

En aquest article, parlaré de com el projecte en el qual estic treballant es va transformar d'un gran monòlit a un conjunt de microserveis.
El projecte va començar la seva història fa força temps, a principis de l'any 2000. Les primeres versions es van escriure en Visual Basic 6. Amb el temps, va quedar clar que el desenvolupament en aquest llenguatge seria difícil de suportar en el futur, ja que l'IDE i el propi llenguatge està poc desenvolupat. A finals dels anys 2000, es va decidir canviar al C# més prometedor. La nova versió es va escriure paral·lelament a la revisió de l'antiga, a poc a poc es va escriure més codi en .NET. El backend en C# es va centrar inicialment en una arquitectura de serveis, però durant el desenvolupament, es van utilitzar biblioteques comunes amb lògica i els serveis es van llançar en un sol procés. El resultat va ser una aplicació que vam anomenar "monòlit de servei".
Un dels pocs avantatges d'aquesta combinació era la capacitat dels serveis de trucar-se entre ells mitjançant una API externa. Hi havia uns requisits previs clars per a la transició a un servei més correcte i, en el futur, una arquitectura de microserveis.
Vam començar el nostre treball de descomposició cap al 2015. Encara no hem arribat a un estat ideal: encara hi ha parts d'un gran projecte que difícilment es poden anomenar monòlits, però tampoc semblen microserveis. No obstant això, el progrés és important.
En parlaré a l'article.
Contingut
Arquitectura i problemes de la solució existent
Inicialment, l'arquitectura tenia aquest aspecte: la interfície d'usuari és una aplicació independent, la part monolítica està escrita en Visual Basic 6, l'aplicació .NET és un conjunt de serveis relacionats que treballen amb una base de dades força gran.
Inconvenients de la solució anterior
Punt únic de fallada
Vam tenir un únic punt d'error: l'aplicació .NET es va executar en un sol procés. Si algun mòdul fallava, fallava tota l'aplicació i s'havia de reiniciar. Com que automatitzem un gran nombre de processos per a diferents usuaris, a causa d'una fallada en un d'ells, tothom no va poder treballar durant algun temps. I en cas d'error de programari, fins i tot la còpia de seguretat no va ajudar.
Cua de millores
Aquest inconvenient és més aviat organitzatiu. La nostra aplicació té molts clients, i tots volen millorar-la el més aviat possible. Abans, era impossible fer-ho en paral·lel i tots els clients es van fer cua. Aquest procés va ser negatiu per a les empreses perquè havien de demostrar que la seva tasca era valuosa. I l'equip de desenvolupament va dedicar temps a organitzar aquesta cua. Això va suposar molt de temps i esforç i, finalment, el producte no va poder canviar tan ràpidament com haurien volgut.
Ús subòptim dels recursos
Quan allotgem serveis en un sol procés, sempre vam copiar completament la configuració de servidor a servidor. Volíem col·locar els serveis amb més càrrega per separat per no malgastar recursos i obtenir un control més flexible sobre el nostre esquema de desplegament.
Difícil d'implementar les tecnologies modernes
Un problema conegut per a tots els desenvolupadors: hi ha un desig d'introduir tecnologies modernes al projecte, però no hi ha oportunitat. Amb una gran solució monolítica, qualsevol actualització de la biblioteca actual, per no parlar de la transició a una de nova, es converteix en una tasca no trivial. Es necessita molt de temps per demostrar al líder de l'equip que això comportarà més bonificacions que nervis malgastats.
Dificultat per emetre canvis
Aquest va ser el problema més greu: vam publicar llançaments cada dos mesos.
Cada llançament es va convertir en un autèntic desastre per al banc, malgrat les proves i els esforços dels desenvolupadors. El negoci va entendre que a principis de setmana algunes de les seves funcionalitats no funcionaran. I els desenvolupadors van entendre que els esperava una setmana de greus incidents.
Tothom tenia el desig de canviar la situació.
Expectatives dels microserveis
Emissió de components quan estigui llest. Lliurament de components quan estiguin preparats mitjançant la descomposició de la solució i la separació de diferents processos.
Petits equips de producte. Això és important perquè un gran equip que treballava a l'antic monòlit era difícil de gestionar. Aquest equip es va veure obligat a treballar segons un procés estricte, però volien més creativitat i independència. Només els petits equips es podien permetre això.
Aïllament de serveis en processos separats. Idealment, m'agradaria aïllar-lo en contenidors, però un gran nombre de serveis escrits al .NET Framework només s'executen sota WindowsAra apareixen serveis basats en .NET Core, però encara n'hi ha pocs.
Flexibilitat de desplegament. Ens agradaria combinar els serveis com ho necessitem, i no com ho obliga el codi.
Ús de les noves tecnologies. Això és interessant per a qualsevol programador.
Problemes de transició
Per descomptat, si fos fàcil trencar un monòlit en microserveis, no caldria parlar-ne a les conferències ni escriure articles. Hi ha molts esculls en aquest procés; descriuré els principals que ens han impedit.
El primer problema típic de la majoria de monòlits: coherència de la lògica empresarial. Quan escrivim un monòlit, volem reutilitzar les nostres classes per no escriure codi innecessari. I quan es passa als microserveis, això es converteix en un problema: tot el codi està força acoblat i és difícil separar els serveis.
En el moment de l'inici del treball, el repositori tenia més de 500 projectes i més de 700 mil línies de codi. Aquesta és una decisió força important i segon problema. No era possible simplement agafar-lo i dividir-lo en microserveis.
Tercer problema - La manca d'infraestructures necessàries. De fet, estàvem copiant manualment el codi font als servidors.
Com passar del monòlit als microserveis
Provisió de microserveis
En primer lloc, vam determinar immediatament per nosaltres mateixos que la separació de microserveis és un procés iteratiu. Sempre se'ns va demanar que desenvolupéssim problemes empresarials en paral·lel. Com implementarem això tècnicament ja és el nostre problema. Per tant, ens hem preparat per a un procés iteratiu. No funcionarà d'una altra manera si teniu una aplicació gran i inicialment no està llesta per ser reescrita.
Quins mètodes utilitzem per aïllar els microserveis?
La primera manera — traslladar els mòduls existents com a serveis. En aquest sentit, vam tenir sort: ja hi havia serveis registrats que funcionaven amb el protocol WCF. Es van separar en assemblees separades. Els vam portar per separat, afegint un petit llançador a cada construcció. Va ser escrit amb la meravellosa biblioteca Topshelf, que us permet executar l'aplicació tant com a servei com a consola. Això és convenient per a la depuració, ja que no calen projectes addicionals a la solució.
Els serveis estaven connectats segons la lògica de negoci, ja que utilitzaven conjunts comuns i treballaven amb una base de dades comuna. Difícilment es podrien anomenar microserveis en la seva forma pura. Tanmateix, podríem oferir aquests serveis per separat, en diferents processos. Només això va permetre reduir la seva influència els uns sobre els altres, reduint el problema amb el desenvolupament paral·lel i un únic punt de fallada.
El muntatge amb l'amfitrió és només una línia de codi a la classe Program. Vam amagar el treball amb Topshelf en una classe auxiliar.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
La segona manera d'assignar microserveis és: crear-los per resoldre nous problemes. Si al mateix temps el monòlit no creix, això ja és excel·lent, la qual cosa vol dir que anem en la direcció correcta. Per resoldre nous problemes, hem intentat crear serveis separats. Si hi havia aquesta oportunitat, vam crear serveis més "canònics" que gestionen completament el seu propi model de dades, una base de dades separada.
Nosaltres, com molts, vam començar amb serveis d'autenticació i autorització. Són perfectes per a això. Són independents, per regla general, tenen un model de dades independent. Ells mateixos no interactuen amb el monòlit, només recorre a ells per resoldre alguns problemes. Mitjançant aquests serveis, podeu començar la transició a una nova arquitectura, depurar-ne la infraestructura, provar alguns enfocaments relacionats amb les biblioteques de xarxa, etc. No tenim cap equip a la nostra organització que no pugui crear un servei d'autenticació.
La tercera manera d'assignar microserveisEl que fem servir és una mica específic per a nosaltres. Aquesta és l'eliminació de la lògica empresarial de la capa d'IU. La nostra aplicació principal d'interfície d'usuari és l'escriptori; com el backend, està escrit en C#. Els desenvolupadors van cometre errors periòdicament i van transferir parts de la lògica a la interfície d'usuari que haurien d'haver existit al backend i reutilitzades.
Si observeu un exemple real del codi de la part d'IU, podeu veure que la major part d'aquesta solució conté lògica de negoci real que és útil en altres processos, no només per crear el formulari d'IU.
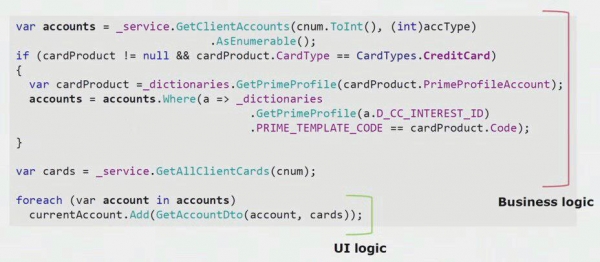
La lògica real de la interfície d'usuari només hi és a les últimes dues línies. El vam transferir al servidor perquè es pogués reutilitzar, reduint així la interfície d'usuari i aconseguint l'arquitectura correcta.
La quarta i més important manera d'aïllar els microserveis, que permet reduir el monòlit, és la supressió dels serveis existents amb tramitació. Quan traiem mòduls existents tal com estan, el resultat no sempre és del gust dels desenvolupadors i el procés de negoci pot haver quedat obsolet des que es va crear la funcionalitat. Amb la refactorització, podem donar suport a un nou procés de negoci perquè els requisits empresarials canvien constantment. Podem millorar el codi font, eliminar defectes coneguts i crear un model de dades millor. Hi ha molts beneficis acumulats.
La separació dels serveis del processament està inextricablement lligada al concepte de context limitat. Aquest és un concepte de Domain Driven Design. Significa una secció del model de domini en què tots els termes d'un sol llenguatge estan definits de manera única. Vegem com a exemple el context de les assegurances i les factures. Tenim una aplicació monolítica, i hem de treballar amb el compte a l'assegurança. Esperem que el desenvolupador trobi una classe de compte existent en un altre conjunt, la faci referència des de la classe d'assegurança i tindrem el codi de treball. Es respectarà el principi DRY, la tasca es farà més ràpid utilitzant el codi existent.
Com a resultat, resulta que els contextos de comptes i assegurances estan connectats. A mesura que sorgeixin nous requisits, aquest acoblament interferirà amb el desenvolupament, augmentant la complexitat de la ja complexa lògica empresarial. Per resoldre aquest problema, heu de trobar els límits entre contextos al codi i eliminar-ne les infraccions. Per exemple, en el context de l'assegurança, és molt possible que un número de compte del Banc Central de 20 dígits i la data d'obertura del compte siguin suficients.
Per separar aquests contextos limitats entre si i començar el procés de separació dels microserveis d'una solució monolítica, hem utilitzat un enfocament com ara crear API externes dins de l'aplicació. Si sabíem que algun mòdul s'havia de convertir en un microservei, d'alguna manera modificat dins del procés, de seguida vam fer trucades a la lògica que pertany a un altre context limitat mitjançant trucades externes. Per exemple, mitjançant REST o WCF.
Vam decidir fermament que no evitaríem el codi que requeriria transaccions distribuïdes. En el nostre cas, va resultar bastant fàcil seguir aquesta regla. Encara no ens hem trobat amb situacions en què realment es necessiten transaccions distribuïdes estrictes: la coherència final entre mòduls és bastant suficient.
Vegem un exemple concret. Tenim el concepte d'un orquestrador: un pipeline que processa l'entitat de l'"aplicació". Crea al seu torn un client, un compte i una targeta bancària. Si el client i el compte es creen correctament, però la creació de la targeta falla, l'aplicació no passa a l'estat d'"èxit" i es manté en l'estat de "targeta no creada". En el futur, l'activitat de fons el recollirà i l'acabarà. El sistema fa temps que es troba en un estat d'incoherència, però en general estem satisfets amb això.
Si es produeix una situació en què cal desar de manera coherent part de les dades, el més probable és que anem a la consolidació del servei per tal de processar-lo en un sol procés.
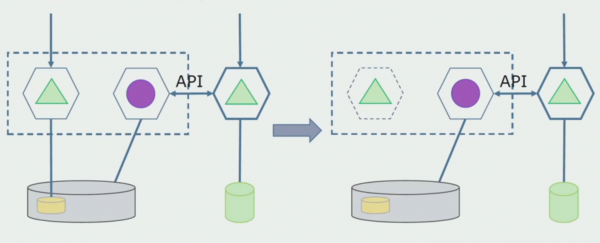
Vegem un exemple d'assignació d'un microservei. Com es pot portar a la producció amb relativa seguretat? En aquest exemple, tenim una part separada del sistema: un mòdul de servei de nòmines, una de les seccions de codi del qual voldríem fer un microservei.
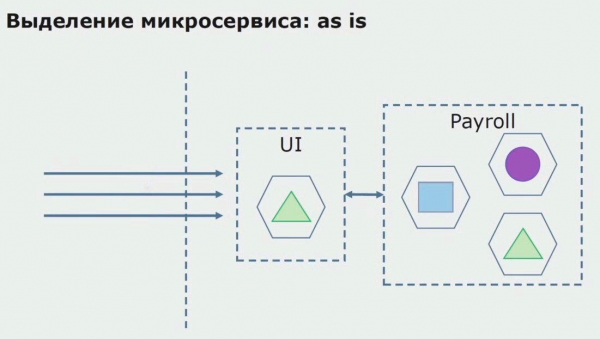
En primer lloc, creem un microservei reescrivint el codi. Estem millorant alguns aspectes amb els quals no estàvem contents. Implementem nous requisits comercials del client. Afegim una passarel·la API a la connexió entre la interfície d'usuari i el backend, que proporcionarà un desviament de trucades.
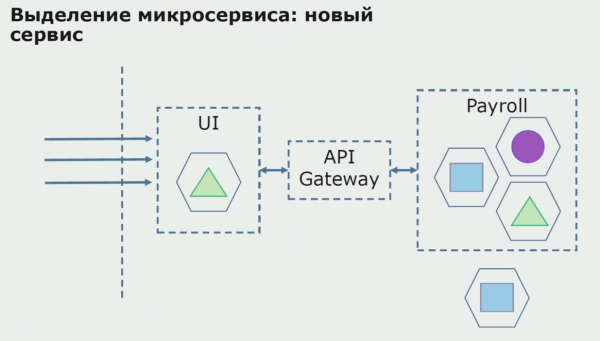
A continuació, posem en funcionament aquesta configuració, però en estat pilot. La majoria dels nostres usuaris encara treballen amb processos empresarials antics. Per als nous usuaris, estem desenvolupant una nova versió de l'aplicació monolítica que ja no conté aquest procés. Essencialment, tenim una combinació d'un monòlit i un microservei que funciona com a pilot.
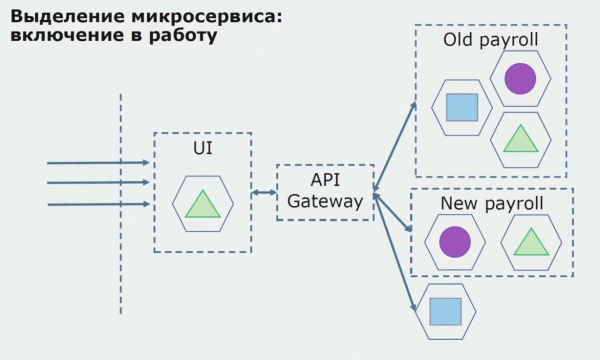
Amb un pilot reeixit, entenem que la nova configuració és efectivament viable, podem eliminar el monòlit antic de l'equació i deixar la nova configuració en lloc de la solució antiga.
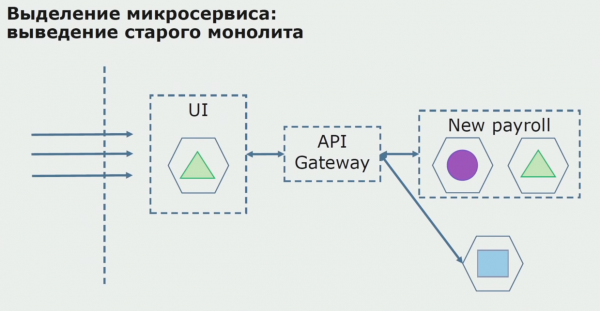
En total, utilitzem gairebé tots els mètodes existents per dividir el codi font d'un monòlit. Tots ells ens permeten reduir la mida de les parts de l'aplicació i traduir-les a noves biblioteques, fent millor el codi font.
Treballant amb la base de dades
La base de dades es pot dividir pitjor que el codi font, ja que conté no només l'esquema actual, sinó també dades històriques acumulades.
La nostra base de dades, com moltes altres, tenia un altre inconvenient important: la seva gran mida. Aquesta base de dades es va dissenyar d'acord amb la intricada lògica empresarial d'un monòlit i les relacions acumulades entre les taules de diversos contextos acotats.
En el nostre cas, per acabar amb tots els problemes (base de dades gran, moltes connexions, de vegades límits poc clars entre taules), va sorgir un problema que es produeix en molts projectes grans: l'ús de la plantilla de base de dades compartida. Les dades es van extreure de taules a través de la visualització, mitjançant la rèplica i es van enviar a altres sistemes on es necessitava aquesta rèplica. Com a resultat, no vam poder moure les taules a un esquema separat perquè s'utilitzaven activament.
La mateixa divisió en contextos limitats al codi ens ajuda a separar-nos. Normalment ens dóna una idea força bona de com desglossem les dades a nivell de base de dades. Entenem quines taules pertanyen a un context acotat i quines a un altre.
Hem utilitzat dos mètodes globals de partició de bases de dades: particionament de taules existents i particionament amb processament.
Dividir les taules existents és un bon mètode per utilitzar si l'estructura de dades és bona, compleix els requisits empresarials i tothom n'està satisfet. En aquest cas, podem separar les taules existents en un esquema separat.
Cal un departament amb tramitació quan el model de negoci ha canviat molt, i les taules ja no ens satisfan gens.
Divisió de taules existents. Hem de determinar què separarem. Sense aquest coneixement, res funcionarà, i aquí la separació de contextos acotats en el codi ens ajudarà. Per regla general, si podeu entendre els límits dels contextos al codi font, queda clar quines taules s'han d'incloure a la llista del departament.
Imaginem que tenim una solució en la qual dos mòduls monòlits interactuen amb una base de dades. Hem d'assegurar-nos que només un mòdul interactua amb la secció de taules separades i l'altre comença a interactuar amb ell mitjançant l'API. Per començar, n'hi ha prou que només la gravació es faci a través de l'API. Aquesta és una condició necessària perquè parlem de la independència dels microserveis. Les connexions de lectura poden romandre sempre que no hi hagi un gran problema.
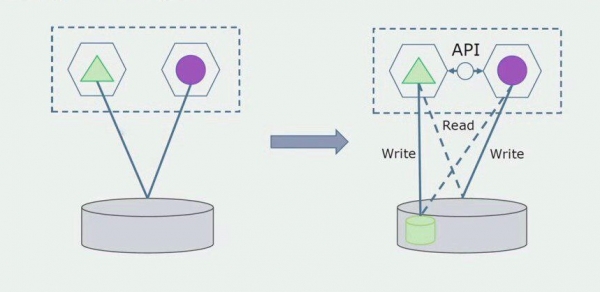
El següent pas és que podem separar la secció de codi que funciona amb taules separades, amb o sense processament, en un microservei independent i executar-lo en un procés independent, un contenidor. Aquest serà un servei independent amb connexió a la base de dades del monòlit i aquelles taules que no hi estiguin relacionades directament. El monòlit encara interactua per llegir amb la part desmuntable.
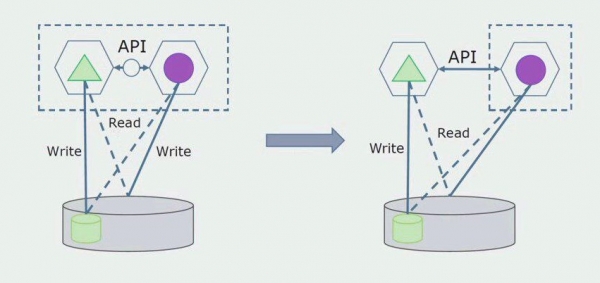
Més endavant eliminarem aquesta connexió, és a dir, la lectura de dades d'una aplicació monolítica de taules separades també es transferirà a l'API.
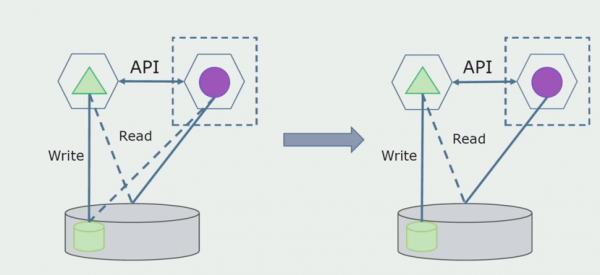
A continuació, seleccionarem de la base de dades general les taules amb les quals només funciona el nou microservei. Podem moure les taules a un esquema independent o fins i tot a una base de dades física independent. Encara hi ha una connexió de lectura entre el microservei i la base de dades monòlit, però no hi ha res de què preocupar-se, en aquesta configuració pot viure força temps.
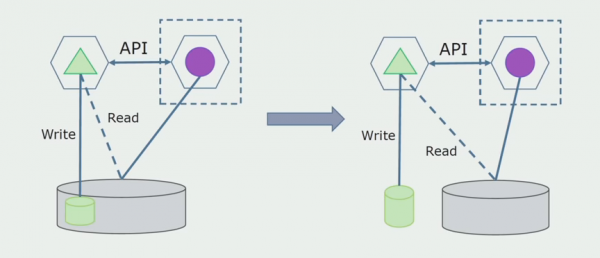
L'últim pas és eliminar completament totes les connexions. En aquest cas, és possible que hàgim de migrar les dades de la base de dades principal. De vegades volem reutilitzar algunes dades o directoris replicats de sistemes externs en diverses bases de dades. Això ens passa periòdicament.
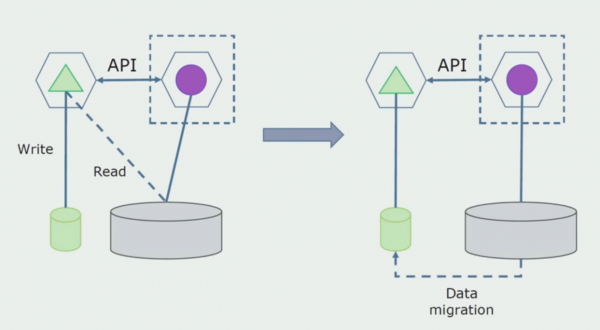
Departament de processament. Aquest mètode és molt semblant al primer, només en ordre invers. Immediatament assignem una nova base de dades i un nou microservei que interactua amb el monòlit mitjançant una API. Però al mateix temps, queda un conjunt de taules de bases de dades que volem suprimir en el futur. Ja no el necessitem; el vam substituir pel nou model.
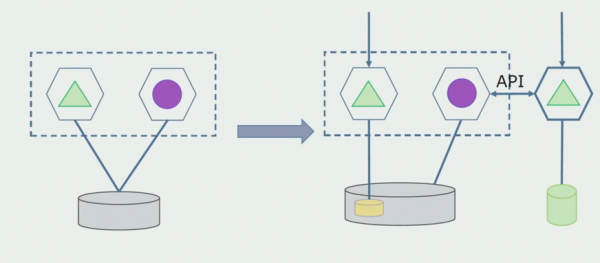
Perquè aquest esquema funcioni, probablement necessitarem un període de transició.
Aleshores hi ha dos enfocaments possibles.
Primer: dupliquem totes les dades a les bases de dades noves i antigues. En aquest cas, tenim redundància de dades i poden sorgir problemes de sincronització. Però podem agafar dos clients diferents. Un funcionarà amb la nova versió, l'altre amb l'antiga.
Segon: dividim les dades segons uns criteris empresarials. Per exemple, teníem 5 productes al sistema que estaven emmagatzemats a la base de dades antiga. Col·loquem el sisè dins de la nova tasca empresarial en una nova base de dades. Però necessitarem una API Gateway que sincronitzi aquestes dades i mostri al client d'on i què ha d'obtenir.
Tots dos enfocaments funcionen, trieu en funció de la situació.
Després d'estar segurs que tot funciona, la part del monòlit que funciona amb estructures de bases de dades antigues es pot desactivar.
L'últim pas és eliminar les estructures de dades antigues.
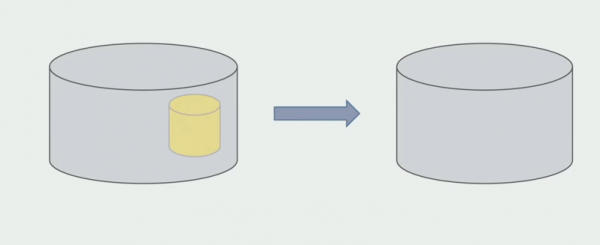
En resum, podem dir que tenim problemes amb la base de dades: és difícil treballar-hi en comparació amb el codi font, és més difícil de compartir, però es pot i s'ha de fer. Hem trobat algunes maneres que ens permeten fer-ho amb força seguretat, però encara és més fàcil cometre errors amb les dades que amb el codi font.
Treballant amb codi font
Així es veia el diagrama del codi font quan vam començar a analitzar el projecte monolític.
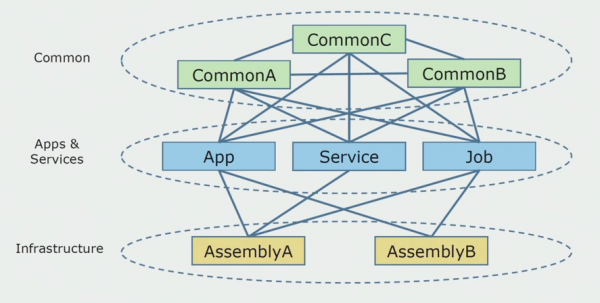
Es pot dividir aproximadament en tres capes. Aquesta és una capa de mòduls, connectors, serveis i activitats individuals llançats. De fet, aquests eren punts d'entrada dins d'una solució monolítica. Tots ells estaven ben tancats amb una capa comuna. Tenia una lògica empresarial que els serveis compartien i moltes connexions. Cada servei i connector utilitzava fins a 10 o més muntatges habituals, depenent de la seva mida i de la consciència dels desenvolupadors.
Vam tenir la sort de tenir biblioteques d'infraestructura que es podien utilitzar per separat.
De vegades va sorgir una situació en què alguns objectes comuns en realitat no pertanyien a aquesta capa, sinó que eren biblioteques d'infraestructura. Això es va solucionar canviant el nom.
La preocupació més gran eren els contextos acotats. Va passar que 3-4 contextos es van barrejar en un conjunt comú i s'utilitzaven entre si dins de les mateixes funcions empresarials. Calia entendre on es podria dividir i al llarg de quins límits, i què fer a continuació amb el mapeig d'aquesta divisió en conjunts de codi font.
Hem formulat diverses regles per al procés de divisió del codi.
La primera: Ja no volíem compartir la lògica empresarial entre serveis, activitats i connectors. Volíem fer que la lògica empresarial sigui independent dins dels microserveis. Els microserveis, en canvi, es pensen idealment com a serveis que existeixen de manera totalment independent. Crec que aquest enfocament és una mica malbaratador, i és difícil d'aconseguir, perquè, per exemple, els serveis en C# estaran connectats en qualsevol cas mitjançant una biblioteca estàndard. El nostre sistema està escrit en C#; encara no hem utilitzat altres tecnologies. Per tant, vam decidir que ens podíem permetre el luxe d'utilitzar conjunts tècnics comuns. El més important és que no contenen cap fragment de lògica empresarial. Si teniu un embolcall de comoditat sobre l'ORM que feu servir, copiar-lo d'un servei a un altre és molt car.
El nostre equip és un fanàtic del disseny basat en dominis, de manera que l'arquitectura de ceba ens va quedar molt bé. La base dels nostres serveis no és la capa d'accés a les dades, sinó un conjunt amb lògica de domini, que només conté lògica de negoci i no té connexions amb la infraestructura. Al mateix temps, podem modificar de manera independent el conjunt del domini per resoldre problemes relacionats amb els frameworks.
En aquesta etapa ens trobem amb el nostre primer problema greu. El servei havia de referir-se a un conjunt de dominis, volíem que la lògica fos independent i el principi DRY ens va obstaculitzar molt aquí. Els desenvolupadors volien reutilitzar les classes de les assemblees veïnes per evitar la duplicació i, com a resultat, els dominis van començar a enllaçar-se de nou. Vam analitzar els resultats i vam decidir que potser el problema també rau en l'àrea del dispositiu d'emmagatzematge del codi font. Teníem un gran repositori que contenia tot el codi font. La solució per a tot el projecte va ser molt difícil de muntar en una màquina local. Per tant, es van crear petites solucions separades per a parts del projecte, i ningú va prohibir afegir-hi algun conjunt comú o de domini i reutilitzar-los. L'única eina que no ens permetia fer-ho era la revisió del codi. Però de vegades també va fracassar.
Després vam començar a passar a un model amb repositoris separats. La lògica empresarial ja no flueix de servei a servei, els dominis s'han tornat realment independents. Els contextos delimitats es donen suport més clarament. Com reutilitzem les biblioteques d'infraestructura? Els vam separar en un dipòsit separat i després els vam posar en paquets Nuget, que vam posar a Artifactory. Amb qualsevol canvi, el muntatge i la publicació es produeixen automàticament.
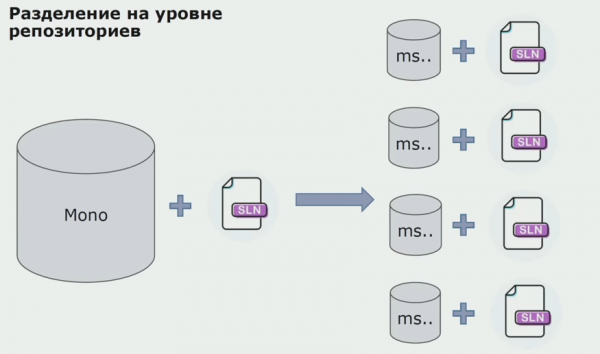
Els nostres serveis van començar a fer referència als paquets d'infraestructura interna de la mateixa manera que els externs. Descarreguem biblioteques externes de Nuget. Per treballar amb Artifactory, on vam col·locar aquests paquets, vam utilitzar dos gestors de paquets. En repositoris petits també hem utilitzat Nuget. En repositoris amb múltiples serveis, hem utilitzat Paket, que proporciona més coherència de versió entre mòduls.
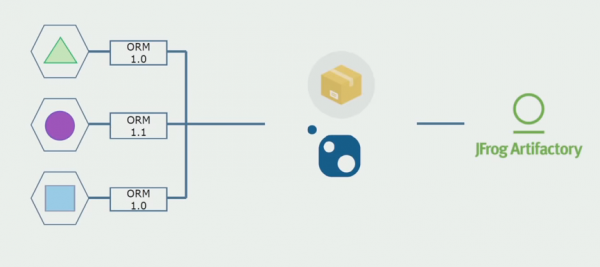
Així, treballant el codi font, canviant lleugerament l'arquitectura i separant els repositoris, fem que els nostres serveis siguin més independents.
Problemes d'infraestructura
La majoria dels inconvenients de passar als microserveis estan relacionats amb la infraestructura. Necessitareu un desplegament automatitzat, necessitareu biblioteques noves per executar la infraestructura.
Instal·lació manual en ambients
Inicialment, vam instal·lar manualment la solució per a entorns. Per automatitzar aquest procés, hem creat un pipeline CI/CD. Hem escollit el procés de lliurament continu perquè el desplegament continu encara no és acceptable per a nosaltres des del punt de vista dels processos empresarials. Per tant, l'enviament per a l'operació es realitza mitjançant un botó i, per a la prova, automàticament.
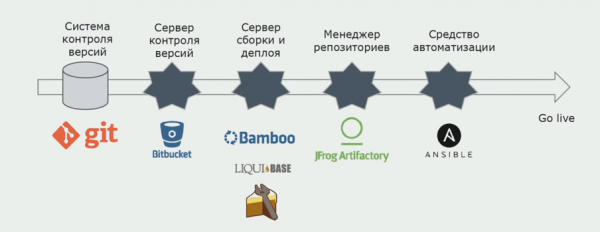
Utilitzem Atlassian, Bitbucket per a l'emmagatzematge del codi font i Bamboo per a la construcció. Ens agrada escriure scripts de compilació a Cake perquè és el mateix que C#. Els paquets preparats arriben a Artifactory i Ansible arriba automàticament als servidors de prova, després dels quals es poden provar immediatament.
Registre separat
En un moment, una de les idees del monòlit era proporcionar un registre compartit. També havíem d'entendre què fer amb els registres individuals que hi ha als discs. Els nostres registres s'escriuen en fitxers de text. Vam decidir utilitzar una pila ELK estàndard. No vam escriure a ELK directament a través dels proveïdors, però vam decidir modificar els registres de text i escriure-hi l'identificador de traça com a identificador, afegint el nom del servei, de manera que aquests registres es poguessin analitzar més tard.
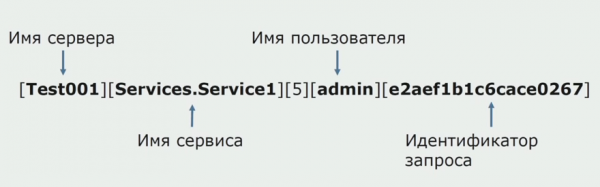
Amb Filebeat podem recopilar els nostres registres de servidors, després transformar-los, utilitzar Kibana per crear consultes a la interfície d'usuari i veure com s'ha encaminat la trucada entre serveis. Els ID de traça són molt útils per a això.
Serveis relacionats amb proves i depuració
Inicialment, no enteníem del tot com depurar els serveis que s'estaven desenvolupant. Tot era senzill amb el monòlit; el vam executar en una màquina local. Al principi van intentar fer el mateix amb els microserveis, però de vegades, per llançar completament un microservei, cal llançar-ne diversos, i això és inconvenient. Ens vam adonar que hem de passar a un model on deixem a la màquina local només el servei o serveis que volem depurar. La resta de serveis s'utilitzen des de servidors que coincideixen amb la configuració amb prod. Després de la depuració, durant la prova, per a cada tasca, només s'emeten al servidor de prova els serveis modificats. Així, la solució es prova en la forma en què apareixerà en producció en el futur.
Hi ha servidors que només executen versions de producció dels serveis. Aquests servidors són necessaris en cas d'incidències, per comprovar el lliurament abans del desplegament i per a la formació interna.
Hem afegit un procés de prova automatitzat mitjançant la popular biblioteca Specflow. Les proves s'executen automàticament mitjançant NUnit immediatament després del desplegament des d'Ansible. Si la cobertura de la tasca és totalment automàtica, no cal fer proves manuals. Tot i que de vegades encara es requereixen proves manuals addicionals. Utilitzem etiquetes a Jira per determinar quines proves s'executen per a un problema específic.
A més, ha augmentat la necessitat de proves de càrrega; anteriorment només es realitzava en casos excepcionals. Utilitzem JMeter per executar proves, InfluxDB per emmagatzemar-les i Grafana per crear gràfics de processos.
Què hem aconseguit?
En primer lloc, ens vam desfer del concepte de "alliberament". Enrere han quedat els llançaments monstruosos de dos mesos quan aquest colós es va desplegar en un entorn de producció, interrompent temporalment els processos empresarials. Ara despleguem serveis de mitjana cada 1,5 dies, agrupant-los perquè entren en funcionament després de l'aprovació.
No hi ha fallades fatals al nostre sistema. Si alliberem un microservei amb un error, la funcionalitat associada amb ell es trencarà i la resta de funcionalitats no es veuran afectades. Això millora molt l'experiència de l'usuari.
Podem controlar el patró de desplegament. Podeu seleccionar grups de serveis per separat de la resta de la solució, si cal.
A més, hem reduït notablement el problema amb una gran cua de millores. Ara tenim equips de producte separats que treballen amb alguns dels serveis de manera independent. El procés Scrum ja s'adapta bé aquí. Un equip específic pot tenir un propietari de producte independent que li assigni tasques.
Resum
- Els microserveis són molt adequats per a la descomposició de sistemes complexos. En el procés, comencem a entendre què hi ha al nostre sistema, quins contextos limitats hi ha, on es troben els seus límits. Això us permet distribuir correctament les millores entre mòduls i evitar confusions de codi.
- Els microserveis ofereixen avantatges organitzatius. Sovint se'n parla només com a arquitectura, però qualsevol arquitectura és necessària per resoldre les necessitats empresarials, i no per si sola. Per tant, podem dir que els microserveis són molt adequats per resoldre problemes en equips petits, atès que Scrum és molt popular ara.
- La separació és un procés iteratiu. No podeu agafar una aplicació i simplement dividir-la en microserveis. És poc probable que el producte resultant sigui funcional. A l'hora de dedicar microserveis, és beneficiós reescriure el llegat existent, és a dir, convertir-lo en codi que ens agradi i que s'adapti millor a les necessitats empresarials en termes de funcionalitat i rapidesa.
Una petita advertència: Els costos de passar als microserveis són força importants. Va trigar molt de temps a resoldre el problema de les infraestructures sol. Per tant, si teniu una aplicació petita que no requereix una escala específica, tret que tingueu un gran nombre de clients competint per l'atenció i el temps del vostre equip, és possible que els microserveis no siguin el que necessiteu avui. És bastant car. Si inicieu el procés amb microserveis, els costos inicialment seran més elevats que si inicieu el mateix projecte amb el desenvolupament d'un monòlit.
PS Una història més emotiva (i com per a tu personalment) - segons .
Aquí teniu la versió completa de l'informe.
Font: www.habr.com
