

כולם מדברים על תהליכי הפיתוח והבדיקות, הכשרת הצוות, הגברת המוטיבציה, אבל התהליכים האלה לא מספיקים כשדקה של השבתת שירות עולה סכומי כסף אדירים. מה לעשות כאשר אתה מבצע עסקאות פיננסיות תחת SLA קפדני? כיצד להגביר את האמינות ואת סבילות התקלות של המערכות שלך, להוציא את הפיתוח והבדיקות מהמשוואה?

כנס HighLoad++ הבא יתקיים ב-6 וב-7 באפריל 2020 בסנט פטרסבורג. פרטים וכרטיסים עבור . 9 בנובמבר, 18:00. HighLoad++ מוסקבה 2018, דלהי + אולם קולקטה. תזות ו .
יבגני קוזובלב (להלן - EC): - חברים, שלום! שמי קוזובלב יבגני. אני מחברת EcommPay, חטיבה ספציפית היא EcommPay IT, חטיבת ה-IT של קבוצת החברות. והיום נדבר על השבתות - על איך להימנע מהן, על איך למזער את ההשלכות שלהן אם אי אפשר להימנע מכך. הנושא מצוין כך: "מה לעשות כאשר דקת השבתה עולה $100"? במבט קדימה, המספרים שלנו ברי השוואה.
מה עושה EcommPay IT?
מי אנחנו? למה אני עומד כאן מולך? למה יש לי את הזכות להגיד לך משהו כאן? ועל מה נדבר כאן ביתר פירוט?
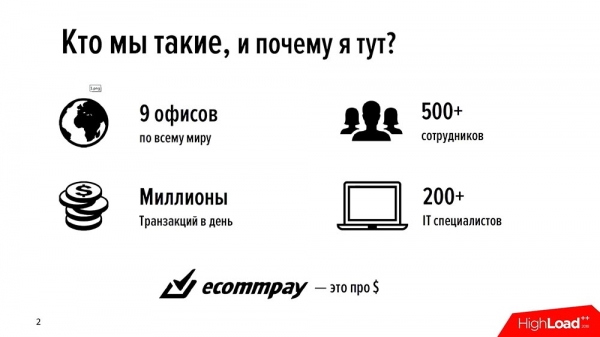
קבוצת החברות EcommPay היא רוכשת בינלאומית. אנו מעבדים תשלומים בכל רחבי העולם - ברוסיה, אירופה, דרום מזרח אסיה (בכל רחבי העולם). יש לנו 9 משרדים, 500 עובדים בסך הכל, וקצת פחות ממחציתם הם מומחי IT. כל מה שאנחנו עושים, כל מה שאנחנו עושים ממנו כסף, עשינו בעצמנו.
את כל המוצרים שלנו (ויש לנו לא מעט מהם - בשורה של מוצרי IT גדולים שלנו יש לנו בערך 16 רכיבים שונים) כתבנו בעצמנו; אנחנו כותבים את עצמנו, אנחנו מפתחים את עצמנו. וכרגע אנחנו מבצעים כמיליון עסקאות ביום (מיליונים זו כנראה הדרך הנכונה לומר זאת). אנחנו חברה די צעירה - אנחנו רק בני שש בערך.
לפני 6 שנים זה היה סטארטאפ כזה כשהחבר'ה הגיעו יחד עם העסק. הם התאחדו על ידי רעיון (לא היה שום דבר אחר מלבד רעיון), ורצנו. כמו כל סטארטאפ, רצנו מהר יותר... עבורנו המהירות הייתה חשובה יותר מהאיכות.
באיזשהו שלב עצרנו: הבנו שאיכשהו כבר לא נוכל לחיות באותה מהירות ובאיכות הזו וצריך להתמקד קודם כל באיכות. ברגע זה, החלטנו לכתוב פלטפורמה חדשה שתהיה נכונה, ניתנת להרחבה ואמינה. הם התחילו לכתוב את הפלטפורמה הזו (הם התחילו להשקיע, לפתח פיתוח, בדיקות), אבל בשלב מסוים הם הבינו שהפיתוח והבדיקות לא מאפשרים לנו להגיע לרמה חדשה של איכות שירות.
אתה מייצר מוצר חדש, אתה מכניס אותו לייצור, אבל בכל זאת משהו ישתבש איפשהו. והיום נדבר על איך להגיע לרמת איכות חדשה (איך עשינו את זה, על הניסיון שלנו), להוציא את הפיתוח והבדיקה מהמשוואה; נדבר על מה זמין לפעולה - איזו פעולה יכולה לעשות בעצמה, מה היא יכולה להציע לבדיקה כדי להשפיע על האיכות.
זמני השבתה. מצוות פעולה.
תמיד אבן היסוד העיקרית, מה שבעצם נדבר עליו היום הוא השבתה. מילה נוראית. אם יש לנו השבתה, הכל רע עבורנו. אנחנו רצים להעלות אותו, המנהלים מחזיקים את השרת - חס וחלילה לא ייפול, כמו שאומרים בשיר ההוא. על זה נדבר היום.

כשהתחלנו לשנות את הגישות שלנו, יצרנו 4 מצוות. יש לי אותם מוצגים בשקופיות:
המצוות האלה די פשוטות:

- זהה במהירות את הבעיה.
- להיפטר ממנו אפילו יותר מהר.
- עזרו להבין את הסיבה (מאוחר יותר, למפתחים).
- ולתקן גישות.
אני רוצה להסב את תשומת לבכם לנקודה מס' 2. אנחנו נפטרים מהבעיה, לא פותרים אותה. ההחלטה היא משנית. עבורנו, הדבר העיקרי הוא שהמשתמש מוגן מפני בעיה זו. הוא יתקיים בסביבה מבודדת כלשהי, אך לסביבה הזו לא יהיה כל מגע איתה. למעשה, נעבור על ארבע קבוצות הבעיות הללו (חלקן ביתר פירוט, חלקן בפירוט פחות), אספר לכם במה אנו משתמשים, באיזה ניסיון רלוונטי יש לנו בפתרונות.
פתרון תקלות: מתי הם קורים ומה לעשות לגביהם?
אבל נתחיל בלי סדר, נתחיל בנקודה מס' 2 - איך נפטרים במהירות מהבעיה? יש בעיה - אנחנו צריכים לתקן אותה. "מה עלינו לעשות בנידון?" - השאלה העיקרית. וכשהתחלנו לחשוב איך לתקן את הבעיה, פיתחנו לעצמנו כמה דרישות שפתרון הבעיות חייב לעמוד בהן.

כדי לגבש את הדרישות הללו, החלטנו לשאול את עצמנו את השאלה: "מתי יש לנו בעיות"? ובעיות, כפי שהתברר, מתרחשות בארבעה מקרים:

- כשל בחומרה.
- שירותים חיצוניים נכשלו.
- שינוי גרסת התוכנה (אותה פריסה).
- גידול עומס נפץ.
לא נדבר על השניים הראשונים. תקלת חומרה ניתנת לפתרון די פשוט: אתה חייב לשכפל הכל. אם אלה דיסקים, יש להרכיב את הדיסקים ב-RAID; אם זה שרת, יש לשכפל את השרת; אם יש לך תשתית רשת, עליך לספק עותק שני של תשתית הרשת, כלומר לקחת אותו לשכפל אותו. ואם משהו נכשל, אתה עובר לכוח מילואים. קשה לומר כאן משהו נוסף.
השני הוא כישלון השירותים החיצוניים. לרוב, המערכת אינה מהווה בעיה כלל, אך לא עבורנו. מאחר שאנו מעבדים תשלומים, אנו אגרגטור העומד בין המשתמש (המזין את נתוני הכרטיס שלו) לבין הבנקים, מערכות התשלומים (ויזה, מאסטרקארד, מירה וכו'). השירותים החיצוניים שלנו (מערכות תשלום, בנקים) נוטים להיכשל. לא אנחנו ולא אתה (אם יש לך שירותים כאלה) לא יכולים להשפיע על זה.
מה לעשות אז? יש כאן שתי אפשרויות. ראשית, אם אתה יכול, עליך לשכפל שירות זה בדרך כלשהי. לדוגמה, אם אנחנו יכולים, אנחנו מעבירים תעבורה משירות אחד למשנהו: למשל, כרטיסים עובדו דרך Sberbank, Sberbank נתקל בבעיות - אנחנו מעבירים תעבורה [בתנאי] ל- Raiffeisen. הדבר השני שאנו יכולים לעשות הוא להבחין בכשל של שירותים חיצוניים מהר מאוד, ולכן נדבר על מהירות התגובה בחלק הבא של הדוח.
למעשה, מתוך ארבע אלו נוכל להשפיע ספציפית על שינוי גרסאות התוכנה – לנקוט בפעולות שיובילו לשיפור המצב בהקשר של פריסות ובהקשר של גידול נפיץ בעומס. למעשה, זה מה שעשינו. הנה, שוב, הערה קטנה...
מבין ארבע הבעיות הללו, כמה נפתרות מיד אם יש לך ענן. אם אתה נמצא בענני Microsoft Azhur, אוזון, או משתמש בעננים שלנו, מ-Yandex או Mail, אז לפחות תקלת חומרה הופכת לבעיה שלהם והכל מיד הופך להיות תקין עבורך בהקשר של תקלת חומרה.
אנחנו חברה קצת לא שגרתית. כאן כולם מדברים על "קובנטס", על עננים - אין לנו "קובנטס" ולא עננים. אבל יש לנו מתלים של חומרה במרכזי נתונים רבים, ואנחנו נאלצים לחיות על החומרה הזו, אנחנו נאלצים להיות אחראים לכל זה. לכן, נדבר בהקשר זה. אז בקשר לבעיות. שני הראשונים הוצאו מסוגריים.
שינוי גרסת התוכנה. בסיסים
למפתחים שלנו אין גישה לייצור. למה? רק שאנחנו מוסמכים PCI DSS, ולמפתחים שלנו פשוט אין את הזכות להיכנס ל"מוצר". זהו, נקודה. בכלל. לכן, אחריות הפיתוח מסתיימת בדיוק ברגע שבו הפיתוח מגיש את ה-build לשחרור.

הבסיס השני שלנו שיש לנו, שגם עוזר לנו מאוד, הוא היעדר ידע בלתי מתועד ייחודי. אני מקווה שאצלך זה אותו דבר. כי אם זה לא המקרה, יהיו לך בעיות. בעיות יתעוררו כאשר הידע הייחודי והלא מתועד זה אינו נוכח בזמן הנכון במקום הנכון. נניח שיש לך אדם אחד שיודע לפרוס רכיב מסוים - האדם לא שם, הוא בחופשה או חולה - זהו, יש לך בעיות.
והבסיס השלישי אליו הגענו. הגענו אליו דרך כאב, דם, דמעות – הגענו למסקנה שכל אחד מהבניינים שלנו מכיל שגיאות, גם אם הוא נטול טעויות. החלטנו את זה בעצמנו: כשאנחנו פורסים משהו, כשאנחנו מגלגלים משהו לייצור, יש לנו מבנה עם שגיאות. יצרנו את הדרישות שהמערכת שלנו חייבת לעמוד בהן.
דרישות לשינוי גרסת התוכנה
ישנן שלוש דרישות:

- אנחנו חייבים להחזיר במהירות את הפריסה.
- עלינו למזער את ההשפעה של פריסה לא מוצלחת.
- ועלינו להיות מסוגלים לפרוס במהירות במקביל.
בדיוק בסדר הזה! למה? מכיוון שקודם כל, בעת פריסת גרסה חדשה, המהירות אינה חשובה, אך חשוב לך, אם משהו משתבש, להתהפך במהירות ולהיות בעל השפעה מינימלית. אבל אם יש לך סט גרסאות בייצור, שמתברר שיש שגיאה (באופן כחול, לא הייתה פריסה, אבל יש שגיאה) - מהירות הפריסה הבאה חשובה לך. מה עשינו כדי לעמוד בדרישות הללו? נקטנו במתודולוגיה הבאה:
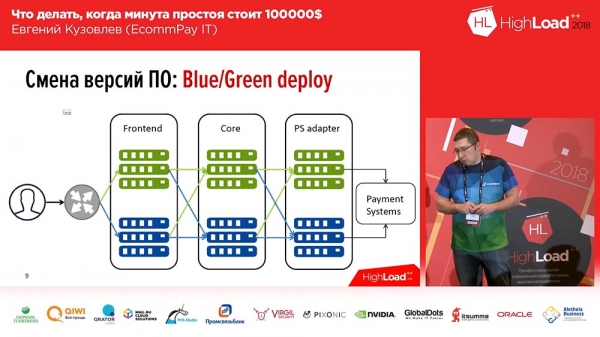
זה די ידוע, מעולם לא המצאנו את זה - זה פריסה כחול/ירוק. מה זה? עליך להיות בעל עותק עבור כל קבוצת שרתים שבהם האפליקציות שלך מותקנות. העותק "חם": אין עליו תנועה, אך בכל רגע ניתן לשלוח תנועה זו לעותק זה. עותק זה מכיל את הגרסה הקודמת. ובזמן הפריסה, אתה מגלגל את הקוד לעותק לא פעיל. לאחר מכן אתה מחליף חלק מהתנועה (או כולה) לגרסה החדשה. כך, כדי לשנות את זרימת התנועה מהגרסה הישנה לחדשה, צריך לעשות רק פעולה אחת: צריך לשנות את האיזון במעלה הזרם, לשנות את הכיוון - ממעלה הזרם אחד לאחר. זה מאוד נוח ופותר את בעיית ההחלפה המהירה והחזרה מהירה.כאן הפתרון לשאלה השנייה הוא מזעור: אתה יכול לשלוח רק חלק מהתנועה שלך לקו חדש, לקו עם קוד חדש (שיהיה, למשל, 2%). ו-2% אלה אינם 100%! אם איבדת 100% מהתנועה שלך בגלל פריסה לא מוצלחת, זה מפחיד; אם איבדת 2% מהתנועה שלך, זה לא נעים, אבל זה לא מפחיד. יתרה מכך, סביר להניח שמשתמשים אפילו לא ישימו לב לכך, מכיוון שבמקרים מסוימים (לא בכולם) אותו משתמש, בלחיצה על F5, יועבר לגרסה אחרת ועובדת.
פריסה כחול/ירוק. ניתוב
עם זאת, לא הכל כל כך פשוט "פריסה כחולה/ירוק"... ניתן לחלק את כל הרכיבים שלנו לשלוש קבוצות:
- זה החזית (דפי תשלום שהלקוחות שלנו רואים);
- ליבת עיבוד;
- מתאם לעבודה עם מערכות תשלום (בנקים, מאסטרקארד, ויזה...).
ויש כאן ניואנס - הניואנס טמון בניתוב בין השורות. אם רק תחליף 100% מהתנועה, אין לך את הבעיות האלה. אבל אם אתה רוצה להחליף 2%, אתה מתחיל לשאול שאלות: "איך לעשות את זה?" הדבר הפשוט ביותר הוא ישר קדימה: אתה יכול להגדיר את Round Robin ב-nginx בבחירה אקראית, ויש לך 2% לשמאל, 98% לימין. אבל זה לא תמיד מתאים.
לדוגמה, במקרה שלנו, משתמש מקיים אינטראקציה עם המערכת עם יותר מבקשה אחת. זה נורמלי: 2, 3, 4, 5 בקשות - ייתכן שהמערכות שלך זהות. ואם חשוב לך שכל בקשות המשתמש יגיעו לאותו קו בו הגיעה הבקשה הראשונה, או (נקודה שניה) כל בקשות המשתמש יגיעו לקו חדש לאחר המעבר (הוא היה יכול להתחיל לעבוד מוקדם יותר עם המערכת, לפני מיתוג), - אז ההתפלגות האקראית הזו לא מתאימה לך. לאחר מכן יש את האפשרויות הבאות:
האפשרות הראשונה, הפשוטה ביותר, מבוססת על הפרמטרים הבסיסיים של הלקוח (IP Hash). יש לך IP, ואתה מחלק אותו מימין לשמאל לפי כתובת IP. ואז המקרה השני שתיארתי יעבוד עבורך, כאשר התרחשה הפריסה, המשתמש כבר יכול היה להתחיל לעבוד עם המערכת שלך, ומרגע הפריסה כל הבקשות יעברו לשורה חדשה (לאותה אחת, נניח).אם מסיבה כלשהי זה לא מתאים לך ואתה חייב לשלוח בקשות לקו שבו הגיעה הבקשה הראשונית, הראשונית של המשתמש, אז יש לך שתי אפשרויות...
אפשרות ראשונה: אתה יכול לקנות nginx+ בתשלום. ישנו מנגנון Sticky sessions, אשר לפי בקשתו הראשונית של המשתמש, מקצה סשן למשתמש ומקשר אותו לאחד או אחר במעלה הזרם. כל בקשות המשתמש הבאות במהלך חיי ההפעלה יישלחו לאותו הזרם שבו ההפעלה פורסמה.זה לא התאים לנו כי כבר היה לנו nginx רגיל. המעבר ל-nginx+ זה לא שזה יקר, זה פשוט היה קצת כואב לנו ולא מאוד נכון. "Ssticks Sessions", למשל, לא עבדו עבורנו מהסיבה הפשוטה ש-Sticks Sessions לא מאפשרים ניתוב על בסיס "או-או". שם אתה יכול לציין מה אנחנו "Ssticks Sessions" עושים, למשל, לפי כתובת IP או לפי כתובת IP וקובצי Cookie או לפי postparameter, אבל "או-או" יותר מסובך שם.
לכן, הגענו לאפשרות הרביעית. לקחנו nginx על סטרואידים (זהו openresty) - זה אותו nginx, שתומך בנוסף בהכללה של סקריפטים אחרונים. אתה יכול לכתוב סקריפט אחרון, לתת לו "מנוחה פתוחה", וסקריפט אחרון זה יתבצע כאשר תגיע בקשת המשתמש.
וכתבנו, למעשה, תסריט כזה, הגדרנו לעצמנו "openresti" ובתסריט הזה אנחנו ממיינים 6 פרמטרים שונים לפי שרשור "אור". בהתאם לנוכחות של פרמטר כזה או אחר, אנו יודעים שהמשתמש הגיע לעמוד כזה או אחר, שורה כזו או אחרת.
פריסה כחול/ירוק. יתרונות וחסרונות
כמובן שאפשר היה לעשות את זה קצת יותר פשוט (תשתמשו באותם "Ssticky Sessions"), אבל יש לנו גם ניואנס כזה שלא רק המשתמש יוצר איתנו אינטראקציה במסגרת של עיבוד אחד של עסקה אחת... אבל גם מערכות התשלום מקיימות איתנו אינטראקציה: לאחר שאנו מעבדים את העסקה (באמצעות שליחת בקשה למערכת התשלומים), אנו מקבלים ציון חוזר.
ונניח, אם בתוך המעגל שלנו נוכל להעביר את כתובת ה-IP של המשתמש בכל הבקשות ולחלק את המשתמשים לפי כתובת ה-IP, אז לא נגיד את אותו "ויזה": "אחי, אנחנו כזו חברת רטרו, נראה לנו להיות בינלאומי (באתר וברוסיה)... אנא ספק לנו את כתובת ה-IP של המשתמש בשדה נוסף, הפרוטוקול שלך סטנדרטי”! ברור שהם לא יסכימו.
לכן זה לא עבד לנו - עשינו פתיחות. בהתאם, עם הניתוב קיבלנו משהו כזה:ל- Blue/Green Deployment יש, בהתאם, את היתרונות שציינתי ואת החסרונות.
שני חסרונות:
- אתה צריך לטרוח עם ניתוב;
- החיסרון העיקרי השני הוא ההוצאה.
אתה צריך פי שניים יותר שרתים, אתה צריך פי שניים משאבים תפעוליים, אתה צריך להשקיע פי שניים מאמץ כדי לתחזק את כל גן החיות הזה.
אגב, בין היתרונות יש עוד דבר שלא ציינתי קודם: יש לך רזרבה במקרה של גידול עומס. אם יש לך גידול נפיץ בעומס, יש לך מספר רב של משתמשים, אז אתה פשוט כולל את השורה השנייה בהפצה של 50 עד 50 - ומיד יש לך שרתי x2 באשכול שלך עד שתפתור את הבעיה של שרתים נוספים.
איך לבצע פריסה מהירה?
דיברנו על איך לפתור את בעיית המיזעור והחזרה מהירה, אבל נותרה השאלה: "איך לפרוס במהירות?"
זה קצר ופשוט כאן.- חייבת להיות לך מערכת CD (משלוח רציף) - אתה לא יכול לחיות בלעדיה. אם יש לך שרת אחד, אתה יכול לפרוס באופן ידני. יש לנו בערך אלף וחצי שרתים ואלף וחצי ידיות, כמובן - אנחנו יכולים לשתול מחלקה בגודל החדר הזה רק כדי לפרוס.
- הפריסה חייבת להיות מקבילה. אם הפריסה שלך היא ברצף, אז הכל רע. שרת אחד הוא רגיל, אתה תפרוס אלף וחצי שרתים כל היום.
- שוב, עבור האצה, זה כנראה כבר לא נחוץ. במהלך הפריסה, הפרויקט נבנה בדרך כלל. יש לך פרויקט אינטרנט, יש חלק חזיתי (עושים שם חבילת אינטרנט, קומפילים npm - משהו כזה), והתהליך הזה הוא, באופן עקרוני, קצר מועד - 5 דקות, אבל 5 הדקות האלה יכולות להיות ביקורתיים. לכן, למשל, אנחנו לא עושים את זה: הסרנו את 5 הדקות האלה, אנחנו פורסים חפצים.
מהו חפץ? חפץ הוא מבנה מורכב שבו כל חלקי ההרכבה כבר הושלמו. אנו מאחסנים את החפץ הזה באחסון החפצים. פעם השתמשנו בשני אחסון כאלה - זה היה Nexus ועכשיו jFrog Artifactory) בהתחלה השתמשנו ב-"Nexus" כי התחלנו לתרגל את הגישה הזו ביישומי Java (זה התאים לה היטב). ואז הם הכניסו לשם כמה מהיישומים שנכתבו ב-PHP; ו-"Nexus" כבר לא התאים, ולכן בחרנו ב-jFrog Artefactory, שיכולה לעצב כמעט הכל. הגענו אפילו לנקודה שבמאגר חפצים זה אנו מאחסנים חבילות בינאריות משלנו שאנו אוספים עבור שרתים.
גידול עומס נפץ
דיברנו על שינוי גרסת התוכנה. הדבר הבא שיש לנו הוא עלייה נפיצה בעומס. כאן, אני כנראה מתכוון בצמיחה נפיצה של העומס לא בדיוק הדבר הנכון...
כתבנו מערכת חדשה - היא מוכוונת שירות, אופנתית, יפה, עובדים בכל מקום, תורים בכל מקום, אסינכרוני בכל מקום. ובמערכות כאלה, נתונים יכולים לזרום דרך זרימות שונות. עבור העסקה הראשונה ניתן להשתמש בעובד 1, 3, 10, עבור העסקה השנייה - 2, 4, 5. והיום, נניח, בבוקר יש לך תזרים נתונים שמשתמש בשלושת העובדים הראשונים, ובערב זה משתנה באופן דרמטי, והכל משתמש בשלושת העובדים האחרים.
והנה מסתבר שאתה צריך איכשהו להגדיל את העובדים, אתה צריך איכשהו להגדיל את השירותים שלך, אבל במקביל למנוע נפיחות משאבים.
הגדרנו את הדרישות שלנו. הדרישות האלה די פשוטות: שיהיה גילוי שירות, פרמטריזציה - הכל סטנדרטי לבניית מערכות מדרגיות כאלה, פרט לנקודה אחת - פחת משאבים. אמרנו שאנחנו לא מוכנים להפחית משאבים כדי שהשרתים יחממו את האוויר. לקחנו את "קונסול", לקחנו את "נומד", שמנהלת את העובדים שלנו.מדוע זו בעיה עבורנו? בואו נחזור קצת אחורה. יש לנו כעת כ-70 מערכות תשלום מאחורינו. בבוקר, התנועה עוברת דרך Sberbank, ואז Sberbank נפל, למשל, ואנחנו מעבירים אותו למערכת תשלום אחרת. היו לנו 100 עובדים לפני Sberbank, ואחרי זה אנחנו צריכים להגדיל בחדות 100 עובדים עבור מערכת תשלום אחרת. ורצוי שכל זה יקרה ללא שיתוף אנושי. כי אם יש השתתפות אנושית, צריך לשבת שם מהנדס 24/7, שאמור לעשות רק את זה, כי כשלים כאלה, כש-70 מערכות מאחוריך, קורות באופן קבוע.
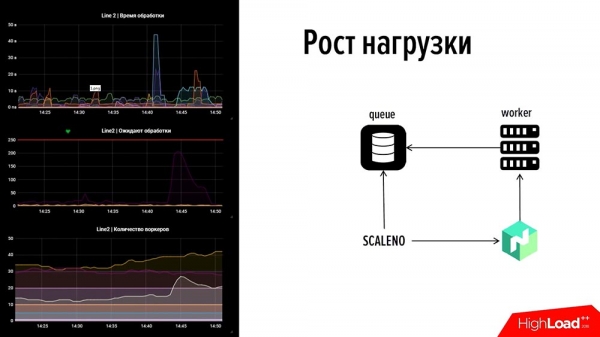
לכן, הסתכלנו על Nomad, שיש לה IP פתוח, וכתבנו דבר משלנו, Scale-Nomad - ScaleNo, שעושה בערך את הדברים הבאים: הוא עוקב אחר גדילת התור ומפחית או מגדיל את מספר העובדים בהתאם לדינמיקה של התור. כשעשינו את זה, חשבנו: "אולי נוכל לפתוח את זה בקוד?" אחר כך הביטו בה - היא הייתה פשוטה כמו שתי קופיקות.
עד כה לא פתחנו את זה בקוד פתוח, אבל אם פתאום אחרי הדיווח, אחרי שהבנת שאתה צריך דבר כזה, אתה צריך את זה, אנשי הקשר שלי נמצאים בשקף האחרון - נא לכתוב לי. אם יהיו לפחות 3-5 אנשים, אנחנו נתמוך בזה.
איך זה עובד? בואו להסתכל! במבט קדימה: בצד שמאל יש חלק מהניטור שלנו: זו שורה אחת, למעלה זמן עיבוד האירוע, באמצע מספר העסקאות, למטה מספר העובדים.אם תסתכל, יש תקלה בתמונה הזו. בגרף העליון אחד הגרפים קרס תוך 45 שניות - אחת ממערכות התשלום ירדה. מיד הוכנסה תנועה תוך 2 דקות והתור החל לגדול במערכת תשלומים אחרת, בה לא היו עובדים (לא ניצלנו משאבים - להיפך, השלכנו את המשאב בצורה נכונה). לא רצינו לחמם - היה מספר מינימלי, בערך 5-10 עובדים, אבל הם לא יכלו להתמודד.
הגרף האחרון מראה "גבנון", מה רק אומר ש"סקאלנו" הכפיל את הסכום הזה. ואז, כשהגרף ירד מעט, הוא הפחית אותו מעט - מספר העובדים השתנה אוטומטית. ככה הדבר הזה עובד. דיברנו על נקודה מספר 2 - "איך להיפטר במהירות מסיבות."
ניטור. איך לזהות במהירות את הבעיה?
כעת הנקודה הראשונה היא "כיצד לזהות במהירות את הבעיה?" ניטור! עלינו להבין דברים מסוימים במהירות. אילו דברים עלינו להבין במהירות?
שלושה דברים!- עלינו להבין ולהבין במהירות את הביצועים של המשאבים שלנו.
- עלינו להבין במהירות כשלים ולנטר את הביצועים של מערכות חיצוניות לנו.
- הנקודה השלישית היא זיהוי שגיאות לוגיות. זה כאשר המערכת עובדת בשבילך, הכל תקין לפי כל האינדיקטורים, אבל משהו משתבש.
אני כנראה לא אספר לך שום דבר כזה מגניב כאן. אני אהיה קפטן ברור. חיפשנו מה יש בשוק. יש לנו "גן חיות מהנה". זה סוג גן החיות שיש לנו עכשיו:
אנו משתמשים ב- Zabbix לניטור חומרה, לניטור האינדיקטורים העיקריים של שרתים. אנו משתמשים ב- Okmeter עבור מסדי נתונים. אנו משתמשים ב-"Grafana" ו-"Prometheus" עבור כל האינדיקטורים האחרים שאינם מתאימים לשני הראשונים, חלקם עם "Grafana" ו-"Prometheus", וחלקם עם "Grafana" עם "Influx" ו-Telegraf.לפני שנה רצינו להשתמש ב- New Relic. דבר מגניב, זה יכול לעשות הכל. אבל עד כמה שהיא יכולה לעשות הכל, היא כל כך יקרה. כשגדלנו לנפח של 1,5 אלף שרתים, הגיע אלינו ספק ואמר: "בואו נסגור הסכם לשנה הבאה". הסתכלנו על המחיר ואמרנו לא, אנחנו לא נעשה את זה. כעת אנו נוטשים את New Relic, נותרו לנו כ-15 שרתים תחת פיקוח של New Relic. המחיר התברר כפרוע לחלוטין.
ויש כלי אחד שיישמנו בעצמנו - זה Debugger. בהתחלה קראנו לזה "באגר", אבל אז עבר מורה לאנגלית, צחק בפראות ושינה את השם ל"Debagger". מה זה? זהו כלי שלמעשה תוך 15-30 שניות על כל רכיב, כמו "קופסה שחורה" של המערכת, מריץ בדיקות על הביצועים הכוללים של הרכיב.
למשל, אם יש דף חיצוני (דף תשלום), הוא פשוט פותח אותו ומסתכל איך הוא צריך להיראות. אם מדובר בעיבוד, הוא שולח "עסקה" בדיקה ומוודא שה"עסקה" הזו מגיעה. אם מדובר בחיבור למערכות תשלום, אנחנו מפטרים בקשת בדיקה בהתאם, איפה שאנחנו יכולים, ורואים שהכל בסדר אצלנו.
אילו אינדיקטורים חשובים לניטור?
על מה אנחנו עוקבים בעיקר? אילו מדדים חשובים לנו?
- זמן תגובה / RPS בחזיתות הוא אינדיקטור חשוב מאוד. הוא עונה מיד שמשהו לא בסדר איתך.
- מספר ההודעות המעובדות בכל התורים.
- מספר עובדים.
- מדדי נכונות בסיסיים.
הנקודה האחרונה היא מדד "עסקים", "עסקים". אם אתה רוצה לפקח על אותו הדבר, אתה צריך להגדיר מדד אחד או שניים שהם האינדיקטורים העיקריים עבורך. המדד שלנו הוא תפוקה (זהו היחס בין מספר העסקאות המוצלחות לתזרים העסקאות הכולל). אם משהו משתנה בו במרווח של 5-10-15 דקות, זה אומר שיש לנו בעיות (אם הוא משתנה באופן קיצוני).
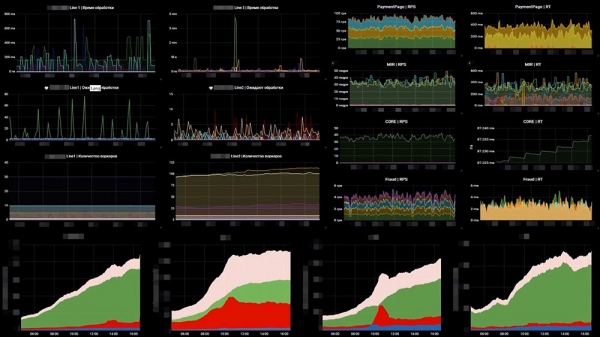
איך זה נראה עבורנו הוא דוגמה לאחד הלוחות שלנו:
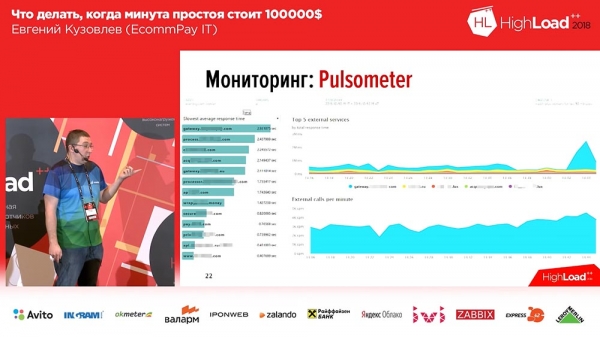
בצד שמאל יש 6 גרפים, זה לפי השורות - מספר העובדים ומספר ההודעות בתורים. בצד ימין - RPS, RTS. להלן אותו מדד "עסקי". ובמדד ה"עסקי" ניתן לראות מיד שמשהו השתבש בשני הגרפים האמצעיים... זו רק עוד מערכת שעומדת מאחורינו שנפלה.הדבר השני שהיינו צריכים לעשות הוא לעקוב אחר נפילת מערכות התשלומים החיצוניות. כאן לקחנו את OpenTracing - מנגנון, סטנדרטי, פרדיגמה המאפשרת להתחקות אחר מערכות מבוזרות; וזה השתנה מעט. פרדיגמת OpenTracing הסטנדרטית אומרת שאנו בונים מעקב לכל בקשה בודדת. לא היינו צריכים את זה, ועטפנו את זה בסיכום, עקבות צבירה. הכנו כלי שמאפשר לנו לעקוב אחר מהירות המערכות מאחורינו.
הגרף מראה לנו שאחת ממערכות התשלום החלה להגיב תוך 3 שניות - יש לנו בעיות. יתר על כן, הדבר הזה יגיב כאשר יתחילו בעיות, במרווח של 20-30 שניות.והסוג השלישי של שגיאות ניטור שקיים הוא ניטור לוגי.
למען האמת, לא ידעתי מה לצייר בשקופית הזו, כי חיפשנו הרבה זמן בשוק משהו שיתאים לנו. לא מצאנו כלום, אז נאלצנו לעשות זאת בעצמנו.
למה אני מתכוון בניטור לוגי? ובכן, תארו לעצמכם: אתם יוצרים לעצמכם מערכת (לדוגמה, שיבוט טינדר); עשית את זה, השקת את זה. המנהל המצליח ואסיה פוקקין שם את זה בטלפון שלו, רואה שם בחורה, מחבב אותה... וכדומה לא הולך לבחורה - כזה הולך למאבטח מיכליץ' מאותו מרכז עסקים. המנהל יורד למטה, ואז תוהה: "למה המאבטח הזה מיכליץ' מחייך אליו כל כך נעים?"במצבים כאלה... אצלנו המצב הזה נשמע קצת אחרת, כי (כתבתי) מדובר באובדן מוניטין שמוביל בעקיפין להפסדים כספיים. מצבנו הפוך: אנו עלולים לספוג הפסדים כספיים ישירים - למשל, אם ביצענו עסקה כמוצלחת, אך היא לא הצליחה (או להיפך). הייתי צריך לכתוב כלי משלי שעוקב אחר מספר העסקאות המוצלחות לאורך זמן באמצעות אינדיקטורים עסקיים. לא מצא שום דבר בשוק! זה בדיוק הרעיון שרציתי להעביר. אין שום דבר בשוק כדי לפתור בעיה מסוג זה.
זה היה על איך לזהות במהירות את הבעיה.
כיצד לקבוע את הסיבות לפריסה
קבוצת הבעיות השלישית שאנו פותרים היא לאחר שזיהינו את הבעיה, לאחר שנפטרנו ממנה, יהיה טוב להבין את הסיבה לפיתוח, לבדיקה ולעשות משהו בנידון. בהתאם, אנחנו צריכים לחקור, אנחנו צריכים להעלות את היומנים.
אם אנחנו מדברים על יומנים (הסיבה העיקרית היא יומנים), עיקר היומנים שלנו נמצאים ב-ELK Stack - כמעט לכולם יש אותו דבר. עבור חלק זה אולי לא ב-ELK, אבל אם תכתוב לוגים בג'יגה-בייט, אז במוקדם או במאוחר תגיע ל-ELK. אנחנו כותבים אותם בטרה-בייט.
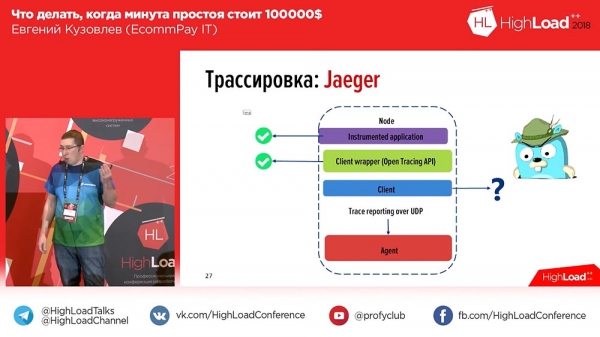
יש כאן בעיה. תיקנו את זה, תיקנו למשתמש את השגיאה, התחלנו לחפור מה יש שם, טיפסנו לקיבאנה, הכנסנו שם את מזהה העסקה וקיבלנו מטלית כזו (מראה הרבה). ושום דבר לא ברור בבד הזה. למה? כן, כי לא ברור איזה חלק שייך לאיזה עובד, איזה חלק שייך לאיזה רכיב. ובאותו רגע הבנו שאנחנו צריכים מעקב - אותו OpenTracing שדיברתי עליו.חשבנו את זה לפני שנה, הפנינו את תשומת הלב שלנו לשוק, והיו שם שני כלים - "זיפקין" ו"ייגר". "ג'אגר" הוא למעשה יורש אידיאולוגי כזה, יורש אידיאולוגי של "זיפקין". הכל טוב בזיפקין, חוץ מזה שהוא לא יודע לצבור, הוא לא יודע לכלול לוגים ב-trace, רק time trace. ו"ג'אגר" תמך בזה.
הסתכלנו על "Jager": אתה יכול מכשירי אפליקציות, אתה יכול לכתוב ב-Api (תקן ה-API ל-PHP באותה תקופה, לעומת זאת, לא אושר - זה היה לפני שנה, אבל עכשיו זה כבר אושר), אבל יש לא היה לקוח לחלוטין. "בסדר," חשבנו וכתבנו ללקוח משלנו. מה קיבלנו? ככה זה נראה בערך:
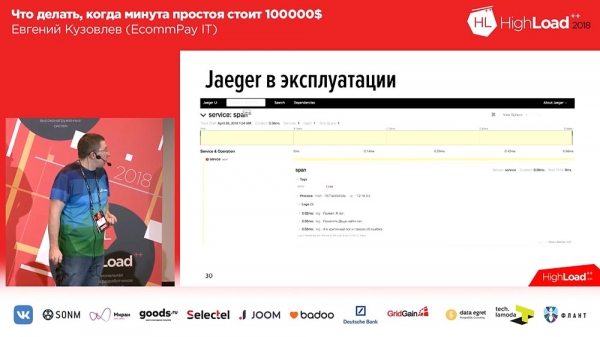
ב-Jaeger, טווחים נוצרים עבור כל הודעה. כלומר, כאשר משתמש פותח את המערכת, הוא רואה בלוק אחד או שניים לכל בקשה נכנסת (1-2-3 - מספר הבקשות הנכנסות מהמשתמש, מספר החסימות). כדי להקל על המשתמשים, הוספנו תגים ליומנים ולעקבות הזמן. בהתאם לכך, במקרה של שגיאה, האפליקציה שלנו תסמן את היומן בתג השגיאה המתאים. ניתן לסנן לפי תג שגיאה ורק טווחים המכילים בלוק זה עם שגיאה יוצגו. כך זה נראה אם נרחיב את הטווח:
בתוך הטווח יש קבוצה של עקבות. במקרה זה, אלו שלוש עקבות בדיקה, והעקיבה השלישית אומרת לנו שאירעה שגיאה. יחד עם זאת, כאן אנו רואים עקבות זמן: יש לנו סולם זמן בחלק העליון, ואנו רואים באיזה מרווח זמן יומן זה או אחר נרשם.בהתאם לכך, הלך לנו טוב. כתבנו הרחבה משלנו ורכשנו אותה בקוד פתוח. אם אתה רוצה לעבוד עם מעקב, אם אתה רוצה לעבוד עם "Jager" ב-PHP, יש את ההרחבה שלנו, מוזמן להשתמש, כמו שאומרים:
יש לנו את התוסף הזה - זה לקוח עבור OpenTracing Api, הוא עשוי כ-php-extension, כלומר, תצטרכו להרכיב אותו ולהתקין אותו במערכת. לפני שנה לא היה שום דבר שונה. עכשיו יש לקוחות אחרים שהם כמו רכיבים. כאן זה תלוי בך: או שאתה שואב את הרכיבים עם מלחין, או שאתה משתמש בהרחבה שתתאים לך.תקנים תאגידיים
דיברנו על שלושת הדיברות. הדיבר הרביעי הוא לתקן גישות. על מה זה? זה על זה:
מדוע המילה "תאגיד" נמצאת כאן? לא בגלל שאנחנו חברה גדולה או בירוקרטית, לא! רציתי להשתמש במילה "תאגיד" כאן בהקשר שלכל חברה, לכל מוצר צריך להיות סטנדרטים משלו, כולל לך. אילו סטנדרטים יש לנו?- יש לנו תקנות פריסה. אנחנו לא זזים לשום מקום בלעדיו, אנחנו לא יכולים. אנו פורסים כ-60 פעמים בשבוע, כלומר אנו פורסים כמעט כל הזמן. יחד עם זאת, יש לנו למשל בתקנות הפריסה טאבו על פריסות ביום שישי - עקרונית אנחנו לא פורסים.
- אנו דורשים תיעוד. אף רכיב חדש לא נכנס לייצור אם אין תיעוד עבורו, גם אם הוא נולד תחת העט של מומחי ה-RnD שלנו. אנחנו דורשים מהם הוראות פריסה, מפת ניטור ותיאור גס (טוב, כפי שמתכנתים יכולים לכתוב) של איך הרכיב הזה עובד, איך לפתור את הבעיות שלו.
- אנחנו פותרים לא את הסיבה לבעיה, אלא את הבעיה - מה שכבר אמרתי. חשוב לנו להגן על המשתמש מפני בעיות.
- יש לנו אישורים. לדוגמה, אנחנו לא מחשיבים את זה כזמן השבתה אם איבדנו 2% מהתנועה בתוך שתי דקות. זה בעצם לא נכלל בסטטיסטיקה שלנו. אם זה יותר באחוזים או זמני, אנחנו כבר סופרים.
- ואנחנו תמיד כותבים נתחים שלאחר המוות. לא משנה מה יקרה לנו, כל מצב שבו מישהו התנהג בצורה חריגה בהפקה יבוא לידי ביטוי בנתיחה שלאחר המוות. נתיחה שלאחר המוות היא מסמך בו אתה כותב מה קרה לך, עיתוי מפורט, מה עשית כדי לתקן אותו ו(זו חסימה חובה!) מה תעשה כדי שזה לא יקרה בעתיד. זה חובה והכרחי לניתוח הבא.
מה נחשב זמן השבתה?
למה כל זה הוביל?זה הוביל לעובדה ש(היו לנו בעיות מסוימות ביציבות, זה לא התאים לא ללקוחות ולא לנו) במהלך 6 החודשים האחרונים אינדיקטור היציבות שלנו היה 99,97. אנחנו יכולים לומר שזה לא הרבה. כן, יש לנו למה לשאוף. מתוך האינדיקטור הזה, כמחצית היא היציבות, כביכול, לא שלנו, אלא של חומת האש של יישומי האינטרנט שלנו, שעומדת מולנו ומשמשת כשירות, אבל ללקוחות זה לא אכפת.
למדנו לישון בלילה. סוף כל סוף! לפני שישה חודשים לא יכולנו. ועל הערה זו עם התוצאות, ברצוני להעיר הערה אחת. אתמול בערב היה דיווח נפלא על מערכת הבקרה של כור גרעיני. אם האנשים שכתבו את המערכת הזו יכולים לשמוע אותי, נא לשכוח ממה שאמרתי לגבי "2% זה לא השבתה." עבורך, 2% הם זמן השבתה, גם אם לשתי דקות!
זה הכל! השאלות שלך.
על מאזנים והגירת מסדי נתונים
שאלה מהקהל (להלן – ב): – ערב טוב. תודה רבה על דוח מנהל כזה! שאלה קצרה על האיזונים שלך. ציינת שיש לך WAF, כלומר, לפי הבנתי אתה משתמש באיזה איזשהו איזון חיצוני...
EK: - לא, אנו משתמשים בשירותים שלנו כמאזן. במקרה זה, WAF הוא אך ורק כלי הגנת DDoS עבורנו.
בתוך: – אתה יכול לומר כמה מילים על מאזנים?
EK: – כפי שכבר אמרתי, מדובר בקבוצת שרתים ב-openresty. יש לנו עכשיו 5 קבוצות מילואים שמגיבות באופן בלעדי... כלומר, שרת שמריץ אך ורק openresty, הוא מעביר רק תעבורה. בהתאם, כדי להבין כמה אנחנו מחזיקים: יש לנו כעת זרימת תנועה קבועה של כמה מאות מגה-ביט. הם מתמודדים, הם מרגישים טוב, הם אפילו לא מתאמצים.
בתוך: - גם שאלה פשוטה. הנה פריסת כחול/ירוק. מה אתה עושה, למשל, עם העברות של מסדי נתונים?
EK: - שאלה טובה! תראה, בפריסה כחול/ירוק יש לנו תורים נפרדים לכל שורה. כלומר, אם אנחנו מדברים על תורי אירועים שמועברים מעובד לעובד, יש תורים נפרדים לקו הכחול ולקו הירוק. אם אנחנו מדברים על מסד הנתונים עצמו, אז צמצמנו אותו בכוונה ככל שיכולנו, העברנו הכל כמעט לתורים; במסד הנתונים אנחנו מאחסנים רק ערימה של עסקאות. וערימת העסקאות שלנו זהה עבור כל הקווים. עם בסיס הנתונים בהקשר הזה: אנחנו לא מחלקים אותו לכחול וירוק, כי שתי הגרסאות של הקוד חייבות לדעת מה קורה עם העסקה.
חברים, יש לי גם פרס קטן לדרבן אתכם - ספר. ואני צריך לקבל את זה עבור השאלה הטובה ביותר.
בתוך: - שלום. תודה על הדיווח. השאלה היא זו. אתה עוקב אחר תשלומים, אתה עוקב אחר השירותים איתם אתה מתקשר... אבל איך עושים מעקב כך שאדם איכשהו הגיע לעמוד התשלום שלך, ביצע תשלום, והפרויקט זיכה אותו בכסף? כלומר, איך אתה מפקח שהמצעד זמין וקיבל את ההתקשרות חזרה שלך?
EK: – "סוחר" עבורנו במקרה זה הוא בדיוק אותו שירות חיצוני כמו מערכת התשלומים. אנו עוקבים אחר מהירות התגובה של הסוחר.
על הצפנת מסד נתונים
בתוך: - שלום. יש לי שאלה קצת קשורה. יש לך נתונים רגישים PCI DSS. רציתי לדעת איך אתה מאחסן PANs בתורים שאתה צריך להעביר אליהם? האם אתה משתמש בהצפנה כלשהי? וזה מוביל לשאלה השנייה: לפי PCI DSS יש צורך להצפין מחדש את בסיס הנתונים מדי פעם במקרה של שינויים (פיטורי מנהלים וכדומה) - מה קורה עם הנגישות במקרה זה?
EK: - שאלה נפלאה! ראשית, אנחנו לא מאחסנים PANs בתורים. אין לנו את הזכות לאחסן PAN בשום מקום בצורה ברורה, באופן עקרוני, אז אנחנו משתמשים בשירות מיוחד (אנחנו קוראים לזה "קדמון") - זה שירות שעושה רק דבר אחד: הוא מקבל הודעה כקלט ושולח להוציא הודעה מוצפנת. ואנחנו מאחסנים הכל עם ההודעה המוצפנת הזו. בהתאם לכך, אורך המפתח שלנו הוא מתחת לקילו-בייט, כך שזה רציני ואמין.בתוך: - האם אתה צריך 2 קילובייט עכשיו?
EK: – נראה כאילו רק אתמול זה היה 256... נו, איפה עוד?!
בהתאם לכך, זהו הראשון. ושנית, הפתרון שקיים, הוא תומך בהליך ההצפנה מחדש - ישנם שני זוגות של "קקס" (מפתחות), שנותנים "חפיסות" שמצפינות (מפתח הם המפתחות, דק הם נגזרות של המפתחות שמצפינים) . ואם ההליך מתחיל (זה קורה באופן קבוע, מ-3 חודשים עד ± כמה), אנחנו מורידים זוג חדש של "עוגות", ומצפינים מחדש את הנתונים. יש לנו שירותים נפרדים שקורעים את כל הנתונים ומצפינים אותם בצורה חדשה; הנתונים מאוחסנים ליד המזהה של המפתח איתו הם מוצפנים. בהתאם לכך, ברגע שאנו מצפינים את הנתונים במפתחות חדשים, אנו מוחקים את המפתח הישן.
לפעמים תשלומים צריכים להתבצע באופן ידני...
בתוך: – כלומר, אם הגיע החזר עבור פעולה כלשהי, האם עדיין תפענח אותו עם המפתח הישן?
EK: - כן.
בתוך: - ואז עוד שאלה קטנה. כאשר מתרחש כשל, נפילה או תקרית כלשהי, יש צורך לדחוף את העסקה באופן ידני. יש מצב כזה.
EK: - כן לפעמים.
בתוך: - מאיפה אתה מביא את הנתונים האלה? או שאתה הולך למתקן האחסון הזה בעצמך?
EK: - לא, ובכן, כמובן, יש לנו איזושהי מערכת Back Office שמכילה ממשק לתמיכה שלנו. אם איננו יודעים באיזה מצב נמצאת העסקה (למשל עד שמערכת התשלומים הגיבה בפסק זמן), איננו יודעים אפריורית, כלומר, אנו מקנים את הסטטוס הסופי רק בביטחון מלא. במקרה זה, אנו מקצים את העסקה לסטטוס מיוחד לעיבוד ידני. בבוקר, למחרת, ברגע שהתמיכה מקבלת מידע שנשארות עסקאות כאלה ואחרות במערכת התשלומים, הם מעבדים אותן באופן ידני בממשק הזה.
בתוך: - יש לי כמה שאלות. אחד מהם הוא המשך אזור PCI DSS: איך רושמים את המעגל שלהם? השאלה הזו היא בגלל שהמפתח יכול היה לשים כל דבר ביומנים! שאלה שנייה: איך מוציאים תיקונים חמים? שימוש ב-handles במסד הנתונים הוא אפשרות אחת, אבל ייתכנו תיקונים חמים בחינם - מה הפרוצדורה שם? והשאלה השלישית קשורה כנראה ל-RTO, RPO. הזמינות שלך הייתה 99,97, כמעט ארבע תשע, אבל לפי הבנתי, יש לך מרכז נתונים שני, מרכז נתונים שלישי ומרכז נתונים חמישי... איך מסנכרנים אותם, משכפלים אותם וכל השאר?EK: - נתחיל עם הראשון. השאלה הראשונה הייתה על יומנים? כשאנחנו כותבים יומנים, יש לנו שכבה שמסווה את כל הנתונים הרגישים. היא מביטה במסכה ובשדות הנוספים. בהתאם לכך, היומנים שלנו יוצאים עם נתונים מכוסים כבר ומעגל PCI DSS. זוהי אחת המשימות הקבועות המוטלות על מחלקת הבדיקות. הם נדרשים לבדוק כל משימה, כולל היומנים שהם כותבים, וזו אחת המשימות הקבועות במהלך ביקורות קוד, על מנת לשלוט שהמפתח לא רשם משהו. בדיקות עוקבות לכך מתבצעות באופן שוטף על ידי מחלקת אבטחת המידע בערך אחת לשבוע: יומנים ליום האחרון נלקחים באופן סלקטיבי והם מופעלים באמצעות סורק-אנליזר מיוחד משרתי בדיקה לבדיקת הכל.
לגבי תיקונים חמים. זה כלול בתקנות הפריסה שלנו. יש לנו סעיף נפרד לגבי תיקונים חמים. אנו מאמינים שאנו פורסים תיקונים חמים מסביב לשעון כאשר אנו זקוקים לכך. ברגע שהגרסה מורכבת, ברגע שהיא מופעלת, ברגע שיש לנו חפץ, יש לנו מנהל מערכת תורן בקריאה מתמיכה, והוא פורס אותה ברגע שצריך.בערך "ארבע תשע". הנתון שיש לנו עכשיו באמת הושג, ושאפנו אליו במרכז נתונים אחר. עכשיו יש לנו מרכז נתונים שני, ואנחנו מתחילים לנתב ביניהם, והנושא של שכפול בין מרכז נתונים הוא באמת שאלה לא טריוויאלית. ניסינו לפתור את זה בבת אחת באמצעים שונים: ניסינו להשתמש באותה "טרנטולה" - זה לא הסתדר לנו, אני אגיד לך מיד. לכן בסופו של דבר הזמנו את ה"סנס" באופן ידני. למעשה, כל אפליקציה במערכת שלנו מפעילה את הסנכרון הדרוש "שינוי - בוצע" בין מרכזי הנתונים באופן אסינכרוני.
בתוך: - אם קיבלת שני, למה לא קיבלת שלישי? כי לאף אחד אין עדיין מוח מפוצל...
EK: - אבל אין לנו מוח מפוצל. בשל העובדה שכל אפליקציה מונעת על ידי מולטימאסטר, לא משנה לנו לאיזה מרכז הגיעה הבקשה. אנחנו מוכנים לעובדה שאם אחד ממרכזי הנתונים שלנו ייכשל (אנחנו מסתמכים על זה) ובאמצע בקשת משתמש עובר למרכז הנתונים השני, אנחנו מוכנים לאבד את המשתמש הזה, אכן; אבל אלו יהיו יחידות, יחידות מוחלטות.
בתוך: - ערב טוב. תודה על הדיווח. דיברת על מאתר הבאגים שלך, שמפעיל כמה עסקאות בדיקה בייצור. אבל ספר לנו על עסקאות בדיקה! כמה עמוק זה מגיע?
EK: - הוא עובר את המחזור המלא של כל הרכיב. לגבי רכיב, אין הבדל בין עסקת בדיקה לעסקת ייצור. אבל מנקודת מבט הגיונית, זה פשוט פרויקט נפרד במערכת, שבו מתנהלות רק עסקאות בדיקה.
בתוך: -איפה חותכים את זה? הנה Core שלח...
EK: – אנחנו עומדים מאחורי "Kor" במקרה הזה לעסקאות בדיקה... יש לנו דבר כזה ניתוב: "Kor" יודע לאיזו מערכת תשלום לשלוח - אנחנו שולחים למערכת תשלום מזויפת, שפשוט נותנת אות http ו זה הכל.
בתוך: – תגיד לי, בבקשה, האם האפליקציה שלך נכתבה במונוליט ענק אחד, או שחתכת אותה לשירותים מסוימים או אפילו למיקרו-שירותים?
EK: - אין לנו מונוליט, כמובן, יש לנו אפליקציה מוכוונת שירות. אנחנו מתבדחים שהשירות שלנו עשוי ממונוליטים - הם באמת די גדולים. קשה לקרוא לזה microservices, אבל אלו שירותים שבתוכם פועלים עובדים של מכונות מבוזרות.
אם השירות בשרת נפגע...
בתוך: - אז יש לי את השאלה הבאה. גם אם זה היה מונוליט, עדיין אמרת שיש לך הרבה מהשרתים המיידיים האלה, כולם בעצם מעבדים נתונים, והשאלה היא: "במקרה של פשרה של אחד מהשרתים המיידיים או אפליקציה, כל קישור בודד , האם יש להם סוג של בקרת גישה? מי מהם יכול לעשות מה? למי עלי לפנות לאיזה מידע?
EK: - כן בהחלט. דרישות האבטחה חמורות למדי. ראשית, יש לנו תנועות נתונים פתוחות, והיציאות הן רק אלו שדרכן אנו צופים מראש תנועת תנועה. אם רכיב מתקשר עם מסד הנתונים (נניח, עם Muskul) דרך 5-4-3-2, רק 5-4-3-2 יהיה פתוח אליו, ויציאות אחרות וכיווני תנועה אחרים לא יהיו זמינים. בנוסף, עליכם להבין שבייצור שלנו יש כ-10 לולאות אבטחה שונות. וגם אם האפליקציה נפגעה איכשהו, חלילה, התוקף לא יוכל לגשת לקונסולת ניהול השרת, כי מדובר באזור אבטחת רשת אחר.בתוך: – ובהקשר הזה, מה שיותר מעניין אותי זה שיש לך חוזים מסוימים עם שירותים - מה הם יכולים לעשות, באמצעות אילו "פעולות" הם יכולים ליצור קשר אחד עם השני... ובזרימה רגילה, כמה שירותים ספציפיים מבקשים כמה שורה, רשימה של "פעולות" בצד השני. נראה שהם לא פונים לאחרים במצב רגיל, ויש להם תחומי אחריות אחרים. אם אחד מהם ייפגע, האם הוא יוכל לשבש את ה"פעולות" של אותו שירות?..
EK: - אני מבין. אם במצב רגיל עם שרת אחר הותרה תקשורת בכלל, אז כן. על פי חוזה ה-SLA, איננו מפקחים על כך שמותר לך רק 3 "פעולות" הראשונות, ואסור לך 4 "פעולות". זה כנראה מיותר עבורנו, כי יש לנו כבר מערכת הגנה בת 4 רמות, באופן עקרוני, למעגלים. אנחנו מעדיפים להגן על עצמנו עם קווי המתאר, ולא ברמת הפנים.
איך ויזה, מאסטרקארד ו-Sberbank פועלות
בתוך: – אני רוצה להבהיר נקודה לגבי מעבר משתמש ממרכז נתונים אחד לאחר. עד כמה שידוע לי, ויזה ומסטרקארד פועלות באמצעות פרוטוקול סינכרוני בינארי 8583, ויש שם מיקסים. ורציתי לדעת, עכשיו אנחנו מתכוונים למעבר - האם זה ישירות "ויזה" ו"מאסטרקארד" או לפני מערכות תשלום, לפני עיבוד?
EK: - זה לפני הערבובים. התערובות שלנו ממוקמות באותו מרכז נתונים.
בתוך: – באופן גס, יש לך נקודת חיבור אחת?
EK: – "ויזה" ו-"מאסטרקארד" - כן. פשוט כי ויזה ומאסטרקארד דורשות השקעות די רציניות בתשתיות כדי לסגור חוזים נפרדים להשגת זוג תערובות שני, למשל. הם שמורים בתוך דאטה סנטר אחד, אבל אם חלילה, הדטה סנטר שלנו, שבו יש תמהילים לחיבור לויזה ומאסטרקארד, ימות, אז יאבד לנו הקשר עם ויזה ומאסטרקארד...
בתוך: - איך אפשר לשמור אותם? אני יודע שוויזה מאפשרת רק חיבור אחד באופן עקרוני!
EK: - הם מספקים את הציוד בעצמם. בכל מקרה קיבלנו ציוד מיותר בפנים.
בתוך: – אז הדוכן הוא מה-Connects Orange שלהם?..
EK: - כן.
בתוך: - אבל מה לגבי המקרה הזה: אם מרכז הנתונים שלך ייעלם, איך אתה יכול להמשיך להשתמש בו? או שהתנועה פשוט נעצרת?
EK: - לא. במקרה כזה, פשוט נעביר את התעבורה לערוץ אחר, שמטבע הדברים יהיה יקר יותר עבורנו ויקר עבור לקוחותינו. אבל התנועה לא תעבור דרך החיבור הישיר שלנו לויזה, מאסטרקארד, אלא דרך Sberbank המותנה (מוגזם מאוד).
אני מתנצל בפראות אם פגעתי בעובדי סברבנק. אבל על פי הסטטיסטיקה שלנו, בקרב הבנקים הרוסיים, Sberbank נופל לרוב. לא עובר חודש בלי שמשהו נופל בסברבנק.

כמה מודעות 🙂
תודה שנשארת איתנו. האם אתה אוהב את המאמרים שלנו? רוצים לראות עוד תוכן מעניין? תמכו בנו על ידי ביצוע הזמנה או המלצה לחברים, , אנלוגי ייחודי של שרתים ברמת הכניסה, שהומצא על ידינו עבורכם: (זמין עם RAID1 ו-RAID10, עד 24 ליבות ועד 40GB DDR4).
Dell R730xd זול פי 2 במרכז הנתונים Equinix Tier IV באמסטרדם? רק כאן בהולנד! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - החל מ-$99! לקרוא על



















מקור: www.habr.com
