

Vi fortsætter med at introducere dig til Cisco HyperFlex hyperkonvergerede system.
I april 2019 vil Cisco endnu engang afholde en række demonstrationer af den nye Cisco HyperFlex hyperkonvergerede løsning i regionerne Rusland og Kasakhstan. Du kan tilmelde dig en demonstration ved hjælp af feedbackformularen ved at følge linket. Kom og vær med!
Tidligere udgav vi en artikel om belastningstests udført af det uafhængige laboratorium ESG Lab i 2017. I 2018 blev funktionerne i Cisco HyperFlex (HX 3.0)-løsningen betydeligt forbedret. Derudover fortsætter konkurrencedygtige løsninger også med at blive forbedret. Derfor udgiver vi en ny, nyere version af ESG's sammenlignende belastningstests.
I sommeren 2018 foretog ESG Lab en anden sammenligning af Cisco HyperFlex med konkurrenterne. I betragtning af den moderne tendens med at bruge softwaredefinerede løsninger, blev producenter af lignende platforme også føjet til den sammenlignende analyse.
Test konfigurationer
I testen blev HyperFlex sammenlignet med to fuldt softwarebaserede hyperkonvergerede systemer, der er installeret på standard x86-servere, samt med én hardware-software-løsning. Testningen blev udført ved hjælp af standardsoftware til hyperkonvergerede systemer – HCIBench, som bruger Oracle Vdbench-værktøjet og automatiserer testprocessen. Især opretter HCIBench automatisk virtuelle maskiner, koordinerer belastningen mellem dem og genererer praktiske og forståelige rapporter.
140 virtuelle maskiner blev oprettet pr. klynge (35 pr. klyngenode). Hver virtuel maskine brugte 4 vCPU'er og 4 GB RAM. Den lokale VM-disk var på 16 GB, og den ekstra disk var på 40 GB.
Følgende klyngekonfigurationer blev testet:
- 220-noders Cisco HyperFlex 1C-klynge med 400 x 6 GB SSD til cache og 1.2 x XNUMX TB SAS-harddisk til data;
- Leverandør En konkurrentklynge på fire noder med 2 x 400 GB SSD til cache og 4 x 1 TB SATA HDD til data;
- Leverandør B-konkurrentklynge med fire noder med 2 x 400 GB SSD til cache og 12 x 1.2 TB SAS-harddiske til data;
- Konkurrentleverandør C-klynge med fire noder med 4 x 480 GB SSD til cache og 12 x 900 GB SAS HDD til data.
Processorerne og RAM'en i alle løsninger var identiske.
Test for antallet af virtuelle maskiner
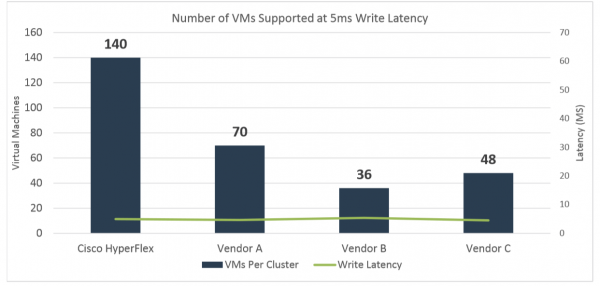
Testningen startede med en arbejdsbelastning designet til at emulere et standard OLTP-benchmark: 70%/30% læsning/skrivning (RW), 100% FullRandom med et mål på 800 IOPS pr. virtuel maskine (VM). Testen blev kørt på 140 virtuelle maskiner i hver klynge i tre til fire timer. Målet med testen er at holde skriveforsinkelser på eller under 5 millisekunder på så mange VM'er som muligt.
Som et resultat af testen (se grafen nedenfor) var HyperFlex den eneste platform, der gennemførte denne test med indledende 140 VM'er og med latenser under 5 ms (4,95 ms). For hver af de andre klynger blev testen gentaget for empirisk at justere antallet af VM'er til den ønskede latenstid på 5 ms over flere iterationer.
Leverandør A håndterede 70 virtuelle maskiner med en gennemsnitlig svartid på 4,65 ms.
Leverandør B opnåede den krævede latenstid på 5,37 ms. kun med 36 VM.
Leverandør C var i stand til at håndtere 48 VM'er med en svartid på 5,02 ms.
SQL Server-indlæsningsemulering
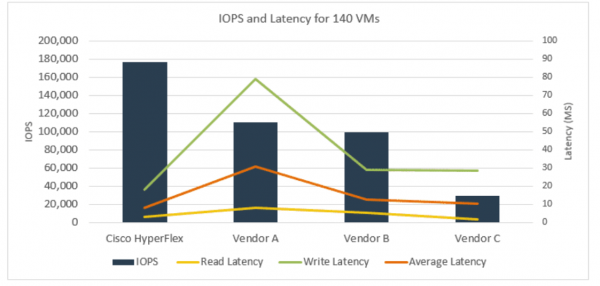
Dernæst emulerede ESG Lab SQL Server-indlæsningen. Testen brugte forskellige blokstørrelser og læse/skrive-forhold. Testen blev også kørt på 140 virtuelle maskiner.
Som vist i figuren nedenfor, fordoblede Cisco HyperFlex-klyngen næsten IOPS for leverandør A og B, og mere end fem gange leverandør C. Cisco HyperFlex' gennemsnitlige svartid var 8,2 ms. Til sammenligning var den gennemsnitlige svartid for leverandør A 30,6 ms, leverandør B 12,8 ms, og leverandør C 10,33 ms.
En interessant observation blev gjort under alle testene. Leverandør B viste betydelig variation i den gennemsnitlige IOPS-ydeevne på tværs af VM'er. Det vil sige, at belastningen var ekstremt ujævnt fordelt, nogle VM'er arbejdede med en gennemsnitlig værdi på 1000 IOPS+, og nogle med en værdi på 64 IOPS. Cisco HyperFlex så meget mere stabil ud i dette tilfælde. Alle 140 virtuelle maskiner modtog i gennemsnit 600 IOPS fra lagringsundersystemet, hvilket betyder, at belastningen blev fordelt meget jævnt mellem de virtuelle maskiner.
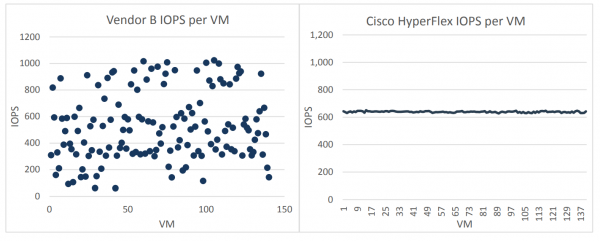
Det er vigtigt at bemærke, at denne ujævne fordeling af IOPS på tværs af virtuelle maskiner hos leverandør B blev observeret i hver test-iteration.
I den virkelige produktion kan sådan systemadfærd være et stort problem for administratorer. Faktisk begynder individuelle virtuelle maskiner tilfældigt at "fryse", og der er praktisk talt ingen måde at kontrollere denne proces på. Den eneste, ikke særlig succesfulde måde at afbalancere belastningen på, når man bruger en løsning fra leverandør B, er at bruge en eller anden implementering af QoS eller afbalancering.
Output
Lad os tænke over, hvad 140 virtuelle maskiner i Cisco Hyperflex pr. fysisk node er i forhold til 1 eller færre i andre løsninger? For virksomheder betyder det, at for at understøtte det samme antal applikationer på Hyperflex, skal man bruge dobbelt så mange noder som i konkurrenternes løsninger, dvs. det endelige system vil være meget billigere. Læg dertil automatiseringsniveauet på tværs af alle netværks-, server- og HX Data Platform-lagringsoperationer, og det bliver tydeligt, hvorfor Cisco Hyperflex-løsninger hurtigt vinder popularitet på markedet.
Samlet set bekræftede ESG Labs, at Cisco HyperFlex Hybrid Networks HX 3.0 leverer højere og mere ensartet ydeevne end andre lignende løsninger.
Samtidig overgik HyperFlex hybridklynger også konkurrenterne med hensyn til IOPS og latenstid. Lige så vigtigt blev HyperFlex-ydeevnen opnået med en meget velfordelt belastning på tværs af hele lageret.
Lad os minde dig om, at du kan se Cisco Hyperflex-løsningen og verificere dens muligheder lige nu. Systemet er tilgængeligt til demonstration for alle interesserede:
Kilde: www.habr.com
