

אומרים שכל דבר בחיים שווה לנסות לפחות פעם אחת. ואם אתם רגילים לעבוד עם DBMSs יחסי, אז כדאי להכיר את NoSQL הלכה למעשה, קודם כל, לפחות לפיתוח כללי. כעת, בשל ההתפתחות המהירה של הטכנולוגיה הזו, יש הרבה דעות סותרות ודיונים סוערים בנושא זה, מה שמעורר במיוחד עניין.
אם תעמיקו במהות כל המחלוקות הללו, תוכלו לראות שהן מתעוררות עקב גישה שגויה. מי שמשתמש בבסיסי נתונים של NoSQL בדיוק היכן שהם צריכים הם מרוצים ומקבלים את כל היתרונות מהפתרון הזה. ונסיינים שמסתמכים על הטכנולוגיה הזו כתרופה פלא שבה היא לא ישימה בכלל מתאכזבים, לאחר שאיבדו את החוזקות של מסדי נתונים יחסיים מבלי להרוויח יתרונות משמעותיים.
אספר לכם על הניסיון שלנו בהטמעת פתרון המבוסס על Cassandra DBMS: מול מה נאלצנו להתמודד, איך יצאנו ממצבים קשים, האם הצלחנו להפיק תועלת משימוש ב-NoSQL והיכן היינו צריכים להשקיע מאמצים/כספים נוספים .
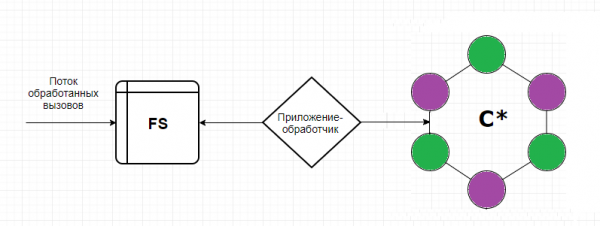
המשימה הראשונית היא לבנות מערכת שמתעדת שיחות באחסון כלשהו.
עקרון הפעולה של המערכת הוא כדלקמן. הקלט כולל קבצים בעלי מבנה ספציפי המתאר את מבנה השיחה. לאחר מכן, האפליקציה מבטיחה שהמבנה הזה מאוחסן בעמודות המתאימות. בעתיד, השיחות שנשמרו משמשות להצגת מידע על צריכת תעבורה למנויים (חיובים, שיחות, היסטוריית יתרות).
די ברור למה הם בחרו בקסנדרה - היא כותבת כמו מקלע, ניתנת להרחבה בקלות וסובלנית לתקלות.
אז זה מה שהניסיון נתן לנו
כן, צומת כושל אינו טרגדיה. זוהי המהות של סובלנות האשם של קסנדרה. אבל צומת יכול להיות חי ובו זמנית להתחיל לסבול בביצועים. כפי שהתברר, זה משפיע מיד על הביצועים של האשכול כולו.
קסנדרה לא תגן עליך במקום שבו אורקל הצילה אותך עם האילוצים שלה. ואם כותב האפליקציה לא הבין זאת מראש, אז הכפיל שהגיע לקסנדרה אינו גרוע מהמקור. ברגע שזה יגיע, נכניס אותו.
IB מאוד לא אהב את קסנדרה החינמית מחוץ לקופסה: אין רישום של פעולות משתמש, אין בידול של זכויות. מידע על שיחות נחשב לנתונים אישיים, מה שאומר שכל הניסיונות לבקש/לשנות אותו בכל דרך חייב להיות מתועד עם אפשרות לביקורת לאחר מכן. כמו כן, עליך להיות מודע לצורך להפריד זכויות ברמות שונות עבור משתמשים שונים. מהנדס תפעול פשוט וסופר אדמין שיכולים למחוק בחופשיות את כל מרחב המפתחות הם תפקידים שונים, תחומי אחריות ויכולות שונות. ללא בידול כזה של זכויות גישה, הערך והשלמות של הנתונים יבואו מיד בסימן שאלה מהר יותר מאשר עם כל רמת עקביות.
לא לקחנו בחשבון ששיחות דורשות גם ניתוח רציני וגם דגימה תקופתית עבור מגוון מצבים. מכיוון שהרשומות הנבחרות אמורות להימחק ולשכתב (כחלק מהמשימה, עלינו לתמוך בתהליך עדכון הנתונים כאשר הנתונים נכנסו ללולאה שלנו בהתחלה בצורה שגויה), קסנדרה אינה חברה שלנו כאן. קסנדרה היא כמו קופת חזירים - זה נוח להכניס דברים, אבל אתה לא יכול לספור בו.
נתקלנו בבעיה בהעברת נתונים לאזורי בדיקה (5 צמתים במבחן מול 20 בנשף). במקרה זה, לא ניתן להשתמש במזבלה.
הבעיה בעדכון סכימת הנתונים של אפליקציה שכותבת לקסנדרה. החזרה לאחור תיצור הרבה מאוד מצבות, מה שעלול להוביל לאובדן תפוקה בדרכים בלתי צפויות.. קסנדרה מותאמת להקלטה, ולא חושבת הרבה לפני הכתיבה.כל פעולה עם נתונים קיימים בה היא גם הקלטה. כלומר, על ידי מחיקת המיותר פשוט נפיק עוד יותר תקליטים ורק חלק מהם יסומנו במצבות.
זמן קצוב בעת הכנסה. קסנדרה יפה בהקלטה, אבל לפעמים הזרם הנכנס יכול להפתיע אותה באופן משמעותי. זה קורה כאשר האפליקציה מתחילה להסתובב בכמה רשומות שלא ניתן להכניס מסיבה כלשהי. ונצטרך DBA אמיתי שיפקח על gc.log, מערכת ויומני ניפוי באגים עבור שאילתות איטיות, מדדים על דחיסה בהמתנה.
מספר מרכזי נתונים באשכול. מאיפה לקרוא ואיפה לכתוב?
אולי התפצל לקריאה וכתיבה? ואם כן, האם צריך להיות DC קרוב יותר לאפליקציה לכתיבה או קריאה? והאם לא נגמור עם מוח מפוצל אמיתי אם נבחר ברמת העקביות הלא נכונה? יש הרבה שאלות, הרבה הגדרות לא ידועות, אפשרויות שאתה באמת רוצה להתעסק איתן.
איך החלטנו
כדי למנוע מהצומת לשקוע, SWAP הושבת. ועכשיו, אם יש חוסר בזיכרון, הצומת צריך לרדת ולא ליצור הפסקות gc גדולות.
אז, אנחנו כבר לא מסתמכים על ההיגיון במסד הנתונים. מפתחי אפליקציות מאמנים את עצמם מחדש ומתחילים לנקוט באמצעי זהירות באופן אקטיבי בקוד שלהם. הפרדה ברורה אידיאלית בין אחסון ועיבוד נתונים.
רכשנו תמיכה מ-DataStax. הפיתוח של קסנדרה המאוחסנת כבר נפסק (ההתחייבות האחרונה הייתה בפברואר 2018). יחד עם זאת, Datastax מציעה שירות מעולה ומספר רב של פתרונות מותאמים ומותאמים לפתרונות IP קיימים.
אני גם רוצה לציין שקסנדרה לא מאוד נוחה לשאילתות בחירה. כמובן, CQL הוא צעד גדול קדימה עבור המשתמשים (לעומת Trift). אבל אם יש לכם מחלקות שלמות שרגילות להצטרפות נוחות שכאלה, סינון חינמי לפי כל שדה ויכולות אופטימיזציה של שאילתות, והמחלקות הללו פועלות לפתור תלונות ותאונות, אז הפתרון בקסנדרה נראה להן עוין ומטופש. והתחלנו להחליט איך הקולגות שלנו צריכים לעשות דוגמאות.
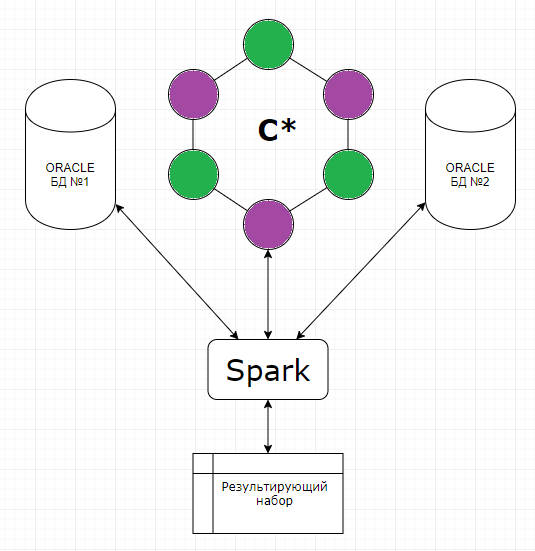
שקלנו שתי אפשרויות, באפשרות הראשונה אנו כותבים קריאות לא רק ב-C*, אלא גם במסד הנתונים הארכיון של Oracle. רק, בניגוד ל-C*, מסד נתונים זה מאחסן שיחות רק עבור החודש הנוכחי (עומק אחסון שיחות מספיק למקרי טעינה). כאן ראינו מיד את הבעיה הבאה: אם נכתוב באופן סינכרוני, אז נאבד את כל היתרונות של C* הקשורים להכנסה מהירה; אם נכתוב באופן אסינכרוני, אין ערובה לכך שכל הקריאות הדרושות נכנסו ל-Oracle בכלל. היה פלוס אחד, אבל אחד גדול: לתפעול נשאר אותו מפתח PL/SQL מוכר, כלומר אנו מיישמים למעשה את דפוס ה"חזית". אפשרות חלופית. אנו מיישמים מנגנון שפורק שיחות מ-C*, מושך כמה נתונים להעשרה מהטבלאות המתאימות ב-Oracle, מצטרף לדגימות המתקבלות ונותן לנו את התוצאה, שבה אנו משתמשים איכשהו (לחזור לאחור, לחזור, לנתח, להתפעל). חסרונות: התהליך די רב-שלבי, ובנוסף, אין ממשק לעובדי התפעול.
בסופו של דבר, הסתפקנו באפשרות השנייה. אפאצ'י ספארק שימש לדגימה מצנצנות שונות. מהות המנגנון צומצמה לקוד ג'אווה, אשר באמצעות המפתחות שצוינו (מנוי, זמן שיחה - מפתחות מדור), שולף נתונים מ-C*, כמו גם את הנתונים הדרושים להעשרה מכל מסד נתונים אחר. לאחר מכן הוא מצטרף אליהם בזיכרון שלו ומציג את התוצאה בטבלה המתקבלת. ציירנו פרצוף רשת מעל הניצוץ וזה יצא די שמיש.
בעת פתרון הבעיה של עדכון נתוני בדיקות תעשייתיות, שקלנו שוב כמה פתרונות. גם העברה דרך Sstloader וגם אפשרות לפצל את האשכול באזור הבדיקה לשני חלקים, שכל אחד מהם שייך לסירוגין לאותו אשכול עם המבצע, ובכך מופעל על ידו. בעת עדכון הבדיקה, תוכנן להחליף ביניהם: החלק שעבד בבדיקה מסולק ונכנס לייצור, והשני מתחיל לעבוד עם הנתונים בנפרד. עם זאת, לאחר שחשבנו שוב, הערכנו בצורה רציונלית יותר את הנתונים שכדאי להעביר, והבנו שהשיחות עצמן הן ישות לא עקבית לבדיקות, שנוצרה במהירות במידת הצורך, ושהנתונים הפרסומיים הם שאין להם ערך להעברה ל- מִבְחָן. ישנם מספר חפצי אחסון שכדאי להעביר, אבל אלה ממש כמה שולחנות, ולא כבדים במיוחד. לכן, אנחנו כפתרון, Spark שוב נחלץ לעזרה, בעזרתו כתבנו והתחלנו להשתמש באופן פעיל בסקריפט להעברת נתונים בין טבלאות, prom-test.
מדיניות הפריסה הנוכחית שלנו מאפשרת לנו לעבוד ללא חזרות. לפני הפרומו, יש ריצת מבחן חובה, שבה טעות לא כל כך יקרה. במקרה של כישלון, אתה תמיד יכול להוריד את מרחב התיק ולגלגל את כל הסכימה מההתחלה.
כדי להבטיח זמינות רציפה של קסנדרה, אתה צריך dba ולא רק אותו. כל מי שעובד עם האפליקציה חייב להבין היכן וכיצד להסתכל על המצב הנוכחי וכיצד לאבחן בעיות בזמן. לשם כך, אנו משתמשים באופן פעיל ב-DataStax OpsCenter (ניהול וניטור עומסי עבודה), מדדי מערכת Cassandra Driver (מספר פסקי הזמן לכתיבה ל-C*, מספר פסקי הזמן לקריאה מ-C*, זמן אחזור מקסימלי וכו'), עוקבים אחר הפעולה. של האפליקציה עצמה, בעבודה עם קסנדרה.
כשחשבנו על השאלה הקודמת, הבנו היכן עשוי להיות הסיכון העיקרי שלנו. אלו הם טפסי הצגת נתונים המציגים נתונים ממספר שאילתות עצמאיות לאחסון. כך נוכל לקבל מידע די לא עקבי. אבל הבעיה הזו תהיה רלוונטית באותה מידה אם נעבוד עם מרכז נתונים אחד בלבד. אז הדבר הסביר ביותר כאן הוא, כמובן, ליצור פונקציית אצווה לקריאת נתונים באפליקציה של צד שלישי, שתבטיח שהנתונים יתקבלו בפרק זמן בודד. לגבי החלוקה לקריאה ולכתיבה מבחינת ביצועים, כאן נעצר הסיכון שעם אובדן מסוים של קשר בין ה-DCs, נוכל להסתיים עם שני אשכולות שאינם עולים בקנה אחד עם זה.
כתוצאה מכך, לעת עתה נעצר ברמת העקביות לכתיבת EACH_QUORUM, לקריאה - LOCAL_QUORUM
רשמים ומסקנות קצרות
על מנת להעריך את הפתרון שנוצר מנקודת מבט של תמיכה תפעולית וסיכויים לפיתוח נוסף, החלטנו לחשוב היכן עוד ניתן ליישם פיתוח כזה.
מיד לאחר מכן, ניקוד נתונים עבור תוכניות כמו "שלם מתי שנוח" (אנחנו טוענים מידע ל-C*, חישוב באמצעות סקריפטים של Spark), התחשבנות בתביעות עם צבירה לפי אזור, אחסון תפקידים וחישוב זכויות גישה למשתמש על סמך התפקיד מַטרִיצָה.
כפי שניתן לראות, הרפרטואר רחב ומגוון. ואם נבחר במחנה התומכים/מתנגדים של NoSQL, אז נצטרף לתומכים, שכן קיבלנו את היתרונות שלנו, ובדיוק איפה שציפינו.
אפילו אפשרות Cassandra מחוץ לקופסה מאפשרת קנה מידה אופקי בזמן אמת, ופותרת ללא כאב את נושא הגדלת הנתונים במערכת. הצלחנו להעביר מנגנון בעל עומס גבוה מאוד לחישוב אגרגטים של שיחות למעגל נפרד, וגם להפריד בין סכימת היישום והלוגיקה, ולהיפטר מהפרקטיקה הרעה של כתיבת עבודות ואובייקטים מותאמים אישית במסד הנתונים עצמו. קיבלנו את ההזדמנות לבחור ולהגדיר, כדי להאיץ, על אילו DCs נבצע חישובים ועל אילו נרשום נתונים, ביטחנו את עצמנו מפני קריסות של שני צמתים בודדים ושל DC בכללותו.
החלת הארכיטקטורה שלנו על פרויקטים חדשים, וכבר שיש לי קצת ניסיון, אני רוצה לקחת בחשבון מיד את הניואנסים שתוארו לעיל, ולמנוע כמה טעויות, להחליק כמה פינות חדות שלא ניתן היה להימנע מהן בתחילה.
לדוגמה, עקוב אחר העדכונים של קסנדרה בזמןכי לא מעט מהבעיות שקיבלנו כבר היו ידועות ומתוקנות.
אל תשים גם את מסד הנתונים עצמו וגם את Spark על אותם צמתים (או חלקו בקפדנות בכמות השימוש המותר במשאבים), מכיוון ש-Spark יכול לאכול יותר OP מהצפוי, ונקבל במהירות בעיה מספר 1 מהרשימה שלנו.
שפר את הניטור והיכולת התפעולית בשלב בדיקת הפרויקט. תחילה, קחו בחשבון ככל האפשר את כל הצרכנים הפוטנציאליים של הפתרון שלנו, כי זה מה שמבנה מסד הנתונים יהיה תלוי בסופו של דבר.
סובב את המעגל המתקבל מספר פעמים לאופטימיזציה אפשרית. בחר אילו שדות ניתן לסידור. להבין אילו טבלאות נוספות עלינו לערוך על מנת לקחת בחשבון בצורה הנכונה והאופטימלית, ולאחר מכן לספק את המידע הנדרש לפי דרישה (למשל, בהנחה שאנו יכולים לאחסן את אותם נתונים בטבלאות שונות, תוך התחשבות בפירוקים שונים לפי קריטריונים שונים, נוכל לחסוך זמן מעבד באופן משמעותי עבור בקשות קריאה).
לא רע ספק מיידית לצירוף TTL וניקוי נתונים מיושנים.
בעת הורדת נתונים מקסנדרה הלוגיקה של האפליקציה צריכה לעבוד על עיקרון ה-FETCH, כך שלא כל השורות נטענות לזיכרון בבת אחת, אלא נבחרות באצווה.
רצוי לפני העברת הפרויקט לפתרון המתואר בדוק את סבילות התקלות של המערכת על ידי ביצוע סדרה של מבחני ריסוק, כגון אובדן נתונים במרכז נתונים אחד, שחזור נתונים פגומים במשך תקופה מסוימת, נשירת רשת בין מרכזי נתונים. בדיקות כאלה לא רק יאפשרו להעריך את היתרונות והחסרונות של הארכיטקטורה המוצעת, אלא גם יספקו תרגול חימום טוב למהנדסים שעורכים אותן, והמיומנות הנרכשת תהיה רחוקה מלהיות מיותרת אם ישוחזרו כשלים במערכת בייצור.
אם אנחנו עובדים עם מידע קריטי (כגון נתונים לחיוב, חישוב חוב מנויים), אז כדאי לשים לב גם לכלים שיפחיתו את הסיכונים הנובעים מתכונות ה-DBMS. לדוגמה, השתמש בכלי השירות nodesync (Datastax), לאחר שפיתח אסטרטגיה אופטימלית לשימוש בו לפי הסדר למען העקביות, אל תיצור עומס יתר על קסנדרה ולהשתמש בו רק עבור טבלאות מסוימות בתקופה מסוימת.
מה קורה לקסנדרה אחרי שישה חודשי חיים? באופן כללי, אין בעיות בלתי פתורות. כמו כן, לא אפשרנו תאונות חמורות או אובדן נתונים. כן, היינו צריכים לחשוב על פיצוי על כמה בעיות שלא הופיעו קודם לכן, אבל בסופו של דבר זה לא העיב מאוד על הפתרון האדריכלי שלנו. אם אתה רוצה ולא מפחד לנסות משהו חדש, ובו בזמן לא רוצה להתאכזב יותר מדי, אז תתכונן לעובדה ששום דבר אינו בחינם. תצטרכו להבין, להתעמק בתיעוד ולהרכיב את המגרפה האישית שלכם יותר מאשר בפתרון הישן, ושום תיאוריה לא תגיד לכם מראש איזו מגרפה מחכה לכם.
מקור: www.habr.com
