

Artikkel koosneb kahest osast:
- Lühike ülevaade mõningatest arhitektuuridest, mis on mõeldud objektide tuvastamiseks piltidel ja piltide segmentimiseks, koos kõige arusaadavamate linkidega ressurssidele. Püüdsin valida video selgitusi, eelistatavalt vene keeles.
- Teine osa keskendub püüdele mõista neuraalvõrkude arhitektuuride arengusuundi. Ja tehnoloogiaid, mis põhinevad neil.

Joonis 1 – Neuraalvõrkude arhitektuuride mõistmine pole lihtne
Kõik algas sellest, et tegin kaks demonstreerivat rakendust objektide klassifitseerimiseks ja tuvastamiseks Android telefonil:
- , kus andmed töödeldakse serveris ja edastatakse telefonile. Piltide klassifitseerimine (image classification) kolmele karu tüübile: pruuni, musta ja pehme karu.
- , kus andmed töödeldakse telefonil. Objektide tuvastamine (object detection) kolmele tüübile: sarapuupähkel, viigimarjad ja datlid.
Klassifitseerimise, objektide tuvastamise ja . Seetõttu tekkis vajadus teada saada, millised tehisnärvivõrgud tuvastavad objekte piltidel ja millised suudavad segmentida. Leidsin järgmised arhitektuurid, millel on minu jaoks kõige arusaadavamad lingid ressurssidele:
- R-CNN arhitektuuride seeria (Rregionid, mis Ckonvolutsioon Nneuraalsete Nvõrkude omadused): R-CNN, Fast R-CNN, , . Pildi objekti tuvastamiseks kasutatakse Region Proposal Network (RPN) mehhanismi, mis eraldab piiratud piirkonnad (bounding boxes). Alguses kasutati RPN asemel aeglasemat Selective Search mehhanismi. Seejärel edastatakse eraldatud piiratud piirkonnad tavapärasele tehisnärvivõrgule klassifitseerimiseks. R-CNN arhitektuuris on selged „for” tsüklid, mis loovad piiratud piirkondade jaoks, kokku kuni 2000 korda läbi sisemise võrgu AlexNet. Selgete „for” tsüklite tõttu aeglustub piltide töötlemise kiirus. Igakuuselt vähendatakse selgete tsüklite arvu ja läbidud ringe sisemise tehisnärvivõrgu kaudu, samuti tehakse kümneid teisi muudatusi kiirusete suurendamiseks ja objekti tuvastamise ülesande asendamiseks objekti segmentimisega Mask R-CNN-s.
- (Yainult Ovaatab Laga Once) – esimene närvivõrk, mis tuvastas objekte reaalajas mobiilseadmetes. Eripära: objektide eristamine ühe läbimisega (piisab korraks vaatamisest). See tähendab, et YOLO arhitektuuris ei ole selgeid 'for' silmuseid, mistõttu töötab võrk kiiresti. Näiteks sarnasus: NumPy-s puuduvad ka silmused 'for' maatriksite operatsioonide puhul, kuna neid teostatakse NumPy-s madalamal arhitektuuritasemel C-programmeerimiskeele abil. YOLO kasutab eelmääratud akendega ruudustikku. Selleks, et sama objekti ei tuvastataks korduvalt, kasutatakse akende kattuvuse koefitsienti (IoU, Intersection over Union). See arhitektuur töötab laias vahemikus ja omab kõrget : mudel saab olla õpetatud fotodel, kuid töötab hästi ka joonistatud piltidel.
- (Single Shot MultiBox Detector) – kasutatakse parimaid YOLO arhitektuuri „nippe“ (nt mitte-maximalne mahasurumine) ning lisatakse uusi, et närvivõrk töötaks kiiremini ja täpsemalt. Eripära: objektide eristamine ühe läbimise kaudu antud akna ruudustiku (default box) abil pildipüramiidis. Pildipüramiid on kodeeritud konvolutsioonitensorites järjestikuste konvolutsiooni ja max-poolingu operatsioonide käigus (max-poolingu operatsiooni puhul väheneb ruumiline mõõde). Nii määratakse suured kui ka väikesed objektid ühe võrgu läbimisega.
- MobileSSD (MobiilneNetV2 + SSD) – kahest närvivõrgu arhitektuurist koosnev kombinatsioon. Esimene võrk töötleb andmeid kiiresti ja suurendab tuvastamise täpsust. MobileNetV2 asendab VGG-16, mida kasutati esialgselt . Teine võrk SSD määrab objektide asukoha pildil.
- – väga väike, kuid täpne tehisintellekt. Üksinda ei lahenda see objektide tuvastamise probleemi. Kuid seda saab kasutada erinevate arhitektuuride kombinatsioonis ning mobiilsetes seadmetes. Iseloomulik omadus on see, et andmed kokkusurutakse nelja 1×1 konvolutsioonifiltri abil, seejärel laiendatakse neid nelja 1×1 ja nelja 3×3 konvolutsioonifiltri abil. Ühte sellist andmete kokkusurumise ja laiendamise iteratsiooni nimetatakse „Fire Module“.
- (Semantilise pildisegmentatsiooni teostamine sügavate konvolutsioonivõrkudega) – objektide segmentatsioon pildil. Arhitektuuri iseloomustab haruldane (dilated convolution) konvolutsioon, mis säilitab ruumilise eraldusvõime. Järgneb tulemuste post-protsessing etapp graafilise tõenäosusmudeliga (conditional random field), mis aitab eemaldada väikeseid segadusi segmentatsioonis ja parandada segmenteeritud pildi kvaliteeti. Kohutava nime „graafiline tõenäosusmudel“ taga peitub tavaline Gaussi filter, mis on viie punkti kaupa lähenenud.
- Püüdsin välja selgitada, kuidas see töötab (Single-Shot Refinement Neural Network for Object Detja, kuid sain vähe aru.
- Vaatasin ka, kuidas töötab tehnoloogia „tähelepanu“ (attention): , , . Tähelepanu arhitektuuri iseloomustab automaatne tähelepanu piirkondade (RoI) esiletõstmine pildil, Rhuvide of Imille võimaldab närvivõrk nimega Attention Unit. Tähelepanu piirkonnad sarnanevad piiritletud alade (bounding boxes) märkidega, kuid erinevalt neist ei ole nad pildile kinnitatud ja võivad omada häguseid piire. Seejärel eraldatakse tähelepanu piirkondadest omadused (features), mis „yoni on“ rekurentsvõrkudele, mille arhitektuurid on . Rekurentsvõrgud suudavad analüüsida omaduste omavahelisi seoseid järjestuses. Rekurentsvõrgud on algselt kasutatud tekstide tõlkimiseks teistesse keeltesse, kuid nüüd ka pildist ja .
Nende arhitektuuride uurimise käigus sain aru, et ma ei saa midagi aru.. Ja asi pole selles, et minu närvivõrgul on tähelepanu mehhanismiga probleeme. Kõikide nende arhitektuuride loomine sarnaneb mõne tohutu hackathoniga, kus autorid võistlevad häkkimises. Hack (häkk) on kiire lahendus keerulisele tarkvaraküsimusele. See tähendab, et kõigi nende arhitektuuride vahel pole nähtavat ega arusaadavat loogilist seost. Kõike, mis neid ühendab, peetakse parimateks häkkideks, mida nad üksteiselt laenavad, pluss ühine kõigile (vea tagasikandmine, backpropagation). Ei ! Pole selge, mida muuta ja kuidas olemasolevaid saavutusi optimeerida.
Tulemuseks on see, et häkkide vahelise loogilise seose puudumise tõttu on need äärmiselt raskesti meeldejätmised ja praktikas rakendatavad. Need on killustatud teadmised. Parimal juhul jäävad meelde mõned huvitavad ja ootamatud hetked, kuid enamik arusaadust ja arusaamatust kaob mälust juba paar päeva pärast. Oleks hea, kui nädal pärast mäletatakse vähemalt arhitektuuri nime. Ja selle artiklite lugemise ja ülevaatevideote vaatamise peale on kulutatud mitu tundi ja isegi päeva tööaega!
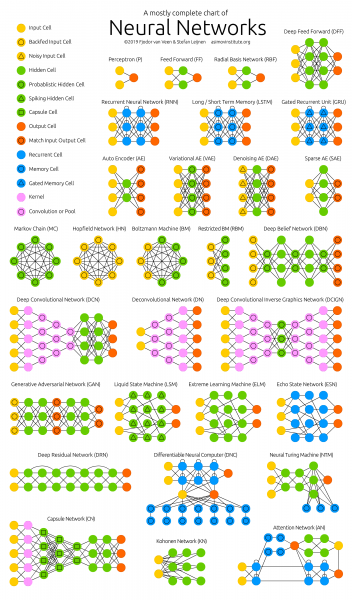
Joonis 2 –
Minu isikliku arvamuse kohaselt püüavad enamik teadusartiklite autoreid teha kõik, et isegi need killustatud teadmised ei jääks lugejale arusaadavaks. Kuid gerundite kasutamine kümnes rida koos valemitega, mis on võetud „laest“ – see on teema eraldi artikli jaoks (probleem ).
Sellepärast tekkis vajadus süsteematiseerida teave neuraalvõrkude kohta ja seeläbi parandada arusaamise ja mäletamise kvaliteeti. Seega sai erinevate tehnoloogiate ja kunstlike neuraalvõrkude arhitektuuride analüüsi põhiteemaks järgmine ülesanne: välja selgitada, kuhu see kõik liigub, mitte millise konkreetse neuraalvõrgu ülesehitusse.
Kuhu see kõik liigub. Peamised tulemused:
- Masinõppe alustestimite arv viimase kahe aasta jooksul . Võimalik põhjus: „neuraalvõrgud ei ole enam millegi uue sümboliks.”
- Igaüks saab luua töötava neuraalvõrgu lihtsa ülesande lahendamiseks. Selleks võtab ta valmis mudeli „mudelite loomaaed” (model zoo) ja treenib neuraalvõrgu viimast kihti () valmisteatud andmete põhjal või tasuta .
- Suurte tehisintellekti tootjate loomine modellide loomaaedade (model zoo). Nende abil on võimalik kiiresti luua ärirakendus: TensorFlow'i jaoks, PyTorch'i jaoks, Caffe2 jaoks, Chainer'i jaoks ja .
- Tehisintellekt, mis töötab reaalses ajas (real-time) mobiilseadmetes. 10 kuni 50 kaadrit sekundis.
- Tehisintellekti rakendamine telefonides (TF Lite), brauserites (TF.js) ja (IoT, Iasjade of Tinternet). Eriti telefonides, mis juba toetavad tehisintellekti riistvara tasemel (neuroakseleraatorid).
- „Iga seade, rõivad ja võib-olla isegi toit saavad IP-v6 aadressi ja suhtlevad omavahel“ – .
- Masinõppe publikatsioonide arv on hakanud (kahekordistumine iga kahe aasta tagant) alates 2015. aastast. On ilmne, et on vaja artiklite analüüsimiseks tehisintellekti.
- Järgmised tehnoloogiad saavad üha populaarsemaks:
- PyTorch – populaarsus kasvab kiiresti ja näib, et see ületab TensorFlow'd.
- Automaatne hüperparameetrite valik AutoML – populaarsus kasvab aeglaselt.
- Täpseuse järkjärguline vähenemine ja arvutuskiirus: , algoritmid , ebatäpsed (ligikaudsed) arvutused, kvantimine (kui närvivõrgu kaalu muudetakse täisarvudeks ja kvantitakse), närviakseleraatorid.
- Tõlge ja .
- Loomine , nüüd juba reaalajas.
- Peamine DL-is on see, et andmeid on palju, kuid nende kogumine ja tähistamine ei ole kerge. Seetõttu areneb automaatne tähistamine () närvivõrkude jaoks kasutades närvivõrke.
- Närvivõrkudega on arvutiteadus äkitselt muutunud eksperimentaalseks teaduseks ja tekkinud on .
- IT-raha ja närvivõrkude populaarsus ilmusid samaaegselt, kui arvutused muutusid turuväärtuseks. Majandus on kuldvaluuta-arvutuslikuks muutumas . Vaadake minu artiklitökonofoorikas Ajanadaliselt tekib uus
ML/DL programmeerimise metodoloogia Joonis 3 – ML/DL kui uus programmeerimise metodoloogia
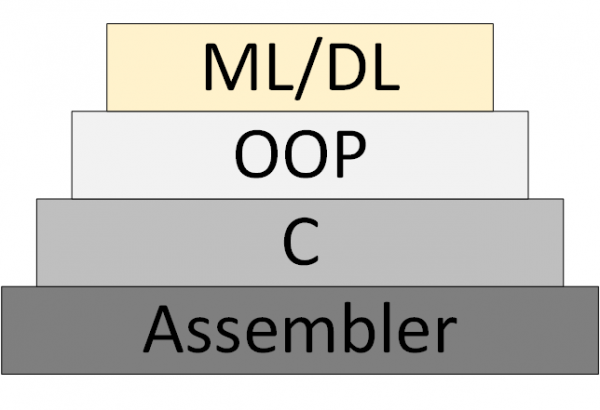
Kuid "neurovõrkude teooriat" pole nii kunagi tekkinud.
Kuid see ei ilmunud kunagi «neuraalvõrkude teooria», mille võivad mõelda ja töötada süsteemselt. See, mis praegu nimetatakse 'teooriaks', on tegelikult eksperimentaalsed, heuristilised algoritmid.
Lingid minu ja mitte ainult ressurssidele:
- Andmeteaduse uudiskiri. Peamiselt piltide töötlemisest. Kes soovib seda saada, saatke e-kiri (foobar167<гаф-гаф>gmail<точка>com). Linke artiklitele ja videotele saatn kogumise käigus.
- Üksikasjalik , mida olen läbinud ja mida sooviksin läbida.
- , millega tasub alustada tehisnärvivõrkude õppimist. Pluss brošüür .
- , kust igaüks leiab endale midagi huvitavat.
- Eriti kasulikud on olnud videokanalid teadusartiklite analüüsiks andmeteaduse valdkonnas. Leidke need, registreeruge neile ja jagage linke oma kolleegidega ning minuga ka. Näiteks:
- tuntud ka kui astep-by-step juhiste ja avatud lähtekoodiga.
Aitäh tähelepanu eest!
Allikas: habr.com
