


Naišao sam na zanimljiv materijal o umjetnoj inteligenciji u igricama. Uz objašnjenje osnovnih stvari o AI pomoću jednostavnih primjera, a unutra se nalazi mnogo korisnih alata i metoda za njegov zgodan razvoj i dizajn. Kako, gdje i kada ih koristiti je također tu.
Većina primjera je napisana u pseudokodu, tako da nije potrebno napredno znanje programiranja. Ispod reza nalazi se 35 listova teksta sa slikama i gifovima, pa se pripremite.
UPD. Izvinjavam se, ali već sam napravio vlastiti prijevod ovog članka na Habréu . Možete pročitati njegovu verziju , ali iz nekog razloga članak je prošao pored mene (koristio sam pretragu, ali nešto je pošlo po zlu). A budući da pišem na blogu posvećenom razvoju igara, odlučio sam ostaviti svoju verziju prijevoda za pretplatnike (neke točke su drugačije formatirane, neke su namjerno izostavljene po savjetu programera).
Šta je AI?
AI igre fokusira se na to koje radnje objekt treba da izvrši na osnovu uslova u kojima se nalazi. Ovo se obično naziva upravljanje "inteligentnim agentom", gdje je agent igrač lik, vozilo, bot ili ponekad nešto apstraktnije: cijela grupa entiteta ili čak civilizacija. U svakom slučaju, to je stvar koja mora da vidi svoje okruženje, da na osnovu njega donosi odluke i da se ponaša u skladu sa njima. Ovo se zove ciklus Osećaj/Razmišljaj/Deluj:
- Smisao: Agent pronalazi ili prima informacije o stvarima u svom okruženju koje mogu uticati na njegovo ponašanje (prijetnje u blizini, predmeti za prikupljanje, zanimljiva mjesta za istraživanje).
- Razmislite: agent odlučuje kako će reagovati (razmatra da li je dovoljno bezbedno da prikupi predmete ili da se prvo bori/sakrije).
- Postupite: agent izvodi radnje za provedbu prethodne odluke (počinje se kretati prema neprijatelju ili objektu).
- ...sada se situacija promijenila djelovanjem likova, pa se ciklus ponavlja sa novim podacima.
AI teži da se fokusira na osjetilni dio petlje. Na primjer, autonomni automobili slikaju cestu, kombinuju ih sa radarskim i lidarskim podacima i tumače ih. To se obično radi mašinskim učenjem, koje obrađuje dolazne podatke i daje im značenje, izvlačeći semantičke informacije kao što je „još jedan automobil je 20 jardi ispred tebe“. To su takozvani problemi klasifikacije.
Igrama nije potreban složen sistem za izdvajanje informacija jer je većina podataka već sastavni dio njih. Nema potrebe za pokretanjem algoritama za prepoznavanje slika da bi se utvrdilo ima li neprijatelja ispred - igra već zna i unosi informacije direktno u proces donošenja odluka. Stoga je dio ciklusa osjetila često mnogo jednostavniji od dijela Misli i djeluj.
Ograničenja AI igre
AI ima niz ograničenja koja se moraju poštovati:
- AI ne treba unaprijed trenirati, kao da je algoritam za mašinsko učenje. Nema smisla pisati neuronsku mrežu tokom razvoja kako bi pratili desetine hiljada igrača i naučili na najbolji način igrati protiv njih. Zašto? Jer igra nije puštena i nema igrača.
- Igra bi trebala biti zabavna i izazovna, tako da agenti ne bi trebali pronaći najbolji pristup protiv ljudi.
- Agenti moraju izgledati realno kako bi se igrači osjećali kao da igraju protiv stvarnih ljudi. AlphaGo program je nadmašio ljude, ali odabrani koraci su bili jako daleko od tradicionalnog razumijevanja igre. Ako igra simulira ljudskog protivnika, ovaj osjećaj ne bi trebao postojati. Algoritam treba promijeniti tako da donosi vjerodostojne odluke, a ne idealne.
- AI mora raditi u realnom vremenu. To znači da algoritam ne može monopolizirati korištenje CPU-a u dugim vremenskim periodima za donošenje odluka. Čak je i 10 milisekundi predugo, jer većini igara treba samo 16 do 33 milisekundi da obavi svu obradu i pređe na sljedeći grafički okvir.
- U idealnom slučaju, barem dio sistema bi trebao biti vođen podacima, tako da ne-koderi mogu napraviti promjene i prilagođavanja se mogu dogoditi brže.
Pogledajmo pristupe umjetne inteligencije koji pokrivaju cijeli ciklus Sense/Think/Act.
Donošenje osnovnih odluka
Počnimo od najjednostavnije igre - Pong. Cilj: pomjeriti veslo tako da se lopta odbije od njega umjesto da proleti pored njega. To je kao tenis, gde gubite ako ne udarite loptu. Ovdje AI ima relativno lak zadatak - odlučivanje u kojem smjeru će pomaknuti platformu.

Uslovne izjave
Za AI u Pongu, najočitije rješenje je da uvijek pokušate postaviti platformu ispod lopte.
Jednostavan algoritam za ovo, napisan u pseudokodu:
svaki okvir/ažuriranje dok igra radi:
ako je lopta lijevo od vesla:
pomjeriti veslo lijevo
inače ako je lopta desno od vesla:
pomaknite veslo udesno
Ako se platforma kreće brzinom lopte, onda je ovo idealan algoritam za AI u Pong-u. Ne treba ništa komplikovati ako nema toliko podataka i mogućih radnji za agenta.
Ovaj pristup je toliko jednostavan da je cijeli ciklus Osjeti/Razmišljaj/Djeluj jedva primjetan. Ali postoji:
- Sense dio je u dva if naredbe. Igra zna gdje je lopta i gdje je platforma, tako da AI traži te informacije.
- Dio Think je također uključen u dvije if izjave. Oni utjelovljuju dva rješenja, koja se u ovom slučaju međusobno isključuju. Kao rezultat, odabire se jedna od tri radnje - pomjerite platformu ulijevo, pomaknite je udesno ili ne radite ništa ako je već ispravno pozicionirana.
- Dio Act se nalazi u izjavama Move Paddle Left i Move Paddle Right. Ovisno o dizajnu igre, oni mogu pomicati platformu trenutno ili određenom brzinom.
Takvi pristupi se nazivaju reaktivnim – postoji jednostavan skup pravila (u ovom slučaju ako su izjave u kodu) koja reaguju na trenutno stanje u svijetu i poduzimaju akciju.
Stablo odluka
Pong primjer je zapravo ekvivalentan formalnom konceptu umjetne inteligencije koji se zove stablo odlučivanja. Algoritam prolazi kroz njega kako bi došao do „lista“—odluke o tome koju radnju poduzeti.
Napravimo blok dijagram stabla odluka za algoritam naše platforme:
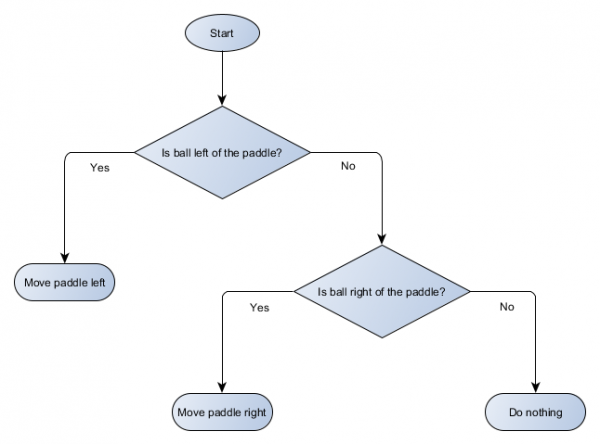
Svaki dio stabla naziva se čvor - AI koristi teoriju grafova da opiše takve strukture. Postoje dvije vrste čvorova:
- Čvorovi odluke: biranje između dvije alternative na osnovu testiranja nekog stanja, gdje je svaka alternativa predstavljena kao poseban čvor.
- Krajnji čvorovi: Radnja koju treba izvršiti koja predstavlja konačnu odluku.
Algoritam počinje od prvog čvora („korijena“ stabla). Ili donosi odluku o tome na koji podređeni čvor da ide, ili izvršava radnju pohranjenu u čvoru i izlazi.
Koja je korist od toga da stablo odlučivanja radi isti posao kao naredbe if u prethodnom odeljku? Ovdje postoji opći sistem gdje svaka odluka ima samo jedan uslov i dva moguća ishoda. Ovo omogućava programeru da kreira AI od podataka koji predstavljaju odluke u stablu bez potrebe da ga čvrsto kodira. Predstavimo to u obliku tabele:
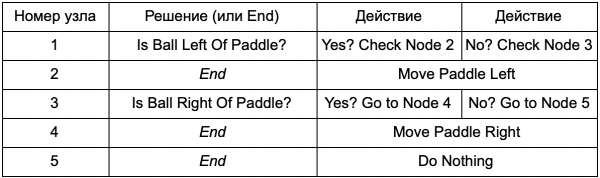
Na strani koda ćete dobiti sistem za čitanje stringova. Kreirajte čvor za svaki od njih, povežite logiku odlučivanja na osnovu druge kolone i podređene čvorove na osnovu treće i četvrte kolone. Još uvijek trebate programirati uvjete i radnje, ali sada će struktura igre biti složenija. Ovdje dodajete dodatne odluke i radnje, a zatim prilagođavate cijeli AI jednostavnim uređivanjem tekstualne datoteke definicije stabla. Zatim prenosite datoteku dizajneru igre, koji može promijeniti ponašanje bez ponovnog kompajliranja igre ili promjene koda.
Stabla odlučivanja su vrlo korisna kada se automatski grade iz velikog skupa primjera (na primjer, korištenjem ID3 algoritma). To ih čini efikasnim alatom visokih performansi za klasifikaciju situacija na osnovu dobijenih podataka. Međutim, idemo dalje od jednostavnog sistema za agente da biraju akcije.
Scenariji
Analizirali smo sistem stabla odlučivanja koji je koristio unapred kreirane uslove i akcije. Osoba koja dizajnira AI može organizirati stablo kako god želi, ali se i dalje mora osloniti na kodera koji je sve to programirao. Šta ako bismo dizajneru mogli dati alate za kreiranje vlastitih uvjeta ili radnji?
Tako da programer ne mora da piše kod za uslove Is Ball Left Of Paddle i Is Ball Right Of Paddle, on može kreirati sistem u kojem će dizajner napisati uslove za proveru ovih vrednosti. Tada će podaci stabla odluka izgledati ovako:
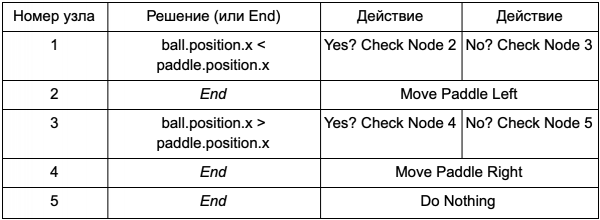
Ovo je u suštini isto kao u prvoj tabeli, ali rješenja unutar sebe imaju svoj vlastiti kod, pomalo kao uslovni dio if naredbe. Na strani koda, ovo bi glasilo u drugom stupcu za čvorove odluke, ali umjesto da traži određeni uslov za izvršenje (Da li je lopta lijevo od vesla), on procjenjuje uvjetni izraz i u skladu s tim vraća true ili false. Ovo se radi pomoću skriptnog jezika Lua ili Angelscript. Koristeći ih, programer može uzeti objekte u svojoj igri (lopta i veslo) i kreirati varijable koje će biti dostupne u skripti (ball.position). Takođe, skript jezik je jednostavniji od C++. Ne zahtijeva potpunu fazu kompilacije, tako da je idealan za brzo prilagođavanje logike igre i omogućava “nekoderima” da sami kreiraju potrebne funkcije.
U gornjem primjeru, skriptni jezik se koristi samo za procjenu uvjetnog izraza, ali se može koristiti i za radnje. Na primjer, podaci Move Paddle Right mogu postati naredba skripte (ball.position.x += 10). Tako da je radnja također definirana u skripti, bez potrebe za programiranjem Move Paddle Right.
Možete ići još dalje i napisati cijelo stablo odlučivanja u skript jeziku. To će biti kod u obliku tvrdo kodiranih uslovnih naredbi, ali će se nalaziti u vanjskim skript datotekama, odnosno mogu se mijenjati bez ponovnog kompajliranja cijelog programa. Često možete uređivati datoteku skripte tokom igranja kako biste brzo testirali različite AI reakcije.
Event Response
Gore navedeni primjeri su savršeni za pong. Oni kontinuirano vode ciklus Osjećaj/Razmišljaj/Djeluj i djeluju na osnovu najnovijeg stanja svijeta. Ali u složenijim igrama morate reagirati na pojedinačne događaje, a ne procjenjivati sve odjednom. Pong je u ovom slučaju već loš primjer. Hajde da izaberemo drugu.
Zamislite pucač u kojem su neprijatelji nepomični dok ne otkriju igrača, nakon čega se ponašaju u zavisnosti od njegove "specijalizacije": neko će trčati da "juri", neko će napasti izdaleka. To je i dalje osnovni reaktivni sistem - "ako je igrač uočen, uradi nešto" - ali se logično može raščlaniti na događaj koji je vidio igrač i reakciju (odaberite odgovor i izvršite ga).
Ovo nas vraća u ciklus Smisao/Razmišljaj/Deluj. Možemo kodirati dio Sense koji će provjeriti svaki kadar da li AI vidi igrača. Ako ne, ništa se ne dešava, ali ako vidi, kreira se događaj Player Seen. Kod će imati poseban odjeljak koji kaže "kada se dogodi događaj koji je vidio Playera, uradi", gdje je odgovor koji vam je potreban da se pozabavite dijelovima Misli i Djeluj. Tako ćete podesiti reakcije na događaj Player Seen: za „juriša“ lik - ChargeAndAttack, a za snajperistu - HideAndSnipe. Ovi odnosi se mogu kreirati u datoteci podataka za brzo uređivanje bez ponovnog kompajliranja. Ovdje se također može koristiti skriptni jezik.
Donošenje teških odluka
Iako su jednostavni sistemi reakcija vrlo moćni, postoje mnoge situacije u kojima oni nisu dovoljni. Ponekad morate donijeti različite odluke na osnovu onoga što agent trenutno radi, ali teško je to zamisliti kao uslov. Ponekad postoji previše uslova da bi ih efektivno predstavili u stablu odlučivanja ili skripti. Ponekad morate unaprijed procijeniti kako će se situacija promijeniti prije nego što odlučite o sljedećem koraku. Za rješavanje ovih problema potrebni su sofisticiraniji pristupi.
Konačna mašina
Konačni automat ili FSM (finite state machine) je način da se kaže da je naš agent trenutno u jednom od nekoliko mogućih stanja i da može prelaziti iz jednog stanja u drugo. Postoji određeni broj takvih država — otuda i naziv. Najbolji primjer iz života je semafor. Postoje različiti nizovi svjetala na različitim mjestima, ali princip je isti – svako stanje predstavlja nešto (zaustavljanje, hodanje, itd.). Semafor je u svakom trenutku u samo jednom stanju i prelazi iz jednog u drugi na osnovu jednostavnih pravila.
Slična je priča i sa NPC-ima u igricama. Na primjer, uzmimo gard sa sljedećim stanjima:
- Patroliranje.
- Napada.
- Bežeći.
I ovi uslovi za promjenu njegovog stanja:
- Ako stražar vidi neprijatelja, on napada.
- Ako stražar napadne, ali više ne vidi neprijatelja, vraća se u patrolu.
- Ako stražar napadne, ali je teško ranjen, bježi.
Također možete napisati if-izjave sa varijablom stanja čuvara i raznim provjerama: ima li neprijatelja u blizini, koji je nivo zdravlja NPC-a, itd. Dodajmo još nekoliko stanja:
- Nerad - između patrola.
- Pretraživanje - kada je uočeni neprijatelj nestao.
- Pronalaženje pomoći - kada je neprijatelj uočen, ali je previše jak da bi se borio sam.
Izbor za svakog od njih je ograničen - na primjer, čuvar neće ići tražiti skrivenog neprijatelja ako je slabog zdravlja.
Uostalom, postoji ogromna lista "ako" , To " može postati previše glomazan, pa moramo formalizirati metodu koja nam omogućava da imamo na umu stanja i prelaze između stanja. Da bismo to učinili, uzimamo u obzir sva stanja, a pod svakim stanjem upisujemo na listu sve prijelaze u druga stanja, zajedno sa uvjetima potrebnim za njih.
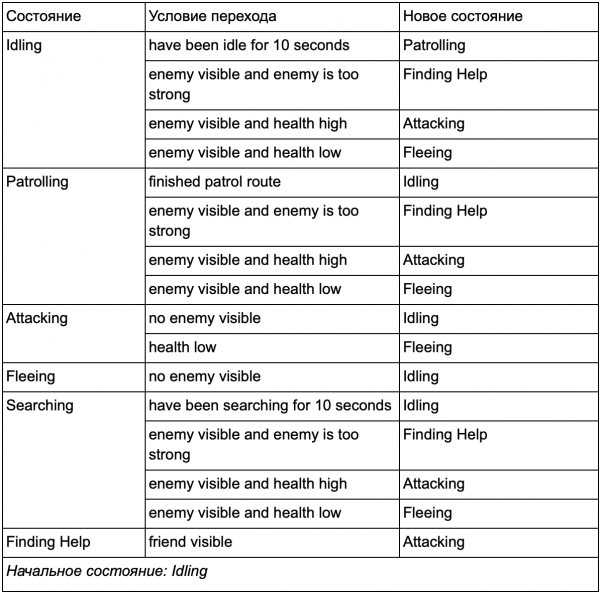
Ovo je tabela prijelaza stanja - sveobuhvatan način predstavljanja FSM-a. Nacrtajmo dijagram i dobijemo potpuni pregled kako se NPC ponašanje mijenja.
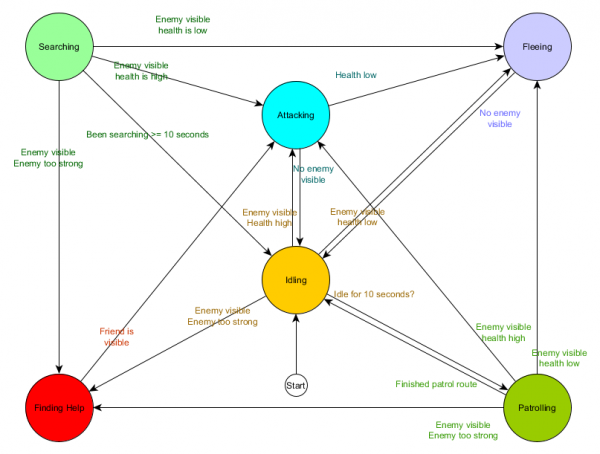
Dijagram odražava suštinu donošenja odluka za ovog agenta na osnovu trenutne situacije. Štaviše, svaka strelica pokazuje prelaz između stanja ako je uslov pored nje tačan.
Svako ažuriranje provjeravamo trenutno stanje agenta, pregledavamo listu prijelaza i ako su ispunjeni uvjeti za tranziciju, prihvata novo stanje. Na primjer, svaki okvir provjerava da li je tajmer od 10 sekundi istekao, i ako jeste, onda zaštita prelazi iz stanja mirovanja u patroliranje. Na isti način, stanje napada provjerava zdravlje agenta - ako je nisko, onda prelazi u stanje bijega.
Ovo je rukovanje prijelazima između stanja, ali što je s ponašanjem povezanim sa samim stanjima? U smislu implementacije stvarnog ponašanja za određeno stanje, tipično postoje dvije vrste "hook" gdje dodjeljujemo akcije FSM-u:
- Radnje koje povremeno izvodimo za trenutno stanje.
- Radnje koje preduzimamo prilikom prelaska iz jednog stanja u drugo.
Primjeri za prvi tip. Stanje patroliranja će pomjeriti agenta duž rute patrole svaki okvir. Stanje Attacking će pokušati pokrenuti napad svaki okvir ili prijeći u stanje u kojem je to moguće.
Za drugi tip, razmislite o prijelazu „ako je neprijatelj vidljiv i neprijatelj je prejak, onda idite u stanje Finding Help. Agent mora odabrati gdje će se obratiti za pomoć i pohraniti ove informacije tako da stanje Finding Help zna kuda treba ići. Kada se pronađe pomoć, agent se vraća u stanje napada. U ovom trenutku, on će htjeti reći savezniku o prijetnji, tako da se može dogoditi akcija NotifyFriendOfThreat.
Još jednom, ovaj sistem možemo posmatrati kroz sočivo ciklusa Osećaj/Misli/Deluj. Smisao je oličen u podacima koje koristi logika tranzicije. Razmislite - tranzicije dostupne u svakom stanju. A Act se provodi radnjama koje se periodično izvode unutar države ili na prijelazima između država.
Ponekad uslovi tranzicije kontinuiranog glasanja mogu biti skupi. Na primjer, ako svaki agent izvodi složene kalkulacije u svakom kadru kako bi utvrdio može li vidjeti neprijatelje i shvatiti može li prijeći iz stanja patroliranja u stanje napada, to će potrajati mnogo procesorskog vremena.
Važne promjene u stanju svijeta mogu se smatrati događajima koji će se procesuirati kako se događaju. Umjesto da FSM provjerava stanje prijelaza "može li moj agent vidjeti igrač svaki okvir, može se konfigurirati poseban sistem da provjerava rjeđe (npr. 5 puta u sekundi?"). I rezultat je izdavanje Player Seen kada prođe ček.
Ovo se prosljeđuje FSM-u, koji bi sada trebao ići u stanje primljenog događaja Player Seen i odgovoriti u skladu s tim. Rezultirajuće ponašanje je isto osim gotovo neprimjetnog kašnjenja prije odgovora. Ali performanse su poboljšane kao rezultat odvajanja dijela Sense u poseban dio programa.
Hijerarhijski stroj konačnog stanja
Međutim, rad s velikim FSM-ovima nije uvijek prikladan. Ako želimo da proširimo stanje napada da odvojimo MeleeAttacking i RangedAttacking, moraćemo da promenimo prelaze iz svih ostalih stanja koja vode u stanje Attacking (trenutno i buduće).
Vjerovatno ste primijetili da u našem primjeru ima puno dupliranih prijelaza. Većina prijelaza u stanju mirovanja identična je prijelazima u stanju patroliranja. Bilo bi lijepo da se ne ponavljamo, pogotovo ako dodamo još sličnih stanja. Ima smisla grupirati Idling i Patrolling pod opštom oznakom "ne-borbeni", gdje postoji samo jedan zajednički skup prijelaza u borbena stanja. Ako ovu oznaku zamislimo kao stanje, onda mirovanje i patroliranje postaju podstanja. Primjer korištenja zasebne prijelazne tablice za novo neborbeno podstanje:
Glavna stanja:
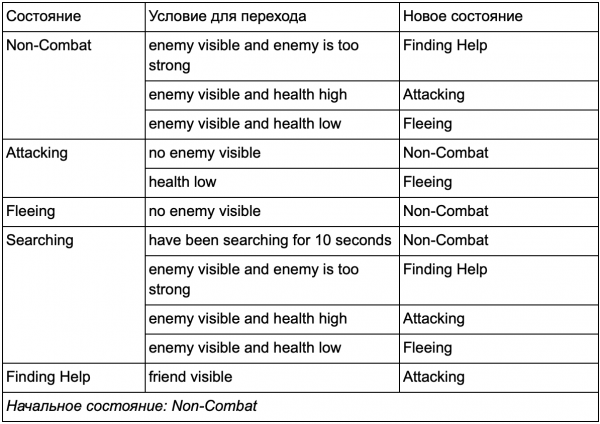
Van borbenog statusa:

I u obliku dijagrama:
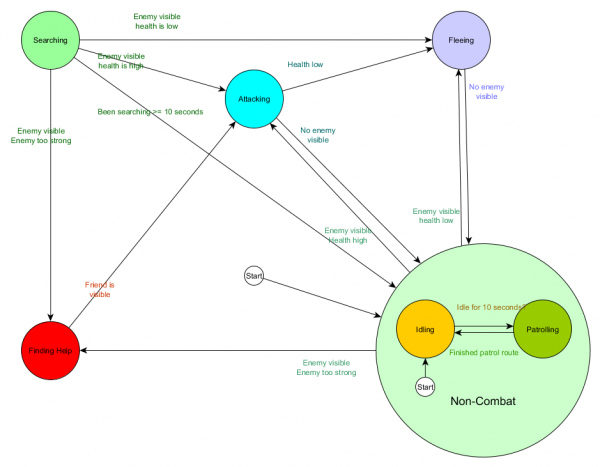
To je isti sistem, ali sa novim neborbenim stanjem koje uključuje mirovanje i patroliranje. Sa svakim stanjem koje sadrži FSM sa podstanjima (a ova podstanja, zauzvrat, sadrže svoje vlastite FSM-ove - i tako dalje koliko god vam je potrebno), dobijamo Hijerarhijski konačni stroj ili HFSM (hijerarhijski konačni stroj). Grupisanjem neborbenog stanja izrezali smo gomilu suvišnih prelaza. Isto možemo učiniti za bilo koje nove države sa zajedničkim prijelazima. Na primjer, ako u budućnosti proširimo stanje Attacking na stanja MeleeAttacking i MissileAttacking, to će biti podstanja koja prelaze jedno na drugo na osnovu udaljenosti do neprijatelja i dostupnosti municije. Kao rezultat toga, složena ponašanja i pod-ponašanja mogu biti predstavljena s minimumom duplih prijelaza.
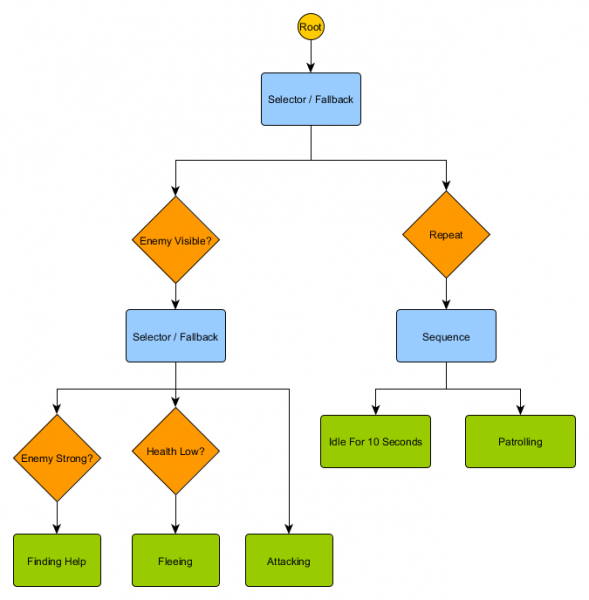
Stablo ponašanja
Uz HFSM, složene kombinacije ponašanja se stvaraju na jednostavan način. Međutim, postoji mala poteškoća da je donošenje odluka u obliku tranzicionih pravila usko povezano sa trenutnim stanjem. A u mnogim igrama to je upravo ono što je potrebno. Pažljiva upotreba hijerarhije stanja može smanjiti broj ponavljanja tranzicije. Ali ponekad su vam potrebna pravila koja funkcionišu bez obzira u kojoj se državi nalazite, ili koja se primjenjuju u gotovo svakoj državi. Na primjer, ako zdravlje agenta padne na 25%, željet ćete da pobjegne bez obzira na to da li je bio u borbi, u stanju mirovanja ili priča - morat ćete dodati ovo stanje svakom stanju. A ako vaš dizajner kasnije želi promijeniti niski zdravstveni prag sa 25% na 10%, onda će to morati ponovo da se uradi.
U idealnom slučaju, ovakva situacija zahtijeva sistem u kojem su odluke o tome „u kakvom stanju biti“ izvan samih država, kako bi se promjene vršile samo na jednom mjestu i ne bi doticale tranzicione uslove. Ovdje se pojavljuju stabla ponašanja.
Postoji nekoliko načina za njihovu implementaciju, ali suština je otprilike ista za sve i slična je stablu odlučivanja: algoritam počinje s “korijenskim” čvorom, a stablo sadrži čvorove koji predstavljaju ili odluke ili akcije. Ipak, postoji nekoliko ključnih razlika:
- Čvorovi sada vraćaju jednu od tri vrijednosti: Uspješno (ako je posao dovršen), Neuspješan (ako se ne može pokrenuti) ili Pokrenut (ako još uvijek radi i nema konačnog rezultata).
- Nema više čvorova odlučivanja za biranje između dvije alternative. Umjesto toga, oni su čvorovi Decorator, koji imaju jedan podređeni čvor. Ako uspiju, izvršavaju svoj jedini podređeni čvor.
- Čvorovi koji izvode radnje vraćaju Running vrijednost koja predstavlja radnje koje se izvode.
Ovaj mali skup čvorova može se kombinirati kako bi se stvorio veliki broj složenih ponašanja. Zamislimo HFSM guard iz prethodnog primjera kao stablo ponašanja:
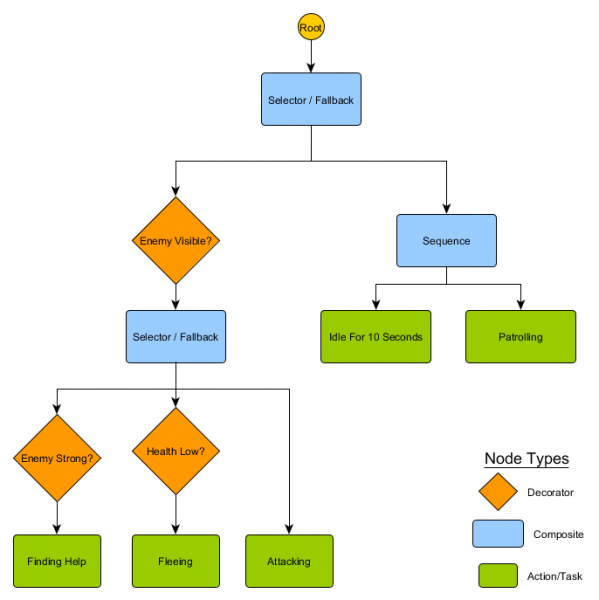
Sa ovom strukturom ne bi trebalo biti očiglednog prijelaza iz stanja mirovanja/patroliranja u stanje napada ili bilo koja druga stanja. Ako je neprijatelj vidljiv i zdravlje lika je slabo, izvršenje će se zaustaviti na čvoru Bežeći, bez obzira na to koji je čvor prethodno izvršavao - patroliranje, mirovanje, napad ili bilo koji drugi.
Stabla ponašanja su složena – postoji mnogo načina da se sastave, a pronalaženje prave kombinacije dekoratora i složenih čvorova može biti izazovno. Postavljaju se i pitanja o tome koliko često treba provjeravati stablo - želimo li proći kroz svaki njegov dio ili samo kada se promijeni jedan od uslova? Kako pohranjujemo stanje koje se odnosi na čvorove - kako znamo kada smo bili u stanju mirovanja 10 sekundi, ili kako znamo koji su čvorovi izvršavali posljednji put da bismo mogli ispravno obraditi sekvencu?
Zbog toga postoji mnogo implementacija. Na primjer, neki sistemi su zamijenili čvorove dekoratera sa inline dekoratorima. Oni ponovo procenjuju stablo kada se uslovi dekoratera promene, pomažu u spajanju čvorova i obezbeđuju periodična ažuriranja.
Sistem zasnovan na komunalnim uslugama
Neke igre imaju mnogo različitih mehanika. Poželjno je da dobiju sve prednosti jednostavnih i općih tranzicionih pravila, ali ne nužno u obliku cjelovitog stabla ponašanja. Umjesto da imate jasan skup izbora ili stablo mogućih radnji, lakše je ispitati sve akcije i odabrati najprikladniju u ovom trenutku.
Sistem zasnovan na uslužnim programima pomoći će upravo u tome. Ovo je sistem u kojem agent ima različite akcije i bira koje će izvršiti na osnovu relativne korisnosti svake od njih. Gdje je korisnost proizvoljna mjera koliko je važno ili poželjno da agent izvrši ovu radnju.
Izračunatu korisnost akcije na osnovu trenutnog stanja i okruženja, agent može provjeriti i odabrati najprikladnije drugo stanje u bilo kojem trenutku. Ovo je slično FSM, osim gdje su prijelazi određeni procjenom za svako potencijalno stanje, uključujući i trenutno. Napominjemo da biramo najkorisniju radnju za nastavak (ili ostanak ako smo je već obavili). Za veću raznolikost, ovo bi mogao biti uravnotežen, ali nasumičan odabir sa male liste.
Sistem dodjeljuje proizvoljan raspon korisnih vrijednosti—na primjer, od 0 (potpuno nepoželjno) do 100 (potpuno poželjno). Svaka radnja ima određeni broj parametara koji utječu na izračunavanje ove vrijednosti. Da se vratimo na naš primjer čuvara:

Prijelazi između radnji su dvosmisleni – svako stanje može slijediti bilo koje drugo. Prioriteti radnji se nalaze u vraćenim vrijednostima uslužnih programa. Ako je neprijatelj vidljiv, a taj neprijatelj je jak, a zdravlje lika je slabo, tada će i Bježanje i pomoć u pronalaženju vratiti visoke vrijednosti različite od nule. U ovom slučaju, FindingHelp će uvijek biti viši. Isto tako, neborbene aktivnosti nikada ne vraćaju više od 50, tako da će uvijek biti niže od borbenih. Ovo morate uzeti u obzir prilikom kreiranja radnji i izračunavanja njihove korisnosti.
U našem primjeru, akcije vraćaju ili fiksnu konstantnu vrijednost ili jednu od dvije fiksne vrijednosti. Realniji sistem bi vratio procjenu iz kontinuiranog raspona vrijednosti. Na primjer, akcija Bježanje vraća veće vrijednosti korisnosti ako je agentovo zdravlje slabo, a akcija Attacking vraća niže vrijednosti korisnosti ako je neprijatelj prejak. Zbog toga, akcija Bježanja ima prednost nad Napadom u svakoj situaciji u kojoj agent smatra da nema dovoljno zdravlja da porazi neprijatelja. Ovo omogućava da se radnje odredi prioritet na osnovu bilo kojeg broja kriterijuma, čineći ovaj pristup fleksibilnijim i varijabilnijim od stabla ponašanja ili FSM-a.
Svaka akcija ima mnogo uslova za proračun programa. Mogu biti napisane skriptnim jezikom ili kao niz matematičkih formula. Sims, koji simulira dnevnu rutinu lika, dodaje dodatni sloj proračuna - agent prima niz "motivacija" koji utiču na ocjenu korisnosti. Ako je lik gladan, vremenom će postati još gladniji, a vrijednost korisnosti akcije EatFood će se povećavati sve dok je lik ne izvrši, smanjujući razinu gladi i vraćajući vrijednost EatFood na nulu.
Ideja odabira radnji na osnovu sistema ocjenjivanja je prilično jednostavna, tako da se sistem zasnovan na uslužnim programima može koristiti kao dio procesa donošenja odluka AI, a ne kao potpuna zamjena za njih. Stablo odlučivanja može tražiti ocjenu korisnosti od dva podređena čvora i odabrati veći. Slično, stablo ponašanja može imati kompozitni uslužni čvor za procjenu korisnosti radnji za odlučivanje koje dijete izvršiti.
Kretanje i navigacija
U prethodnim primjerima imali smo platformu koju smo pomicali lijevo ili desno i stražara koji je patrolirao ili napadao. Ali kako tačno postupamo sa kretanjem agenata u određenom vremenskom periodu? Kako postavljamo brzinu, kako izbjegavamo prepreke i kako planiramo rutu kada je doći do odredišta teže nego samo pravolinijsko kretanje? Pogledajmo ovo.
Upravljanje
U početnoj fazi, pretpostavit ćemo da svaki agent ima vrijednost brzine, koja uključuje koliko se brzo kreće i u kojem smjeru. Može se mjeriti u metrima u sekundi, kilometrima na sat, pikselima u sekundi, itd. Prisjećajući se petlje Sense/Think/Act, možemo zamisliti da dio Think odabire brzinu, a dio Act primjenjuje tu brzinu na agenta. Obično igre imaju sistem fizike koji radi ovaj zadatak umjesto vas, učeći vrijednost brzine svakog objekta i prilagođavajući je. Stoga, AI možete ostaviti s jednim zadatkom - odlučiti kojom brzinom agent treba imati. Ako znate gdje bi agent trebao biti, onda ga morate pomaknuti u pravom smjeru zadanom brzinom. Vrlo trivijalna jednadžba:
željeno_putovanje = odredišna_pozicija – pozicija_ agenta
Zamislite 2D svijet. Agent je u tački (-2,-2), odredište je negdje na sjeveroistoku u tački (30, 20), a potrebna staza da agent tamo stigne je (32, 22). Recimo da se ove pozicije mjere u metrima - ako uzmemo brzinu agenta na 5 metara u sekundi, onda ćemo skalirati naš vektor pomaka i dobiti brzinu od približno (4.12, 2.83). Sa ovim parametrima agent bi na odredište stigao za skoro 8 sekundi.
Vrijednosti možete ponovo izračunati u bilo kojem trenutku. Da je agent bio na pola puta do cilja, kretanje bi bilo pola dužine, ali pošto je maksimalna brzina agenta 5 m/s (ovo smo odlučili gore), brzina će biti ista. Ovo također radi i za pokretne mete, omogućavajući agentu da napravi male promjene dok se kreću.
Ali želimo više varijacija - na primjer, polagano povećanje brzine kako bi se simulirao lik koji se kreće iz stajanja u trčanje. Isto se može učiniti na kraju prije zaustavljanja. Ove karakteristike su poznate kao ponašanja upravljanja, od kojih svaka ima specifične nazive: traženje, bijeg, dolazak, itd. Ideja je da se sile ubrzanja mogu primijeniti na brzinu agenta, na osnovu poređenja agentove pozicije i trenutne brzine sa odredištem u kako bi se koristile različite metode kretanja do cilja.
Svako ponašanje ima malo drugačiju svrhu. Traženje i dolazak su načini da premjestite agenta na odredište. Izbjegavanje prepreka i razdvajanje prilagođavaju kretanje agenta kako bi izbjegli prepreke na putu do cilja. Usklađenost i kohezija omogućavaju da se agenti kreću zajedno. Bilo koji broj različitih ponašanja upravljanja može se sabrati kako bi se dobio jedan vektor putanje uzimajući u obzir sve faktore. Agent koji koristi ponašanje dolaska, razdvajanja i izbjegavanja prepreka kako bi se držao podalje od zidova i drugih agenata. Ovaj pristup dobro funkcionira na otvorenim lokacijama bez nepotrebnih detalja.
U težim uvjetima, dodavanje različitih ponašanja djeluje lošije - na primjer, agent se može zaglaviti u zidu zbog sukoba između dolaska i izbjegavanja prepreka. Stoga morate razmotriti opcije koje su složenije od jednostavnog dodavanja svih vrijednosti. Način je sljedeći: umjesto zbrajanja rezultata svakog ponašanja, možete razmotriti kretanje u različitim smjerovima i odabrati najbolju opciju.
Međutim, u složenom okruženju sa ćorsokacima i izborima kojim putem ići, trebat će nam nešto još naprednije.
Pronalaženje načina
Ponašanje upravljanja je odlično za jednostavno kretanje na otvorenom (fudbalskom igralištu ili areni) gdje je od A do B ravna staza sa samo manjim obilaznicama oko prepreka. Za složene rute potrebno nam je pronalaženje puta, što je način istraživanja svijeta i odlučivanja o ruti kroz njega.
Najjednostavnije je primijeniti mrežu na svaki kvadrat pored agenta i procijeniti kome od njih je dozvoljeno da se kreće. Ako je jedno od njih odredište, pratite rutu od svakog kvadrata do prethodnog dok ne dođete do početka. Ovo je ruta. U suprotnom, ponovite postupak s obližnjim drugim kvadratima dok ne pronađete odredište ili dok vam ne ponestane kvadrata (što znači da nema moguće rute). Ovo je ono što je formalno poznato kao Breadth-First Search ili BFS (algoritam pretrage u širinu). Na svakom koraku gleda na sve strane (dakle širinu, "širinu"). Prostor za pretragu je poput valnog fronta koji se kreće dok ne dođe do željene lokacije – prostor za pretragu se širi na svakom koraku dok se ne uključi krajnja tačka, nakon čega se može pratiti do početka.
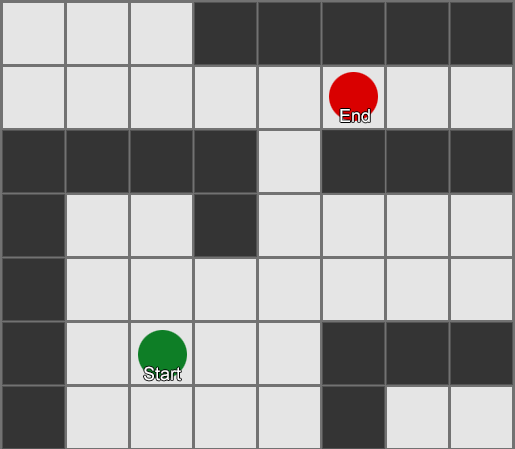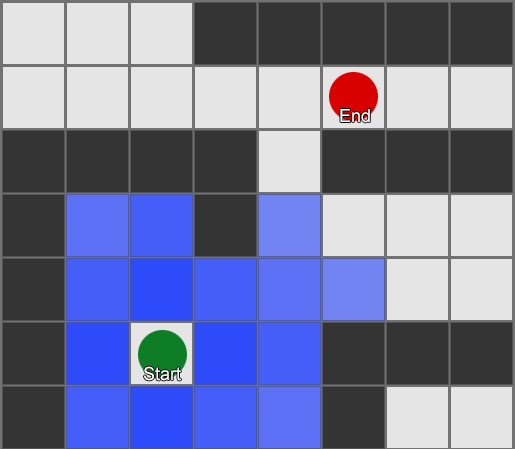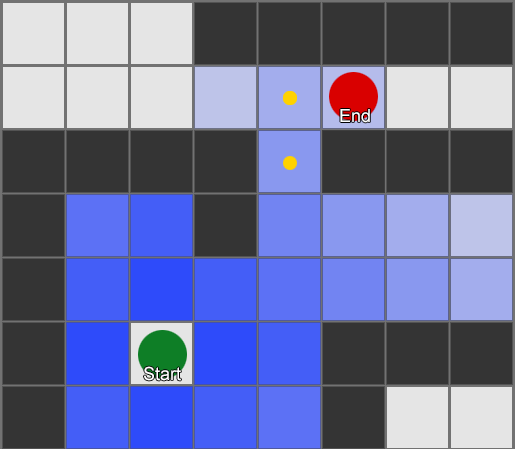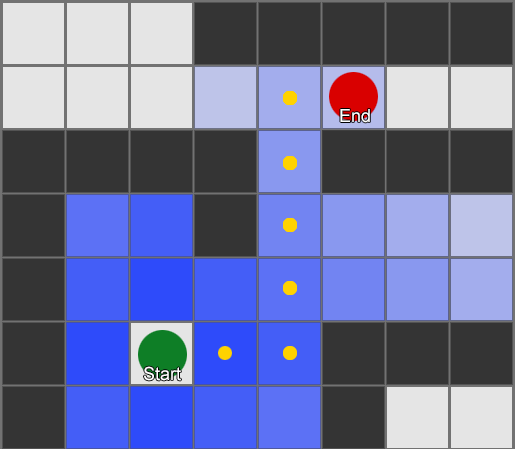
Kao rezultat, dobit ćete listu kvadrata duž kojih se sastavlja željena ruta. Ovo je put (dakle, pronalaženje puta) - lista mjesta koja će agent posjetiti dok prati odredište.
S obzirom na to da znamo poziciju svakog kvadrata na svijetu, možemo koristiti ponašanje upravljanja za kretanje duž putanje - od čvora 1 do čvora 2, zatim od čvora 2 do čvora 3, itd. Najjednostavnija opcija je krenuti prema centru sljedećeg kvadrata, ali još bolja opcija je da se zaustavite na sredini ruba između trenutnog i sljedećeg kvadrata. Zbog toga će agent moći rezati uglove na oštrim zavojima.
BFS algoritam ima i nedostatke - istražuje onoliko kvadrata u "pogrešnom" smjeru koliko i u "pravom" smjeru. Ovdje na scenu stupa složeniji algoritam koji se zove A* (A zvijezda). Radi na isti način, ali umjesto slijepog ispitivanja susjednih kvadrata (zatim susjeda susjeda, zatim susjeda susjeda susjeda, i tako dalje), skuplja čvorove u listu i sortira ih tako da je sljedeći ispitani čvor uvijek onaj koji vodi do najkraćeg puta. Čvorovi se sortiraju na osnovu heurističke metode koja uzima u obzir dvije stvari — „cijenu“ hipotetičke rute do željenog kvadrata (uključujući sve putne troškove) i procjenu koliko je taj kvadrat udaljen od odredišta (pristranost pretraživanja u pravi smjer).
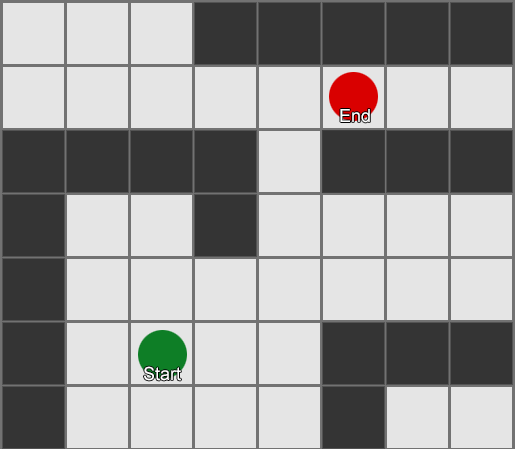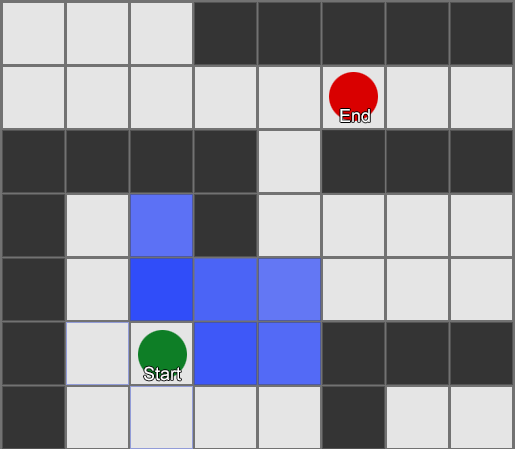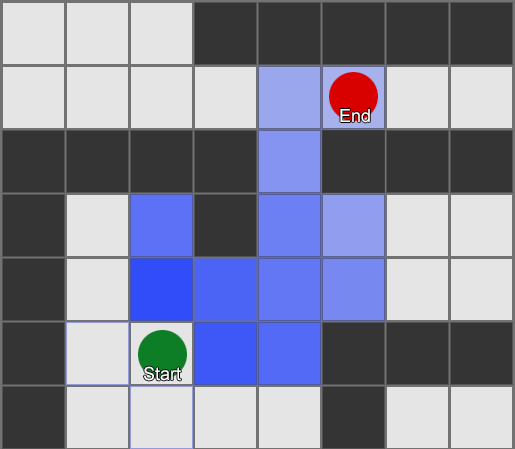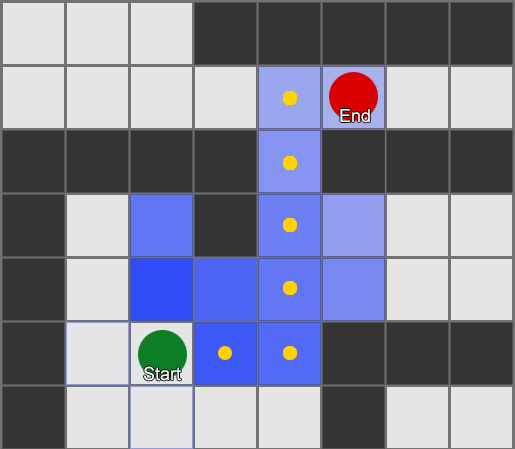
Ovaj primjer pokazuje da agent istražuje jedan po jedan kvadrat, svaki put birajući susjedni koji najviše obećava. Rezultirajuća putanja je ista kao i BFS, ali je manje kvadrata uzeto u obzir u procesu - što ima veliki utjecaj na performanse igre.
Kretanje bez rešetke
Ali većina igara nije raspoređena na mreži i često je nemoguće to učiniti bez žrtvovanja realizma. Potrebni su kompromisi. Koje veličine treba da budu kvadrati? Preveliki i neće moći pravilno da predstave male hodnike ili skretanja, premali i biće previše kvadrata za traženje, što će u konačnici potrajati.
Prva stvar koju treba razumjeti je da nam mreža daje graf povezanih čvorova. A* i BFS algoritmi zapravo rade na grafovima i uopće ih nije briga za našu mrežu. Mogli bismo postaviti čvorove bilo gdje u svijetu igre: sve dok postoji veza između bilo koja dva povezana čvora, kao i između početne i krajnje točke i barem jednog od čvorova, algoritam će raditi jednako dobro kao i prije. Ovo se često naziva sistemom putnih tačaka, budući da svaki čvor predstavlja značajnu poziciju u svijetu koja može biti dio bilo kojeg broja hipotetičkih puteva.
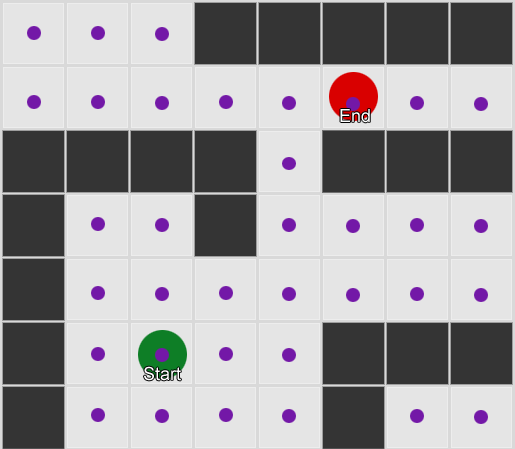
Primjer 1: čvor u svakom kvadratu. Pretraga počinje od čvora u kojem se agent nalazi i završava na čvoru željenog kvadrata.
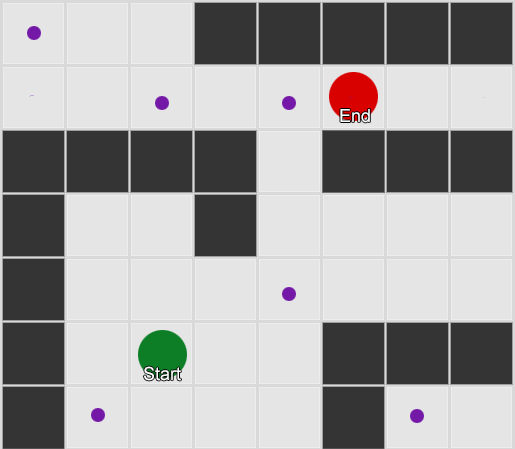
Primjer 2: Manji skup čvorova (putnih tačaka). Pretraga počinje na agentovom kvadratu, prolazi kroz potreban broj čvorova, a zatim se nastavlja do odredišta.
Ovo je potpuno fleksibilan i moćan sistem. Ali potrebna je određena pažnja pri odlučivanju gdje i kako postaviti međutačku, inače agenti jednostavno neće vidjeti najbližu tačku i neće moći započeti put. Bilo bi lakše kada bismo mogli automatski postaviti putne tačke na osnovu geometrije svijeta.
Ovdje se pojavljuje navigacijska mreža ili navmesh (navigacijska mreža). Ovo je obično 2D mreža trouglova koja je prekrivena geometrijom svijeta - gdje god je agentu dozvoljeno da hoda. Svaki od trouglova u mreži postaje čvor u grafu i ima do tri susedna trougla koji postaju susedni čvorovi u grafu.
Ova slika je primjer iz Unity engine-a - analizirala je geometriju u svijetu i kreirala navmesh (na snimku zaslona svijetlo plava). Svaki poligon u navmesh-u je područje u kojem agent može stajati ili se kretati s jednog poligona na drugi poligon. U ovom primjeru, poligoni su manji od etaža na kojima se nalaze - to je učinjeno kako bi se uzela u obzir veličina agenta koji će se širiti izvan svoje nominalne pozicije.

Možemo tražiti rutu kroz ovu mrežu, opet koristeći A* algoritam. Ovo će nam dati gotovo savršenu rutu u svijetu, koja uzima u obzir svu geometriju i ne zahtijeva nepotrebne čvorove i kreiranje putnih točaka.
Pronalaženje putanje je preširoka tema za koju jedan dio članka nije dovoljan. Ako ga želite detaljnije proučiti, onda će vam ovo pomoći .
Planiranje
Sa pronalaženjem puta naučili smo da ponekad nije dovoljno samo odabrati pravac i krenuti - moramo odabrati rutu i napraviti nekoliko skretanja da bismo došli do željenog odredišta. Ovu ideju možemo generalizirati: postizanje cilja nije samo sljedeći korak, već čitav niz u kojem ponekad morate pogledati nekoliko koraka unaprijed kako biste saznali koji bi prvi trebao biti. Ovo se zove planiranje. Pronalaženje puta se može smatrati jednim od nekoliko proširenja planiranja. Što se tiče našeg ciklusa Sense/Think/Act, ovo je mjesto gdje dio Razmišljanja planira više djelova Djela za budućnost.
Pogledajmo primjer društvene igre Magic: The Gathering. Idemo prvi sa sljedećim setom karata u rukama:
- Močvara - Daje 1 crnu manu (zemljišna karta).
- Šuma - daje 1 zelenu manu (zemljišna karta).
- Čarobnjak odbjeglog - Za prizivanje je potrebna 1 plava mana.
- Elvish Mystic - Za prizivanje je potrebna 1 zelena mana.
Zanemarimo preostale tri kartice kako bismo olakšali. Prema pravilima, igraču je dozvoljeno da igra 1 zemaljsku kartu po potezu, može "tapnuti" ovu kartu da izvuče manu iz nje, a zatim baca čarolije (uključujući pozivanje stvorenja) prema količini mane. U ovoj situaciji, ljudski igrač zna igrati Forest, dodirnuti 1 zelenu manu, a zatim pozvati Elvish Mystic. Ali kako AI igre to može shvatiti?
Lako planiranje
Trivijalan pristup je da pokušate svaku radnju redom dok ne preostane nijedna odgovarajuća. Gledajući karte, AI vidi šta Swamp može igrati. I on to svira. Ima li još nekih radnji u ovom skretanju? Ne može prizvati vilenjačkog mistika ili čarobnjaka odbjeglog, jer im je potrebna zelena i plava mana da bi ih pozvali, dok Močvara daje samo crnu manu. I više neće moći da igra Forest, jer je već igrao Močvaru. Tako je igra AI slijedila pravila, ali je to uradila loše. Može se poboljšati.
Planiranje može pronaći listu radnji koje igru dovode u željeno stanje. Kao što je svaki kvadrat na putu imao susjede (u pronalaženju puta), svaka akcija u planu također ima susjede ili nasljednike. Možemo tražiti ove i naknadne radnje dok ne dođemo do željenog stanja.
U našem primjeru, željeni rezultat je "pozovite stvorenje ako je moguće". Na početku okreta vidimo samo dvije moguće radnje dozvoljene pravilima igre:
1. Igrajte Swamp (rezultat: Swamp u igri)
2. Igrajte Forest (rezultat: Šuma u igri)
Svaka poduzeta radnja može dovesti do daljnjih radnji i zatvoriti druge, opet ovisno o pravilima igre. Zamislite da smo igrali Swamp - ovo će ukloniti Swamp kao sljedeći korak (već smo ga igrali), a ovo će također ukloniti Forest (jer prema pravilima možete igrati jednu zemlju kartu po potezu). Nakon ovoga, AI dodaje dobivanje 1 crne mane kao sljedeći korak jer nema drugih opcija. Ako krene naprijed i odabere Tap the Swamp, dobit će 1 jedinicu crne mane i neće moći ništa učiniti s njom.
1. Igrajte Swamp (rezultat: Swamp u igri)
1.1 “Tap” Močvara (rezultat: Močvara “tapčana”, +1 jedinica crne mane)
Nema dostupnih radnji - KRAJ
2. Igrajte Forest (rezultat: Šuma u igri)
Lista akcija je bila kratka, došli smo u ćorsokak. Ponavljamo postupak za sljedeći korak. Igramo Forest, otvaramo akciju "dobi 1 zelenu manu", koja će zauzvrat otvoriti treću akciju - pozvati Elvish Mystic.
1. Igrajte Swamp (rezultat: Swamp u igri)
1.1 “Tap” Močvara (rezultat: Močvara “tapčana”, +1 jedinica crne mane)
Nema dostupnih radnji - KRAJ
2. Igrajte Forest (rezultat: Šuma u igri)
2.1 “Tap” šuma (rezultat: šuma je “tapkana”, +1 jedinica zelene mane)
2.1.1 Pozovite Elvish Mystic (rezultat: Elvish Mystic u igri, -1 zelena mana)
Nema dostupnih radnji - KRAJ
Konačno smo istražili sve moguće radnje i pronašli plan koji priziva stvorenje.
Ovo je vrlo pojednostavljen primjer. Preporučljivo je odabrati najbolji mogući plan, a ne bilo koji plan koji ispunjava neke kriterije. Općenito je moguće ocijeniti potencijalne planove na osnovu ishoda ili ukupne koristi od njihove implementacije. Možete osvojiti 1 bod za igranje karte zemlje i 3 boda za prizivanje stvorenja. Igranje Swamp bi bio plan od 1 boda. A igranje Forest → Tap the Forest → pozovite Elvish Mystic će odmah dati 4 boda.
Ovako funkcionira planiranje u Magic: The Gatheringu, ali ista logika vrijedi i u drugim situacijama. Na primjer, pomicanje pješaka da bi se napravio prostor za biskupa da se kreće u šahu. Ili se sklonite iza zida da bezbedno snimate u XCOM-u ovako. Općenito, shvatili ste ideju.
Poboljšano planiranje
Ponekad postoji previše potencijalnih radnji da bismo razmotrili svaku moguću opciju. Da se vratimo na primjer sa Magic: The Gathering: recimo da u igri i u vašoj ruci postoji nekoliko karata zemlje i stvorenja - broj mogućih kombinacija poteza može biti na desetine. Postoji nekoliko rješenja za problem.
Prva metoda je ulančavanje unatrag. Umjesto isprobavanja svih kombinacija, bolje je početi s konačnim rezultatom i pokušati pronaći direktnu rutu. Umjesto da idemo od korijena stabla do određenog lista, krećemo se u suprotnom smjeru – od lista do korijena. Ova metoda je lakša i brža.
Ako neprijatelj ima 1 zdravlje, možete pronaći plan "zaradi 1 ili više štete". Da bi se to postiglo potrebno je ispuniti niz uslova:
1. Oštećenje može biti uzrokovano čarolijom - mora biti u ruci.
2. Da bacite čini, potrebna vam je mana.
3. Da biste dobili manu, morate odigrati kartu zemlje.
4. Da biste igrali zemaljsku kartu, morate je imati u ruci.
Drugi način je najbolje prvo pretraživanje. Umjesto da isprobavamo sve puteve, biramo najprikladniji. Najčešće ova metoda daje optimalan plan bez nepotrebnih troškova pretraživanja. A* je oblik najbolje prve pretrage - ispitivanjem najperspektivnijih ruta od početka, već može pronaći najbolju stazu bez potrebe da provjerava druge opcije.
Zanimljiva i sve popularnija opcija najbolje-prve pretrage je Monte Carlo Tree Search. Umjesto da nagađa koji su planovi bolji od drugih prilikom odabira svake sljedeće akcije, algoritam bira nasumične nasljednike u svakom koraku dok ne dođe do kraja (kada je plan rezultirao pobjedom ili porazom). Konačni rezultat se zatim koristi za povećanje ili smanjenje težine prethodnih opcija. Ponavljajući ovaj proces nekoliko puta zaredom, algoritam daje dobru procjenu koji je najbolji sljedeći potez, čak i ako se situacija promijeni (ako neprijatelj preduzme akciju da ometa igrača).
Nijedna priča o planiranju u igricama ne bi bila potpuna bez Goal-Oriented Action Planning ili GOAP-a (goal-oriented action planning). Ovo je široko korištena metoda i o kojoj se raspravlja, ali osim nekoliko posebnih detalja, to je u suštini metoda ulančavanja unatrag o kojoj smo ranije govorili. Ako je cilj bio "uništiti igrača", a igrač je iza zaklona, plan bi mogao biti: uništiti granatom → uzeti je → baciti.
Obično postoji nekoliko ciljeva, svaki sa svojim prioritetom. Ako se cilj najvišeg prioriteta ne može ispuniti (nijedna kombinacija radnji ne stvara plan "ubi igrača" jer igrač nije vidljiv), AI će se vratiti na ciljeve nižeg prioriteta.
Obuka i adaptacija
Već smo rekli da AI igre obično ne koristi mašinsko učenje jer nije pogodno za upravljanje agentima u realnom vremenu. Ali to ne znači da ne možete posuditi nešto iz ove oblasti. Želimo protivnika u šuteru od kojeg možemo nešto naučiti. Na primjer, saznajte o najboljim pozicijama na mapi. Ili protivnik u borbenoj igri koji bi blokirao igračeve često korištene kombinirane poteze, motivirajući ga da koristi druge. Dakle, mašinsko učenje može biti veoma korisno u takvim situacijama.
Statistika i vjerovatnoće
Prije nego što pređemo na složene primjere, hajde da vidimo koliko daleko možemo ići uzimajući nekoliko jednostavnih mjerenja i koristeći ih za donošenje odluka. Na primjer, strategija u realnom vremenu – kako odrediti da li igrač može krenuti u napad u prvih nekoliko minuta igre i kakvu odbranu treba pripremiti protiv toga? Možemo proučiti prošla iskustva igrača da bismo razumjeli kakve bi buduće reakcije mogle biti. Za početak, nemamo tako sirove podatke, ali ih možemo prikupiti - svaki put kada AI igra protiv čovjeka, može snimiti vrijeme prvog napada. Nakon nekoliko sesija, dobićemo prosjek vremena koje će igraču trebati da napadne u budućnosti.
Postoji i problem s prosječnim vrijednostima: ako je igrač jurio 20 puta i igrao polako 20 puta, tada će tražene vrijednosti biti negdje u sredini, a to nam neće dati ništa korisno. Jedno rješenje je ograničiti ulazne podatke - zadnjih 20 komada se može uzeti u obzir.
Sličan pristup se koristi kada se procjenjuje vjerovatnoća određenih radnji uz pretpostavku da će prethodne preferencije igrača biti iste u budućnosti. Ako nas igrač napadne pet puta vatrenom loptom, dva puta munjom i jednom meleom, očigledno je da preferira vatrenu loptu. Hajde da ekstrapoliramo i vidimo vjerovatnoću upotrebe različitog oružja: vatrena lopta=62,5%, munja=25% i melee=12,5%. Naša igra AI treba da se pripremi da se zaštiti od vatre.
Još jedna zanimljiva metoda je korištenje naivnog Bayesovog klasifikatora za proučavanje velikih količina ulaznih podataka i klasifikaciju situacije tako da AI reagira na željeni način. Bayesovi klasifikatori su najpoznatiji po upotrebi u filterima neželjene e-pošte. Tamo ispituju riječi, upoređuju ih s mjestima na kojima su se te riječi ranije pojavljivale (u neželjenoj pošti ili ne) i donose zaključke o dolaznim e-porukama. Možemo učiniti istu stvar čak i sa manje unosa. Na osnovu svih korisnih informacija koje AI vidi (poput toga koje su neprijateljske jedinice stvorene, ili koje čarolije koriste, ili koje su tehnologije istraživale), i konačnog rezultata (rat ili mir, žurba ili obrana, itd.) - izabraćemo željeno ponašanje AI.
Sve ove metode obuke su dovoljne, ali je preporučljivo koristiti ih na osnovu podataka testiranja. AI će naučiti da se prilagodi različitim strategijama koje su koristili vaši igrači. AI koji se prilagođava igraču nakon puštanja može postati previše predvidljiv ili previše težak za poraz.
Adaptacija zasnovana na vrijednosti
S obzirom na sadržaj našeg svijeta igre i pravila, možemo promijeniti skup vrijednosti koje utiču na donošenje odluka, umjesto da jednostavno koristimo ulazne podatke. radimo ovo:
- Neka AI prikuplja podatke o stanju svijeta i ključnim događajima tokom igre (kao gore).
- Promijenimo nekoliko važnih vrijednosti na osnovu ovih podataka.
- Mi implementiramo naše odluke na osnovu obrade ili evaluacije ovih vrijednosti.
Na primjer, agent ima nekoliko soba koje može izabrati na mapi pucačina iz prvog lica. Svaka soba ima svoju vrijednost, koja određuje koliko je poželjno posjetiti. AI nasumično bira u koju će sobu otići na osnovu vrijednosti. Agent tada pamti u kojoj je sobi ubijen i smanjuje njenu vrijednost (vjerovatnost da će se tamo vratiti). Slično i za obrnutu situaciju - ako agent uništi mnogo protivnika, onda se vrijednost sobe povećava.
Markov model
Šta ako bismo prikupljene podatke koristili za predviđanja? Ako pamtimo svaku sobu u kojoj vidimo igrača u određenom vremenskom periodu, predvidjeti ćemo u koju sobu bi igrač mogao otići. Praćenjem i snimanjem kretanja igrača po sobama (vrijednosti), možemo ih predvidjeti.
Uzmimo tri sobe: crvenu, zelenu i plavu. A također i zapažanja koja smo zabilježili dok smo gledali utakmicu:
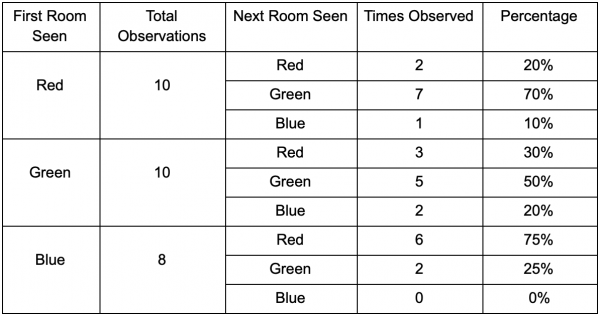
Broj zapažanja u svakoj prostoriji je gotovo jednak - još uvijek ne znamo gdje napraviti dobro mjesto za zasjedu. Prikupljanje statistike je također komplikovano ponovnim pojavljivanjem igrača, koji se pojavljuju ravnomjerno po cijeloj mapi. Ali podaci o sljedećoj prostoriji u koju ulaze nakon što se pojave na karti već su korisni.
Vidi se da zelena soba odgovara igračima - većina ljudi prelazi iz crvene sobe u nju, od kojih 50% ostaje tamo dalje. Plava soba, naprotiv, nije popularna u nju, a ako i ide, ne ostaje dugo.
Ali podaci nam govore nešto važnije – kada je igrač u plavoj sobi, sljedeća soba u kojoj ga vidimo bit će crvena, a ne zelena. Iako je zelena soba popularnija od crvene sobe, situacija se mijenja ako je igrač u plavoj sobi. Sljedeće stanje (tj. soba u koju će igrač otići) zavisi od prethodnog stanja (tj. sobe u kojoj se igrač trenutno nalazi). Budući da istražujemo ovisnosti, napravit ćemo preciznija predviđanja nego kada bismo jednostavno neovisno brojali opažanja.
Predviđanje budućeg stanja na osnovu podataka iz prošlog stanja naziva se Markovljev model, a takvi primjeri (sa sobama) nazivaju se Markovljevi lanci. Budući da obrasci predstavljaju vjerovatnoću promjena između uzastopnih stanja, oni se vizualno prikazuju kao FSM-ovi s vjerovatnoćom oko svake tranzicije. Ranije smo koristili FSM za predstavljanje stanja ponašanja u kojem je agent bio, ali ovaj koncept se proteže na bilo koje stanje, bez obzira da li je povezano s agentom ili ne. U ovom slučaju, stanja predstavljaju prostoriju koju agent zauzima:
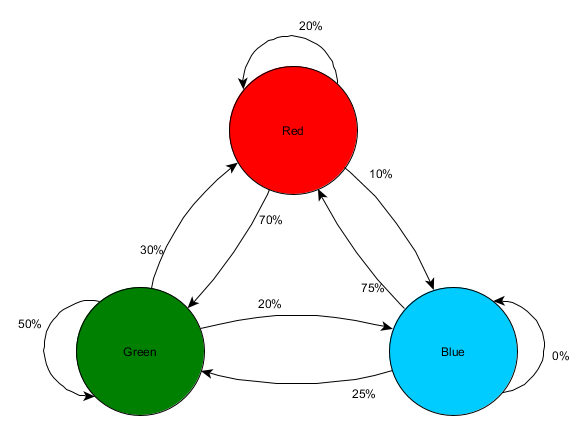
Ovo je jednostavan način predstavljanja relativne vjerovatnoće promjena stanja, dajući AI određenu sposobnost da predvidi sljedeće stanje. Možete predvidjeti nekoliko koraka unaprijed.
Ako je igrač u zelenoj sobi, postoji 50% šanse da će ostati tamo sljedeći put kada bude promatran. Ali kakve su šanse da će i nakon toga ostati tamo? Ne samo da postoji šansa da je igrač ostao u zelenoj sobi nakon dva posmatranja, već postoji i šansa da je otišao i vratio se. Evo nove tabele koja uzima u obzir nove podatke:
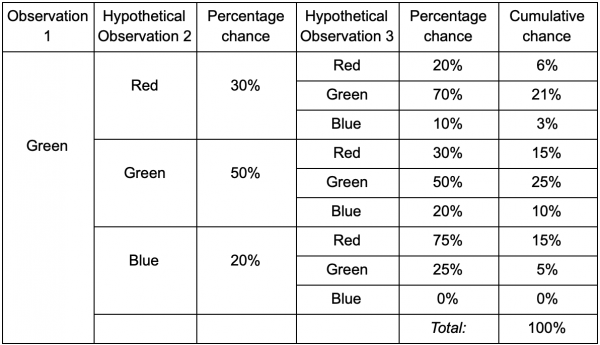
Pokazuje da će šansa da se igrač vidi u zelenoj sobi nakon dva posmatranja jednaka 51% - 21% da će biti iz crvene sobe, 5% da će igrač posjetiti plavu sobu između njih, i 25% koje igrač neće napustiti zelenu sobu.
Tabela je jednostavno vizuelni alat - procedura zahteva samo množenje verovatnoće u svakom koraku. To znači da možete gledati daleko u budućnost uz jedno upozorenje: pretpostavljamo da šansa za ulazak u sobu u potpunosti ovisi o trenutnoj prostoriji. Ovo se zove Markovljevo svojstvo - buduće stanje zavisi samo od sadašnjosti. Ali ovo nije sto posto tačno. Igrači mogu mijenjati odluke ovisno o drugim faktorima: zdravstvenom nivou ili količini municije. Budući da ne bilježimo ove vrijednosti, naše će prognoze biti manje tačne.
N-Grams
Što je s primjerom borbene igre i predviđanjem kombinacija igrača? Isto! Ali umjesto jednog stanja ili događaja, ispitat ćemo cijele sekvence koje čine kombinovani udar.
Jedan od načina da to učinite je da pohranite svaki ulaz (kao što je Kick, Punch ili Block) u bafer i zapišete cijeli bafer kao događaj. Dakle, igrač više puta pritiska Kick, Kick, Punch da koristi napad SuperDeathFist, AI sistem pohranjuje sve ulaze u međuspremnik i pamti posljednja tri korištena u svakom koraku.
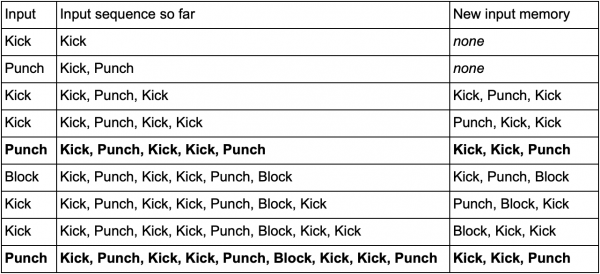
(Podebljane linije su kada igrač pokrene napad SuperDeathFist.)
AI će vidjeti sve opcije kada igrač odabere Kick, nakon čega slijedi još jedan udarac, a zatim primijeti da je sljedeći unos uvijek Punch. Ovo će omogućiti agentu da predvidi kombinovani potez SuperDeathFista i blokira ga ako je moguće.
Ovi nizovi događaja nazivaju se N-grami, gdje je N broj pohranjenih elemenata. U prethodnom primjeru to je bio 3-gram (trigram), što znači: prva dva unosa se koriste za predviđanje trećeg. Shodno tome, u 5-gramu, prva četiri unosa predviđaju petu i tako dalje.
Dizajner treba pažljivo odabrati veličinu N-grama. Manje N zahtijeva manje memorije, ali također pohranjuje manje povijesti. Na primjer, 2-gram (bigram) će snimiti Kick, Kick ili Kick, Punch, ali neće moći pohraniti Kick, Kick, Punch, tako da AI neće odgovoriti na kombinaciju SuperDeathFist.
S druge strane, veći brojevi zahtijevaju više memorije i AI će biti teže trenirati jer će biti mnogo više mogućih opcija. Da imate tri moguća unosa Kick, Punch ili Block, a mi koristimo 10-gram, to bi bilo oko 60 hiljada različitih opcija.
Bigramski model je jednostavan Markovljev lanac - svaki par prošlih stanja/trenutnog stanja je bigram, a drugo stanje možete predvidjeti na osnovu prvog. N-grami od 3 grama i veći se također mogu smatrati Markovljevim lancima, gdje svi elementi (osim posljednjeg u N-gramu) zajedno čine prvo stanje, a posljednji element drugo. Primjer borbene igre pokazuje mogućnost prijelaza iz stanja udarca i udarca u stanje udarca i udarca. Tretirajući višestruke unose istorije unosa kao jednu jedinicu, mi u suštini transformišemo ulaznu sekvencu u deo celog stanja. Ovo nam daje Markovljevo svojstvo, koje nam omogućava da koristimo Markovljeve lance da predvidimo sljedeći ulaz i pogodimo koji će kombo potez biti sljedeći.
zaključak
Razgovarali smo o najčešćim alatima i pristupima u razvoju umjetne inteligencije. Razmotrili smo i situacije u kojima ih treba koristiti i gdje su posebno korisni.
Ovo bi trebalo biti dovoljno za razumijevanje osnova AI igre. Ali, naravno, to nisu sve metode. Manje popularni, ali ne manje efikasni uključuju:
- algoritmi optimizacije uključujući penjanje uzbrdo, gradijentni spust i genetske algoritme
- algoritmi za suparničko pretraživanje/raspored (minimax i alfa-beta skraćenje)
- metode klasifikacije (perceptroni, neuronske mreže i mašine za vektore podrške)
- sistemi za obradu percepcije i memorije agenata
- arhitektonski pristupi AI (hibridni sistemi, arhitekture podskupova i drugi načini preklapanja AI sistema)
- alati za animaciju (planiranje i koordinacija pokreta)
- faktori performansi (nivo detalja, bilo kada i algoritmi za određivanje vremena)
Online resursi na ovu temu:
1. GameDev.net ima I .
2. sadrži mnoge prezentacije i članke o širokom spektru tema vezanih za razvoj AI igara.
3. uključuje teme sa GDC AI samita, od kojih su mnoge dostupne besplatno.
4. Korisni materijali se također mogu naći na web stranici .
5. Tommy Thompson, istraživač umjetne inteligencije i programer igara, snima video zapise na YouTube-u sa objašnjenjem i proučavanjem AI u komercijalnim igrama.
Knjige na temu:
1. Serija knjiga Game AI Pro je zbirka kratkih članaka koji objašnjavaju kako implementirati određene funkcije ili kako riješiti specifične probleme.
2. AI Game Programming Wisdom serijal je prethodnik Game AI Pro serije. Sadrži starije metode, ali gotovo sve su aktuelne i danas.
3. jedan je od osnovnih tekstova za sve koji žele razumjeti opće područje umjetne inteligencije. Ovo nije knjiga o razvoju igara - ona podučava osnove AI.
izvor: www.habr.com
