

Izvor:
Linearna regresija je jedan od osnovnih algoritama za mnoga područja vezana uz analizu podataka. Razlog tome je očit. Ovo je vrlo jednostavan i razumljiv algoritam, koji je pridonio njegovoj širokoj upotrebi desetcima, ako ne i stotinama godina. Ideja je da pretpostavimo linearnu ovisnost jedne varijable o skupu drugih varijabli, a zatim pokušamo vratiti tu ovisnost.
Ali ovaj članak ne govori o korištenju linearne regresije za rješavanje praktičnih problema. Ovdje ćemo razmotriti zanimljive značajke implementacije distribuiranih algoritama za njegov oporavak, na koje smo naišli prilikom pisanja modula strojnog učenja u . Malo osnovne matematike, strojnog učenja i distribuiranog računalstva može vam pomoći da shvatite kako izvesti linearnu regresiju čak i kada su vaši podaci raspoređeni na tisuće čvorova.
O čemu pričamo?
Suočeni smo sa zadatkom ponovnog uspostavljanja linearne ovisnosti. Kao ulazni podatak zadan je skup vektora navodno nezavisnih varijabli od kojih je svakoj pridružena određena vrijednost zavisne varijable. Ovi podaci se mogu prikazati u obliku dvije matrice:

Budući da je ovisnost pretpostavljena, a uz to i linearna, pretpostavku ćemo napisati u obliku umnoška matrica (radi pojednostavljenja zapisa, ovdje i dolje se pretpostavlja da se slobodni član jednadžbe krije iza  , i posljednji stupac matrice
, i posljednji stupac matrice  sadrži jedinice):
sadrži jedinice):

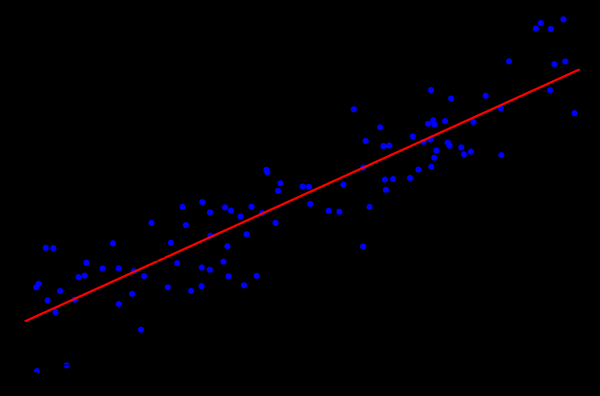
Zvuči dosta poput sustava linearnih jednadžbi, zar ne? Čini se, ali najvjerojatnije neće biti rješenja za takav sustav jednadžbi. Razlog tome je šum, koji je prisutan u gotovo svim stvarnim podacima. Drugi razlog može biti nepostojanje linearne ovisnosti kao takve, protiv čega se može boriti uvođenjem dodatnih varijabli koje nelinearno ovise o izvornim. Razmotrite sljedeći primjer:
Izvor:
Ovo je jednostavan primjer linearne regresije koji pokazuje odnos jedne varijable (duž osi  ) iz druge varijable (duž osi
) iz druge varijable (duž osi  ). Da bi sustav linearnih jednadžbi koji odgovara ovom primjeru imao rješenje, sve točke moraju ležati točno na istoj ravnoj liniji. Ali to nije istina. Ali oni ne leže na istoj ravnoj liniji upravo zbog šuma (ili zato što je pretpostavka o linearnom odnosu bila pogrešna). Dakle, da bi se obnovio linearni odnos iz stvarnih podataka, obično je potrebno uvesti još jednu pretpostavku: ulazni podaci sadrže šum i taj šum ima . Možete napraviti pretpostavke o drugim vrstama distribucije buke, ali u velikoj većini slučajeva u obzir se uzima normalna distribucija, o čemu ćemo dalje raspravljati.
). Da bi sustav linearnih jednadžbi koji odgovara ovom primjeru imao rješenje, sve točke moraju ležati točno na istoj ravnoj liniji. Ali to nije istina. Ali oni ne leže na istoj ravnoj liniji upravo zbog šuma (ili zato što je pretpostavka o linearnom odnosu bila pogrešna). Dakle, da bi se obnovio linearni odnos iz stvarnih podataka, obično je potrebno uvesti još jednu pretpostavku: ulazni podaci sadrže šum i taj šum ima . Možete napraviti pretpostavke o drugim vrstama distribucije buke, ali u velikoj većini slučajeva u obzir se uzima normalna distribucija, o čemu ćemo dalje raspravljati.
Metoda najveće vjerojatnosti
Dakle, pretpostavili smo prisutnost slučajnog normalno distribuiranog šuma. Što učiniti u takvoj situaciji? Za ovaj slučaj u matematici postoji i široko se koristi . Ukratko, njegova bit leži u izboru i njegovo naknadno maksimiziranje.
Vraćamo se obnavljanju linearnog odnosa iz podataka s normalnim šumom. Imajte na umu da je pretpostavljeni linearni odnos matematičko očekivanje  postojeće normalne distribucije. Istodobno, vjerojatnost da
postojeće normalne distribucije. Istodobno, vjerojatnost da  poprima jednu ili drugu vrijednost, ovisno o prisutnosti vidljivih vrijednosti
poprima jednu ili drugu vrijednost, ovisno o prisutnosti vidljivih vrijednosti  , izgleda ovako:
, izgleda ovako:

Zamijenimo sada umjesto toga  и
и  Varijable koje su nam potrebne su:
Varijable koje su nam potrebne su:

Ostaje samo pronaći vektor  , pri čemu je ta vjerojatnost najveća. Da bi se maksimizirala takva funkcija, zgodno je prvo uzeti njen logaritam (logaritam funkcije će dosegnuti maksimum u istoj točki kao i sama funkcija):
, pri čemu je ta vjerojatnost najveća. Da bi se maksimizirala takva funkcija, zgodno je prvo uzeti njen logaritam (logaritam funkcije će dosegnuti maksimum u istoj točki kao i sama funkcija):

Što se pak svodi na minimiziranje sljedeće funkcije:

Usput, ovo se zove metoda . Često su sva gore navedena razmatranja izostavljena i jednostavno se koristi ova metoda.
QR dekompozicija
Minimum gornje funkcije može se pronaći pronalaskom točke u kojoj je gradijent te funkcije nula. A gradijent će biti napisan na sljedeći način:

je matrična metoda za rješavanje problema minimizacije koja se koristi u metodi najmanjih kvadrata. U tom smislu, prepisujemo jednadžbu u matričnom obliku:

Dakle, rastavljamo matricu  na matrice
na matrice  и
и  i izvršiti niz transformacija (sam algoritam QR dekompozicije ovdje nećemo razmatrati, samo njegovu upotrebu u odnosu na zadatak):
i izvršiti niz transformacija (sam algoritam QR dekompozicije ovdje nećemo razmatrati, samo njegovu upotrebu u odnosu na zadatak):

Matrica  je ortogonalna. To nam omogućuje da se riješimo posla
je ortogonalna. To nam omogućuje da se riješimo posla  :
:

A ako zamijenite  na
na  , onda će uspjeti
, onda će uspjeti  . S obzirom na to
. S obzirom na to  je gornja trokutasta matrica, izgleda ovako:
je gornja trokutasta matrica, izgleda ovako:

To se može riješiti metodom supstitucije. Element  nalazi se kao
nalazi se kao  , prethodni element
, prethodni element  nalazi se kao
nalazi se kao  i tako dalje.
i tako dalje.
Ovdje je vrijedno napomenuti da je složenost rezultirajućeg algoritma zbog upotrebe QR dekompozicije jednaka  . Štoviše, unatoč činjenici da je operacija množenja matrice dobro paralelizirana, nije moguće napisati učinkovitu distribuiranu verziju ovog algoritma.
. Štoviše, unatoč činjenici da je operacija množenja matrice dobro paralelizirana, nije moguće napisati učinkovitu distribuiranu verziju ovog algoritma.
Gradijentni silazak
Kada govorimo o minimiziranju funkcije, uvijek se vrijedi sjetiti metode (stohastičkog) gradijentnog spuštanja. Ovo je jednostavna i učinkovita metoda minimizacije koja se temelji na iterativnom izračunavanju gradijenta funkcije u točki i zatim njezinom pomicanju u smjeru suprotnom od gradijenta. Svaki takav korak približava rješenje minimumu. Gradijent i dalje izgleda isto:

Ova metoda je također dobro paralelizirana i distribuirana zbog linearnih svojstava operatora gradijenta. Imajte na umu da se u gornjoj formuli ispod znaka zbroja nalaze nezavisni članovi. Drugim riječima, gradijent možemo izračunati neovisno za sve indekse  od prvog do
od prvog do  , paralelno s tim izračunajte gradijent za indekse s
, paralelno s tim izračunajte gradijent za indekse s  na
na  . Zatim dodajte dobivene gradijente. Rezultat zbrajanja bit će isti kao da smo odmah izračunali gradijent za indekse od prvog do
. Zatim dodajte dobivene gradijente. Rezultat zbrajanja bit će isti kao da smo odmah izračunali gradijent za indekse od prvog do  . Stoga, ako su podaci raspoređeni među nekoliko dijelova podataka, gradijent se može izračunati neovisno o svakom dijelu, a zatim se rezultati tih izračuna mogu zbrojiti kako bi se dobio konačni rezultat:
. Stoga, ako su podaci raspoređeni među nekoliko dijelova podataka, gradijent se može izračunati neovisno o svakom dijelu, a zatim se rezultati tih izračuna mogu zbrojiti kako bi se dobio konačni rezultat:

Sa stajališta implementacije, ovo odgovara paradigmi . U svakom koraku spuštanja gradijenta, zadatak se šalje svakom podatkovnom čvoru za izračun gradijenta, zatim se izračunati gradijenti prikupljaju zajedno, a rezultat njihovog zbroja koristi se za poboljšanje rezultata.
Unatoč jednostavnosti implementacije i mogućnosti izvođenja u MapReduce paradigmi, gradijentni silazak također ima svoje nedostatke. Konkretno, broj koraka potrebnih za postizanje konvergencije značajno je veći u usporedbi s drugim specijaliziranijim metodama.
LSQR
je još jedna metoda za rješavanje problema, koja je prikladna i za obnavljanje linearne regresije i za rješavanje sustava linearnih jednadžbi. Njegova glavna značajka je da kombinira prednosti matričnih metoda i iterativnog pristupa. Implementacije ove metode mogu se pronaći u obje knjižnice , i u . Ovdje neće biti dat opis ove metode (može se naći u članku ). Umjesto toga, demonstrirat će se pristup prilagođavanja LSQR-a za izvođenje u distribuiranom okruženju.
Metoda LSQR temelji se na . Ovo je iterativni postupak, a svako se ponavljanje sastoji od sljedećih koraka:

Ali ako pretpostavimo da matrica  je horizontalno podijeljen, tada se svaka iteracija može predstaviti kao dva MapReduce koraka. Na taj način je moguće minimizirati prijenose podataka tijekom svake iteracije (samo vektori čija je duljina jednaka broju nepoznanica):
je horizontalno podijeljen, tada se svaka iteracija može predstaviti kao dva MapReduce koraka. Na taj način je moguće minimizirati prijenose podataka tijekom svake iteracije (samo vektori čija je duljina jednaka broju nepoznanica):
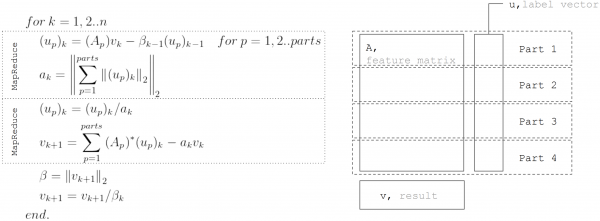
Upravo se ovaj pristup koristi pri implementaciji linearne regresije u .
Zaključak
Postoji mnogo algoritama za oporavak linearne regresije, ali ne mogu se svi primijeniti u svim uvjetima. Stoga je QR dekompozicija izvrsna za točna rješenja na malim skupovima podataka. Gradijentni silazak jednostavan je za implementaciju i omogućuje vam brzo pronalaženje približnog rješenja. A LSQR kombinira najbolja svojstva prethodna dva algoritma, budući da se može distribuirati, konvergira brže u usporedbi s gradijentnim spuštanjem, a također omogućuje rano zaustavljanje algoritma, za razliku od QR dekompozicije, kako bi se pronašlo približno rješenje.
Izvor: www.habr.com
