

Představte si: obsluhujete IT infrastrukturu velkého nákupního centra. Ve městě začíná pršet. Proudy deště prorážejí střechu, voda naplňuje obchodní prostory po kotníky. Doufáme, že vaše serverovna není v suterénu, jinak se problémům nelze vyhnout.
Popisovaný příběh není fantasy, ale souhrnný popis několika událostí roku 2020. Ve velkých společnostech je pro tento případ vždy po ruce plán obnovy po havárii nebo plán obnovy po havárii (DRP). V korporacích za to odpovídají specialisté na kontinuitu podnikání. Ve středních a malých firmách ale řešení takových problémů spadá na IT služby. Musíte sami pochopit obchodní logiku, pochopit, co může selhat a kde, vymyslet ochranu a implementovat ji.
Je skvělé, když IT specialista může jednat s firmou a diskutovat o potřebě ochrany. Ale nejednou jsem viděl, jak společnost šetřila řešením pro obnovu po havárii (DR), protože je považovala za nadbytečné. Když došlo k nehodě, dlouhé zotavování hrozilo ztrátami a podnik nebyl připraven. Můžete opakovat, jak chcete: „Říkal jsem vám to“, ale služba IT bude muset služby obnovit.

Z pozice architekta vám řeknu, jak se této situaci vyhnout. V první části článku ukážu přípravné práce: jak se zákazníkem probrat tři otázky pro výběr bezpečnostních nástrojů:
- Co chráníme?
- Před čím se chráníme?
- Jak moc chráníme?
V druhé části si povíme o možnostech, jak odpovědět na otázku: jak se bránit. Uvedu příklady případů, jak si různí zákazníci budují ochranu.
Co chráníme: identifikace kritických obchodních funkcí
Je lepší začít s přípravou diskusí o akčním plánu po mimořádné události s firemním zákazníkem. Hlavním problémem je zde najít společný jazyk. Zákazníka většinou nezajímá, jak IT řešení funguje. Zajímá ho, zda služba může plnit obchodní funkce a přinášet peníze. Například: pokud stránka funguje, ale platební systém nefunguje, nejsou žádné příjmy od klientů a „extrémisté“ jsou stále IT specialisté.
IT profesionál může mít s takovým jednáním potíže z několika důvodů:
- IT služba plně nerozumí roli informačního systému v podnikání. Pokud například není k dispozici popis obchodních procesů nebo transparentní obchodní model.
- Ne celý proces závisí na IT službě. Například když část práce provádějí dodavatelé a IT specialisté na ně nemají přímý vliv.
Konverzaci bych strukturoval takto:
- Vysvětlujeme firmám, že nehody se stávají každému a zotavení vyžaduje čas. Nejlepší je předvést situace, jak se to děje a jaké jsou možné důsledky.
- Ukazujeme, že ne vše závisí na IT službě, ale jste připraveni pomoci s akčním plánem ve vaší oblasti odpovědnosti.
- Žádáme obchodního zákazníka, aby odpověděl: pokud dojde k apokalypse, který proces by měl být obnoven jako první? Kdo a jak se na něm podílí?
Od firmy je například vyžadována jednoduchá odpověď: call centrum musí pokračovat v registraci žádostí 24/7.
- Žádáme jednoho nebo dva uživatele systému, aby tento proces podrobně popsali.
Je lepší zapojit analytika, aby vám pomohl, pokud ho vaše společnost má.Pro začátek může popis vypadat takto: call centrum přijímá požadavky telefonicky, poštou a prostřednictvím zpráv z webu. Pak je přes webové rozhraní zadá do 1C a odtud je takto vezme výroba.
- Poté se podíváme na to, jaká hardwarová a softwarová řešení tento proces podporují. Pro komplexní ochranu bereme v úvahu tři úrovně:
- aplikace a systémy v rámci webu (softwarová úroveň),
- samotné místo, kde systémy běží (úroveň infrastruktury),
- sítě (často na to zapomínají).
- Identifikujeme potenciální body selhání: systémové uzly, na kterých závisí provoz služby. Identifikujeme také uzly podporované jinými společnostmi, jako jsou telekomunikační operátoři, poskytovatelé hostingu, datová centra atd. S ohledem na to se můžete vrátit k firemnímu zákazníkovi pro další krok.
Před čím se chráníme: před riziky
Dále od firemního zákazníka zjišťujeme, před jakými riziky se chráníme jako první. Všechna rizika lze rozdělit do dvou skupin:
- ztráta času v důsledku výpadku služby;
- ztráta dat v důsledku fyzických vlivů, lidského faktoru atd.
Firmy se bojí ztráty dat i času – to vše vede ke ztrátě peněz. Znovu tedy položíme otázky pro každou rizikovou skupinu:
- Dokážeme u tohoto procesu odhadnout, kolik stojí ztráta dat a ztráta času v penězích?
- Jaká data nesmíme ztratit?
- Kde nemůžeme dovolit prostoje?
- Jaké události jsou pro nás nejpravděpodobnější a nejvíce ohrožující?
Po diskusi pochopíme, jak upřednostňovat body selhání.
Jak moc chráníme: RPO a RTO
Když jsou jasné kritické body selhání, vypočítáme ukazatele RTO a RPO.
Připomínám vám to RTO (cíl doby zotavení) — toto je přípustná doba od okamžiku nehody do úplného obnovení provozu. V obchodní řeči je to přijatelné prostoje. Pokud víme, kolik peněz proces přinesl, můžeme vypočítat ztráty z každé minuty výpadku a vypočítat přijatelnou ztrátu.
RPO (cíl bodu obnovy) — platný bod obnovy dat. Určuje dobu, po kterou můžeme data ztratit. Z obchodního hlediska může ztráta dat vést například k pokutám. Takové ztráty lze také převést na peníze.
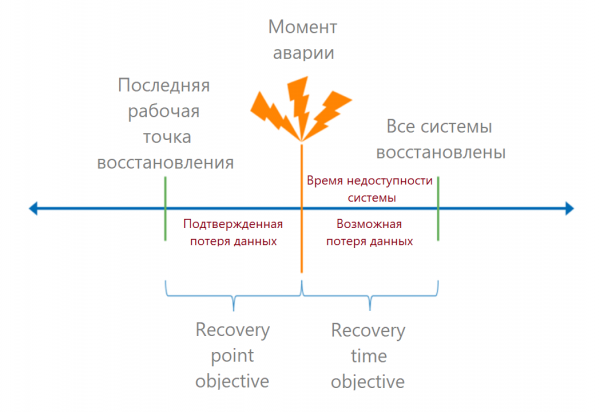
Pro koncového uživatele je třeba vypočítat dobu obnovy: jak dlouho se bude moci přihlásit do systému. Nejprve tedy sečteme dobu zotavení všech článků v řetězu. Často se zde dělá chyba: vezmou RTO poskytovatele ze smlouvy SLA a zapomenou na zbývající podmínky.
Podívejme se na konkrétní příklad. Uživatel se přihlásí do 1C, systém se otevře s chybou databáze. Kontaktuje správce systému. Databáze je umístěna v cloudu, správce systému nahlásí problém poskytovateli služby. Řekněme, že veškerá komunikace trvá 15 minut. V cloudu bude databáze této velikosti obnovena ze zálohy za hodinu, proto je RTO na straně poskytovatele služby hodinu. Toto však není konečný termín, pro uživatele je k němu přidáno 15 minut na odhalení problému.
Dále musí správce systému zkontrolovat, zda je databáze správná, připojit ji k 1C a spustit služby. To vyžaduje další hodinu, což znamená, že RTO na straně správce je již 2 hodiny a 15 minut. Uživatel potřebuje dalších 15 minut: přihlaste se, zkontrolujte, zda se objevily potřebné transakce. V tomto příkladu je celková doba obnovení služby 2 hodiny 30 minut.
Tyto výpočty ukážou podniku, na jakých vnějších faktorech závisí období zotavení. Pokud je například kancelář zaplavena, musíte nejprve najít únik a opravit jej. Zabere to čas, který nezávisí na IT.
Jak chráníme: výběr nástrojů pro různá rizika
Po projednání všech bodů již zákazník rozumí nákladům podniku na nehodu. Nyní si můžete vybrat nástroje a diskutovat o rozpočtu. Na příkladech klientských případů vám ukážu, jaké nástroje nabízíme pro různé úkoly.
Začněme první skupinou rizik: ztráty v důsledku prostojů služeb. Řešení tohoto problému by měla poskytovat dobré RTO.
- Hostování aplikace v cloudu
Pro začátek se můžete jednoduše přesunout do cloudu – poskytovatel již promyslel otázky vysoké dostupnosti. Hostitelé virtualizace jsou sestaveni do clusteru, napájení a síť jsou rezervovány, data jsou uložena na úložných systémech odolných proti chybám a poskytovatel služeb je finančně odpovědný za prostoje.
Můžete například hostovat virtuální počítač s databází v cloudu. Aplikace se připojí k databázi externě prostřednictvím zavedeného kanálu nebo ze stejného cloudu. Pokud nastanou problémy s jedním ze serverů v clusteru, virtuální počítač se restartuje na sousedním serveru za méně než 2 minuty. Poté se v něm spustí DBMS a za pár minut bude databáze dostupná.
RTO: měřeno v minutách. Tyto podmínky mohou být specifikovány ve smlouvě s poskytovatelem.
Stát: Vypočítáme náklady na cloudové zdroje pro vaši aplikaci.
Před čím vás neochrání: z masivních poruch na místě poskytovatele, například v důsledku nehod na úrovni města. - Cluster aplikace
Pokud chcete zlepšit RTO, můžete posílit předchozí možnost a rovnou umístit clusterovanou aplikaci do cloudu.
Cluster můžete implementovat v režimu aktivní-pasivní nebo aktivní-aktivní. Vytváříme několik VM na základě požadavků dodavatele. Pro větší spolehlivost je distribuujeme na různé servery a úložné systémy. Pokud selže server s jednou z databází, zálohovací uzel převezme zatížení během několika sekund.
RTO: Měřeno v sekundách.
Stát: o něco dražší než běžný cloud, pro clustering budou vyžadovány další zdroje.
Před čím vás neochrání: Stále neochrání před masivními selháními na místě. Místní narušení ale nebude trvat tak dlouho.Z praxe: Maloobchodní společnost měla několik informačních systémů a webových stránek. Všechny databáze byly umístěny lokálně v kanceláři společnosti. O žádném DR se neuvažovalo, dokud úřad nezůstal několikrát za sebou bez proudu. Zákazníci byli nespokojeni s pády webových stránek.
Problém s dostupností služby byl vyřešen po přesunu do cloudu. Navíc se nám podařilo optimalizovat zatížení databází vyvážením provozu mezi uzly. - Přesuňte se do cloudu odolného proti katastrofě
Pokud potřebujete zajistit, aby ani živelná pohroma na hlavním webu nenarušila vaši práci, můžete zvolit cloud odolný proti katastrofám.V této možnosti poskytovatel rozloží virtualizační cluster mezi 2 datová centra. Konstantní synchronní replikace probíhá mezi datovými centry, jedna ku jedné. Kanály mezi datovými centry jsou vyhrazené a jdou po různých trasách, takže se takový cluster nebojí problémů se sítí.
RTO: má tendenci k 0.
Stát: Nejdražší cloudová varianta.
Před čím vás neochrání: Proti poškození dat nepomůže, stejně jako z lidského faktoru, proto se doporučuje dělat zálohy současně.Z praxe: Jeden z našich klientů vyvinul komplexní plán obnovy po havárii. Tuto strategii zvolil:
- Cloud odolný vůči katastrofám chrání aplikaci před selháním na úrovni infrastruktury.
- Dvouúrovňová záloha poskytuje ochranu v případě lidské chyby. Existují dva typy záloh: „studené“ a „horké“. „Studená“ záloha je ve vypnutém stavu a její nasazení nějakou dobu trvá. „Hot“ záloha je již připravena k použití a obnovuje se rychleji. Je uložen na speciálně vyhrazeném úložném systému. Třetí kopie je nahrána na pásku a uložena v jiné místnosti.
Jednou týdně klient testuje ochranu a kontroluje funkčnost všech záloh, včetně těch z pásky. Společnost každý rok testuje celý cloud odolný proti katastrofám.
- Uspořádejte replikaci na jiný web
Další možnost, jak se vyhnout globálním problémům na hlavním webu: poskytnout georezervaci. Jinými slovy, vytvořte záložní virtuální stroje na místě v jiném městě. K tomu jsou vhodná speciální řešení pro DR: v naší společnosti používáme VMware vCloud Availability (vCAV). S jeho pomocí můžete nakonfigurovat ochranu mezi několika weby poskytovatelů cloudu nebo obnovit do cloudu z místního webu. O schématu práce s vCAV jsem již mluvil podrobněji .
RPO a RTO: od 5 minut.
Stát: dražší než první možnost, ale levnější než replikace hardwaru v cloudu odolném proti katastrofě. Cena se skládá z nákladů na licenci vCAV, administrativních poplatků, nákladů na cloudové zdroje a rezervní zdroje dle PAYG modelu (10 % nákladů na pracovní zdroje pro vypnuté VM).
Z praxe: Klient měl v našem cloudu v Moskvě 6 virtuálních strojů s různými databázemi. Nejprve byla ochrana zajišťována zálohováním: některé záložní kopie byly uloženy v cloudu v Moskvě a některé na našem webu v Petrohradě. Postupem času se databáze zvětšovaly a obnova ze zálohy začala zabírat více času.
Do záloh byla přidána replikace založená na VMware vCloud Availability. Repliky virtuálních strojů jsou uloženy na záložním místě v Petrohradě a jsou aktualizovány každých 5 minut. Pokud dojde k poruše na hlavním pracovišti, zaměstnanci nezávisle přejdou na repliku virtuálního stroje v Petrohradu a pokračují v práci s ním.
Všechna zvažovaná řešení poskytují vysokou dostupnost, ale nechrání před ztrátou dat v důsledku ransomwarového viru nebo náhodné chyby zaměstnance. V tomto případě budeme potřebovat zálohy, které zajistí požadované RPO.
5. Nezapomeňte na zálohování
Každý ví, že musíte zálohovat, i když máte to nejlepší řešení odolné proti katastrofě. Proto vám jen krátce připomenu několik bodů.
Přísně vzato, záloha není DR. A proto:
- Je to dlouhá doba. Pokud jsou data měřena v terabajtech, bude obnova trvat déle než jednu hodinu. Potřebujete obnovit, přiřadit síť, zkontrolovat, zda se zapíná, zda jsou data v pořádku. Takže můžete poskytnout dobrý RTO pouze v případě, že je málo dat.
- Data nemusí být obnovena napoprvé a je třeba nechat čas na opakování akce. Jsou například chvíle, kdy přesně nevíme, kdy byla data ztracena. Řekněme, že ztráta byla zaznamenána v 15.00:15.00 a kopie se vytvářejí každou hodinu. Od 14:00 se podíváme na všechny body zotavení: 13:00, XNUMX:XNUMX a tak dále. Pokud je systém důležitý, snažíme se minimalizovat stáří bodu obnovy. Pokud však čerstvá záloha neobsahovala potřebná data, vezmeme další bod - to je další čas.
V tomto případě může plán zálohování poskytnout požadované RPO. Pro zálohy je důležité zajistit geografickou rezervaci pro případ problémů s hlavním webem. Některé záložní kopie se doporučuje ukládat samostatně.
Konečný plán obnovy po havárii by měl obsahovat alespoň 2 nástroje:
- Jedna z možností 1-4, která ochrání systémy před poruchami a pády.
- Zálohování pro ochranu dat před ztrátou.
Vyplatí se také postarat se o záložní komunikační kanál pro případ výpadku hlavního poskytovatele internetu. A - voila! — DR za minimální mzdy je již připraveno.
Zdroj: www.habr.com
