

Hey Habr!
Nəzərinizə çatdırırıq ki, daha bir son dərəcə maraqlı və faydalı nəşri yayımlamışıq Kubernetes nümunələri haqqında. Hamısı " ilə başladı"Brendan Burns və yeri gəlmişkən, bu seqmentdə işimiz var . Bu gün sizi MiniIO bloqundan Kubernetes-də məlumat saxlama nümunələrinin tendensiyalarını və xüsusiyyətlərini qısaca təsvir edən məqaləni oxumağa dəvət edirik.
Kubernetes ənənəvi proqram inkişafı və yerləşdirmə nümunələrini əsaslı şəkildə dəyişdi. İndi komanda bir neçə gün ərzində tətbiqi inkişaf etdirə, sınaqdan keçirə və yerləşdirə bilər – bir çox mühitdə, hamısı Kubernetes klasterlərində. Əvvəlki texnologiya nəsilləri ilə belə iş adətən aylar olmasa da həftələr çəkdi.
Bu sürətləndirmə Kubernetes tərəfindən təmin edilən abstraksiya sayəsində mümkün olur - yəni Kubernetesin özü fiziki və ya virtual maşınların aşağı səviyyəli detalları ilə qarşılıqlı əlaqədə olduğundan, istifadəçilərə istədikləri prosessoru, istənilən yaddaş miqdarını və konteynerin sayını elan etməyə imkan verir. misallar, digər parametrlər arasında. Kubernetes-i dəstəkləyən və onun qəbulu daim genişlənən nəhəng bir icma ilə Kubernetes, bütün konteyner orkestr platformaları arasında geniş fərqlə liderdir.
Kubernetes-dən istifadə artdıqca, onun saxlama nümunələri ilə bağlı qarışıqlıq da artır..
Hər kəs Kubernetes pastasının bir parçası (yəni məlumatların saxlanması) üçün rəqabət apararkən, məlumatların saxlanması haqqında danışmağa gəldikdə, siqnal çox səs-küydə boğulur.
Kubernetes tətbiqin inkişafı, yerləşdirilməsi və idarə edilməsi üçün müasir modeli təcəssüm etdirir. Bu müasir model məlumat yaddaşını hesablamadan ayırır. Kubernetes kontekstində dekolmanı tam başa düşmək üçün siz həmçinin statuslu və vətəndaşlığı olmayan tətbiqlərin nə olduğunu və məlumat yaddaşının buna necə uyğun gəldiyini başa düşməlisiniz. S3 tərəfindən istifadə edilən REST API yanaşmasının digər həllərin POSIX/CSI yanaşması ilə müqayisədə aydın üstünlükləri buradadır.
Bu yazıda Kubernetes-də məlumat saxlama nümunələri haqqında danışacağıq və aralarındakı fərqin nə olduğunu və nə üçün vacib olduğunu daha yaxşı başa düşmək üçün dövlət və vətəndaşlığı olmayan tətbiqlər arasındakı mübahisəyə toxunacağıq. Mətnin qalan hissəsi konteynerlər və Kubernetes ilə işləmək üçün ən yaxşı təcrübələr işığında tətbiqlərə və onların məlumat saxlama nümunələrinə baxacaq.
Vətəndaşlığı olmayan konteynerlər
Konteynerlər təbiətcə yüngül və efemerdir. Onlar asanlıqla dayandırıla, çıxarıla və ya başqa bir qovşaqda yerləşdirilə bilər - hamısı bir neçə saniyə ərzində. Böyük konteyner orkestrləşdirmə sistemində bu cür əməliyyatlar hər zaman baş verir və istifadəçilər belə dəyişikliklərin fərqinə varmırlar. Bununla belə, hərəkətlər yalnız konteynerin yerləşdiyi qovşaqdan asılılığı olmadıqda mümkündür. Belə qabların işlədiyi deyilir vətəndaşlığı olmayan.
Vəziyyəti bildirən konteynerlər
Konteyner məlumatları yerli olaraq qoşulmuş cihazlarda (və ya blok cihazda) saxlayırsa, nasazlıq halında onun yerləşdiyi məlumat anbarı konteynerin özü ilə birlikdə yeni qovşağa köçürülməli olacaq. Bu vacibdir, çünki əks halda konteynerdə işləyən proqram düzgün işləyə bilməyəcək, çünki o, yerli mediada saxlanılan məlumatlara daxil olmalıdır. Belə qabların işlədiyi deyilir dövlətli.
Sırf texniki nöqteyi-nəzərdən vəziyyət bildirən konteynerlər digər qovşaqlara da köçürülə bilər. Bu, adətən, paylanmış fayl sistemlərindən və ya konteynerlərlə işləyən bütün qovşaqlara qoşulmuş şəbəkə saxlama blokundan istifadə etməklə əldə edilir. Beləliklə, konteynerlər məlumatların davamlı saxlanması üçün həcmlərə daxil olur və məlumat bütün şəbəkədə yerləşən disklərdə saxlanılır. Mən bu metodu çağıracağam "statuslu konteyner yanaşması", və məqalənin qalan hissəsində vahidlik naminə bunu adlandıracağam.
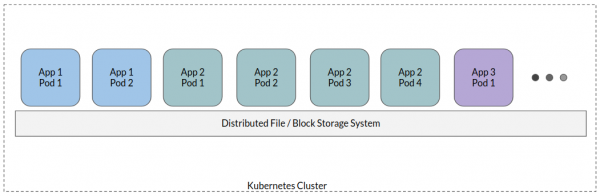
Tipik statuslu konteyner yanaşmasında, bütün proqram podları vahid paylanmış fayl sisteminə - bütün proqram məlumatlarının yerləşdiyi bir növ paylaşılan yaddaşa əlavə olunur. Bəzi dəyişikliklər mümkün olsa da, bu yüksək səviyyəli bir yanaşmadır.
İndi gəlin nəzər salaq ki, nəyə görə statuslu konteyner yanaşması bulud mərkəzli dünyada anti-naxışdır.
Bulud-doğma proqram dizaynı
Ənənəvi olaraq, proqramlar məlumatların strukturlaşdırılmış saxlanması və yerli disklər və ya bütün strukturlaşdırılmamış və ya hətta yarı strukturlaşdırılmış məlumatların atıldığı paylanmış fayl sistemləri üçün verilənlər bazalarından istifadə edirdi. Strukturlaşdırılmamış məlumatların həcmi artdıqca, tərtibatçılar POSIX-in həddən artıq danışıq olduğunu, əhəmiyyətli yükə malik olduğunu və nəhayət, həqiqətən böyük miqyaslara keçərkən tətbiqin işinə mane olduğunu başa düşdülər.
Bu, əsasən REST API əsasında işləyən və tətbiqi yerli məlumat yaddaşının ağır təmirindən azad edən məlumatların saxlanması üçün yeni standartın, yəni bulud əsaslı yaddaşın yaranmasına kömək etdi. Bu halda, proqram effektiv şəkildə vətəndaşlıqsız rejimə keçir (dövlət uzaq yaddaşda olduğundan). Müasir tətbiqlər bu amili nəzərə alaraq sıfırdan qurulur. Bir qayda olaraq, bu və ya digər növ məlumatları emal edən hər hansı müasir proqram (loglar, metadata, bloblar və s.) bulud yönümlü paradiqmaya uyğun olaraq qurulur, burada dövlət onun saxlanması üçün xüsusi ayrılmış proqram sisteminə ötürülür.
Vəziyyətli konteyner yanaşması bütün bu paradiqmanı başladığı yerə geri qaytarmağa məcbur edir!
Məlumatların saxlanması üçün POSIX interfeyslərindən istifadə etməklə, proqramlar statuslu kimi işləyir və buna görə də onlar bulud mərkəzli dizaynın ən mühüm prinsiplərindən, yəni daxil olanlardan asılı olaraq proqram işçisi iplərinin ölçüsünü dəyişmək qabiliyyətindən uzaqlaşırlar. giriş.yükləmək, cari node uğursuz olan kimi yeni qovşağa keçmək və s.
Bu vəziyyətə daha yaxından nəzər salsaq görərik ki, məlumat anbarı seçərkən biz təkrar-təkrar POSIX-ə qarşı REST API dilemması ilə qarşılaşırıq, AMMA Kubernetes mühitlərinin paylanmış təbiətinə görə POSIX problemlərinin əlavə kəskinləşməsi ilə. Xüsusilə,
- POSIX danışıqlıdır: POSIX semantikası tələb edir ki, hər bir əməliyyat əməliyyatın vəziyyətini saxlamağa kömək edən metadata və fayl deskriptorları ilə əlaqələndirilməlidir. Bu, heç bir real dəyəri olmayan əhəmiyyətli xərclərlə nəticələnir. Obyekt saxlama API-ləri, xüsusən də S3 API, bu tələblərdən xilas olmaqla, tətbiqin işə salınmasına və sonra zəngi “unutmasına” imkan verir. Yaddaş sisteminin cavabı əməliyyatın uğurlu olub-olmadığını göstərir. Əgər uğursuz olarsa, proqram yenidən cəhd edə bilər.
- Şəbəkə məhdudiyyətləri: Paylanmış sistemdə eyni əlavə edilmiş mediaya məlumat yazmağa çalışan bir çox proqramın ola biləcəyi nəzərdə tutulur. Buna görə də, proqramlar nəinki məlumat ötürmə bant genişliyi (məlumatları mediaya göndərmək üçün) üçün bir-biri ilə rəqabət aparmayacaq, həm də saxlama sisteminin özü məlumatı fiziki disklər arasında göndərməklə bu bant genişliyi üçün yarışacaq. POSIX-in səssizliyinə görə şəbəkə zənglərinin sayı bir neçə dəfə artır. Digər tərəfdən, S3 API müştəridən serverə gələnlər və server daxilində baş verənlər arasında şəbəkə zəngləri arasında aydın fərq təmin edir.
- təhlükəsizlik: POSIX təhlükəsizlik modeli aktiv insan iştirakı üçün nəzərdə tutulmuşdur: administratorlar hər bir istifadəçi və ya qrup üçün xüsusi giriş səviyyələrini konfiqurasiya edirlər. Bu paradiqmanı bulud mərkəzli dünyaya uyğunlaşdırmaq çətindir. Müasir tətbiqlər API əsaslı təhlükəsizlik modellərindən asılıdır, burada giriş hüquqları bir sıra siyasətlər, xidmət hesabları, müvəqqəti etimadnamələr və s. kimi müəyyən edilir.
- İdarəetmə: Vəziyyəti bildirən konteynerlərdə bəzi idarəetmə yükü var. Söhbət verilənlərə paralel girişin sinxronlaşdırılmasından, məlumatların ardıcıllığının təmin edilməsindən gedir, bütün bunlar hansı verilənlərə giriş nümunələrinin istifadə edilməsinin diqqətlə nəzərdən keçirilməsini tələb edir. Əlavə proqram təminatı quraşdırılmalı, monitorinq edilməli və konfiqurasiya edilməlidir, əlavə inkişaf səylərini qeyd etməmək lazımdır.
Konteyner Məlumat Saxlama İnterfeysi
Konteyner Saxlama İnterfeysi (CSI) Kubernetes həcm qatının yayılmasında böyük kömək olsa da, qismən üçüncü tərəf saxlama təchizatçılarına autsorsinq versə də, o, həm də təsadüfən statistik konteyner yanaşmasının tövsiyə olunan üsul olduğuna inanmağa kömək etdi. Kubernetes-də məlumatların saxlanması.
CSI, Kubernetes-də işləyərkən köhnə tətbiqlərə ixtiyari blok və fayl saxlama sistemlərini təmin etmək üçün standart olaraq hazırlanmışdır. Və bu məqalədə göstərildiyi kimi, statuslu konteyner yanaşmasının (və indiki formada CSI) mənasını verən yeganə vəziyyət, tətbiqin özü obyekt saxlama API-si üçün dəstək əlavə etmək mümkün olmayan köhnə sistemdir. .
Anlamaq vacibdir ki, CSI-ni hazırkı formada istifadə edərək, yəni müasir tətbiqlərlə işləyərkən həcmləri artırmaq, məlumatların saxlanmasının POSIX üslubunda təşkil edildiyi sistemlərdə yaranan təxminən eyni problemlərlə qarşılaşacağıq.
Daha yaxşı yanaşma
Bu halda, anlamaq vacibdir ki, əksər proqramlar mahiyyət etibarilə xüsusi olaraq dövlət və ya vətəndaşlığı olmayan iş üçün nəzərdə tutulmayıb. Bu davranış ümumi sistem arxitekturasından və edilən xüsusi dizayn seçimlərindən asılıdır. Gəlin bir az dövlət tətbiqləri haqqında danışaq.
Prinsipcə, bütün tətbiq məlumatları bir neçə geniş növə bölünə bilər:
- Giriş məlumatları
- Vaxt möhürü məlumatları
- Əməliyyat məlumatları
- Metadata
- Konteyner şəkilləri
- Blob (ikili böyük obyekt) məlumatları
Bu məlumat növlərinin hamısı müasir saxlama platformalarında çox yaxşı dəstəklənir və bu xüsusi formatların hər birində məlumatların çatdırılması üçün uyğunlaşdırılmış bir neçə bulud platforması mövcuddur. Məsələn, əməliyyat məlumatları və metaməlumatlar CockroachDB, YugaByte və s. kimi müasir bulud-doğma verilənlər bazasında yerləşə bilər. Konteyner şəkilləri və ya blob məlumatları MiniIO əsasında docker reyestrində saxlanıla bilər. Zaman möhürü məlumatları InfluxDB və s. kimi zaman seriyası verilənlər bazasında saxlanıla bilər. Biz burada hər bir məlumat növü və onun tətbiqləri haqqında təfərrüatlara girməyəcəyik, lakin ümumi fikir, yerli disk montajına əsaslanan davamlı məlumat yaddaşının qarşısını almaqdır.
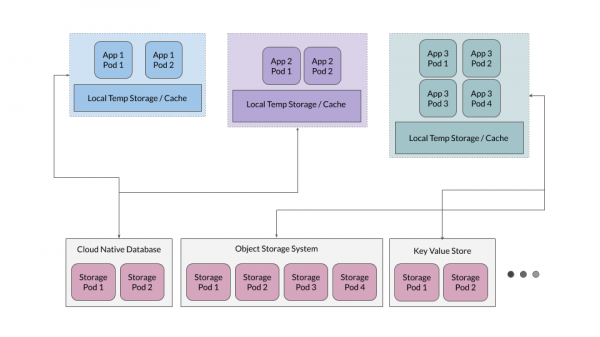
Əlavə olaraq, tətbiqlər üçün müvəqqəti fayl anbarı kimi xidmət edən müvəqqəti keşləmə qatını təmin etmək çox vaxt effektivdir, lakin tətbiqlər həqiqət mənbəyi kimi bu təbəqədən asılı olmamalıdır.
Vəziyyətli tətbiq yaddaşı
Əksər hallarda tətbiqləri vətəndaşsız saxlamaq faydalı olsa da, verilənlər bazası, obyekt anbarları, açar-dəyər anbarları kimi məlumatların saxlanması üçün nəzərdə tutulmuş proqramlar vəziyyətə uyğun olmalıdır. Gəlin bu tətbiqlərin Kubernetes-də niyə yerləşdirildiyinə baxaq. Nümunə olaraq MiniIO-nu götürək, lakin oxşar prinsiplər istənilən digər iri buludlu yerli saxlama sisteminə aiddir.
Bulud-doğma tətbiqlər konteynerlərə xas olan çeviklikdən tam istifadə etmək üçün nəzərdə tutulub. Bu o deməkdir ki, onlar yerləşdiriləcəkləri mühitlə bağlı heç bir fərziyyə etmirlər. Məsələn, MiniIO, disklərin yarısı uğursuz olsa belə, sistemin işləmək üçün kifayət qədər davamlılığı təmin edən daxili silmə kodlaşdırma mexanizmindən istifadə edir. MiniIO həmçinin mülkiyyətçi server tərəfi hashing və şifrələmədən istifadə edərək məlumatların bütövlüyünü və təhlükəsizliyini idarə edir.
Belə bulud mərkəzli proqramlar üçün yerli davamlı həcmlər (PV) ehtiyat yaddaş kimi ən əlverişlidir. Yerli PV xam məlumatları saxlamaq imkanı verir, eyni zamanda bu PV-lərin üzərində işləyən proqramlar məlumatları miqyaslaşdırmaq və artan məlumat tələblərini idarə etmək üçün müstəqil olaraq məlumat toplayır.
Bu yanaşma CSI əsaslı PV-lərə nisbətən daha sadə və əhəmiyyətli dərəcədə daha genişlənə bilər, hansı ki, sistemə öz verilənlərin idarə edilməsi və ehtiyat qatlarını təqdim edir; Məsələ ondadır ki, bu təbəqələr adətən statuslu olmaq üçün nəzərdə tutulmuş proqramlarla ziddiyyət təşkil edir.
Hesablamalardan məlumatların ayrılması istiqamətində güclü hərəkət
Bu yazıda biz proqramların vəziyyəti saxlamadan işləmək üçün necə yönləndirildiyi və ya başqa sözlə, məlumatların saxlanmasının onun üzərində hesablamadan ayrılması haqqında danışdıq. Sonda bu tendensiyanın bəzi real nümunələrinə baxaq.
, görkəmli məlumat analitik platforması ənənəvi olaraq vəziyyətə uyğun olub və HDFS-də yerləşdirilib. Bununla belə, Spark bulud mərkəzli dünyaya keçdikcə, platforma `s3a` istifadə edərək getdikcə daha çox vətəndaşsız istifadə olunur. Spark vəziyyəti digər sistemlərə ötürmək üçün s3a-dan istifadə edir, Spark konteynerləri isə tamamilə vətəndaşsız işləyir. Böyük verilənlərin analitikası sahəsində digər böyük müəssisə oyunçuları, xüsusən, , , Onlar həmçinin məlumatların saxlanması və onlar üzərində hesablamaların ayrılması ilə işləməyə keçirlər.
Oxşar nümunələri Presto, Tensorflow to R, Jupyter də daxil olmaqla digər böyük analitik platformalarda da görmək olar. Vəziyyəti uzaq bulud saxlama sistemlərinə yükləməklə, tətbiqinizi idarə etmək və miqyasını artırmaq daha asan olur. Bundan əlavə, o, tətbiqin müxtəlif mühitlərə daşınmasını asanlaşdırır.
Mənbə: www.habr.com
