

La primera API de MySklad apareció hace 10 años. Todo este tiempo hemos estado trabajando en versiones existentes de la API y desarrollando otras nuevas. Y ya se han enterrado varias versiones de la API.
Este artículo contendrá muchas cosas: cómo se creó la API, por qué la necesita el servicio en la nube, qué ofrece a los usuarios, qué errores logramos cometer y qué queremos hacer a continuación.
Mi nombre es Oleg Alekseev , Soy el director técnico y cofundador de MySklad.
¿Por qué crear una API para un servicio?
Nuestros clientes, decenas de miles de empresarios, utilizan activamente soluciones en la nube: banca, tiendas online, contabilidad de productos básicos, CRM. Una vez que te conectas a uno, es difícil detenerlo. Y ahora el quinto, octavo y décimo servicio facilita el trabajo del emprendedor, pero los usuarios transfieren datos entre estos servicios en la nube manualmente. El trabajo se convierte en una pesadilla.
La solución obvia es brindar a los usuarios la posibilidad de transferir datos entre servicios en la nube. Por ejemplo, importe y exporte datos como archivos, que luego se pueden cargar en el servicio deseado. Los archivos suelen modificarse para adaptarse al formato de cada servicio. Se trata de un trabajo manual más o menos sencillo, pero con el aumento del número de estos servicios, resulta cada vez más difícil de realizar.
Por tanto, el siguiente paso es la API. Con él, el servicio en la nube se beneficia del hecho de que conecta varios servicios en un solo punto. El surgimiento de un ecosistema de este tipo atrae a nuevos clientes gracias a las oportunidades adicionales. Un producto con nueva funcionalidad se vuelve más rentable y útil.
Si crea sus propias interfaces de programación, esto atraerá a vendedores externos en forma de programadores que conocen su producto gracias a la API. Comienzan a crear soluciones basadas en la API propuesta y ganan dinero automatizando las tareas de sus clientes.
El sistema de contabilidad MySklad se basa en procesos simples. Lo principal es trabajar con documentos primarios, la capacidad de aceptar y enviar mercancías y recibir informes comerciales basados en documentos primarios. También está la transferencia de datos, por ejemplo a la contabilidad en la nube, y su recepción de sistemas bancarios o puntos de venta. También trabajamos con tiendas online: recibimos información de productos y enviamos información de saldos.
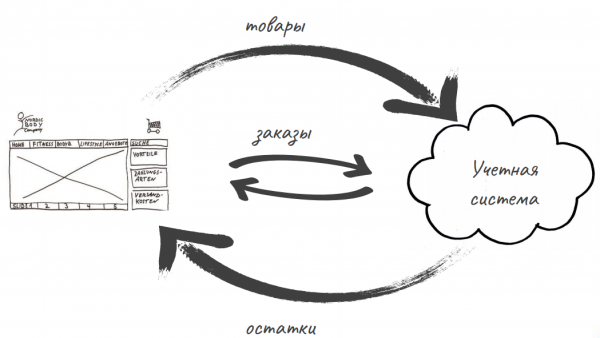
La primera API de MySklad
Durante los 10 años que MySklad trabaja con API, hemos adquirido todo tipo de integraciones que nos permiten intercambiar datos, trabajar con bancos, realizar pagos y utilizar telefonía externa.
Durante el primer año, hicimos posible descargar cualquier dato en formato XML. En aquel entonces, era mucho más claro y común que los usuarios mantuvieran los datos fuera de línea, en lugar de en alguna nube, y se los dimos. La carga se inició mediante exportación manual desde la interfaz. Es decir, todavía no se puede llamar API.
Al mismo tiempo, comenzamos a cooperar con la empresa Rusagro: ya utilizaban un ERP "para adultos" para la planificación de producción y ventas, pero automatizaron la carga de automóviles en las fábricas de MySklad. Así obtuvimos los primeros rudimentos de una API real: el intercambio entre nuestro servicio y el ERP se realizaba mediante el envío de un archivo de gran tamaño con datos de todo tipo de documentos.
Esta es una buena opción para el intercambio de datos por lotes, pero junto con los documentos tuvimos que transferir sus dependencias: información sobre bienes, contratistas y almacenes. Un volcado de este tipo no es tan difícil de generar al exportar, pero es bastante difícil de analizar al importar, ya que toda la información viene en un solo paquete: tanto sobre documentos nuevos como sobre los existentes.
La primera API XML no duró mucho; dos años después comenzamos a reconstruirla. Incluso al comienzo de su trabajo, cometimos varios errores al construir la interfaz del software.

Cómo se creó la API XML: ilustración de uno de nuestros arquitectos. Por cierto, estad atentos a sus artículos.
Aquí están nuestros principales errores:
- El marcado JAXB se realizó directamente en beans de entidad. Usamos Hibernate para comunicarnos con la base de datos y se realizó el marcado JAXB para los mismos beans. Este error apareció casi de inmediato: cualquier actualización de la estructura de datos generaba la necesidad de notificar urgentemente a todos los que utilizan la API o de construir muletas que garantizaran la compatibilidad con la estructura de datos anterior.
- La API creció como un complemento e inicialmente no definimos qué parte del producto era. Ni siquiera pensaron si la API era algo importante, si era necesaria para mantener la compatibilidad con versiones anteriores de sus primeros clientes. En un momento, el número de usuarios de API era aproximadamente el 5% del pequeño número y no se les prestó atención. El filtrado universal realizado en un momento llevó a que nos utilizaran como backend. Este filtrado no era GraphQL en absoluto, sino algo así: funcionó a través de muchos parámetros de cadena de consulta. Con una herramienta tan poderosa, a los usuarios les resultó difícil resistirse y las solicitudes nos fueron transferidas para que fueran enviadas directamente desde la interfaz de usuario de sus tiendas en línea. La situación fue una sorpresa desagradable, porque la prestación de un servicio de este tipo debería requerir precios diferentes y una comprensión generalmente diferente de la API en sí como producto.
- Debido a que la API no se desarrolló como producto principal, la documentación de la API se produjo y publicó de forma residual, mediante ingeniería inversa. Este camino parece bastante simple y conveniente, pero contradice el trabajo bajo contrato. Esto es cuando hay un determinado componente con un esquema de funcionamiento preestablecido. El desarrollador lo implementa de acuerdo con este esquema y tarea, el componente se prueba y el cliente recibe un producto que coincide con la idea del analista. La ingeniería inversa lanza al mercado un producto que simplemente existe: con muletas, soluciones extrañas y bicicletas en lugar de la funcionalidad necesaria.
- Todo el flujo de solicitudes que llegaron a través de la API podría analizarse como nada más que un registro de Nginx o del servidor de aplicaciones. Esto no nos permitió identificar áreas temáticas, excepto quizás por usuarios y suscriptores. Si no hay forma de regular las solicitudes o el registro de clientes, resulta imposible analizar la situación. Este problema tuvo el menor impacto en el desarrollo de la API; se trata más de comprender su relevancia y funcionalidad.
Intento número dos: API REST
En 2010 intentamos crear un sistema de intercambio con contabilidad en línea: BukhSoft. No despegó. Pero durante el proceso de integración apareció una API completa: un servicio de intercambio REST, donde no había libertades como acceder a operaciones en forma de llamadas RPC. Toda la comunicación con la API se llevó al modo estándar para descansar: la línea de consulta contiene el nombre de la entidad y la operación que se realiza con ella se especifica mediante el método http. Agregamos filtrado basado en cuándo se actualizaron las entidades y los usuarios ahora tienen la oportunidad de crear replicación con sus sistemas.
Ese mismo año apareció una API para descargar saldos de almacén e inventario. Las partes más valiosas del sistema están disponibles para los usuarios a través de API: el intercambio de documentos primarios y datos calculados sobre saldos y costos de bienes.
En diciembre de 2015, RetailCRM publicó la primera biblioteca de terceros para acceder a nuestra API. Comenzó a usarse de manera bastante activa, mientras que la popularidad del servicio en su conjunto crecía, la carga en la API crecía más rápido que la carga en la interfaz web. Un día, el crecimiento se convirtió en un aumento de carga.
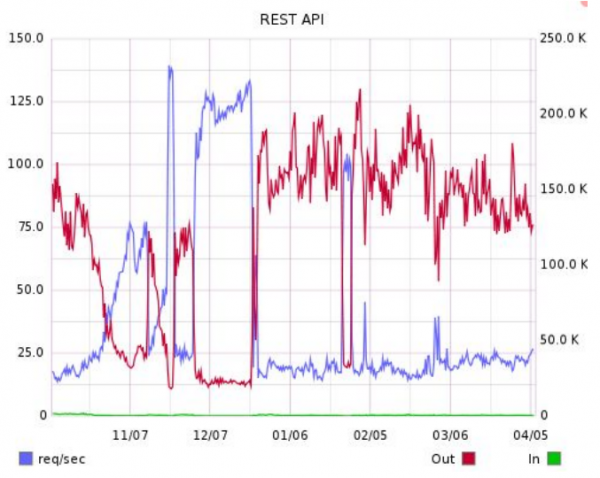
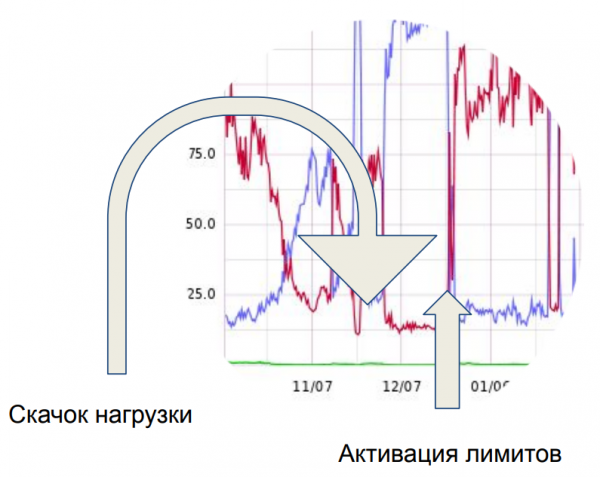
Y este salto, indicado por la flecha de la izquierda, asombró por completo al servidor que sirve nuestra API. Pasamos una semana averiguando qué estaba generando exactamente esta carga. Resultó que estas son las mismas solicitudes transmitidas a nuestra API desde el frente del cliente. Unos 50 clientes comieron de todo. Fue entonces cuando nos dimos cuenta de uno de nuestros errores: la falta total de límites.
Como resultado, introdujimos un límite en la cantidad de solicitudes simultáneas. Ahora es posible abrir no más de dos solicitudes simultáneamente desde una cuenta. Esto es suficiente para trabajar en modo de replicación para el intercambio de datos en modo por lotes. Y aquellos que querían utilizarnos como backend, a partir de ese momento, se vieron obligados a cumplir mejor con las tarifas, ya que introdujeron en su software el trabajo en varias cuentas.
Pongámoslo en orden
Desde 2014, la demanda de la API existente se ha convertido en una parte importante del negocio, y la propia API genera el mayor volumen de datos en el intercambio de datos con los clientes. En 2015, lanzamos un proyecto para limpiar la API. Elegimos JSON en lugar de XML como formato y comenzamos a construirlo en base a las características que se identificaron durante la implementación de la versión anterior:
- Capacidad para gestionar versiones. El control de versiones le permite desarrollar una nueva versión sin afectar la aplicación existente ni interrumpir la experiencia del usuario.
- La capacidad del usuario de ver metadatos en la propia respuesta que recibe.
- Posibilidad de intercambiar documentos de gran tamaño. Si procesamos un documento con más de 4-5 mil posiciones, esto se convierte en un problema para el servidor: una transacción larga, una solicitud http larga. Construimos un mecanismo especial que le permite actualizar un documento en partes y administrar posiciones individuales de este documento enviándolos al servidor.
- Las herramientas de replicación también estaban presentes en la versión anterior.
- Los límites de carga son como un legado del rastrillo que se pisó en la versión anterior. Introdujimos límites en la cantidad de solicitudes en un período de tiempo, la cantidad de solicitudes paralelas y solicitudes de una dirección IP.
Desde entonces, hemos lanzado dos versiones menores de la API y lanzamos varias API especializadas, pero el enfoque general no ha cambiado. El formato de intercambio actualizado y la nueva arquitectura hicieron posible corregir fallas en la API mucho más rápido.
API MySklad hoy
Hoy, la API MySklad resuelve muchos problemas:
- intercambio de datos con tiendas online, sistemas contables, bancos;
- obtener datos e informes calculados;
- Úselo como backend para aplicaciones de clientes: nuestras aplicaciones móviles y la caja registradora de escritorio funcionan a través de API
- enviar notificaciones sobre cambios de datos en MySklad - webhooks;
- telefonía;
- Sistemas de fidelización.
Basado en la API, nuestro CEO Askar Rakhimberdiev en cuatro horas escribí un bot de Telegram que extrae los restos a través de la API:
Ahora números secos.
Aquí están nuestras estadísticas para la antigua API REST:
- 400 empresas;
- 600 usuarios;
- 2 millones de solicitudes por día;
- 200 GB/día de tráfico saliente.
Y esto es lo que se nos ocurrió para todas las API de MySklad:
- Más de 70 integraciones (algunas de ellas se pueden ver aquí). );
- 8500 empresas;
- 12 usuarios;
- 46 millones de solicitudes por día;
- 2 TB/día de tráfico saliente.
¿Qué sigue
Los planes de desarrollo de API se están debatiendo activamente. Intentamos tener en cuenta la experiencia operativa que nos brindan los usuarios. No siempre es posible hacer todo a la vez, pero una nueva versión de la API está a la vuelta de la esquina con metadatos más convenientes y una estructura menos esponjosa, OAuth para autenticación y una API para aplicaciones integradas en la interfaz.
Puedes seguir las novedades en un sitio web especial para desarrolladores de integraciones con MySklad: .
Fuente: habr.com
