陳超凡、李奧斯卡、陶丹尼爾、Alina Barnett、Cynthia Rudin、Jonathan K. Su
- 莎拉·胡克、杜米特魯·埃爾汗、彼得·簡·金德曼斯、貝恩·金
- 亞歷山大·莫特、丹尼爾·佐蘭、麥克·切爾扎諾夫斯基、達安·維爾斯特拉、達尼洛·希門尼斯·雷森德
- 小李、王宇、Sumanta Basu、Karl Kumbier、於斌
- Jaemin Yoo、Minyong Cho、Taebum Kim、U Kang
- 愛德華·拉夫
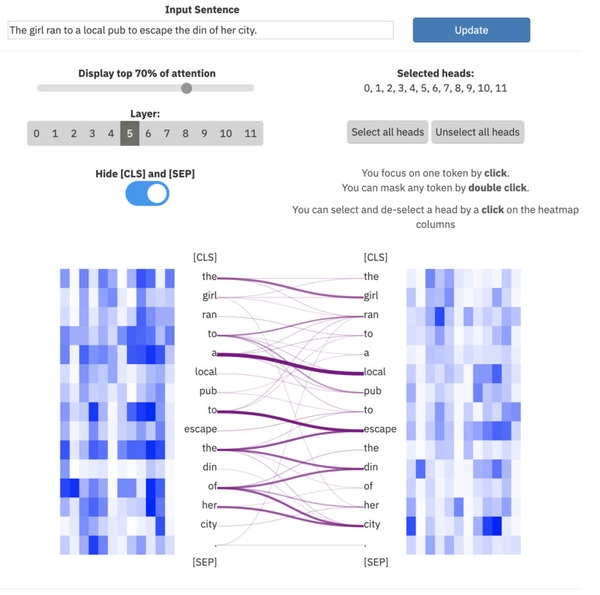
ExBert.net 展示了文字處理任務模型的解釋
2. 多學科性
為了確保可靠的驗證,並開發驗證和知識補充機制,需要相關領域的專家,他們同時具備機器學習和相關學科領域(醫學、語言學、神經生物學、教育學等)的能力。尤其值得注意的是,神經科學和認知科學領域的著作和演講數量顯著增加——專家之間的匯聚和思想的借鑒正在形成。
除了這種融合之外,多學科性正在出現在來自各種來源的資訊的聯合處理中:文字和照片、文字和遊戲、圖形資料庫+文字和照片。
文章:
- 神經科學+機器學習—
- VisualQA —
- 強化學習 + 自然語言處理 —
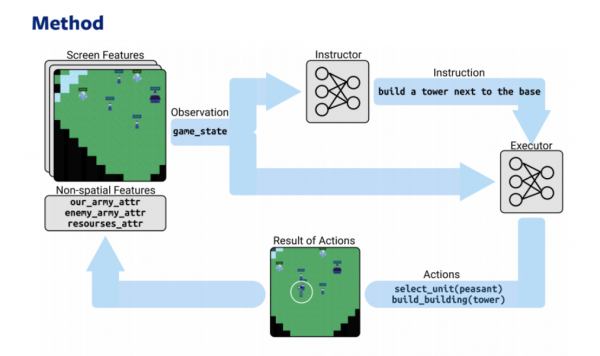
基於 RL 和 NLP 的兩種模型 - 策略者和執行者 - 玩線上策略
3. 推理
強化人工智慧是朝著自主學習系統、「意識」、推理和辯論(推理)邁進的一場運動。特別是,因果推理和常識推理正在發展。一些報告致力於元學習(如何學習)以及深度學習技術與一階和二階邏輯的結合——「通用人工智慧」(AGI)這個術語正成為演講者演講中的常用術語。
文章:
- 餘偉江、週靜文、餘偉豪、梁曉丹、蕭農
- 戴旺週、徐秋玲、於陽、週志華
- 維沙克·貝爾,布倫丹·朱巴
- 安東·巴赫金、勞倫斯·范德馬滕、賈斯汀·約翰遜、勞拉·古斯塔夫森、羅斯·吉爾希克
- Dinesh Garg、Shajith Ikbal、Santosh K. Srivastava、Harit Vishwakarma、Hima Karanam、L Venkata Subramaniam
4.強化學習
大部分工作繼續開發傳統的 RL 方向 - DOTA2、星海爭霸,將架構與電腦視覺、NLP、圖形資料庫結合。
會議中特別安排了一天的 RL 研討會,會上展示了樂觀行動者評論家模型架構,超越了之前的所有架構,尤其是軟行動者評論家模型。
文章:
- ;卡米爾·喬塞克、Quan Vuong、羅伯特·洛夫廷、卡佳·霍夫曼
- ; Yasuhiro Fujita(Preferred Networks, Inc.)*;Toshiki Kataoka(Preferred Networks, Inc.);Prabhat Nagarajan(Preferred Networks);Takahiro Ishikawa(東京大學)[外部 pdf 連結]。
- ; Danijar Hafner(Google)*;Timothy Lillicrap(DeepMind);Jimmy Ba(多倫多大學);Mohammad Norouzi(Google大腦)

星海爭霸選手對戰 Alphastar(DeepMind)模型
5. GAN
生成網路仍然備受關注,許多論文使用原始 GAN 進行數學證明,並以新的、不尋常的方式應用它們(圖形生成模型、處理序列、將它們應用於數據中的因果關係等)。
文章:
- Sangwoo Mo、Chiheon Kim、Sungwoong Kim、Minsu Cho、Jinwoo Shin
- 張丹、安娜·科雷娃
- 徐雷、Maria Skoularidou、Alfredo Cuesta-Infante、Kalyan Veeramachaneni
由於有超過 100 件作品被接受 下面我們將向您介紹最重要的表演。
特邀報告
“社會智能”,Blaise Aguera y Arcas(Google)
本次演講探討了機器學習的通用方法論以及目前正在改變產業的前景——我們正面臨哪些十字路口?大腦和演化是如何運作的?為什麼我們對自然系統發展已有的認知卻如此匱乏?
ML 的工業發展很大程度上與Google的發展里程碑相吻合,Google年復一年地在 NeurIPS 上發布其研究成果:
- 1997 年-推出搜尋功能、首批伺服器、小型運算能力
- 2010 年-Jeff Dean 推出 Google Brain,神經網路熱潮才剛開始
- 2015年——神經網路的工業化應用,直接在本地設備上實現快速人臉識別,以及專為張量計算量身定制的低階處理器——TPU。谷歌推出了Coral AI——一款類似樹莓派的設備,一款用於在實驗裝置中實現神經網路的微型電腦。
- 2017 年 - 谷歌開始開發去中心化學習,並將來自不同設備的神經網路學習結果整合到一個模型中 - 在 Android 上
如今,整個產業都在致力於解決資料安全、本地設備上學習成果的整合和再現等問題。
——一種機器學習方向,其中各個模型彼此獨立地進行訓練,然後組合成一個單一模型(無需集中管理來源資料),並針對罕見事件、異常情況、個人化等進行調整。所有設備均具備 Android 本質上是一台供谷歌使用的超級電腦。
谷歌表示,基於聯邦學習的生成模型是一個充滿希望的未來方向,目前正處於「指數成長的早期階段」。講師表示,生成對抗網路(GAN)能夠學習重現生物群體的群體行為以及思考演算法。
我們利用兩種簡單的 GAN 架構,證明了它們對最佳化路徑的搜尋會繞圈,這意味著最佳化本身不會發生。同時,這些模型非常成功地模擬了生物學家對細菌群體進行的實驗,迫使它們學習新的覓食行為策略。我們可以得出結論,生命的運作方式與最佳化函數不同。
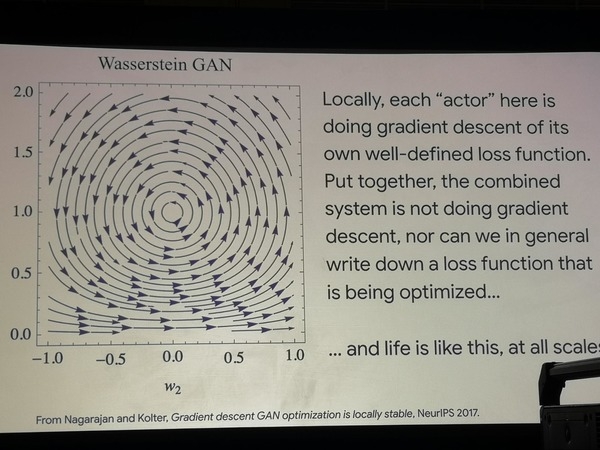
漫遊GAN最佳化
我們現在在機器學習中所做的一切都是狹窄且高度形式化的任務,而這些形式主義的概括性較差,與我們在神經生理學和生物學等領域的學科知識不符。
在不久的將來,神經生理學領域真正值得借鏡的是新的神經元結構和對誤差反向傳播機制的輕微修改。
人類大腦本身並不像神經網路那樣學習:
- 他沒有隨機的原始輸入,包括透過感官和童年輸入的輸入。
- 他有預先決定的本能發展方向(嬰兒學習語言的慾望、直立行走)
了解個體大腦是一項低階任務,也許我們應該考慮快速變化的個體的“群體”,相互傳遞知識以重現群體進化的機制。
我們現在可以將其應用到 ML 演算法中:
- 應用細胞譜系模型,為群體提供學習機會,但為個體(「個體大腦」)提供較短的壽命
- 基於少量樣本的少樣本學習
- 更複雜的神經元結構,略有不同的活化函數
- 將「基因組」傳遞給下一代—反向傳播演算法
- 一旦我們將神經生理學和神經網路結合起來,我們將學會從許多組件建立一個多功能的大腦。
從這個角度來看,SOTA 解決方案的實踐是有害的,應該進行修改,以利於開發通用任務(基準)。
“真實數據科學”,Bin Yu(伯克利)
本報告致力於探討機器學習模型的解釋問題及其直接驗證和確認的方法。任何經過訓練的機器學習模型都可以被視為必須從中提取的知識來源。
在許多領域,尤其是在醫學領域,如果不提取這些隱藏的知識並解釋模型的結果,就無法應用模型——否則,我們將無法確保結果的穩定性、非隨機性、可靠性,以及不會危及患者的生命。在深度學習範式中,一種全新的方法論正在發展,並且超越了它——真實數據科學。它是什麼?
我們希望實現這樣的科學出版物品質和模型的可重複性:
- 可預測
- 可計算的
- 穩定的
這三個原則構成了新方法論的基礎。我們如何檢查機器學習模型是否符合這些標準?最簡單的方法是建立可立即解釋的模型(迴歸模型、決策樹模型)。然而,我們也希望獲得深度學習的直接益處。
目前有幾種方法可以解決這個問題:
- 解釋模型;
- 使用基於注意力的方法;
- 在訓練中使用演算法集合,並確保線性可解釋模型透過解釋線性模型的特徵來學習預測與神經網路相同的反應;
- 改變和增強訓練資料。這包括添加雜訊、幹擾和資料增強;
- 任何確保模型結果不是隨機的並且不依賴不必要的小噪音(對抗性攻擊)的方法;
- 訓練後,對模型進行事後解釋;
- 以不同的方式研究特徵權重;
- 研究所有假設的機率、類別的分佈。

對抗性攻擊
建模錯誤對每個人來說都是代價高昂的:一個突出的例子就是萊因哈特和羅戈夫的工作”「影響了許多歐洲國家的經濟政策,迫使它們推行緊縮政策,但多年後對這些數據及其處理進行仔細的重新審視,卻顯示出相反的結果!
任何機器學習技術都有其自身的生命週期,從實施到實現。新方法論的任務是在模型生命週期的每個階段檢查三個主要原則。
結果:
- 目前有多個專案正在進行中,旨在提高機器學習模型的可靠性。例如,deeptune(連結至: );
- 為了進一步發展該方法,有必要大幅提高機器學習領域出版物的品質;
- 機器學習需要具有多學科背景、兼具技術和人文領域專業知識的領導者。
「利用機器學習進行人類行為建模:機會與挑戰」 Nuria M Oliver、Albert Ali Salah
專門討論人類行為建模、其技術基礎和應用前景的講座。
人類行為建模可以分為:
- 個人行為
- 一小部分人的行為
- 群體行為
每種類型都可以使用機器學習進行建模,但輸入資訊和特徵完全不同。每種類型也都有各自的倫理問題,每個項目都會經歷這些問題:
- 個人行為-身分盜竊、深度偽造;
- 群眾的行為-去匿名化、獲取有關行動、電話等的資訊;
個人行為
更大程度上,它涉及電腦視覺——識別人類情緒及其反應。這只有在情境、時間或自身情緒變化的相對尺度下才有可能實現。幻燈片中,我們利用地中海女性的情緒譜來辨識蒙娜麗莎的情緒。結果:她露出了喜悅的微笑,但又夾雜著輕蔑和厭惡。原因很可能在於辨識「中性」情緒的技術方法。
一小群個體的行為
到目前為止,最差的建模是由於資訊不足。例如,2018-2019 年的作品在數十個人和數十個影片中展示(請參閱 100 萬多個圖像資料集)。為了在此任務框架內實現最佳建模,需要多模態訊息,最好是來自人體高度計、溫度計、麥克風錄音等感測器的資訊。
群體行為
這是最發達的地區,因為客戶是聯合國和許多國家。監視攝影機、電話塔數據(包括帳單、簡訊、通話、國家邊界之間的流動數據)所有這些都能提供非常可靠的人員流動和社會不穩定資訊。該技術的潛在應用包括:優化救援行動、提供援助以及在緊急情況下及時疏散人口。目前,所使用的模型大多解釋不清楚—例如各種長短期記憶(LSTM)和卷積網路。有人簡短地表示,聯合國正在遊說制定一項新法律,強制歐洲企業分享任何研究所需的匿名數據。
Yoshua Bengio 的“從系統 1 到系統 2 深度學習”
在 Yoshua Bengio 的演講中,深度學習在目標設定層面與神經科學相遇。
Bengio 根據諾貝爾獎得主 Daniel Kahneman 的方法論(書“» )
類型 1 - 系統 1,我們「自動」進行的無意識行為(古老大腦):在熟悉的地方駕駛汽車、行走、辨識臉孔。
類型 2 - 系統 2,有意識的行動(大腦皮質)、目標設定、分析、思考、複合任務。
人工智慧迄今為止僅在第一類任務上取得了足夠的高度,而我們的任務是將其提升到第二類,教導它執行多學科操作並以邏輯和高級認知技能進行操作。
為實現這一目標,建議:
- 在 NLP 任務中,使用注意力作為建模思維的關鍵機制
- 使用後設學習和表徵學習來更好地模擬影響意識及其定位的特徵,並在此基礎上繼續操作更高層次的概念。
最後,我們留下了一段受邀演講的錄音:Bengio 是眾多試圖將 ML 領域擴展到優化問題、SOTA 和新架構之外的科學家之一。
意識問題、語言對思考的影響、神經生物學和演算法的結合將在多大程度上影響我們未來,並使我們能夠走向像人一樣「思考」的機器,這個問題仍然懸而未決。
謝謝!

來源: www.habr.com
