

Prima di tutto, quando si inizia a lavorare con un nuovo set di dati, è fondamentale comprenderlo. A tal fine, è necessario scoprire ad esempio gli intervalli di valori assunti dalle variabili, i loro tipi e anche conoscere il numero di valori mancanti.
La libreria pandas ci offre molti strumenti utili per eseguire l'analisi esplorativa dei dati (Exploratory Data Analysis, EDA). Tuttavia, prima di utilizzarli, di solito è necessario partire da funzioni di carattere più generale, come df.describe(). Va notato che le possibilità offerte da funzioni simili sono limitate, e i primi passi nel lavoro con qualsiasi set di dati durante l'EDA sono spesso molto simili tra loro.
L'autore del materiale che pubblichiamo oggi afferma di non essere un amante delle azioni ripetitive. Di conseguenza, nella sua ricerca di strumenti che consentano di eseguire rapidamente e efficacemente l'analisi esplorativa dei dati, ha trovato la libreria . I risultati del suo lavoro non si traducono in indicatori singoli, ma in un rapporto HTML piuttosto dettagliato, contenente gran parte delle informazioni sui dati analizzati che potrebbero essere utili prima di intraprendere un lavoro più approfondito.
In questa sede verranno esaminate le peculiarità dell'utilizzo della libreria pandas-profiling attraverso il dataset Titanic.
Analisi esplorativa dei dati con pandas
Ho deciso di sperimentare con pandas-profiling sul dataset Titanic perché contiene dati di vari tipi e presenta valori mancanti. Credo che la libreria pandas-profiling sia particolarmente interessante quando i dati non sono ancora puliti e richiedono ulteriori elaborazioni, a seconda delle loro caratteristiche. Per eseguire con successo tale elaborazione, è fondamentale sapere da dove cominciare e quali aspetti considerare. Qui ci vengono in aiuto le funzionalità di pandas-profiling.
Per iniziare, importiamo i dati e utilizziamo pandas per ottenere le metriche di statistica descrittiva:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
import numpy as np
# импорт данных
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
# вычисление показателей описательной статистики
df.describe()Dopo aver eseguito questo frammento di codice, si otterrà quanto mostrato nella seguente illustrazione.
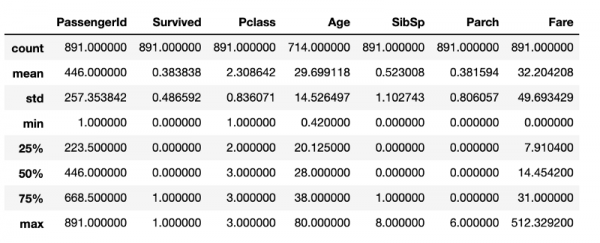
Indicatori di statistica descrittiva ottenuti tramite gli strumenti standard di pandas
Sebbene ci siano molte informazioni utili qui, non c'è tutto ciò che sarebbe interessante sapere sui dati analizzati. Ad esempio, si potrebbe supporre che nel frame di dati, nella struttura DataFrame, ci siano 891 righe. Se è necessario controllare questo, sarà necessaria un'altra riga di codice per definire la dimensione del frame. Anche se questi calcoli non sono particolarmente dispendiosi in termini di risorse, la loro ripetizione costante porterà inevitabilmente a perdite di tempo, tempo che probabilmente sarebbe meglio dedicare alla pulizia dei dati.
Analisi esplorativa dei dati utilizzando pandas-profiling
Ora facciamo lo stesso utilizzando pandas-profiling:
pandas_profiling.ProfileReport(df)Eseguendo la riga di codice sopra riportata sarà possibile generare un rapporto con le statistiche dell'analisi esplorativa dei dati. Il codice mostrato sopra porterà all'output delle informazioni trovate sui dati, ma si può fare in modo che il risultato sia un file HTML che, ad esempio, si può mostrare a qualcun altro.
La prima parte del rapporto conterrà una sezione Panoramica, che fornisce informazioni di base sui dati (numero di osservazioni, numero di variabili e così via). Inoltre, conterrà un elenco di avvisi per informare l'analista su cosa prestare particolare attenzione. Questi avvisi possono servire come suggerimenti su dove concentrare gli sforzi nella pulizia dei dati.
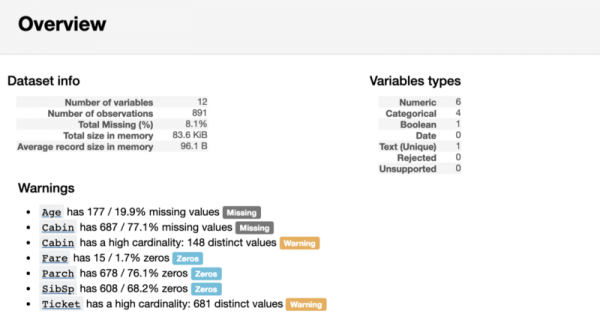
Sezione del rapporto Panoramica
Analisi esplorativa delle variabili
Dopo la sezione Panoramica nel rapporto, è possibile trovare informazioni utili su ogni variabile. Queste includono, tra l'altro, piccoli grafici che descrivono la distribuzione di ciascuna variabile.

Informazioni sulla variabile numerica Età
Come si può vedere dal precedente esempio, pandas-profiling ci offre alcuni indicatori utili, come la percentuale e il numero di valori mancanti, oltre ai parametri di statistica descrittiva che abbiamo già visto. Poiché Età è una variabile numerica, la visualizzazione della sua distribuzione sotto forma di istogramma ci consente di concludere che si tratta di una distribuzione inclinata a destra.
Quando si analizza una variabile categoriale, le metriche risultanti differiscono leggermente da quelle trovate per una variabile numerica.

Informazioni sulla variabile categoriale Sesso
Infatti, invece di calcolare la media, il minimo e il massimo, la libreria pandas-profiling ha trovato il numero di classi. Poiché Sesso è una variabile binaria, i suoi valori sono rappresentati da due classi.
Se, come me, ami esplorare il codice, potresti essere interessato a come la libreria pandas-profiling calcola queste metriche. Scoprire questo, considerando che il codice della libreria è aperto e disponibile su GitHub, non è così difficile. Poiché non amo molto utilizzare "scatole nere" nei miei progetti, ho dato un'occhiata al codice sorgente della libreria. Ad esempio, ecco come appare il meccanismo di gestione delle variabili numeriche, presentato dalla funzione :
def descrivi_numeric_1d(series, **kwargs):
"""Calcola statistiche riassuntive di una variabile numerica (`TYPE_NUM`) (una Series).
Crea anche istogrammi (mini e completi) della sua distribuzione.
Parametri
----------
series : Series
La variabile da descrivere.
Ritorna
-------
Series
La descrizione della variabile come una Series con indice che rappresenta le chiavi delle statistiche.
"""
# Formatta un numero come percentuale. Ad esempio, 0,25 verrà convertito in 25%.
_percentile_format = "{:.0%}"
stats = dict()
stats['type'] = base.TYPE_NUM
stats['mean'] = series.mean()
stats['std'] = series.std()
stats['variance'] = series.var()
stats['min'] = series.min()
stats['max'] = series.max()
stats['range'] = stats['max'] - stats['min']
# Per evitare di calcolarlo più volte
_series_no_na = series.dropna()
for percentile in np.array([0.05, 0.25, 0.5, 0.75, 0.95]):
# Il dropna() è una soluzione per https://github.com/pydata/pandas/issues/13098
stats[_percentile_format.format(percentile)] = _series_no_na.quantile(percentile)
stats['iqr'] = stats['75%'] - stats['25%']
stats['kurtosis'] = series.kurt()
stats['skewness'] = series.skew()
stats['sum'] = series.sum()
stats['mad'] = series.mad()
stats['cv'] = stats['std'] / stats['mean'] se stats['mean'] altrimenti np.NaN
stats['n_zeros'] = (len(series) - np.count_nonzero(series))
stats['p_zeros'] = stats['n_zeros'] * 1.0 / len(series)
# Istogrammi
stats['histogram'] = histogram(series, **kwargs)
stats['mini_histogram'] = mini_histogram(series, **kwargs)
return pd.Series(stats, name=series.name) Anche se questo frammento di codice può sembrare piuttosto grande e complesso, in realtà è molto semplice da comprendere. Si tratta del fatto che nel codice sorgente della libreria è presente una funzione che determina i tipi di variabili. Se la libreria incontra una variabile numerica, la funzione sopra citata troverà gli indicatori che abbiamo esaminato. In questa funzione vengono utilizzate operazioni standard di pandas per lavorare con oggetti di tipo Series, simili a series.mean(). I risultati dei calcoli vengono memorizzati in un dizionario stats. Gli istogrammi vengono creati utilizzando una versione adattata della funzione matplotlib.pyplot.hist. L'adattamento è volto a consentire alla funzione di lavorare con diversi tipi di set di dati.
Indicatori di correlazione e campione di dati in esame
Dopo l'analisi delle variabili, pandas-profiling genererà, nella sezione Correlations, matrici di correlazione di Pearson e Spearman.
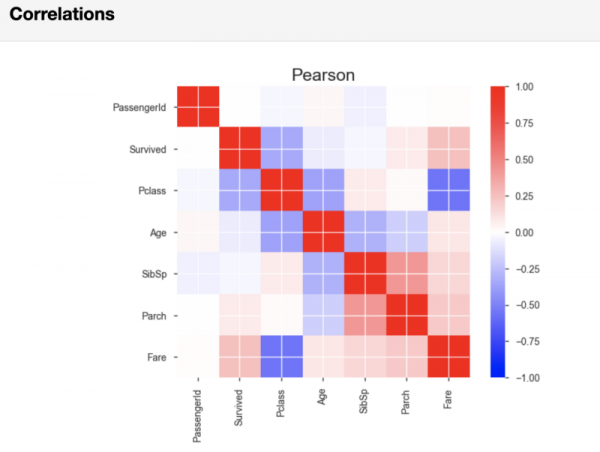
Matrice di correlazione di Pearson
Se necessario, è possibile impostare i valori soglia nella riga di codice che avvia la generazione del rapporto, utilizzati nel calcolo della correlazione. Facendo ciò, potete specificare quale forza di correlazione è considerata significativa per la vostra analisi.
Infine, nel rapporto pandas-profiling, nella sezione Campione, viene visualizzato un frammento di dati prelevato dall'inizio del set di dati come esempio. Questo approccio può portare a spiacevoli sorprese, poiché le prime osservazioni possono rappresentare un campione che non riflette le caratteristiche dell'intero set di dati.
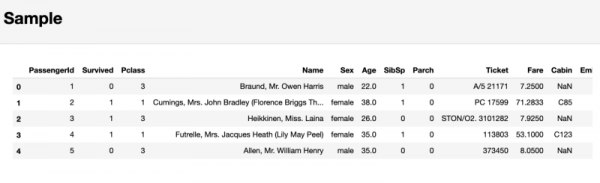
Sezione contenente un campione dei dati esaminati
Pertanto, non consiglio di prestare attenzione a quest'ultima sezione. È meglio utilizzare il comando df.sample(5), che selezionerà casualmente 5 osservazioni dal set di dati.
Risultati
In sintesi, si può notare che la libreria pandas-profiling offre agli analisti alcune utili funzionalità, che possono rivelarsi preziose quando è necessario ottenere rapidamente una panoramica generale dei dati o inviare a qualcuno un report sull'analisi esplorativa dei dati. Tuttavia, il lavoro reale con i dati, che tiene conto delle loro peculiarità, viene eseguito a mano, come anche senza l'uso di pandas-profiling.
Se vuoi vedere come appare l'intera analisi esplorativa dei dati in un unico notebook Jupyter, dai un'occhiata al mio progetto realizzato tramite nbviewer. E nel repository GitHub puoi trovare il codice corrispondente.
Gentili lettori! Da dove inizi ad analizzare nuovi set di dati?
Fonte: habr.com
