

Esimene samm uue andmestikuga töötamisel on selle mõistmine. Selleks on näiteks vajalik välja selgitada, millised on muutuja väärtuste vahemikud, nende tüübid ning teada saada puuduvate väärtuste kogus.
Pandas'i raamatukogu pakub meile palju kasulikke tööriistu andmete uurimise analüüsi (Exploratory Data Analysis, EDA) teostamiseks. Kuid tavaliselt tuleb alustada üldisema plaaniga funktsioonidest, nagu df.describe(). Tuleb aga märkida, et selliste funktsioonide pakutavad võimalused on piiratud ning EDA esimesed sammud erinevate andmestikega on väga sageli üksteisele sarnased.
Tänases avaldatud materjali autor ütleb, et ta ei ole korduvate tegevuste fänn. Seetõttu leidis ta vahendeid, mis võimaldavad kiiresti ja tõhusalt andmete uurimise analüüsi teostada, ja avastas raamatukogu. . Tulemused ei väljendu eraldi näitajate kujul, vaid suhteliselt üksikasjaliku HTML-raporti vormis, mis sisaldab enamikku analüüsitud andmete kohta vajalikest teadmistest, mis võivad olla vajalikud enne sügavamale töötamise alustamist.
Siin arutatakse pandas-profiling raamatukogu kasutamise eripära Titanic andmehulgaga.
Andmete uuriv analüüs pandas'iga
Otsustasin katsetada pandas-profiling'ut Titanic andmehulgaga, kuna seal on erinevat tüüpi andmeid ja puuduvad väärtused. Arvan, et pandas-profiling raamatukogu on eriti huvitav olukordades, kus andmed pole veel puhastatud ja vajavad edasist töötlemist, mis sõltub nende omadustest. Selleks, et sellist töötlemist edukalt teostada, on oluline teada, kust alustada ja millele tähelepanu pöörata. Siin tulevadki mängu pandas-profiling võimalused.
Alustame andmete importimisega ja kasutame pandas't, et saada kirjeldava statistika näitajaid:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
import numpy as np
# импорт данных
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
# вычисление показателей описательной статистики
df.describe()Pärast selle koodilõigu täitmist saadakse see, mis on esitatud järgmises joonises.
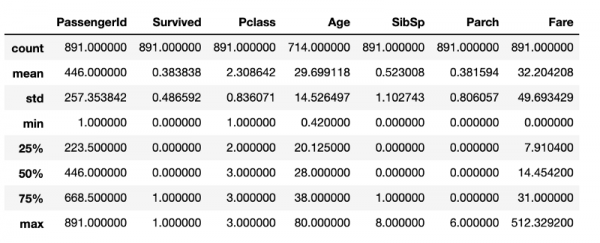
Pandas' standard tools provide descriptive statistical indicators.
While this contains a lot of useful information, it doesn't cover everything that might be interesting about the data studied. For example, we can assume that the data frame has 891 rows. DataFrameIf you need to verify this, you'll need another line of code to determine the frame size. Although these calculations are not particularly resource-intensive, constantly repeating them will undoubtedly lead to time loss, which is probably better spent on data cleaning.
Exploratory data analysis using pandas-profiling
Now let's do the same using pandas-profiling:
pandas_profiling.ProfileReport(df)Executing the code above will generate a report with exploratory data analysis indicators. The code shown will output the found information about the data, but it can be configured to produce an HTML file that can be shown to someone.
Aru ülevaate osa sisaldab jaotist Overview, mis annab põhiteavet andmete kohta (näide, vaatlemiste arv, muutujate arv jne). Samuti sisaldab see hoiatuste loetelu, mis teavitab analüütikut, millele tasub erilist tähelepanu pöörata. Need hoiatused võivad anda vihjeid, millele tuleks andmete puhastamisel keskenduda.
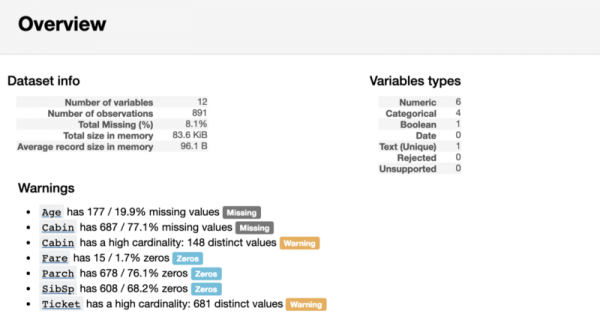
Raporti jaotis Overview
Muutujate uurimine
Jaotisest Overview leiate kasulikke andmeid igas muutuja kohta. Nendesse kuuluvad muu hulgas väikesed diagrammid, mis kirjeldavad iga muutuja jaotust.

Numbrilise muutuja Age andmed
Kuna eelmisest näitest on näha, annab pandas-profiling meile mitmeid kasulikke näitajaid, nagu puuduvate väärtuste protsent ja arv ning kirjeldava statistika näitajad, mida oleme juba näinud. Kuna Age on numbriline muutuja, võimaldab selle jaotuse visualiseerimine histogrammina järeldada, et meil on tegemist paremale kalduva jaotusega.
Kategooria muutujat käsitletakse veidi teisiti kui numbrilisi muutujaid.

Kategooria muutuja andmed: Sugu
Kuna keskmise, miinimumi ja maksimumi leidmise asemel leidis pandas-profiling klasside arvu. Kuna Sugu on binaarne muutuja, siis on selle väärtused esindatud kahe klassiga.
Kui teile, nagu ka mulle, meeldib koodi uurida, siis võib teid huvitada, kuidas täpselt pandas-profiling need näitajad arvutab. Sellega tutvumine ei ole keeruline, arvestades, et teegi kood on avatud ja saadaval GitHubis. Kuna ma ei ole suur fänn «mustade kastide» kasutamise suhtes oma projektides, heitsin pilgu teegi lähtekoodi. Näiteks selline on numbriliste muutujate töötlemise mehhanism, mille esindab funktsioon :
def describe_numeric_1d(series, **kwargs):
"""Compute summary statistics of a numerical (`TYPE_NUM`) variable (a Series).
Also create histograms (mini an full) of its distribution.
Parameters
----------
series : Series
The variable to describe.
Returns
-------
Series
The description of the variable as a Series with index being stats keys.
"""
# Format a number as a percentage. For example 0.25 will be turned to 25%.
_percentile_format = "{:.0%}"
stats = dict()
stats['type'] = base.TYPE_NUM
stats['mean'] = series.mean()
stats['std'] = series.std()
stats['variance'] = series.var()
stats['min'] = series.min()
stats['max'] = series.max()
stats['range'] = stats['max'] - stats['min']
# To avoid to compute it several times
_series_no_na = series.dropna()
for percentile in np.array([0.05, 0.25, 0.5, 0.75, 0.95]):
# The dropna() is a workaround for https://github.com/pydata/pandas/issues/13098
stats[_percentile_format.format(percentile)] = _series_no_na.quantile(percentile)
stats['iqr'] = stats['75%'] - stats['25%']
stats['kurtosis'] = series.kurt()
stats['skewness'] = series.skew()
stats['sum'] = series.sum()
stats['mad'] = series.mad()
stats['cv'] = stats['std'] / stats['mean'] if stats['mean'] else np.NaN
stats['n_zeros'] = (len(series) - np.count_nonzero(series))
stats['p_zeros'] = stats['n_zeros'] * 1.0 / len(series)
# Histograms
stats['histogram'] = histogram(series, **kwargs)
stats['mini_histogram'] = mini_histogram(series, **kwargs)
return pd.Series(stats, name=series.name) Kuigi see koodifragm võib tunduda üsna suur ja keeruline, on selle mõistmine tegelikult väga lihtne. Jutt on sellest, et teegis on funktsioon, mis määratleb muutujate tüübid. Kui selgub, et teek on kohanud numbrilist muutujat, leiab ülaltoodud funktsioon näitajad, mida oleme käsitlenud. Selles funktsioonis kasutatakse pandas'e standardoperatsioone objektidega, mis on seeria, nagu näiteks series.mean(). Arvutuste tulemused salvestatakse sõnaraamatusse statistika. Histogrammid luuakse kohandatud versiooni abil funktsioonist matplotlib.pyplot.hist. Kohandamine on suunatud sellele, et funktsioon suudaks töötada erinevat tüüpi andmekomplektidega.
Korrelaatsiooninäitajad ja uurimistulemuste proov
Pärast pandas-profilingu muutujate analüüsi tulemusi, toob jaotis Korrelaatsioonid välja Pearsons'i ja Spearmani korrelatsioonimatriigid.
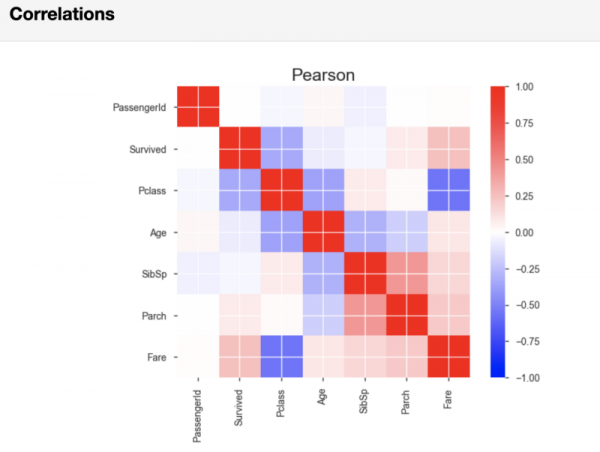
Pearsoni korrelatsioonimatriis
Kui vaja, saate koodireas, mis käivitab aruande genereerimise, seada korrelatsiooni arvutamisega kaasnevad lävendiväärtused. Sellega saate määra, kui tugev korrelatsioon loetakse teie analüüsi jaoks oluliseks.
Ja lõpuks, aruandes pandas-profiling, jaotises Sample, kuvatakse näidisena andmefragment, mis on saadud andmekogumi algusest. Selline lähenemine võib tuua kaasa ebameeldivaid üllatusi, kuna esimesed paar vaatlust võivad olla valik, mis ei kajasta kogu andmekogumi eripära.
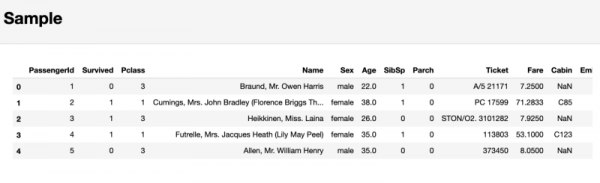
Jaotis, mis sisaldab uuritava andmeproovi
Seetõttu ei soovita ma sellele viimasele jaotisele tähelepanu pöörata. Selle asemel on parem kasutada käsku df.sample(5), mis valib juhuslikult 5 vaatlust andmekogumist.
Kokkuvõte
Kokkuvõttes võib öelda, et pandas-profiling raamatukogu pakub analüütikutele mitmeid kasulikke võimalusi, mis tulevad kasuks olukordades, kus on vaja kiiresti saada üldine ligikaudne ülevaade andmetest või edastada kellegile andmete uurimise aruannet. Samas toimub tegelik andmetöötlus, mis arvestab nende omadustega, nagu ka ilma pandas-profilinguta, käsitsi.
Kui soovite näha, kuidas kogu andmete uurimise analüüs ühes Jupyteri märkmikus välja näeb, vaadake minu projekti, mis on loodud kasutades nbviewer. Lisaks leiate GitHubi hoidlast vastava koodi.
Lugupidamisega lugejad! Kust alustate uute andmekogude analüüsi?
Allikas: habr.com
