


Les xarxes neuronals en visió per computador s'estan desenvolupant activament, molts problemes encara estan lluny de resoldre's. Per estar a la moda en el vostre camp, només heu de seguir els influencers a Twitter i llegir articles rellevants a arXiv.org. Però vam tenir l'oportunitat d'anar a la International Conference on Computer Vision (ICCV) 2019. Aquest any se celebra a Corea del Sud. Ara volem compartir amb els lectors de Habr el que hem vist i après.
Allà érem molts de Yandex: van venir desenvolupadors de cotxes autònoms, investigadors i aquells que s'ocupen de tasques de CV als serveis. Però ara volem presentar un punt de vista una mica subjectiu del nostre equip: el Laboratori d'Intel·ligència Màquina (Yandex MILAB). Els altres nois probablement van mirar la conferència des del seu propi angle.
Què fa el laboratori?Realitzem projectes experimentals relacionats amb la generació d'imatges i música amb finalitats d'entreteniment. Ens interessen especialment les xarxes neuronals que permeten canviar el contingut de l'usuari (per a les fotos, aquesta tasca s'anomena manipulació d'imatges). el resultat del nostre treball de la conferència YaC 2019.
Hi ha moltes jornades científiques, però destaquen les més destacades, les anomenades jornades A*, on se solen publicar articles sobre les tecnologies més interessants i importants. No hi ha una llista exacta de conferències A*, aquí hi ha una llista aproximada i incompleta: NeurIPS (anteriorment NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Els tres últims estan especialitzats en el tema del currículum.
ICCV a simple vista: pòsters, tutorials, tallers, estands
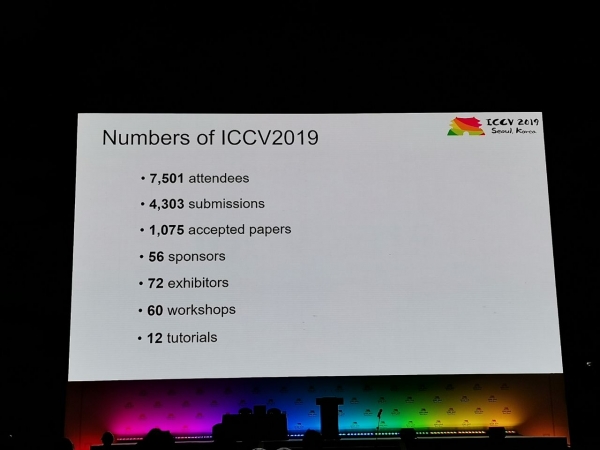
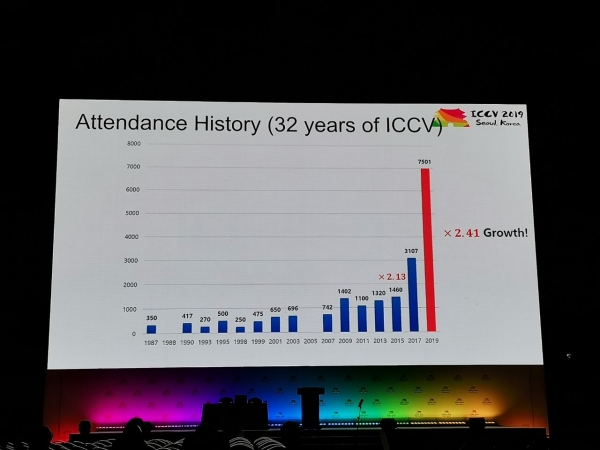
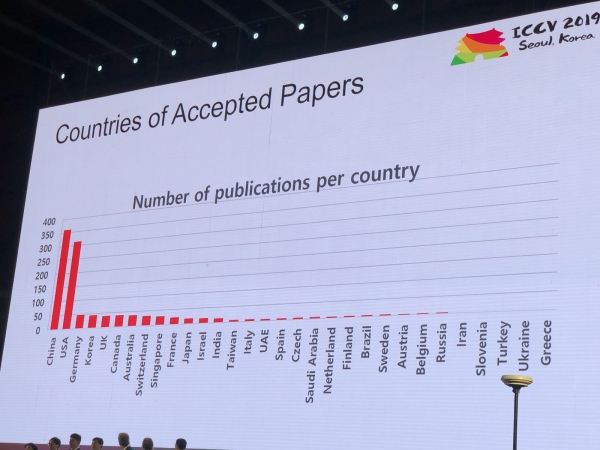
La conferència va rebre 1075 ponències, hi va haver 7500 participants, 103 persones van venir de Rússia, hi va haver articles d'empleats de Yandex, Skoltech, Samsung AI Center de Moscou i la Universitat de Samara. Aquest any, no molts investigadors de primer nivell han visitat l'ICCV, però, per exemple, Alexey (Alyosha) Efros, que sempre atrau molta gent:

estadística 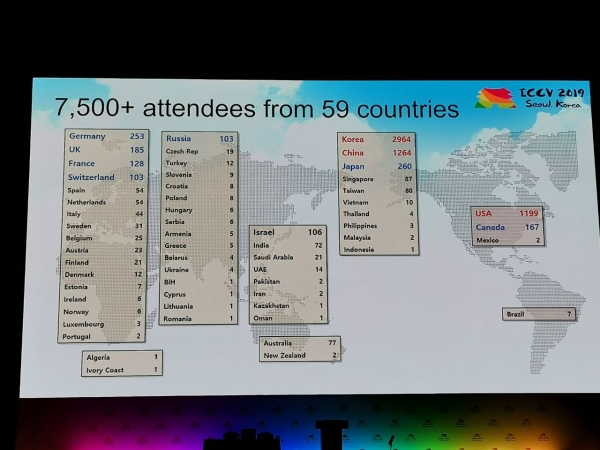

En totes aquestes conferències, els articles es presenten en forma de pòsters ( sobre el format), i els millors també es presenten en forma de breus informes.
Aquí teniu algunes de les obres de Rússia 


Amb les tutories pots submergir-te en una àrea temàtica concreta, recorda una conferència a una universitat. El llegeix una sola persona, normalment sense parlar d'obres concretes. Un exemple d'un tutorial fantàstic ():

Als tallers, al contrari, parlen d'articles. Normalment es tracta de treballs d'algun tema estret, històries de caps de laboratori sobre tots els últims treballs dels estudiants o articles que no van ser acceptats a la conferència principal.
Les empreses patrocinadores venen a l'ICCV amb estands. Aquest any han vingut Google, Facebook, Amazon i moltes altres empreses internacionals, així com un gran nombre de startups: coreanes i xineses. Hi havia especialment moltes startups especialitzades en l'etiquetatge de dades. Hi ha actuacions a les grades, pots agafar merch i fer preguntes. A efectes de caça, les empreses patrocinadores fan festes. Podeu entrar-hi si convenceu els reclutadors que esteu interessats i que potencialment podeu superar entrevistes. Si has publicat un article (o, a més, l'has presentat), començat o estàs acabant un doctorat, això és un avantatge, però de vegades pots negociar a l'estand fent preguntes interessants als enginyers de l'empresa.
Tendències
La conferència us permet fer una ullada a tot el camp del CV. Pel nombre de pòsters sobre un tema concret, podeu avaluar l'actualitat del tema. Algunes conclusions es suggereixen a partir de les paraules clau:

Zero-shot, one-shot, few-shot, autosupervisat i semi-supervisat: nous enfocaments a les tasques llargament estudiades
La gent està aprenent a utilitzar les dades de manera més eficaç. Per exemple, en és possible generar expressions facials d'animals que no estaven en el conjunt d'entrenament (en aplicació, proporcionant diverses imatges de referència). S'han desenvolupat les idees de Deep Image Prior i ara les xarxes GAN es poden entrenar en una sola imatge; en parlarem a continuació. . Podeu utilitzar l'autosupervisió per a l'entrenament previ (per resoldre un problema pel qual podeu sintetitzar dades alineades, com ara predir l'angle de rotació d'una imatge) o aprendre simultàniament a partir de dades etiquetades i no etiquetades. En aquest sentit, l'article es pot considerar la corona de la creació . I aquí teniu la formació prèvia a ImageNet ajuda.

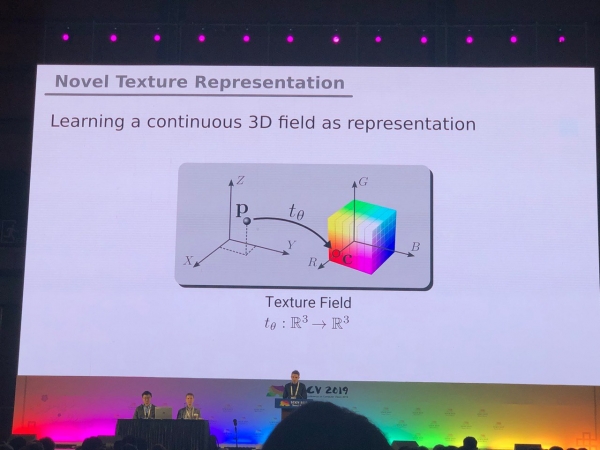
3D i 360°
Els problemes que es van resoldre majoritàriament per a fotos (segmentació, detecció) requereixen investigacions addicionals per a models 3D i vídeos panoràmics. Hem vist molts articles sobre com convertir RGB i RGB-D a 3D. Alguns problemes, com l'estimació de la postura humana, es poden resoldre de manera més natural passant a models 3D. Però encara no hi ha consens sobre com representar exactament els models XNUMXD, en forma de malla, núvol de punts, voxels o SDF. Aquí hi ha una altra opció:
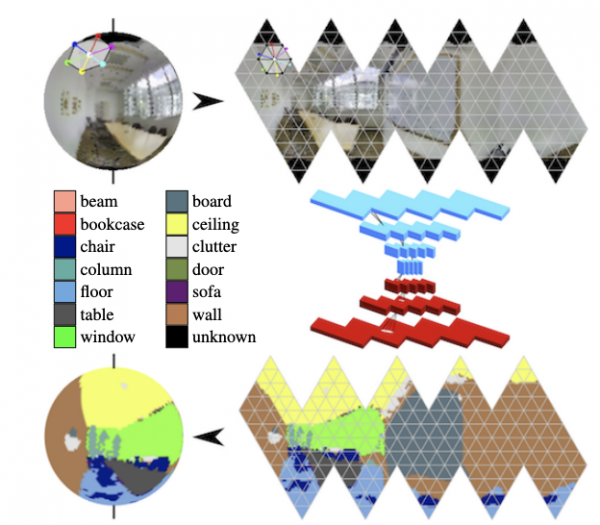
A les panoràmiques, les circumvolucions de l'esfera es desenvolupen activament (vegeu. ) i cerqueu objectes clau al marc.
Detecció de posicions i predicció del moviment humà
Ja hi ha hagut avenços en la detecció de poses en 2D; ara l'enfocament s'ha desplaçat cap a treballar amb diverses càmeres i en 3D. També és possible, per exemple, detectar un esquelet a través d'una paret mitjançant el seguiment dels canvis en el senyal Wi-Fi a mesura que passa pel cos humà.
S'ha treballat molt en el camp de la detecció de punts clau de mà. Han aparegut nous conjunts de dades, inclosos els basats en vídeos de diàlegs entre dues persones; ara podeu predir els gestos de les mans a partir de l'àudio o el text d'una conversa! El mateix progrés s'ha fet en les tasques de seguiment ocular (estimació de la mirada).

També es pot identificar un gran cúmul de treballs relacionats amb la predicció del moviment humà (per exemple, o ). La tasca és important i, a partir de converses amb els autors, s'utilitza més sovint per analitzar el comportament dels vianants en la conducció autònoma.
Manipulacions amb persones en fotos i vídeos, cames virtuals
La tendència principal és canviar les imatges facials segons paràmetres interpretables. Idees: deepfake basat en una imatge, canvi d'expressió basat en la representació facial (), feedforward: canvieu els paràmetres (per exemple, ). Les transferències d'estil han passat del títol del tema a l'aplicació de l'obra. Els provadors virtuals són una història diferent, gairebé sempre funcionen malament; demostracions.


Generació a partir d'esbossos/gràfics
El desenvolupament de la idea “Deixem que la graella generi quelcom a partir de l'experiència prèvia” es va convertir en una altra: “Mostrem a la graella quina opció ens interessa”.
permet fer inpaint guiat: l'usuari pot acabar de pintar part de la cara a la zona esborrada de la imatge i obtenir una imatge restaurada en funció de la finalització.
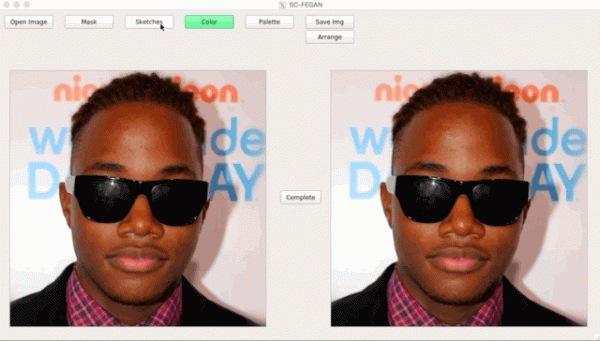
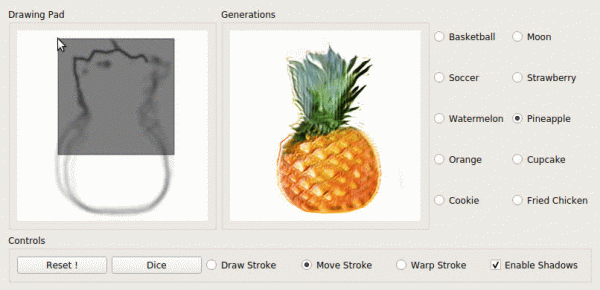
Un dels 25 articles d'Adobe per a ICCV combina dos GAN: un completa l'esbós per a l'usuari, l'altre genera una imatge fotorealista a partir de l'esbós ().
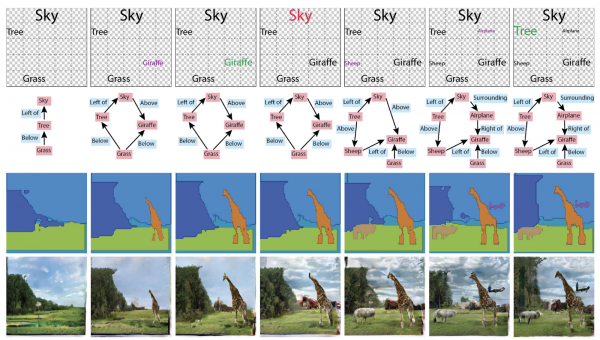
Abans, els gràfics no eren necessaris en la generació d'imatges, però ara s'han fet un contenidor de coneixement sobre l'escena. L'article també ha guanyat el premi a la millor menció d'honor del treball basat en els resultats de l'ICCV . En general, podeu utilitzar-los de diferents maneres: generar gràfics a partir d'imatges, o imatges i textos a partir de gràfics.
Reidentificació de persones i cotxes, comptant la mida de la multitud (!)
Molts articles es dediquen a rastrejar persones i reidentificar persones i màquines. Però el que ens va sorprendre va ser un munt d'articles sobre recompte de multituds, tots de la Xina.
pòsters 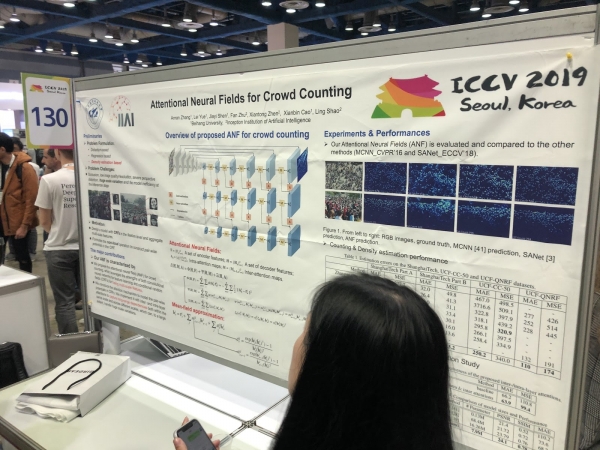
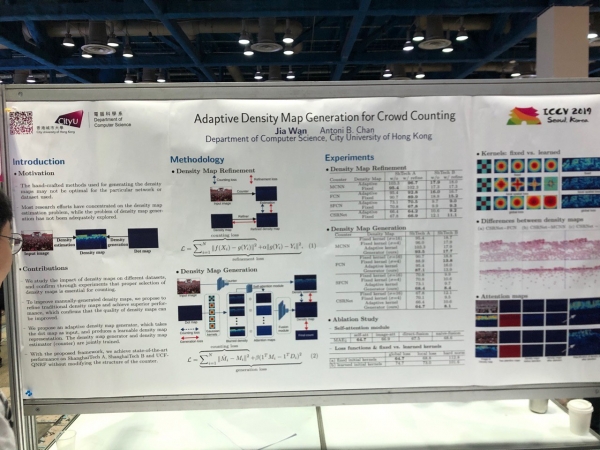
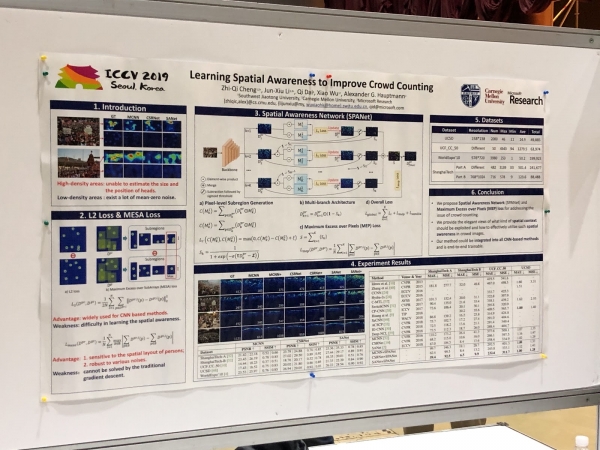


Però Facebook, per contra, anonimitza la foto. I ho fa d'una manera interessant: entrena la xarxa neuronal per generar una cara sense detalls únics, semblant, però no tan semblant que es pugui identificar correctament mitjançant sistemes de reconeixement facial.

Protecció contra atacs adversaris
Amb el desenvolupament d'aplicacions de visió per ordinador al món real (en cotxes autònoms, en reconeixement facial), es planteja cada cop més la qüestió de la fiabilitat d'aquests sistemes. Per utilitzar plenament CV, heu d'assegurar-vos que el sistema és resistent als atacs adversaris, per això no hi havia menys articles sobre protecció contra ells que sobre els atacs en si. S'ha treballat molt per explicar les prediccions de la xarxa (mapa de rellevància) i mesurar la confiança en el resultat.
Tasques combinades
En la majoria de tasques amb un objectiu, les possibilitats de millorar la qualitat estan pràcticament esgotades, una de les noves direccions per augmentar encara més la qualitat és ensenyar a les xarxes neuronals a resoldre simultàniament diversos problemes. Exemples:
— predicció d'acció + predicció de flux òptic,
— presentació de vídeo + presentació en llengua (),
- .
També hi ha articles sobre segmentació, determinació de poses i reidentificació d'animals!

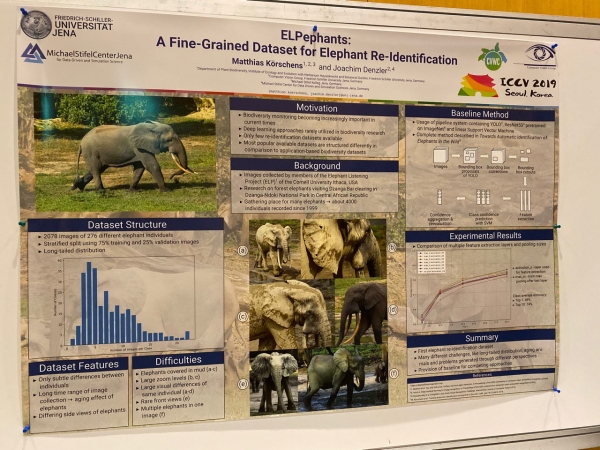
Destacats
Gairebé tots els articles es coneixien amb antelació, el text estava disponible a arXiv.org. Per tant, la presentació d'obres com Everybody Dance Now, FUNIT, Image2StyleGAN sembla força estranya: són obres molt útils, però no noves. Sembla que el procés clàssic de les publicacions científiques s'està trencant aquí: la ciència s'està movent massa ràpid.
És molt difícil determinar les millors obres: n'hi ha moltes, els temes són diferents. S'han rebut diversos articles .
Volem destacar treballs interessants des del punt de vista de la manipulació d'imatges, ja que aquest és el nostre tema. Ens van resultar força frescos i interessants (no pretenem ser objectius).
SinGAN (premi al millor paper) i InGAN
SinGAN: , , .
InGAN: , , .
Desenvolupament de la idea de Deep Image Prior de Dmitry Ulyanov, Andrea Vedaldi i Victor Lempitsky. En lloc d'entrenar un GAN en un conjunt de dades, les xarxes aprenen de fragments de la mateixa imatge per recordar les estadístiques que hi ha dins. La xarxa entrenada permet editar i animar fotos (SinGAN) o generar noves imatges de qualsevol mida a partir de les textures de la imatge original, conservant l'estructura local (InGAN).
SinGAN:

InGAN:

Veure el que un GAN no pot generar
.
Les xarxes neuronals que generen imatges solen prendre un vector de soroll aleatori com a entrada. En una xarxa entrenada, molts vectors d'entrada formen un espai, petits moviments al llarg dels quals condueixen a petits canvis en la imatge. Amb l'optimització, podeu resoldre el problema invers: trobar un vector d'entrada adequat per a una imatge del món real. L'autor mostra que gairebé mai és possible trobar una imatge que coincideixi completament en una xarxa neuronal. Alguns objectes de la imatge no es generen (aparentment a causa de la gran variabilitat d'aquests objectes).
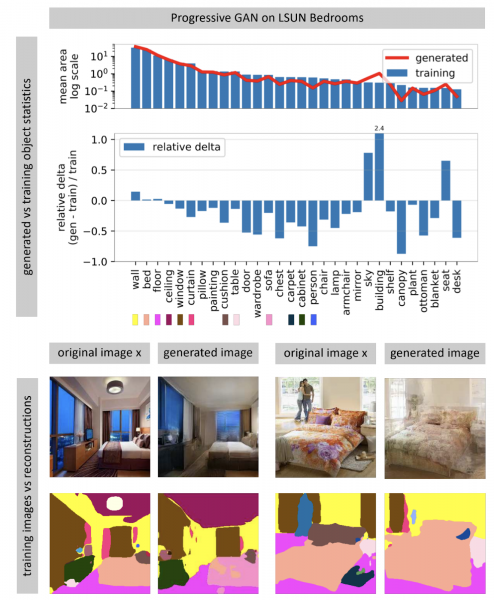
L'autor planteja la hipòtesi que GAN no cobreix tot l'espai d'imatges, sinó només algun subconjunt, farcit de forats, com el formatge. Quan intentem trobar-hi fotos del món real, sempre fallarem, perquè GAN encara genera fotos no del tot reals. Les diferències entre imatges reals i generades només es poden superar canviant els pesos de la xarxa, és a dir, reentrenant-la per a una foto específica.

Quan la xarxa està entrenada addicionalment per a una foto específica, podeu provar diverses manipulacions amb aquesta imatge. A l'exemple següent, es va afegir una finestra a la foto i la xarxa també va generar reflexos a la unitat de cuina. Això vol dir que la xarxa, fins i tot després d'una formació addicional per a la fotografia, no va perdre la capacitat de veure la connexió entre els objectes de l'escena.

GANalyze: cap a les definicions visuals de les propietats cognitives de la imatge
, .
Amb l'enfocament d'aquest treball, podeu visualitzar i analitzar què ha après la xarxa neuronal. Els autors proposen entrenar GAN per crear imatges per a les quals la xarxa generarà prediccions especificades. L'article va utilitzar diverses xarxes com a exemples, inclosa MemNet, que prediu la memorabilitat de les fotos. Va resultar que per a una millor memorabilitat, l'objecte de la foto hauria de:
- estar més a prop del centre
- tenen una forma més rodona o quadrada i una estructura senzilla,
- estar sobre un fons uniforme,
- continguin ulls expressius (almenys per a fotos de gossos),
- ser més brillant, més saturat, en alguns casos, més vermell.

Liquid Warping GAN: un marc unificat per a la imitació del moviment humà, la transferència d'aparença i la síntesi de noves vistes
, , .
Pipeline per generar fotos de persones una foto a la vegada. Els autors mostren exemples reeixits de transferir el moviment d'una persona a una altra, transferir roba entre persones i generar nous angles d'una persona, tot a partir d'una fotografia. A diferència de treballs anteriors, aquí no fem servir punts clau en 2D (posa), sinó una malla 3D del cos (posa + forma) per crear condicions. Els autors també van descobrir com transferir informació de la imatge original a la generada (Liquid Warping Block). Els resultats semblen decents, però la resolució de la imatge resultant és només de 256 x 256. En comparació, vid2vid, que va aparèixer fa un any, és capaç de generar una resolució de 2048x1024, però requereix fins a 10 minuts de gravació de vídeo com a conjunt de dades.

FSGAN: Subject Agnostic Face Swapping and Reenactment
, .
Al principi sembla que no hi ha res d'estrany: un deepfake amb una qualitat més o menys normal. Però el principal èxit de l'obra és la substitució de cares d'una imatge. A diferència de treballs anteriors, es requeria formació en moltes fotografies d'una persona concreta. El pipeline va resultar feixuc (recreació i segmentació, interpolació de vistes, inpainting, barreja) i amb molts hacks tècnics, però el resultat val la pena.

Detecció de l'inesperat mitjançant la resíntesi d'imatges
.
Com pot un dron entendre que de cop ha aparegut davant seu un objecte que no entra en cap classe de segmentació semàntica? Hi ha diversos mètodes, però els autors proposen un algorisme nou i intuïtiu que funciona millor que els seus predecessors. La segmentació semàntica es prediu a partir de la imatge de la carretera d'entrada. S'alimenta com a entrada al GAN (pix2pixHD), que intenta restaurar la imatge original només des del mapa semàntic. Les anomalies que no cauen en cap dels segments diferiran significativament en la sortida i la imatge generada. Les tres imatges (original, segmentació i reconstruïda) s'alimenten a una altra xarxa que prediu anomalies. El conjunt de dades per a això es va generar a partir del conegut conjunt de dades Cityscapes, canviant aleatòriament les classes de la segmentació semàntica. Curiosament, en aquest entorn, un gos parat al mig de la carretera, però segmentat correctament (la qual cosa significa que hi ha una classe) no és una anomalia, ja que el sistema va ser capaç de reconèixer-lo.
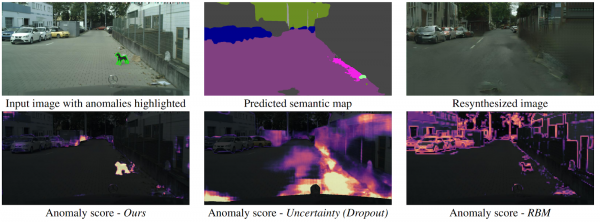
Conclusió
Abans de la conferència, és important saber quins són els teus interessos científics, a quines presentacions t'agradaria assistir i amb qui parlar. Aleshores tot serà molt més productiu.
ICCV és, en primer lloc, treball en xarxa. Entens que hi ha instituts de primer nivell i departaments científics de primer nivell, comences a entendre això, coneixes gent. I podeu llegir articles sobre arXiv i, per cert, és genial que no hàgiu d'anar enlloc per obtenir coneixements.
A més, a la conferència podreu aprofundir en temes que no us són propers i veure tendències. Bé, escriviu una llista d'articles per llegir. Si ets estudiant, aquesta és una oportunitat per conèixer un professor potencial, si ets del sector, després amb un nou empresari, i si és una empresa, per mostrar-te.
Subscriu-te a ! Aquest és un projecte personal: el liderem junts . Hem penjat aquí tots els treballs que ens han agradat durant la conferència: .
Font: www.habr.com
