


oleh St-Pete
Halo semua! Saya Mons Anderson, arsitek platform , saya akan memberi tahu Anda cara kami membangun penyimpanan S3, cara kerjanya, solusi mana yang berhasil, dan solusi mana yang layak diubah jika kami memulai proyek yang sama dari awal sekarang.
Artikel ini disusun berdasarkan laporan di oleh Solusi Cloud Mail.ru & Tarantool. Dalam artikel ini kita akan berbicara:
- bagaimana penyimpanan Mail.ru dirancang, di atasnya kami membangun penyimpanan S3;
- apa yang kami tambahkan untuk membuat Penyimpanan Cloud Mail.ru;
- bagaimana model penyimpanan objek bekerja dan langkah apa yang diambil untuk memasuki produksi;
- tentang peningkatan sistem tempur: failover dan penskalaan;
- bagaimana kami menerapkan sharding dan resharding;
- dan juga tentang bekerja dengan sertifikat SSL.
Jika Anda tidak ingin membaca, Anda bisa .
Bagaimana penyimpanan Mail.ru dirancang, selain itu kami membangun penyimpanan S3
Pengembangan S3 kami dimulai di atas penyimpanan Cloud Mail.ru, jadi ada baiknya untuk mengetahui terlebih dahulu cara kerjanya dan apa yang dapat dilakukannya.
Penyimpanan cloud Mail.ru terdiri dari server dengan disk. Rata-rata, server penyimpanan modern memiliki 36 disk yang masing-masing berukuran 12–14 terabyte. Sebelumnya, disk berukuran lebih kecil, namun dalam tiga tahun volume disk telah berkembang dan saat ini volumenya hampir setengah petabyte data mentah.
Disk dari server penyimpanan yang berbeda digabungkan menjadi apa yang disebut “pasangan”. Sepasang adalah unit penyimpanan file tunggal. Pada dasarnya, ini adalah disk yang dipasang pada partisi tertentu di jalur tertentu, tempat file yang diidentifikasi oleh hash dapat ditemukan.
Pair adalah nama sejarah yang bertahan hingga saat ini, meski kini pair tidak serta merta hanya memiliki dua disc. Disknya bisa tiga, dan bisa juga berbagai penyimpanan hybrid, misalnya 3/2.
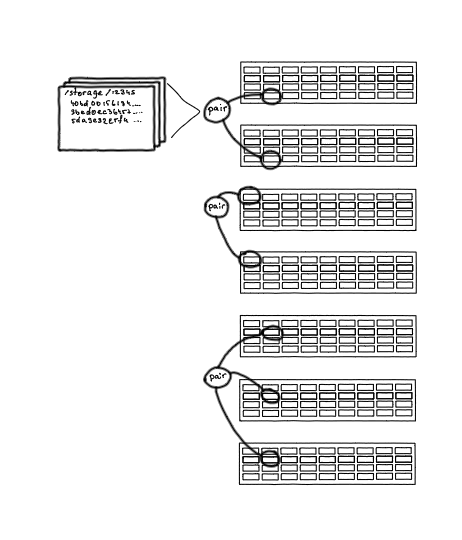
Pasangan adalah unit penyimpanan objek
Semua pasangan disimpan di PairDB yang merupakan aplikasi berbasis Tarantool. Semua database di repositori kami, mulai dari yang pertama, adalah Tarantool; kami tidak menggunakan database lain.
PairDB menyimpan semua pasangan, statusnya, ruang kosong, kemungkinan kegagalan, dan kesalahan terakhir. Dia juga dapat pergi ke kelas sendiri, memperbarui statusnya, memeriksa apakah mereka bekerja atau tidak. Artinya, PairDB adalah gambaran umum status semua disk di sistem kami.
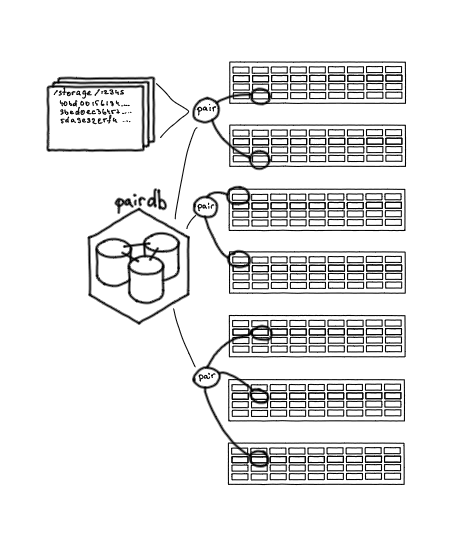
Pasangkan DB: Pasangkan basis data negara bagian
File disimpan berpasangan, dan untuk mengetahui pasangan mana yang berisi file mana, Anda memerlukan database lain - FileDB. Ini menyimpan pemetaan, pencocokan definisi: file ini dan itu disimpan pada pasangan ini dan itu, serta sejumlah kecil atribut yang diperlukan.
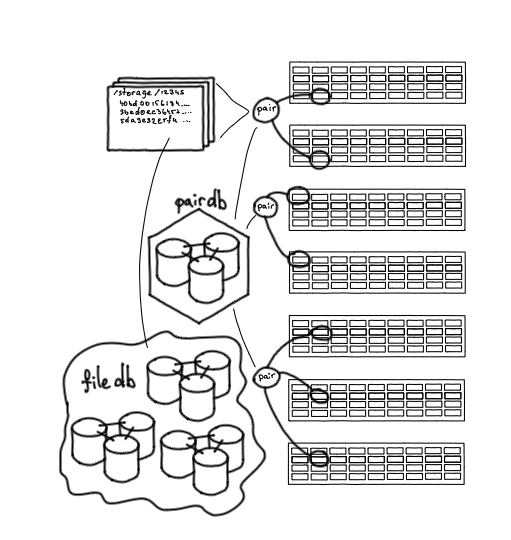 File DB: lokasi penyimpanan file
File DB: lokasi penyimpanan file
Tautan penting lainnya adalah layanan Nylon, router untuk bekerja dengan database. Ini adalah titik masuk tunggal dan memungkinkan Anda bekerja melalui satu antarmuka dengan PairDB dan FileDB. Ini adalah layanan tanpa kewarganegaraan, ia menyeimbangkan permintaan, memahami pecahan FileDB mana yang harus dituju, mengetahui pasangan mana yang aktif dan mana yang tidak.
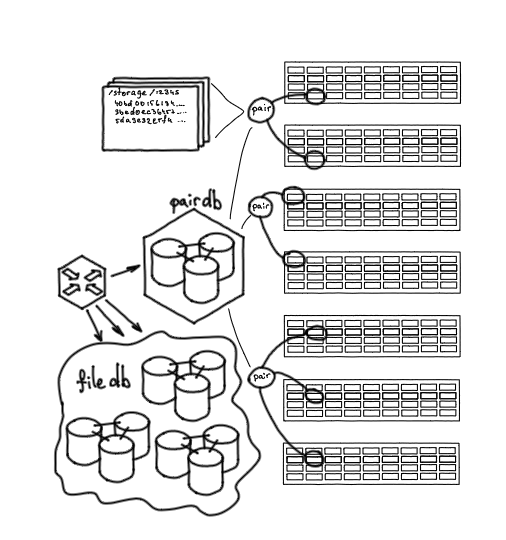
Nylon: router untuk bekerja dengan database
Anda juga perlu menyimpan konten di penyimpanan. Ada layanan untuk ini - Streamer. Ini menyediakan dua metode HTTP: metode PUT untuk memasukkan konten ke dalam penyimpanan, dan metode GET untuk mengambilnya dari sana. HTTP adalah protokol yang cukup populer dan nyaman untuk transfer data.
Saat kami menghubungi Streamer, ia mengakses PairDB melalui Nylon, mengetahui pasangan mana yang dapat mengunggah file, dan kemudian mentransfer data melalui WebDAV ke pasangan ini.
Pada dasarnya, server penyimpanan apa pun adalah nginx plus disk yang dipasang di sepanjang jalur tertentu. Kita dapat mengunggah file ke penyimpanan dari Streamer, menghapusnya, mengganti namanya, atau memeriksa integritasnya. Artinya, ini adalah antarmuka yang nyaman untuk interaksi tingkat rendah dengan penyimpanan.

Streamer: titik masuk penyimpanan
Apa yang kami tambahkan untuk membuat penyimpanan S3
Jadi, kami melihat desain penyimpanan dasar secara umum saat kami akan meluncurkan penyimpanan S3. Dengan menggunakan metode PUT, kita dapat menempatkan konten sembarang di sana dan mendapatkan hash sebagai pengidentifikasi untuk data ini. Dengan ID ini nantinya Anda bisa datang dan mengambil file aslinya. Namun hal ini tidak cukup untuk mengimplementasikan S3. Protokol S3, selain menyimpan objek itu sendiri, memiliki:
- penyimpanan metadata - properti tambahan objek;
- mengatur akses ke objek melalui HTTP;
- mengelompokkan objek ke dalam koleksi - ember;
- Titik Akhir HTTP-S3. S3 mengatur data ke dalam struktur spesifik yang disebut bucket, yang masing-masing menyediakan titik masuk untuk menyimpan file.
Untuk mengimplementasikan logika ini, diperlukan layanan terpisah. Saya juga ingin segera menyediakan arsitektur untuk pertumbuhan layanan lebih lanjut dengan skalabilitas linier.
Komponen pertama
Daemon yang mengimplementasikan S3 API. Ini adalah API S3 standar Amazon yang mendukung XML untuk metadata dan memungkinkan konten dialirkan secara langsung. Kami tidak perlu menciptakan apa pun, semuanya telah dijelaskan dan didokumentasikan.
Kami juga menginstal Nginx di depan layanan. Kami menggunakannya untuk penghentian SSL, penyeimbangan beban, dan juga untuk beberapa logika di Lua (metrik, logging, dan penelusuran).
Kami juga memilih Tarantool untuk menyimpan metadata S3. Pada versi pertama, daemon S3 masuk ke database ini untuk metadata; kontennya sendiri disimpan dalam penyimpanan besar melalui Streamer.

Nginx + S3 API + metadata
Model penyimpanan objek
Mari kita lihat cara kerja S3. Pengguna dapat membuat keranjang - kumpulan objek. Bucket dialamatkan berdasarkan nama host dan merupakan subdomain layanan. Di dalam bucket, pengguna dapat membuat objek. Pengidentifikasi objek akan menjadi URL. Konten objek berupa blob, berupa array data biner yang akan kita simpan di penyimpanan. Objek juga memiliki atribut: nama - URL yang sama, ACL (daftar kontrol akses), atribut tambahan atau arbitrer lainnya - semua ini disimpan dalam metadata.
Diagram yang dinormalisasi dari data ini mungkin terlihat seperti ini: ada proyek yang memiliki keranjang, yang memiliki objek, dan objek dapat berupa komposit. Karena salah satu cara suatu objek dapat dimuat dalam beberapa bagian, ada dua tabel tambahan untuk memuat: unggahan dan potongan. Proyek juga memiliki kredensial akses dan penagihan.

Skema Data
Karena kami membuat layanan b2b dengan akses berbayar, skema ini memerlukan penagihan.
Kami juga menerapkan layanan penagihan di Tarantool.

Peningkatan penyimpanan S3: langkah menuju produksi
Kami telah membuat model kerja yang dapat digunakan: objek dan metadata disimpan, namun beberapa poin hilang untuk masuk ke produksi.
Pertama, sistem batasan tarif. Jika kami memulai layanan tanpa itu, maka selama beban puncak kami dapat membebani bagian mana pun dari sistem secara tidak terduga. Batas lajunya akan berfungsi seperti ini: setiap permintaan S3 datang ke host tertentu, host ini adalah pengidentifikasi bucket, dan bucket tersebut milik beberapa klien. Kita perlu mendefinisikan beberapa fungsi dari bucket yang memungkinkan kita menghitung batas laju.
Selain itu, sistem batas kecepatan harus cukup kuat untuk menangani beban yang datang ke S3.
Di sini kami menggunakan Tarantool lagi. Batas Kecepatan adalah cluster yang terdiri dari 21 instance, instance dibagi menjadi beberapa grup, dipisahkan menjadi tiga node fisik dan digabungkan menjadi cluster topologi besar. Perubahan konfigurasi secara otomatis disebarkan melaluinya: batas kecepatan, default, dan konfigurasi ditetapkan. Setiap ember dilayani hanya oleh satu contoh. Saat permintaan tiba untuk bucket tertentu, instance yang bertanggung jawab atas bucket ini dihitung. Dalam node ini, tingkat permintaan saat ini dihitung menggunakan algoritma yang mirip dengan Token Bucket. Selanjutnya, sistem batas laju, berdasarkan indikator beban saat ini dan properti yang ditetapkan untuk bucket tertentu, menentukan apakah permintaan dapat dipenuhi atau tidak. Pemeriksaan batas dilakukan pada tahap paling awal permintaan S3, melindungi semua elemen sistem lainnya dari beban berlebihan.

Selain itu, saat memuat, cukup sulit dilakukan tanpa cache. S3 menyiratkan akses berulang ke objek yang sama, yaitu penyimpanan panas. Dalam kasus biasa, akses ke satu file dilayani oleh rantai lengkap: Streamer, FileDB, PairDB, Storage. Namun saat mengakses file beberapa kali, kami mengoptimalkan akses ke konten ini menggunakan cache lokal.
Cache berlapis-lapis dan diimplementasikan menggunakan disk nginx, lokal, SSD, dan RAM. Disini kami tidak menggunakan Tarantool, karena lebih nyaman menyajikan objek dari sistem file, sehingga kami dapat melakukan cache tiering. Selain itu, kami memiliki objek besar dengan ukuran maksimum 32 gigabyte, dan Tarantool hanya dapat menyimpan objek kecil dalam cache.

Sistem pertama yang kami luncurkan ini memiliki kapasitas yang diperhitungkan, cukup untuk penelitian, pemahaman produk, sehingga dapat berfungsi.
Perbaikan pada sistem pertarungan: failover dan penskalaan
Sistem sudah beraksi, tetapi pada awalnya kami melewatkan sesuatu - kami perlu menambahkan failover dan penskalaan.
Daemon S3 kami mengambil metadata menggunakan protokol Tarantool. Sebagai pengganti database asli, kami menginstal Tarantool, yang bertindak sebagai router proxy untuk permintaan metadata. Dari sudut pandang aplikasi yang mengimplementasikan API, tidak ada yang berubah - aplikasi terus mengakses database menggunakan protokol Tarantool, namun router mampu memberikan failover aktif. Artinya, kami dapat memeriksa ketersediaan node, menjeda saat peralihan dan kegagalan, dan sebagainya. Namun, kami tidak memodifikasi aplikasi itu sendiri.

Pelajari lebih lanjut tentang cara kami menerapkan sharding
Masalah berikutnya yang harus kami khawatirkan adalah sharding. Sistemnya berkembang, jumlah objeknya bertambah, dan peluang untuk pertumbuhan lebih lanjut perlu diberikan.
Mari kembali ke skema data: ada proyek, ada keranjang, pinjaman, dan penagihan. Ini adalah objek yang, dengan kemungkinan besar, di masa mendatang tidak akan tumbuh melampaui batas satu instance, baik dalam volume maupun permintaan. Artinya, tidak ada gunanya melakukan sharding, dan kami memindahkannya ke instance terpisah, yang tidak akan di-sharding. Hal ini memungkinkan pengelolaan proyek dan bucket yang lebih konsisten karena terdapat satu titik yang tidak terpecah.

Juga dalam skema tersebut terdapat objek yang tumbuh secara linier - awalnya jumlahnya ratusan ribu, sekarang jumlahnya diukur dalam beberapa miliar. Benda-benda tersebut, beserta bagian-bagiannya, harus dimasukkan ke dalam kelompok pecahan.

Kami telah membagi skemanya, tetapi objek harus bekerja dengan bucket: objek selalu menjadi milik bucket tertentu, ditambah ACL yang berfungsi pada bucket. Oleh karena itu, untuk setiap pecahan objek, kami menyimpan salinan bayangan dari setiap keranjang. Selain itu, saat memodifikasi objek dan menjalankan kueri, Anda perlu menghitung volume untuk melakukan penagihan, sehingga setiap pecahan memiliki penghitung penagihan.
Kami juga menambahkan beberapa tabel dan komponen lagi:
- recycle bin untuk menghancurkan proyek lama yang dihapus atau dibekukan;
- antrian untuk tugas latar belakang, yaitu penyimpanan utama dapat melakukan tugas latar belakang yang perlu dilakukan di cluster;
- dukungan siklus hidup - mekanisme yang memungkinkan Anda bekerja dengan objek dan mengelola siklus hidupnya.

Karena kami mentransfer sebagian data ke shard, kami memerlukan proxy sharding. Dimungkinkan untuk menggunakan kembali router untuk peran ini, tetapi proxy sharding terpisah, yang hanya bertanggung jawab untuk sharding data, memungkinkan Anda mengambil seluruh data dari router tanpa memikirkan tentang sharding.

Saya akan memberi tahu Anda secara terpisah mengapa kami tidak mengambil solusi siap pakai, tetapi ingin membuat fungsi sharding khusus.
Mari kita lihat cara kerjanya. Kami memiliki 256 pecahan yang tersedia. Untuk setiap bucket, kami memilih rentang menggunakan fungsi konsistensi tertentu. Sederhana saja - sama seperti Anda menggunakan fungsi konsistensi untuk menentukan apakah Anda termasuk dalam satu shard, Anda menentukan shard awal dan memilih rentang:
f(bucket, shards) = subset
Artinya, jika Anda mengambil keranjang, Anda dapat mengatakan bahwa keranjang tersebut dan datanya akan selalu berada pada subset tertentu dari semua pecahan. Hal ini memungkinkan Anda mengurangi pengaruh beberapa keranjang terhadap keranjang lainnya dan menyederhanakan pekerjaan kueri pengurangan peta saat Anda perlu, misalnya, membuat daftar objek keranjang. Untuk melakukan ini, Anda perlu melakukan polling pada semua pecahan tempat objek ini disimpan. Jika objek ditempatkan di semua pecahan, daftar apa pun akan memengaruhi keseluruhan sistem, namun di sini hanya memengaruhi subset tertentu.
Selanjutnya, setiap objek termasuk dalam keranjang tertentu, jadi ketika kita mengakses suatu objek, kita mengakses objek tersebut berdasarkan nama dalam keranjang tertentu. Artinya, kita dapat mendefinisikan fungsi untuk suatu objek bukan dari seluruh rentang pecahan yang tersedia, namun hanya dari sebagian keranjangnya:
f(object, subset) = shard
Kami mengambil objek tertentu, tidak meneruskan semua pecahan ke sana sebagai argumen fungsi, tetapi sebagian dari keranjangnya - dan kami mendapatkan pecahan tertentu.
Jadi sharding diimplementasikan, ada proxy sharding. Maka yang tersisa hanyalah beralih dari router dan database dengan metadata ke proxy sharding. Misalnya, untuk membuat objek salinan bayangan - saat kita membuat bucket, penyimpanan utama harus membuat perwakilan bucket ini di semua pecahan yang seharusnya ada.

Bagaimana kami menerapkan resharding
Masalah terbesar dengan sharding adalah resharding. Penting bagi kami untuk melakukannya tanpa downtime, karena sistem sudah dalam produksi. Saya akan menunjukkan kepada Anda bagaimana kami memecahkan masalah tersebut menggunakan contoh masalah serupa dengan migrasi data langsung dari satu proyek ke proyek lainnya.
Di bawah ini adalah diagram cluster kami, yang dihasilkan setelah memperkenalkan sharding. Kami memiliki nginx, S3 API, router, database utama dengan proyek, proxy sharding, dan shard itu sendiri

Di atas, saya melewatkan poin bahwa pada tahap tertentu proyek ada tugas produk: "Meluncurkan fasilitas penyimpanan lain, Icebox, seperti Hotbox, hanya untuk data dingin." Pada dasarnya penyimpanannya sama, tetapi pada URL berbeda dan tanpa cache.

Icebox digunakan lebih sedikit dibandingkan Hotbox, sehingga bertahan cukup lama tanpa adanya sharding. Pada akhirnya, kami memutuskan untuk meninggalkannya dan menggabungkan Hotbox dan Icebox menjadi satu layanan, cukup dengan memisahkan kelas penyimpanan.
Bucket di penyimpanan tidak tumpang tindih, dapat dengan mudah digabungkan dan dipindahkan, namun klien menggunakan kedua fasilitas penyimpanan tersebut, yang berarti bahwa masalah kurangnya waktu henti harus diselesaikan. Anda tidak bisa begitu saja mematikannya dan menyalinnya. Kami melakukan migrasi dalam beberapa tahap.
Untuk memulainya, kami menyinkronkan penyimpanan utama. Kami memiliki Tarantool dan saat membuat objek kami dapat melakukan ini:
- permintaan datang ke database untuk membuat bucket, misalnya di Hotbox;
- Tarantool memeriksa database lain (dalam hal ini, Icebox) bahwa tidak ada keranjang seperti itu;
- jika ada bucket, database mengatakan tidak dapat dibuat, dan disinkronkan dengan yang sudah ada.

Sinkronisasi keranjang

Di fasilitas penyimpanan, yang seharusnya menerima semua data, sebuah tanda diperkenalkan untuk proyek dan ember yang menyatakan di mana objek ini disimpan. Bisa disimpan secara lokal, yaitu di Hotbox, Icebox - kemudian tidak ada data darinya di penyimpanan baru, atau bisa juga dalam keadaan migrasi.
Jika proyek atau bucket memiliki tanda Migrasi, maka selama migrasi, permintaan dieksekusi terlebih dahulu ke penyimpanan baru tempat data seharusnya ditempatkan, dan jika tidak ada, maka permintaan dialihkan ke penyimpanan alternatif.
Selanjutnya kami mengalihkan lalu lintas. Karena API dapat melayani permintaan Icebox dan Hotbox, kami dapat mengalihkan lalu lintas tanpa downtime hanya dengan memindahkan host dan menambahkan entri yang sesuai di Nginx.
Setelah lalu lintas dialihkan, Nginx dan Icebox API dapat dihapus.
Lalu kami menghapus Icebox nginx dan S3 API - dan semuanya berfungsi:

Selanjutnya, kami meluncurkan proses migrasi latar belakang yang berfungsi di dalam database - proses ini menelusuri semua proyek dan bucketnya elemen demi elemen, menyetel tanda Migrasi untuk proyek tersebut, mentransfer data dan, setelah transfer selesai, menyetel tanda Lokal.

Setelah migrasi data, kami tidak lagi memerlukan penyimpanan lama, dan kami menghapus bagian yang tersisa dari sistem lama, dan juga menghapus dukungan untuk status migrasi dari kode.

Pemindahan ulang dari penyimpanan lama ke penyimpanan shard dilakukan dengan menggunakan prinsip yang sama:
- Menandai semua ember sebagai
Non-sharded. Semua permintaan kepada mereka dikirim ke penyimpanan asli yang tidak dipecah. - Bucket baru segera dibuat di status
Sharded. - Mereka mengambil ember satu per satu dan mengatur statusnya
Migratingdan mentransfer datanya.
Permintaan dilayani berdasarkan prinsip berikut:
- Kita membaca di yang baru, lalu di yang lama.
- Kami hanya menciptakan yang baru.
- Kami memperbarui dalam dua tahap: jika tidak ada yang baru, kami mentransfernya dari yang lama ke yang baru, lalu kami memperbaruinya.
Bekerja dengan sertifikat SSL
Di frontend kami menggunakan Nginx. Dalam kasus kami, ini bukan Nginx biasa, tapi OpenResty, Nginx dengan dukungan LuaJIT.
Bagian lain dari sistem ini bekerja dengan sertifikat SSL. Di penyimpanan S3, Anda dapat mengatur domain Anda sendiri untuk mengakses bucket tertentu, cukup dengan menggunakan CNAME. Namun saat ini Anda tidak dapat melakukannya tanpa HTTPS: domain Anda sendiri berarti sertifikat SSL Anda sendiri.
Seperti yang sudah saya katakan, Nginx bertanggung jawab untuk menyeimbangkan dan mengakhiri SSL. Dalam kasus kami, ini bukan Nginx biasa, tapi OpenResty, Nginx dengan dukungan LuaJIT.
Hal ini memungkinkan kami dengan mudah mengajarkan Nginx kami untuk mengeluarkan sertifikat sewenang-wenang. Selain itu, kami perlu menerbitkan sertifikat secara dinamis (tanpa perlu mendaftarkannya di file konfigurasi). Kami menggunakan ekstensi ssl_certificate_by_lua, yang memungkinkan Anda membaca sertifikat dari sumber mana pun secara langsung selama jabat tangan TLS. Kami juga menggunakan Tarantool sebagai penyimpan sertifikat: ini memungkinkan Anda mengelola sertifikat secara eksternal dan memberikan hasil yang sangat cepat.
Daemon terpisah juga diterapkan, yang tugasnya memperbarui sertifikat yang diterbitkan menggunakan Let's Encrypt secara berkala.

Apa yang akan saya simpan dan apa yang akan saya lakukan secara berbeda jika saya mengembangkan repositori dari awal?
Apa yang seharusnya digunakan sejak awal
Segera berbagi. Resharding menyebabkan cukup banyak masalah. Hal ini mudah dilakukan, namun demikian, jika Anda memulai proyek yang perlu ditingkatkan skalanya, lebih baik segera mengambil cluster sharded, bahkan dengan node yang minimal. Menerapkan sharding di awal hampir gratis dibandingkan dengan memperkenalkan sharding ke dalam sistem produksi.
Bekerja dengan Tarantool melalui penyeimbang. Sekarang kami segera menghubungkan semua database baru untuk bekerja melalui penyeimbang. Hal ini memungkinkan Anda untuk memperluas fungsionalitas dan mencapai toleransi kesalahan yang lebih tinggi.
kegagalan otomatis. Saya akan menginstal semua alat yang diperlukan untuk autofailover, karena kegagalan pertama setelah peluncuran dikaitkan dengan ketidakhadirannya. Setelah pengalaman dengan S3, semua produk berikutnya diluncurkan dengan pemikiran ini.
Fitur S3 “Pembuatan Versi”. Awalnya tampaknya fungsi ini tidak terlalu populer. Sangat sulit untuk mengintegrasikan kemampuan ini ke dalam arsitektur sistem yang sedang berjalan.
Pisahkan penagihan. Cara kami memasukkan penagihan ke dalam sistem kami berfungsi dengan baik pada awalnya, namun kemudian mulai mengganggu; akan lebih baik jika layanan tersebut benar-benar terpisah.
Apa keputusan yang bagus?
Model data. Sejarah telah menunjukkan bahwa seiring berkembangnya layanan, kami sangat cocok dengan model data Amazon, sehingga kami dapat mengimplementasikan fitur-fitur yang ada di sana.
Skema pembagian. Saya akan mendukung sharding dengan rentang yang sama di seluruh keranjang, karena hal ini memungkinkan permintaan dari keranjang yang berbeda didistribusikan dengan baik ke seluruh cluster besar.
Menggunakan Tarantool. Tarantool banyak membantu dalam pengembangan layanan dan modifikasinya; kami dengan mudah bekerja dengan data, mengubah dan membagi penyimpanan, tanpa perlu naik ke lapisan aplikasi.
Laporan ini pertama kali dipresentasikan pada oleh Solusi Cloud Mail.ru & Tarantool. Lihat pertunjukan lainnya dan berlangganan pengumuman acara di Telegram .
Anda juga dapat menonton laporan lama saya tentang S3 atau membaca artikel rekan saya tentang penyimpanan blok.
- .
- .
Sumber: www.habr.com
