


Kód softwarových produktů pro strojové učení je často složitý a značně matoucí. Detekce a odstranění chyb v něm je úkol náročný na zdroje. Dokonce i ty nejjednodušší vyžadují seriózní přístup k architektuře sítě, inicializaci vah a optimalizaci sítě. Malá chyba může vést k nepříjemným problémům.
Tento článek je o algoritmu pro ladění vašich neuronových sítí.
Skillbox doporučuje: Praktický kurz .
Připomínáme: pro všechny čtenáře "Habr" - sleva 10 000 rublů při zápisu do jakéhokoli kurzu Skillbox pomocí propagačního kódu "Habr".
Algoritmus se skládá z pěti fází:
- snadný start;
- potvrzení ztrát;
- kontrola mezivýsledků a spojení;
- diagnostika parametrů;
- kontrola práce.
Pokud se vám něco zdá zajímavější než ostatní, můžete rovnou přeskočit na tyto sekce.
Snadný start
Neuronová síť se složitou architekturou, regularizací a plánovačem rychlosti učení se ladí obtížněji než běžná síť. Jsme zde trochu záludní, protože samotný bod nepřímo souvisí s laděním, ale i tak je to důležité doporučení.
Jednoduchým začátkem je vytvoření zjednodušeného modelu a jeho natrénování na jedné množině (bodu) dat.
Nejprve vytvoříme zjednodušený model
Abychom mohli rychle začít, vytvoříme malou síť s jednou skrytou vrstvou a zkontrolujeme, zda vše funguje správně. Poté model postupně komplikujeme, kontrolujeme každý nový aspekt jeho struktury (další vrstva, parametr atd.) a pokračujeme dál.
Model trénujeme na jedné množině (bodu) dat
Jako rychlou kontrolu vašeho projektu můžete použít jeden nebo dva tréninkové datové body k potvrzení, zda systém funguje správně. Neuronová síť musí vykazovat 100% přesnost při tréninku a testování. Pokud tomu tak není, pak je buď model příliš malý, nebo již máte chybu.
I když je vše v pořádku, připravte model na jednu nebo více epoch, než budete pokračovat.
Hodnocení ztráty
Odhad ztráty je hlavním způsobem, jak zpřesnit výkon modelu. Musíte se ujistit, že ztráta odpovídá problému a že funkce ztráty jsou hodnoceny na správné stupnici. Pokud používáte více než jeden typ ztráty, ujistěte se, že jsou všechny ve stejném pořadí a jsou správně škálovány.
Je důležité dávat pozor na počáteční ztráty. Zkontrolujte, jak blízko je skutečný výsledek očekávanému výsledku, pokud model začínal náhodným odhadem. V : „Ujistěte se, že dosáhnete očekávaného výsledku, když začnete s malým počtem parametrů. Je lepší okamžitě zkontrolovat ztrátu dat (s mírou regularizace nastavenou na nulu). Například pro CIFAR-10 s klasifikátorem Softmax očekáváme počáteční ztrátu 2.302, protože očekávaná difúzní pravděpodobnost je 0,1 pro každou třídu (protože existuje 10 tříd) a ztráta Softmax je negativní logaritmická pravděpodobnost správné třídy. jako − ln (0.1) = 2.302.”
U binárního příkladu se jednoduše provede podobný výpočet pro každou z tříd. Zde jsou například data: 20 % 0 a 80 % 1. Očekávaná počáteční ztráta bude až –0,2 ln (0,5) –0,8 ln (0,5) = 0,693147. Pokud je výsledek větší než 1, může to znamenat, že váhy neuronové sítě nejsou správně vyváženy nebo data nejsou normalizovaná.
Kontrola mezivýsledků a spojení
Pro odladění neuronové sítě je nutné porozumět dynamice procesů uvnitř sítě a roli jednotlivých mezivrstev při jejich propojení. Zde jsou běžné chyby, se kterými se můžete setkat:
- nesprávné výrazy pro aktualizace gradle;
- aktualizace hmotnosti se nepoužijí;
- explodující gradienty.
Pokud jsou hodnoty přechodu nulové, znamená to, že rychlost učení v optimalizátoru je příliš pomalá nebo že se setkáváte s nesprávným výrazem pro aktualizaci přechodu.
Kromě toho je nutné sledovat hodnoty aktivačních funkcí, váhy a aktualizace každé z vrstev. Například velikost aktualizací parametrů (váhy a vychýlení) .
Existuje fenomén zvaný “Dying ReLU” resp , kdy neurony ReLU vydají nulu poté, co se naučí velkou zápornou hodnotu zkreslení pro své váhy. Tyto neurony se již nikdy nevystřelí v žádném bodě dat.
K identifikaci těchto chyb můžete použít kontrolu přechodu aproximací přechodu pomocí numerického přístupu. Pokud je blízko vypočteným gradientům, pak byla zpětná propagace implementována správně. Chcete-li vytvořit kontrolu přechodu, podívejte se na tyto skvělé zdroje od CS231 и Stejně jako Andrew Nga na toto téma.
označuje tři hlavní způsoby vizualizace neuronové sítě:
- Preliminary jsou jednoduché metody, které nám ukazují obecnou strukturu trénovaného modelu. Patří mezi ně výstup tvarů či filtrů jednotlivých vrstev neuronové sítě a parametry v rámci každé vrstvy.
- Na základě aktivace. V nich dešifrujeme aktivace jednotlivých neuronů nebo skupin neuronů, abychom pochopili jejich funkce.
- Na základě gradientů. Tyto metody mají tendenci manipulovat s gradienty, které se tvoří z dopředných a zpětných průchodů modelového tréninku (včetně map význačnosti a map aktivace tříd).
Pro vizualizaci aktivací a propojení jednotlivých vrstev existuje několik užitečných nástrojů, např. и .
Diagnostika parametrů
Neuronové sítě mají spoustu parametrů, které se vzájemně ovlivňují, což komplikuje optimalizaci. Ve skutečnosti je tato část předmětem aktivního výzkumu specialistů, takže níže uvedené návrhy je třeba považovat pouze za rady, výchozí body, ze kterých lze stavět.
Velikost balení (velikost dávky) – Pokud chcete, aby velikost dávky byla dostatečně velká, aby bylo možné získat přesné odhady gradientu chyb, ale dostatečně malá pro sestup stochastického gradientu (SGD) k regularizaci vaší sítě. Malé velikosti dávek povedou k rychlé konvergenci kvůli hluku během tréninkového procesu a následně k potížím s optimalizací. Toto je popsáno podrobněji .
Míra učení - příliš nízká povede k pomalé konvergenci nebo riziku uvíznutí v místních minimech. Vysoká rychlost učení zároveň způsobí optimalizační divergenci, protože riskujete proskočení hluboké, ale úzké části funkce ztráty. Zkuste použít plánování rychlosti k jejímu snížení při trénování neuronové sítě. Aktualizováno s CS231n .
Oříznutí přechodu — oříznutí gradientů parametrů během zpětného šíření na maximální hodnotu nebo mezní normu. Užitečné pro řešení případných explodujících přechodů, se kterými se můžete setkat v bodě tři.
Dávková normalizace - slouží k normalizaci vstupních dat každé vrstvy, což nám umožňuje řešit problém vnitřního posunu kovariát. Pokud používáte Dropout a Batch Norma společně, .
Stochastický gradient klesání (SGD) — existuje několik druhů SGD, které využívají hybnost, adaptivní rychlost učení a Nesterovovu metodu. Žádný z nich však nemá jasnou výhodu, pokud jde o efektivitu učení a zobecnění ().
Regulace - je rozhodující pro vytvoření zobecnitelného modelu, protože přidává penalizaci za složitost modelu nebo extrémní hodnoty parametrů. Toto je způsob, jak snížit rozptyl modelu, aniž by se výrazně zvýšilo jeho zkreslení. Více .
Chcete-li vše vyhodnotit sami, musíte zakázat regularizaci a sami zkontrolovat gradient ztráty dat.
Odpadnutí je další metoda zefektivnění sítě, aby se zabránilo přetížení. Při tréninku se dropout provádí pouze udržováním aktivity neuronu s určitou pravděpodobností p (hyperparametr) nebo jejím nastavením na nulu v opačném případě. V důsledku toho musí síť používat pro každou tréninkovou dávku jinou podmnožinu parametrů, což snižuje změny určitých parametrů, které se stávají dominantními.
Důležité: Pokud používáte jak výpadek, tak i dávkovou normalizaci, buďte opatrní na pořadí těchto operací nebo dokonce na jejich společné použití. To vše se stále aktivně projednává a doplňuje. Zde jsou dvě důležité diskuse na toto téma и .
Kontrola práce
Jde o dokumentaci pracovních postupů a experimentů. Pokud nic nedoložíte, můžete zapomenout například na to, jaká rychlost učení nebo váhy tříd se používají. Díky ovládání můžete snadno prohlížet a reprodukovat předchozí experimenty. To vám umožní snížit počet duplicitních experimentů.
Ruční dokumentace se však v případě velkého objemu práce může stát obtížným úkolem. Zde přicházejí nástroje jako Comet.ml, které vám pomohou automaticky protokolovat datové sady, změny kódu, experimentální historii a produkční modely, včetně klíčových informací o vašem modelu (hyperparametry, metriky výkonu modelu a informace o prostředí).
Neuronová síť může být velmi citlivá na malé změny, což povede k poklesu výkonu modelu. Sledování a dokumentování vaší práce je prvním krokem, který můžete udělat pro standardizaci vašeho prostředí a modelování.
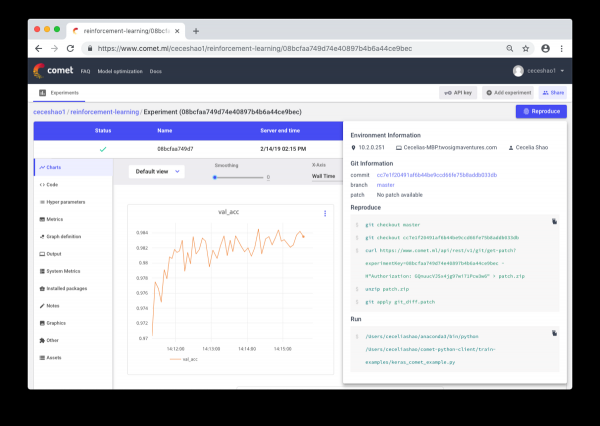
Doufám, že tento příspěvek může být výchozím bodem pro zahájení ladění vaší neuronové sítě.
Skillbox doporučuje:
- Dvouletý praktický kurz .
- Online kurz .
- Praktický roční kurz .
Zdroj: www.habr.com
