

- Oh, aucun abri ne peut résister à un impact de météorite. Mais comme tout le monde, vous disposez d’une réserve, vous n’avez donc pas à vous inquiéter.
Stanislav Lem, « Journaux étoilés d'Ijon le Calme »
La sauvegarde fait référence à l'enregistrement d'une copie des données quelque part en dehors de leur emplacement de stockage principal.

L'objectif principal de la sauvegarde est de restaurer les données après leur perte. À cet égard, vous entendez souvent dire que si vous disposez d’une réplique de base de données, vous pouvez toujours restaurer les données à partir de celle-ci et aucune sauvegarde n’est nécessaire. En fait, la sauvegarde permet de résoudre au moins trois problèmes qui ne peuvent être résolus à l'aide d'une réplique, et une réplique ne peut pas être initialisée sans copie de sauvegarde.
Premièrement, une sauvegarde permet de récupérer des données après une erreur logique. Par exemple, un comptable a supprimé un groupe de transactions ou un administrateur de base de données a détruit un espace table. Les deux opérations sont tout à fait légales du point de vue de la base de données, et le processus de réplication les reproduira dans la base de données réplica.
Deuxièmement, les SGBD modernes sont des systèmes logiciels très fiables, mais les structures internes des bases de données sont parfois endommagées, après quoi l'accès aux données est perdu. Ce qui est particulièrement offensant, c'est qu'une telle violation se produit généralement sous une charge élevée ou lors de l'installation d'une sorte de mise à jour. Mais la charge élevée et les mises à jour régulières indiquent que la base de données n'est en aucun cas une base de données de test et que les données qui y sont stockées sont précieuses.
Enfin, la troisième tâche, dont la solution nécessite une copie de sauvegarde, est le clonage de bases de données, par exemple à des fins de tests.
La sauvegarde de la base de données repose d'une manière ou d'une autre sur l'un des deux principes suivants :
- Échantillonnage des données et sauvegarde ultérieure dans un format personnalisé ;
- Instantané des fichiers de base de données et enregistrement des journaux.
Examinons de plus près ces principes et les outils qui les mettent en œuvre.
Téléchargement de données
L'ensemble des utilitaires inclus avec tout SGBD doit inclure des outils pour télécharger et charger des données. Les données sont stockées soit au format texte, soit dans un format binaire spécifique à un SGBD particulier. Le tableau ci-dessous fournit une liste de ces outils :
Format binaire
Format du texte
Oracle
Exportation DataPump/Importation DataPump
Export / Import
Chargeur SQL*Plus/SQL*
PostgreSQL
pg_dump, pg_dumpall/pg_restore
pg_dump, pg_dumpall/psql
Microsoft SQL Server
bcp
bcp
DB2
décharger/charger
décharger/charger
MySQL
mysqldump, mysqlpump/mysql, mysqlimport
MongoDB
mongodump/mongorestore
mongoexport/mongoimport
Cassandra
instantané de nodetool/sstableloader
cqlsh
L'avantage du format texte est qu'il peut être modifié ou même créé par des programmes externes, et le format binaire, à son tour, est bon car il vous permet de télécharger et de télécharger des données plus rapidement en économisant des ressources lors de la conversion de format.
Malgré la simplicité et l'évidence de l'idée de télécharger des données, cette méthode est rarement utilisée pour sauvegarder des bases de données industrielles chargées. Voici les raisons pour lesquelles le déchargement ne convient pas à une sauvegarde complète :
- le processus de déchargement crée une charge importante sur le système source ;
- le déchargement prend beaucoup de temps - une fois le déchargement terminé, il ne sera plus pertinent ;
- Il est presque impossible d'effectuer un déchargement coordonné de l'ensemble de la base de données sous une charge élevée, car le SGBD est obligé de stocker un instantané de son état au moment où le déchargement commence. Plus les transactions ont été effectuées depuis le début du téléchargement, plus la taille de l'instantané est grande (copies de données non pertinentes dans PostgreSQL, espace d'annulation dans Oracle, tempdb dans Microsoft SQL Server, etc.) ;
- le déchargement préserve la structure logique des données, mais ne préserve pas sa structure physique - paramètres de stockage physique des tables, index, etc.
Cependant, le téléchargement a aussi ses avantages :
- haute sélectivité : vous pouvez télécharger des tableaux individuels, des champs individuels et même des lignes individuelles ;
- les données téléchargées peuvent être chargées dans une base de données d'une autre version, et si le téléchargement est effectué au format texte, alors dans une autre base de données.
Ainsi, le téléchargement est principalement utilisé pour des tâches telles que la sauvegarde de petites tables (par exemple, des répertoires) ou la distribution d'ensembles de données avec la prochaine version de l'application.
La méthode la plus courante de sauvegarde de base de données consiste à copier les fichiers de base de données.
Stockage à froid des fichiers de base de données
L'idée évidente est d'arrêter la base de données et de copier tous ses fichiers. Cette sauvegarde est appelée sauvegarde « à froid ». La méthode est extrêmement fiable et simple, mais elle présente deux inconvénients évidents :
- A partir d'une sauvegarde « à froid », vous ne pouvez restaurer que l'état de la base de données qui était au moment de l'arrêt ; les transactions effectuées après le redémarrage de la base de données ne seront pas incluses dans la copie de sauvegarde « à froid » ;
- Toutes les bases de données ne disposent pas d'une fenêtre technologique permettant d'arrêter la base de données.
Si la sauvegarde « à froid » vous convient, vous devez vous en rappeler
- La copie froide doit parfois inclure des journaux. Les méthodes permettant de déterminer les journaux qui doivent être placés dans la copie « à froid » sont individuelles pour chaque SGBD. Par exemple, dans Oracle, il est nécessaire de copier ce qu'on appelle la restauration en ligne, c'est-à-dire un nombre fixe de fichiers journaux dans un répertoire spécial, même lorsque la base de données est arrêtée correctement. Dans PostgreSQL, vous devez enregistrer tous les journaux en commençant par celui contenant le dernier point de contrôle, dont les informations sont contenues dans le fichier de contrôle.
- Le répertoire de la base de données peut contenir des fichiers d'espace de table temporaires suffisamment volumineux pour ne pas avoir besoin d'être inclus dans la sauvegarde. D’ailleurs, cette remarque est également vraie pour les sauvegardes à chaud.
Sauvegarde de fichiers à chaud
La plupart des sauvegardes de bases de données modernes sont effectuées en copiant les fichiers de la base de données sans arrêter la base de données. Il y a plusieurs problèmes ici :
- Lorsque la copie commence, le contenu de la base de données peut ne pas coïncider avec le contenu des fichiers, car certaines informations se trouvent dans le cache et n'ont pas encore été écrites sur le disque.
- Lors de la copie, le contenu de la base de données peut changer. Si des structures de données mutables sont utilisées, le contenu des fichiers change, et lorsque des structures immuables sont utilisées, l'ensemble des fichiers change : de nouveaux fichiers apparaissent et les anciens sont supprimés.
- Étant donné que l'écriture des données dans la base de données et la lecture des fichiers de la base de données ne sont en aucun cas synchronisées, le programme de sauvegarde peut lire une page incorrecte, dont la moitié proviendra de l'ancienne version de la page et l'autre moitié de la nouvelle.
Pour que la sauvegarde soit cohérente, chaque SGBD dispose d'une commande qui notifie que le processus de sauvegarde a commencé. Syntaxiquement, cette commande peut être différente :
- dans Oracle, il s'agit d'une commande distincte ALTER DATABASE/TABLESPACE BEGIN BACKUP ;
- dans PostgreSQL – fonction pg_start_backup();
- Dans Microsoft SQL Server et DB2, la préparation de la sauvegarde est effectuée implicitement lors de l'exécution de la commande BACKUP DATABASE ;
- dans MySQL Enterprise, Cassandra et MongoDB, la préparation est implicitement effectuée par un utilitaire externe - mysqlbackup, OpsCenter et Ops Manager, respectivement.
Malgré les différences de syntaxe, le processus de préparation d'une sauvegarde est le même.
Voici à quoi ressemble la préparation à la sauvegarde dans un SGBD avec des structures de disques mutables, c'est-à-dire dans tous les systèmes relationnels de disques traditionnels :
- Le moment où la sauvegarde a démarré est mémorisé ; la sauvegarde devra désormais contenir les journaux de la base de données.
- Un point de contrôle est effectué, c'est-à-dire que toutes les modifications survenues dans les pages de données avant le moment mémorisé sont vidées sur le disque. Cela garantit qu'aucun journal n'est nécessaire avant le démarrage de la sauvegarde pendant la récupération.
- Un mode de journalisation spécial est activé : si une page de données a changé pour la première fois après le chargement à partir du disque, au lieu d'écrire les modifications de page dans le journal, la base de données y écrira la page entière. Lors de l'exécution de la procédure de préparation, toutes les pages sont vidées sur le disque. Ainsi, lors de la première modification, le bloc entier sera toujours écrit dans le journal. Mais si la page est à nouveau expulsée du disque pendant le processus de sauvegarde, la prochaine modification entraînera également l'apparition d'une copie complète de la page dans le journal. Cela garantit que si la page s'avère incorrecte lors de la copie d'un fichier de données, l'application d'un journal la corrigera à nouveau.
- Les modifications apportées aux en-têtes du fichier de données sont bloquées, c'est-à-dire la partie de celui-ci dont les modifications ne sont pas reflétées dans les journaux. Cela garantit que l'en-tête est copié correctement et que les journaux sont ensuite appliqués correctement au fichier de données.
Une fois toutes les procédures ci-dessus terminées, vous pouvez copier des fichiers de données à l'aide des outils du système d'exploitation - cp, rsync et autres. L'activation du mode sauvegarde réduit les performances de la base de données : d'une part, le volume des journaux augmente, et d'autre part, si soudainement une panne se produit dans le mode sauvegarde, la récupération prendra plus de temps car les en-têtes des fichiers de données ne sont pas mis à jour. Plus la sauvegarde est terminée rapidement, mieux c'est pour la base de données, il est donc approprié d'utiliser des outils tels qu'un instantané du système de fichiers ou la rupture du miroir (BCV) dans la baie de disques. Certains SGBD (Oracle, PostgreSQL) laissent à l'administrateur la possibilité de choisir indépendamment la méthode de copie, d'autres (Microsoft SQL Server) fournissent une interface pour intégrer leurs propres utilitaires de sauvegarde avec le système de fichiers ou les mécanismes de stockage.
Une fois la sauvegarde terminée, vous devez remettre la base de données à son état normal. Dans Oracle, cela se fait avec la commande ALTER DATABASE/TABLESPACE END BACKUP, dans PostgreSQL en appelant la fonction pg_stop_backup(), et dans d'autres bases de données par des routines internes des commandes correspondantes ou des services externes.
Voici à quoi ressemble la chronologie du processus de sauvegarde :
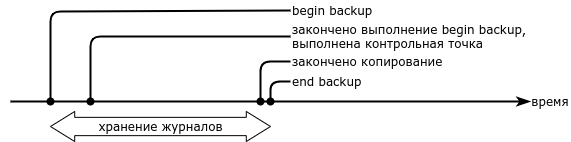
- Préparer une sauvegarde prend du temps, parfois un temps considérable. Même si des volumes en miroir ou des systèmes de fichiers compatibles avec les instantanés sont utilisés, le processus de sauvegarde ne sera pas instantané.
- Parallèlement aux fichiers de données, il est nécessaire de sauvegarder les journaux à partir du moment où vous commencez la préparation de la sauvegarde jusqu'au moment où la base de données revient à son état normal.
- Vous pouvez restaurer à partir de cette sauvegarde au moment où la base revient à son état normal. La restauration à un point antérieur n'est pas possible.
Avec des bases de données qui utilisent des structures de données immuables (instantanés mémoire, arborescences LSM), la situation est plus simple. La préparation d'une sauvegarde comprend les étapes suivantes :
- Les données de la mémoire sont vidées sur le disque.
- La liste des fichiers inclus dans la copie de sauvegarde est enregistrée. Jusqu'à ce que le processus de sauvegarde soit terminé, il est interdit à la base de données de supprimer ces fichiers, même s'ils ne sont plus nécessaires.
Dès que la sauvegarde est terminée, la base de données aux structures immuables peut à nouveau supprimer les fichiers inutiles.
Récupération au point
Une copie de sauvegarde permet de restaurer l'état de la base de données au moment où la commande de retour du mode sauvegarde est terminée. Cependant, un accident nécessitant une récupération peut survenir à tout moment. La tâche de restauration de l'état d'une base de données à un moment arbitraire est appelée « récupération à un moment donné ».
Pour garantir que cela est possible, vous devez enregistrer les journaux de la base de données à partir de la fin de la sauvegarde et, pendant le processus de récupération, continuer à appliquer les journaux à la copie restaurée. Une fois la base de données restaurée à partir d'une copie de sauvegarde, au moment où la copie est terminée, l'état de la base de données (fichiers et pages mises en cache) est garanti correct, un mode de journalisation spécial n'est donc pas nécessaire. En appliquant les journaux au bon moment, vous pouvez obtenir l'état de la base de données à tout moment.
Alors que la vitesse à laquelle une sauvegarde peut être restaurée n'est limitée que par la bande passante du disque, la vitesse à laquelle les journaux peuvent être appliqués est généralement limitée par les performances du processeur. Si des modifications se produisent en parallèle dans la base de données principale, alors pendant la récupération, toutes les modifications sont effectuées séquentiellement - dans l'ordre dans lequel elles sont lues dans le journal. Ainsi, le temps de récupération dépend linéairement de la distance entre le point de récupération et le point final de la sauvegarde. Pour cette raison, il est nécessaire d'effectuer des sauvegardes complètes assez souvent - au moins une fois par semaine pour les bases de données avec une faible charge de transactions et jusqu'à des copies quotidiennes des bases de données très chargées.
Sauvegarde incrémentielle
Pour accélérer la récupération jusqu'à un certain point, j'aimerais pouvoir effectuer des sauvegardes aussi souvent que possible, mais en même temps ne pas occuper d'espace disque supplémentaire et ne pas charger la base de données avec des tâches de sauvegarde.
La solution au problème consiste à effectuer une sauvegarde incrémentielle, c'est-à-dire à copier uniquement les pages de données modifiées depuis la sauvegarde précédente.
Les sauvegardes incrémentielles n'ont de sens que pour les SGBD qui utilisent des structures de données mutables.
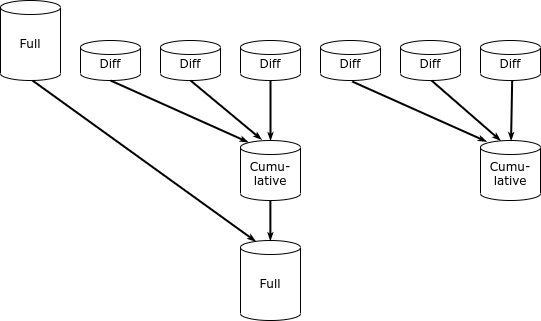
L'incrément peut être compté soit à partir d'une sauvegarde complète (copie cumulative), soit à partir de toute copie précédente (copie différentielle).

Malheureusement, il n'existe pas de terminologie uniforme et différents fabricants utilisent des termes différents :
différentiel
Cumulatif
Oracle
Différentielle
accumulé
PostgreSQL
Incrémental
-
Microsoft SQL Server
-
Différentielle
IBM DB2
Delta
Incrémental
S'il existe des copies incrémentielles, le processus de restauration vers un point est le suivant :
- la dernière sauvegarde complète effectuée avant la restauration ;
- les copies incrémentielles sont restaurées par-dessus la copie complète ;
- les journaux sont regroupés depuis le point de départ de la sauvegarde jusqu'au point de récupération.
Avoir une copie cumulative accélère le processus de récupération. Ainsi, par exemple, pour restaurer l'état de la base de données à un point compris entre T3 et T4, il faut restaurer deux copies incrémentielles, et pour restaurer à un point après T4, une seule.
Évidemment, la taille d'une copie cumulative est inférieure à la taille de plusieurs copies différentielles, car certaines pages ont changé plusieurs fois et chaque copie incrémentielle contient une version différente de la page.
Il existe trois manières de créer une copie incrémentielle :
- créer une copie complète et calculer la différence avec la copie complète précédente ;
- analyser les journaux, créer une liste des pages modifiées et sauvegarder les pages incluses dans la liste ;
- interroger les pages modifiées dans la base de données.
La première méthode permet d'économiser de l'espace disque, mais ne réduit pas la charge sur la base de données. De plus, si une sauvegarde complète est disponible, la convertir en sauvegarde incrémentielle est inutile, car la restauration d'une sauvegarde complète est plus rapide que la restauration d'une sauvegarde complète précédente et d'une sauvegarde incrémentielle. Il est préférable de déléguer la tâche d'économie d'espace disque, avec cette approche, à des composants spécialisés dotés de mécanismes de déduplication intégrés. Il peut s'agir de systèmes de stockage dédiés (EMC DataDomain, HPE StorageWorks VLS, toute la gamme NetApp) ou de logiciels (ZFS, Veritas NetBackup PureFile, etc.). Windows Server Déduplication des données).
Les deuxième et troisième méthodes diffèrent par le mécanisme permettant de déterminer la liste des pages modifiées. L'analyse des journaux nécessite plus de ressources et, pour la mettre en œuvre, vous devez connaître la structure des fichiers journaux. Le moyen le plus simple est de demander à la base de données elle-même quelles pages ont été modifiées, mais pour cela, le noyau du SGBD doit disposer d'une fonctionnalité de suivi des modifications de bloc.
La fonctionnalité de sauvegarde incrémentielle a été introduite pour la première fois dans le logiciel Oracle Recovery Manager (RMAN), introduit dans la version Oracle 8i. Oracle a immédiatement mis en œuvre le suivi des blocs modifiés, il n'est donc pas nécessaire d'analyser les journaux.
PostgreSQL ne suit pas les blocs modifiés, c'est pourquoi l'utilitaire pg_probackup, développé par la société russe Postgres Professional, détermine les pages modifiées en analysant le journal. Cependant, la société fournit également le SGBD PostgresPro, qui inclut l'extension ptrack qui suit les modifications de page. Lors de l'utilisation de pg_probackup avec le SGBD PostgresPro, l'utilitaire demande des pages modifiées à partir de la base de données elle-même - exactement la même chose que RMAN.
Microsoft SQL Server, comme Oracle, suit les pages modifiées, mais la commande BACKUP vous permet uniquement d'effectuer des sauvegardes complètes et cumulatives.
DB2 a la capacité de suivre les pages modifiées, mais elle est désactivée par défaut. Une fois activé, DB2 autorisera les sauvegardes complètes, différentielles et cumulatives.
Une différence importante entre les outils décrits dans cette section (sauf pg_probackup) et les outils de sauvegarde de fichiers est qu'ils demandent des images de page à la base de données plutôt que de lire eux-mêmes les données du disque. L'inconvénient de cette approche est une petite charge supplémentaire sur la base. Cependant, cet inconvénient est plus que compensé par le fait que la page lue est toujours correcte, il n'est donc pas nécessaire d'activer un mode de journalisation spécial lors de la sauvegarde.
Veuillez noter à nouveau que la présence de copies incrémentielles n'élimine pas la nécessité de disposer de journaux disponibles pour la récupération à un moment arbitraire. Par conséquent, dans les bases de données industrielles, les journaux sont constamment réécrits sur des supports externes et des sauvegardes, complètes et/ou incrémentielles, sont créées selon un calendrier.
La meilleure implémentation actuelle du concept de sauvegarde incrémentielle est l'appliance Zero Data Loss Recovery Appliance, un système matériel et logiciel (un système conçu sur mesure selon la terminologie Oracle) – une solution Oracle spécialisée pour la sauvegarde de sa propre base de données. Ce système est un cluster. les serveurs ZDLRA dispose d'une grande capacité de stockage et exécute une version modifiée du logiciel Recovery Manager. Il est compatible avec d'autres systèmes matériels et logiciels Oracle (Database Appliance, Exadata, SPARC Supercluster) ainsi qu'avec les bases de données Oracle déployées sur une infrastructure traditionnelle. Contrairement à RMAN classique, ZDLRA implémente le concept de sauvegarde incrémentale permanente. Le système crée une copie complète de la base de données une seule fois, puis effectue uniquement des copies incrémentales. Des modules RMAN supplémentaires permettent de fusionner les copies, créant ainsi de nouvelles copies complètes à partir des copies incrémentales.
Au crédit des développeurs russes, il convient de noter que pg_probackup peut également fusionner des copies incrémentielles.
Contrairement à de nombreuses questions similaires, la question « quelle méthode de sauvegarde est la meilleure » a une réponse claire : la meilleure option est un utilitaire natif du SGBD utilisé, qui offre la possibilité d'effectuer des sauvegardes incrémentielles.
Pour l'administrateur de base de données, les questions liées au choix d'une stratégie de sauvegarde et à l'intégration des outils de sauvegarde de base de données dans l'infrastructure de l'entreprise sont bien plus importantes. Mais ces questions dépassent le cadre de cet article.
Source: habr.com
