

Ez a megjegyzés azok számára érdekes, akik a táblázatos adatfeldolgozási könyvtárat használják az R - data.table számára, és örömmel látják, hogy különféle példákban alkalmazzák a rugalmasságot.
Egy jó példa ihlette , és abban a reményben, hogy már elolvastad a cikkét, azt javaslom, hogy mélyebben áss a kódoptimalizálás és a teljesítmény felé. adattábla.
Bevezetés: Honnan származik a data.table?
A könyvtárral való ismerkedést a legjobb egy kicsit messziről kezdeni, mégpedig azokkal az adatstruktúrákkal, amelyekből a data.table objektum (továbbiakban DT) beszerezhető.
sor
Kód
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Az egyik ilyen struktúra egy tömb (?bázis::tömb). Más nyelvekhez hasonlóan itt is többdimenziós a tömb. Azonban az az érdekes, hogy például egy kétdimenziós tömb elkezdi örökölni a mátrix osztály tulajdonságait. (?bázis::mátrix), és egy egydimenziós tömb, ami szintén fontos, nem öröklődik vektorból (?bázis::vektor).
Meg kell érteni, hogy a függvény segítségével ellenőrizni kell az objektumokban található adatok típusát alap::típus, amely a szerinti belső típusleírást adja vissza R Internals - az eredetihez kapcsolódó nyelv általános protokollja C.
Egy másik parancs az objektum osztályának meghatározására alap::osztály, vektorok esetén a vektortípust adja vissza (névben különbözik a belsőtől, de lehetővé teszi az adattípus megértését is).
Lista
Egy kétdimenziós tömbből, más néven mátrixból, a listára (?alap::list).
Kód
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Több dolog történik egyszerre:
- A mátrix második dimenziója összeomlik, vagyis egyszerre kapunk listát és vektort.
- A lista tehát ezekből az osztályokból öröklődik. Szem előtt kell tartani, hogy egy listaelem egy (skaláris) értéknek fog megfelelni a tömbmátrix cellájából.
Mivel a lista egyben vektor is, néhány vektorfüggvény alkalmazható rá.
Dataframe
Listából, mátrixból vagy vektorból adatkeretbe léphet (?base::data.frame).
Kód
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Ami érdekes benne: a dataframe a listából öröklődik! Az adatkeret oszlopai listacellák. Ez később fontos lesz, amikor a listákra alkalmazott függvényeket használjuk.
adattábla
DT (?data.table::data.table) származhat adatkeret, lista, vektor vagy mátrix. Például így (helyben).
Kód
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Hasznos, hogy az adatkeretekhez hasonlóan a DT örökli egy lista tulajdonságait.
DT és memória
Ellentétben az R bázis összes többi objektumával, a DT-k hivatkozással kerülnek átadásra. Ha új memóriaterületre kell másolnia, szüksége van egy funkcióra adatok.tábla::másolat vagy a régi objektumból kell kiválasztania.
Kód
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Ezzel a bevezetés véget is ér. A DT az R-ben lévő adatszerkezetek fejlesztésének folytatása, amely főként az adatkeret osztályba tartozó objektumokon végzett műveletek bővítése és felgyorsítása miatt következik be. Ugyanakkor megmarad az öröklődés más primitívektől.
Néhány példa a data.table tulajdonságok használatára
Mint egy lista...
Egy adatkeret vagy DT sorain át iterálni nem jó ötlet, mivel a hurokkód a nyelvben R sokkal lassabb C, de teljesen át lehet lépni az oszlopokon, amelyek általában sokkal kisebbek. Ha végigmegyünk az oszlopokon, ne feledjük, hogy minden oszlop egy lista eleme, amely általában egy vektort tartalmaz. A vektorokon végzett műveletek pedig jól vektorizáltak a nyelv alapvető funkcióiban. Használhatja a listákban és vektorokban megszokott kiválasztási operátorokat is: `[[`, "$"..
Kód
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorizálás
Ha át kell menni egy nagy DT sorain, a legjobb megoldás egy függvény írása vektorizálással. De ha ez nem működik, akkor emlékeznie kell arra, hogy a ciklus belső A DT még mindig gyorsabb, mint a ciklus R, mivel azt hajtják végre C.
Próbáljuk meg egy nagyobb, 100 XNUMX soros példán. A vektoroszlopban szereplő szavakból kivonjuk az első betűt w.
korszerűsített
Kód
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Az iteráció első futtatása a sorokon:
Mértékegysége: ezredmásodperc
expr min
{ dt[, `:=`(első_l, unlist(strsplit(w, split = " ", fix = T))[1]), by = 1:nrow(dt)] } 439.6217
lq átlag medián uq max neval
451.9998 alkalmazott 460.9147 621.4042 100
A második futás, ahol a vektorizálás úgy történik, hogy a listát mátrixmá alakítjuk, és az 1-es indexű szeletre elemeket veszünk (ez utóbbi maga a vektorizálás). Javítás: vektorizálás függvényszinten strsplit, amely vektort tud fogadni bemenetként. Kiderült, hogy a lista mátrixsá alakításának eljárása sokkal nehezebb, mint maga a vektorizálás, de ebben az esetben sokkal gyorsabb, mint a nem vektorizált változat.
Mértékegysége: ezredmásodperc
expr min lq átlag medián uq max neval
{ dt[, `:=`(első_l, .(első_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 alkalmazott
Gyorsulás medián in 3 idők.
A harmadik futtatás, ahol a mátrixba való transzformációs séma megváltozott.
Mértékegysége: ezredmásodperc
expr min lq átlag medián uq max neval
{ dt[, `:=`(első_l, .(első_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 alkalmazott
Gyorsulás medián in 13 idők.
Kísérleteznie kell ezzel a kérdéssel, minél többet, annál jobb lesz.
Egy másik példa a vektorizálással, ahol van szöveg is, de közel áll a valós feltételekhez: különböző hosszúságú szavak, különböző szavak száma. Meg kell kapnia az első 3 szót. Mint ez:
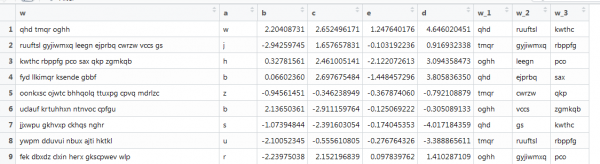
Itt az előző függvény nem működik, mivel a vektorok különböző hosszúságúak, és beállítjuk a mátrix méretét. Tegyük újra ezt úgy, hogy kutakodunk az interneten.
Kód
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Mértékegysége: ezredmásodperc
expr min lq átlagos medián
{ dt[, `:=`((beillesztés0("w_", 1:3)), strsplit(w, split = " ", fix = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 alkalmazott
A forgatókönyv átlagosan 1 másodperces sebességgel futott. Nem rossz.
Egy lánccal összekötve...
A DT objektumokkal láncolás segítségével dolgozhat. Úgy néz ki, mintha zárójeles szintaxist csatolnánk a jobb oldalra, lényegében a cukrot.
Kód
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
A csöveken keresztül folyik...
Ugyanezek a műveletek csővezetéken keresztül is elvégezhetők, hasonlónak tűnik, de funkcionálisan gazdagabb, hiszen bármilyen módszert használhat, nem csak DT-t. Vezessünk logisztikus regressziós együtthatókat szintetikus adatainkhoz számos szűrővel a DT-n.
Kód
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statisztikák, gépi tanulás és egyebek a DT-n belül
Használhat lambda függvényeket, de néha jobb, ha külön hozza létre őket, írja be a teljes adatelemzési folyamatot, és folytassa – a DT-n belül működnek. A példa az összes fenti funkcióval gazdagodik, plusz számos hasznos dolog a DT-arzenálból (például magának a DT-nek elérése a DT-n belül egy linken keresztül, amelyet néha nem szekvenciálisan, hanem úgy kell beilleszteni, hogy az legyen).
Kód
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
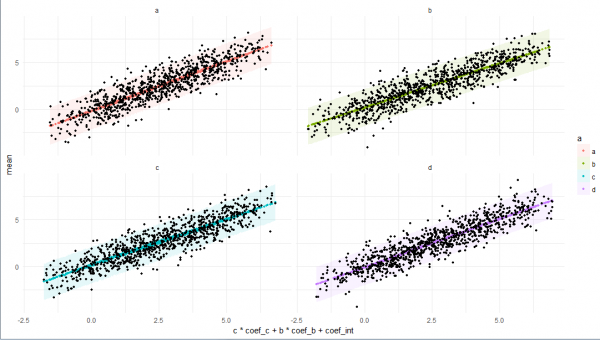
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Következtetés
Remélem sikerült egy teljes, de természetesen nem teljes képet alkotnom egy ilyen objektumról, mint például a data.table, kezdve az R osztályokból származó öröklődéshez kapcsolódó tulajdonságaival, egészen a saját jellemzőiig és környezetéig, a tidyverse elemekből. . Remélem, ez segít Önnek abban, hogy jobban megtanulja és használja ezt a könyvtárat munkához és szórakozás.
Köszönöm!
Teljes kód
Kód
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Forrás: will.com
