


Te enfrentas de nuevo a la tarea de detección de objetos. La prioridad es la velocidad con una precisión aceptable. Tomas la arquitectura YOLOv3 y la reentrenas. La precisión (mAp75) es superior a 0.95. Pero el tiempo de ejecución sigue siendo lento. ¡Maldición!
Hoy omitiremos la cuantización. Pero a continuación veremos... Poda modelo — Eliminar las partes redundantes de la red para acelerar la inferencia sin perder precisión. Esto muestra claramente dónde, cuánto y cómo eliminar. Veremos cómo hacerlo manualmente y dónde se puede automatizar. Al final se incluye un repositorio de Keras.
introducción
En mi anterior trabajo, Macroscop en Perm, desarrollé la costumbre de monitorizar constantemente los tiempos de ejecución de los algoritmos. Los tiempos de ejecución de la red siempre se verifican mediante un filtro de suficiencia. Los datos de última generación en producción normalmente no superan este filtro, lo que me llevó a la poda.
La poda es un tema antiguo que se ha discutido en En 2017. La idea básica es reducir el tamaño de una red neuronal entrenada sin perder precisión mediante la eliminación de varios nodos. Suena interesante, pero rara vez oigo hablar de su uso. Quizás no haya suficientes implementaciones, no existan artículos en ruso o, simplemente, todo el mundo considera la poda un conocimiento especializado y prefiere no compartirlo.
Pero es difícil de averiguar.
Una mirada a la biología
Me encanta cuando las ideas de la biología se incorporan al aprendizaje profundo. Al igual que la evolución, son fiables (¿sabías que ReLU es muy similar a ?)
El proceso de poda de modelos también guarda cierta similitud con la biología. La respuesta de la red en este caso puede compararse con la plasticidad cerebral. El libro incluye un par de ejemplos interesantes. :
- El cerebro de una mujer nacida con solo la mitad del cuerpo se ha reprogramado para realizar las funciones de la mitad faltante.
- El hombre se voló la parte del cerebro responsable de la visión. Con el tiempo, otras partes del cerebro asumieron estas funciones. (No intentaremos repetirlo).
De igual forma, puedes eliminar algunos de los haces más débiles de tu modelo. En caso de necesidad, los haces restantes pueden usarse para reemplazar los que se eliminaron.
¿Te encanta el aprendizaje por transferencia o estás aprendiendo desde cero?
Opción número uno. Estás utilizando aprendizaje por transferencia en YOLOv3, Retina, Mask-RCNN o U-Net. Sin embargo, lo más frecuente es que no necesitemos reconocer 80 clases de objetos, como en COCO. En mi experiencia, suele bastar con 1 o 2 clases. Podría parecer que una arquitectura para 80 clases es excesiva, lo que sugiere que es necesario reducirla. Además, nos gustaría hacerlo sin perder los pesos preentrenados existentes.
Opción número dos. Quizás tengas muchos datos y recursos informáticos, o simplemente necesites una arquitectura súper personalizada. No importa. Pero estás entrenando la red desde cero. El procedimiento habitual consiste en analizar la estructura de los datos, elegir una arquitectura muy potente e implementar dropout para evitar el sobreajuste. He visto valores de dropout de 0.6, Karl.
En ambos casos, la red se puede reducir. Me has motivado. Ahora veamos qué es la poda.
Algoritmo general
Decidimos que podíamos quitar los pliegues. Parece bastante sencillo:
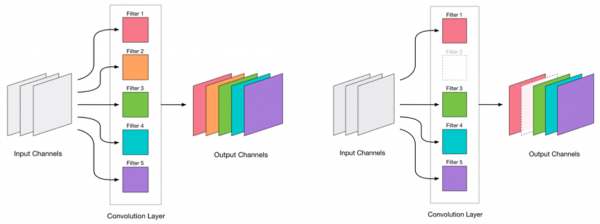
Eliminar cualquier convolución sobrecarga la red, lo que suele provocar un ligero aumento del error. Por un lado, este aumento indica la eficacia de la eliminación de convoluciones (por ejemplo, un aumento considerable indica un error). Sin embargo, un pequeño aumento del error es perfectamente aceptable y a menudo se puede corregir con un reentrenamiento ligero posterior con una tasa de aprendizaje baja. Añadamos un paso de reentrenamiento:
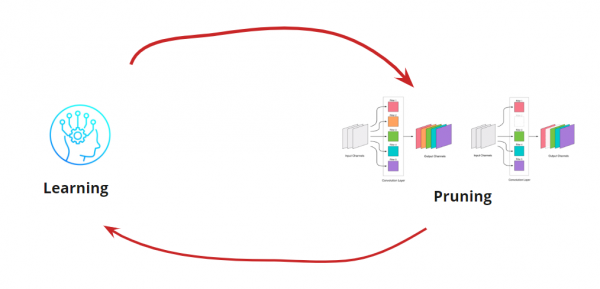
Ahora debemos determinar cuándo queremos detener nuestro ciclo de Aprendizaje-Poda. Pueden darse casos excepcionales, como cuando necesitamos reducir la escala de la red a un tamaño y una frecuencia de ejecución específicos (por ejemplo, para dispositivos móviles). Sin embargo, lo más común es continuar el ciclo hasta que el error supere un valor aceptable. Añadamos la condición:
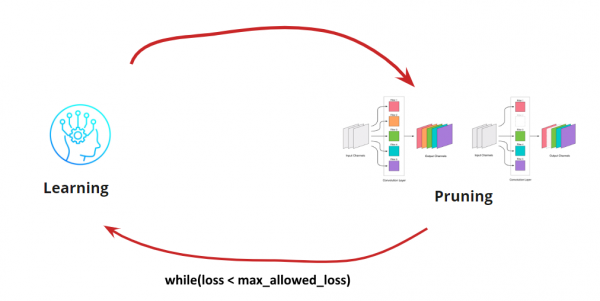
El algoritmo está claro. Ahora veamos cómo determinar qué convoluciones eliminar.
Buscar pliegues eliminables
Necesitamos eliminar algunos paquetes. Eliminarlos todos a la ligera es una mala idea, aunque funcione. Pero si tienes algo de criterio, puedes pensarlo bien e intentar identificar los paquetes más vulnerables para eliminarlos. Hay varias opciones:
- La idea de que las convoluciones con valores de peso pequeños contribuyen poco a la decisión final
- La puntuación L1 más baja, dada la media y la desviación estándar. Complementada con una estimación de la naturaleza de la distribución.
- Detección más precisa de pliegues insignificantes, pero requiere mucho tiempo y recursos.
- Otros
Cada opción tiene sus propias consideraciones de viabilidad e implementación. Aquí, consideraremos la opción con la puntuación L1 más baja.
Proceso manual para YOLOv3
La arquitectura original contiene bloques residuales. Si bien son muy útiles para redes profundas, resultan un tanto engorrosos. La dificultad radica en que no podemos eliminar las comparaciones con diferentes índices en estas capas.
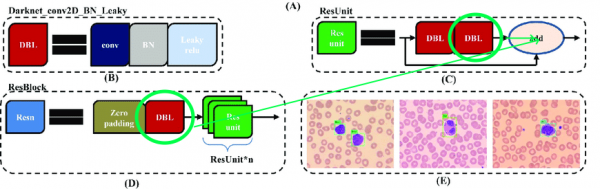
Por lo tanto, seleccionemos las capas de las que podemos eliminar libremente las reconciliaciones:

Ahora vamos a crear un ciclo de trabajo:
- Descarga de activaciones
- Vamos a averiguar cuánto recortar.
- Cortamos
- Estudiamos 10 épocas con LR=1e-4
- Prueba
El desdoblamiento de pliegues es útil para evaluar cuánto se puede eliminar en un paso determinado. Ejemplos de desdoblamiento:
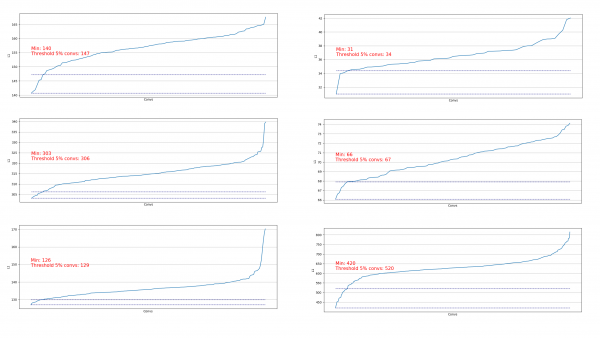
Observamos que, prácticamente en todos los casos, el 5 % de las convoluciones tienen una norma L1 muy baja, por lo que podemos eliminarlas. En cada paso, se repitió esta eliminación y se evaluó qué capas y cuántas se podían eliminar.
Todo el proceso constó de cuatro pasos (los números que se muestran aquí y en todas partes corresponden a la RTX 2060 Super):
| Paso | mAp75 | Número de parámetros, millones | Tamaño de la red, MB | Del original, % | Tiempo de ejecución, ms | condición de circuncisión |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | 5% de todos |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | 5% de todos |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15% para capas con más de 400 convoluciones |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 10% para capas con más de 100 convoluciones |
El paso 2 agregó un efecto positivo: el tamaño del lote 4 se ajustó a la memoria, lo que aceleró significativamente el proceso de reentrenamiento.
En el paso 4, el proceso se detuvo, ya que incluso un entrenamiento adicional a largo plazo no elevó mAp75 a los valores anteriores.
Como resultado, logramos acelerar la inferencia. un 15%reducir tamaño por un 35% y no perder precisión.
Automatización para arquitecturas más simples
Para arquitecturas de red más simples (sin bloques de suma condicional, concatenación y residuales), es muy posible centrarse en procesar todas las capas convolucionales y automatizar el proceso de eliminación de convoluciones.
Implementé esta opción. .
Es sencillo: todo lo que necesitas es una función de pérdida, un optimizador y generadores de lotes:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)Si es necesario, puede cambiar los parámetros de configuración:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}Además, se ha implementado una restricción basada en la desviación estándar. El objetivo es limitar la porción de datos que se eliminará, excluyendo las convoluciones con medidas L1 ya "suficientes":
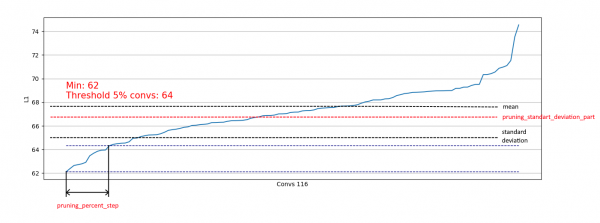
De esta forma, solo permitimos que se eliminen las convoluciones débiles de distribuciones similares a la de la derecha, sin afectar la eliminación de las distribuciones similares a la de la izquierda:

Cuando la distribución se aproxima a la normalidad, el coeficiente pruning_standard_deviation_part se puede seleccionar de:
Recomiendo una tolerancia de 2 sigmas. Como alternativa, puede ignorar esta característica y dejar el valor < 1.0.
La salida es un gráfico del tamaño de la red, la pérdida y el tiempo de ejecución de la red para toda la prueba, normalizados a 1.0. Por ejemplo, aquí el tamaño de la red se redujo casi a la mitad sin ninguna pérdida de calidad (una pequeña red convolucional con 100.000 pesos):
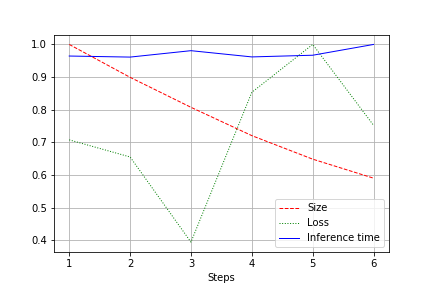
La velocidad de carrera está sujeta a fluctuaciones normales y se ha mantenido prácticamente sin cambios. Esto tiene una explicación:
- El número de convoluciones cambia de valores convenientes (32, 64, 128) a valores no tan convenientes para las tarjetas de vídeo: 27, 51, etc. Podría estar equivocado, pero lo más probable es que esto tenga un efecto.
- La arquitectura no es ancha, pero sí consistente. Al reducir el ancho, mantenemos la profundidad intacta. Esto reduce la carga sin afectar la velocidad.
Por lo tanto, la mejora resultó en una reducción del 20-30% en la carga de CUDA durante la ejecución, pero no en una reducción en el tiempo de ejecución.
resultados
Reflexionemos. Consideramos dos opciones de poda: una para YOLOv3 (que requiere procesamiento manual) y otra para redes con arquitecturas más simples. Es evidente que, en ambos casos, se puede reducir el tamaño de la red y acelerar el proceso sin sacrificar la precisión. Resultados:
- Reduciendo el tamaño
- Ejecución de aceleración
- Reducción de la carga CUDA
- Como resultado, se optimiza el uso futuro de los recursos informáticos, fomentando la sostenibilidad (en algún lugar, uno se siente satisfecho). )
Apéndice
- Tras el paso de poda, también puedes ajustar la cuantización (por ejemplo, con TensorRT).
- TensorFlow proporciona capacidades para . Obras.
- Quiero desarrollarme y agradecería recibir ayuda.
Fuente: habr.com
