

Čas pro reporting v Excelu rychle mizí – trend k pohodlným nástrojům pro prezentaci a analýzu informací je patrný ve všech oblastech. O digitalizaci reportingu jsme interně diskutovali již delší dobu a zvolili jsme vizualizační a samoobslužný analytický systém Tableau. Alexander Bezugly, vedoucí oddělení analytických řešení a reportingu skupiny M.Video-Eldorado, hovořil o zkušenostech a výsledcích budování bojového dashboardu.
Okamžitě řeknu, že ne všechno, co bylo plánováno, bylo realizováno, ale zkušenost to byla zajímavá, doufám, že to bude užitečné i pro vás. A pokud má někdo nějaké nápady, jak by to šlo udělat lépe, budu moc vděčná za vaše rady a nápady.

Pod střihem je o tom, s čím jsme se setkali a o čem jsme se dozvěděli.
kde jsme začali?
M.Video-Eldorado má dobře propracovaný datový model: strukturované informace s požadovanou hloubkou úložiště a obrovské množství reportů s pevnou formou (viz více podrobností ). Analytici z nich vytvářejí buď kontingenční tabulky nebo formátované bulletiny v Excelu, nebo krásné PowerPointové prezentace pro koncové uživatele.
Zhruba před dvěma lety jsme místo sestav s pevnou formou začali vytvářet analytické sestavy v SAP Analysis (doplněk Excelu, v podstatě kontingenční tabulka nad OLAP enginem). Tento nástroj však nedokázal uspokojit potřeby všech uživatelů, většina nadále využívala informace dodatečně zpracované analytiky.
Naši koncoví uživatelé se dělí do tří kategorií:
Vedení firmy. Požaduje informace dobře podané a jasně srozumitelné.
Střední management, pokročilí uživatelé. Zajímáte se o průzkum dat a jste schopni samostatně vytvářet sestavy, pokud jsou k dispozici nástroje. Stali se klíčovými uživateli analytických sestav v SAP Analysis.
Masoví uživatelé. Nezajímá je nezávislá analýza dat, používají reporty s omezenou mírou volnosti ve formátu newsletterů a kontingenčních tabulek v Excelu.
Naší myšlenkou bylo pokrýt potřeby všech uživatelů a poskytnout jim jediný pohodlný nástroj. Rozhodli jsme se začít s top managementem. Potřebovali snadno použitelné řídicí panely pro analýzu klíčových obchodních výsledků. Začali jsme tedy s Tableau a nejprve jsme zvolili dva směry: maloobchodní a online ukazatele prodeje s omezenou hloubkou a šířkou analýzy, které by pokrývaly přibližně 80 % dat požadovaných vrcholovým managementem.
Vzhledem k tomu, že uživatelé dashboardů byli top management, objevil se další KPI produktu – rychlost odezvy. Nikdo nebude čekat 20-30 sekund na aktualizaci dat. Navigace by měla být provedena během 4–5 sekund, nebo ještě lépe okamžitě. A to se nám bohužel nepodařilo dosáhnout.
Takto vypadalo rozvržení našeho hlavního panelu:
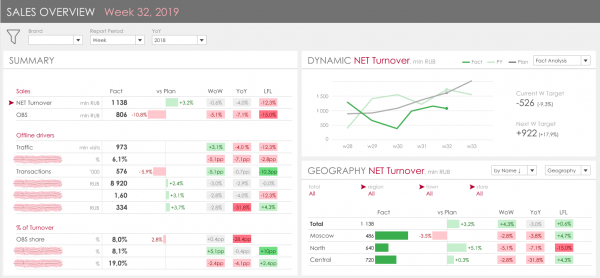
Klíčovou myšlenkou je zkombinovat hlavní tahouny KPI, kterých bylo celkem 19, vlevo a prezentovat jejich dynamiku a rozdělení podle hlavních atributů vpravo. Úkol se zdá jednoduchý, vizualizace je logická a srozumitelná, dokud se neponoříte do detailů.
Detail 1. Objem dat
Naše hlavní tabulka pro roční prodeje zabírá asi 300 milionů řádků. Vzhledem k tomu, že je nutné zohlednit dynamiku za loňský a předloňský rok, je objem dat jen o skutečných tržbách cca 1 miliarda řádků. Odděleně jsou ukládány také informace o plánovaných datech a online prodejní blok. I když jsme tedy použili sloupcový in-memory DB SAP HANA, rychlost dotazu s výběrem všech indikátorů na jeden týden z aktuálního úložiště za běhu byla cca 15-20 sekund. Řešení tohoto problému se nabízí samo – dodatečná materializace dat. Má to ale i úskalí, více o nich níže.
Detail 2. Neaditivní ukazatele
Mnoho našich KPI je vázáno na počet účtenek. A tento indikátor představuje COUNT DISTINCT počtu řádků (kontrolních hlaviček) a ukazuje různé částky v závislosti na zvolených atributech. Například, jak by se měl tento ukazatel a jeho derivát vypočítat:

Aby byly vaše výpočty správné, můžete:
- Vypočítejte takové ukazatele za chodu v úložišti;
- Proveďte výpočty na celý objem dat v Tableau, tzn. na vyžádání v Tableau poskytnout všechna data dle vybraných filtrů v granularitě pozice účtenky;
- Vytvořte materializovanou vitrínu, ve které budou všechny indikátory vypočítány ve všech možnostech vzorku, které poskytují různé neaditivní výsledky.
Je zřejmé, že v příkladu UTE1 a UTE2 jsou materiálové atributy představující hierarchii produktu. Nejedná se o statickou věc, její prostřednictvím probíhá řízení uvnitř firmy, protože... Různí manažeři jsou zodpovědní za různé skupiny produktů. Měli jsme mnoho globálních revizí této hierarchie, kdy se změnily všechny úrovně, kdy byly revidovány vztahy, a neustálých bodových změn, kdy se jedna skupina přesunula z jednoho uzlu do druhého. V konvenčním reportingu se to vše počítá za běhu z atributů materiálu, v případě materializace těchto dat je nutné vyvinout mechanismus pro sledování takových změn a automatické přečítání historických dat. Velmi netriviální úkol.
Detail 3. Porovnání dat
Tento bod je podobný předchozímu. Pointa je, že při analýze společnosti je obvyklé vytvořit několik úrovní srovnání s předchozím obdobím:
Srovnání s předchozím obdobím (ze dne na den, z týdne na týden, z měsíce na měsíc)
V tomto srovnání se předpokládá, že v závislosti na uživatelem zvoleném období (například 33. týden v roce) bychom měli dynamiku zobrazit do 32. týdne, pokud bychom vybrali data za měsíc, např. květen , pak by toto srovnání ukázalo dynamiku do dubna.
Srovnání s loňským rokem
Zde je hlavní nuance, že při porovnávání po dnech a týdnech neberete stejný den loňského roku, tj. nemůžete prostě dát aktuální rok mínus jedna. Musíte se podívat na den v týdnu, který porovnáváte. Při porovnávání měsíců je naopak potřeba vzít přesně stejný kalendářní den loňského roku. Existují také nuance s přestupnými roky. V původních úložištích jsou všechny informace distribuovány po dnech, nejsou zde žádná samostatná pole s týdny, měsíci nebo roky. Proto, abyste získali úplný analytický průřez v panelu, musíte počítat ne jedno období, například týden, ale 4 týdny, a poté tato data porovnat, odrážet dynamiku, odchylky. V souladu s tím může být tato logika pro generování porovnání dynamiky také implementována buď v Tableau, nebo na straně výkladu. Ano, a samozřejmě jsme o těchto detailech věděli a přemýšleli o nich ve fázi návrhu, ale bylo těžké předvídat jejich dopad na výkon finální palubní desky.
Při implementaci palubní desky jsme šli dlouhou cestou Agile. Naším úkolem bylo co nejrychleji poskytnout pracovní nástroj s potřebnými daty pro testování. Proto jsme šli do sprintů a začali jsme od minimalizace práce na straně současného úložiště.
Část 1: Víra v tablo
Abychom zjednodušili IT podporu a rychle implementovali změny, rozhodli jsme se vytvořit logiku pro výpočet neaditivních ukazatelů a porovnávání minulých období v Tableau.
Fáze 1. Vše je živé, žádné úpravy oken.
V této fázi jsme připojili Tableau k aktuálním výlohám a rozhodli jsme se zjistit, jak se bude počítat počet účtenek za jeden rok.
Výsledek:
Odpověď byla depresivní – 20 minut. Přenos dat po síti, vysoké zatížení Tableau. Uvědomili jsme si, že na HANA je třeba implementovat logiku s neaditivními indikátory. To nás moc nevyděsilo, už jsme měli podobnou zkušenost s BO a Analysis a věděli jsme, jak v HANA postavit rychlé vitríny, které produkují správně vypočítané neaditivní ukazatele. Teď už jen zbývalo je upravit na Tableau.
Fáze 2. Ladíme vitríny, žádná materializace, vše za pochodu.
Vytvořili jsme samostatnou novou vitrínu, která produkovala požadovaná data pro TABLEAU za chodu. Obecně jsme dosáhli dobrého výsledku, zkrátili jsme čas pro generování všech indikátorů za týden na 9-10 sekund. A upřímně jsme čekali, že v Tableau bude doba odezvy dashboardu 20-30 sekund při prvním otevření a následně kvůli cache od 10 do 12, což by nám obecně vyhovovalo.
Výsledek:
První otevření palubní desky: 4-5 minut
Jakékoli kliknutí: 3-4 minuty
Nikdo nečekal takový dodatečný nárůst práce výlohy.
Část 2. Ponořte se do Tableau
Fáze 1. Analýza výkonu v tabulce a rychlé ladění
Začali jsme analyzovat, kde Tableau tráví většinu času. A existují na to docela dobré nástroje, což je samozřejmě plus Tableau. Hlavním problémem, který jsme identifikovali, byly velmi složité SQL dotazy, které Tableau sestavoval. Byly spojeny především s:
— transpozice dat. Vzhledem k tomu, že Tableau nemá nástroje pro transpozici datových sad, pro vytvoření levé strany řídicího panelu s podrobnou reprezentací všech klíčových ukazatelů výkonu jsme museli vytvořit tabulku pomocí případu. Velikost SQL dotazů v databázi dosáhla 120 000 znaků.

- volba časového období. Kompilace takového dotazu na úrovni databáze zabrala více času než provedení:

Tito. zpracování požadavku 12 sekund + 5 sekund provedení.
Rozhodli jsme se zjednodušit výpočetní logiku na straně Tableau a přesunout další část výpočtů na úroveň obchodu a databáze. To přineslo dobré výsledky.
Nejprve jsme provedli transpozici za chodu, provedli jsme to přes úplné vnější spojení v konečné fázi výpočtu VIEW, podle tohoto přístupu popsaného na wiki и .
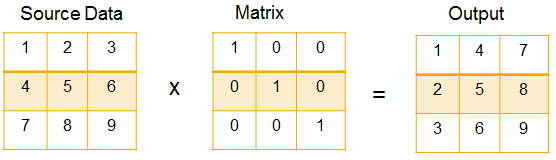
To znamená, že jsme vytvořili nastavovací tabulku - transpoziční matici (21x21) a obdrželi všechny indikátory v členění po řádcích.
Bylo to:

Stalo se:
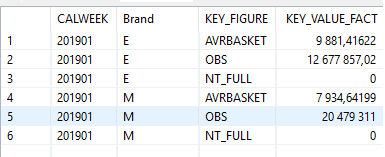
Samotná transpozice databáze nestráví téměř žádný čas. Požadavek na všechny indikátory pro daný týden byl nadále zpracováván přibližně za 10 sekund. Ale na druhou stranu se ztratila flexibilita z hlediska konstrukce dashboardu na základě konkrétního ukazatele, tzn. pro pravou stranu palubní desky, kde je prezentována dynamika a detailní rozpis konkrétního ukazatele, dříve okno displeje fungovalo za 1-3 sekundy, protože požadavek byl založen na jednom indikátoru a nyní databáze vždy vybrala všechny indikátory a filtrovala výsledek, než výsledek vrátila do Tableau.
V důsledku toho se rychlost palubní desky snížila téměř 3krát.
Výsledek:
- 5 sekund – parsování dashboardů, vizualizace
- 15-20 sekund - příprava na sestavení dotazů s provedením předkalkulací v Tableau
- 35-45 sec - kompilace SQL dotazů a jejich paralelně-sekvenční provádění na Hané
- 5 sec – zpracování výsledků, řazení, přepočítávání vizualizací v Tableau
- Takové výsledky samozřejmě obchodu nevyhovovaly a pokračovali jsme v optimalizaci.
Fáze 2. Minimální logika v Tableau, kompletní materializace
Pochopili jsme, že není možné postavit dashboard s dobou odezvy několik sekund na výloze, která běží 10 sekund, a zvažovali jsme možnosti zhmotnění dat na straně databáze speciálně pro požadovaný dashboard. Ale narazili jsme na globální problém popsaný výše – neaditivní ukazatele. Nebyli jsme schopni zajistit, aby při změně filtrů nebo rozbalení Tableau flexibilně přepínalo mezi různými výklady a úrovněmi předem navrženými pro různé hierarchie produktů (v příkladu tři dotazy bez UTE, s UTE1 a UTE2 generovaly různé výsledky). Rozhodli jsme se proto dashboard zjednodušit, opustit hierarchii produktů v dashboardu a podívat se, jak rychlý by mohl být ve zjednodušené verzi.
V této poslední fázi jsme tedy sestavili samostatné úložiště, do kterého jsme přidali všechny KPI v transponované podobě. Na straně databáze je jakýkoli požadavek na takové úložiště zpracován za 0,1 - 0,3 sekundy. Na řídicím panelu jsme obdrželi následující výsledky:
První otevření: 8-10 sekund
Jakékoli kliknutí: 6-7 sekund
Čas strávený Tableau se skládá z:
- 0,3 sec. — analýza a kompilace SQL dotazů na řídicím panelu
- 1,5-3 sec. — provádění SQL dotazů v Haně pro hlavní vizualizace (běží paralelně s krokem 1)
- 1,5-2 sec. — rendering, přepočet vizualizací
- 1,3 s — provedení dalších SQL dotazů pro získání relevantních hodnot filtru (značka, divize, město, obchod), analýza výsledků
Abych to stručně shrnul
Nástroj Tableau se nám líbil z pohledu vizualizace. Ve fázi prototypování jsme zvažovali různé vizualizační prvky a všechny jsme je našli v knihovnách, včetně komplexní víceúrovňové segmentace a vodopádu s více ovladači.
Při implementaci dashboardů s klíčovými ukazateli prodeje jsme narazili na výkonnostní potíže, které se nám zatím nepodařilo překonat. Strávili jsme více než dva měsíce a dostali jsme funkčně nekompletní dashboard, jehož rychlost odezvy je na hranici akceptovatelnosti. A vyvodili jsme závěry pro sebe:
- Tableau neumí pracovat s velkým množstvím dat. Pokud máte v původním datovém modelu více než 10 GB dat (přibližně 200 milionů X 50 řádků), řídicí panel se vážně zpomalí - z 10 sekund na několik minut na každé kliknutí. Experimentovali jsme jak s live-connect, tak s extraktem. Provozní rychlost je srovnatelná.
- Omezení při použití více úložišť (datových sad). Neexistuje žádný způsob, jak naznačit vztah mezi datovými sadami pomocí standardních prostředků. Pokud k připojení datových sad použijete zástupná řešení, výrazně to ovlivní výkon. V našem případě jsme zvažovali možnost materializace dat v každé požadované sekci pohledu a přepínání těchto materializovaných datových sad při zachování dříve vybraných filtrů – to se v Tableau ukázalo jako nemožné.
- V Tableau není možné vytvářet dynamické parametry. Parametr, který se používá k filtrování datové sady v extraktu nebo během živého připojení, nemůžete vyplnit výsledkem jiného výběru z datové sady nebo výsledkem jiného SQL dotazu, pouze nativním uživatelským vstupem nebo konstantou.
- Omezení spojená s vytvářením řídicího panelu s prvky OLAP|PivotTable.
Pokud v MSTR, SAP SAC, SAP Analysis přidáte datovou sadu do sestavy, pak všechny objekty v ní budou ve výchozím nastavení vzájemně související. Tableau toto nemá, připojení je nutné nakonfigurovat ručně. To je pravděpodobně flexibilnější, ale pro všechny naše palubní desky je to povinný požadavek na prvky – jedná se tedy o dodatečné náklady na pracovní sílu. Pokud navíc uděláte související filtry tak, že například při filtrování regionu je seznam měst omezen pouze na města tohoto regionu, okamžitě skončíte s po sobě jdoucími dotazy do databáze nebo výpisu, což znatelně zpomaluje přístrojová deska. - Omezení ve funkcích. Hromadné transformace nelze provádět ani na výpisu, ani ZVLÁŠTNĚ na datové sadě z Live-connecta. To lze provést pomocí Tableau Prep, ale je to další práce a další nástroj, který se musíte naučit a udržovat. Nemůžete například transponovat data nebo je spojit sama se sebou. Co se uzavírá pomocí transformací na jednotlivých sloupcích nebo polích, které je nutné volit pomocí case nebo if, a to generuje velmi složité SQL dotazy, ve kterých databáze většinu času stráví sestavováním textu dotazu. Tato nepružnost nástroje musela být vyřešena na úrovni showcase, což vede ke složitějšímu ukládání, dalším stahováním a transformacím.
Tableau jsme nevzdali. Ale nepovažujeme Tableau za nástroj schopný vytvářet průmyslové dashboardy a nástroj, kterým lze nahradit a digitalizovat celý firemní systém výkaznictví.
Nyní aktivně vyvíjíme podobný dashboard v jiném nástroji a zároveň se snažíme revidovat architekturu dashboardu v Tableau, abychom ji ještě více zjednodušili. Pokud bude mít komunita zájem, sdělíme vám výsledky.
Čekáme také na vaše nápady nebo rady, jak v Tabeau můžete postavit rychlé dashboardy nad tak velkými objemy dat, protože máme web, kde je dat mnohem více než v retailu.
Zdroj: www.habr.com
