

NeurIPS () – die größte Konferenz der Welt für maschinelles Lernen und künstliche Intelligenz sowie das wichtigste Ereignis im Bereich Deep Learning.
Werden wir, die DS-Ingenieure, im neuen Jahrzehnt auch Biologie, Linguistik, Psychologie erlernen? Darüber berichten wir in unserem Überblick.

In diesem Jahr versammelte die Konferenz mehr als 13.500 Teilnehmer aus 80 Ländern in Vancouver (Kanada). Die Sberbank vertritt Russland seit mehreren Jahren auf der Konferenz – das DS-Team berichtete über die Implementierung von ML in Bankprozesse, über einen ML-Wettbewerb und über die Möglichkeiten der Sberbank DS-Plattform. Was waren die wichtigsten Trends des Jahres 2019 in der ML-Community? Das berichten die Teilnehmer der Konferenz: und .
In diesem Jahr wurden auf NeurIPS mehr als 1400 Beiträge angenommen – Algorithmen, neue Modelle und neue Anwendungen für neue Daten.
Inhalt:
- Trends
- Interpretierbarkeit von Modellen
- Multidisziplinarität
- Reasoning
- RL
- GAN
- Hauptvorträge
- „Soziale Intelligenz“, Blaise Aguera y Arcas (Google)
- „Veridical Data Science“, Bin Yu (Berkeley)
- „Modellierung menschlichen Verhaltens mit maschinellem Lernen: Chancen und Herausforderungen“, Nuria M Oliver, Albert Ali Salah
- „Von System 1 zu System 2 Deep Learning“, Yoshua Bengio
Trends 2019
1. Interpretierbarkeit von Modellen und neue Methodologie im ML
Das Hauptthema der Konferenz ist die Interpretation und die Beweise, warum wir bestimmte Ergebnisse erzielen. Man kann lange über die philosophische Wichtigkeit der Interpretation des „Schwarzen Kastens“ nachdenken, aber es gab mehr praktische Methoden und technische Entwicklungen in diesem Bereich.
Die Methodologie der Reproduzierbarkeit von Modellen und der Wissensgewinnung aus ihnen ist ein neues Werkzeug der Wissenschaft. Modelle können als Instrument zur Gewinnung und Überprüfung neuen Wissens dienen, wobei jeder Schritt der Datenvorverarbeitung, des Lernens und der Anwendung des Modells reproduzierbar sein sollte.
Ein wesentlicher Teil der Veröffentlichungen widmet sich nicht dem Aufbau von Modellen und Werkzeugen, sondern den Problemen der Sicherheit, Transparenz und Überprüfbarkeit der Ergebnisse. Insbesondere gibt es einen separaten Stream zu Angriffen auf Modelle (adversarial attacks), bei dem sowohl Angriffe auf das Training als auch Angriffe auf die Anwendung betrachtet werden.
Artikel:
- — ein softwaretechnischer Artikel über die Methodologie der Modellverifizierung. Er umfasst einen Überblick über moderne Mittel zur Interpretation von Modellen, insbesondere die Verwendung von Attention und die Gewinnung von Feature Importance durch die „Distillation“ von neuronalen Netzen mit linearen Modellen.
- Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jimenez Rezende
- Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Edward Raff
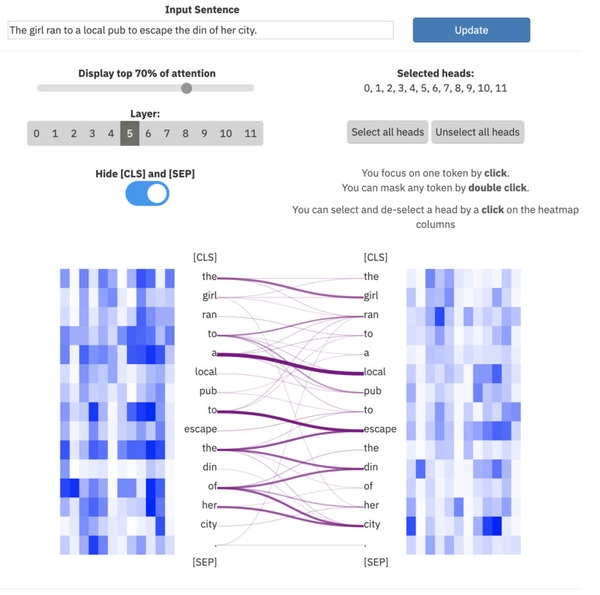
ExBert.net zeigt die Interpretation von Modellen für Textverarbeitungsaufgaben
2. Multidisziplinarität
Um eine zuverlässige Prüfung zu gewährleisten und Mechanismen zur Prüfung und Erweiterung von Wissen zu entwickeln, sind Fachleute aus verwandten Bereichen erforderlich, die gleichzeitig über Kompetenzen in ML und im Fachgebiet (Medizin, Linguistik, Neurobiologie, Bildung usw.) verfügen. Besonders hervorzuheben ist die verstärkte Präsenz von Arbeiten und Vorträgen über Neurowissenschaften und kognitive Wissenschaften – es findet eine Annäherung der Fachleute und eine Übernahme von Ideen statt.
Neben dieser Annäherung zeichnen sich multidisziplinäre Ansätze in der gemeinsamen Verarbeitung von Informationen aus verschiedenen Quellen ab: Text und Foto, Text und Spiele, Graphdatenbanken + Text und Foto.
Artikel:
- Neurobiologie + ML —
- VisualQA —
- RL + NLP —
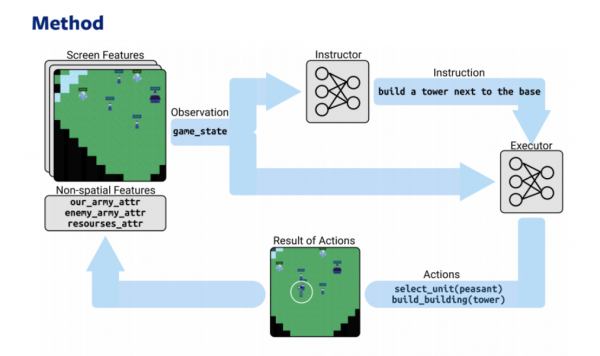
Zwei Modelle — Stratege und ausführender Spieler — basierend auf RL und NLP spielen ein Online-Strategie-Spiel
3. Schlussfolgerung
Stärkung der künstlichen Intelligenz – ein Schritt in Richtung selbstlernender Systeme, die 'bewusst', schlussfolgernd und argumentierend sind. Insbesondere entwickelt sich die kausale Inferenz und das gesunde Menschenverstand-Reasoning. Ein Teil der Vorträge ist dem Meta-Lernen gewidmet (darüber, wie man lernen lernt) und der Verbindung von DL-Technologien mit Logik erster und zweiter Ordnung — der Begriff der Artificial General Intelligence (AGI) wird zunehmend in den Präsentationen verwendet.
Artikel:
- Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Vaishak Belle, Brendan Juba
- Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, Ross Girshick
- Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4. Verstärkendes Lernen
Der Großteil der Arbeiten konzentriert sich weiterhin auf traditionelle Bereiche des RL — DOTA2, Starcraft, die Verbindung von Architekturen mit Computer Vision, NLP, graphenbasierten Datenbanken.
Ein ganzer Tag der Konferenz war dem RL-Workshop gewidmet, auf dem die Architektur des Optimistic Actor Critic Model vorgestellt wurde, das alle vorherigen Modelle übertrifft, insbesondere das Soft Actor Critic.
Artikel:
- ; Kamil Ciosek, Quan Vuong, Robert Loftin, Katja Hofmann
- ; Yasuhiro Fujita (Preferred Networks, Inc.)*; Toshiki Kataoka (Preferred Networks, Inc.); Prabhat Nagarajan (Preferred Networks); Takahiro Ishikawa (Universität Tokio) [external pdf link].
- ; Danijar Hafner (Google)*; Timothy Lillicrap (DeepMind); Jimmy Ba (Universität Toronto); Mohammad Norouzi (Google Brain)

StarCraft-Spieler kämpfen gegen das Alphastar-Modell (DeepMind)
5. GAN
Generative Netze stehen immer noch im Fokus: viele Arbeiten nutzen Vanilla GANs für mathematische Beweise und wenden sie in neuen, ungewöhnlichen Varianten an (graphenbasierte generative Modelle, Arbeiten mit Zeitreihen, Anwendung auf Kausalbeziehungen in Daten usw.).
Artikel:
- Sangwoo Mo, Chiheon Kim, Sungwoong Kim, Minsu Cho, Jinwoo Shin
- Dan Zhang, Anna Khoreva
- Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni
Seit mehr als werden wir die wichtigsten Präsentationen vorstellen.
Einladungsvorträge
„Soziale Intelligenz“, Blaise Aguera y Arcas (Google)
Der Vortrag widmet sich der allgemeinen Methodologie des maschinellen Lernens und den Perspektiven, die die Industrie gerade jetzt verändern – an welcher Weggabelung stehen wir? Wie funktioniert das Gehirn und die Evolution, und warum nutzen wir so wenig von dem, was wir bereits über die Entwicklung natürlicher Systeme wissen?
Die industrielle Entwicklung von ML stimmt in vielerlei Hinsicht mit den Meilensteinen der Entwicklung von Google überein, das Jahr für Jahr seine Forschungsarbeiten auf NeurIPS veröffentlicht:
- 1997 – Einführung von Suchleistungen, erste Server, geringe Rechenleistung
- 2010 – Jeff Dean startet das Google Brain-Projekt, Boom der neuronalen Netze ganz zu Anfang
- 2015 – industrielle Implementierung von neuronalen Netzen, schnelle Gesichtserkennung direkt auf dem lokalen Gerät, Low-Level-Prozessoren, spezialisiert auf Tensorberechnungen – TPU. Google startet Coral ai – eine Variante von Raspberry Pi, ein Mini-Computer zur Implementierung neuronaler Netze in experimentellen Anwendungen.
- 2017 – Google beginnt mit der Entwicklung des dezentralisierten Lernens und der Kombination von Lernergebnissen von neuronalen Netzen auf verschiedenen Geräten zu einem Modell – auf Android.
Heute beschäftigt sich eine ganze Branche mit Fragen der Datensicherheit, der Zusammenführung und der Reproduktion von Lernergebnissen auf lokalen Geräten.
– ein Bereich des ML, in dem einzelne Modelle unabhängig voneinander lernen und dann in ein einheitliches Modell kombiniert werden (ohne Zentralisierung der Ausgangsdaten), unter Berücksichtigung seltener Ereignisse, Anomalien, Personalisierung usw. Alle Android-Geräte fungieren im Wesentlichen als ein einziger computergestützter Supercomputer für Google.
Generative Modelle auf Basis von federated learning – eine vielversprechende Richtung aus Googles Sicht, die sich "in den frühen Phasen exponentiellen Wachstums" befindet. GANs sind laut dem Vortragenden in der Lage, das Massverhalten von Populationen lebender Organismen zu lernen sowie Denkalgorithmen.
Anhand von zwei einfachen GAN-Architekturen wird gezeigt, dass die Suche nach einem Optimierungsweg im Kreis verläuft, sodass eine tatsächliche Optimierung nicht stattfindet. Diese Modelle hingegen simulieren sehr erfolgreich die Experimente, die Biologen mit Bakterienpopulationen durchführen, indem sie diese dazu bringen, neue Verhaltensstrategien auf der Suche nach Nahrung zu lernen. Daraus lässt sich schließen, dass das Leben anders funktioniert als eine Optimierungsfunktion.
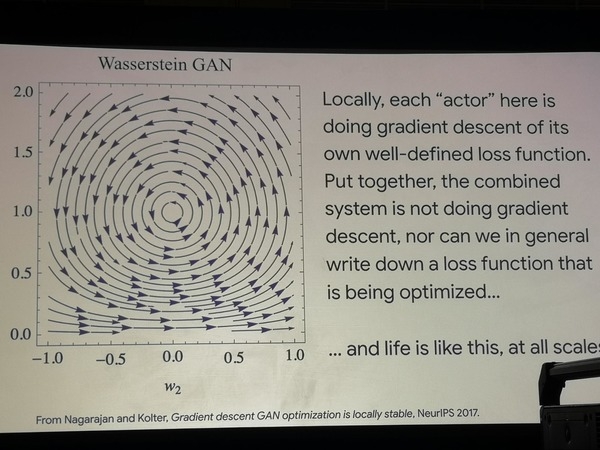
Umherirrende Optimierung von GAN
Alles, was wir derzeit im Bereich des maschinellen Lernens tun, sind eng umrissene und stark formalisierte Aufgaben, während diese Formalismen schlecht verallgemeinerbar sind und nicht mit unserem Fachwissen in Bereichen wie Neurophysiologie und Biologie übereinstimmen.
Was wir in naher Zukunft wirklich aus der Neurophysiologie übernehmen sollten, sind neue neuronale Architekturen und eine Überprüfung der Mechanismen des rückpropagierten Fehlers.
Das menschliche Gehirn selbst lernt nicht wie ein neuronales Netzwerk:
- Es hat keine zufälligen primären Eingaben, einschließlich derjenigen, die über die Sinne und in der Kindheit geprägt wurden.
- Es gibt angelegte Richtungen der instinctiven Entwicklung (das Verlangen eines Säuglings, eine Sprache zu lernen, aufrechtes Gehen).
Das Training des individuellen Gehirns ist eine niedrigstufige Aufgabe. Möglicherweise sollten wir "Kolonien" schnell wechselnder Individuen betrachten, die Wissen austauschen, um Mechanismen der Gruppenevolution zu reproduzieren.
Was wir bereits jetzt in ML-Algorithmen übernehmen können:
- Anwendung von Zelllinienmodellen, die das Lernen der Population ermöglichen, jedoch mit einer kurzen Lebensdauer des Individuums (des "individuellen Gehirns").
- Few-shot Learning mit einer begrenzten Anzahl an Beispielen.
- Komplexere neuronale Strukturen und etwas andere Aktivierungsfunktionen.
- Übertragung des "Genoms" an die nächsten Generationen – der Algorithmus des Rückpropagierungsfehlers.
- Sobald wir Neurophysiologie und neuronale Netzwerke verbinden, werden wir lernen, ein multifunktionales Gehirn aus vielen Komponenten zu konstruieren.
Aus dieser Perspektive betrachten die praktischen SOTA-Lösungen als schädlich und sollten zugunsten der Entwicklung gemeinsamer Aufgaben (Benchmarks) überdacht werden.
„Veridical Data Science“, Bin Yu (Berkeley)
Der Bericht behandelt die Problematik der Interpretation von Machine-Learning-Modellen und der Methodologie ihrer direkten Prüfung und Verifizierung. Jedes trainierte ML-Modell kann als Wissensquelle betrachtet werden, aus der Erkenntnisse gewonnen werden müssen.
In vielen Bereichen, insbesondere in der Medizin, ist die Anwendung eines Modells ohne die Extraktion dieser verborgenen Kenntnisse und die Interpretation der Modellresultate unmöglich – andernfalls können wir uns nicht sicher sein, dass die Ergebnisse stabil, nicht zufällig, zuverlässig sind und keinen Patienten gefährden. Ein ganzes Methodologiefeld entwickelt sich innerhalb der Deep-Learning-Paradigmatik und geht darüber hinaus – veridical data science. Was ist das?
Wir streben an, eine solche Qualität wissenschaftlicher Veröffentlichungen und Reproduzierbarkeit von Modellen zu erreichen, dass sie folgende Eigenschaften aufweisen:
- vorhersagbar
- berechenbar
- stabil
Diese drei Prinzipien bilden die Grundlage einer neuen Methodologie. Wie kann man ML-Modelle auf Übereinstimmung mit diesen Kriterien testen? Der einfachste Weg ist, von Anfang an interpretierbare Modelle (Regressionen, Entscheidungsbäume) zu bauen. Dennoch möchten wir auch die unmittelbaren Vorteile des Deep Learning nutzen.
Einige bestehende Ansätze zur Lösung des Problems sind:
- das Modell interpretieren;
- Methoden verwenden, die auf Attention basieren;
- Ensembles von Algorithmen beim Training einsetzen und sicherstellen, dass lineare, interpretierbare Modelle lernen, dieselben Antworten vorherzusagen wie neuronale Netze, indem sie Merkmale aus dem linearen Modell interpretieren;
- Daten für das Training ändern und augmentieren. Dazu gehören das Hinzufügen von Rauschen, Störungen und Data Augmentation;
- Alle Methoden, die sicherstellen, dass die Ergebnisse des Modells nicht zufällig und nicht von kleinen unerwünschten Störungen (Adversarial Attacks) abhängig sind;
- Das Modell post-faktum interpretieren, nach dem Training;
- Die Gewichtungen der Merkmale auf verschiedene Weise untersuchen;
- Die Wahrscheinlichkeiten aller Hypothesen und die Verteilung der Klassen untersuchen.

Adversarial attack
Modellierungsfehler kosten alle viel: Ein markantes Beispiel ist die Arbeit von Reinhardt und Rogoff "" beeinflusste die Wirtschaftspolitik vieler europäischer Länder und zwang sie zu einer Sparpolitik, aber eine sorgfältige Nachprüfung der Daten und ihrer Verarbeitung viele Jahre später zeigt ein gegenteiliges Ergebnis!
Jede ML-Technologie hat ihren Lebenszyklus von der Implementierung bis zur Einführung. Die Aufgabe der neuen Methodologie besteht darin, die Überprüfung nach drei grundlegenden Prinzipien in jeder Phase des Modelllebenszyklus vorzunehmen.
Zusammenfassung:
- Es laufen mehrere Projekte, die helfen werden, ML-Modelle zuverlässiger zu machen. Zum Beispiel deeptune (link to: );
- Für die weitere Entwicklung der Methodologie muss die Qualität der Veröffentlichungen im Bereich ML erheblich gesteigert werden;
- Maschinenlernen benötigt Führungspersönlichkeiten mit multidisziplinärer Ausbildung und Expertise sowohl in technischen als auch in geisteswissenschaftlichen Bereichen.
„Modellierung menschlichen Verhaltens mit maschinellem Lernen: Chancen und Herausforderungen“ Nuria M Oliver, Albert Ali Salah
Eine Vorlesung über die Modellierung menschlichen Verhaltens, deren technologische Grundlagen und Anwendungsmöglichkeiten.
Die Modellierung menschlichen Verhaltens kann unterteilt werden in:
- individuelles Verhalten
- Verhalten kleiner Gruppen
- kollektives Verhalten
Jeder dieser Typen kann mit ML modelliert werden, jedoch mit absolut unterschiedlichen Eingabedaten und Merkmalen. Jeder Typ hat auch seine eigenen ethischen Probleme, die jedes Projekt durchläuft:
- individuelles Verhalten – Identitätsdiebstahl, Deepfake;
- Verhalten von Gruppen – De-Anonymisierung, Informationsbeschaffung über Bewegungen, Telefonanrufe usw.;
Individuelles Verhalten
Bezieht sich hauptsächlich auf das Thema Computer Vision – Erkennung menschlicher Emotionen und Reaktionen. Möglich nur im Kontext, zeitlich oder relativ zu seiner eigenen Variabilität der Emotionen. Auf der Folie – Erkennung der Emotionen der Mona Lisa mithilfe des Kontexts aus dem emotionalen Spektrum mediterraner Frauen. Ergebnis: ein Lächeln der Freude, jedoch mit Verachtung und Ekel. Der Grund liegt wahrscheinlich in der technischen Bestimmung der 'neutralen' Emotion.
Verhalten einer kleinen Gruppe von Personen
Wird derzeit am schlechtesten modelliert aufgrund unzureichender Informationen. Als Beispiel wurden Arbeiten aus den Jahren 2018 – 2019 an Dutzenden von Personen über Dutzende von Videos gezeigt (vgl. Bilddatensätze 100k++). Für die beste Modellierung in diesem Rahmen ist multimodale Information erforderlich, idealerweise von Sensoren wie Altimeter, Thermometer, Mikrofonaufnahmen usw.
Massenverhalten
Das am weitesten entwickelte Gebiet, da die Auftraggeber die UNO und viele Staaten sind. Überwachungskameras, Daten von Mobilfunkmasten – Abrechnung, SMS, Anrufe, Daten über Bewegungen zwischen den Grenzen der Staaten – all dies gibt ein sehr zuverlässiges Bild über die Bewegungen von Menschenströmen und soziale Unruhen. Potenzielle Anwendungen der Technologie: Optimierung von Rettungsoperationen, Unterstützung und rechtzeitige Evakuierung der Bevölkerung bei Notfällen. Die verwendeten Modelle sind bisher meist schlecht interpretierbar – es handelt sich um verschiedene LSTM- und Convolutional-Netzwerke. Es gab eine kurze Anmerkung, dass die UNO ein neues Gesetz lobbyiert, das europäische Unternehmen verpflichtet, anonymisierte Daten, die für jegliche Forschungen erforderlich sind, zu teilen.
„Von System 1 zu System 2 Deep Learning“, Yoshua Bengio
In der Vorlesung von Yoshua Bengio trifft Deep Learning auf Neurowissenschaften auf der Ebene der Zielsetzung.
Bengio hebt zwei Haupttypen von Aufgaben nach der Methodologie des Nobelpreisträgers Daniel Kahneman hervor (Buch „» )
Typ 1 – System 1, unbewusste Handlungen, die wir „automatisch“ ausführen (das alte Gehirn): Autofahren auf vertrauten Strecken, Gehen, Gesichtserkennung.
Typ 2 — System 2, bewusstes Handeln (Großhirnrinde), Zielsetzung, Analyse, Denken, komplexe Aufgaben.
KI erreicht bisher nur in Aufgaben des ersten Typs ausreichende Höhen — während unser Ziel darin besteht, sie zum zweiten zu führen, indem wir sie lehren, multidisziplinäre Operationen durchzuführen und mit Logik sowie hochrangigen kognitiven Fähigkeiten zu operieren.
Zur Erreichung dieses Ziels wird vorgeschlagen:
- In NLP-Aufgaben attention als Schlüsselmechanismus zur Modellierung des Denkens zu verwenden.
- Meta-Learning und Representation Learning für ein besseres Modellieren der Merkmale zu nutzen, die das Bewusstsein beeinflussen, und deren Lokalisierung – um auf dieser Basis zu hochrangigen Konzepten überzuleiten.
Statt eines Schlusses hinterlassen wir eine Aufzeichnung des eingeladenen Vortrags: Bengio ist einer von vielen Wissenschaftlern, die versuchen, das Gebiet des ML über Optimierungsprobleme, SOTA und neue Architekturen hinaus zu erweitern.
Die Frage bleibt offen, inwieweit die Verbindung von Problemen des Bewusstseins, dem Einfluss der Sprache auf das Denken, der Neurowissenschaft und Algorithmen das ist, was uns in Zukunft erwartet und uns zu Maschinen führen wird, die "denken" wie Menschen.
Danke!

Quelle: habr.com
