

L'articolo è composto da due parti:
- Una breve descrizione di alcune architetture delle reti per il rilevamento degli oggetti nelle immagini e la segmentazione delle immagini, con i link più chiari per me. Ho cercato di scegliere video esplicativi, preferibilmente in lingua russa.
- La seconda parte consiste nel tentativo di comprendere la direzione di sviluppo delle architetture delle reti neurali e delle tecnologie basate su di esse.

Figura 1 – Comprendere le architetture delle reti neurali non è semplice
Tutto è iniziato con la creazione di due applicazioni dimostrative per la classificazione e il rilevamento di oggetti su telefono Android:
- , quando i dati vengono elaborati sul server e inviati al telefono. Classificazione delle immagini (image classification) di tre tipi di orsi: bruno, nero e di peluche.
- , quando i dati vengono elaborati direttamente sul telefono. Rilevamento degli oggetti (object detection) di tre tipi: nocciola, fico e dattero.
C'è una differenza tra le attività di classificazione delle immagini, rilevamento degli oggetti nelle immagini e . Perciò, è emersa la necessità di comprendere quali architetture delle reti neurali rilevano oggetti nelle immagini e quali possono segmentarli. Ho trovato i seguenti esempi di architetture con collegamenti a risorse che mi sembrano più comprensibili:
- Serie di architetture basate su R-CNN (Rregioni con Cvoluzione Nrettile Nrete): R-CNN, Fast R-CNN, , . Per la rilevazione di un oggetto nell'immagine, tramite il meccanismo Region Proposal Network (RPN), vengono evidenziate regioni limitate (bounding boxes). Inizialmente, invece di RPN, veniva utilizzato un meccanismo più lento chiamato Selective Search. Successivamente, le regioni limitate identificate vengono fornite come input a una rete neurale convenzionale per la classificazione. Nell'architettura R-CNN ci sono cicli espliciti 'for' per passare attraverso le regioni limitate, con fino a 2000 passaggi attraverso la rete interna AlexNet. A causa di questi cicli espliciti 'for', la velocità di elaborazione delle immagini è rallentata. Il numero di cicli espliciti, di passaggi attraverso la rete neurale interna, diminuisce con ogni nuova versione dell'architettura, e vengono implementate decine di altre modifiche per aumentare la velocità e per sostituire la task di rilevamento degli oggetti con la segmentazione degli oggetti in Mask R-CNN.
- (Ypuò Osolo Lguardare Once) – la prima rete neurale in grado di riconoscere oggetti in tempo reale su dispositivi mobili. La caratteristica distintiva: la distinzione degli oggetti in un'unica passata (basta guardare una volta). Quindi, nell'architettura YOLO non ci sono cicli espliciti "for", il che rende la rete veloce. Ad esempio, una simile analogia: in NumPy, durante le operazioni con le matrici, non ci sono cicli espliciti "for", poiché vengono implementati a un livello inferiore attraverso il linguaggio di programmazione C. YOLO utilizza una rete di finestre predefinite. Per evitare che lo stesso oggetto venga identificato più volte, viene utilizzato un coefficiente di sovrapposizione delle finestre (IoU, Intersection over Union). Questa architettura funziona su un'ampia gamma e ha un'alta : il modello può essere addestrato su fotografie, ma funziona bene anche su dipinti.
- (Single Shot MultiBox DDetectors) – vengono utilizzati i migliori "hack" dell'architettura YOLO (ad esempio, la soppressione non massima) e vengono aggiunti nuovi metodi per far funzionare la rete neurale più rapidamente e con maggiore precisione. Una caratteristica distintiva è la distinzione degli oggetti in un solo passaggio utilizzando una griglia di finestre (default box) su una piramide di immagini. La piramide delle immagini è codificata in tensori convoluzionali durante operazioni successive di convoluzione e pooling (durante l'operazione di max-pooling, la dimensione spaziale diminuisce). In questo modo vengono definiti sia oggetti grandi che piccoli in un solo passaggio della rete.
- MobileSSD (MobileNetV2 + SSD) – combinazione di due architetture di reti neurali. La prima rete lavora rapidamente e aumenta la precisione del riconoscimento. MobileNetV2 è utilizzato al posto di VGG-16, che era originariamente impiegato in . La seconda rete SSD determina la posizione degli oggetti nell'immagine.
- – una rete neurale molto piccola, ma precisa. Di per sé non risolve il problema del rilevamento degli oggetti. Tuttavia, può essere utilizzata in combinazione con diverse architetture e impiegata nei dispositivi mobili. La caratteristica distintiva è che i dati vengono inizialmente compressi in quattro filtri convoluzionali 1×1, per poi essere espansi in quattro filtri 1×1 e quattro filtri 3×3. Un'iterazione di compressione-espansione dei dati è chiamata «Fire Module».
- (Segmentazione semantica delle immagini con reti neurali convoluzionali profonde) – segmentazione degli oggetti in un'immagine. La caratteristica distintiva dell'architettura è la convoluzione dilatata, che preserva la risoluzione spaziale. Segue una fase di post-elaborazione dei risultati tramite un modello probabilistico grafico, che consente di rimuovere piccoli rumori nella segmentazione e migliorare la qualità dell'immagine segmentata. Dietro il temibile nome «modello probabilistico grafico» si cela un comune filtro gaussiano approssimato su cinque punti.
- Ho cercato di capire il funzionamento (Single-Shot Refinement Neural Network for Object Detsezione), ma non ho capito molto.
- Ho anche guardato come funziona la tecnologia dell'«attenzione»: , , . La caratteristica distintiva dell'architettura dell'«attenzione» è l'individuazione automatica delle regioni di maggiore interesse sull'immagine (RoI, Rregioni of Idi interesse) tramite una rete neurale chiamata Attention Unit. Le regioni di attenzione assomigliano a dei bounding boxes, ma a differenza di queste, non sono fissate sull'immagine e possono avere confini sfocati. Successivamente, dalle regioni di interesse vengono estratti dei tratti (features), che vengono "alimentati" a reti neurali ricorrenti con architetture . Le reti neurali ricorrenti sono in grado di analizzare le relazioni tra i tratti in una sequenza. Inizialmente, le reti neurali ricorrenti venivano utilizzate per le traduzioni di testo in altre lingue, e ora anche per la traduzione e .
Man mano che studiavo queste architetture ho capito che non capivo nulla. E non si tratta del fatto che la mia rete neurale abbia problemi con il meccanismo di attenzione. Creare tutte queste architetture sembra un enorme hackathon, dove gli autori competono nel trovare hacks. Un hack è una soluzione rapida a un difficile problema software. Cioè, tra tutte queste architetture non c'è un legame logico visibile e comprensibile. Tutto ciò che le unisce è un insieme dei migliori hacks che si rubano l'un l'altro, più un comune denominatore. (propagazione dell'errore inversa, backpropagation). Nessun ! Non è chiaro cosa cambiare e come ottimizzare i risultati ottenuti.
Di conseguenza, a causa della mancanza di connessione logica tra gli hacks, è estremamente difficile ricordarli e applicarli nella pratica. Si tratta di conoscenze frammentate. Al meglio, si ricordano solo pochi dettagli interessanti e inaspettati, ma la maggior parte di quanto compreso e non compreso svanisce dalla memoria già dopo qualche giorno. Sarà un risultato positivo se dopo una settimana si ricorderà almeno il nome dell'architettura. Ma per leggere articoli e guardare video di panoramica sono state dedicate molte ore e persino giorni di lavoro!
Figura 2 –
La maggior parte degli autori di articoli scientifici, secondo la mia opinione personale, fa tutto il possibile affinché anche queste conoscenze frammentate non siano comprese dal lettore. Ma le costruzioni gerundive in dieci frasi con formule, prese 'dal nulla' – questo è un tema per un articolo a parte (problema ).
Per questo motivo è emersa la necessità di sistematizzare le informazioni sulle reti neurali e, in questo modo, aumentare la qualità della comprensione e della memoria. Pertanto, il tema principale dell'analisi delle singole tecnologie e architetture delle reti neurali artificiali è diventato il seguente compito: capire in che direzione ci si sta muovendo, e non il funzionamento di una specifica rete neurale in particolare.
In che direzione ci si sta muovendo. Risultati principali:
- Il numero di startup nel campo dell'apprendimento automatico negli ultimi due anni . Possibile causa: 'le reti neurali hanno smesso di essere qualcosa di nuovo'.
- Chiunque sarà in grado di creare una rete neurale funzionante per risolvere un compito semplice. A tal fine, prenderà un modello già pronto dallo 'zoo dei modelli' (model zoo) e allenerà l'ultimo strato della rete neurale () su dati esistenti da o da nella gratuita .
- I principali produttori di reti neurali hanno iniziato a creare «zoo di modelli» (model zoo). Con essi è possibile creare rapidamente un'applicazione commerciale: per TensorFlow, per PyTorch, per Caffe2, per Chainer e .
- Reti neurali funzionanti in tempo reale (real-time) su dispositivi mobili. Da 10 a 50 fotogrammi al secondo.
- Utilizzo delle reti neurali nei telefoni (TF Lite), nei browser (TF.js) e in (IoT, Iinternet of Tdelle cose). Soprattutto nei telefoni, che già supportano le reti neurali a livello di «hardware» (neuroacceleratori).
- «Ogni dispositivo, indumenti e, forse, anche il cibo avranno un indirizzo IP-v6 e comunicheranno tra loro» – .
- L'aumento delle pubblicazioni su machine learning ha iniziato a (raddoppiando ogni due anni) dal 2015. È evidente che servono reti neurali per l'analisi degli articoli.
- Stanno guadagnando popolarità le seguenti tecnologie:
- PyTorch – la popolarità sta crescendo rapidamente e sembra superare TensorFlow.
- Ottimizzazione automatica degli iperparametri AutoML – la popolarità sta crescendo lentamente.
- Riduzione graduale della precisione e aumento della velocità di calcolo: , algoritmi , calcoli imprecisi (approssimativi), quantizzazione (quando i pesi della rete neurale vengono convertiti in numeri interi e quantizzati), neuroacceleratori.
- Traduzione e .
- Creazione , ora in tempo reale.
- L'elemento principale nel DL è la grande quantità di dati, ma raccoglierli e annotarli non è facile. Per questo motivo si sviluppa l'automazione dell'annotazione () per le reti neurali tramite altre reti neurali.
- Con le reti neurali, la Computer Science è diventata improvvisamente una scienza sperimentale ed è emerso .
- I soldi IT e la popolarità delle reti neurali sono emersi simultaneamente, quando il calcolo è diventato un valore di mercato. L'economia da oro-valutaria diventa oro-valuta-calcolo.Guarda il mio articolo su e il motivo dell'emergere dei soldi IT.
Gradualmente emerge una nuova (Machine Learning & Deep Learning), che si basa sulla rappresentazione del programma come un insieme di modelli neurali addestrati.
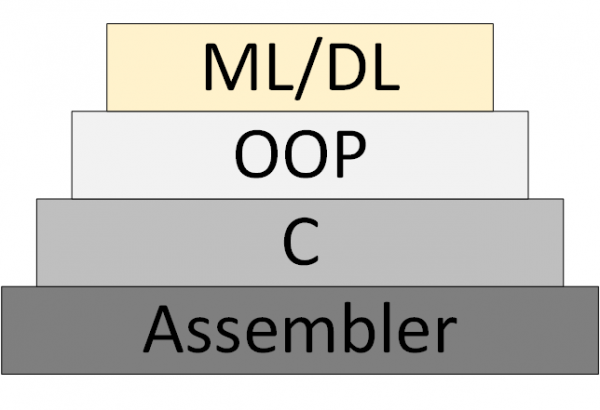
Figura 3 – ML/DL come nuova metodologia di programmazione
Tuttavia, non è emersa una «teoria delle reti neurali», nell'ambito del quale è possibile pensare e lavorare in modo sistemico. Ciò che attualmente è chiamato «teoria» sono in realtà algoritmi sperimentali ed euristici.
Link alle mie e non solo risorse:
- Newsletter su Data Science. Principalmente sulla elaborazione di immagini. Chi desidera riceverla, può inviare un'email (foobar167<знак>gmail<точка>com). I link ad articoli e video vengono inviati man mano che accumulo materiale.
- Generale , che ho seguito e che vorrei seguire.
- , con cui vale la pena iniziare a studiare le reti neurali. Inoltre, una brochure .
- , dove ognuno può trovare qualcosa di interessante per sé.
- Sono stati estremamente utili i canali video che analizzano articoli scientifici su Data Science. Trovate, iscrivetevi a loro e inviate i link anche ai vostri colleghi e a me. Esempi:
- aka con istruzioni passo passo e codice sorgente aperto.
Grazie per l'attenzione!
Fonte: habr.com
