

Terkadang, untuk menyelesaikan suatu masalah, Anda hanya perlu melihatnya dari sudut yang berbeda. Sekalipun selama 10 tahun terakhir permasalahan serupa telah diselesaikan dengan cara yang sama dan dampak yang berbeda, namun faktanya metode ini bukanlah satu-satunya.
Ada topik seperti churn pelanggan. Hal ini tidak dapat dihindari, karena pelanggan perusahaan mana pun, karena berbagai alasan, dapat berhenti menggunakan produk atau layanannya. Tentu saja, bagi sebuah perusahaan, churn adalah hal yang wajar, tetapi bukan tindakan yang paling diinginkan, jadi semua orang berusaha meminimalkan churn ini. Lebih baik lagi, prediksi kemungkinan churn untuk kategori pengguna tertentu, atau pengguna tertentu, dan sarankan beberapa langkah untuk mempertahankannya.
Penting untuk menganalisis dan mencoba mempertahankan klien, jika memungkinkan, setidaknya karena alasan berikut:
- menarik pelanggan baru lebih mahal daripada prosedur retensi. Untuk menarik pelanggan baru, biasanya Anda perlu mengeluarkan sejumlah uang (iklan), sedangkan pelanggan yang sudah ada dapat diaktifkan dengan penawaran khusus dengan ketentuan khusus;
- Memahami alasan mengapa pelanggan pergi adalah kunci untuk meningkatkan produk dan layanan.
Ada pendekatan standar untuk memprediksi churn. Namun di salah satu kejuaraan AI, kami memutuskan untuk mencoba distribusi Weibull untuk ini. Hal ini paling sering digunakan untuk analisis kemampuan bertahan hidup, prakiraan cuaca, analisis bencana alam, teknik industri dan sejenisnya. Distribusi Weibull adalah fungsi distribusi khusus yang diparameterisasi oleh dua parameter  и
и  .
.
Wikipedia
Secara umum, ini merupakan hal yang menarik, namun untuk memperkirakan arus keluar, dan di fintech secara umum, hal ini jarang digunakan. Di bawah ini kami akan memberi tahu Anda bagaimana kami (Laboratorium Penambangan Data) melakukan hal ini, sekaligus memenangkan medali emas di Kejuaraan Kecerdasan Buatan dalam kategori “AI di Bank”.
Tentang churn secara umum
Mari kita pahami sedikit tentang apa itu churn pelanggan dan mengapa hal itu sangat penting. Basis pelanggan penting untuk bisnis. Pelanggan baru datang ke basis ini, misalnya, setelah mengetahui suatu produk atau jasa dari sebuah iklan, hidup selama beberapa waktu (aktif menggunakan produk tersebut) dan setelah beberapa waktu berhenti menggunakannya. Periode ini disebut “Customer Lifecycle” (Siklus Hidup Pelanggan) – istilah yang menggambarkan tahapan yang dilalui pelanggan ketika ia mempelajari suatu produk, membuat keputusan pembelian, membayar, menggunakan dan menjadi konsumen setia, dan akhirnya berhenti menggunakan produk tersebut karena satu dan lain hal. Oleh karena itu, churn adalah tahap akhir dari siklus hidup klien, ketika klien berhenti menggunakan layanan, dan bagi sebuah bisnis, ini berarti klien tidak lagi menghasilkan keuntungan atau keuntungan apa pun.
Setiap nasabah bank adalah orang tertentu yang memilih satu atau beberapa kartu bank khusus untuk kebutuhannya. Jika Anda sering bepergian, kartu bermil-mil akan berguna. Beli banyak - halo, kartu cashback. Dia membeli banyak di toko tertentu - dan sudah ada plastik mitra khusus untuk ini. Tentu saja, terkadang kartu dipilih berdasarkan kriteria “Layanan Termurah”. Secara umum, ada cukup banyak variabel di sini.
Dan seseorang juga memilih bank itu sendiri - apakah ada gunanya memilih kartu dari bank yang cabangnya hanya ada di Moskow dan wilayah tersebut, ketika Anda berasal dari Khabarovsk? Sekalipun kartu dari bank tersebut setidaknya 2 kali lebih menguntungkan, keberadaan cabang bank terdekat tetap menjadi kriteria penting. Ya, tahun 2019 sudah tiba dan digital adalah segalanya bagi kami, namun sejumlah permasalahan pada beberapa bank hanya dapat diselesaikan di cabang. Ditambah lagi, sebagian masyarakat lebih mempercayai bank fisik dibandingkan aplikasi di smartphone, hal ini juga perlu diperhatikan.
Akibatnya, seseorang mungkin mempunyai banyak alasan untuk menolak produk bank (atau bank itu sendiri). Saya berganti pekerjaan, dan tarif kartu berubah dari gaji menjadi “Untuk manusia biasa”, yang kurang menguntungkan. Saya pindah ke kota lain yang tidak memiliki cabang bank. Saya tidak suka interaksi dengan operator yang tidak memenuhi syarat di cabang. Artinya, mungkin ada lebih banyak alasan untuk menutup akun daripada menggunakan produk.
Dan klien tidak hanya dapat dengan jelas mengungkapkan niatnya - datang ke bank dan menulis pernyataan, tetapi juga berhenti menggunakan produk tanpa mengakhiri kontrak. Diputuskan untuk menggunakan pembelajaran mesin dan AI untuk memahami masalah tersebut.
Selain itu, churn pelanggan dapat terjadi di industri mana pun (telekomunikasi, penyedia Internet, perusahaan asuransi, secara umum, di mana pun terdapat basis pelanggan dan transaksi berkala).
Apa yang telah kita lakukan
Pertama-tama, penting untuk menggambarkan batasan yang jelas - mulai dari jam berapa kami mulai menganggap klien telah pergi. Dari sudut pandang bank, yang memberi kami data pekerjaan, status aktivitas klien adalah biner - aktif atau tidak. Terdapat tanda ACTIVE_FLAG di tabel "Aktivitas", yang nilainya dapat berupa "0" atau "1" (masing-masing, "Tidak aktif" dan "Aktif"). Dan semuanya akan baik-baik saja, tetapi seseorang sedemikian rupa sehingga dia dapat menggunakannya secara aktif untuk beberapa waktu, dan kemudian keluar dari daftar aktif selama sebulan - dia sakit, pergi ke negara lain untuk berlibur, atau bahkan pergi untuk menguji a kartu dari bank lain. Atau mungkin setelah lama tidak aktif, mulai menggunakan kembali layanan bank tersebut
Oleh karena itu, kami memutuskan untuk menyebut periode tidak aktif sebagai periode waktu tertentu yang berkelanjutan di mana benderanya disetel ke “0”.
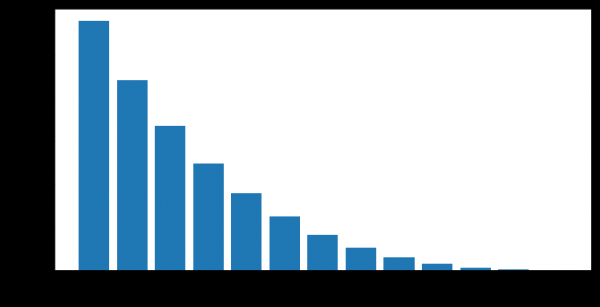
Klien berpindah dari tidak aktif menjadi aktif setelah periode tidak aktif dalam jangka waktu yang berbeda-beda. Kami memiliki kesempatan untuk menghitung tingkat nilai empiris "keandalan periode tidak aktif" - yaitu, kemungkinan seseorang akan mulai menggunakan produk bank lagi setelah tidak aktif sementara.
Misalnya, grafik ini menunjukkan dimulainya kembali aktivitas (ACTIVE_FLAG=1) klien setelah beberapa bulan tidak aktif (ACTIVE_FLAG=0).
Di sini kami akan memperjelas sedikit kumpulan data yang mulai kami gunakan. Jadi, bank menyediakan informasi agregat selama 19 bulan dalam tabel berikut:
- "Aktivitas" - transaksi bulanan pelanggan (dengan kartu, di Internet banking dan mobile banking), termasuk penggajian dan informasi omset.
- "Kartu" - data pada semua kartu yang dimiliki klien, dengan jadwal tarif terperinci.
- "Perjanjian" - informasi tentang perjanjian klien (baik terbuka maupun tertutup): pinjaman, deposito, dll., yang menunjukkan parameter masing-masing.
- “Pelanggan” - sekumpulan data demografi (jenis kelamin dan usia) dan ketersediaan informasi kontak.
Untuk pekerjaan kami membutuhkan semua tabel kecuali "Peta".
Ada kesulitan lain di sini - dalam data ini bank tidak menunjukkan jenis aktivitas apa yang terjadi pada kartu tersebut. Artinya, kita bisa memahami ada atau tidaknya transaksi, tapi kita tidak bisa lagi menentukan jenisnya. Oleh karena itu, tidak jelas apakah klien menarik uang tunai, menerima gaji, atau membelanjakan uangnya untuk pembelian. Kami juga tidak memiliki data saldo rekening, yang mungkin berguna.
Sampelnya sendiri tidak memihak - dalam sampel ini, selama 19 bulan, bank tidak melakukan upaya apa pun untuk mempertahankan pelanggan dan meminimalkan arus keluar.
Jadi, tentang periode tidak aktif.
Untuk merumuskan definisi churn, periode tidak aktif harus dipilih. Untuk membuat perkiraan churn pada suatu waktu  , Anda harus memiliki riwayat pelanggan minimal 3 bulan dengan interval tertentu
, Anda harus memiliki riwayat pelanggan minimal 3 bulan dengan interval tertentu  . Riwayat kami dibatasi hingga 19 bulan, jadi kami memutuskan untuk mengambil masa tidak aktif selama 6 bulan, jika tersedia. Dan untuk jangka waktu minimal ramalan berkualitas tinggi, kami membutuhkan waktu 3 bulan. Kami mengambil angka selama 3 dan 6 bulan secara empiris berdasarkan analisis perilaku data pelanggan.
. Riwayat kami dibatasi hingga 19 bulan, jadi kami memutuskan untuk mengambil masa tidak aktif selama 6 bulan, jika tersedia. Dan untuk jangka waktu minimal ramalan berkualitas tinggi, kami membutuhkan waktu 3 bulan. Kami mengambil angka selama 3 dan 6 bulan secara empiris berdasarkan analisis perilaku data pelanggan.
Kami merumuskan definisi churn sebagai berikut: bulan churn pelanggan  ini adalah bulan pertama dengan ACTIVE_FLAG=0, dimana mulai bulan ini terdapat minimal enam angka nol berturut-turut pada kolom ACTIVE_FLAG, dengan kata lain, bulan dimana klien tidak aktif selama 6 bulan.
ini adalah bulan pertama dengan ACTIVE_FLAG=0, dimana mulai bulan ini terdapat minimal enam angka nol berturut-turut pada kolom ACTIVE_FLAG, dengan kata lain, bulan dimana klien tidak aktif selama 6 bulan.
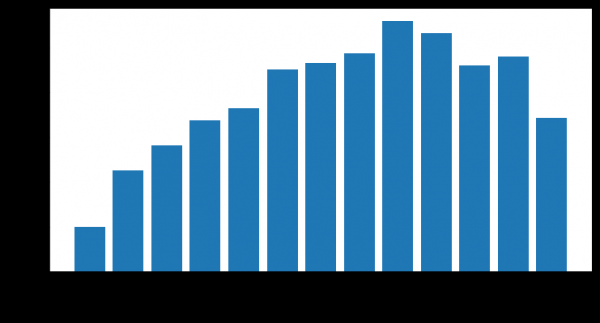
Jumlah klien yang keluar
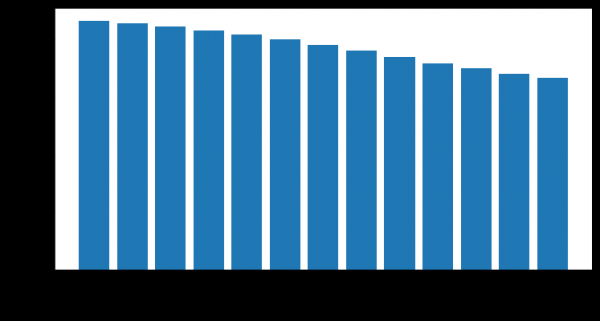
Jumlah klien yang tersisa
Bagaimana cara menghitung churn?
Dalam kompetisi seperti itu, dan dalam praktik secara umum, arus keluar sering kali diprediksi dengan cara ini. Klien menggunakan produk dan layanan pada periode waktu yang berbeda, data interaksi dengannya direpresentasikan sebagai vektor fitur dengan panjang tetap n. Paling sering informasi ini meliputi:
- Data yang mengkarakterisasi pengguna (data demografi, segmen pemasaran).
- Riwayat penggunaan produk dan jasa perbankan (tindakan nasabah yang selalu terikat pada waktu atau jangka waktu tertentu dalam jangka waktu yang kita perlukan).
- Data eksternal, jika memungkinkan - misalnya, ulasan dari jejaring sosial.
Dan setelah itu, mereka memperoleh definisi churn yang berbeda-beda untuk setiap tugas. Kemudian mereka menggunakan algoritme pembelajaran mesin, yang memprediksi kemungkinan keluarnya klien  berdasarkan vektor faktor
berdasarkan vektor faktor  . Untuk melatih algoritme, salah satu kerangka kerja terkenal untuk membangun ansambel pohon keputusan digunakan, , , atau modifikasinya.
. Untuk melatih algoritme, salah satu kerangka kerja terkenal untuk membangun ansambel pohon keputusan digunakan, , , atau modifikasinya.
Algoritmenya sendiri tidak buruk, tetapi memiliki beberapa kelemahan serius dalam memprediksi churn.
- Dia tidak memiliki apa yang disebut “ingatan”. Masukan model adalah sejumlah fitur tertentu yang sesuai dengan titik waktu saat ini. Untuk menyimpan informasi tentang riwayat perubahan parameter, perlu dihitung fitur-fitur khusus yang mencirikan perubahan parameter dari waktu ke waktu, misalnya jumlah atau jumlah transaksi bank selama 1,2,3, XNUMX, XNUMX bulan terakhir. Pendekatan ini hanya dapat mencerminkan sebagian sifat perubahan sementara.
- Memperbaiki cakrawala perkiraan. Model ini hanya mampu memprediksi churn pelanggan untuk jangka waktu yang telah ditentukan, misalnya perkiraan satu bulan sebelumnya. Jika perkiraan diperlukan untuk periode waktu yang berbeda, misalnya tiga bulan, maka Anda perlu membangun kembali set pelatihan dan melatih kembali model baru.
Pendekatan kami
Kami segera memutuskan bahwa kami tidak akan menggunakan pendekatan standar. Selain kami, 497 orang lagi mendaftar di kejuaraan tersebut, yang masing-masing memiliki pengalaman yang cukup di belakang mereka. Jadi mencoba melakukan sesuatu sesuai skema standar dalam kondisi seperti itu bukanlah ide yang baik.
Dan kami mulai memecahkan masalah yang dihadapi model klasifikasi biner dengan memprediksi distribusi probabilitas waktu churn pelanggan. Pendekatan serupa dapat dilihat , ini memungkinkan Anda memprediksi churn dengan lebih fleksibel dan menguji hipotesis yang lebih kompleks dibandingkan pendekatan klasik. Sebagai keluarga distribusi yang memodelkan waktu arus keluar, kami memilih distribusi tersebut untuk digunakan secara luas dalam analisis kelangsungan hidup. Perilaku klien dapat dipandang sebagai semacam kelangsungan hidup.
Berikut adalah contoh distribusi kepadatan probabilitas Weibull bergantung pada parameter  и
и  :
:
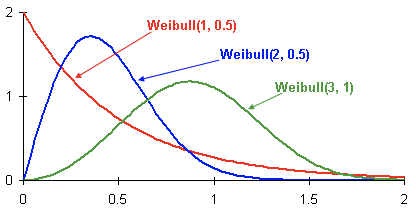
Ini adalah fungsi kepadatan probabilitas dari tiga pelanggan berbeda yang berpindah dari waktu ke waktu. Waktu disajikan dalam bulan. Dengan kata lain, grafik ini menunjukkan kapan klien kemungkinan besar akan churn dalam dua bulan ke depan. Seperti yang Anda lihat, klien dengan distribusi memiliki potensi lebih besar untuk keluar lebih awal dibandingkan klien dengan Weibull(2, 0.5) dan Weibull. (3,1) distribusi.
Hasilnya adalah sebuah model yang, untuk setiap klien, untuk setiap orang
bulan memprediksi parameter distribusi Weibull, yang paling mencerminkan terjadinya kemungkinan arus keluar dari waktu ke waktu. Lebih detailnya:
- Fitur target pada set pelatihan adalah waktu yang tersisa hingga churn pada bulan tertentu untuk klien tertentu.
- Jika tidak ada churn rate untuk pelanggan, kami berasumsi bahwa churn time lebih besar dari jumlah bulan dari bulan ini hingga akhir riwayat yang kami miliki.
- Model yang digunakan: jaringan saraf berulang dengan lapisan LSTM.
- Sebagai fungsi kerugian, kami menggunakan fungsi log-likelihood negatif untuk distribusi Weibull.
Berikut kelebihan metode ini:
- Distribusi probabilitas, selain kemungkinan klasifikasi biner yang jelas, memungkinkan prediksi yang fleksibel terhadap berbagai peristiwa, misalnya, apakah nasabah akan berhenti menggunakan layanan bank dalam waktu 3 bulan. Selain itu, jika perlu, berbagai metrik dapat dirata-ratakan pada distribusi ini.
- Jaringan saraf berulang LSTM memiliki memori dan secara efektif menggunakan seluruh riwayat yang tersedia. Ketika cerita diperluas atau disempurnakan, akurasi meningkat.
- Pendekatan ini dapat dengan mudah diperluas ketika membagi periode waktu menjadi lebih kecil (misalnya, ketika membagi bulan menjadi minggu).
Namun membuat model yang baik saja tidak cukup; Anda juga perlu mengevaluasi kualitasnya dengan tepat.
Bagaimana kualitas dinilai?
Kami memilih Lift Curve sebagai metriknya. Ini digunakan dalam bisnis untuk kasus-kasus seperti itu karena interpretasinya yang jelas, dijelaskan dengan baik и . Jika Anda mendeskripsikan arti metrik ini dalam satu kalimat, maka kalimatnya adalah “Berapa kali algoritme membuat prediksi terbaik pada saat pertama?”  % daripada secara acak."
% daripada secara acak."
Model pelatihan
Kondisi persaingan tidak menetapkan metrik kualitas spesifik yang dapat digunakan untuk membandingkan model dan pendekatan yang berbeda. Selain itu, definisi churn bisa berbeda-beda dan mungkin bergantung pada rumusan masalah, yang pada gilirannya ditentukan oleh tujuan bisnis. Oleh karena itu, untuk memahami metode mana yang lebih baik, kami melatih dua model:
- Pendekatan klasifikasi biner yang umum digunakan menggunakan algoritma pembelajaran mesin pohon keputusan ansambel ();
- Model Weibull-LSTM
Set pengujian terdiri dari 500 klien yang telah dipilih sebelumnya yang tidak mengikuti set pelatihan. Hyper-parameter dipilih untuk model menggunakan validasi silang, yang dikelompokkan berdasarkan klien. Kumpulan fitur yang sama digunakan untuk melatih setiap model.
Karena model tidak memiliki memori, fitur khusus diambil untuk model tersebut, yang menunjukkan rasio perubahan parameter satu bulan dengan nilai rata-rata parameter selama tiga bulan terakhir. Apa yang menjadi ciri laju perubahan nilai selama periode tiga bulan terakhir. Tanpa hal ini, model berbasis Random Forest akan berada pada posisi yang kurang menguntungkan dibandingkan Weibull-LSTM.
Mengapa LSTM dengan distribusi Weibull lebih baik daripada pendekatan pohon keputusan ansambel
Semuanya jelas di sini hanya dalam beberapa gambar.
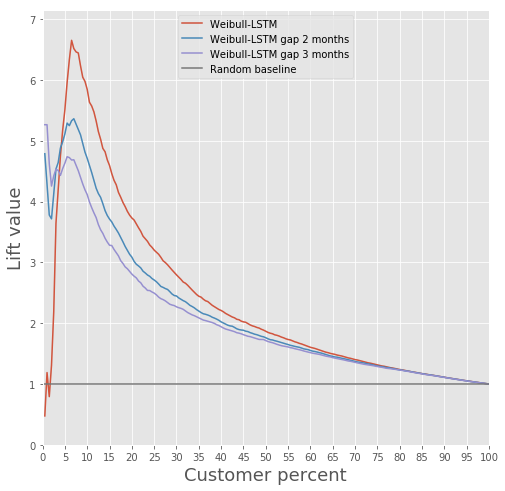
Perbandingan Lift Curve untuk algoritma klasik dan Weibull-LSTM
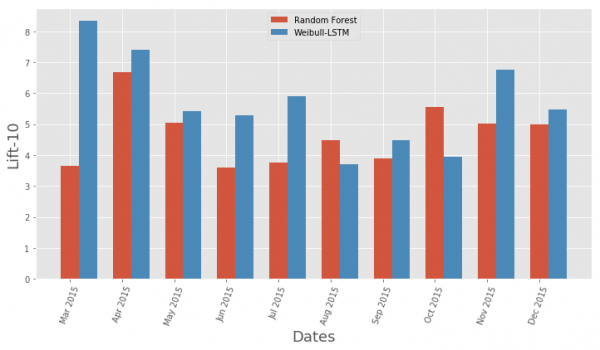
Perbandingan metrik Lift Curve berdasarkan bulan untuk algoritma klasik dan Weibull-LSTM
Secara umum, LSTM lebih unggul dari algoritma klasik di hampir semua kasus.
Prediksi churn
Model yang didasarkan pada jaringan saraf berulang dengan sel LSTM dengan distribusi Weibull dapat memprediksi churn terlebih dahulu, misalnya memprediksi churn pelanggan dalam n bulan ke depan. Pertimbangkan kasus untuk n = 3. Dalam hal ini, untuk setiap bulan, jaringan saraf harus menentukan dengan benar apakah klien akan keluar, mulai dari bulan berikutnya hingga bulan ke-n. Dengan kata lain, ia harus menentukan dengan tepat apakah pelanggan akan tetap tinggal setelah n bulan. Ini dapat dianggap sebagai perkiraan sebelumnya: memprediksi momen ketika klien baru mulai berpikir untuk pergi.
Mari kita bandingkan Lift Curve untuk Weibull-LSTM 1, 2 dan 3 bulan sebelum churn:
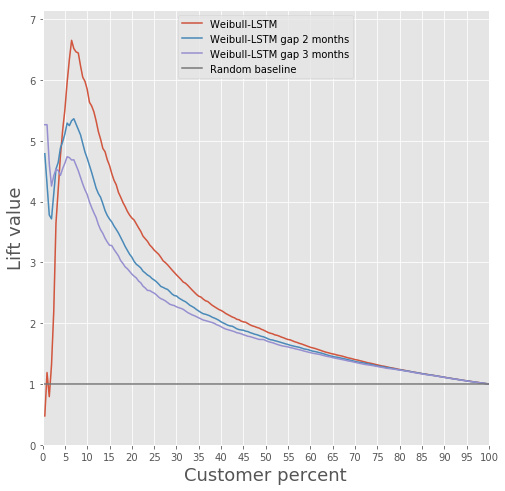
Sudah kami tulis di atas bahwa perkiraan yang dibuat untuk klien yang sudah tidak aktif untuk beberapa waktu juga penting. Oleh karena itu, di sini kami akan menambahkan contoh kasus ketika pelanggan yang pergi sudah tidak aktif selama satu atau dua bulan, dan memeriksa apakah Weibull-LSTM dengan benar mengklasifikasikan kasus tersebut sebagai churn. Karena kasus-kasus seperti ini terdapat dalam sampel, kami berharap jaringan dapat menanganinya dengan baik:
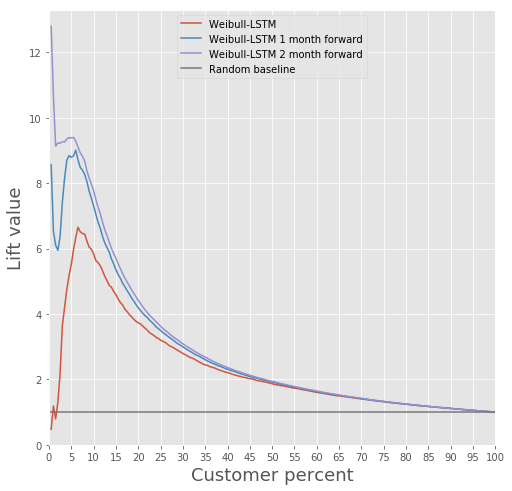
Retensi pelanggan
Sebenarnya, ini adalah hal utama yang dapat dilakukan, dengan memiliki informasi bahwa klien ini dan itu sedang bersiap untuk berhenti menggunakan produk. Berbicara tentang membangun model yang dapat menawarkan sesuatu yang berguna kepada pelanggan untuk mempertahankan mereka, hal ini tidak dapat dilakukan jika Anda tidak memiliki riwayat upaya serupa yang akan berakhir dengan baik.
Kami tidak punya cerita seperti itu, jadi kami memutuskannya seperti ini.
- Kami sedang membangun model yang mengidentifikasi produk menarik untuk setiap klien.
- Setiap bulan kami menjalankan pengklasifikasi dan mengidentifikasi pelanggan yang berpotensi keluar.
- Kami menawarkan produk kepada beberapa klien, sesuai dengan model dari poin 1, dan mengingat tindakan kami.
- Setelah beberapa bulan, kami melihat klien mana yang tersisa dan mana yang tersisa. Jadi, kami membentuk sampel pelatihan.
- Kami melatih model menggunakan riwayat yang diperoleh pada langkah 4.
- Secara opsional, kami ulangi prosedurnya, mengganti model dari langkah 1 dengan model yang diperoleh pada langkah 5.
Uji kualitas retensi tersebut dapat dilakukan dengan pengujian A/B reguler - kami membagi pelanggan yang berpotensi keluar menjadi dua kelompok. Kami menawarkan produk kepada salah satu pihak berdasarkan model retensi kami, dan kepada pihak lain kami tidak menawarkan apa pun. Kami memutuskan untuk melatih model yang mungkin berguna pada poin 1 contoh kami.
Kami ingin membuat segmentasi dapat diinterpretasikan semaksimal mungkin. Untuk melakukan ini, kami memilih beberapa fitur yang mudah diinterpretasikan: jumlah total transaksi, gaji, total perputaran akun, usia, jenis kelamin. Fitur dari tabel “Maps” tidak dianggap tidak informatif, dan fitur dari tabel 3 “Kontrak” tidak diperhitungkan karena rumitnya pemrosesan untuk menghindari kebocoran data antara set validasi dan set pelatihan.
Clustering dilakukan dengan menggunakan model campuran Gaussian. Kriteria informasi Akaike memungkinkan kami menentukan 2 optima. Optimal pertama berhubungan dengan 1 cluster. Optimal kedua, yang kurang menonjol, berhubungan dengan 80 cluster. Berdasarkan hasil ini, kita dapat menarik kesimpulan sebagai berikut: sangat sulit untuk membagi data menjadi beberapa cluster tanpa informasi yang ditentukan secara apriori. Untuk pengelompokan yang lebih baik, Anda memerlukan data yang menjelaskan setiap klien secara detail.
Oleh karena itu, masalah pembelajaran yang diawasi dipertimbangkan untuk menawarkan produk yang berbeda kepada setiap klien. Produk-produk berikut dipertimbangkan: “Deposito Berjangka”, “Kartu Kredit”, “Cerukan”, “Pinjaman Konsumen”, “Pinjaman Mobil”, “Hipotek”.
Data tersebut mencakup satu jenis produk lagi: “Rekening Giro”. Namun kami tidak mempertimbangkannya karena kandungan informasinya yang rendah. Untuk pengguna yang merupakan nasabah bank, mis. tidak berhenti menggunakan produknya, sebuah model dibangun untuk memprediksi produk mana yang mungkin menarik bagi mereka. Regresi logistik dipilih sebagai model, dan nilai Peningkatan untuk 10 persentil pertama digunakan sebagai metrik penilaian kualitas.
Kualitas model dapat dinilai pada gambar.
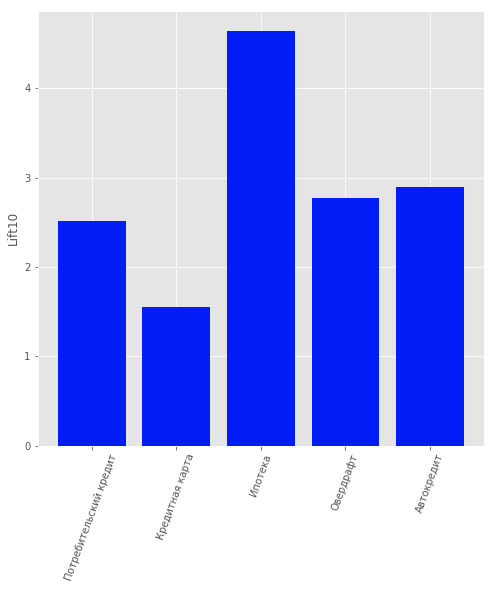
Hasil model rekomendasi produk untuk pelanggan
Total
Pendekatan ini membawa kami menjadi juara pertama dalam kategori “AI in Banks” di RAIF-Challenge 2017 AI Championship.

Rupanya, hal utama adalah mendekati masalah dari sudut pandang yang kurang familiar dan menggunakan metode yang biasanya digunakan untuk situasi lain.
Meskipun arus keluar pengguna secara besar-besaran mungkin merupakan bencana alam bagi layanan.
Metode ini dapat diperhitungkan di area lain mana pun yang penting untuk memperhitungkan arus keluar, tidak hanya bank. Misalnya, kami menggunakannya untuk menghitung arus keluar kami sendiri - di Rostelecom cabang Siberia dan St. Petersburg.
Perusahaan "Laboratorium Penambangan Data" "Portal Pencarian" Sputnik "
Sumber: www.habr.com
