

Այս նշումը կհետաքրքրի նրանց, ովքեր օգտագործում են R աղյուսակի տվյալների մշակման data.table գրադարանը, և նրանք կարող են գոհ լինել տեսնելով դրա կիրառման ճկունությունը տարբեր օրինակներում։
Լավ օրինակից ոգեշնչված , և հուսով եմ, որ դուք արդեն կարդացել եք նրա հոդվածը, առաջարկում եմ ավելի խորը ուսումնասիրել կոդի օպտիմալացումը և կատարողականությունը՝ հիմնվելով դրա վրա։ տվյալներ.աղյուսակ.
Ներածություն. Որտեղի՞ց է վերցված data.table-ը։
Լավագույնն է գրադարանի հետ ծանոթանալը սկսել հեռվից, այն է՝ այն տվյալների կառուցվածքների հետ, որոնցից կարելի է ստանալ data.table օբյեկտը (այսուհետ՝ DT):
Array
Code
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Այդպիսի կառուցվածքներից մեկը զանգվածն է (?base::array)։ Ինչպես մյուս լեզուներում, այստեղ զանգվածները բազմաչափ են։ Սակայն հետաքրքիրն այն է, որ, օրինակ, երկչափ զանգվածը սկսում է ժառանգել հատկություններ մատրիցային դասից։ (?base::matrix), և միաչափ զանգվածը, որը նույնպես կարևոր է, չի ժառանգում վեկտորից (?base::vector).
Կարևոր է հասկանալ, որ ցանկացած օբյեկտում պարունակվող տվյալների տեսակը պետք է ստուգվի ֆունկցիայի կողմից։ հիմք::տիպը, որը վերադարձնում է տիպի ներքին նկարագրությունը՝ համաձայն R ներքին — բնօրինակի հետ կապված ընդհանուր լեզվական արձանագրություն C.
Մեկ այլ հրաման՝ օբյեկտի դասը որոշելու համար, հիմք::դաս, վեկտորների դեպքում վերադարձնում է վեկտորի տեսակը (այն ունի ներքին անունից տարբերվող անուն, բայց նաև թույլ է տալիս հասկանալ տվյալների տեսակը):
Ցուցակ
Երկչափ զանգվածից, որը հայտնի է նաև որպես մատրից, կարող եք անցնել ցուցակի (?base::list).
Code
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Միանգամից մի քանի բան է պատահում.
- Մատրիցի երկրորդ չափումը փլուզվում է, այսինքն՝ մենք միաժամանակ ստանում ենք և՛ ցուցակ, և՛ վեկտոր։
- Այսպիսով, ցանկը ժառանգում է այս դասերից։ Պետք է հիշել, որ ցանկի տարրը կհամապատասխանի մատրից-զանգվածի բջջից մեկ (սկալյար) արժեքի։
Քանի որ ցանկը նույնպես վեկտոր է, դրա վրա կարող են կիրառվել որոշ վեկտորային ֆունկցիաներ։
Տվյալների շրջանակ
Ցանկից, մատրիցից կամ վեկտորից կարող եք անցնել տվյալների շրջանակի (?base::data.frame).
Code
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Հետաքրքիրն այն է, որ տվյալների շրջանակը ժառանգում է ցուցակից։ Տվյալների շրջանակի սյուները ցուցակի բջիջներն են։ Սա կարևոր կլինի հետագայում, երբ մենք օգտագործենք ցուցակներին վերաբերող ֆունկցիաներ։
տվյալներ.աղյուսակ
Ստացեք DT (?data.table::data.table) կարող է լինել տվյալների շրջանակ, ցանկ, վեկտոր կամ մատրից։ Օրինակ, այսպես (տեղում)։
Code
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Օգտակարն այն է, որ ինչպես տվյալների շրջանակը, DT-ն ժառանգում է ցուցակի հատկությունները։
DT և հիշողություն
Ի տարբերություն R բազայի մյուս բոլոր օբյեկտների, DT-ները փոխանցվում են հղման միջոցով։ Եթե անհրաժեշտ է պատճենել նոր հիշողության տարածքում, ապա ձեզ անհրաժեշտ է ֆունկցիան։ data.table::copy կամ դուք պետք է ընտրություն կատարեք հին օբյեկտից։
Code
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Սա եզրափակում է նախաբանը։ DT-ն R-ում տվյալների կառուցվածքների զարգացման շարունակությունն է, որը հիմնականում տեղի է ունենում dataframe դասի օբյեկտների վրա կատարված գործողությունների ընդլայնման և արագացման շնորհիվ։ Միևնույն ժամանակ, պահպանվում է այլ պրիմիտիվներից ժառանգությունը։
Data.table հատկությունների օգտագործման որոշ օրինակներ
Որպես ցանկ…
Տվյալների շրջանակի կամ տվյալների փոխանցման տողերի վրայով իտերացիան լավ գաղափար չէ, քանի որ ցիկլի կոդը լեզվի մեջ է։ R շատ ավելի դանդաղ C, և բավականին հնարավոր է սյուները անցնել ցիկլով, որոնք սովորաբար շատ ավելի փոքր են։ Սյուները անցնելիս հիշեք, որ յուրաքանչյուր սյուն ցուցակի տարր է, որը սովորաբար պարունակում է վեկտոր։ Եվ վեկտորների վրա գործողությունները լավ վեկտորացված են լեզվի հիմնական ֆունկցիաներում։ Կարող եք նաև օգտագործել ցուցակներին և վեկտորներին բնորոշ ընտրության օպերատորները՝ `[[`, `$`.
Code
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Վեկտորիզացիա
Եթե անհրաժեշտություն կա անցնել մեծ DT-ի տողերով, լավագույն լուծումը կլինի վեկտորիզացիայով ֆունկցիա գրելը։ Բայց եթե դա չի աշխատում, ապա պետք է հիշել, որ ցիկլը ներսում DT-ն դեռևս ավելի արագ է, քան ցիկլը R, քանի որ այն իրականացվում է C.
Եկեք փորձենք դա ավելի մեծ օրինակի վրա՝ 100 հազար տողերով։ Մենք կհանենք վեկտորային սյունակում ներառված բառերի առաջին տառը։ w.
Թարմացվել է
Code
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Առաջին գործարկում տողերի վրայով իտերացիայով՝
Միավոր՝ միլիվայրկյաններ
արտահայտության նվազագույն
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
lq միջին միջնարժեք uq մաքսիմում neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Երկրորդ գործարկումը, որտեղ վեկտորացումը տեղի է ունենում ցուցակը մատրիցի վերածելու և կտորի վրա 1 ինդեքսով տարրեր վերցնելու միջոցով (վերջինս իրականում վեկտորացում է): Թույլ տվեք ուղղել ինձ. վեկտորացում ֆունկցիայի մակարդակում ստրսպլիտ, որը կարող է վեկտոր ընդունել որպես մուտքային տվյալ։ Պարզվում է, որ ցուցակը մատրիցի վերածելու ընթացակարգը շատ ավելի դժվար է, քան վեկտորացումը, բայց նույնիսկ այս դեպքում այն շատ ավելի արագ է, քան ոչ վեկտորացված տարբերակը։
Միավոր՝ միլիվայրկյաններ
expr min lq միջին միջին uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Միջնարժեքով արագացումը 3 անգամ.
Երրորդ վազքը, որտեղ փոխվեց մատրիցային փոխակերպման սխեման։
Միավոր՝ միլիվայրկյաններ
expr min lq միջին միջին uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Միջնարժեքով արագացումը 13 անգամ.
Դուք պետք է փորձարկեք այս հարցում, որքան շատ, այնքան լավ։
Վեկտորիզացիայի մեկ այլ օրինակ, որտեղ նույնպես կա տեքստ, բայց այն մոտ է իրական պայմաններին. բառերի տարբեր երկարություններ, բառերի տարբեր քանակներ: Անհրաժեշտ է ստանալ առաջին 3 բառերը: Ահա այսպես.
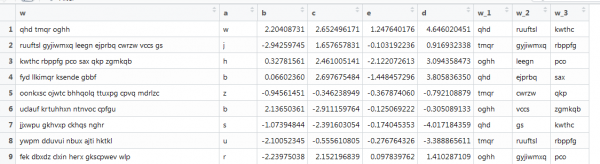
Այստեղ նախորդ ֆունկցիան չի աշխատում, քանի որ վեկտորները տարբեր երկարությունների են, և մենք նշել ենք մատրիցի չափը։ Եկեք կրկնենք սա՝ ինտերնետում փնտրտուքներ կատարելով։
Code
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Միավոր՝ միլիվայրկյաններ
expr min lq միջին միջնարժեք
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = "", fixed = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Սցենարը աշխատեց միջինը 1 վայրկյան արագությամբ։ Վատ չէր։
Մի շղթայով կապված…
Դուք կարող եք աշխատել DT օբյեկտների հետ՝ օգտագործելով շղթայական կապ։ Այն նման է փակագծերի սինտաքսի աջ կողմին կցելուն, ըստ էության՝ շաքար։
Code
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Այն հոսում է խողովակների միջով...
Նույն գործողությունները կարող են կատարվել խողովակաշարի միջոցով, այն նման է, բայց ֆունկցիոնալ առումով ավելի հարուստ է, քանի որ կարող է օգտագործվել ցանկացած մեթոդ, ոչ միայն DT-ն։ Եկեք ստացնենք մեր սինթետիկ տվյալների լոգիստիկ ռեգրեսիայի գործակիցները՝ DT-ի վրա մի շարք ֆիլտրերի միջոցով։
Code
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Վիճակագրություն, մեքենայական ուսուցում և DT-ի ներսում առկա այլ բաներ
Կարող եք օգտագործել lambda ֆունկցիաներ, բայց երբեմն ավելի լավ է դրանք ստեղծել առանձին, գրել ամբողջ տվյալների վերլուծության խողովակաշարը և շարունակել՝ դրանք աշխատում են տվյալների վերլուծության ներսում։ Օրինակը հարստացված է վերը նշված բոլոր հնարավորություններով, գումարած տվյալների վերլուծության զինանոցից մի քանի օգտակար բաներով (օրինակ՝ հղումով տվյալների վերլուծությանը մուտք գործելը տվյալների վերլուծության ներսում, երբեմն մուտքագրվելով ոչ թե հաջորդաբար, այլ այնպես, որ այն այնտեղ լինի)։
Code
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
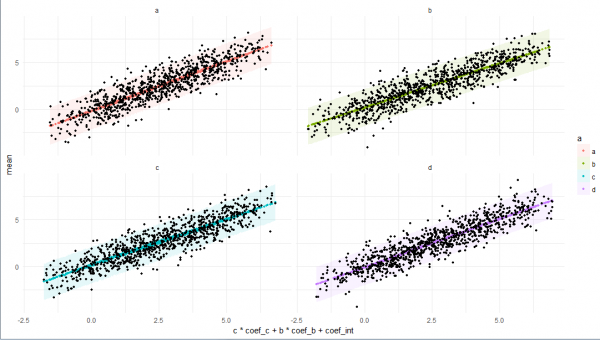
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Ամփոփում
Հուսով եմ՝ կարողացա ստեղծել data.table-ի նման օբյեկտի ամբողջական, բայց անկասկած ոչ ամբողջական պատկերը՝ սկսած R դասերից ժառանգելու հետ կապված դրա հատկություններից և վերջացրած tidyverse տարրերից ստացված իր սեփական առանձնահատկություններով և միջավայրով։ Հուսով եմ՝ սա կօգնի ձեզ ավելի լավ հասկանալ և կիրառել այս գրադարանը աշխատանքի և... զվարճություն.
Thank you!
Ամբողջական կոդը
Code
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Source: www.habr.com
