

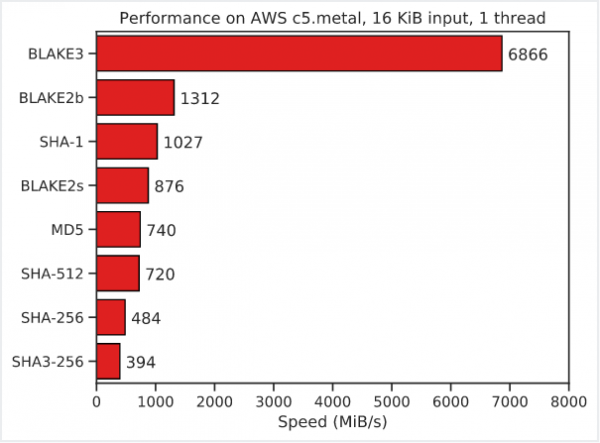
Состоялся релиз эталонной реализации криптографической хеш-функции BLAKE3 1.0, примечательной очень высокой производительностью вычисления хеша при обеспечении надёжности на уровне SHA-3. В тесте на генерацию хеша для файла, размером 16 КБ, BLAKE3 с 256-битным ключом опережает SHA3-256 в 17 раз, SHA-256 — в 14 раз, SHA-512 — в 9 раз, SHA-1 — в 6 раз, а BLAKE2b — в 5 раз. Значительный отрыв сохраняется и при обработке очень больших объёмов данных, например, BLAKE3 оказался быстрее SHA-256 в 8 раз при вычислении хеша для 1ГБ случайных данных. Код эталонной реализация BLAKE3 поставляется в вариантах на языках Си и Rust под двойной лицензией — общественное достояние (CC0) и Apache 2.0.
Хэш-функция рассчитана на такое применение, как проверка целостности файлов, аутентификация сообщений и формирование данных для криптографических цифровых подписей. BLAKE3 не предназначена для хеширования паролей, так как нацелена на максимально быстрое вычисление хешей (для паролей рекомендуется использовать медленные хеш-функции yescrypt, bcrypt, scrypt или Argon2). Рассматриваемая хеш-функция нечувствительна к размеру хешируемых данных и защищена от атак по подбору коллизий и нахождению прообраза.
Алгоритм разработан известными специалистами по криптографии (Jack O’Connor, Jean-Philippe Aumasson, Samuel Neves, Zooko Wilcox-O’Hearn) и продолжает развитие алгоритма BLAKE2 и применяет для кодирования дерева цепочек блоков механизм Bao. В отличие от BLAKE2 (BLAKE2b, BLAKE2s), в BLAKE3 для всех платформ предложен единый алгоритм, не привязанный к разрядности и размеру хеша.
Повышения производительности удалось добиться благодаря сокращению числа раундов с 10 до 7 и раздельному хешированию блоков кусочками по 1 Кб. По заявлению создателей, они нашли убедительное математическое доказательство, что можно обойтись 7 раундами вместо 10 при сохранении того же уровня надёжности (для наглядности можно привести пример с перемешиванием фруктов в миксере — через 7 секунд фрукты уже полностью перемешаны, и дополнительные 3 секунды не скажутся на консистенции смеси). При этом некоторые исследователи выражают сомнение, полагая, что даже если в настоящее время 7 раундов достаточно для противостояния всем известным атакам на хеши, то дополнительные 3 раунда могут оказаться полезны в случае выявления новых атак в будущем.
Что касается разделения на блоки, то в BLAKE3 поток разбивается на кусочки по 1 Кб и каждый кусочек хешируется независимо. На основе хешей кусочков на базе бинарного дерева Меркла формируется один большой хеш. Указанное разделение позволяет решить проблему с распараллеливанием обработки данных при вычислении хеша — например, можно использовать 4-поточные SIMD-инструкции для одновременного вычисления хешей 4 блоков. Традиционные хеш-функции SHA-* обрабатывают данные последовательно.
Особенности BLAKE3:
- Высокая производительность, BLAKE3 значительно быстрее MD5, SHA-1, SHA-2, SHA-3 и BLAKE2.
- Безопасность, в том числе стойкость к атаке удлинением сообщения, которой подвержен SHA-2;
- Доступны варианты на языке Rust, оптимизированные для использования инструкций SSE2, SSE4.1, AVX2, AVX-512 и NEON.
- Обеспечение распараллеливания вычислений на любое число потоков и SIMD-каналов.
- Возможность инкрементального обновления и верифицированной обработки потоков;
- Применение в режимах PRF, MAC, KDF, XOF и как обычный хеш;
- Единый алгоритм для всех архитектур, быстрый как на системах x86-64, так и на 32-разрядных процессорах ARM.
Основные отличия BLAKE3 от BLAKE2:
- Использование бинарной древовидной структуры, позволяющей добиться неограниченного параллелизма при вычислении хеша.
- Сокращение числа раундов с 10 до 7.
- Три режима работы: хеширование, хеширование с ключом (HMAC) и формирование ключа (KDF).
- Отсутствие дополнительных накладных расходов при хешировании с ключом за счёт использования области, ранее занимаемой блоком параметров ключа.
- Встроенный механизм работы в форме функции с удлиняемым результатом (XOF, Extendable Output Function), допускающей распараллеливание и позиционирование (seek).
Fonte: opennet.ru
