

A Heisenberg-féle bizonytalansági elv kimondja, hogy nem lehet egyszerre mérni egy objektum helyzetét és sebességét. Ha egy tárgy mozog, akkor nincs helye. És ha van hely, az azt jelenti, hogy nincs sebessége.

Ami a Red Hat OpenShift platformon (és a Kuberneteset futtató) található mikroszolgáltatásokat illeti, a megfelelő nyílt forráskódú szoftvernek köszönhetően egyszerre tudnak beszámolni teljesítményükről és állapotukról. Ez persze nem cáfolja a régi Heisenberget, de kiküszöböli a bizonytalanságot a felhőalkalmazásokkal való munka során. Az Istio megkönnyíti ezen alkalmazások nyomon követését és felügyeletét, hogy mindent kézben tarthasson.
Döntés a terminológiáról
Alatt nyomon követése (Nyomkövetés) értjük a rendszertevékenység naplózását. Ez meglehetősen általánosan hangzik, de valójában az egyik alapvető szabály itt az, hogy a nyomkövetési adatokat a megfelelő tárolóba kell helyezni anélkül, hogy aggódna a formázás miatt. Az adatok keresésének és elemzésének minden munkája pedig a fogyasztóra hárul. Az Istio a Jaeger nyomkövetési rendszert használja, amely az OpenTracing adatmodellt valósítja meg.
Az ösvényeken (Nyomok, és a „nyomok” szót itt „nyomok” értelemben használjuk, mint például a ballisztikai vizsgálatnál) olyan adatokat fogunk nevezni, amelyek teljes mértékben leírják egy kérés vagy egy munkaegység áthaladását, ahogy mondani szokás, "tól és odáig." Például minden, ami attól a pillanattól kezdve, hogy a felhasználó egy weboldalon lévő gombra kattint, az adatok visszaadásáig történik, beleértve az összes érintett mikroszolgáltatást is. Azt mondhatjuk, hogy az egyik nyom teljesen leírja (vagy modellezi) egy kérés oda-vissza útját. A Jaeger interfészben a nyomok az időtengely mentén komponensekre bonthatók, hasonlóan ahhoz, ahogy egy láncot egyedi linkekre lehet bontani. Csak a linkek helyett az útvonal úgynevezett spanokból áll.
Span a munkaegység kezdetétől annak befejezéséig eltelt idő. Folytatva a hasonlatot, azt mondhatjuk, hogy minden szakasz egy külön láncszemet jelent. Egy szakasznak lehet (vagy nem) egy vagy több alárendelt tartománya. Következésképpen a legfelső fesztáv (gyökértartomány) teljes időtartama megegyezik a hozzá tartozó nyomvonal teljes időtartamával.
megfigyelés - ez valójában a rendszer megfigyelése - a szemével, a felhasználói felületen vagy az automatizálási eszközökön keresztül. A megfigyelés nyomkövetési adatokon alapul. Az Istióban a felügyelet a Prometheus segítségével valósul meg, és megfelelő felhasználói felülettel rendelkezik. A Prometheus támogatja az automatikus felügyeletet riasztások és riasztáskezelők segítségével.
Nyomokat hagyunk
Ahhoz, hogy a nyomkövetés lehetséges legyen, az alkalmazásnak létre kell hoznia egy tartománygyűjteményt. Ezután exportálni kell őket a Jaegerbe, hogy az viszont vizuálisan ábrázolja a nyomot. Többek között ezek a szakaszok jelzik a művelet nevét, valamint a kezdési és befejezési időbélyegeket. A szakaszok átvitele a Jaeger-specifikus HTTP-kérelem fejlécek továbbításával történik a bejövő kérésekről a kimenő kérésekre. A használt programozási nyelvtől függően ez kisebb módosításokat tehet szükségessé az alkalmazás forráskódjában. Az alábbiakban egy Java-mintakód található (a Spring Boot keretrendszer használatával), amely B3-as (Zipkin-stílusú) fejléceket ad a kéréséhez a Spring konfigurációs osztályban:

A következő fejlécbeállítások használatosak:
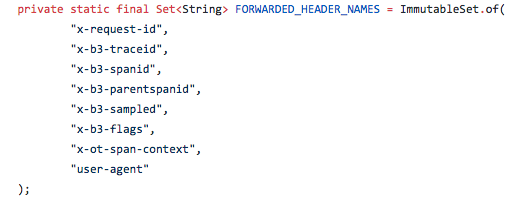
Ha Java-t használ, hagyja békén a kódot, és csak néhány sort adjon a Maven POM fájlhoz, és beállíthatja a környezeti változókat. A következő sorokat kell hozzáadnia a POM.XML fájlhoz a Jaeger Tracer Resolver megvalósításához:

És a megfelelő környezeti változók a Dockerfile-ban vannak beállítva:

Ennyi, most minden be van állítva, és mikroszolgáltatásaink elkezdenek nyomkövetési adatokat generálni.
Nézzük általánosságban
Az Istio tartalmaz egy egyszerű, Grafana alapú vezérlőpanelt. Miután minden be van állítva és fut a Red Hat OpenShift PaaS platformon (példánkban a Red Hat OpenShift és a Kubernetes minishiftre van telepítve), ez a panel a következő paranccsal indul:
open "$(minishift openshift service grafana -u)/d/1/istio-dashboard?refresh=5⩝Id=1"
A Grafana panel lehetővé teszi a rendszer teljesítményének gyors értékelését. Ennek a panelnek egy részlete látható az alábbi ábrán:
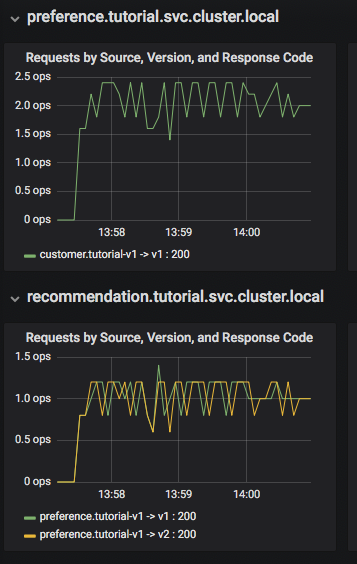
Itt látható, hogy az ügyfél mikroszolgáltatása a preferencia v1 mikroszolgáltatást hívja, amely viszont az ajánlást v1 és v2 mikroszolgáltatásnak hívja. A Grafana panel rendelkezik egy Dashboard Row blokkkal a magas szintű mérőszámokhoz, például a kérések teljes számához (Global Request Volume), a sikerarányokhoz, a 4xx hibákhoz. Ezenkívül van egy Server Mesh nézet, amely grafikonokat tartalmaz minden szolgáltatáshoz, és egy Szolgáltatássor blokk, amely az egyes szolgáltatásokhoz tartozó tárolókra vonatkozó részletes információkat tekinthet meg.
Most ássunk mélyebbre
A megfelelően konfigurált nyomkövetéssel az Istio, ahogy mondani szokták, azonnal lehetővé teszi, hogy mélyebben elmélyüljön a rendszer teljesítményének elemzésében. A Jaeger felhasználói felületén megtekintheti a nyomokat, és megnézheti, milyen messzire és mélyre mennek, valamint vizuálisan lokalizálhatja a teljesítmény szűk keresztmetszeteit. Ha a Red Hat OpenShiftet minishift platformon használja, indítsa el a Jaeger UI-t a következő paranccsal:
minishift openshift service jaeger-query --in-browser
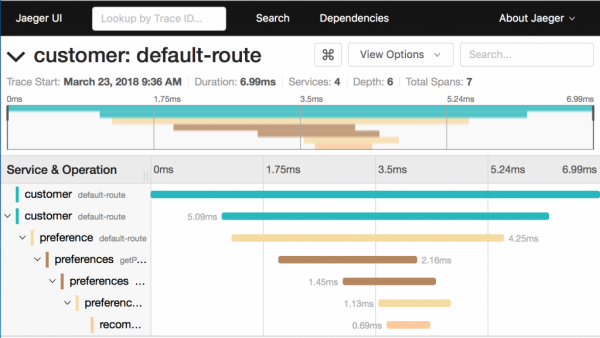
Mit tud mondani a követésről ezen a képernyőn:
- 7 szakaszra oszlik.
- A teljes végrehajtási idő 6.99 ms.
- Az ajánlási mikroszolgáltatás, amely az utolsó a láncban, 0.69 ms-ot tölt.
Az ilyen típusú diagramok lehetővé teszik, hogy gyorsan megértse azt a helyzetet, amikor egy rosszul működő szolgáltatás miatt a teljes rendszer teljesítménye megsérül.
Most bonyolítsuk le a feladatot, és indítsuk el az ajánlás két példányát: v2 mikroszolgáltatás az oc skála paranccsal —replicas=2 deployment/recommendation-v2. Íme a készletünk ezek után:
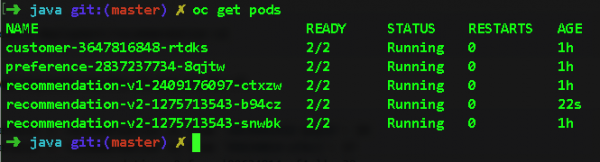
Ha most visszaváltunk a Jaegerre, és kibővítjük az ajánlási szolgáltatás terjedelmét, láthatjuk, hogy a kérelmek melyik podba vannak irányítva. Így könnyen lokalizálhatjuk a fékeket egy adott pod szintjén. Ebben az esetben meg kell néznie a node_id mezőt:

Hol és hogyan megy minden
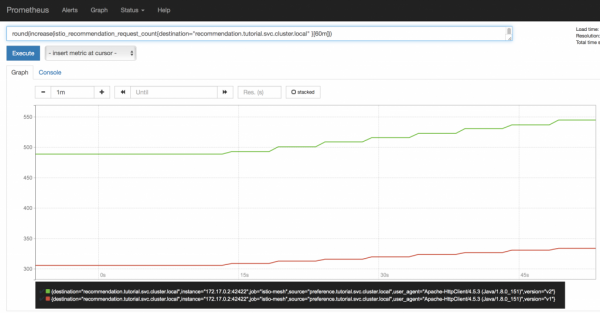
Most megyünk a Prometheus felületre, és ott várhatóan azt látjuk, hogy az ajánló szolgáltatás második és első verziója között a kérések 2:1 arányban oszlanak meg, szigorúan a működő podok száma szerint. Sőt, ez a grafikon dinamikusan fog változni, ahogy a pod-ok felfelé és lefelé skálázódnak, ami különösen hasznos lesz a Canary Deployment esetében (legközelebb ezt a telepítési sémát fogjuk közelebbről megvizsgálni).
Még csak most kezdődik
Valójában ma, ahogy mondani szokták, csak a felszínét kapargattuk a Jaegerről, Grafanáról és Prométheuszról szóló hasznos információk tárházának. Általában ez volt a célunk – hogy a helyes irányba mutassuk Önt, és megnyissa a kilátásokat Istio előtt.
És ne feledd, mindez már be van építve az Istioba. Bizonyos programozási nyelvek (például Java) és keretrendszerek (például Spring Boot) használatakor mindez megvalósítható anélkül, hogy magát az alkalmazáskódot érintené. Igen, a kódot kissé módosítani kell, ha más nyelveket használ, elsősorban Nodejs-t vagy C#-t. De mivel a nyomon követhetőség (értsd: „nyomkövetés”) a megbízható felhőrendszerek létrehozásának egyik előfeltétele, a kódot mindenképpen szerkeszteni kell, akár van Istio, akár nincs. Miért ne fordíthatná erőfeszítéseit jobban?
Legalább azért, hogy mindig válaszoljon a „hol?” kérdésekre. és milyen gyorsan? 100%-os biztonsággal.
Káoszmérnökség az Istióban: így tervezték
A dolgok törésének képessége segít megakadályozni, hogy eltörjenek.
A szoftvertesztelés nem csak nehéz, de fontos is. Ugyanakkor a helyesség tesztelése (például, hogy egy függvény a helyes eredményt adja-e vissza) egy dolog, de egy megbízhatatlan hálózatban teljesen más feladat (gyakran feltételezik, hogy a hálózat mindig hiba nélkül működik, és ez az első az elosztott számításokkal kapcsolatos nyolc tévhit közül). A probléma megoldásának egyik nehézsége az, hogy hogyan lehet szimulálni a rendszer meghibásodásait, vagy szándékosan bevezetni, úgynevezett hibabefecskendezéssel. Ezt magának az alkalmazásnak a forráskódjának módosításával lehet megtenni. De akkor már nem az eredeti kódot fogja tesztelni, hanem annak egy olyan verzióját, amely kifejezetten a hibákat szimulálja. Ennek eredményeként fennáll annak a veszélye, hogy beleesik a hibabefecskendezés halálos ölelésébe, és Heisenbugokkal találkozik – olyan hibák, amelyek eltűnnek, amikor megpróbálja észlelni őket.
Most megmutatjuk, hogyan segít az Istio egy darabban kezelni ezeket a bonyolultságokat.
Hogy néz ki minden, amikor minden nagyszerű?
Tekintsük a következő forgatókönyvet: két pod van az ajánló mikroszolgáltatásunkhoz, amelyet az Istio oktatóanyagból vettünk át. Az egyik pod címkéje v1, a másik pedig v2. Mint látható, eddig minden jól működik:
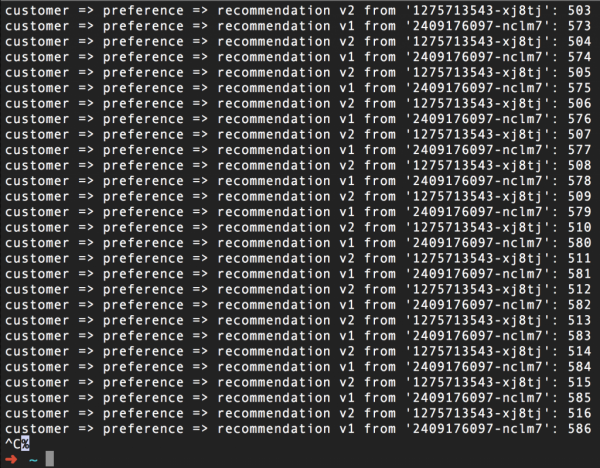
(Egyébként a jobb oldali szám csak a hívásszámláló minden egyes podhoz)
De nem erre van szükségünk, igaz? Nos, próbáljunk meg mindent feltörni anélkül, hogy a forráskódhoz nyúlnánk.
A mikroszolgáltatás működésében fennakadásokat rendezünk
Az alábbiakban egy Istio útválasztási szabály yaml fájlja látható, amely az esetek felében hibát jelez. szerver 503):
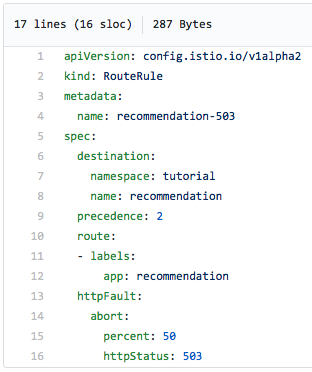
Felhívjuk figyelmét, hogy kifejezetten kijelentjük, hogy az esetek felében 503-as hibát kell visszaadni.
És íme, hogyan fog kinézni egy ciklusban futó curl parancs képernyőképe, miután aktiváltuk ezt a szabályt a hibák szimulálására. Mint látható, a kérelmek fele 503-as hibát ad vissza, függetlenül attól, hogy melyik pod – v1 vagy v2 – címre mennek:
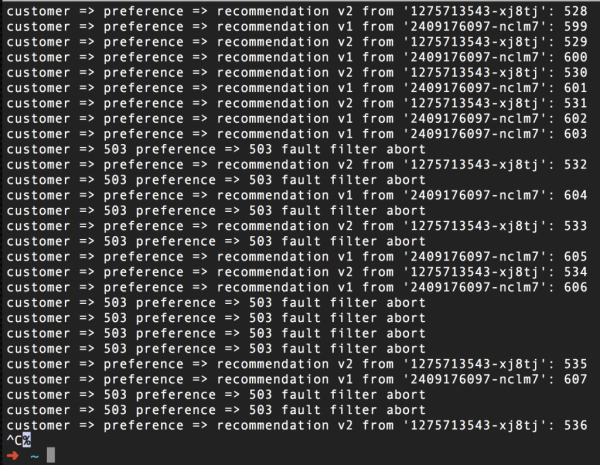
A normál működés visszaállításához elegendő ezt a szabályt törölni, esetünkben az istioctl delete routerule ajánlás-503 -n tutorial paranccsal. Itt az oktatóprogram az Istio oktatóanyagunkat futtató Red Hat OpenShift projekt neve.
Mesterséges késleltetések bevezetése
A hamis 503-as hibák segítenek tesztelni a rendszer meghibásodásokkal szembeni ellenálló képességét, de a késések előrejelzésének és kezelésének képessége még jobban lenyűgözi Önt. És a való életben a késések gyakrabban fordulnak elő, mint a kudarcok. A lassú mikroszolgáltatás egy méreg, amely az egész rendszerre kihat. Az Istio segítségével tesztelheti a késleltetéssel kapcsolatos kódot anélkül, hogy bármilyen módon megváltoztatná. Először is bemutatjuk, hogyan kell ezt megtenni mesterségesen bevezetett hálózati késések esetén.
Kérjük, vegye figyelembe, hogy az ilyen tesztelés után szükség lehet (vagy módosítani kell) a kódot. A jó hír az, hogy ebben az esetben inkább proaktív lesz, mint reaktív. Pontosan így kell felépíteni a fejlesztési ciklust: kódolás-tesztelés-visszacsatolás-kódolás-tesztelés...
Így néz ki a szabály... Bár tudod mit? Az Istio annyira egyszerű, és ez a yaml-fájl olyan egyértelmű, hogy ebben a példában minden önmagáért beszél, csak nézze meg:
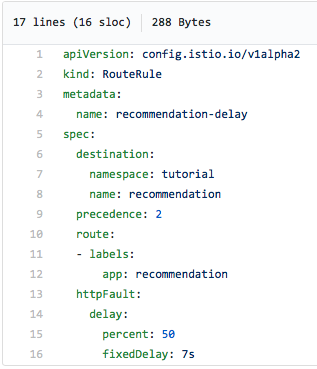
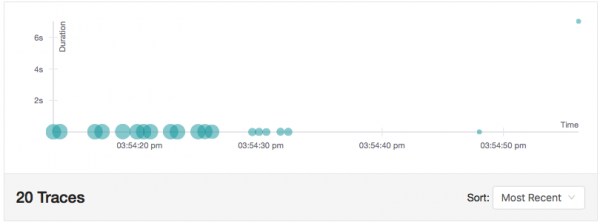
Az idő felében 7 másodperces késést tapasztalunk. Ez pedig egyáltalán nem ugyanaz, mintha a forráskódba beszúrtunk volna egy alvás parancsot, mivel az Istio valójában 7 másodperccel késlelteti a kérést. Mivel az Istio támogatja a Jaeger nyomkövetést, ez a késés észrevehető a Jaeger UI-ban, amint az az alábbi képernyőképen látható. Ügyeljen a diagram jobb felső sarkában lévő hosszú kérésre - időtartama 7.02 másodperc:
Ez a szkript lehetővé teszi a kód tesztelését hálózati késleltetési feltételek mellett. És egyértelmű, hogy ennek a szabálynak a megszüntetésével megszüntetjük a mesterséges késleltetést. Megismételjük, de mindezt ismét úgy tettük, hogy a forráskódot semmilyen módon nem érintettük.
Ne vonulj vissza és ne add fel
Az Istio egy másik hasznos funkciója a káosztervezés számára a szolgáltatás meghatározott számú ismételt hívása. Itt az a lényeg, hogy tovább próbálkozzunk, amikor az első kérés 503-as hibával végződik – és akkor talán az N-tizenegyedik alkalommal lesz szerencsénk. Lehet, hogy a szolgáltatás ilyen vagy olyan okok miatt egy időre leállt. Igen, ezt az okot ki kell ásni és meg kell szüntetni. De ez később jön, de egyelőre megpróbáljuk biztosítani, hogy a rendszer továbbra is működjön.
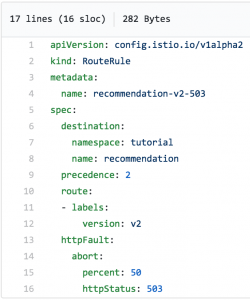
Tehát azt szeretnénk, hogy a szolgáltatás időnként 503-as hibát dobjon ki, majd az Istio újra megpróbálja felvenni vele a kapcsolatot. És itt egyértelműen szükségünk van egy módra, hogy 503-as hibát generáljunk anélkül, hogy hozzáérnénk a kódhoz...
Állj, várj! Csak megcsináltuk.
Ez a fájl eléri, hogy az ajánlás-v2 szolgáltatás az idő felében 503-as hibát adjon ki:
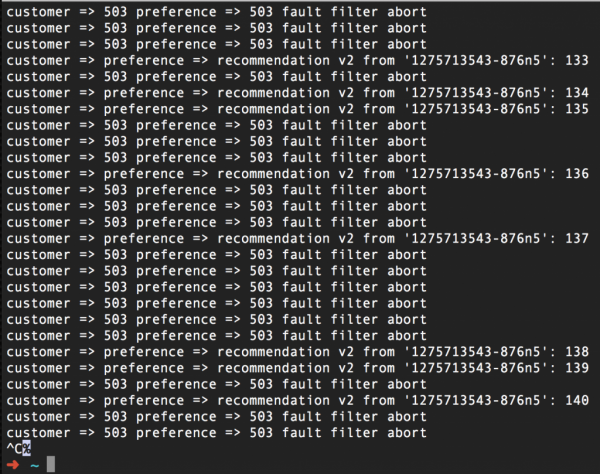
Nyilvánvalóan néhány kérés sikertelen lesz:
Most használjuk az Istio Retry függvényt:
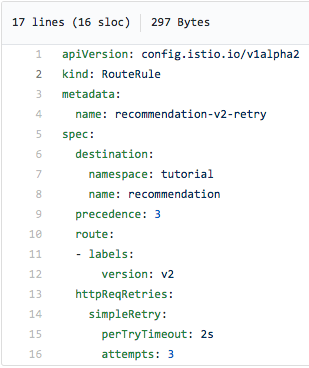
Ez az útválasztási szabály háromszor ismétlődik két másodperces időközönként, és csökkentenie kell (és ideális esetben el kell távolítania a radarról) az 503-as hibákat:
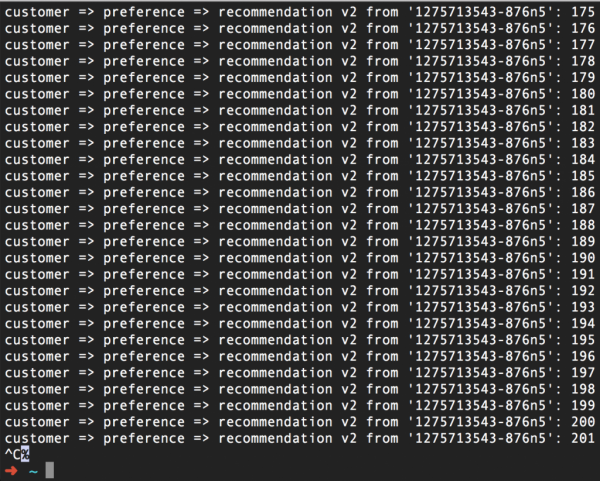
Összefoglalva: azt csináltuk, hogy az Istio először is 503-as hibát generál a kérések felénél. Másodszor, ugyanaz az Istio háromszor is megpróbálja újra felvenni a kapcsolatot a szolgáltatással, ha 503-as hiba lép fel, ennek eredményeként minden tökéletesen működik. Így az Újrapróbálkozás funkció használatával teljesítettük azt az ígéretünket, hogy nem vonulunk vissza és nem adjuk fel.
És igen, újra megtettük anélkül, hogy a kódhoz nyúltunk volna. Csak két Istio-útválasztási szabályra volt szükségünk:

Hogyan ne hagyja cserben a felhasználót, vagy hét ne számítson rá
Most fordítsuk meg a helyzetet, és vegyünk fontolóra egy olyan forgatókönyvet, ahol az egyetlen dolog, amit meg kell tenned, hogy nem vonulsz vissza, vagy nem adod fel meghatározott időre. Ezután már csak abba kell hagynia a kérés feldolgozását, hogy ne kényszerítsen mindenkit arra, hogy várjon egy lassú szolgáltatásra. Vagyis nem egy elvesztett pozíciót fogunk megvédeni, hanem tartaléksorba vonulunk vissza, hogy ne hagyjuk cserben az oldal használóját, és ne kényszerítsük tudatlanságban sínylődni.
Az Istio-ban beállíthat egy lekérdezés-végrehajtási időtúllépést. Ha a szolgáltatás túllépi ezt az időtúllépést, 504-es hibaüzenet (Gateway Timeout) jelenik meg – ez ismét az Istio konfiguráción keresztül történik. De hozzá kell adnunk egy alvás parancsot a szolgáltatás forráskódjához (majd természetesen újraépítést és újratelepítést kell végrehajtanunk), hogy szimuláljuk a szolgáltatás lassú működését. Jaj, ez másképp nem fog működni.
Tehát beszúrtunk egy három másodperces alvást az ajánlás v2-es szolgáltatáskódjába, újraépítettük a megfelelő képet és újratelepítettük a tárolót, és most a következő Istio útválasztási szabály segítségével időkorlátot adunk hozzá:
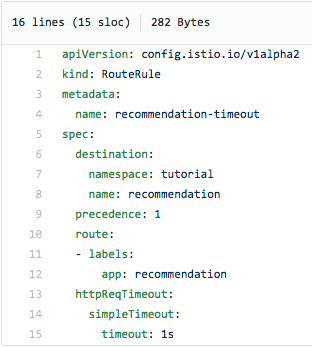
A fenti képernyőképen látható, hogy feladjuk az ajánlószolgálattal való kapcsolatfelvételt, ha egy másodpercen belül, azaz az 504-es hiba fellépése előtt nem kapunk választ. Az útválasztási szabály alkalmazása (és három másodperces alvó állapot hozzáadása) a :v2 ajánlási szolgáltatáskódhoz), ezt kapjuk:
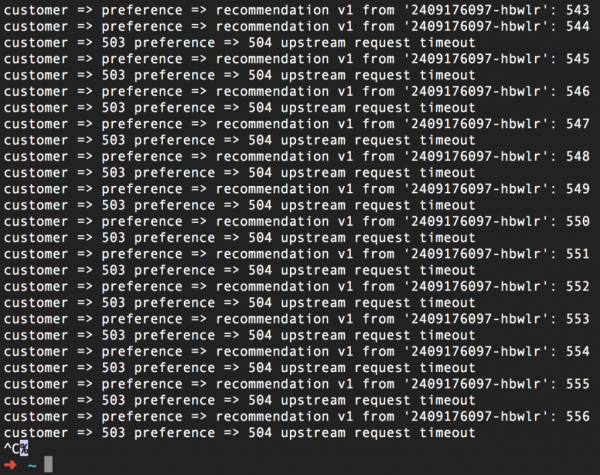
Ismételjük, de az időtúllépés a forráskód érintése nélkül is beállítható. A hozzáadott bónusz pedig az, hogy mostantól módosíthatja kódját, hogy reagáljon az időtúllépésre, és egyszerűen tesztelheti ezeket a módosításokat az Istio segítségével.
És most minden együtt van
Egy kis káosz beszúrása az Istio-val nagyszerű módja annak, hogy tesztelje a kódját és a rendszer egészének megbízhatóságát. A tartalék-, válaszfal- és megszakító minták, a mesterséges hibák és késleltetések létrehozására szolgáló mechanizmusok, valamint az újrapróbálkozási hívások és időtúllépések nagyon hasznosak lesznek a hibatűrő felhőrendszerek létrehozásakor. A Kubernetes és a Red Hat OpenShift eszközzel kombinálva ezek az eszközök segítenek abban, hogy magabiztosan nézzen a jövőbe.
Forrás: will.com
