

A volte, per risolvere un problema, è sufficiente guardarlo da un'altra prospettiva. Anche se negli ultimi dieci anni problemi simili sono stati risolti nello stesso modo con effetti diversi, non è detto che questo metodo sia l'unico possibile.
C'è un argomento chiamato abbandono dei clienti. È una cosa inevitabile, perché i clienti di qualsiasi azienda possono smettere di utilizzare i suoi prodotti o servizi per molteplici motivi. È chiaro che per un'azienda l'abbandono, sebbene naturale, non è l'azione più desiderabile, quindi tutti cercano di minimizzare il tasso di abbandono. Ancor meglio sarebbe prevedere la probabilità di abbandono di una certa categoria di utenti, o di un utente specifico, e proporre alcune misure di retention.
Analizzare e cercare di mantenere il cliente, se possibile, è importante per almeno le seguenti ragioni:
- acquisire nuovi clienti è più costoso rispetto alle misure di retention. L'acquisizione di nuovi clienti richiede solitamente una certa somma di denaro (pubblicità), mentre ai clienti esistenti si può offrire un incentivo speciale con condizioni vantaggiose;
- Comprendere le ragioni della perdita di clienti è fondamentale per migliorare prodotti e servizi.
Esistono approcci standard per prevedere il tasso di abbandono. Ma a uno dei campionati di intelligenza artificiale abbiamo deciso di sperimentare la distribuzione di Weibull. Viene comunemente utilizzata per analisi di sopravvivenza, previsioni meteorologiche, analisi di disastri naturali, ingegneria industriale e simili. La distribuzione di Weibull è una funzione di distribuzione speciale, parametrizzata da due parametri  e
e  .
.
Wikipedia
In generale, è un argomento interessante, ma non è frequentemente utilizzato per la previsione del tasso di abbandono, né in generale nel fintech. Ne parleremo sotto, raccontandovi come noi (Laboratorio di analisi intelligente dei dati) lo abbiamo fatto, conquistando nel contempo l'oro al Campionato di intelligenza artificiale nella categoria "AI nelle banche".
Sul tasso di abbandono in generale
Vediamo un po' cosa si intende per abbandono del cliente e perché è così importante. Per un'azienda, la base clienti è fondamentale. In questa base entrano nuovi clienti, ad esempio, venendo a conoscenza di un prodotto o servizio tramite la pubblicità, utilizzano attivamente i prodotti per un certo periodo e, dopo un po', smettono di farlo. Questo periodo è definito "Ciclo di vita del cliente" (in inglese, Customer Lifecycle) — un termine che descrive le fasi che un cliente attraversa quando scopre un prodotto, prende una decisione d'acquisto, paga, utilizza e diventa un consumatore fedele, per poi smettere di utilizzarlo per vari motivi. Di conseguenza, l'abbandono rappresenta la fase finale del ciclo di vita del cliente, quando il cliente smette di usufruire dei servizi, il che significa che per l'azienda il cliente ha smesso di generare profitto e qualsiasi tipo di valore.
Ogni cliente della banca è una persona concreta, che sceglie una carta bancaria specifica in base alle proprie esigenze. Se viaggi spesso, potrebbe servirti una carta con punti. Se fai molti acquisti, ecco una carta con cashback. E se acquisti spesso in negozi specifici, ci sono carte dedicate per questo. Certo, a volte si sceglie anche in base al criterio "Il servizio più economico". In sostanza, ci sono molte variabili da considerare.
Inoltre, la scelta della banca è fondamentale: quale senso ha scegliere la carta di una banca che ha filiali solo a Mosca e nei dintorni, quando sei a Chabarovsk? Anche se la carta di quella banca fosse due volte più vantaggiosa, la presenza di filiali nelle vicinanze resta un criterio importante. Sì, il 2019 è già qui e il digitale è il nostro tutto, ma alcune questioni con alcune banche possono essere risolte solo in filiale. Inoltre, una parte della popolazione ripone maggiore fiducia in una banca fisica piuttosto che in un'app sullo smartphone, e anche questo fattore deve essere considerato.
Di conseguenza, ci possono essere molteplici motivi per cui una persona decide di rinunciare ai prodotti di una banca (o alla banca stessa). Ha cambiato lavoro e il piano della carta è passato da 'salariale' a 'per i comuni mortali', che è meno vantaggioso. Si è trasferito in un'altra città, dove non ci sono filiali della banca. Non gli è piaciuto il rapporto con un operatore poco qualificato in filiale. In altre parole, i motivi per chiudere un conto possono essere molto più numerosi rispetto a quelli per utilizzare un prodotto.
Inoltre, un cliente può non solo esprimere esplicitamente la sua intenzione — recarsi in banca e scrivere una richiesta, ma semplicemente smettere di utilizzare i prodotti, senza rescindere il contratto. È per comprendere situazioni simili che si è deciso di utilizzare l'apprendimento automatico e l'IA.
Inoltre, il tasso di abbandono dei clienti può verificarsi in qualsiasi settore (telecomunicazioni, fornitori di servizi internet, compagnie assicurative, insomma, ovunque ci sia una base clienti e transazioni periodiche).
Cosa abbiamo fatto
Prima di tutto, è stata necessaria una chiara definizione del momento in cui iniziamo a considerare un cliente come inattivo. Dal punto di vista della banca che ci ha fornito i dati per l'analisi, lo stato di attività del cliente era binario: o era attivo o no. C'era un flag ACTIVE_FLAG nella tabella "Attività", il cui valore poteva essere "0" o "1" (rispettivamente, "Non attivo" e "Attivo"). E tutto sarebbe andato bene, ma un essere umano può utilizzare attivamente i servizi per un certo periodo e poi diventare inattivo per un mese — malattia, viaggio all'estero per vacanza, o addirittura provare una carta di un'altra banca. O, dopo un lungo periodo di inattività, può iniziare a utilizzare nuovamente i servizi della banca.
Pertanto, abbiamo deciso di definire un periodo di inattività come un intervallo continuo di tempo in cui il flag per lui veniva impostato come "0".
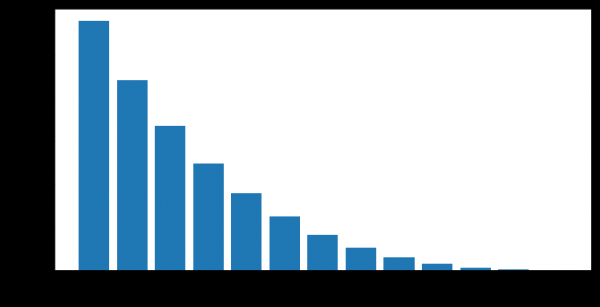
I clienti passano da uno stato inattivo a uno attivo dopo periodi di inattività di diversa lunghezza. Abbiamo l'opportunità di calcolare il grado della grandezza empirica "affidabilità dei periodi di inattività" — ovvero la probabilità che una persona ricominci a utilizzare i prodotti bancari dopo un periodo di inattività temporanea.
Ad esempio, in questo grafico è mostrato il ripristino dell'attività (ACTIVE_FLAG=1) dei clienti dopo alcuni mesi di inattività (ACTIVE_FLAG=0).
Qui specificeremo leggermente il set di dati con cui abbiamo iniziato a lavorare. Quindi, la banca ha fornito informazioni aggregate per 19 mesi nelle seguenti tabelle:
- "Attività" — transazioni mensili dei clienti (tramite carte, internet banking e mobile banking), inclusi gli accrediti degli stipendi e informazioni sui volumi.
- "Carte" — dati su tutte le carte del cliente, con dettagli sulla struttura tariffaria.
- "Contratti" — informazioni sui contratti del cliente (sia aperti che chiusi): prestiti, depositi e altro, con indicazione dei parametri di ciascuno.
- "Clienti" — un insieme di dati demografici (sesso e età) e disponibilità delle informazioni di contatto.
Per il nostro lavoro abbiamo bisogno di tutte le tabelle tranne quella "Carta".
La difficoltà qui risiedeva nel fatto che la banca non specificava quale tipo di attività avesse avuto luogo con le carte. Cioè, potevamo capire se ci fossero state transazioni, ma non potevamo determinare il loro tipo. Perciò non era chiaro se il cliente prelevasse contante, ricevesse uno stipendio o se stesse spendendo soldi per acquisti. Inoltre, non avevamo dati sulle giacenze sui conti, il che sarebbe stato utile.
Il campionamento stesso non era campionato — in questo intervallo di 19 mesi, la banca non ha fatto alcun tentativo di trattenere i clienti e minimizzare il dislocamento.
A proposito dei periodi di inattività.
Per formulare una definizione di dislocazione, è necessario scegliere un periodo di inattività. Per creare una previsione di dislocazione in un determinato momento  , è necessario avere la storia dei clienti per almeno 3 mesi nell'intervallo di
, è necessario avere la storia dei clienti per almeno 3 mesi nell'intervallo di  . La nostra storia era limitata a 19 mesi, quindi abbiamo deciso di considerare un periodo di inattività di 6 mesi, se presente. E per il periodo minimo per una previsione qualitativa abbiamo preso 3 mesi. I numeri di 3 e 6 mesi sono stati scelti empiricamente sulla base dell'analisi del comportamento di questi clienti.
. La nostra storia era limitata a 19 mesi, quindi abbiamo deciso di considerare un periodo di inattività di 6 mesi, se presente. E per il periodo minimo per una previsione qualitativa abbiamo preso 3 mesi. I numeri di 3 e 6 mesi sono stati scelti empiricamente sulla base dell'analisi del comportamento di questi clienti.
Abbiamo definito il tasso di abbandono nel seguente modo: il mese di abbandono del cliente  è il primo mese con ACTIVE_FLAG=0, in cui a partire da questo mese ci sono almeno sei zeri consecutivi nel campo ACTIVE_FLAG, in altre parole, il mese a partire dal quale il cliente è stato inattivo per 6 mesi.
è il primo mese con ACTIVE_FLAG=0, in cui a partire da questo mese ci sono almeno sei zeri consecutivi nel campo ACTIVE_FLAG, in altre parole, il mese a partire dal quale il cliente è stato inattivo per 6 mesi.
Numero di clienti persi
Numero di clienti rimanenti
Come si considera comunemente l'abbandono
In competizioni simili e anche nella pratica, il tasso di abbandono viene spesso previsto in questo modo. Il cliente utilizza prodotti e servizi in diversi momenti, i dati sulle interazioni con lui vengono rappresentati come un vettore di caratteristiche di lunghezza fissa n. Di solito, queste informazioni includono:
- Dati caratterizzanti l'utente (dati demografici, segmento di mercato).
- Storia dell'uso di prodotti e servizi bancari (queste sono azioni dei clienti, sempre legate a un tempo specifico o a un periodo dell'intervallo necessario).
- Dati esterni, se riusciti a ottenere—ad esempio, recensioni sui social media.
E dopo di ciò, forniscono una definizione del churn, specifica per ogni compito. Utilizzano poi un algoritmo di machine learning che prevede la probabilità di abbandono del cliente.  sulla base del vettore di fattori.
sulla base del vettore di fattori.  Per addestrare l'algoritmo, viene utilizzato uno dei noti framework per la costruzione di ensemble di alberi decisionali, , , o le loro variazioni.
Per addestrare l'algoritmo, viene utilizzato uno dei noti framework per la costruzione di ensemble di alberi decisionali, , , o le loro variazioni.
L'algoritmo in sé non è male, ma presenta alcuni seri svantaggi, soprattutto nella previsione del churn.
- Non ha quella che viene chiamata 'memoria'.Il modello riceve un determinato numero di caratteristiche che corrispondono al momento attuale. Per incorporare informazioni sulla storia delle variazioni dei parametri, è necessario calcolare caratteristiche speciali che descrivono le variazioni nel tempo dei parametri, ad esempio il numero o la somma delle transazioni bancarie negli ultimi 1, 2, 3 mesi. Questo approccio può riflettere solo parzialmente la natura dei cambiamenti nel tempo.
- Orizzonte di previsione fisso. Il modello è in grado di prevedere l'abbandono dei clienti solo per un intervallo di tempo predeterminato, ad esempio, una previsione per un mese. Se è necessaria una previsione per un altro intervallo di tempo, ad esempio, tre mesi, è necessario ristrutturare il campione di addestramento e riaddestrare un nuovo modello.
Il nostro approccio
Abbiamo deciso fin da subito di non utilizzare approcci standard. Al campionato si sono registrate altre 497 persone, ognuna delle quali aveva una solida esperienza alle spalle. Pertanto, cercare di adottare schemi standard in tali condizioni non è affatto una buona idea.
E abbiamo iniziato a risolvere i problemi legati al modello di classificazione binaria utilizzando la previsione della distribuzione probabilistica del tempo di abbandono dei clienti. Questo approccio consente di prevedere l'abbandono in modo più flessibile e di testare ipotesi più complesse rispetto a un approccio classico. , e consente di prevedere l'abbandono in modo più flessibile e di testare ipotesi più complesse rispetto a un approccio classico. Come famiglia di distribuzioni che modellano il tempo di abbandono, abbiamo scelto la distribuzione per il suo ampio utilizzo nell'analisi della sopravvivenza. Il comportamento del cliente può essere considerato una sorta di sopravvivenza.
Ecco esempi di distribuzioni di densità di probabilità di Weibull in base ai parametri  e
e  :
:
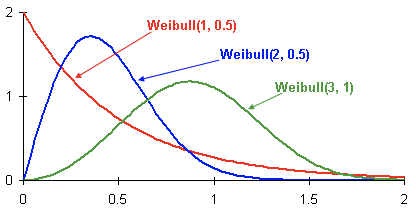
Questa è la densità di distribuzione della probabilità di abbandono per tre diversi clienti nel tempo. Il tempo è rappresentato in mesi. In altre parole, questo grafico mostra quando è più probabile che si verifichi l'abbandono di un cliente nei prossimi due mesi. Come si può vedere, il cliente con la distribuzione ha un potenziale maggiore di andarsene prima rispetto ai clienti con le distribuzioni Weibull(2, 0.5) e Weibull(3,1).
Ne risulta un modello che per ogni cliente, per ogni
mese, prevede i parametri della distribuzione di Weibull, che meglio riflettono l'emergere della probabilità di abbandono nel tempo. Per essere più precisi:
- Le caratteristiche target nel set di addestramento sono il tempo rimanente fino all'abbandono in un mese specifico per un cliente specifico.
- Se il tasso di abbandono per un cliente non è disponibile, si presume che il tempo di abbandono sia maggiore del numero di mesi che intercorrono dall'attuale fino alla fine della storia disponibile.
- Modello utilizzato: rete neurale ricorrente con strato LSTM.
- Come funzione di perdita utilizziamo la funzione logaritmica negativa della probabilità per la distribuzione di Weibull.
Ecco i vantaggi di questo metodo:
- La distribuzione di probabilità, oltre alla sua chiara capacità di classificazione binaria, permette di prevedere eventi diversi in modo flessibile, come ad esempio se un cliente smetterà di utilizzare i servizi di una banca entro 3 mesi. Inoltre, se necessario, vari metriche possono essere mediate utilizzando questa distribuzione.
- La rete neurale ricorrente LSTM ha memoria e utilizza efficacemente tutta la storia disponibile. Con l'espansione o il perfezionamento della storia, la precisione aumenta.
- L'approccio può essere facilmente scalato suddividendo gli intervalli temporali in parti più piccole (ad esempio, suddividendo i mesi in settimane).
Ma non basta creare un buon modello, è necessario anche valutare adeguatamente la sua qualità.
Come è stata valutata la qualità
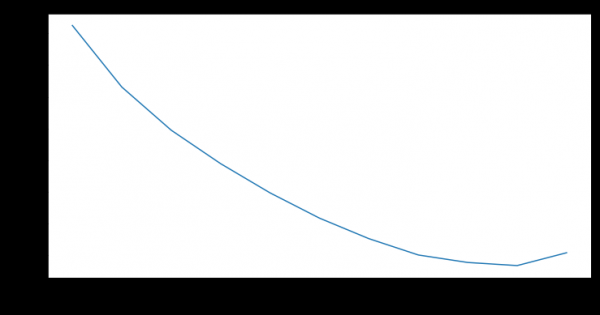
Come metrica abbiamo scelto la Lift Curve. Viene utilizzata nel business in casi simili per la sua interpretazione chiara, ed è ben descritta e . Se dovessimo descrivere il significato di questa metrica in una frase, sarebbe "Di quanto migliore è la previsione dell'algoritmo nelle prime  %, rispetto al caso casuale.
%, rispetto al caso casuale.
Formiamo modelli
Le condizioni della competizione non stabilivano una metrica specifica di qualità per confrontare diversi modelli e approcci. Inoltre, la definizione del concetto di abbandono può variare e dipendere dall'impostazione del problema, che a sua volta è fissata dagli obiettivi aziendali. Pertanto, per capire quale metodo sia migliore, abbiamo addestrato due modelli:
- Un approccio frequentemente utilizzato è la classificazione binaria, impiegando un algoritmo di apprendimento automatico basato su un ensemble di alberi decisionali ();
- Modello Weibull-LSTM
Il campione di test era composto da 500 clienti selezionati in anticipo, che non erano presenti nel set di addestramento. Per il modello, è stata effettuata l'ottimizzazione degli iperparametri utilizzando la cross-validazione con suddivisione per cliente. Sono stati utilizzati set di caratteristiche identici per l'addestramento di ciascun modello.
Poiché il modello non dispone di memoria, sono state utilizzate caratteristiche specifiche che mostrano la relazione del cambiamento dei parametri di un mese rispetto al valore medio dei parametri negli ultimi tre mesi. Questi caratterizzavano la velocità di cambiamento dei valori nell'ultimo periodo di tre mesi. Senza questo, il modello basato su Random Forest sarebbe stato in una posizione di svantaggio rispetto a Weibull-LSTM.
Perché LSTM con distribuzione Weibull è migliore rispetto all'approccio basato su un ensemble di alberi decisionali
Qui tutto è chiaro, bastano un paio di immagini.
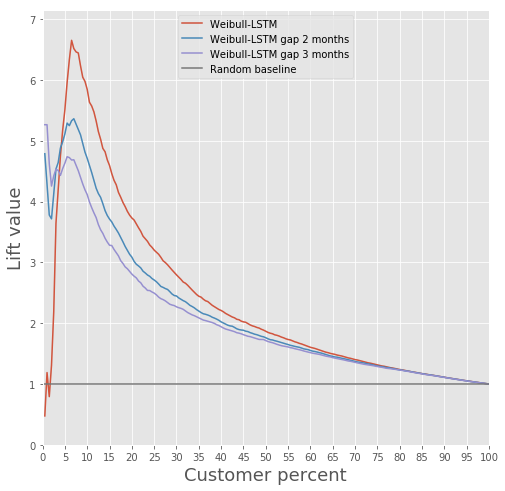
Confronto della Lift Curve tra l'algoritmo classico e Weibull-LSTM
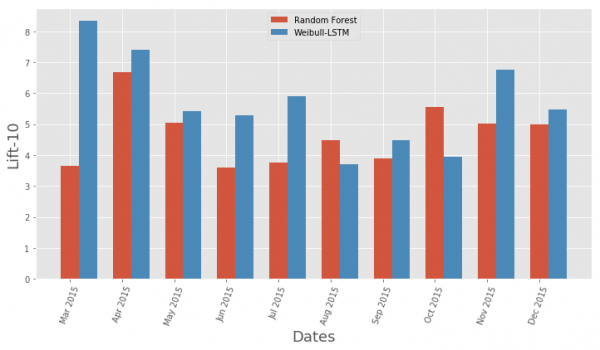
Confronto della metrica Lift Curve mensile tra l'algoritmo classico e Weibull-LSTM
In generale, LSTM supera l'algoritmo classico in quasi tutti i casi.
Predizione del churn
Un modello basato su una rete neurale ricorrente con celle LSTM e distribuzione Weibull può prevedere l'abbandono in anticipo, per esempio, prevedere la partenza di un cliente nei prossimi n mesi. Consideriamo il caso per n = 3. In questo caso, per ogni mese, la rete neurale deve determinare correttamente se il cliente abbandonerà, a partire dal mese successivo fino al mese n. In altre parole, deve determinare correttamente se il cliente rimarrà dopo n mesi. Questo può essere considerato una previsione anticipata: prevedere il momento in cui un cliente ha appena iniziato a pensare di andarsene.
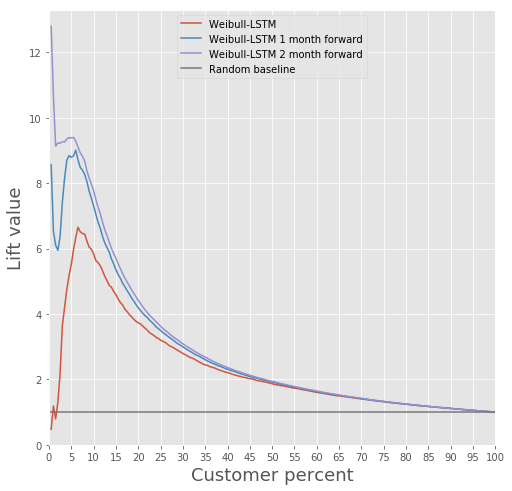
Confrontiamo la Lift Curve per Weibull-LSTM a 1, 2 e 3 mesi prima dell'abbandono:
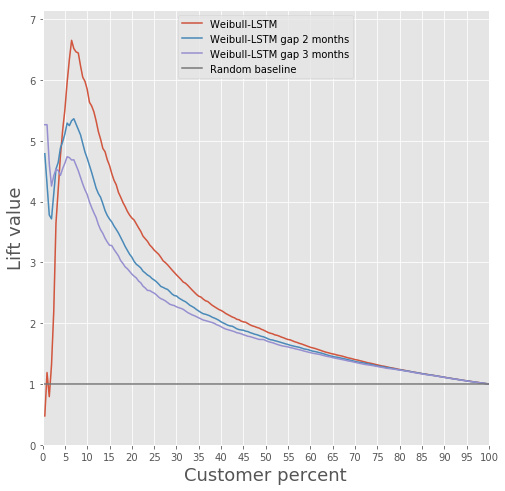
Abbiamo già scritto sopra che anche le previsioni fatte per i clienti che diventano inattivi per un certo periodo sono importanti. Pertanto, qui aggiungeremo al campione tali casi in cui un cliente che ha abbandonato è già stato inattivo per uno o due mesi, e verificheremo affinché Weibull-LSTM classifichi correttamente tali casi come abbandono. Poiché tali casi erano presenti nel campione, ci aspettiamo che la rete li gestisca bene:
Fidelizzazione dei clienti
In effetti, è questo il principale passo da compiere quando si ha l'informazione che determinati clienti stanno per smettere di utilizzare un prodotto. Parlando della costruzione di un modello che possa offrire qualcosa di utile ai clienti per trattenerli, non sarà possibile farlo se non si ha una storia di tentativi che siano terminati bene.
Noi non abbiamo avuto una tale storia, quindi abbiamo deciso di procedere in questo modo.
- Stiamo costruendo un modello che identifica i prodotti interessanti per ciascun cliente.
- Ogni mese eseguiamo il classificatore e identifichiamo i clienti potenzialmente in uscita.
- Offriamo un prodotto a una parte dei clienti, secondo il modello del punto 1, e registriamo le nostre azioni.
- Dopo alcuni mesi, verifichiamo quali di questi clienti potenzialmente in uscita se ne sono andati e quali sono rimasti. In questo modo formiamo il campione per l'addestramento.
- Addestriamo il modello sulla storia ottenuta nel punto 4.
- Facoltativamente, ripetiamo la procedura, sostituendo il modello del punto 1 con quello ottenuto al punto 5.
Un modo per verificare la qualità di tale retention può essere il consueto A/B testing: suddividiamo i clienti potenzialmente in uscita in due gruppi. A uno proponiamo prodotti basati sul nostro modello di retention, all'altro non proponiamo nulla. Abbiamo deciso di addestrare un modello che potrebbe essere utile già al punto 1 del nostro esempio.
Volevamo rendere la segmentazione il più interpretabile possibile. Per questo motivo, abbiamo scelto alcune caratteristiche facilmente interpretabili: numero totale di transazioni, stipendio, fatturato totale del conto, età, sesso. Non sono stati considerati i criteri nella tabella 'Carte' poiché poco informativi, e quelli nella tabella 3 'Contratti' a causa della complessità di elaborazione per evitare perdite di dati tra il set di validazione e il set di addestramento.
La clusterizzazione è stata effettuata utilizzando i modelli di mistura gaussiana. Il criterio informativo di Akaike ha permesso di determinare 2 ottimi. Il primo ottimo corrisponde a 1 cluster. Il secondo ottimo, meno definito, corrisponde a 80 cluster. Da questo risultato si può concludere che è estremamente difficile separare i dati in cluster senza informazioni predefinite. Per una clusterizzazione di migliore qualità sono necessari dati che descrivano dettagliatamente ogni cliente.
Pertanto, è stata considerata la questione dell'apprendimento supervisionato per proporre a ciascun cliente un prodotto specifico. Sono stati presi in considerazione i seguenti prodotti: "Deposito a termine", "Carta di credito", "Scoperto", "Prestito al consumo", "Prestito auto", "Mutuo".
Nei dati era presente un altro tipo di prodotto: "Conto corrente". Tuttavia, non l'abbiamo considerato a causa della scarsa informatività. È stato costruito un modello sui clienti della banca, ovvero coloro che non hanno smesso di utilizzare i suoi prodotti, per prevedere quale prodotto potrebbe interessarli. È stata scelta la regressione logistica come modello e, per la valutazione della qualità, è stato utilizzato il valore di Lift per i primi 10 percentile.
La qualità del modello può essere valutata nella figura.
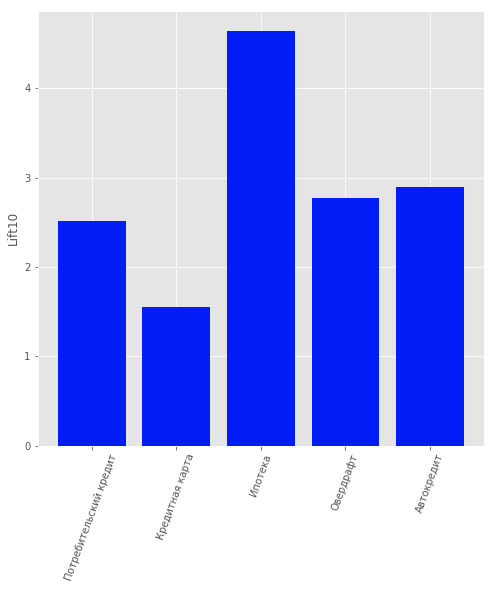
Risultati del modello di raccomandazione di prodotti per i clienti
Risultato
Questo approccio ci ha permesso di ottenere il primo posto nella categoria "AI nelle banche" al Campionato di IA RAIF-Challenge 2017.

Sembra che l'importante fosse avvicinarsi al problema da una prospettiva non convenzionale e utilizzare un metodo solitamente impiegato in altre situazioni.
Tuttavia, un'imponente fuga di utenti può rappresentare una vera e propria calamità per i servizi.
Questo metodo può essere utile anche in altri settori in cui l'analisi del churn è importante, non solo nelle banche. Ad esempio, lo abbiamo utilizzato per calcolare il nostro tasso di abbandono nelle filiali di Rostelecom in Siberia e San Pietroburgo.
«Laboratorio di analisi dei dati intelligenti» della società «Portale di ricerca Sputnik»
Fonte: habr.com
