

Ahoj všichni. Níže je dešifrování .
– systém pro monitorování různých systémů a služeb, s jehož pomocí mohou správci systému shromažďovat informace o aktuálních parametrech systémů a nastavovat upozornění pro příjem upozornění na odchylky v provozu systémů.
Zpráva bude porovnávat и — projekty pro dlouhodobé ukládání metrik Prometheus.



Nejprve vám povím o Prometheovi. Jedná se o monitorovací systém, který shromažďuje metriky z daných cílů a ukládá je do místního úložiště. Prometheus umí zapisovat metriky do vzdáleného úložiště, může generovat upozornění a pravidla nahrávání.

Omezení Prometheus:
- Nemá zobrazení globálního dotazu. To je, když máte více nezávislých instancí prometheus. Sbírají metriky. A chcete se dotazovat na všechny tyto metriky shromážděné z různých instancí prometheus. Prometheus to nedovoluje.
- S prometheus je výkon omezen pouze na jeden server. Prometheus nemůže automaticky škálovat na více serverů. Své cíle můžete rozdělit pouze ručně mezi více Prometheů.
- Rozsah metrik v Prometheus je omezen pouze na jeden server ze stejného důvodu, že se nemůže automaticky automaticky škálovat na více serverů.
- V Prometheus není tak snadné zorganizovat bezpečnost dat.

Řešení těchto problémů/úkolů?
Řešení jsou:
Všechna tato řešení jsou určena pro vzdálené ukládání dat shromážděných společností Prometheus. Problém vzdáleného úložiště z předchozího snímku řeší různými způsoby. V této prezentaci budu hovořit pouze o prvních dvou řešeních: и .
Poprvé informace o se objevil na . Je popsána architektura a jak to funguje.

Thanos vezme data, která Prometheus uložil na místní disk a zkopíruje je do S3, nebo do jiného úložiště objektů.

Thanos tedy poskytuje globální pohled na dotazy. Data uložená v úložišti objektů můžete dotazovat z více instancí Prometheus.

Thanos podporuje PromQL a .

Thanos používá k ukládání dat kód Prometheus.

Thanos je vyvíjen stejnými vývojáři jako Prometheus.
O . Zde kde jsme poprvé mluvili .
VictoriaMetrics přijímá data od několika prometheus protokol podporovaný společností Prometheus.
VictoriaMetrics poskytuje globální zobrazení dotazů, protože více instancí Prometheus může zapisovat data do jednoho VictoriaMetrics. V souladu s tím můžete klást dotazy na všechna tato data.

VictoriaMetrics také podporuje, jako Thanos, PromQL a Prometheus dotazovací API.

Na rozdíl od Thanos je zdrojový kód VictoriaMetrics napsán od začátku a je optimalizován pro rychlost a spotřebu zdrojů.

VictoriaMetrics, na rozdíl od Thanos, měřítko jak vertikálně, tak horizontálně. Jíst , která se vertikálně mění. Můžete začít s jedním procesorem a 1 GB paměti a rozšířit se až na stovky procesorů a 1 TB paměti. VictoriaMetrics ví, jak všechny tyto zdroje využít. Jeho výkon se ve srovnání s 100jádrovým systémem zvýší asi 1krát.

Historie Thanose začala v listopadu 2017, kdy se objevil první veřejný závazek. Předtím byl Thanos vyvíjen interně .

V červnu 2019 došlo k přelomové verzi 0.5.0, ve které protokol. Byl odstraněn z Thanose, protože nevystupoval dobře. Klastr Thanos často nefungoval správně, uzly se k němu nesprávně připojovaly kvůli gossip protokolu. Tak jsme se rozhodli to odtamtud odstranit. Věřím, že je to správné rozhodnutí.

Ve stejném červnu 2019 zaslali číslo přihlášky в .

A po několika měsících byl Thanos přijat , která zahrnuje Prometheus, Kubernetes a další oblíbené projekty.

V lednu 2018 začal vývoj VictoriaMetrics.

V září 2018 jsem poprvé veřejně zmínil VictoriaMetrics.

V prosinci 2018 byla publikována verze Single-node.

V květnu 2019 zdroje verze s jedním uzlem i s clusterem.

V červnu 2019 jsme stejně jako Thanos podali žádost do nadace CNCF pod číslem . Přihlásili jsme se jeden den před Thanosem.

Ale bohužel nás tam stále nepřijali. Potřebná pomoc komunity.

Zvažte nejdůležitější snímky zobrazující architekturu Thanos a VictoriaMetrics.
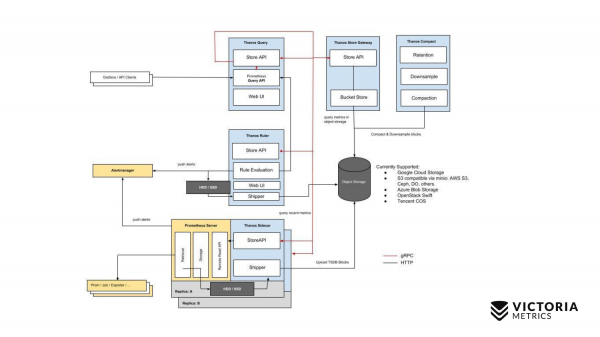
Začněme Thanosem. Žluté komponenty jsou komponenty Prometheus. Vše ostatní jsou komponenty Thanos. Začněme tou nejdůležitější složkou. Thanos Sidecar je komponenta, která se instaluje vedle každého Promethea. Je zodpovědný za načítání dat Prometheus z místního úložiště do S3 nebo jiného Object Storage.
Existuje také taková komponenta, jako je Thanos Store Gateway, která dokáže číst tato data z Object Storage na základě příchozích požadavků z Thanos Query. Thanos Query implementuje PromQL a Prometheus API. To znamená, že zvenčí vypadá jako Prometheus. Přijímá požadavky PromQL, odesílá je do Thanos Store Gateway, Thanos Store Gateway získává potřebná data z Object Storage a posílá je zpět.
Ale máme data uložená v Object Storage bez posledních dvou hodin kvůli implementaci Thanos Sidecar, která nemůže nahrát poslední dvě hodiny do Object Storage S3, protože Prometheus ještě nevytvořil soubory v místním úložišti pro tyto dvě hodiny.
Jak jste se rozhodli toto obejít? Thanos Query, kromě požadavků na bránu Thanos Store Gateway, posílá paralelní požadavky do každého Thanos Sidecar, který je vedle Promethea.
A Thanos Sidecar na oplátku zasílá požadavky dále Prometheovi a získává data za poslední dvě hodiny.
Kromě těchto komponentů je zde i volitelný komponent, bez kterého se bude Thanos cítit špatně. Toto je Thanos Compact, který spojuje malé soubory na Object Storage do větších souborů, které sem nahrál Thanos Sidecars. Thanos Sidecar tam nahrává datové soubory po dobu dvou hodin. Tyto soubory, pokud nejsou sloučeny do větších souborů, může jejich počet velmi výrazně narůst. Čím více takových souborů, tím více paměti je potřeba pro Thanos Store Gateway, tím více zdrojů je potřeba k přenosu dat po síti, metadat. Thanos Store Gateway se stává neefektivní. Proto je nutné spustit Thanos Compact, který sloučí malé soubory do větších, aby takových souborů bylo méně a snížila se režie na Thanos Store Gateway.
Existuje také komponenta jako Thanos Ruler. Provádí pravidla výstrahy Prometheus a může vypočítat pravidla nahrávání Prometheus, aby mohla zapisovat data zpět do Object Storage. Tuto součást se však nedoporučuje používat, protože. On .
Zde je jednoduché schéma pro Thanose.
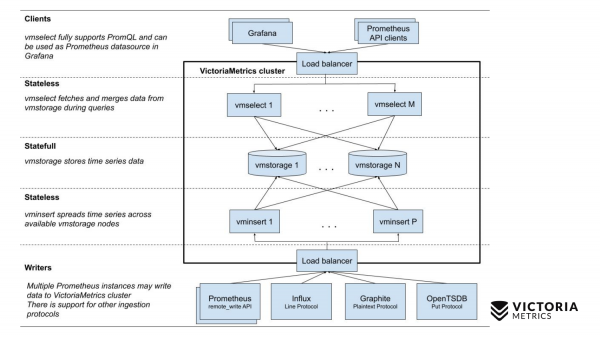
Nyní porovnejme se schématem VictoriaMetrics.
VictoriaMetrics má 2 verze: Single-node a cluster verze. Jeden uzel běží na jednom počítači. Single-node nemá tyto komponenty, jen jednu binární. Tato dvojhvězda na snímku vypadá jako tento čtverec. Vše uvnitř čtverce je obsah binárního souboru pro verzi s jedním uzlem. Nemusíte o tom vědět. Stačí spustit binární soubor - a vše funguje za nás.
Klastrová verze je obtížnější. Uvnitř jsou tři různé komponenty: vmselect, vminsert a vmstorage. Z jejich názvu by mělo být zřejmé, co každý z nich dělá. Komponenta Insert přijímá data v různých formátech: z API vzdáleného zápisu Prometheus, protokolu Influx line, protokolu Graphite a protokolu OpenTSDB. Komponenta Insert je přijímá, analyzuje a distribuuje mezi existující komponenty úložiště, kde jsou již data uložena. Komponenta Select zase přijímá dotazy PromQL. Realizuje , stejně jako dotazovací API Prometheus a lze jej použít jako náhradu za Prometheus v Grafaně nebo jiných klientech Prometheus API. Select převezme požadavek promql, analyzuje jej, načte data nezbytná k provedení tohoto požadavku z uzlů úložiště, zpracuje tato data a vrátí odpověď.

Porovnejme náročnost instalace Thanos a VictoriaMetrics.

Začněme Thanosem. Než začnete pracovat s Thanosem, musíte vytvořit bucket v Object Storage, jako je S3 nebo GCS, aby tam Thanos Sidecar mohl zapisovat data.

Pak pro každý Prometheus musíte nainstalovat Thanos Sidecar. Předtím si musíte zapamatovat, že v Prometheus je zakázáno komprimování dat. Kompaktování dat pravidelně komprimuje data v místním úložišti Prometheus, aby se snížila spotřeba zdrojů.
Když nainstalujete Thanos Sidecar na váš Prometheus, musíte toto komprimování dat zakázat, protože Thanos Sidecar nefunguje správně, když je komprimace dat povolena. To znamená, že váš Prometheus začne ukládat data v blocích po dvou hodinách a přestane tyto bloky spojovat do větších. Pokud tedy zadáte požadavky, které překročí dobu trvání posledních dvou hodin, nebudou fungovat tak efektivně, jak by mohly fungovat, pokud by bylo povoleno zhutňování dat.

Thanos proto doporučuje zkrátit dobu uchovávání dat v místním úložišti na 6–8 hodin, aby se snížila tato režie velkého počtu malých bloků.
Poté, co jste nainstalovali Thanos Sidecar, musíte nainstalovat dvě součásti pro každý objekt úložiště. Jedná se o Thanos Compactor a Thanos Store Gateway.

Poté musíte nainstalovat Thanos Query a nakonfigurovat jej tak, aby se mohl připojit ke všem Thanos Store Gateways, které máte, a také se mohl připojit ke všem Thanos Sidecars.
Tady může být malý problém.

Musíte nastavit spolehlivé a bezpečné připojení z Thanos Query k těmto komponentám. A pokud máte Prometheus'y umístěné v různých datových centrech nebo v různých VPC, pak je připojení zvenčí zakázáno. Ale aby Thanos Query fungovalo, musíte tam nějak nakonfigurovat připojení a musíte přijít na způsob.
Pokud máte takových datových center hodně, pak se spolehlivost celého systému snižuje. Protože Thanos Query musí neustále udržovat spojení se všemi Thanos Sidecars umístěnými v různých datových centrech. S každým příchozím požadavkem odešle požadavky všem Thanos Sidecars. Pokud je spojení přerušeno, obdržíte buď neúplnou datovou sadu, nebo obdržíte odpověď „klastr nefunguje“.

Ve VictoriaMetrics jsou věci trochu jednodušší. U verze Single-node stačí spustit jeden binární soubor a vše funguje.

V clusterové verzi stačí spustit všechny výše uvedené tři typy komponent v libovolném množství, které potřebujete nebo používáte k automatizaci spouštění komponent v Kubernetes. Plánujeme také udělat operátora Kubernetes. Tabulka kormidla nepokrývá některé případy a umožňuje vám vystřelit si nohu. Umožňuje například snížit počet uzlů úložiště, což povede ke ztrátě dat.

Po spuštění jedné binární nebo clusterové verze stačí přidat do konfigurace Prometheus takže začne zapisovat data paralelně do místního úložiště a vzdáleného úložiště. Jak vidíte, tato konfigurace by měla fungovat mnohem spolehlivěji než konfigurace Thanos. Nemusíme udržovat spojení z VictoriaMetrics se všemi Prometheus's, protože Prometheus's samy se připojují k VictoriaMetrics a přenášejí data.

Zvažte podporu pro Thanos a VictoriaMetrics.

Thanos musí dávat pozor na Sidecar, aby nepřestali nahrávat data do Object Storage. Mohou zastavit toto stahování dat kvůli chybám stahování, jako je dočasné přerušení síťového připojení k úložišti objektů nebo dočasně nedostupné úložiště objektů. Thanos Sidecar si toho v tuto chvíli všimne, nahlásí chybu, může selhat a poté přestane fungovat. Pokud to nebudete monitorovat, vaše data již nebudou přenášena do Object Storage. Pokud doba uchování uplyne (doporučuje se 6-8 hodin), ztratíte data, která se nedostala do Object Storage.

Kompaktory Thanos mohou přestat fungovat kvůli . Zhutňovače berou data z Object Storage a spojují je do větších kusů dat. Protože kompaktory nejsou synchronizovány s postranními vozíky, může se stát následující: postranní vozík ještě nestihl přidat blok, kompaktor se rozhodne, že tento blok byl kompletně zapsán. Compactor jej začne číst. Přečte blok neúplně a přestane fungovat. Prohlednout detaily .

Store Gateway může vrátit nekonzistentní data kvůli závodům mezi Compactor a Sidecars. Zde je to stejné, protože Store Gateway není nijak synchronizován s Compactory a Sidecars. V souladu s tím mohou nastat závody, když brána obchodu nevidí část dat nebo vidí data navíc.

Komponenta Query v Thanosu ve výchozím nastavení vrací částečný výsledek, pokud některé postranní vozíky nebo brány obchodů nejsou momentálně dostupné. Obdržíte některá data a ani nebudete vědět, že jste neobdrželi všechna data. Takto to funguje standardně. V podobné situaci VictoriaMetrics vrátí označená data jako částečná.

Na rozdíl od Thanos, VictoriaMetrics zřídka ztratí data. I když je spojení z Prometheus do VictoriaMetrics přerušeno, pak to není problém, protože Prometheus pokračuje v zapisování příchozích nových dat do protokolu Write Ahead, který trvá 2 hodiny. Pokud obnovíte připojení k VictoriaMetrics do dvou hodin, data nebudou ztracena. Prometheus .

Na rozdíl od Thanos, který zapisuje data do objektového úložiště až po dvou hodinách, Prometheus automaticky replikuje data prostřednictvím protokolu vzdáleného zápisu do vzdáleného úložiště, jako je VictoriaMetrics. Nebojíte se ztráty místního úložiště v Prometheus. Pokud náhle ztratil místní úložiště, ztratíte poslední sekundy dat, která se v nejhorším případě nestihla zapsat na vzdálené úložiště.

Kubernetes spravuje cluster automaticky na rozdíl od Thanos. Je obtížné umístit všechny komponenty Thanos do jednoho clusteru Kubernetes, na rozdíl od komponent clusteru VictoriaMetrics.

VictoriaMetrics má velmi snadný upgrade na novou verzi. Stačí zastavit VictoriaMetrics, aktualizovat binární soubory a začít. Po zastavení pomocí signálu SIGINT se všechny binární soubory VictoriaMetrics elegantně vypnou. Správně ukládají potřebná data, správně uzavírají příchozí spojení, aby o nic nepřišli. Upgradem tedy nic neztratíte.

Pro VictoriaMetrics je velmi snadné cluster rozšířit. Stačí přidat potřebné komponenty a pokračovat v práci.

O úskalích v Thanos a VictoriaMetrics.

Thanos má následující úskalí. Prometheus by měl ukládat data za poslední dvě hodiny. Pokud se ztratí, ztratíte je úplně, protože neměly čas zapisovat do Object Storage, jako je S3.

Komponenta Store Gateway a komponenta kompaktoru mohou být náročné na paměť, aby se vypořádaly s úložištěm velkých objektů, pokud je tam uloženo mnoho malých souborů. Čím větší je počet a velikost souborů, tím více paměti RAM Store Gateway a kompaktor potřebují k ukládání metainformací. Thanos má spoustu problémů ohledně čeho .

Thanos je inzerován jako schopný neomezeně škálovat podle počtu Prometheus, který máte. Ve skutečnosti to není pravda. Protože všechny požadavky procházejí komponentou Query, která musí paralelně dotazovat všechny komponenty Store Gateway a všechny komponenty Sidecar, extrahovat odtud data a poté je předzpracovat. Je zřejmé, že rychlost požadavků je omezena nejpomalejším slabým článkem, nejpomalejší Store Gateway nebo nejpomalejším Sidecarem.
Tyto součásti mohou být nerovnoměrně zatíženy. Například máte Prometheus, který shromažďuje miliony metrik za sekundu. A je tu Prometheus, který shromažďuje tisíce metrik za sekundu. Prometheus, který shromažďuje miliony metrik za sekundu, načítá server, na kterém běží, mnohem více. Sidecar je tam tedy pomalejší. A obecně je tam všechno pomalé. A komponenta Query odtud bude tahat data velmi pomalu. Výkon celého vašeho clusteru bude tedy touto pomalou sajdkárou omezen.

Ve výchozím nastavení Thanos vrací částečná data, pokud nejsou k dispozici některé postranní vozíky a brány obchodu. Pokud máte například Sidecars rozeseté po celém světě v různých datových centrech, pak se pravděpodobnost odpojení a nedostupnosti komponent značně zvyšuje. V souladu s tím ve většině případů obdržíte částečná data, aniž byste o tom věděli.
VictoriaMetrics má také úskalí. Prvním úskalím je možnost, která omezuje množství paměti RAM použité pro mezipaměť VictoriaMetrics. Výchozí hodnota je 60 % RAM na počítači, kde běží VictoriaMetrics, nebo 60 % RAM na VictoriaMetrics pod v Kubernetes.
Pokud tuto hodnotu změníte nesprávně, můžete zničit výkon VictoriaMetrics. Pokud je například hodnota nastavena příliš nízko, data se již nemusí vejít do mezipaměti VictoriaMetrics. Ta kvůli tomu bude muset dělat práci navíc a zatěžovat procesor s diskem. Pokud tuto možnost nastavíte příliš velkou, zvýší se za prvé pravděpodobnost, že VictoriaMetrics spadne s chybou nedostatku paměti, a zadruhé to povede k tomu, že operačnímu systému zbude velmi málo paměti RAM pro soubor. mezipaměti. A VictoriaMetrics spoléhá na výkon mezipaměti souborů. Pokud to nestačí, může se zatížení disku výrazně zvýšit. Proto rada: neměňte parametr, pokud to není nezbytně nutné.
Druhá možnost. Toto retenční období je období, které je standardně nastaveno na 1 měsíc. Toto je doba, po kterou VictoriaMetrics uchovává data. Po uplynutí této doby VictoriaMetrics data odstraní.
Mnoho lidí provozuje VictoriaMetrics bez této možnosti a zaznamenává data po dobu jednoho měsíce. A pak se ptají: proč zmizela data za předchozí měsíc? Protože výchozí doba uchování je 1 měsíc. Proto musíte znát a nastavit správnou retenční dobu.

Pojďme si projít jedinečné funkce.

Thanos má funkci zvanou downsampling: 5minutové a hodinové intervaly, které jsou často . Pokud googlujete a podíváte se na jejich problém na githubu, existuje mnoho problémů souvisejících s tímto downsamplingem, že někdy nefunguje správně nebo nefunguje tak, jak uživatelé očekávají.

Thanos má deduplikaci dat pro páry Prometheus HA. Když dva Prometheové shromáždí stejné metriky ze stejných cílů a Thanos je přidá do Object Storage. Thanos dokáže tato data správně odstranit, na rozdíl od VictoriaMetrics.

Thanos má výstražnou komponentu, která byla na schématu Thanos. Ale on .

Thanos má tu výhodu, že Thanos a Prometheus sdílejí stejný kód. Thanos a Prometheus jsou vyvíjeny stejnými vývojáři. S vylepšeními v Thanos nebo Prometheus vítězí druhá strana.

Hlavním rysem VictoriaMetrics je MetricsQL. Toto jsou rozšíření VictoriaMetrics pro PromQL, o kterých jsem mluvil na předchozím velkém monitorovacím setkání.

VictoriaMetrics podporuje nahrávání dat pomocí mnoha různých protokolů. VictoriaMetrics dokáže přijímat data nejen z Prometheus, ale také prostřednictvím protokolů Influx, OpenTSDB a Graphite.

Data VictoriaMetrics zabírají mnohem méně místa než Thanos a Prometheus.
Při zápisu reálných dat uživatelé hovoří o 2-5násobném snížení velikosti dat na disku oproti Prometheus a Thanos.

Další výhodou VictoriaMetrics je, že je optimalizována pro rychlost.

Pojďme k nákladům na infrastrukturu.

Jednou z výhod Thanosu je, že ukládá data do objektového úložiště, což je relativně levné.
Při ukládání dat do objektového úložiště musíte zaplatit za operace zápisu a čtení dat (10 USD za milion operací). Když zapisujete data do objektového úložiště, platíte své náklady na hosting za nahrávání dat na internet, pokud váš cluster není v AWS – tam je to zdarma. Když čtete data, zaplatíte mezi 10 a 230 dolary za 1 TB. To může být významné, pokud často požadujete historická data z clusteru Thanos.

Pro cluster Thanos musíte platit za servery za Compact, Store Gateway, Query komponenty, které vyžadují hodně paměti, CPU pro velké množství dat.

VictoriaMetrics má následující náklady. Pokud data ukládáte na GCE HDD, pak vyjde 40 dolarů za 1 TB. Pro VictoriaMetrics stačí obyčejné HDD disky, nejsou potřeba SSD, která stojí pětkrát víc. VictoriaMetrics je optimalizována pro HDD.

VictoriaMetrics potřebuje servery pro komponenty: buď Single-nod, nebo pro clusterované komponenty, které na rozdíl od komponent Thanos vyžadují mnohem méně CPU, RAM – respektive budou levnější.

Příklady implementace.

Pro Thanos je příkladem implementace Gitlab. Gitlab běží výhradně na Thanos. Ale ne všechno je tam tak hladké. Pokud se na ně podíváte , pak můžete vidět, že neustále nějaké mají : Nedostatek paměti pro komponenty Store Gateway nebo Query. Neustále musí zvyšovat množství paměti.
Z tohoto důvodu rostou náklady na řešení těchto problémů.
Druhou implementací, která může být úspěšnější, je Improbable, který odstartoval vývoj Thanose. Uvolnili zdroj Thanose. Improbable je společnost, která vyvíjí herní enginy.

VictoriaMetrics má veřejné příklady implementace, které jsou:
- tvůrce webových stránek wix
- Adidas implementuje VictoriaMetrics a dokonce se prezentoval na posledním PromConu 2019
- Reklamní síť TrafficStars
- Seznam.cz je oblíbený český vyhledávač.
A pak tu byly no-name společnosti, které teď nedokážu pojmenovat. Nesouhlasili.
- Jeden významný herní vývojář. Větší než im nepravděpodobný.
- Velký vývojář grafického softwaru.
- Velká ruská banka.
- Evropský výrobce větrných turbín, který úspěšně testoval VictoriaMetrics. Tento výrobce implementuje VictoriaMetrics pro monitorování dat větrných turbín rychlostí 50 vzorků za sekundu na senzor. Každá větrná turbína má několik stovek senzorů. Mají několik stovek větrných turbín.
- Ruské aerolinky, které chtějí zavést VictoriaMetrics, ale stále nemohou. Jsme s nimi ve fázi smlouvy.
 Závěry.
Závěry.
VictoriaMetrics a Thanos řeší podobné problémy, ale různými způsoby:
- Globální zobrazení dotazu
- horizontální měřítko
- svévolné zadržení

Děkuju.
Čekáme na vás na našem .

Průzkumu se mohou zúčastnit pouze registrovaní uživatelé. , prosím.
Co používáte jako dlouhodobé úložiště pro Prometheus?
35,3%Thanos6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%ostatní4
Hlasovalo 17 uživatelů. 16 uživatelů se zdrželo hlasování.
Zdroj: www.habr.com
