


Saya menemukan beberapa materi menarik tentang kecerdasan buatan dalam game. Dengan penjelasan tentang hal-hal dasar tentang AI menggunakan contoh-contoh sederhana, dan di dalamnya terdapat banyak alat dan metode yang berguna untuk pengembangan dan desainnya yang mudah. Bagaimana, dimana dan kapan menggunakannya juga ada.
Sebagian besar contoh ditulis dalam pseudocode, jadi tidak diperlukan pengetahuan pemrograman tingkat lanjut. Di bawah potongannya ada 35 lembar teks dengan gambar dan gif, jadi bersiaplah.
UPD. Saya minta maaf, tapi saya sudah menerjemahkan sendiri artikel ini di Habré . Anda dapat membaca versinya , tetapi karena alasan tertentu artikel tersebut terlewatkan (saya menggunakan pencarian, tetapi ada yang tidak beres). Dan karena saya menulis di blog yang didedikasikan untuk pengembangan game, saya memutuskan untuk meninggalkan versi terjemahan saya untuk pelanggan (beberapa poin diformat berbeda, beberapa sengaja dihilangkan atas saran pengembang).
Apa itu AI?
Game AI berfokus pada tindakan apa yang harus dilakukan suatu objek berdasarkan kondisi lokasinya. Hal ini biasanya disebut sebagai manajemen "agen cerdas", di mana agen adalah karakter pemain, kendaraan, bot, atau terkadang sesuatu yang lebih abstrak: seluruh kelompok entitas atau bahkan sebuah peradaban. Dalam setiap kasus, ia adalah sesuatu yang harus melihat lingkungannya, mengambil keputusan berdasarkan lingkungan tersebut, dan bertindak sesuai dengan lingkungan tersebut. Ini disebut siklus Merasakan/Berpikir/Bertindak:
- Sense: Agen menemukan atau menerima informasi tentang hal-hal di lingkungannya yang dapat mempengaruhi perilakunya (ancaman di sekitar, barang untuk dikumpulkan, tempat menarik untuk dijelajahi).
- Pikirkan: Agen memutuskan bagaimana bereaksi (mempertimbangkan apakah cukup aman untuk mengumpulkan item atau apakah dia harus bertarung/bersembunyi terlebih dahulu).
- Act: agen melakukan tindakan untuk melaksanakan keputusan sebelumnya (mulai bergerak menuju musuh atau objek).
- ...sekarang situasinya telah berubah karena tindakan karakter, sehingga siklus berulang dengan data baru.
AI cenderung fokus pada bagian Sense dari loop. Misalnya, mobil otonom mengambil gambar jalan, menggabungkannya dengan data radar dan lidar, dan menafsirkannya. Hal ini biasanya dilakukan dengan pembelajaran mesin, yang memproses data yang masuk dan memberinya makna, mengekstraksi informasi semantik seperti “ada mobil lain 20 meter di depan Anda.” Inilah yang disebut masalah klasifikasi.
Game tidak memerlukan sistem yang rumit untuk mengekstrak informasi karena sebagian besar data sudah menjadi bagian integralnya. Tidak perlu menjalankan algoritme pengenalan gambar untuk menentukan apakah ada musuh di depan—game sudah mengetahui dan memasukkan informasi tersebut langsung ke dalam proses pengambilan keputusan. Oleh karena itu, bagian Sense dari siklus ini seringkali jauh lebih sederhana dibandingkan bagian Think and Act.
Keterbatasan Game AI
AI memiliki sejumlah keterbatasan yang harus diperhatikan:
- AI tidak perlu dilatih terlebih dahulu, seolah-olah AI adalah algoritma pembelajaran mesin. Tidak masuk akal untuk menulis jaringan saraf selama pengembangan untuk memantau puluhan ribu pemain dan mempelajari cara terbaik untuk bermain melawan mereka. Mengapa? Karena gamenya belum dirilis dan belum ada pemainnya.
- Permainannya harus menyenangkan dan menantang, jadi agen tidak boleh menemukan pendekatan terbaik terhadap orang lain.
- Agen harus tampil realistis agar pemain merasa seperti sedang bermain melawan orang sungguhan. Program AlphaGo mengungguli manusia, namun langkah yang dipilih sangat jauh dari pemahaman tradisional tentang permainan tersebut. Jika game tersebut mensimulasikan lawan manusia, perasaan ini seharusnya tidak ada. Algoritme perlu diubah agar dapat menghasilkan keputusan yang masuk akal, bukan keputusan ideal.
- AI harus bekerja secara real time. Artinya algoritma tidak dapat memonopoli penggunaan CPU dalam jangka waktu yang lama untuk mengambil keputusan. Bahkan 10 milidetik pun terlalu lama, karena sebagian besar game hanya membutuhkan 16 hingga 33 milidetik untuk melakukan semua pemrosesan dan beralih ke bingkai grafis berikutnya.
- Idealnya, setidaknya sebagian dari sistem harus berbasis data, sehingga non-coders dapat membuat perubahan dan penyesuaian dapat terjadi lebih cepat.
Mari kita lihat pendekatan AI yang mencakup keseluruhan siklus Sense/Think/Act.
Membuat Keputusan Dasar
Mari kita mulai dengan permainan paling sederhana - Pong. Sasaran: gerakkan dayung sehingga bola memantul dan tidak terbang melewatinya. Ibarat tenis, Anda kalah jika tidak memukul bola. Di sini AI memiliki tugas yang relatif mudah - memutuskan ke arah mana platform akan dipindahkan.

Pernyataan bersyarat
Untuk AI di Pong, solusi paling jelas adalah selalu mencoba menempatkan platform di bawah bola.
Algoritma sederhana untuk ini, ditulis dalam pseudocode:
setiap frame/pembaruan saat game sedang berjalan:
jika bola berada di sebelah kiri dayung:
gerakkan dayung ke kiri
else jika bola berada di sebelah kanan dayung:
gerakkan dayung ke kanan
Jika platform bergerak dengan kecepatan bola, maka ini adalah algoritma yang ideal untuk AI di Pong. Tidak perlu memperumit apa pun jika tidak banyak data dan kemungkinan tindakan untuk agen.
Pendekatan ini sangat sederhana sehingga keseluruhan siklus Sense/Think/Act hampir tidak terlihat. Tapi itu ada di sana:
- Bagian Sense ada dalam dua pernyataan if. Permainan mengetahui di mana bola berada dan di mana platform berada, sehingga AI mencari informasi tersebut.
- Bagian Think juga disertakan dalam dua pernyataan if. Mereka mewujudkan dua solusi, yang dalam hal ini saling eksklusif. Hasilnya, salah satu dari tiga tindakan dipilih - pindahkan platform ke kiri, pindahkan ke kanan, atau tidak melakukan apa pun jika posisinya sudah benar.
- Bagian Act ditemukan dalam pernyataan Move Paddle Left dan Move Paddle Right. Tergantung pada desain gamenya, mereka dapat menggerakkan platform secara instan atau dengan kecepatan tertentu.
Pendekatan seperti ini disebut reaktif - ada seperangkat aturan sederhana (dalam hal ini pernyataan dalam kode) yang bereaksi terhadap keadaan dunia saat ini dan mengambil tindakan.
Pohon keputusan
Contoh Pong sebenarnya setara dengan konsep AI formal yang disebut pohon keputusan. Algoritme melewatinya untuk mencapai “daun”—keputusan tentang tindakan apa yang harus diambil.
Mari kita buat diagram blok pohon keputusan untuk algoritma platform kita:
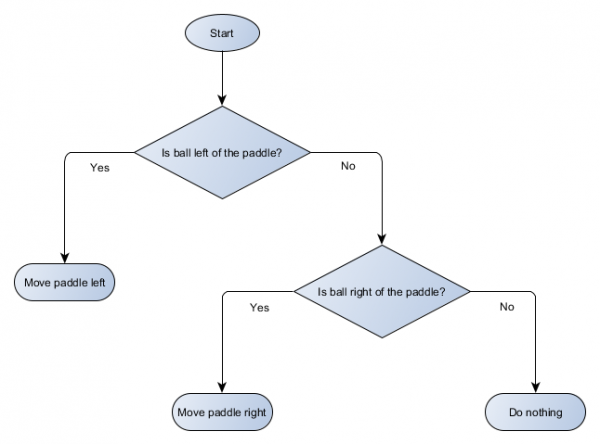
Setiap bagian pohon disebut simpul - AI menggunakan teori grafik untuk menggambarkan struktur tersebut. Ada dua jenis node:
- Node keputusan: memilih antara dua alternatif berdasarkan pengujian beberapa kondisi, dimana setiap alternatif direpresentasikan sebagai node terpisah.
- Node akhir: Tindakan yang harus dilakukan yang mewakili keputusan akhir.
Algoritmenya dimulai dari node pertama (“akar” pohon). Ia akan membuat keputusan tentang node anak mana yang akan dituju, atau mengeksekusi tindakan yang tersimpan di node tersebut dan keluar.
Apa manfaat pohon keputusan melakukan tugas yang sama seperti pernyataan if di bagian sebelumnya? Ada sistem umum di sini di mana setiap keputusan hanya memiliki satu kondisi dan dua kemungkinan hasil. Hal ini memungkinkan pengembang untuk membuat AI dari data yang mewakili keputusan di pohon tanpa harus melakukan hard-code. Mari kita sajikan dalam bentuk tabel:
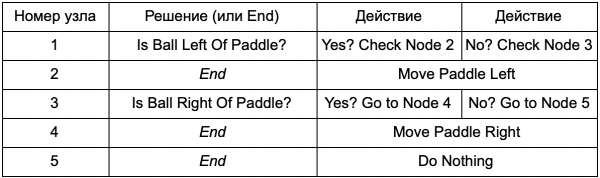
Di sisi kode Anda akan mendapatkan sistem untuk membaca string. Buat node untuk masing-masing node, sambungkan logika keputusan berdasarkan kolom kedua, dan node anak berdasarkan kolom ketiga dan keempat. Anda masih perlu memprogram kondisi dan tindakan, tetapi sekarang struktur permainan akan lebih kompleks. Di sini Anda menambahkan keputusan dan tindakan tambahan, lalu menyesuaikan seluruh AI hanya dengan mengedit file teks definisi pohon. Selanjutnya, Anda mentransfer file ke perancang game, yang dapat mengubah perilaku tanpa mengkompilasi ulang game atau mengubah kode.
Pohon keputusan sangat berguna ketika dibuat secara otomatis dari sejumlah besar contoh (misalnya, menggunakan algoritma ID3). Hal ini menjadikannya alat yang efektif dan berkinerja tinggi untuk mengklasifikasikan situasi berdasarkan data yang diperoleh. Namun, kami lebih dari sekadar sistem sederhana bagi agen untuk memilih tindakan.
Skenario
Kami menganalisis sistem pohon keputusan yang menggunakan kondisi dan tindakan yang telah dibuat sebelumnya. Orang yang merancang AI dapat mengatur pohon sesukanya, namun ia tetap harus bergantung pada pembuat kode yang memprogram semuanya. Bagaimana jika kita dapat memberikan alat kepada perancang untuk menciptakan kondisi atau tindakannya sendiri?
Agar pemrogram tidak perlu menulis kode untuk kondisi Is Ball Left Of Paddle dan Is Ball Right Of Paddle, ia dapat membuat sistem di mana perancang akan menulis kondisi untuk memeriksa nilai-nilai tersebut. Maka data pohon keputusan akan terlihat seperti ini:
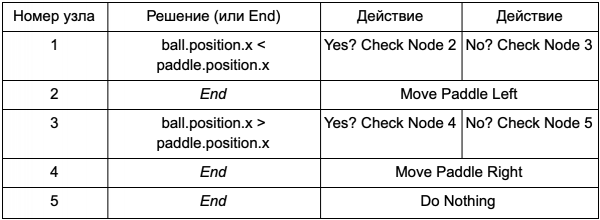
Ini pada dasarnya sama seperti pada tabel pertama, tetapi solusi di dalamnya memiliki kodenya sendiri, mirip dengan bagian kondisional dari pernyataan if. Di sisi kode, ini akan dibaca di kolom kedua untuk node keputusan, tetapi alih-alih mencari kondisi tertentu untuk dieksekusi (Apakah Bola Tersisa Dari Dayung), ini mengevaluasi ekspresi kondisional dan mengembalikan nilai benar atau salah. Hal ini dilakukan dengan menggunakan bahasa skrip Lua atau Angelscript. Dengan menggunakannya, pengembang dapat mengambil objek dalam permainannya (bola dan dayung) dan membuat variabel yang akan tersedia dalam skrip (posisi bola). Selain itu, bahasa skripnya lebih sederhana daripada C++. Ini tidak memerlukan tahap kompilasi penuh, sehingga ideal untuk menyesuaikan logika permainan dengan cepat dan memungkinkan “non-coder” untuk membuat sendiri fungsi yang diperlukan.
Dalam contoh di atas, bahasa scripting hanya digunakan untuk mengevaluasi ekspresi kondisional, namun bisa juga digunakan untuk tindakan. Misalnya, data Move Paddle Right bisa menjadi pernyataan skrip (ball.position.x += 10). Sehingga aksinya juga sudah ditentukan di script, tanpa perlu memprogram Move Paddle Right.
Anda dapat melangkah lebih jauh dan menulis seluruh pohon keputusan dalam bahasa skrip. Ini akan menjadi kode dalam bentuk pernyataan kondisional yang dikodekan secara hardcode, tetapi kode tersebut akan ditempatkan di file skrip eksternal, artinya, kode tersebut dapat diubah tanpa mengkompilasi ulang seluruh program. Anda sering kali dapat mengedit file skrip selama bermain game untuk menguji berbagai respons AI dengan cepat.
Respon Acara
Contoh di atas sangat cocok untuk Pong. Mereka terus menjalankan siklus Sense/Think/Act dan bertindak berdasarkan keadaan dunia terkini. Namun dalam permainan yang lebih kompleks, Anda perlu bereaksi terhadap peristiwa individual, dan tidak mengevaluasi semuanya sekaligus. Pong dalam hal ini sudah menjadi contoh buruk. Ayo pilih yang lain.
Bayangkan sebuah penembak di mana musuh tidak bergerak sampai mereka mendeteksi pemainnya, setelah itu mereka bertindak tergantung pada "spesialisasi" mereka: seseorang akan berlari untuk "terburu-buru", seseorang akan menyerang dari jauh. Ini masih merupakan sistem reaktif dasar - "jika seorang pemain terlihat, lakukan sesuatu" - tetapi secara logis dapat dipecah menjadi acara Player Seen dan Reaksi (pilih respons dan jalankan).
Hal ini membawa kita kembali ke siklus Merasakan/Berpikir/Bertindak. Kita dapat mengkodekan bagian Sense yang akan memeriksa setiap frame apakah AI melihat pemain. Jika tidak maka tidak terjadi apa-apa, namun jika terlihat maka event Player Seen akan dibuat. Kode akan memiliki bagian terpisah yang mengatakan "ketika peristiwa Player Seen terjadi, lakukan" yang merupakan respons yang Anda perlukan untuk menangani bagian Berpikir dan Bertindak. Dengan demikian, Anda akan mengatur reaksi terhadap acara Player Seen: untuk karakter "bergegas" - ChargeAndAttack, dan untuk penembak jitu - HideAndSnipe. Hubungan ini dapat dibuat dalam file data untuk pengeditan cepat tanpa harus dikompilasi ulang. Bahasa skrip juga dapat digunakan di sini.
Membuat keputusan sulit
Meskipun sistem reaksi sederhana sangat ampuh, ada banyak situasi di mana sistem tersebut tidak cukup. Terkadang Anda perlu membuat keputusan berbeda berdasarkan apa yang sedang dilakukan agen, namun sulit membayangkan ini sebagai suatu kondisi. Terkadang terdapat terlalu banyak kondisi untuk mewakilinya secara efektif dalam pohon keputusan atau skrip. Terkadang Anda perlu menilai terlebih dahulu bagaimana situasi akan berubah sebelum memutuskan langkah berikutnya. Diperlukan pendekatan yang lebih canggih untuk menyelesaikan permasalahan ini.
Mesin keadaan terbatas
Mesin keadaan terbatas atau FSM (mesin keadaan terbatas) adalah cara untuk mengatakan bahwa agen kita saat ini berada di salah satu dari beberapa kemungkinan keadaan, dan dapat bertransisi dari satu keadaan ke keadaan lainnya. Ada sejumlah negara bagian seperti itu—sesuai dengan namanya. Contoh terbaik dari kehidupan adalah lampu lalu lintas. Ada rangkaian lampu yang berbeda di tempat yang berbeda, namun prinsipnya sama - setiap keadaan mewakili sesuatu (berhenti, berjalan, dll.). Lampu lalu lintas hanya berada dalam satu keadaan pada waktu tertentu, dan berpindah dari satu keadaan ke keadaan lain berdasarkan aturan sederhana.
Ceritanya mirip dengan NPC di game. Sebagai contoh, mari kita ambil penjaga dengan status berikut:
- Ronda.
- Menyerang.
- Kabur.
Dan syarat untuk mengubah statusnya adalah:
- Jika penjaga melihat musuh, dia menyerang.
- Jika penjaga menyerang tetapi tidak lagi melihat musuh, dia kembali berpatroli.
- Jika seorang penjaga menyerang tetapi terluka parah, dia akan melarikan diri.
Anda juga dapat menulis pernyataan if dengan variabel status penjaga dan berbagai pemeriksaan: apakah ada musuh di sekitar, berapa tingkat kesehatan NPC, dll. Mari tambahkan beberapa status lagi:
- Kemalasan - di antara patroli.
- Pencarian - ketika musuh yang diketahui telah menghilang.
- Mencari Bantuan - ketika musuh terlihat, tetapi terlalu kuat untuk bertarung sendirian.
Pilihan masing-masing dari mereka terbatas - misalnya, penjaga tidak akan mencari musuh yang tersembunyi jika kesehatannya rendah.
Lagi pula, ada banyak sekali daftar "seandainya" , Itu " bisa menjadi terlalu rumit, jadi kita perlu memformalkan metode yang memungkinkan kita mempertimbangkan negara bagian dan transisi antar negara bagian. Untuk melakukan ini, kami memperhitungkan semua negara bagian, dan di bawah setiap negara bagian kami menuliskan dalam daftar semua transisi ke negara bagian lain, bersama dengan kondisi yang diperlukan untuk negara bagian tersebut.
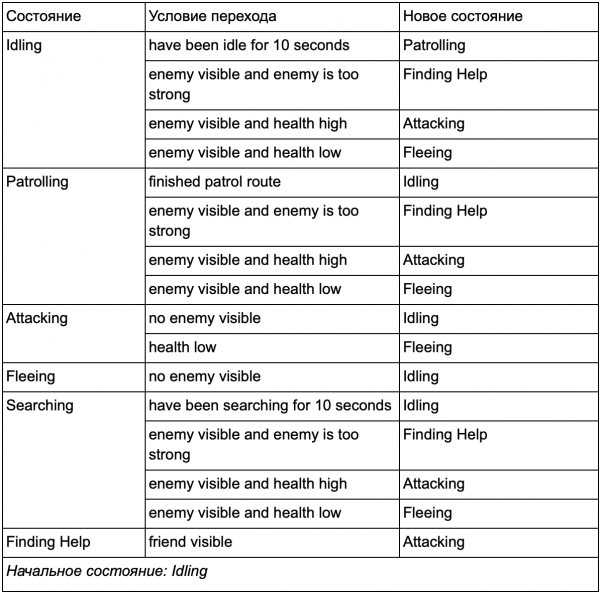
Ini adalah tabel transisi keadaan - cara komprehensif untuk mewakili FSM. Mari menggambar diagram dan mendapatkan gambaran lengkap tentang bagaimana perilaku NPC berubah.
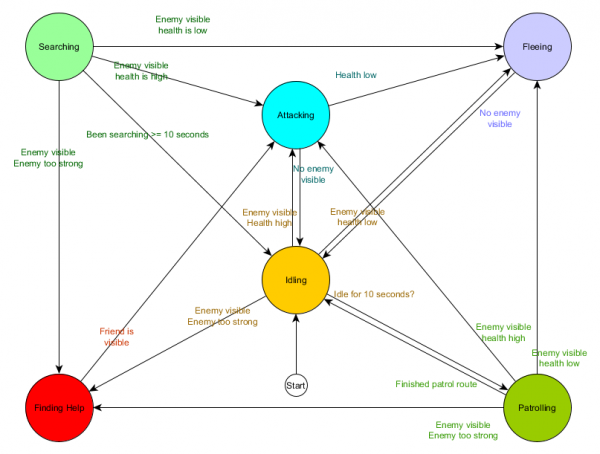
Diagram mencerminkan esensi pengambilan keputusan agen ini berdasarkan situasi saat ini. Selain itu, setiap panah menunjukkan transisi antar keadaan jika kondisi di sebelahnya benar.
Setiap pembaruan, kami memeriksa status agen saat ini, memeriksa daftar transisi, dan jika kondisi untuk transisi terpenuhi, agen menerima status baru. Misalnya, setiap frame memeriksa apakah pengatur waktu 10 detik telah kedaluwarsa, dan jika demikian, penjaga beralih dari status Idling ke Patroli. Dengan cara yang sama, status Menyerang memeriksa kesehatan agen - jika kesehatannya rendah, maka ia masuk ke status Kabur.
Ini menangani transisi antar negara bagian, tapi bagaimana dengan perilaku yang terkait dengan negara bagian itu sendiri? Dalam hal penerapan perilaku aktual untuk keadaan tertentu, biasanya ada dua jenis "hook" tempat kami menetapkan tindakan ke FSM:
- Tindakan yang kami lakukan secara berkala untuk kondisi saat ini.
- Tindakan yang kita ambil saat bertransisi dari satu keadaan ke keadaan lainnya.
Contoh untuk tipe pertama. Negara bagian Patroli akan memindahkan agen di sepanjang rute patroli setiap frame. Status Menyerang akan mencoba untuk memulai serangan setiap frame atau transisi ke keadaan yang memungkinkan hal ini.
Untuk tipe kedua, pertimbangkan transisi “jika musuh terlihat dan musuh terlalu kuat, maka masuk ke status Finding Help. Agen harus memilih ke mana harus mencari bantuan dan menyimpan informasi ini sehingga status Mencari Bantuan mengetahui ke mana harus pergi. Setelah bantuan ditemukan, agen kembali ke status Menyerang. Pada titik ini, dia ingin memberi tahu sekutunya tentang ancaman tersebut, sehingga tindakan NotifyFriendOfThreat dapat terjadi.
Sekali lagi, kita dapat melihat sistem ini melalui lensa siklus Sense/Think/Act. Sense diwujudkan dalam data yang digunakan oleh logika transisi. Pikirkan - transisi tersedia di setiap negara bagian. Dan perbuatan itu dilakukan dengan perbuatan yang dilakukan secara periodik dalam suatu negara atau pada peralihan antar negara.
Terkadang kondisi transisi pemungutan suara secara terus-menerus bisa memakan biaya yang besar. Misalnya, jika setiap agen melakukan penghitungan kompleks setiap frame untuk menentukan apakah agen dapat melihat musuh dan memahami apakah agen dapat bertransisi dari status Patroli ke Menyerang, hal ini akan memakan banyak waktu CPU.
Perubahan-perubahan penting dalam keadaan dunia dapat dianggap sebagai peristiwa-peristiwa yang akan diproses pada saat terjadinya. Daripada FSM memeriksa kondisi transisi "dapatkah agen saya melihat pemain?" setiap frame, sistem terpisah dapat dikonfigurasi untuk memeriksa lebih jarang (misalnya 5 kali per detik). Dan hasilnya adalah mengeluarkan Player Seen ketika pengecekan lolos.
Ini diteruskan ke FSM, yang sekarang harus menuju ke kondisi penerimaan acara Player Seen dan merespons dengan tepat. Perilaku yang dihasilkan sama kecuali adanya penundaan yang hampir tidak terlihat sebelum merespons. Namun kinerjanya telah meningkat karena pemisahan bagian Sense menjadi bagian terpisah dari program.
Mesin negara terbatas hierarkis
Namun, bekerja dengan FSM besar tidak selalu nyaman. Jika kita ingin memperluas status serangan untuk memisahkan MeleeAttacking dan RangedAttacking, kita harus mengubah transisi dari semua status lain yang mengarah ke status Menyerang (saat ini dan masa depan).
Anda mungkin memperhatikan bahwa dalam contoh kita ada banyak transisi duplikat. Sebagian besar transisi dalam keadaan Idling identik dengan transisi dalam keadaan Patroli. Alangkah baiknya jika kita tidak mengulanginya, terutama jika kita menambahkan lebih banyak keadaan serupa. Masuk akal untuk mengelompokkan Idling dan Patroling di bawah label umum "non-tempur", karena hanya ada satu rangkaian transisi umum ke negara-negara yang berperang. Jika kita menganggap label ini sebagai sebuah negara bagian, maka Idling dan Patroling menjadi sub-negara bagian. Contoh penggunaan tabel transisi terpisah untuk subnegara non-tempur yang baru:
Negara bagian utama:
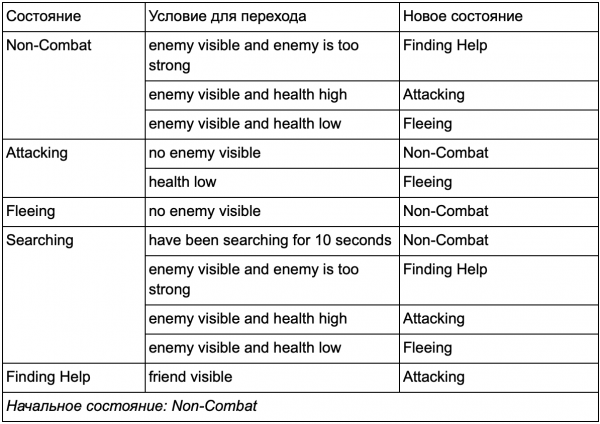
Status di luar pertempuran:

Dan dalam bentuk diagram:
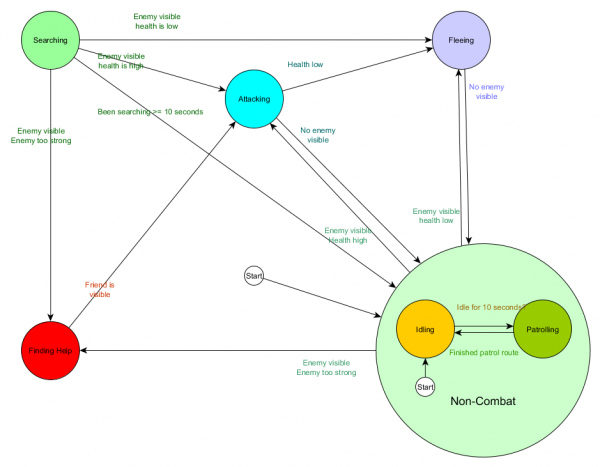
Sistemnya sama, tetapi dengan status non-tempur baru yang mencakup Idling dan Patroli. Dengan setiap negara bagian berisi FSM dengan subnegara bagian (dan subnegara bagian ini, pada gilirannya, berisi FSM mereka sendiri - dan seterusnya selama Anda membutuhkannya), kita mendapatkan Hierarchical Finite State Machine atau HFSM (hierarchical finite state machine). Dengan mengelompokkan keadaan non-tempur, kami menghilangkan banyak transisi yang berlebihan. Kita dapat melakukan hal yang sama untuk negara bagian baru mana pun yang memiliki transisi yang sama. Contohnya, jika di masa depan kita memperluas status Menyerang ke status MeleeAttacking dan MissileAttacking, keduanya akan menjadi substat yang bertransisi satu sama lain berdasarkan jarak ke musuh dan ketersediaan amunisi. Hasilnya, perilaku dan sub-perilaku kompleks dapat direpresentasikan dengan transisi duplikat yang minimal.
Pohon perilaku
Dengan HFSM, kombinasi perilaku yang kompleks dibuat dengan cara yang sederhana. Namun ada sedikit kesulitan bahwa pengambilan keputusan berupa aturan transisi berkaitan erat dengan keadaan saat ini. Dan di banyak permainan, inilah yang dibutuhkan. Dan penggunaan hierarki negara secara hati-hati dapat mengurangi jumlah pengulangan transisi. Namun terkadang Anda memerlukan aturan yang berlaku di negara bagian mana pun Anda berada, atau yang berlaku di hampir semua negara bagian. Misalnya, jika kesehatan agen turun hingga 25%, Anda ingin dia melarikan diri terlepas dari apakah dia sedang bertempur, diam, atau berbicara - Anda harus menambahkan kondisi ini ke setiap negara bagian. Dan jika nanti desainer Anda ingin mengubah ambang kesehatan rendah dari 25% menjadi 10%, maka hal ini harus dilakukan lagi.
Idealnya, situasi ini memerlukan suatu sistem yang pengambilan keputusan mengenai “di negara bagian mana” berada di luar negara bagian itu sendiri, agar perubahan dapat dilakukan hanya di satu tempat saja dan tidak menyentuh kondisi transisi. Pohon perilaku muncul di sini.
Ada beberapa cara untuk mengimplementasikannya, tetapi intinya kira-kira sama untuk semua orang dan mirip dengan pohon keputusan: algoritme dimulai dengan simpul “root”, dan pohon tersebut berisi simpul yang mewakili keputusan atau tindakan. Namun ada beberapa perbedaan utama:
- Node sekarang mengembalikan salah satu dari tiga nilai: Berhasil (jika pekerjaan selesai), Gagal (jika tidak dapat dimulai), atau Berjalan (jika masih berjalan dan tidak ada hasil akhir).
- Tidak ada lagi simpul keputusan untuk memilih di antara dua alternatif. Sebaliknya, mereka adalah node Dekorator, yang memiliki satu node anak. Jika Berhasil, mereka mengeksekusi satu-satunya simpul anak mereka.
- Node yang melakukan tindakan mengembalikan nilai Running untuk mewakili tindakan yang sedang dilakukan.
Kumpulan node kecil ini dapat digabungkan untuk menciptakan sejumlah besar perilaku kompleks. Bayangkan penjaga HFSM dari contoh sebelumnya sebagai pohon perilaku:
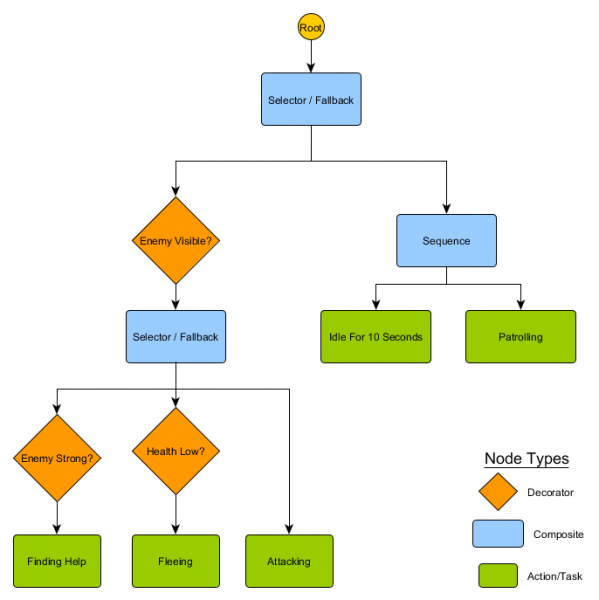
Dengan struktur ini seharusnya tidak ada transisi yang jelas dari keadaan Idling/Patroli ke Menyerang atau keadaan lainnya. Jika musuh terlihat dan kesehatan karakter rendah, eksekusi akan berhenti di node Kabur, terlepas dari node mana yang dieksekusi sebelumnya - Patroli, Idling, Attacking, atau lainnya.
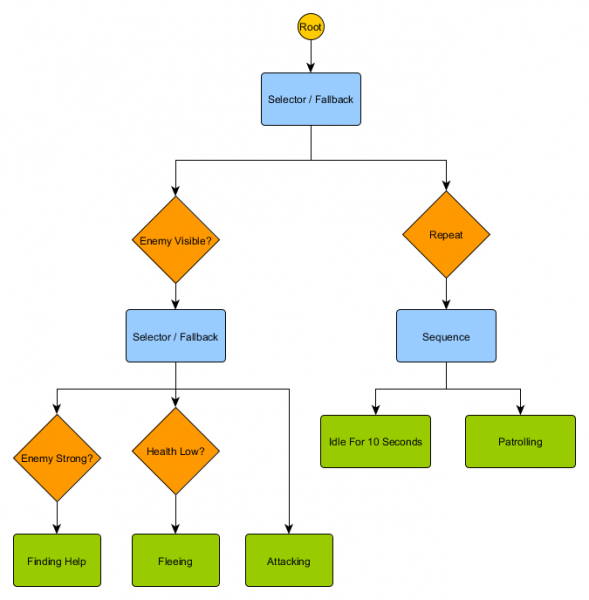
Pohon perilaku itu rumit—ada banyak cara untuk menyusunnya, dan menemukan kombinasi dekorator dan node gabungan yang tepat bisa menjadi suatu tantangan. Ada juga pertanyaan tentang seberapa sering memeriksa pohon - apakah kita ingin memeriksa setiap bagiannya atau hanya ketika salah satu kondisinya berubah? Bagaimana kita menyimpan status yang berkaitan dengan node - bagaimana kita mengetahui kapan kita telah Idle selama 10 detik, atau bagaimana kita mengetahui node mana yang terakhir kali dieksekusi sehingga kita dapat memproses urutannya dengan benar?
Inilah sebabnya mengapa ada banyak implementasi. Misalnya, beberapa sistem telah mengganti node dekorator dengan dekorator inline. Mereka mengevaluasi ulang pohon ketika kondisi dekorator berubah, membantu menggabungkan node, dan memberikan pembaruan berkala.
Sistem berbasis utilitas
Beberapa permainan memiliki banyak mekanisme berbeda. Sangat diharapkan bahwa mereka menerima semua manfaat dari aturan transisi yang sederhana dan umum, namun tidak harus dalam bentuk pohon perilaku yang lengkap. Daripada memiliki serangkaian pilihan yang jelas atau serangkaian tindakan yang mungkin dilakukan, lebih mudah untuk memeriksa semua tindakan dan memilih tindakan yang paling tepat pada saat itu.
Sistem berbasis Utilitas akan membantu dalam hal ini. Ini adalah sistem di mana agen memiliki beragam tindakan dan memilih tindakan mana yang akan dilakukan berdasarkan kegunaan relatif dari masing-masing tindakan. Dimana utilitas adalah ukuran sewenang-wenang mengenai seberapa penting atau diinginkan agen untuk melakukan tindakan ini.
Utilitas yang dihitung dari suatu tindakan berdasarkan keadaan dan lingkungan saat ini, agen dapat memeriksa dan memilih keadaan lain yang paling sesuai kapan saja. Hal ini mirip dengan FSM, kecuali transisi ditentukan oleh perkiraan untuk setiap keadaan potensial, termasuk keadaan saat ini. Harap dicatat bahwa kami memilih tindakan yang paling berguna untuk dilanjutkan (atau tetap jika kami sudah menyelesaikannya). Untuk lebih banyak variasi, ini bisa menjadi pilihan yang seimbang namun acak dari daftar kecil.
Sistem menetapkan rentang nilai utilitas yang berubah-ubah—misalnya, dari 0 (sangat tidak diinginkan) hingga 100 (sangat diinginkan). Setiap tindakan memiliki sejumlah parameter yang mempengaruhi penghitungan nilai ini. Kembali ke contoh wali kami:

Transisi antar tindakan bersifat ambigu—negara mana pun dapat mengikuti negara lain. Prioritas tindakan ditemukan dalam nilai utilitas yang dikembalikan. Jika musuh terlihat, dan musuh tersebut kuat, serta kesehatan karakternya rendah, maka Fleeing dan FindingHelp akan mengembalikan nilai yang tinggi bukan nol. Dalam hal ini, FindingHelp akan selalu lebih tinggi. Demikian pula, aktivitas non-tempur tidak pernah menghasilkan lebih dari 50, sehingga aktivitas tersebut akan selalu lebih rendah daripada aktivitas tempur. Anda perlu mempertimbangkan hal ini saat membuat tindakan dan menghitung kegunaannya.
Dalam contoh kita, tindakan mengembalikan nilai konstanta tetap atau salah satu dari dua nilai tetap. Sistem yang lebih realistis akan menghasilkan perkiraan dari rentang nilai yang berkesinambungan. Misalnya, tindakan Kabur mengembalikan nilai utilitas yang lebih tinggi jika kesehatan agen rendah, dan tindakan Menyerang mengembalikan nilai utilitas yang lebih rendah jika musuh terlalu kuat. Oleh karena itu, tindakan Kabur lebih diutamakan daripada Menyerang dalam situasi apa pun di mana agen merasa tidak memiliki kesehatan yang cukup untuk mengalahkan musuh. Hal ini memungkinkan tindakan untuk diprioritaskan berdasarkan sejumlah kriteria, menjadikan pendekatan ini lebih fleksibel dan bervariasi dibandingkan pohon perilaku atau FSM.
Setiap tindakan memiliki banyak kondisi untuk perhitungan program. Mereka dapat ditulis dalam bahasa skrip atau sebagai rangkaian rumus matematika. The Sims, yang mensimulasikan rutinitas harian karakter, menambahkan lapisan perhitungan tambahan - agen menerima serangkaian "motivasi" yang memengaruhi peringkat utilitas. Jika karakter lapar, mereka akan menjadi semakin lapar seiring berjalannya waktu, dan nilai utilitas dari tindakan EatFood akan meningkat hingga karakter tersebut melakukannya, mengurangi tingkat kelaparan dan mengembalikan nilai EatFood ke nol.
Gagasan memilih tindakan berdasarkan sistem pemeringkatan cukup sederhana, sehingga sistem berbasis Utilitas dapat digunakan sebagai bagian dari proses pengambilan keputusan AI, bukan sebagai penggantinya sepenuhnya. Pohon keputusan mungkin meminta peringkat utilitas dari dua node anak dan memilih yang lebih tinggi. Demikian pula, pohon perilaku dapat memiliki simpul Utilitas gabungan untuk mengevaluasi kegunaan tindakan guna memutuskan anak mana yang akan dieksekusi.
Pergerakan dan navigasi
Pada contoh sebelumnya, kita mempunyai platform yang kita gerakkan ke kiri atau ke kanan, dan seorang penjaga yang berpatroli atau menyerang. Namun bagaimana tepatnya kita menangani pergerakan agen selama periode waktu tertentu? Bagaimana kita mengatur kecepatan, bagaimana kita menghindari rintangan, dan bagaimana kita merencanakan rute ketika mencapai suatu tujuan lebih sulit dari sekedar bergerak lurus? Mari kita lihat ini.
Управление
Pada tahap awal, kita asumsikan bahwa setiap agen memiliki nilai kecepatan, yang meliputi seberapa cepat ia bergerak dan ke arah mana. Hal ini dapat diukur dalam meter per detik, kilometer per jam, piksel per detik, dll. Mengingat loop Sense/Think/Act, kita dapat membayangkan bahwa bagian Think memilih kecepatan, dan bagian Act menerapkan kecepatan tersebut ke agen. Biasanya permainan memiliki sistem fisika yang melakukan tugas ini untuk Anda, mempelajari nilai kecepatan setiap objek dan menyesuaikannya. Oleh karena itu, Anda dapat menyerahkan satu tugas kepada AI - memutuskan kecepatan yang seharusnya dimiliki agen. Jika Anda mengetahui di mana agen seharusnya berada, maka Anda perlu memindahkannya ke arah yang benar dengan kecepatan yang ditentukan. Persamaan yang sangat sepele:
perjalanan_yang diinginkan = posisi_tujuan – posisi_agen
Bayangkan dunia 2D. Agen berada di titik (-2,-2), tujuannya berada di suatu tempat di timur laut di titik (30, 20), dan jalur yang diperlukan agen untuk sampai ke sana adalah (32, 22). Katakanlah posisi ini diukur dalam meter - jika kita menganggap kecepatan agen adalah 5 meter per detik, maka kita akan menskalakan vektor perpindahan dan mendapatkan kecepatan kira-kira (4.12, 2.83). Dengan parameter tersebut, agen akan sampai di tujuan dalam waktu hampir 8 detik.
Anda dapat menghitung ulang nilainya kapan saja. Jika agen berada setengah jalan menuju target, maka panjang pergerakannya akan menjadi setengah, tetapi karena kecepatan maksimum agen adalah 5 m/s (kami memutuskan ini di atas), kecepatannya akan sama. Ini juga berfungsi untuk memindahkan target, memungkinkan agen membuat perubahan kecil saat mereka bergerak.
Namun kami menginginkan lebih banyak variasi - misalnya, meningkatkan kecepatan secara perlahan untuk menyimulasikan karakter bergerak dari berdiri ke berlari. Hal yang sama bisa dilakukan di akhir sebelum berhenti. Fitur-fitur ini dikenal sebagai perilaku kemudi, yang masing-masing memiliki nama khusus: Mencari, Melarikan Diri, Kedatangan, dll. Idenya adalah bahwa gaya percepatan dapat diterapkan pada kecepatan agen, berdasarkan perbandingan posisi agen dan kecepatan saat ini dengan tujuan di untuk menggunakan metode yang berbeda untuk bergerak menuju tujuan.
Setiap perilaku memiliki tujuan yang sedikit berbeda. Seek and Arrival adalah cara untuk memindahkan agen ke suatu tujuan. Penghindaran dan Pemisahan Rintangan menyesuaikan pergerakan agen untuk menghindari rintangan dalam perjalanan menuju tujuan. Penyelarasan dan Kohesi membuat agen terus bergerak bersama. Sejumlah perilaku kemudi yang berbeda dapat dijumlahkan untuk menghasilkan vektor jalur tunggal dengan mempertimbangkan semua faktor. Agen yang menggunakan perilaku Kedatangan, Pemisahan, dan Penghindaran Rintangan untuk menjauhi tembok dan agen lainnya. Pendekatan ini bekerja dengan baik di lokasi terbuka tanpa detail yang tidak perlu.
Dalam kondisi yang lebih sulit, penambahan perilaku yang berbeda akan berdampak lebih buruk - misalnya, agen dapat terjebak di dinding karena konflik antara Kedatangan dan Penghindaran Rintangan. Oleh karena itu, Anda perlu mempertimbangkan opsi yang lebih kompleks daripada sekadar menjumlahkan semua nilai. Caranya begini: alih-alih menjumlahkan hasil dari setiap perilaku, Anda dapat mempertimbangkan pergerakan ke arah yang berbeda dan memilih opsi terbaik.
Namun, dalam lingkungan yang kompleks dengan jalan buntu dan pilihan mana yang harus diambil, kita memerlukan sesuatu yang lebih maju.
Menemukan cara
Perilaku mengemudi sangat baik untuk pergerakan sederhana di area terbuka (lapangan sepak bola atau arena) dimana perjalanan dari A ke B merupakan jalur lurus dengan hanya sedikit jalan memutar di sekitar rintangan. Untuk rute yang kompleks, kita memerlukan pencarian jalur, yaitu cara menjelajahi dunia dan memutuskan rute yang melewatinya.
Cara paling sederhana adalah dengan menerapkan grid ke setiap kotak di sebelah agen dan mengevaluasi kotak mana yang boleh dipindahkan. Jika salah satunya adalah tujuan, ikuti rute dari setiap kotak ke kotak sebelumnya hingga mencapai awal. Ini adalah rutenya. Jika tidak, ulangi proses ini dengan kotak lain di dekatnya hingga Anda menemukan tujuan atau Anda kehabisan kotak (artinya tidak ada rute yang memungkinkan). Inilah yang secara formal dikenal sebagai Breadth-First Search atau BFS (breadth-first search algoritma). Pada setiap langkah dia melihat ke segala arah (karena itu lebarnya, "lebar"). Ruang pencarian ibarat muka gelombang yang bergerak hingga mencapai lokasi yang diinginkan – ruang pencarian meluas pada setiap langkah hingga titik akhir disertakan, setelah itu dapat ditelusuri kembali ke awal.
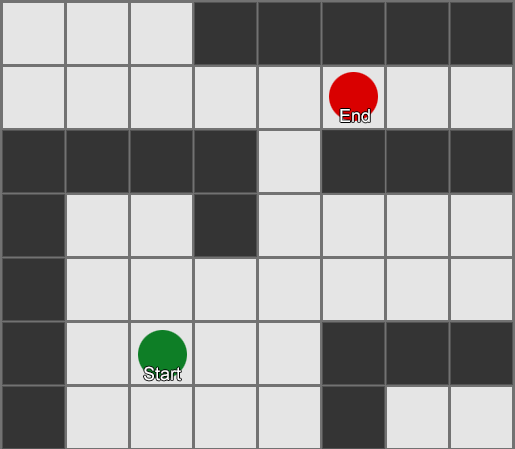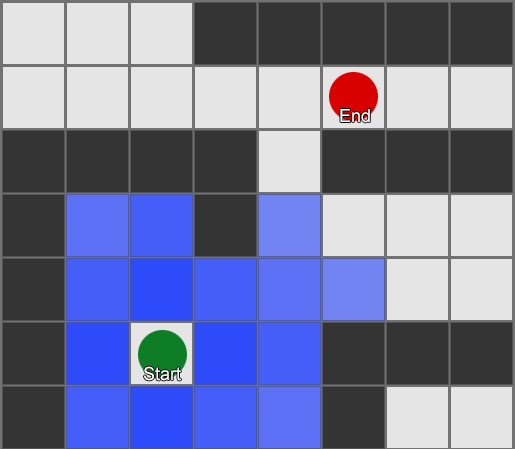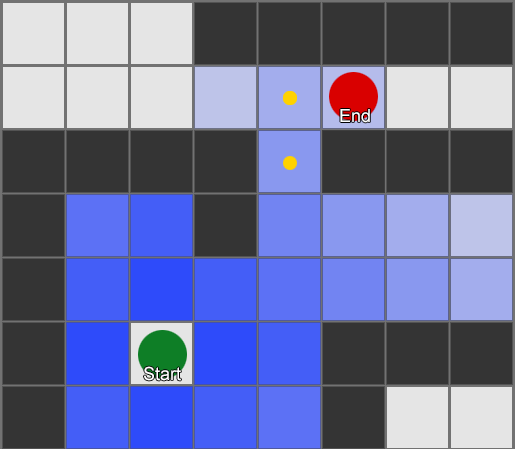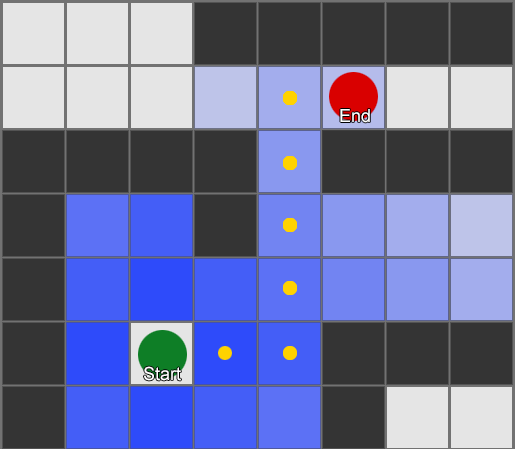
Hasilnya, Anda akan menerima daftar kotak di mana rute yang diinginkan telah disusun. Ini adalah jalannya (karenanya, pencarian jalan) - daftar tempat yang akan dikunjungi agen saat mengikuti tujuan.
Mengingat kita mengetahui posisi setiap kotak di dunia, kita dapat menggunakan perilaku kemudi untuk bergerak di sepanjang jalur - dari node 1 ke node 2, lalu dari node 2 ke node 3, dan seterusnya. Pilihan paling sederhana adalah menuju ke tengah kotak berikutnya, namun pilihan yang lebih baik lagi adalah berhenti di tengah tepi antara kotak saat ini dan kotak berikutnya. Karena itu, agen akan mampu mengambil jalan pintas di tikungan tajam.
Algoritme BFS juga memiliki kelemahan - algoritma ini mengeksplorasi kotak pada arah yang "salah" sebanyak yang ada pada arah yang "benar". Di sinilah algoritma yang lebih kompleks yang disebut A* (A star) berperan. Cara kerjanya sama, namun alih-alih memeriksa kotak tetangga secara membabi buta (kemudian tetangga dari tetangga, lalu tetangga dari tetangga dari tetangga, dan seterusnya), ia mengumpulkan node-node ke dalam sebuah daftar dan mengurutkannya sehingga node berikutnya yang diperiksa selalu merupakan yang pertama. salah satu yang mengarah ke rute terpendek. Node diurutkan berdasarkan heuristik yang mempertimbangkan dua hal— “biaya” dari rute hipotetis ke kotak yang diinginkan (termasuk biaya perjalanan) dan perkiraan seberapa jauh kotak tersebut dari tujuan (membiaskan pencarian ke arah yang benar). ).
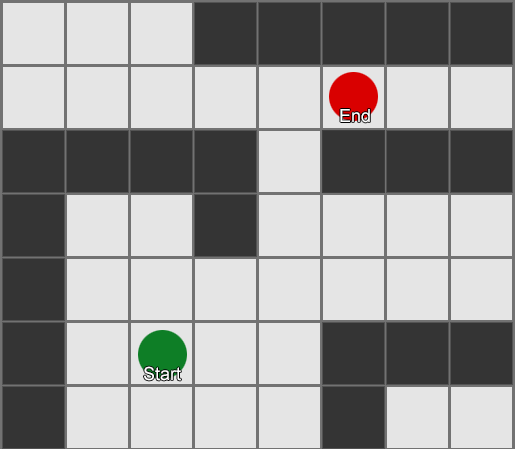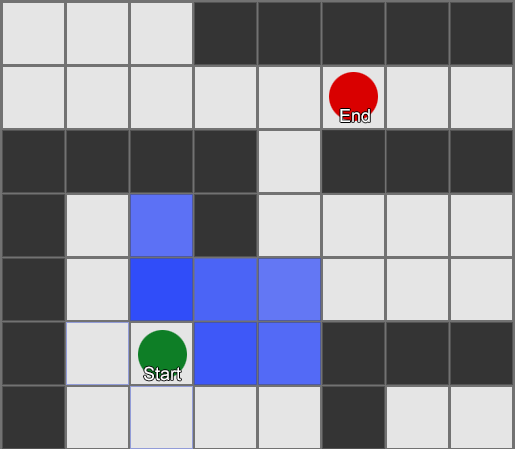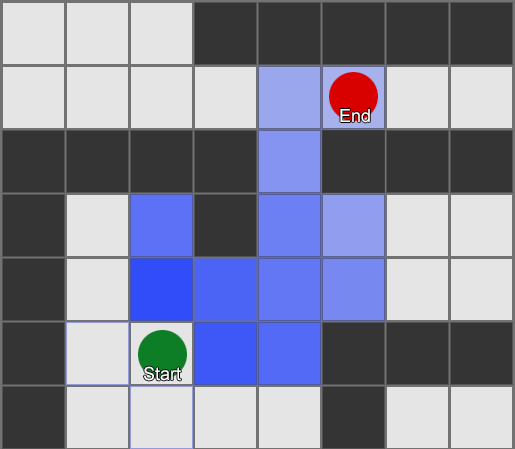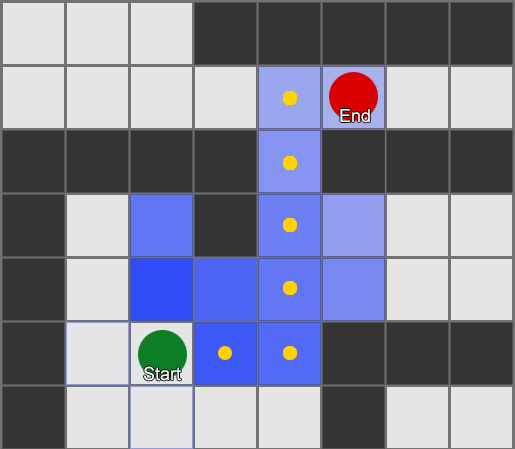
Contoh ini menunjukkan bahwa agen mengeksplorasi satu kotak pada suatu waktu, setiap kali memilih kotak terdekat yang paling menjanjikan. Jalur yang dihasilkan sama dengan BFS, namun lebih sedikit kotak yang dipertimbangkan dalam prosesnya - yang berdampak besar pada performa game.
Gerakan tanpa grid
Namun sebagian besar game tidak disusun dalam bentuk grid, dan sering kali hal tersebut tidak mungkin dilakukan tanpa mengorbankan realisme. Kompromi diperlukan. Berapa ukuran kotaknya? Terlalu besar maka mereka tidak akan dapat mewakili koridor atau belokan kecil dengan benar, terlalu kecil dan akan terdapat terlalu banyak kotak untuk dicari, yang pada akhirnya akan memakan banyak waktu.
Hal pertama yang harus dipahami adalah bahwa mesh memberi kita grafik node yang terhubung. Algoritme A* dan BFS sebenarnya bekerja pada grafik dan tidak peduli sama sekali dengan mesh kita. Kita dapat menempatkan node di manapun dalam dunia game: selama ada koneksi antara dua node yang terhubung, serta antara titik awal dan akhir dan setidaknya salah satu node, algoritma akan bekerja sama baiknya seperti sebelumnya. Hal ini sering disebut sistem waypoint, karena setiap node mewakili posisi penting di dunia yang dapat menjadi bagian dari sejumlah jalur hipotetis.
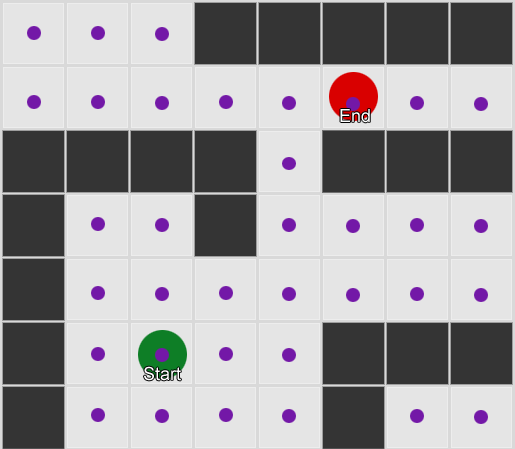
Contoh 1: sebuah simpul di setiap kotak. Pencarian dimulai dari node dimana agen berada dan berakhir pada node kotak yang diinginkan.
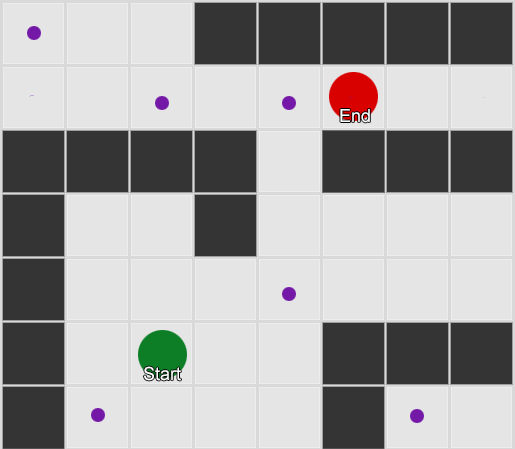
Contoh 2: Kumpulan node yang lebih kecil (titik jalan). Pencarian dimulai di alun-alun agen, melewati jumlah node yang diperlukan, dan kemudian berlanjut ke tujuan.
Ini adalah sistem yang sepenuhnya fleksibel dan kuat. Namun kehati-hatian diperlukan dalam memutuskan di mana dan bagaimana menempatkan titik jalan, jika tidak, agen mungkin tidak melihat titik terdekat dan tidak dapat memulai jalurnya. Akan lebih mudah jika kita dapat secara otomatis menempatkan titik arah berdasarkan geometri dunia.
Di sinilah muncul jaring navigasi atau navmesh (navigation mesh). Ini biasanya berupa jaring segitiga 2D yang dilapiskan pada geometri dunia - ke mana pun agen diizinkan berjalan. Masing-masing segitiga dalam jaring menjadi simpul pada grafik, dan memiliki hingga tiga segitiga berdekatan yang menjadi simpul berdekatan pada grafik.
Gambar ini adalah contoh dari mesin Unity - yang menganalisis geometri di dunia dan membuat navmesh (di tangkapan layar berwarna biru muda). Setiap poligon dalam navmesh merupakan area dimana agen dapat berdiri atau berpindah dari satu poligon ke poligon lainnya. Dalam contoh ini, poligon lebih kecil dari lantai tempatnya berada - hal ini dilakukan untuk memperhitungkan ukuran agen, yang akan melampaui posisi nominalnya.

Kita dapat mencari rute melalui mesh ini, sekali lagi menggunakan algoritma A*. Ini akan memberi kita rute yang hampir sempurna di dunia, yang memperhitungkan semua geometri dan tidak memerlukan node yang tidak perlu dan pembuatan titik jalan.
Pencarian jalan adalah topik yang terlalu luas sehingga satu bagian artikel saja tidak cukup. Jika Anda ingin mempelajarinya lebih detail, ini akan membantu .
Планирование
Kita telah belajar dengan merintis jalan bahwa terkadang tidak cukup hanya memilih arah dan bergerak - kita harus memilih rute dan berbelok beberapa kali untuk mencapai tujuan yang kita inginkan. Kita dapat menggeneralisasi gagasan ini: mencapai suatu tujuan bukan hanya langkah berikutnya, tetapi keseluruhan rangkaian di mana terkadang Anda perlu melihat beberapa langkah ke depan untuk mengetahui langkah pertama yang harus dilakukan. Ini disebut perencanaan. Pencarian jalan dapat dianggap sebagai salah satu dari beberapa perluasan perencanaan. Dalam siklus Sense/Think/Act, di sinilah bagian Think merencanakan beberapa bagian Act untuk masa depan.
Mari kita lihat contoh permainan papan Magic: The Gathering. Kami pergi dulu dengan set kartu berikut di tangan kami:
- Rawa - Memberikan 1 mana hitam (kartu tanah).
- Hutan - memberikan 1 mana hijau (kartu tanah).
- Fugitive Wizard - Membutuhkan 1 mana biru untuk dipanggil.
- Elvish Mystic - Membutuhkan 1 mana hijau untuk dipanggil.
Tiga kartu sisanya kita abaikan agar lebih mudah. Menurut aturan, pemain diperbolehkan memainkan 1 kartu tanah per giliran, dia dapat “mengetuk” kartu ini untuk mengambil mana darinya, dan kemudian menggunakan mantra (termasuk memanggil makhluk) sesuai dengan jumlah mana. Dalam situasi ini, pemain manusia mengetahui cara memainkan Forest, mengetuk 1 mana hijau, lalu memanggil Elvish Mystic. Tapi bagaimana AI game bisa mengetahui hal ini?
Perencanaan yang mudah
Pendekatan sepelenya adalah mencoba setiap tindakan secara bergantian hingga tidak ada lagi tindakan yang cocok. Dengan melihat kartunya, AI melihat apa yang bisa dimainkan oleh Swamp. Dan dia memainkannya. Apakah masih ada tindakan lain yang tersisa pada giliran ini? Ia tidak dapat memanggil Elvish Mystic atau Fugitive Wizard, karena masing-masing membutuhkan mana hijau dan biru untuk memanggil mereka, sedangkan Swamp hanya menyediakan mana hitam. Dan dia tidak bisa lagi bermain Forest, karena dia sudah bermain Swamp. Oleh karena itu, AI game mengikuti aturan, tetapi melakukannya dengan buruk. Dapat ditingkatkan.
Perencanaan dapat menemukan daftar tindakan yang membawa permainan ke keadaan yang diinginkan. Sama seperti setiap kotak pada sebuah jalan memiliki tetangganya (dalam pencarian jalan), setiap tindakan dalam sebuah rencana juga memiliki tetangga atau penerusnya. Kita dapat mencari tindakan tersebut dan tindakan selanjutnya hingga mencapai keadaan yang diinginkan.
Dalam contoh kita, hasil yang diinginkan adalah “memanggil makhluk jika memungkinkan”. Di awal giliran, kita hanya melihat dua kemungkinan tindakan yang diperbolehkan oleh aturan permainan:
1. Mainkan Swamp (hasil: Swamp di dalam game)
2. Mainkan Hutan (hasil: Hutan dalam game)
Setiap tindakan yang dilakukan dapat mengarah pada tindakan selanjutnya dan menutup tindakan lainnya, sekali lagi tergantung pada aturan mainnya. Bayangkan kita memainkan Swamp - ini akan menghapus Swamp sebagai langkah selanjutnya (kita sudah memainkannya), dan ini juga akan menghapus Forest (karena menurut aturan Anda dapat memainkan satu kartu tanah per giliran). Setelah ini, AI menambahkan mendapatkan 1 mana hitam sebagai langkah selanjutnya karena tidak ada pilihan lain. Jika dia melanjutkan dan memilih Tap the Swamp, dia akan menerima 1 unit mana hitam dan tidak akan bisa melakukan apa pun dengannya.
1. Mainkan Swamp (hasil: Swamp di dalam game)
1.1 Rawa “Ketuk” (hasil: Rawa “ketuk”, +1 unit mana hitam)
Tidak ada tindakan yang tersedia - AKHIR
2. Mainkan Hutan (hasil: Hutan dalam game)
Daftar tindakannya pendek, kami menemui jalan buntu. Kami ulangi proses untuk langkah selanjutnya. Kami memainkan Forest, buka aksi "dapatkan 1 mana hijau", yang pada gilirannya akan membuka aksi ketiga - panggil Elvish Mystic.
1. Mainkan Swamp (hasil: Swamp di dalam game)
1.1 Rawa “Ketuk” (hasil: Rawa “ketuk”, +1 unit mana hitam)
Tidak ada tindakan yang tersedia - AKHIR
2. Mainkan Hutan (hasil: Hutan dalam game)
2.1 “Ketuk” Hutan (hasil: Hutan “disadap”, +1 unit mana hijau)
2.1.1 Panggil Elvish Mystic (hasil: Elvish Mystic sedang dimainkan, -1 mana hijau)
Tidak ada tindakan yang tersedia - AKHIR
Akhirnya, kami menjelajahi semua tindakan yang mungkin dilakukan dan menemukan rencana untuk memanggil makhluk.
Ini adalah contoh yang sangat sederhana. Dianjurkan untuk memilih rencana terbaik, daripada rencana apa pun yang memenuhi beberapa kriteria. Secara umum dimungkinkan untuk mengevaluasi rencana potensial berdasarkan hasil atau manfaat keseluruhan dari penerapannya. Anda dapat mencetak sendiri 1 poin untuk memainkan kartu tanah dan 3 poin untuk memanggil makhluk. Memainkan Rawa akan menjadi rencana 1 poin. Dan memainkan Hutan → Ketuk Hutan → panggil Elvish Mystic akan langsung memberikan 4 poin.
Beginilah cara perencanaan bekerja di Magic: The Gathering, tetapi logika yang sama berlaku di situasi lain. Misalnya menggerakkan pion untuk memberikan ruang bagi uskup untuk bergerak dalam catur. Atau berlindung di balik tembok untuk memotret dengan aman di XCOM seperti ini. Secara umum, Anda mengerti maksudnya.
Perencanaan yang lebih baik
Terkadang ada terlalu banyak tindakan potensial untuk mempertimbangkan setiap pilihan yang ada. Kembali ke contoh dengan Magic: The Gathering: katakanlah dalam permainan dan di tangan Anda ada beberapa kartu tanah dan makhluk - jumlah kemungkinan kombinasi gerakan bisa mencapai puluhan. Ada beberapa solusi untuk masalah ini.
Metode pertama adalah backward chaining. Daripada mencoba semua kombinasi, lebih baik memulai dengan hasil akhir dan mencoba mencari jalur langsung. Daripada berpindah dari akar pohon ke daun tertentu, kita bergerak ke arah yang berlawanan - dari daun ke akar. Cara ini lebih mudah dan cepat.
Jika musuh memiliki 1 kesehatan, Anda dapat menemukan rencana "menimbulkan 1 atau lebih kerusakan". Untuk mencapai hal ini, sejumlah syarat harus dipenuhi:
1. Kerusakan bisa disebabkan oleh mantra - harus ada di tangan.
2. Untuk merapal mantra, Anda memerlukan mana.
3. Untuk mendapatkan mana, Anda perlu memainkan kartu tanah.
4. Untuk memainkan kartu tanah, Anda harus memilikinya di tangan Anda.
Cara lainnya adalah pencarian terbaik-pertama. Daripada mencoba semua jalan, kita memilih salah satu yang paling cocok. Seringkali, metode ini memberikan rencana optimal tanpa biaya pencarian yang tidak perlu. A* adalah salah satu bentuk pencarian terbaik pertama - dengan memeriksa rute yang paling menjanjikan dari awal, ia sudah dapat menemukan jalur terbaik tanpa harus memeriksa opsi lain.
Opsi pencarian terbaik pertama yang menarik dan semakin populer adalah Monte Carlo Tree Search. Alih-alih menebak rencana mana yang lebih baik daripada yang lain ketika memilih setiap tindakan berikutnya, algoritme memilih penerus acak di setiap langkah hingga mencapai akhir (ketika rencana tersebut menghasilkan kemenangan atau kekalahan). Hasil akhirnya kemudian digunakan untuk menambah atau mengurangi bobot pilihan sebelumnya. Dengan mengulangi proses ini beberapa kali berturut-turut, algoritme memberikan perkiraan yang baik tentang langkah terbaik selanjutnya, meskipun situasinya berubah (jika musuh mengambil tindakan untuk mengganggu pemain).
Cerita tentang perencanaan dalam game tidak akan lengkap tanpa Perencanaan Aksi Berorientasi Tujuan atau GOAP (perencanaan tindakan berorientasi tujuan). Ini adalah metode yang banyak digunakan dan didiskusikan, namun selain beberapa detail yang membedakan, ini pada dasarnya adalah metode rantai mundur yang telah kita bicarakan sebelumnya. Jika tujuannya adalah untuk "menghancurkan pemain" dan pemain tersebut berada di balik perlindungan, rencananya dapat berupa: hancurkan dengan granat → ambil → lempar.
Biasanya ada beberapa tujuan, masing-masing dengan prioritasnya sendiri. Jika tujuan dengan prioritas tertinggi tidak dapat diselesaikan (tidak ada kombinasi tindakan yang menciptakan rencana "bunuh pemain" karena pemain tidak terlihat), AI akan kembali ke tujuan dengan prioritas lebih rendah.
Pelatihan dan adaptasi
Kami sudah mengatakan bahwa game AI biasanya tidak menggunakan pembelajaran mesin karena tidak cocok untuk mengelola agen secara real time. Namun bukan berarti Anda tidak bisa meminjam sesuatu dari daerah ini. Kami ingin lawan dalam penembak yang bisa kami pelajari. Misalnya, mencari tahu posisi terbaik di peta. Atau lawan dalam game pertarungan yang akan memblokir gerakan kombo yang sering digunakan pemain, memotivasi dia untuk menggunakan gerakan kombo lainnya. Jadi pembelajaran mesin bisa sangat berguna dalam situasi seperti itu.
Statistik dan Probabilitas
Sebelum kita membahas contoh yang rumit, mari kita lihat sejauh mana kita bisa melangkah dengan melakukan beberapa pengukuran sederhana dan menggunakannya untuk mengambil keputusan. Misalnya, strategi real-time - bagaimana kita menentukan apakah seorang pemain dapat melancarkan serangan di beberapa menit pertama permainan dan pertahanan apa yang harus dipersiapkan untuk menghadapinya? Kita dapat mempelajari pengalaman masa lalu seorang pemain untuk memahami reaksi apa yang mungkin terjadi di masa depan. Pertama-tama, kami tidak memiliki data mentah seperti itu, tetapi kami dapat mengumpulkannya - setiap kali AI bermain melawan manusia, AI dapat mencatat waktu serangan pertama. Setelah beberapa sesi, kami akan mendapatkan rata-rata waktu yang dibutuhkan pemain untuk menyerang di masa depan.
Ada juga masalah dengan nilai rata-rata: jika seorang pemain terburu-buru 20 kali dan bermain lambat 20 kali, maka nilai yang diperlukan akan berada di tengah-tengah, dan ini tidak akan memberi kita sesuatu yang berguna. Salah satu solusinya adalah dengan membatasi data masukan - 20 buah terakhir dapat diperhitungkan.
Pendekatan serupa digunakan ketika memperkirakan kemungkinan tindakan tertentu dengan mengasumsikan bahwa preferensi pemain di masa lalu akan sama di masa depan. Jika seorang pemain menyerang kita lima kali dengan bola api, dua kali dengan kilat, dan satu kali dengan jarak dekat, jelas dia lebih menyukai bola api. Mari kita ekstrapolasi dan lihat kemungkinan penggunaan senjata yang berbeda: bola api=62,5%, petir=25%, dan jarak dekat=12,5%. AI game kami perlu bersiap untuk melindungi dirinya dari api.
Metode menarik lainnya adalah dengan menggunakan Naive Bayes Classifier untuk mempelajari sejumlah besar data masukan dan mengklasifikasikan situasi sehingga AI bereaksi sesuai keinginan. Pengklasifikasi Bayesian terkenal karena penggunaannya dalam filter spam email. Di sana mereka memeriksa kata-kata tersebut, membandingkannya dengan tempat kata-kata tersebut pernah muncul sebelumnya (dalam spam atau tidak), dan menarik kesimpulan tentang email yang masuk. Kita dapat melakukan hal yang sama meskipun dengan masukan yang lebih sedikit. Berdasarkan semua informasi berguna yang dilihat AI (seperti unit musuh apa yang diciptakan, atau mantra apa yang mereka gunakan, atau teknologi apa yang mereka teliti), dan hasil akhirnya (perang atau damai, terburu-buru atau bertahan, dll.) - kami akan memilih perilaku AI yang diinginkan.
Semua metode pelatihan ini sudah cukup, namun disarankan untuk menggunakannya berdasarkan data pengujian. AI akan belajar beradaptasi dengan berbagai strategi yang digunakan penguji permainan Anda. AI yang beradaptasi dengan pemain setelah rilis mungkin menjadi terlalu mudah diprediksi atau terlalu sulit untuk dikalahkan.
Adaptasi berbasis nilai
Mengingat konten dunia game kami dan aturannya, kami dapat mengubah serangkaian nilai yang memengaruhi pengambilan keputusan, bukan hanya menggunakan data masukan. Kami melakukan ini:
- Biarkan AI mengumpulkan data tentang keadaan dunia dan peristiwa penting selama permainan (seperti di atas).
- Mari kita ubah beberapa nilai penting berdasarkan data ini.
- Kami menerapkan keputusan kami berdasarkan pemrosesan atau evaluasi nilai-nilai ini.
Misalnya, seorang agen memiliki beberapa ruangan untuk dipilih di peta penembak orang pertama. Setiap ruangan memiliki nilai tersendiri, yang menentukan seberapa menarik untuk dikunjungi. AI secara acak memilih ruangan mana yang akan dituju berdasarkan nilainya. Agen kemudian mengingat di ruangan mana dia dibunuh dan mengurangi nilainya (kemungkinan dia akan kembali ke sana). Demikian pula dengan situasi sebaliknya - jika agen menghancurkan banyak lawan, maka nilai ruangan meningkat.
Model Markov
Bagaimana jika kita menggunakan data yang dikumpulkan untuk membuat prediksi? Jika kita mengingat setiap ruangan tempat kita melihat pemain dalam jangka waktu tertentu, kita akan memprediksi ruangan mana yang mungkin dituju oleh pemain tersebut. Dengan melacak dan mencatat pergerakan pemain melintasi ruangan (nilai), kami dapat memprediksinya.
Mari kita ambil tiga ruangan: merah, hijau dan biru. Dan juga observasi yang kami rekam saat menyaksikan sesi permainan:
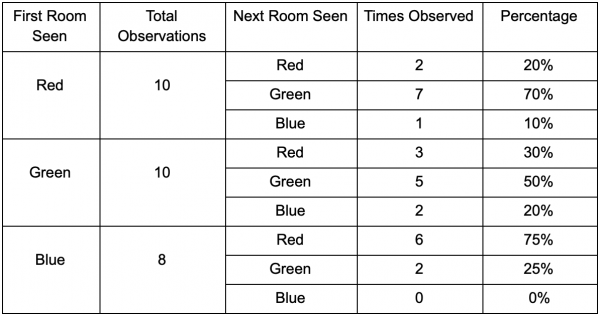
Jumlah observasi di setiap ruangan hampir sama - kami masih belum tahu di mana harus membuat tempat yang bagus untuk penyergapan. Mengumpulkan statistik juga dipersulit dengan munculnya kembali pemain, yang muncul secara merata di seluruh peta. Tapi data tentang ruangan selanjutnya yang mereka masuki setelah muncul di peta sudah berguna.
Dapat dilihat bahwa ruang hijau cocok untuk para pemain - kebanyakan orang berpindah dari ruang merah ke ruang hijau, 50% di antaranya tetap tinggal di sana. Sebaliknya, ruangan biru tidak populer; hampir tidak ada orang yang mengunjunginya, dan jika mereka melakukannya, mereka tidak akan bertahan lama.
Namun data tersebut memberi tahu kita sesuatu yang lebih penting - ketika seorang pemain berada di ruangan biru, ruangan berikutnya yang kita lihat akan berwarna merah, bukan hijau. Meskipun ruangan hijau lebih populer dibandingkan ruangan merah, namun keadaan berubah jika pemain berada di ruangan biru. Keadaan selanjutnya (yaitu ruangan yang akan dituju pemain) bergantung pada keadaan sebelumnya (yaitu ruangan tempat pemain berada saat ini). Karena kita mengeksplorasi ketergantungan, kita akan membuat prediksi yang lebih akurat dibandingkan jika kita hanya menghitung observasi secara independen.
Memprediksi keadaan masa depan berdasarkan data dari keadaan masa lalu disebut model Markov, dan contoh seperti itu (dengan ruangan) disebut rantai Markov. Karena pola tersebut mewakili kemungkinan perubahan antar keadaan yang berurutan, pola tersebut ditampilkan secara visual sebagai FSM dengan probabilitas di setiap transisi. Sebelumnya, kami menggunakan FSM untuk merepresentasikan status perilaku yang dimiliki agen, namun konsep ini berlaku untuk status mana pun, baik terkait dengan agen atau tidak. Dalam hal ini, negara bagian mewakili ruangan yang ditempati agen:
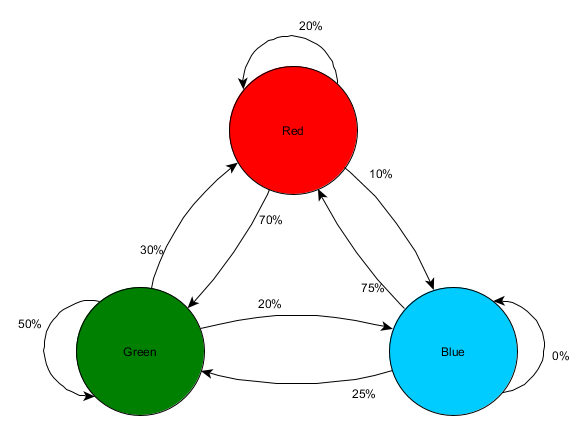
Ini adalah cara sederhana untuk mewakili kemungkinan relatif perubahan keadaan, memberikan AI kemampuan untuk memprediksi keadaan selanjutnya. Anda bisa mengantisipasinya dengan beberapa langkah ke depan.
Jika seorang pemain berada di ruang hijau, ada kemungkinan 50% dia akan tetap berada di sana pada saat dia diamati lagi. Tapi seberapa besar kemungkinan dia akan tetap berada di sana bahkan setelahnya? Tidak hanya ada kemungkinan pemain tetap berada di ruang hijau setelah dua kali observasi, tetapi ada juga kemungkinan dia keluar dan kembali. Berikut adalah tabel baru dengan mempertimbangkan data baru:
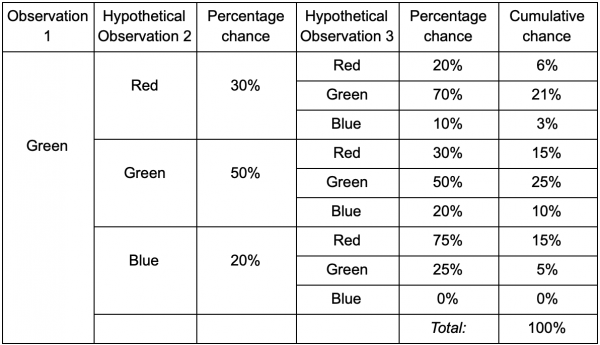
Hal ini menunjukkan bahwa peluang melihat pemain di ruang hijau setelah dua kali pengamatan adalah sama dengan 51% - 21% bahwa dia akan berasal dari ruang merah, 5% di antaranya pemain akan mengunjungi ruang biru di antara mereka, dan 25% pemain tidak akan meninggalkan ruang hijau.
Tabel hanyalah alat visual - prosedurnya hanya perlu mengalikan probabilitas pada setiap langkah. Ini berarti Anda dapat melihat jauh ke masa depan dengan satu peringatan: kami berasumsi bahwa peluang memasuki suatu ruangan bergantung sepenuhnya pada ruangan saat ini. Ini disebut Properti Markov - keadaan masa depan hanya bergantung pada masa kini. Namun hal ini tidak seratus persen akurat. Pemain dapat mengubah keputusan tergantung pada faktor lain: tingkat kesehatan atau jumlah amunisi. Karena kami tidak mencatat nilai-nilai ini, perkiraan kami akan menjadi kurang akurat.
N-Gram
Bagaimana dengan contoh game pertarungan dan memprediksi gerakan kombo pemain? Sama! Namun alih-alih hanya satu keadaan atau peristiwa, kita akan memeriksa seluruh rangkaian yang membentuk serangan kombo.
Salah satu cara untuk melakukan ini adalah dengan menyimpan setiap input (seperti Kick, Punch, atau Block) dalam buffer dan menulis seluruh buffer sebagai sebuah event. Jadi pemain berulang kali menekan Kick, Kick, Punch untuk menggunakan serangan SuperDeathFist, sistem AI menyimpan semua input dalam buffer dan mengingat tiga input terakhir yang digunakan dalam setiap langkah.
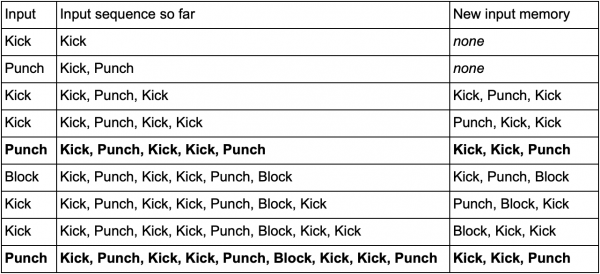
(Garis yang dicetak tebal adalah saat pemain meluncurkan serangan SuperDeathFist.)
AI akan melihat semua opsi ketika pemain memilih Tendangan, diikuti dengan Tendangan lainnya, dan kemudian menyadari bahwa masukan berikutnya selalu Pukulan. Ini akan memungkinkan agen untuk memprediksi gerakan kombo SuperDeathFist dan memblokirnya jika memungkinkan.
Urutan kejadian ini disebut N-gram, dimana N adalah jumlah elemen yang disimpan. Pada contoh sebelumnya adalah 3 gram (trigram), artinya: dua entri pertama digunakan untuk memprediksi entri ketiga. Oleh karena itu, dalam 5 gram, empat entri pertama memprediksi entri kelima dan seterusnya.
Perancang perlu memilih ukuran N-gram dengan hati-hati. N yang lebih kecil memerlukan lebih sedikit memori tetapi juga menyimpan lebih sedikit riwayat. Misal 2 gram (bigram) akan merekam Kick, Kick atau Kick, Punch, namun tidak bisa menyimpan Kick, Kick, Punch, sehingga AI tidak akan merespon kombo SuperDeathFist.
Di sisi lain, angka yang lebih besar memerlukan lebih banyak memori dan AI akan lebih sulit untuk dilatih karena akan ada lebih banyak pilihan yang memungkinkan. Jika Anda memiliki tiga kemungkinan masukan Tendangan, Pukulan, atau Blokir, dan kami menggunakan 10 gram, itu berarti sekitar 60 ribu opsi berbeda.
Model bigram adalah rantai Markov sederhana - setiap pasangan keadaan masa lalu/keadaan saat ini adalah bigram, dan Anda dapat memprediksi keadaan kedua berdasarkan keadaan pertama. N-gram berukuran 3 gram dan lebih besar juga dapat dianggap sebagai rantai Markov, di mana semua elemen (kecuali yang terakhir dalam N-gram) bersama-sama membentuk keadaan pertama dan elemen terakhir membentuk keadaan kedua. Contoh game pertarungan menunjukkan peluang transisi dari status Tendangan dan Tendangan ke status Tendangan dan Pukulan. Dengan memperlakukan beberapa entri riwayat masukan sebagai satu unit, pada dasarnya kami mengubah urutan masukan menjadi bagian dari keseluruhan keadaan. Ini memberi kita properti Markov, yang memungkinkan kita menggunakan rantai Markov untuk memprediksi masukan berikutnya dan menebak gerakan kombo apa yang akan terjadi selanjutnya.
Kesimpulan
Kami berbicara tentang alat dan pendekatan paling umum dalam pengembangan kecerdasan buatan. Kami juga melihat situasi di mana mereka perlu digunakan dan di mana mereka sangat berguna.
Ini seharusnya cukup untuk memahami dasar-dasar AI game. Namun, tentu saja, ini belum semuanya metode. Kurang populer, namun tidak kalah efektifnya antara lain:
- algoritma optimasi termasuk pendakian bukit, penurunan gradien dan algoritma genetika
- algoritma pencarian/penjadwalan permusuhan (pemangkasan minimax dan alfa-beta)
- metode klasifikasi (perceptron, jaringan saraf, dan mesin vektor pendukung)
- sistem untuk memproses persepsi dan memori agen
- pendekatan arsitektural terhadap AI (sistem hybrid, arsitektur subset, dan cara lain untuk melapisi sistem AI)
- alat animasi (perencanaan dan koordinasi gerak)
- faktor kinerja (tingkat detail, kapan saja, dan algoritma pengiris waktu)
Sumber daya internet tentang topik:
1. GameDev.net punya Dan .
2. berisi banyak presentasi dan artikel tentang berbagai topik terkait pengembangan AI game.
3. mencakup topik-topik dari GDC AI Summit, yang sebagian besar tersedia secara gratis.
4. Materi bermanfaat juga dapat ditemukan di website .
5. Tommy Thompson, peneliti AI dan pengembang game, membuat video di YouTube dengan penjelasan dan kajian AI pada game komersial.
Buku dengan topik:
1. Seri buku Game AI Pro merupakan kumpulan artikel pendek yang menjelaskan cara mengimplementasikan fitur tertentu atau cara menyelesaikan masalah tertentu.
2. Seri Kebijaksanaan Pemrograman Game AI adalah pendahulu dari seri Game AI Pro. Ini berisi metode-metode lama, tetapi hampir semuanya masih relevan hingga saat ini.
3. adalah salah satu teks dasar untuk semua orang yang ingin memahami bidang umum kecerdasan buatan. Ini bukan buku tentang pengembangan game - ini mengajarkan dasar-dasar AI.
Sumber: www.habr.com
