

Ás veces, para resolver un problema, só hai que miralo desde un ángulo diferente. Aínda que nos últimos 10 anos problemas semellantes foron resoltos do mesmo xeito con diferentes efectos, non é un feito que este método sexa o único.
Hai un tema como o cliente churn. A cousa é inevitable, porque os clientes de calquera empresa poden, por moitos motivos, deixar de utilizar os seus produtos ou servizos. Por suposto, para unha empresa, o churn é unha acción natural, pero non a máis desexable, polo que todos intentan minimizar este churn. Mellor aínda, prevé a probabilidade de abandono dunha determinada categoría de usuarios ou dun usuario específico e suxire algúns pasos para conservalos.
É necesario analizar e tratar de reter ao cliente, se é posible, polo menos polos seguintes motivos:
- atraer novos clientes é máis caro que os procedementos de retención. Para atraer novos clientes, por regra xeral, cómpre gastar algo de diñeiro (publicidade), mentres que os clientes existentes pódense activar cunha oferta especial con condicións especiais;
- Comprender as razóns polas que os clientes marchan é a clave para mellorar os produtos e servizos.
Existen enfoques estándar para predicir o abandono. Pero nun dos campionatos de IA, decidimos probar a distribución Weibull para iso. A miúdo úsase para análise de supervivencia, previsión do tempo, análise de desastres naturais, enxeñería industrial e similares. A distribución Weibull é unha función de distribución especial parametrizada por dous parámetros  и
и  .
.
Wikipedia
En xeral, é algo interesante, pero para a previsión de saídas, e en fintech en xeral, non se usa con tanta frecuencia. Debaixo do corte contarémosche como o fixemos nós (Data Mining Laboratory), gañando simultaneamente o ouro no Campionato de Intelixencia Artificial na categoría "AI nos Bancos".
Sobre o churn en xeral
Imos entender un pouco o que é a perda de clientes e por que é tan importante. Unha base de clientes é importante para unha empresa. Os novos clientes chegan a esta base, por exemplo, despois de coñecer un produto ou servizo a partir dunha publicidade, viven durante algún tempo (utilizan os produtos activamente) e despois dun tempo deixan de usalo. Este período chámase "Ciclo de vida do cliente", un termo que describe as etapas polas que atravesa un cliente cando se entera dun produto, toma unha decisión de compra, paga, usa e convértese nun consumidor fiel e, finalmente, deixa de usar o produto. por un ou outro motivo. En consecuencia, o churn é a etapa final do ciclo de vida do cliente, cando o cliente deixa de usar os servizos, e para unha empresa isto significa que o cliente deixou de obter beneficios ou ningún beneficio.
Cada cliente bancario é unha persoa concreta que elixe unha ou outra tarxeta bancaria especificamente para as súas necesidades. Se viaxas a miúdo, unha tarxeta con millas será útil. Compra moito: ola, tarxeta de reembolso. El compra moito en tendas específicas - e xa hai un plástico socio especial para iso. Por suposto, ás veces se selecciona unha tarxeta en función do criterio "Servizo máis barato". En xeral, aquí hai bastantes variables.
E unha persoa tamén elixe o propio banco: ten sentido elixir unha tarxeta dun banco cuxas sucursais están só en Moscova e na rexión, cando es de Khabarovsk? Aínda que unha tarxeta deste banco sexa polo menos 2 veces máis rendible, a presenza de sucursais bancarias nas proximidades segue sendo un criterio importante. Si, 2019 xa está aquí e o dixital é o noso todo, pero unha serie de problemas con algúns bancos só se poden resolver nunha sucursal. Ademais, de novo, algunha parte da poboación confía moito máis nun banco físico que nunha aplicación nun smartphone, isto tamén hai que telo en conta.
Como resultado, unha persoa pode ter moitas razóns para rexeitar produtos bancarios (ou o propio banco). Cambiei de traballo e a tarifa da tarxeta pasou de soldo a "Para simples mortais", que é menos rendible. Mudeime a outra cidade onde non hai sucursais bancarias. Non me gustou a interacción co operador non cualificado da sucursal. É dicir, pode haber aínda máis motivos para pechar unha conta que para usar o produto.
E o cliente non só pode expresar claramente a súa intención: vir ao banco e escribir unha declaración, senón simplemente deixar de usar os produtos sen rescindir o contrato. Decidiuse utilizar a aprendizaxe automática e a IA para comprender tales problemas.
Ademais, o churn de clientes pode ocorrer en calquera industria (telecomunicacións, provedores de Internet, compañías de seguros, en xeral, onde haxa unha base de clientes e transaccións periódicas).
Que fixemos
En primeiro lugar, era necesario describir un límite claro: a partir do momento en que comezamos a considerar que o cliente se foi. Desde o punto de vista do banco, que nos proporcionou datos para o traballo, o estado da actividade do cliente era binario: está activo ou non. Había unha marca ACTIVE_FLAG na táboa "Actividade", cuxo valor podía ser "0" ou "1" ("Inactivo" e "Activo", respectivamente). E todo estaría ben, pero unha persoa é tal que pode usalo activamente durante algún tempo e despois caer da lista activa durante un mes: enfermou, marchou a outro país de vacacións ou mesmo foi a probar un tarxeta doutro banco. Ou quizais despois dun longo período de inactividade, comece a utilizar de novo os servizos do banco
Polo tanto, decidimos chamar un período de inactividade a un determinado período de tempo continuo durante o cal a bandeira do mesmo se estableceu en "0".
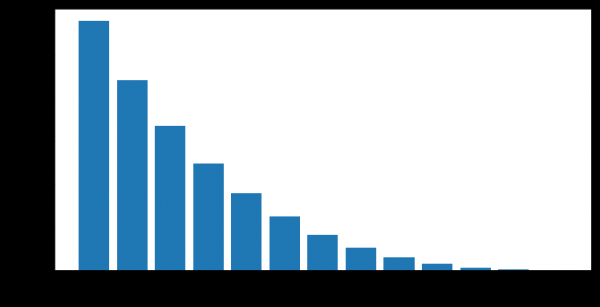
Os clientes pasan de inactivo a activo despois de períodos de inactividade de duración variable. Temos a oportunidade de calcular o grao de valor empírico "fiabilidade dos períodos de inactividade", é dicir, a probabilidade de que unha persoa comece a usar produtos bancarios de novo despois dunha inactividade temporal.
Por exemplo, este gráfico mostra a reanudación da actividade (ACTIVE_FLAG=1) dos clientes despois de varios meses de inactividade (ACTIVE_FLAG=0).
Aquí aclararemos un pouco o conxunto de datos co que comezamos a traballar. Así, o banco proporcionou información agregada durante 19 meses nas seguintes táboas:
- "Actividade" - transaccións mensuais dos clientes (por tarxetas, en banca por Internet e banca móbil), incluíndo nóminas e información sobre a facturación.
- "Tarxetas": datos sobre todas as tarxetas que ten o cliente, cunha tarifa detallada.
- "Acordos" - información sobre os acordos do cliente (tanto abertos como pechados): préstamos, depósitos, etc., indicando os parámetros de cada un.
- "Clientes" - un conxunto de datos demográficos (xénero e idade) e a dispoñibilidade de información de contacto.
Para traballar necesitabamos todas as táboas agás o "Mapa".
Houbo outra dificultade aquí: nestes datos o banco non indicaba que tipo de actividade tiña lugar nas tarxetas. É dicir, poderiamos entender se había transaccións ou non, pero xa non puidemos determinar o seu tipo. Polo tanto, non estaba claro se o cliente estaba a retirar diñeiro en efectivo, a recibir un salario ou a gastar o diñeiro en compras. Tampouco tiñamos datos sobre os saldos das contas, que serían útiles.
A mostra en si foi imparcial: nesta mostra, ao longo de 19 meses, o banco non fixo ningún intento de reter clientes e minimizar a saída.
Entón, sobre períodos de inactividade.
Para formular unha definición de churn, debe seleccionarse un período de inactividade. Para crear unha previsión de abandono nun momento determinado  , debes ter un historial de clientes de polo menos 3 meses a intervalos
, debes ter un historial de clientes de polo menos 3 meses a intervalos  . O noso historial limitouse a 19 meses, polo que decidimos levar un período de inactividade de 6 meses, se está dispoñible. E para o período mínimo para unha previsión de alta calidade, levamos 3 meses. Tomamos as cifras durante 3 e 6 meses empíricamente baseándonos nunha análise do comportamento dos datos dos clientes.
. O noso historial limitouse a 19 meses, polo que decidimos levar un período de inactividade de 6 meses, se está dispoñible. E para o período mínimo para unha previsión de alta calidade, levamos 3 meses. Tomamos as cifras durante 3 e 6 meses empíricamente baseándonos nunha análise do comportamento dos datos dos clientes.
Formulamos a definición de churn do seguinte xeito: mes de abandono do cliente  este é o primeiro mes con ACTIVE_FLAG=0, onde a partir deste mes hai polo menos seis ceros consecutivos no campo ACTIVE_FLAG, é dicir, o mes desde o que o cliente estivo inactivo durante 6 meses.
este é o primeiro mes con ACTIVE_FLAG=0, onde a partir deste mes hai polo menos seis ceros consecutivos no campo ACTIVE_FLAG, é dicir, o mes desde o que o cliente estivo inactivo durante 6 meses.
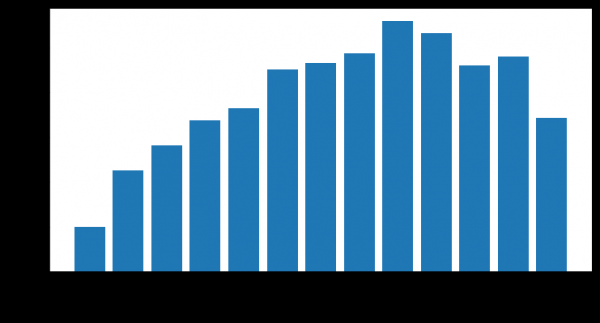
Número de clientes que saíron
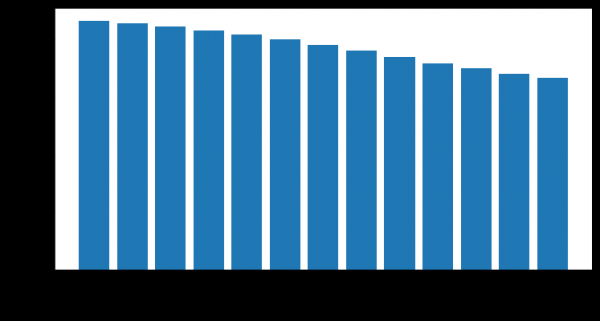
Número de clientes restantes
Como se calcula o churn?
En tales competicións, e na práctica en xeral, a saída adoita prever deste xeito. O cliente utiliza produtos e servizos en diferentes períodos de tempo, os datos sobre a interacción con el represéntanse como un vector de características dunha lonxitude fixa n. Na maioría das veces, esta información inclúe:
- Datos que caracterizan ao usuario (datos demográficos, segmento de mercadotecnia).
- Historial do uso de produtos e servizos bancarios (son accións do cliente que sempre están ligadas a un momento ou período concreto do intervalo que necesitamos).
- Datos externos, se fose posible obtelos - por exemplo, comentarios das redes sociais.
E despois diso, derivan unha definición de churn, diferente para cada tarefa. Despois usan un algoritmo de aprendizaxe automática, que prevé a probabilidade de que un cliente marche  baseado nun vector de factores
baseado nun vector de factores  . Para adestrar o algoritmo, utilízase un dos marcos coñecidos para construír conxuntos de árbores de decisión, , , ou modificacións dos mesmos.
. Para adestrar o algoritmo, utilízase un dos marcos coñecidos para construír conxuntos de árbores de decisión, , , ou modificacións dos mesmos.
O algoritmo en si non é malo, pero ten varias desvantaxes graves á hora de prever o abandono.
- Non ten a chamada "memoria". A entrada do modelo é un número especificado de características que corresponden ao momento actual. Para almacenar información sobre o historial de cambios nos parámetros, é necesario calcular características especiais que caracterizan os cambios nos parámetros ao longo do tempo, por exemplo, o número ou a cantidade de transaccións bancarias nos últimos 1,2,3, XNUMX, XNUMX meses. Este enfoque só pode reflectir parcialmente a natureza dos cambios temporais.
- Horizonte de previsión fixo. O modelo só é capaz de prever a rotación dos clientes durante un período de tempo predefinido, por exemplo, unha previsión cun mes de antelación. Se se require unha previsión para un período de tempo diferente, por exemplo, tres meses, entón cómpre reconstruír o conxunto de adestramento e volver adestrar un novo modelo.
O noso enfoque
Decidimos de inmediato que non utilizaríamos enfoques estándar. Ademais de nós, no campionato inscribíronse 497 persoas máis, cada unha das cales contaba cunha considerable experiencia ás súas costas. Polo tanto, tentar facer algo segundo un esquema estándar en tales condicións non é unha boa idea.
E comezamos a resolver os problemas aos que se enfronta o modelo de clasificación binaria predindo a distribución de probabilidade dos tempos de abandono dos clientes. Pódese ver un enfoque similar , permítelle predecir o churn de forma máis flexible e probar hipóteses máis complexas que no enfoque clásico. Como unha familia de distribucións que modelan o tempo de saída, escollemos a distribución polo seu uso xeneralizado na análise de supervivencia. O comportamento do cliente pódese ver como unha especie de supervivencia.
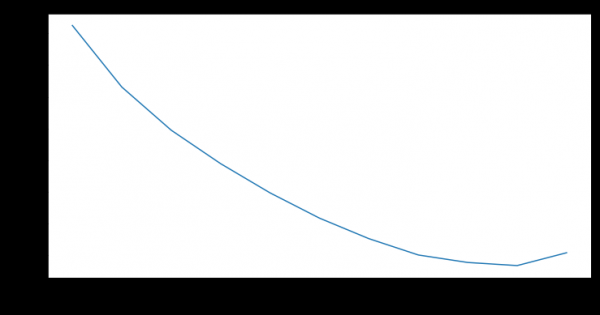
Aquí tes exemplos de distribucións de densidade de probabilidade de Weibull dependendo dos parámetros  и
и  :
:
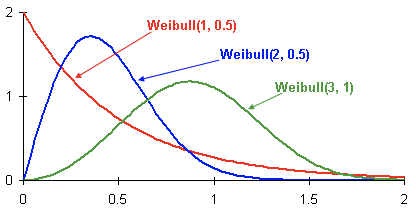
Esta é a función de densidade de probabilidade de tres clientes diferentes ao longo do tempo. O tempo preséntase en meses. Noutras palabras, este gráfico mostra cando un cliente ten máis probabilidades de perder nos próximos dous meses. Como podes ver, un cliente cunha distribución ten un maior potencial para saír antes que os clientes con Weibull(2, 0.5) e Weibull. (3,1) distribucións.
O resultado é un modelo que, para cada cliente, para cada
mes predice os parámetros da distribución de Weibull, que mellor reflicte a aparición da probabilidade de saída ao longo do tempo. Máis en detalle:
- As funcións obxectivo do conxunto de adestramento son o tempo que queda ata que se desexen nun mes específico para un cliente específico.
- Se non hai taxa de abandono para un cliente, supoñemos que o tempo de abandono é maior que o número de meses desde o mes actual ata o final do historial que temos.
- Modelo utilizado: rede neuronal recorrente con capa LSTM.
- Como función de perda, usamos a función de verosimilitud negativa para a distribución de Weibull.
Aquí están as vantaxes deste método:
- A distribución de probabilidade, ademais da posibilidade obvia de clasificación binaria, permite unha predición flexible de varios eventos, por exemplo, se un cliente deixará de usar os servizos do banco dentro de 3 meses. Ademais, se é necesario, pódense promediar varias métricas sobre esta distribución.
- A rede neuronal recorrente LSTM ten memoria e utiliza de forma eficaz todo o historial dispoñible. A medida que a historia se amplía ou se refina, a precisión aumenta.
- O enfoque pódese escalar facilmente ao dividir períodos de tempo en outros máis pequenos (por exemplo, ao dividir meses en semanas).
Pero non abonda con crear un bo modelo; tamén hai que avaliar adecuadamente a súa calidade.
Como se avaliou a calidade?
Escollemos a curva de elevación como métrica. Utilízase nos negocios para tales casos debido á súa clara interpretación, está ben descrito и . Se describes o significado desta métrica nunha frase, sería "Cantas veces fai o algoritmo a mellor predición na primeira  % que ao azar."
% que ao azar."
Modelos de formación
As condicións da competencia non estableceron unha métrica de calidade específica pola que se poidan comparar diferentes modelos e enfoques. Ademais, a definición de churn pode ser diferente e pode depender da declaración do problema, que, á súa vez, está determinada polos obxectivos empresariais. Polo tanto, para comprender que método é mellor, adestramos dous modelos:
- Unha aproximación de clasificación binaria de uso común que utiliza un algoritmo de aprendizaxe automática de árbore de decisións de conxunto ();
- Modelo Weibull-LSTM
O conxunto de probas estaba composto por 500 clientes preseleccionados que non estaban no conxunto de adestramento. Seleccionáronse hiperparámetros para o modelo mediante validación cruzada, desglosados por cliente. Utilizáronse os mesmos conxuntos de funcións para adestrar cada modelo.
Debido ao feito de que o modelo non ten memoria, tomáronse características especiais para el, mostrando a relación entre os cambios nos parámetros durante un mes e o valor medio dos parámetros nos últimos tres meses. O que caracterizou a taxa de variación dos valores durante o último período de tres meses. Sen isto, o modelo baseado en Random Forest estaría en desvantaxe con respecto a Weibull-LSTM.
Por que LSTM con distribución Weibull é mellor que un enfoque de árbore de decisión de conxunto
Aquí está todo claro en só un par de imaxes.
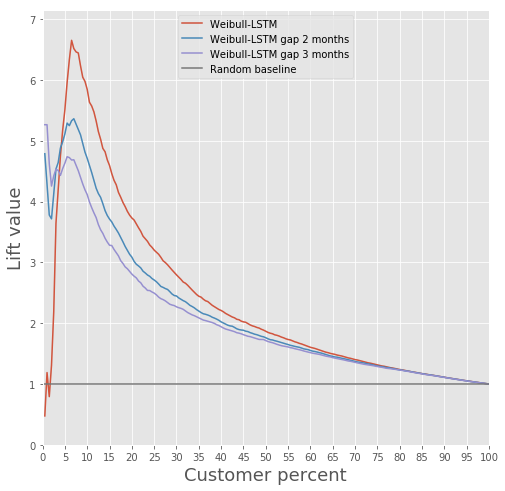
Comparación da curva de elevación para o algoritmo clásico e Weibull-LSTM
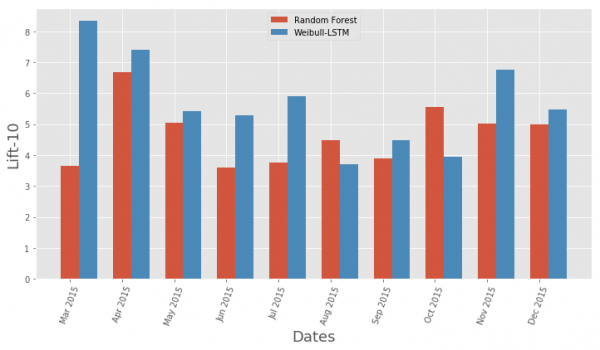
Comparación da métrica da curva de elevación por mes para o algoritmo clásico e Weibull-LSTM
En xeral, LSTM é superior ao algoritmo clásico en case todos os casos.
Predición de churn
Un modelo baseado nunha rede neuronal recorrente con células LSTM con distribución Weibull pode predecir a rotación con antelación, por exemplo, predecir a rotación dos clientes nos próximos n meses. Considere o caso de n = 3. Neste caso, para cada mes, a rede neuronal debe determinar correctamente se o cliente marchará, a partir do mes seguinte e ata o mes enésimo. Noutras palabras, debe determinar correctamente se o cliente permanecerá despois de n meses. Isto pódese considerar unha previsión anticipada: prever o momento no que o cliente comezaba a pensar en marchar.
Comparemos a curva de elevación para Weibull-LSTM 1, 2 e 3 meses antes da saída:
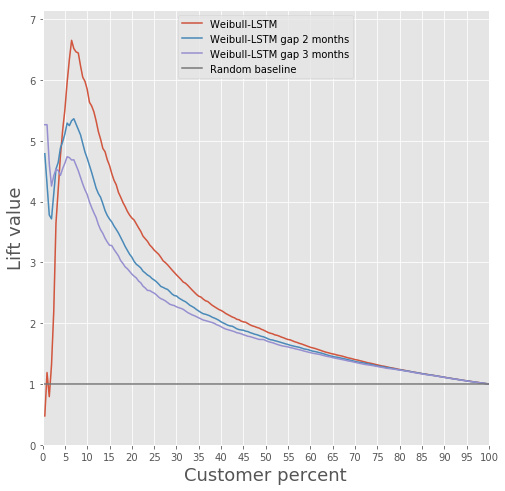
Xa escribimos anteriormente que tamén son importantes as previsións realizadas para os clientes que xa hai tempo que non están activos. Polo tanto, aquí engadiremos á mostra os casos nos que o cliente que se foi xa estivo inactivo durante un ou dous meses e comprobaremos que Weibull-LSTM clasifique correctamente tales casos como abandono. Dado que estes casos estaban presentes na mostra, esperamos que a rede os xestione ben:
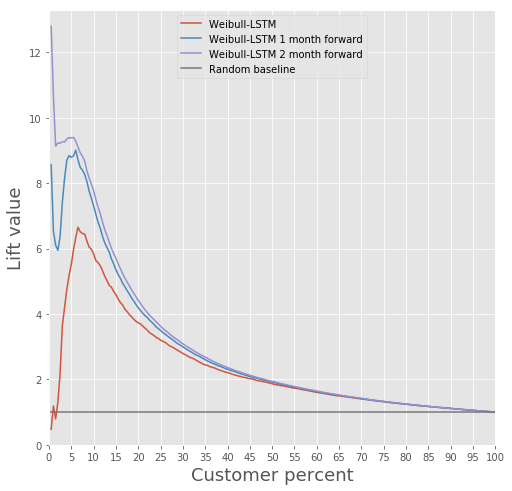
Retención de clientes
En realidade, isto é o principal que se pode facer, tendo na man a información de que tales clientes se están preparando para deixar de usar o produto. Falando de construír un modelo que poida ofrecer algo útil aos clientes para conservalos, non se pode facer se non se ten un historial de intentos similares que acabarían ben.
Non tiñamos tal historia, así que decidimos así.
- Estamos construíndo un modelo que identifique produtos interesantes para cada cliente.
- Todos os meses executamos o clasificador e identificamos clientes potencialmente abandonados.
- Ofrecemos a algúns clientes o produto, segundo o modelo do punto 1, e lembramos as nosas accións.
- Despois duns meses, miramos cal destes clientes potencialmente abandonados deixou e cales quedaron. Así, formamos unha mostra de formación.
- Adestramos o modelo utilizando o historial obtido no paso 4.
- Opcionalmente, repetimos o procedemento, substituíndo o modelo do paso 1 polo modelo obtido no paso 5.
Pódese facer unha proba da calidade desta retención mediante probas A/B regulares: dividimos os clientes que potencialmente abandonan en dous grupos. Ofrecémoslle produtos a un segundo o noso modelo de retención e ao outro non ofrecemos nada. Decidimos formar un modelo que podería ser útil xa no punto 1 do noso exemplo.
Queriamos facer a segmentación o máis interpretable posible. Para iso, escollemos varias características que poderían ser facilmente interpretadas: o número total de transaccións, os salarios, a rotación total da conta, a idade, o sexo. As características da táboa "Mapas" non se tiveron en conta como pouco informativas e as características da táboa 3 "Contratos" non se tiveron en conta debido á complexidade do procesamento para evitar a fuga de datos entre o conxunto de validación e o conxunto de formación.
A agrupación realizouse mediante modelos de mesturas gaussianas. O criterio de información de Akaike permitiunos determinar 2 óptimos. O primeiro óptimo corresponde a 1 cluster. O segundo óptimo, menos pronunciado, corresponde a 80 grupos. En base a este resultado, podemos extraer a seguinte conclusión: é extremadamente difícil dividir os datos en clusters sen unha información a priori dada. Para unha mellor agrupación, necesitas datos que describan cada cliente en detalle.
Polo tanto, considerouse o problema da aprendizaxe supervisada para ofrecer a cada cliente individual un produto diferente. Consideráronse os seguintes produtos: "Depósito a prazo", "Tarxeta de crédito", "Descubierto", "Préstamo de consumo", "Préstamo de coche", "Hipoteca".
Os datos incluían un tipo máis de produto: "Conta corrente". Pero non o consideramos debido ao seu baixo contido informativo. Para usuarios que son clientes bancarios, é dicir. non deixou de usar os seus produtos, construíuse un modelo para predicir que produto podería ser do seu interese. Elixiuse a regresión loxística como modelo e utilizouse o valor Lift para os primeiros 10 percentiles como métrica de avaliación da calidade.
A calidade do modelo pódese avaliar na figura.
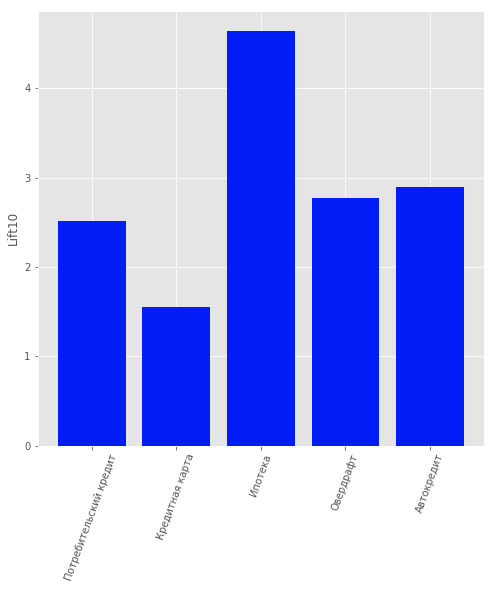
Resultados do modelo de recomendación de produtos para os clientes
Total
Este enfoque levounos o primeiro lugar na categoría "AI en bancos" no Campionato de IA RAIF-Challenge 2017.

Ao parecer, o principal era abordar o problema desde un ángulo non convencional e utilizar un método que se adoita empregar para outras situacións.
Aínda que unha saída masiva de usuarios pode ser un desastre natural para os servizos.
Este método pódese ter en conta para calquera outra área onde sexa importante ter en conta a saída, non só os bancos. Por exemplo, usámolo para calcular o noso propio fluxo de saída - nas sucursais de Rostelecom en Siberia e San Petersburgo.
Empresa "Data Mining Laboratory" "Portal de busca "Sputnik"
Fonte: www.habr.com
