

Mikroteenuste arhitektuuril, nagu kõigel siin maailmas, on oma plussid ja miinused. Mõned protsessid muutuvad sellega lihtsamaks, teised raskemaks. Ja muutuste kiiruse ja parema skaleeritavuse nimel peate tooma ohvreid. Üks neist on analüütika muutuv keerukus. Kui monoliidis saab kogu operatiivanalüütika taandada SQL päringuteks analüütiliseks replikaks, siis mitmeteenuselises arhitektuuris on igal teenusel oma andmebaas ja tundub, et ühte päringut ei saa teha (või äkki saab?). Keda huvitab, kuidas me oma ettevõttes operatiivanalüütika probleemi lahendasime ja kuidas selle lahendusega elama õppisime – tere tulemast.

Minu nimi on Pavel Sivash, DomClickis töötan ma meeskonnas, mis vastutab analüütilise andmelao hooldamise eest. Tavapäraselt võib meie tegevust liigitada andmetehnika alla, kuid tegelikult on ülesannete ring palju laiem. Andmetöötluseks on olemas ETL/ELT standard, andmeanalüüsi tööriistade tugi ja kohandamine ning oma tööriistade arendamine. Eelkõige operatiivaruandluse jaoks otsustasime "teeselda", et meil on monoliit ja anda analüütikutele üks andmebaas, mis sisaldab kõiki neile vajalikke andmeid.
Üldiselt kaalusime erinevaid variante. Täisväärtuslik hoidla oli võimalik ehitada - me isegi proovisime, kuid ausalt öeldes ei suutnud me ühendada üsna sagedasi loogikamuudatusi hoidla ehitamise ja muudatuste tegemise üsna aeglase protsessiga (kui kellelgi see õnnestus , kirjutage kommentaaridesse, kuidas). Analüütikutele oli võimalik öelda: “Kutid, õppige pythonit ja minge analüütiliste koopiate juurde,” aga see on värbamisel lisanõue ja tundus, et seda tuleks võimalusel vältida. Otsustasime proovida kasutada FDW (Foreign Data Wrapper) tehnoloogiat: sisuliselt on tegemist standardse dblinkiga, mis on küll SQL standardis, kuid oma palju mugavama liidesega. Selle põhjal tegime lahenduse, mis lõpuks külge sai, ja leppisime sellega. Selle üksikasjad on eraldi artikli teema ja võib-olla rohkem kui üks, sest ma tahan rääkida paljust: andmebaasiskeemide sünkroonimisest juurdepääsu kontrolli ja isikuandmete depersonaliseerimiseni. Samuti tuleb märkida, et see lahendus ei asenda reaalseid analüütilisi andmebaase ja repositooriume, vaid lahendab vaid konkreetse probleemi.
Tipptasemel näeb see välja järgmine:
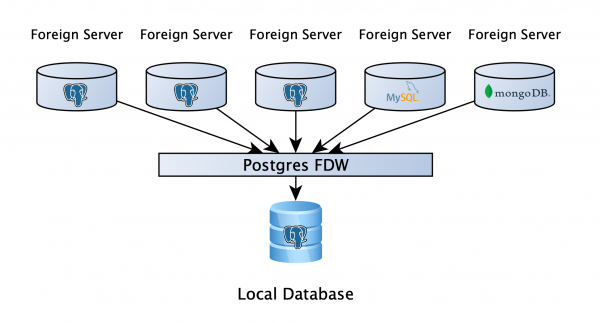
Seal on PostgreSQL andmebaas, kuhu kasutajad saavad oma tööandmeid salvestada ja mis kõige tähtsam – kõigi teenuste analüütilised koopiad on FDW kaudu selle andmebaasiga ühendatud. See võimaldab kirjutada päringu mitmesse andmebaasi ja pole vahet, mis see on: PostgreSQL, MySQL, MongoDB või midagi muud (fail, API, kui äkki pole sobivat ümbrist, võite kirjutada oma). Noh, kõik tundub suurepärane! Kas me läheme lahku?
Kui kõik lõppeks nii kiiresti ja lihtsalt, poleks tõenäoliselt artiklit.
Oluline on olla selge, kuidas Postgres töötleb kaugserveritele suunatud päringuid. See tundub loogiline, kuid sageli ei pööra inimesed sellele tähelepanu: Postgres jagab päringu osadeks, mida kaugserverites täidetakse iseseisvalt, kogub need andmed ja teeb ise lõplikud arvutused, nii et päringu täitmise kiirus sõltub suuresti kuidas see on kirjutatud. Samuti tuleb märkida: kui andmed kaugserverist saabuvad, pole sellel enam indekseid, miski ei aitaks planeerijat, seetõttu saame teda aidata ja nõustada ainult meie ise. Ja just sellest tahan ma täpsemalt rääkida.
Lihtne päring ja plaan sellega
Näitamaks, kuidas Postgres käivitab päringu 6 miljoni reaga tabelis kaugserveris server, vaatame lihtsat plaani.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table;
Aggregate (cost=418383.23..418383.24 rows=1 width=8) (actual time=3857.198..3857.198 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..402376.14 rows=6402838 width=0) (actual time=4.874..3256.511 rows=6406868 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Remote SQL: SELECT NULL FROM fdw_schema.table
Planning time: 0.986 ms
Execution time: 3857.436 msVERBOSE lause kasutamine võimaldab näha päringut, mis saadetakse kaugserverisse ja mille tulemused saame edasiseks töötlemiseks (RemoteSQL rida).
Läheme veidi kaugemale ja lisame oma päringule mitu filtrit: üks jaoks loogiline välja, üks esinemise järgi ajatempel intervalliga ja ükshaaval jsonb.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta->>'source' = 'test';
Aggregate (cost=577487.69..577487.70 rows=1 width=8) (actual time=27473.818..25473.819 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..577469.21 rows=7390 width=0) (actual time=31.369..25372.466 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND (("table".meta ->> 'source'::text) = 'test'::text) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 5046843
Remote SQL: SELECT created_dt, is_active, meta FROM fdw_schema.table
Planning time: 0.665 ms
Execution time: 27474.118 msSee on koht, millele peate päringute kirjutamisel tähelepanu pöörama. Filtreid ei viidud kaugserverisse, mis tähendab, et selle täitmiseks tõmbab Postgres kõik 6 miljonit rida välja, et seejärel kohapeal filtreerida (Filter row) ja koondada. Edu võti on kirjutada päring nii, et filtrid kantakse üle kaugmasinasse ning me saame ja koondame ainult vajalikud read.
See on mingi jama
Boolean väljadega on kõik lihtne. Algses taotluses oli probleem tingitud operaatorist is. Kui asendate selle =, siis saame järgmise tulemuse:
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active = True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta->>'source' = 'test';
Aggregate (cost=508010.14..508010.15 rows=1 width=8) (actual time=19064.314..19064.314 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..507988.44 rows=8679 width=0) (actual time=33.035..18951.278 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: ((("table".meta ->> 'source'::text) = 'test'::text) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 3567989
Remote SQL: SELECT created_dt, meta FROM fdw_schema.table WHERE (is_active)
Planning time: 0.834 ms
Execution time: 19064.534 msNagu näete, lendas filter kaugserverisse ja täitmisaeg vähenes 27 sekundilt 19 sekundile.
Väärib märkimist, et operaator is erinevad operaatorist = sest see võib töötada nullväärtusega. See tähendab et ei ole tõsi jätab filtrisse väärtused False ja Null, samas kui != Tõsi jätavad ainult valed väärtused. Seetõttu operaatori vahetamisel ei ole kaks tingimust operaatoriga VÕI tuleks filtrile edastada, näiteks WHERE (veerg != Tõene) VÕI (veerg on null).
Oleme Booleaniga tegelenud, liigume edasi. Nüüd tagastame Boole'i filtri algsele kujule, et teiste muudatuste mõju iseseisvalt arvesse võtta.
ajatempel? hz
Üldiselt tuleb sageli katsetada, kuidas kaugservereid hõlmavat päringut õigesti kirjutada, ja alles siis otsida selgitust, miks see nii juhtub. Internetist leiab selle kohta väga vähe infot. Seega leidsime katsetes, et fikseeritud kuupäeva filter lendab suure hooga kaugserverisse, kuid kui tahame kuupäeva dünaamiliselt määrata, näiteks nüüd() või CURRENT_DATE, siis seda ei juhtu. Meie näites lisasime filtri, nii et veerg Created_at sisaldas täpselt 1 kuu andmeid minevikus (BETWEEN CURRENT_DATE – INTERVAL '7 kuud' JA CURRENT_DATE - INTERVAL '6 kuud'). Mida me sel juhul tegime?
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt >= (SELECT CURRENT_DATE::timestamptz - INTERVAL '7 month')
AND created_dt <(SELECT CURRENT_DATE::timestamptz - INTERVAL '6 month')
AND meta->>'source' = 'test';
Aggregate (cost=306875.17..306875.18 rows=1 width=8) (actual time=4789.114..4789.115 rows=1 loops=1)
Output: count(1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.007..0.008 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '7 mons'::interval)
InitPlan 2 (returns $1)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.002..0.002 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)
-> Foreign Scan on fdw_schema."table" (cost=100.02..306874.86 rows=105 width=0) (actual time=23.475..4681.419 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND (("table".meta ->> 'source'::text) = 'test'::text))
Rows Removed by Filter: 76934
Remote SQL: SELECT is_active, meta FROM fdw_schema.table WHERE ((created_dt >= $1::timestamp with time zone)) AND ((created_dt < $2::timestamp with time zone))
Planning time: 0.703 ms
Execution time: 4789.379 msÜtlesime planeerijale, et arvutage alampäringus kuupäev ette ja edastage valmis muutuja filtrisse. Ja see vihje andis meile suurepärase tulemuse, taotlus muutus peaaegu 6 korda kiiremaks!
Jällegi, siin on oluline olla ettevaatlik: alampäringu andmetüüp peab olema sama, mis väljal, mille järgi filtreerime, vastasel juhul otsustab planeerija, et kuna tüübid on erinevad, tuleb kõigepealt hankida kõik andmed. andmed ja filtreerige need kohapeal.
Taastame kuupäevafiltri algse väärtuse.
Freddy vs. Jsonb
Üldiselt on Boole'i väljad ja kuupäevad meie päringut juba piisavalt kiirendanud, kuid järele jäi veel üks andmetüüp. Võitlus selle järgi filtreerimisega pole ausalt öeldes veel lõppenud, kuigi ka siin on edu. Niisiis, nii õnnestus meil filtrist mööda minna jsonb välja kaugserverisse.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta @> '{"source":"test"}'::jsonb;
Aggregate (cost=245463.60..245463.61 rows=1 width=8) (actual time=6727.589..6727.590 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=1100.00..245459.90 rows=1478 width=0) (actual time=16.213..6634.794 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 619961
Remote SQL: SELECT created_dt, is_active FROM fdw_schema.table WHERE ((meta @> '{"source": "test"}'::jsonb))
Planning time: 0.747 ms
Execution time: 6727.815 msOperaatorite filtreerimise asemel peate kasutama ühe operaatori olemasolu jsonb erinevas. 7 sekundit algse 29 asemel. Siiani on see ainus edukas variant filtrite edastamiseks jsonb kaugserverisse, kuid siin on oluline arvestada ühe piiranguga: meil on kasutusel andmebaasi versioon 9.6, kuid aprilli lõpuks plaanime viimased testid ära teha ja minna üle versioonile 12. Kui oleme värskendanud, kirjutame, kuidas see mõjutas, sest seal on üsna palju muudatusi, millele on palju lootust: json_path, uus CTE käitumine, surumine alla (olemas alates versioonist 10). Ma tõesti tahan seda varsti proovida.
Tee talle lõpp
Testisime, kuidas iga muudatus individuaalselt päringu kiirust mõjutas. Vaatame nüüd, mis juhtub, kui kõik kolm filtrit on õigesti kirjutatud.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active = True
AND created_dt >= (SELECT CURRENT_DATE::timestamptz - INTERVAL '7 month')
AND created_dt <(SELECT CURRENT_DATE::timestamptz - INTERVAL '6 month')
AND meta @> '{"source":"test"}'::jsonb;
Aggregate (cost=322041.51..322041.52 rows=1 width=8) (actual time=2278.867..2278.867 rows=1 loops=1)
Output: count(1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.010..0.010 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '7 mons'::interval)
InitPlan 2 (returns $1)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.003..0.003 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)
-> Foreign Scan on fdw_schema."table" (cost=100.02..322041.41 rows=25 width=0) (actual time=8.597..2153.809 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Remote SQL: SELECT NULL FROM fdw_schema.table WHERE (is_active) AND ((created_dt >= $1::timestamp with time zone)) AND ((created_dt < $2::timestamp with time zone)) AND ((meta @> '{"source": "test"}'::jsonb))
Planning time: 0.820 ms
Execution time: 2279.087 msJah, taotlus tundub keerulisem, see on sunnitud tasu, kuid täitmise kiirus on 2 sekundit, mis on üle 10 korra kiirem! Ja me räägime lihtsast päringust suhteliselt väikese andmekogumi vastu. Tõeliste taotluste korral saime kuni mitmesajakordse tõusu.
Kokkuvõtteks: kui kasutate PostgreSQL-i koos FDW-ga, kontrollige alati, et kõik filtrid saadetaks kaugserverisse ja olete rahul... Vähemalt seni, kuni jõuate erinevate tabelite vaheliste ühendusteni. serveridAga see on juba lugu teise artikli jaoks.
Täname tähelepanu eest! Mulle meeldiks kommentaarides kuulda küsimusi, kommentaare ja lugusid teie kogemuste kohta.
Allikas: www.habr.com
