

In diesem Artikel werden wir über funktionale Abhängigkeiten in Datenbanken sprechen – was sie sind, wo sie angewendet werden und welche Algorithmen es zu ihrer Erkennung gibt.
Wir betrachten funktionale Abhängigkeiten im Kontext von relationalen Datenbanken. Grob gesagt werden in solchen Datenbanken Informationen in Form von Tabellen gespeichert. Im Folgenden verwenden wir ungefähre Begriffe, die in der strengen relationalen Theorie nicht austauschbar sind: Die Tabelle selbst nennen wir Relation, die Spalten – Attribute (deren Menge – das Schema der Relation), und die Menge der Werte einer Zeile über eine Teilmenge von Attributen – ein Tupel.
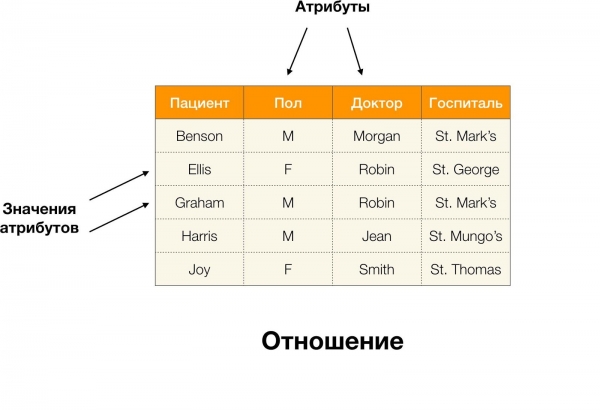
Zum Beispiel, in der obigen Tabelle, (Benson, M, M organ) ist ein Tupel über die Attribute (Patient, Geschlecht, Arzt).
Formell wird dies wie folgt notiert:  [Patient, Geschlecht, Arzt] = (Benson, M, M organ).
[Patient, Geschlecht, Arzt] = (Benson, M, M organ).
Nun können wir das Konzept der funktionalen Abhängigkeit (FÄ) einführen:
Definition 1. Eine Relation R erfüllt die FÄ X → Y (wobei X, Y ⊆ R) genau dann, wenn für alle Tupel  ,
,  ∈ R gilt: wenn
∈ R gilt: wenn  [X] =
[X] =  [X], dann
[X], dann  [Y ] =
[Y ] =  [Y ]. In diesem Fall sagt man, dass X (Determinante oder definierende Menge von Attributen) funktional Y (abhängige Menge) bestimmt.
[Y ]. In diesem Fall sagt man, dass X (Determinante oder definierende Menge von Attributen) funktional Y (abhängige Menge) bestimmt.
Mit anderen Worten, das Vorhandensein von FZ X → Y bedeutet, dass, wenn wir zwei Tupel in R haben und sie in den Attributen übereinstimmen X, sie auch in den Attributen übereinstimmen werden. Y.
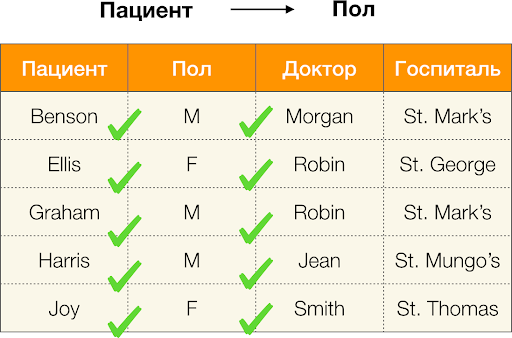
Nun der Reihe nach. Lassen Sie uns die Attribute betrachten Patient und Geschlecht für die wir herausfinden möchten, ob es Abhängigkeiten zwischen ihnen gibt oder nicht. Für eine solche Menge von Attributen können folgende Abhängigkeiten bestehen:
- Patient → Geschlecht
- Geschlecht → Patient
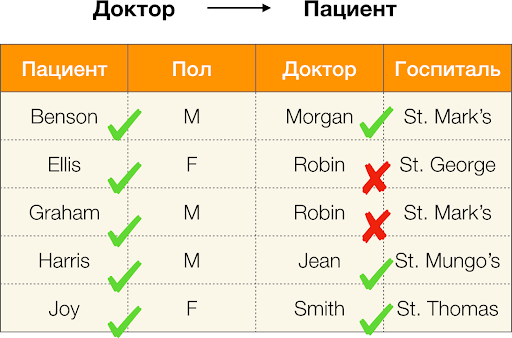
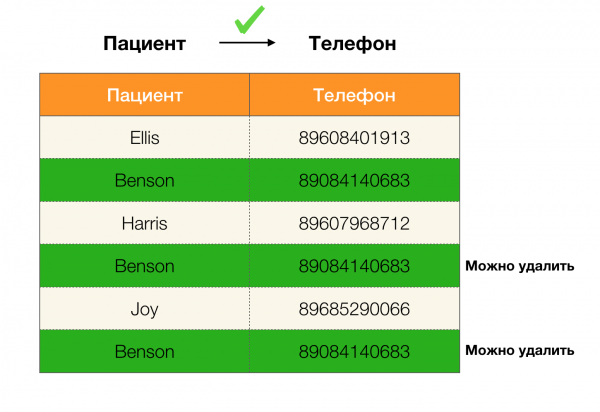
Laut der obigen Definition muss, damit die erste Abhängigkeit besteht, jedem einzigartigen Wert der Spalte Patient nur ein Wert der anderen Spalte entsprechen. Geschlecht. Und für die Beispieltabelle ist dies tatsächlich der Fall. Allerdings funktioniert dies nicht in umgekehrter Richtung, das heißt, die zweite Abhängigkeit wird nicht erfüllt, und das Attribut Geschlecht ist kein Determinant für Patienten.Ähnlich, wenn man die Abhängigkeit betrachtet Arzt → Patient, kann man feststellen, dass sie verletzt wird, da der Wert Robin für dieses Attribut mehrere unterschiedliche Werte hat — Ellis und Graham..
Funktionale Abhängigkeiten ermöglichen es, die bestehenden Verbindungen zwischen Gruppen von Attributen einer Tabelle zu bestimmen. Daher werden wir in Zukunft die interessantesten Zusammenhänge betrachten, insbesondere solche X → Y, die folgende Eigenschaften aufweisen:
- non-trivial sind, das heißt, die rechte Seite der Abhängigkeit ist kein Teil der linken Seite (Y ̸⊆ X);
- minimal sind, was bedeutet, dass es keine solche Abhängigkeit gibt Z → Y, dass Z ⊂ X.
Die bisher betrachteten Abhängigkeiten waren strikt, das heißt, sie erlaubten keinerlei Abweichungen in der Tabelle. Neben diesen gibt es jedoch auch solche, die eine gewisse Inkonsistenz zwischen den Werten der Tupel zulassen. Diese Abhängigkeiten werden in eine eigene Klasse eingeordnet, als angenäherte Abhängigkeiten bezeichnet und dürfen bei einer bestimmten Anzahl von Tupeln verletzt werden. Diese Anzahl wird durch den maximalen Fehlerwert emax geregelt. Zum Beispiel der Fehleranteil  = 0,01 kann bedeuten, dass die Abweichung bei 1 % der vorhandenen Tupel in der betrachteten Attributmenge auftreten kann. Das heißt, bei 1000 Datensätzen könnten maximal 10 Tupel gegen das Gesetz verstoßen. Wir werden jedoch eine etwas andere Metrik betrachten, die auf paarweise unterschiedlichen Werten der verglichenen Tupel basiert. Für die Abhängigkeit X → Y im Verhältnis r wird sie so berechnet:
= 0,01 kann bedeuten, dass die Abweichung bei 1 % der vorhandenen Tupel in der betrachteten Attributmenge auftreten kann. Das heißt, bei 1000 Datensätzen könnten maximal 10 Tupel gegen das Gesetz verstoßen. Wir werden jedoch eine etwas andere Metrik betrachten, die auf paarweise unterschiedlichen Werten der verglichenen Tupel basiert. Für die Abhängigkeit X → Y im Verhältnis r wird sie so berechnet:

Berechnen wir den Fehler für Arzt → Patient das obige Beispiel. Wir haben zwei Tupel, deren Werte sich im Attribut Patient, aber im Übereinstimmen:  [Arzt, Patient] = (Robin, Ellis) und
[Arzt, Patient] = (Robin, Ellis) und  [Arzt, Patient] = (Robin, Graham). So wie es in der Fehlerdefinition steht, müssen wir alle konfliktierenden Paare berücksichtigen, was bedeutet, dass es zwei solche Paare geben wird: (
[Arzt, Patient] = (Robin, Graham). So wie es in der Fehlerdefinition steht, müssen wir alle konfliktierenden Paare berücksichtigen, was bedeutet, dass es zwei solche Paare geben wird: ( ,
,  ) und ihre Inversion (
) und ihre Inversion ( ,
,  ). Setzen wir dies in die Formel ein und erhalten:
). Setzen wir dies in die Formel ein und erhalten:

Nun wollen wir die Frage beantworten: „Und wozu das alles?“. Tatsächlich gibt es verschiedene Arten von Abhängigkeiten. Der erste Typ sind solche Abhängigkeiten, die vom Administrator in der Entwurfsphase der Datenbank festgelegt werden. Diese sind in der Regel wenige, streng und ihr Hauptanwendungsbereich ist die Normalisierung der Daten und das Design des Beziehungsschemas.
Der zweite Typ sind Abhängigkeiten, die "versteckte" Daten und zuvor unbekannte Verbindungen zwischen Attributen darstellen. Das heißt, solche Abhängigkeiten wurden beim Design nicht berücksichtigt und werden erst anhand des bestehenden Datensatzes gefunden, um darauf basierend durch die Vielzahl entdeckter funktionaler Abhängigkeiten (FZ) Rückschlüsse auf die gespeicherten Informationen zu ziehen. Genau mit solchen Abhängigkeiten arbeiten wir. Ein ganzes Feld des Data Mining beschäftigt sich damit, verschiedene Techniken zur Auffindung und basierend darauf entwickelte Algorithmen zu nutzen. Lassen Sie uns untersuchen, wie die gefundenen funktionalen Abhängigkeiten (sowohl exakte als auch angenäherte) in bestimmten Daten nützlich sein können.

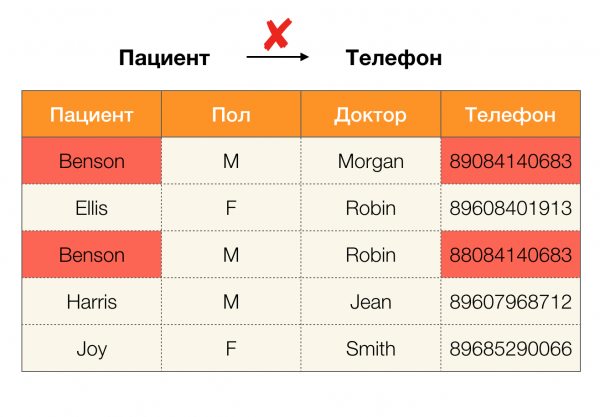
Heute sind die Hauptanwendungsbereiche von Abhängigkeiten die Datenbereinigung. Sie umfasst die Entwicklung von Prozessen zur Identifizierung "schmutziger Daten" und deren anschließender Korrektur. Zu den typischen Beispielen für "schmutzige Daten" gehören Duplikate, Datenfehler oder Tippfehler, fehlende Werte, veraltete Daten, überflüssige Leerzeichen und Ähnliches.
Beispiel für einen Datenfehler:
Beispiel für Duplikate in Daten:
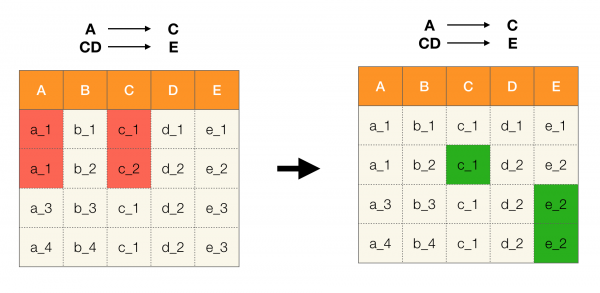
Zum Beispiel haben wir eine Tabelle und eine Reihe von Anforderungen, die erfüllt werden müssen. Die Datenbereinigung in diesem Fall bedeutet, die Daten so zu ändern, dass die Anforderungen korrekt eingehalten werden. Dabei sollte die Anzahl der Modifikationen minimal sein (für dieses Verfahren gibt es spezifische Algorithmen, auf die wir in diesem Artikel nicht eingehen werden). Unten sehen Sie ein Beispiel für eine solche Datenumwandlung. Links befindet sich die ursprüngliche Beziehung, in der offensichtlich die erforderlichen Anforderungen nicht erfüllt sind (ein Beispiel für einen Verstoß gegen eine der Anforderungen ist rot hervorgehoben). Rechts sehen Sie die aktualisierte Beziehung, in der die grünen Zellen die geänderten Werte anzeigen. Nach Durchführung dieses Verfahrens wurden die erforderlichen Abhängigkeiten nun eingehalten.
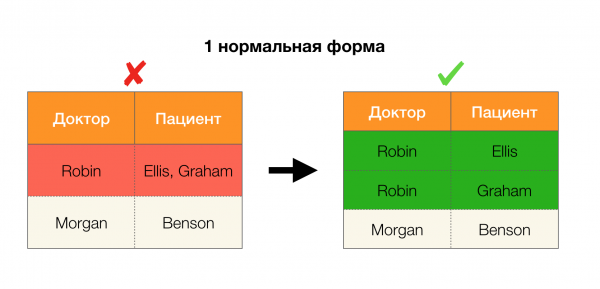
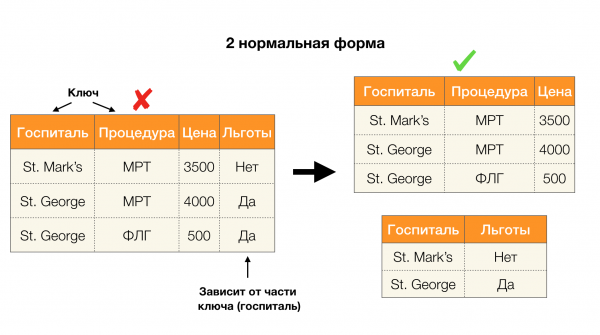
Ein weiterer beliebter Anwendungsbereich ist das Design von Datenbanken. Hier sollte man auf die Normalformen und die Normalisierung hinweisen. Die Normalisierung ist der Prozess, eine Relation gemäß einem bestimmten Satz von Anforderungen zu gestalten, die jeweils durch eine Normalform definiert werden. Wir werden die Anforderungen der verschiedenen Normalformen nicht im Detail behandeln (dies wird in jedem Einführungsbuch über Datenbanken erklärt), sondern nur anmerken, dass jede von ihnen das Konzept der funktionalen Abhängigkeiten auf ihre Weise verwendet. Diese Abhängigkeiten sind im Wesentlichen Integritätsbedingungen, die bei der Planung einer Datenbank berücksichtigt werden (im Kontext dieser Aufgabe werden sie manchmal als Super-Schlüssel bezeichnet).
Betrachten wir ihre Anwendung auf vier Normalformen in der Abbildung unten. Erinnern wir uns, dass die Boyce-Codd-Normalform strenger als die dritte Form, aber weniger streng als die vierte ist. Letztere möchten wir vorerst nicht betrachten, da ihr Verständnis mehrwertige Abhängigkeiten erfordert, die in diesem Artikel nicht im Fokus stehen.
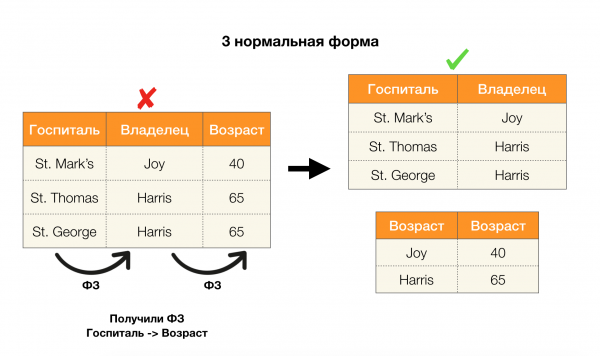
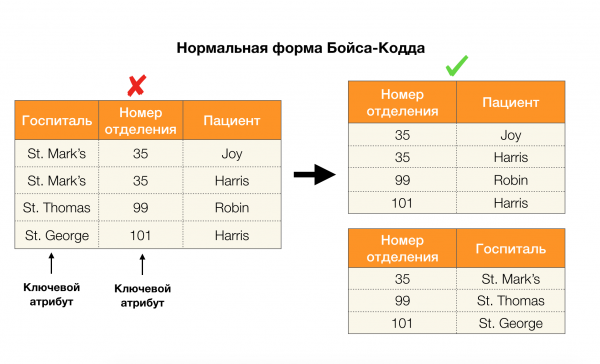
Ein weiteres Anwendungsgebiet, in dem Abhängigkeiten genutzt werden, ist die Dimensionsreduktion von Merkmalsräumen in Aufgaben wie dem Aufbau eines naiven bayesischen Klassifikators, der Identifizierung signifikanter Merkmale und der Neuparametrisierung von Regressionsmodellen. In den Originalartikeln wird diese Aufgabe als Bestimmung überflüssiger Merkmale (feature redundancy) und relevanter Merkmale (feature relevancy) bezeichnet [5, 6], und sie wird unter aktiver Nutzung von Konzepten aus der Datenbanktechnik gelöst. Mit dem Aufkommen solcher Arbeiten können wir sagen, dass es heutzutage einen Bedarf an Lösungen gibt, die Datenbanken, Analytik und die Umsetzung der genannten Optimierungsprobleme in einem Werkzeug vereinen [7, 8, 9].
Für die Suche nach FZ in Datensätzen gibt es zahlreiche Algorithmen (sowohl moderne als auch ältere). Diese Algorithmen lassen sich in drei Gruppen unterteilen:
- Algorithmen, die algebraische Gitterdurchläufe nutzen (Lattice traversal algorithms)
- Algorithmen, die auf der Suche nach übereinstimmenden Werten basieren (Difference- and agree-set algorithms)
- Algorithmen, die auf paarweisen Vergleichen basieren (Dependency induction algorithms)
Eine kurze Beschreibung der verschiedenen Algorithmustypen finden Sie in der folgenden Tabelle:
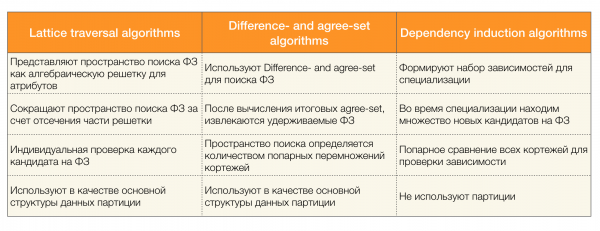
Mehr über diese Klassifikation können Sie [4] nachlesen. Im Folgenden finden Sie Beispiele für Algorithmen jeder Kategorie:
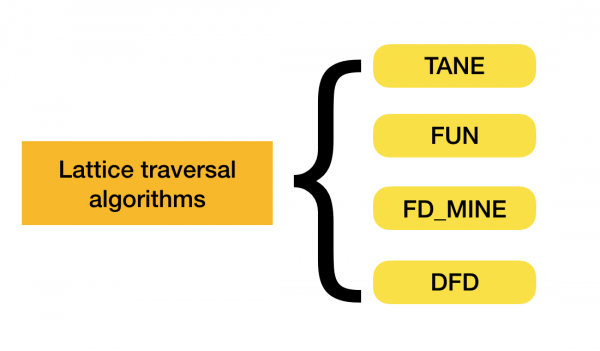
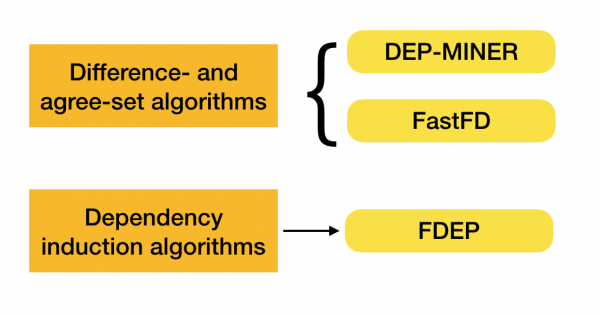
Derzeit entstehen neue Algorithmen, die mehrere Ansätze zur Suche nach funktionalen Abhängigkeiten kombinieren. Beispiele für solche Algorithmen sind Pyro [2] und HyFD [3]. Eine detaillierte Analyse ihrer Funktionsweise ist in den folgenden Artikeln dieser Reihe geplant. In diesem Artikel werden wir zunächst die grundlegenden Konzepte und das Lemma besprechen, die für das Verständnis der Abhängigkeitsidentifikation erforderlich sind.
Beginnen wir mit den einfachen Begriffen – dem difference-set und dem agree-set, die im zweiten Typ der Algorithmen verwendet werden. Das Difference-set ist eine Menge von Tupeln, die sich in ihren Werten unterscheiden, während das agree-set im Gegenteil – Tupel mit übereinstimmenden Werten enthält. Es ist erwähnenswert, dass wir in diesem Fall nur den linken Teil der Abhängigkeit betrachten.
Ein weiteres wichtiges Konzept, das zuvor erwähnt wurde, ist die algebraische Gitterstruktur. Da viele moderne Algorithmen mit diesem Konzept arbeiten, müssen wir ein Verständnis dafür haben, was es bedeutet.
Um das Konzept einer Gitterstruktur einzuführen, ist eine Definition einer teilweise geordneten Menge (oder partially ordered set, kurz poset) erforderlich.
Definition 2. Eine Menge S wird als teilweise geordnet mit der binären Relation ⩽ bezeichnet, wenn die folgenden Eigenschaften für alle a, b, c ∈ S erfüllt sind:
- Reflexivität, d. h. a ⩽ a
- Antisymmetrie, d. h., wenn a ⩽ b und b ⩽ a, dann ist a = b
- Transitivität, d. h. aus a ⩽ b und b ⩽ c folgt, dass a ⩽ c
Eine solche Relation wird als (nicht-strenge) partielle Ordnung bezeichnet, und die Menge selbst ist eine teilweise geordnete Menge. Formelle Bezeichnung: ⟨S, ⩽⟩.
Ein einfaches Beispiel für eine teilweise geordnete Menge ist die Menge aller natürlichen Zahlen N mit der üblichen Ordnungsrelation ⩽. Es ist nicht schwer zu überprüfen, dass alle notwendigen Axiome erfüllt sind.
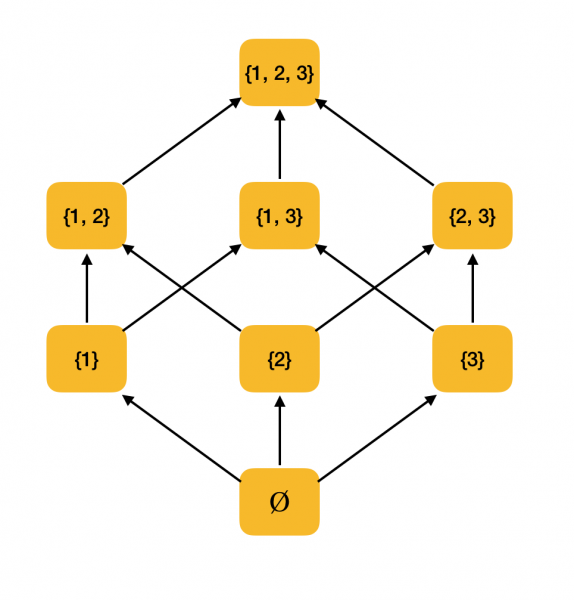
Ein anschauliches Beispiel: Betrachten wir die Menge aller Teilmengen {1, 2, 3}, geordnet durch die Inklusionsbeziehung ⊆. Tatsächlich erfüllt diese Beziehung alle Bedingungen einer partiellen Ordnung, daher ist ⟨P ({1, 2, 3}), ⊆⟩ eine teilweise geordnete Menge. Die Struktur dieser Menge ist im folgenden Diagramm dargestellt: Wenn von einem Element aus durch Pfeile ein anderes Element erreicht werden kann, stehen sie in einer Ordungsrelation.
Wir benötigen noch zwei grundlegende Definitionen aus der Mathematik – das Supremum und das Infimum.
Definition 3. Sei ⟨S, ⩽⟩ eine teilweise geordnete Menge, A ⊆ S. Eine obere Schranke von A ist ein Element u ∈ S, so dass gilt: ∀x ∈ S: x ⩽ u. Sei U die Menge aller oberen Schranken von S. Wenn in U das kleinste Element existiert, wird es als Supremum bezeichnet und mit sup A notiert.
Analog wird das Konzept der exakten unteren Schranke eingeführt.
Definition 4. Sei ⟨S, ⩽⟩ eine teilweise geordnete Menge, A ⊆ S. Eine untere Schranke von A ist ein Element l ∈ S, so dass gilt: ∀x ∈ S: l ⩽ x. Sei L die Menge aller unteren Schranken von S. Wenn in L das größte Element existiert, wird es als Infimum bezeichnet und mit inf A notiert.
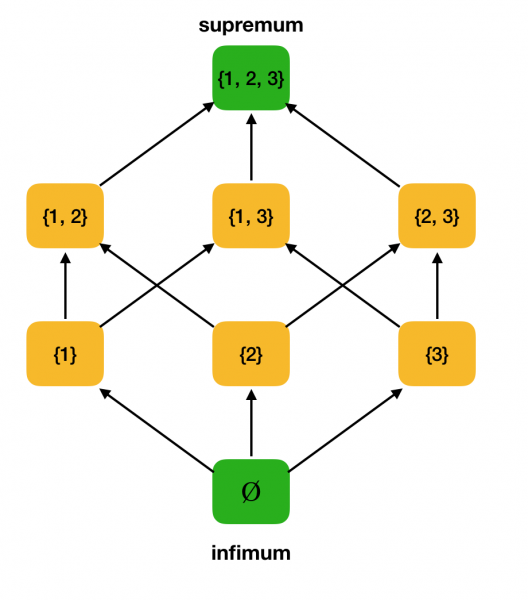
Betrachten wir als Beispiel die oben angegebene teilweise geordnete Menge ⟨P ({1, 2, 3}), ⊆⟩ und finden darin das Supremum und Infimum.
Nun können wir die Definition einer algebraischen Hülle formulieren.
Definition 5. Sei ⟨P, ⩽⟩ eine teilweise geordnete Menge, sodass jede zweielementige Teilmenge exakte obere und untere Schranken hat. Dann wird P als algebraische Hülle bezeichnet. Dabei wird sup{x, y} als x ∨ y und inf {x, y} als x ∧ y geschrieben.
Überprüfen wir, ob unser Arbeitsbeispiel ⟨P ({1, 2, 3}), ⊆⟩ eine Hülle ist. In der Tat, für alle a, b ∈ P ({1, 2, 3}), gilt a∨b = a∪b und a∧b = a∩b. Betrachten wir beispielsweise die Mengen {1, 2} und {1, 3} und finden deren Infimum und Supremum. Wenn wir sie schneiden, erhalten wir die Menge {1}, die das Infimum darstellt. Das Supremum ergibt sich aus ihrer Vereinigung — {1, 2, 3}.
In den Algorithmen zur Erkennung von Abhängigkeiten wird der Suchraum häufig in Form einer Hülle dargestellt, wobei Mengen aus einem Element (verstanden als die erste Ebene der Suchhülle, in der die linke Seite der Abhängigkeiten aus einem Attribut besteht) jedes Attribut der ursprünglichen Relation repräsentieren.
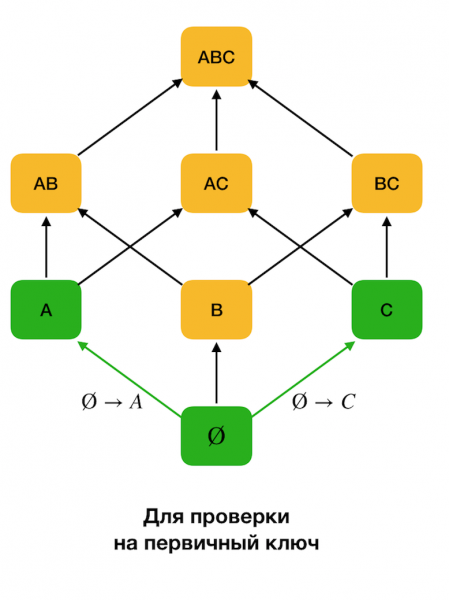
Zu Beginn werden Abhängigkeiten der Form ∅ → betrachtet. Einzelattribut. Dieser Schritt ermöglicht es, die Primärschlüsselattribute zu bestimmen (für solche Attribute gibt es keine Determinanten, sodass die linke Seite leer bleibt). Anschließend bewegen sich solche Algorithmen nach oben auf dem Gitter. Dabei ist zu beachten, dass das Gitter nicht vollständig durchlaufen werden muss. Wenn man also die gewünschte maximale Größe der linken Seite angibt, wird der Algorithmus nicht über diese Größenebene hinaus fortfahren.
Die Abbildung unten zeigt, wie man ein algebraisches Gitter zur Lösung der FZ-Aufgabe verwenden kann. Hier stellt jede Kante (X, XY) eine Abhängigkeit dar X → Y. Zum Beispiel haben wir die erste Ebene passiert und wissen, dass die Abhängigkeit gehalten wird A → B (wir stellen dies durch eine grüne Verbindung zwischen den Knoten dar A und B). Das bedeutet, wenn wir weiter nach oben im Gitter voranschreiten, können wir die Abhängigkeit A, C → Bnicht überprüfen, da sie bereits nicht minimal wäre. Ähnlich würden wir sie nicht überprüfen, wenn die Abhängigkeit C → B.
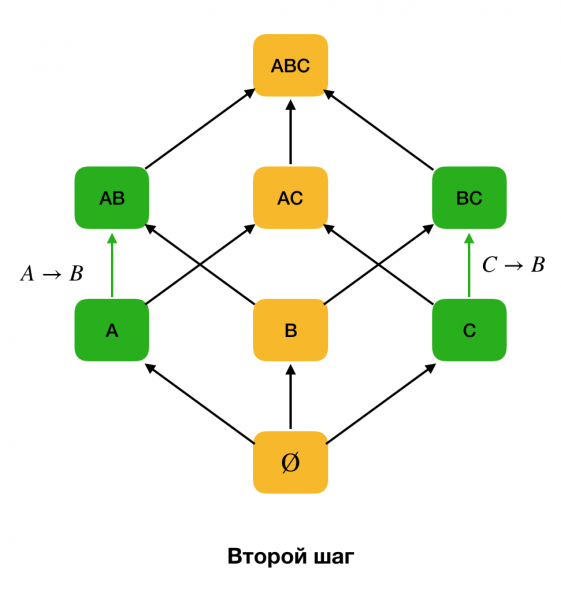
Darüber hinaus verwenden nahezu alle modernen Algorithmen zur Suche nach FZ eine Datenstruktur namens Partition (im Original – stripped partition [1]). Die formale Definition einer Partition lautet wie folgt:
Definition 6. Sei X ⊆ R eine Menge von Attributen für die Relation r. Ein Cluster besteht aus einer Menge von Indizes von Tupeln aus r, die für X denselben Wert haben, d.h. c(t) = {i|ti[X] = t[X]}. Eine Partition ist eine Menge von Clustern, die Cluster mit einer Länge von eins ausschließt:

Einfach ausgedrückt, ist eine Partition für das Attribut X eine Menge von Listen, wobei jede Liste die Zeilennummern mit denselben Werten für Xenthält. In der modernen Literatur wird die Struktur, die Partitionen darstellt, als position list index (PLI) bezeichnet. Cluster mit einer Länge von eins werden zum Zweck der Kompression von PLI ausgeschlossen, da dies Cluster sind, die nur die Nummer eines Eintrags mit einem einzigartigen Wert enthalten, der immer leicht festgestellt werden kann.
Betrachten wir ein Beispiel. Kehren wir erneut zur Tabelle mit den Patienten zurück und erstellen wir Partitionen für die Spalten Patient und Geschlecht (es ist eine neue Spalte links hinzugekommen, in der die Zeilennummern der Tabelle markiert sind):
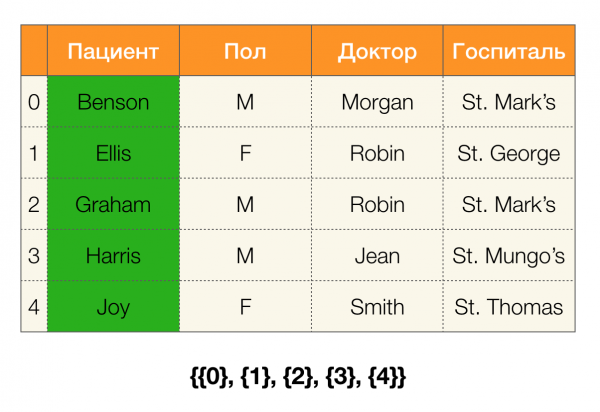
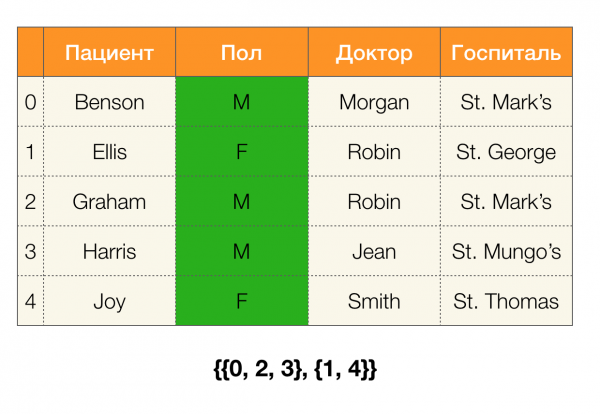
Laut Definition ist die Partition für die Spalte Patient tatsächlich leer, da einzelne Cluster von der Partition ausgeschlossen werden.
Partitionen können anhand mehrerer Attribute erstellt werden. Dafür gibt es zwei Möglichkeiten: Entweder durch das Durchlaufen der Tabelle, um die Partition direkt für alle erforderlichen Attribute zu erstellen, oder durch die Erstellung einer Partition mittels der Schnittoperation zwischen den Partitionen eines Teilmengenattributs. Die Suche-Algorithmen verwenden die zweite Variante.
Einfach ausgedrückt, um beispielsweise eine Partition für die Spalten ABC, zu erhalten, können die Partitionen für AC und B (oder jede andere Auswahl von nicht überlappenden Teilmengen) genommen und untereinander geschnitten werden. Die Schnittoperation zwischen zwei Partitionen hebt die längsten Cluster hervor, die für beide Partitionen gemeinsam sind.
Betrachten wir ein Beispiel:
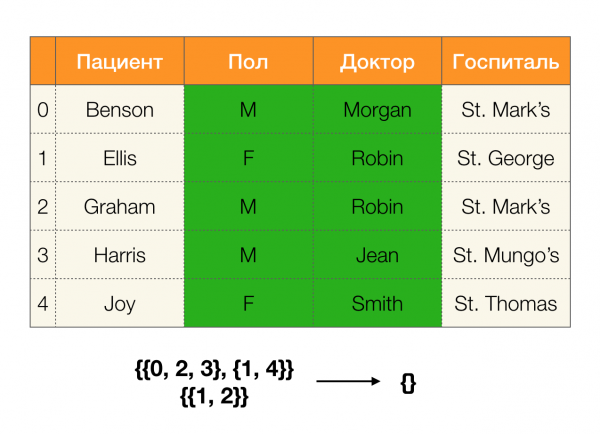

Im ersten Fall haben wir eine leere Partition erhalten. Wenn wir die Tabelle näher betrachten, stellen wir fest, dass es in der Tat keine identischen Werte in den beiden Attributen gibt. Wenn wir jedoch die Tabelle ein wenig modifizieren (rechts abgebildeter Fall), erhalten wir eine nicht leere Schnittmenge. Dabei enthalten die Zeilen 1 und 2 tatsächlich identische Werte in den Attributen. Geschlecht und Doktor.
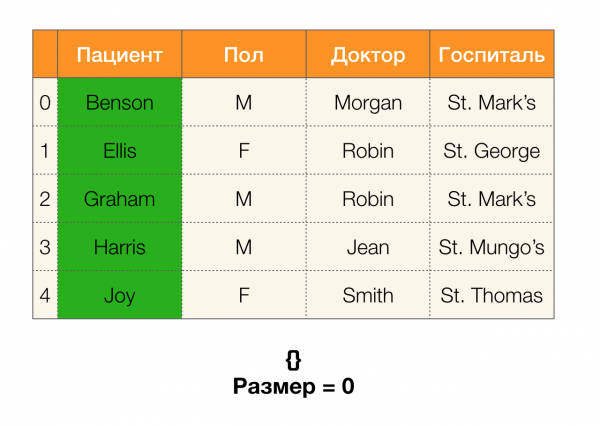
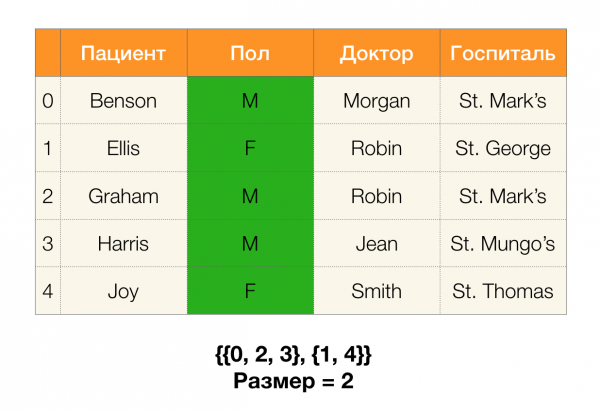
Als Nächstes benötigen wir das Konzept der Partitiongröße. Formal gesagt:

Einfach ausgedrückt, die Partitiongröße ist die Anzahl der Cluster, die in die Partition fallen (denken Sie daran, dass einzelne Cluster nicht in die Partition gehören!):
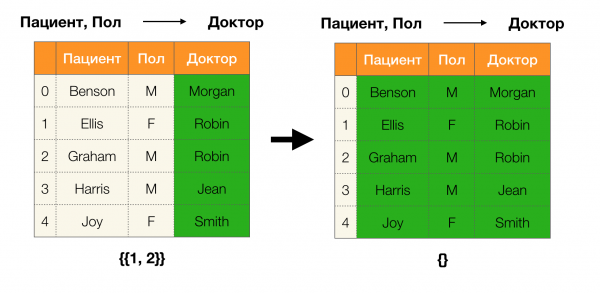
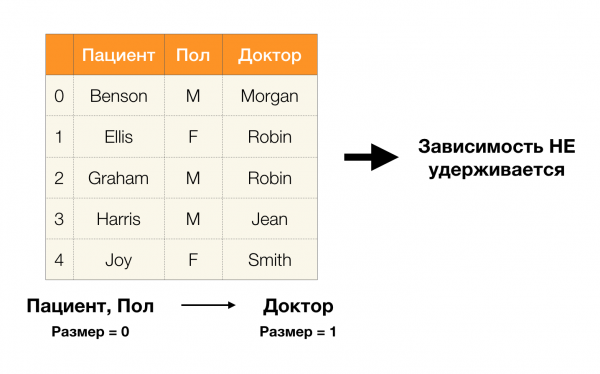
Nun können wir eine der entscheidenden Lemmata definieren, die es für gegebene Partitionen ermöglichen zu bestimmen, ob die Abhängigkeit aufrechterhalten wird oder nicht:
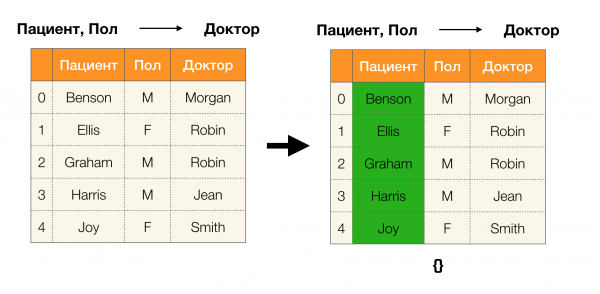
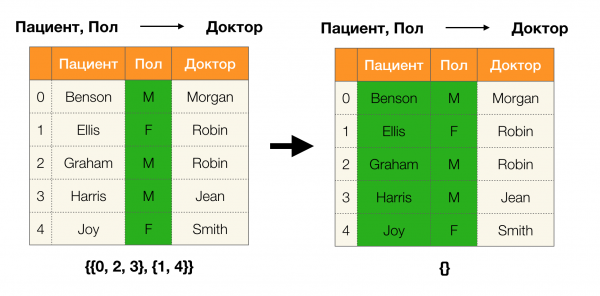
Lemma 1. Eine Abhängigkeit A, B → C wird aufrechterhalten, wenn und nur wenn

Laut dem Lemma sind vier Schritte erforderlich, um zu bestimmen, ob die Abhängigkeit aufrechterhalten wird:
- Berechnen Sie die Partition für die linke Seite der Abhängigkeit
- Berechnen Sie die Partition für die rechte Seite der Abhängigkeit
- Berechnen Sie das Produkt der ersten beiden Schritte
- Vergleichen Sie die Größen der Partitionen, die in Schritt eins und Schritt drei ermittelt wurden
Nachfolgend finden Sie ein Beispiel, um zu überprüfen, ob die Abhängigkeit gemäß diesem Lemma aufrechterhalten wird:
In diesem Artikel haben wir Konzepte wie funktionale Abhängigkeit und angenäherte funktionale Abhängigkeit erörtert, ihre Anwendungsbereiche untersucht und verschiedene Algorithmen zur Suche nach funktionalen Abhängigkeiten vorgestellt. Zudem haben wir grundlegende, aber wichtige Begriffe detailliert behandelt, die in modernen Algorithmen zur Suche nach funktionalen Abhängigkeiten aktiv verwendet werden.
Literaturverweise:
- Huhtala Y. et al. TANE: Ein effizienter Algorithmus zur Entdeckung funktionaler und approximierter Abhängigkeiten // The Computer Journal. – 1999. – Bd. 42. – Nr. 2. – S. 100-111.
- Kruse S., Naumann F. Effiziente Entdeckung approximierter Abhängigkeiten // Proceedings of the VLDB Endowment. – 2018. – Bd. 11. – Nr. 7. – S. 759-772.
- Papenbrock T., Naumann F. Ein hybrider Ansatz zur Entdeckung funktionaler Abhängigkeiten // Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – S. 821-833.
- Papenbrock T. et al. Entdeckung funktionaler Abhängigkeiten: Eine experimentelle Evaluierung von sieben Algorithmen // Proceedings of the VLDB Endowment. – 2015. – Bd. 8. – Nr. 10. – S. 1082-1093.
- Kumar A. et al. Join oder nicht?: Zweimal über Joins nachdenken vor der Merkmalsauswahl // Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – S. 19-34.
- Abo Khamis M. et al. In-Datenbank-Lernen mit spärlichen Tensoren // Proceedings of the 37th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems. – ACM, 2018. – S. 325-340.
- Hellerstein J. M. et al. Die MADlib-Analysebibliothek: oder MAD-Fähigkeiten, das SQL // Proceedings of the VLDB Endowment. – 2012. – Bd. 5. – Nr. 12. – S. 1700-1711.
- Qin C., Rusu F. Spekulative Näherungen für die verteilte Gradientabstieg-Optimierung im Terascale-Bereich //Proceedings of the Fourth Workshop on Data analytics in the Cloud. – ACM, 2015. – S. 1.
- Meng X. et al. Mllib: Maschinelles Lernen in Apache Spark //The Journal of Machine Learning Research. – 2016. – Bd. 17. – Nr. 1. – S. 1235-1241.
Autoren des Artikels: , Forscherin bei , und , Forscherin bei
Quelle: habr.com
