


TL; DR
- כדי להשיג צפיות גבוהה של קונטיינרים ומיקרו-שירותים, יומנים ומדדים ראשיים אינם מספיקים.
- להתאוששות מהירה יותר ולגמישות מוגברת, יישומים צריכים ליישם את עיקרון התצפית הגבוהה (HOP).
- ברמת האפליקציה, NOP דורש: רישום נכון, ניטור צמוד, בדיקות שפיות ומעקב אחר ביצועים/מעברים.
- השתמש בהמחאות כרכיב של NOR מוכנות בדיקה и livenessProbe קוברנט.
מהי תבנית בדיקת בריאות?
בעת תכנון אפליקציה קריטית למשימה וזמינה מאוד, חשוב מאוד לחשוב על היבט כזה כמו סובלנות לתקלות. אפליקציה נחשבת סובלנית לתקלות אם היא מתאוששת במהירות מכשל. אפליקציית ענן טיפוסית משתמשת בארכיטקטורת microservices - כאשר כל רכיב ממוקם בקונטיינר נפרד. וכדי לוודא שהאפליקציה ב-k8s זמינה מאוד כשאתה מעצב אשכול, אתה צריך לעקוב אחר דפוסים מסוימים. ביניהם יש את תבנית בדיקת הבריאות. זה מגדיר איך האפליקציה מתקשרת ל-k8s שהיא בריאה. זה לא רק מידע על האם הפוד פועל, אלא גם על האופן שבו הוא מקבל ומגיב לבקשות. ככל ש-Kubernetes יודע יותר על בריאות הפוד, כך הוא מקבל החלטות חכמות יותר לגבי ניתוב תנועה ואיזון עומסים. לפיכך, עיקרון High Observability מאפשר לאפליקציה להגיב לבקשות בזמן.
עקרון צפיות גבוה (HOP)
העיקרון של צפיות גבוהה הוא אחד מהם . בארכיטקטורת מיקרו-שירותים, לשירותים לא אכפת איך מעובדים את הבקשה שלהם (ובצדק), אבל מה שחשוב הוא איך הם מקבלים תגובות מהשירותים המקבלים. לדוגמה, כדי לאמת משתמש, קונטיינר אחד שולח בקשת HTTP לאחרת, מצפה לתגובה בפורמט מסוים - זה הכל. PythonJS יכול גם לעבד את הבקשה, ו-Python Flask יכול להגיב. מיכלים הם כמו קופסאות שחורות עם תוכן מוסתר זה לזה. עם זאת, עיקרון ה-NOP מחייב כל שירות לחשוף מספר נקודות קצה של API המציינים עד כמה הוא בריא, כמו גם את מוכנותו וסובלנות התקלות שלו. Kubernetes מבקש את האינדיקטורים האלה כדי לחשוב על השלבים הבאים לניתוב ואיזון עומסים.
יישום ענן מעוצב היטב רושם את האירועים העיקריים שלו באמצעות זרמי ה-I/O הסטנדרטיים STDERR ו-STDOUT. בהמשך מגיע שירות עזר, למשל filebeat, logstash או fluentd, אספקת יומנים למערכת ניטור מרכזית (למשל Prometheus) ומערכת איסוף יומנים (חבילת תוכנות ELK). התרשים שלהלן מראה כיצד אפליקציית ענן פועלת על פי דפוס מבחן הבריאות ועקרון התצפית הגבוהה.
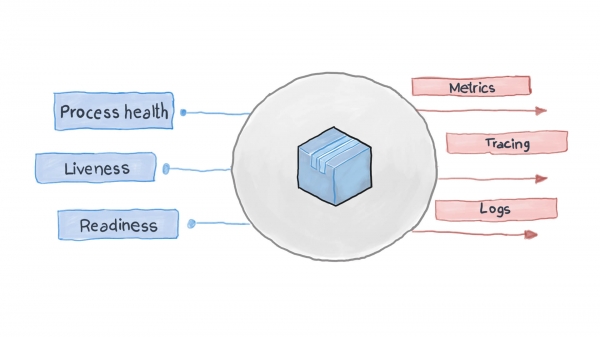
כיצד ליישם את דפוס בדיקת הבריאות ב-Kubernetes?
מחוץ לקופסה, k8s מנטר את מצב הפודים באמצעות אחד הבקרים (, , , וכו' וכו'). לאחר שגילה שהפוד נפל מסיבה כלשהי, הבקר מנסה להפעיל אותו מחדש או להעביר אותו לצומת אחר. עם זאת, פוד עשוי לדווח שהוא פועל, אך הוא עצמו אינו פועל. בוא ניתן דוגמה: האפליקציה שלך משתמשת ב- Apache כשרת אינטרנט, התקנת את הרכיב על מספר פודים של האשכול. מאחר שהספרייה הוגדרה בצורה שגויה, כל הבקשות לאפליקציה מגיבות בקוד 500 (שגיאת שרת פנימית). בבדיקת משלוח, בדיקת סטטוס הפודים נותנת תוצאה מוצלחת, אך הלקוחות חושבים אחרת. נתאר מצב לא רצוי זה באופן הבא:
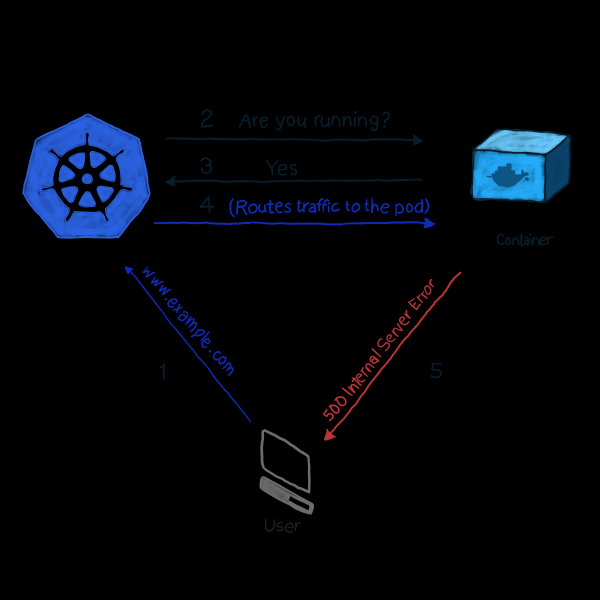
בדוגמה שלנו, k8s כן בדיקת פונקציונליות. בסוג זה של אימות, הקובלט בודק באופן רציף את מצב התהליך במיכל. ברגע שהוא יבין שהתהליך נעצר, הוא יתחיל אותו מחדש. אם ניתן לפתור את השגיאה פשוט על ידי הפעלה מחדש של היישום, והתוכנית מתוכננת לכבות על כל שגיאה, אז בדיקת תקינות התהליך היא כל מה שאתה צריך כדי לעקוב אחר ה-NOP ודפוס בדיקת הבריאות. החבל היחיד הוא שלא כל השגיאות נמחקות על ידי הפעלה מחדש. במקרה זה, k8s מציעה 2 דרכים עמוקות יותר לזהות בעיות עם הפוד: и .
LivenessProbe
במהלך livenessProbe kubelet מבצעת 3 סוגי בדיקות: לא רק קובעת אם הפוד פועל, אלא גם אם הוא מוכן לקבל ולהגיב כראוי לבקשות:
- הגדר בקשת HTTP לפוד. התגובה חייבת להכיל קוד תגובת HTTP בטווח שבין 200 ל-399. לפיכך, הקודים 5xx ו-4xx מאותתים כי הפוד נתקל בבעיות, למרות שהתהליך פועל.
- כדי לבדוק פודים עם שירותים שאינם HTTP (לדוגמה, שרת הדואר Postfix), עליך ליצור חיבור TCP.
- בצע פקודה שרירותית עבור תרמיל (פנימי). הבדיקה נחשבת מוצלחת אם קוד השלמת הפקודה הוא 0.
דוגמה לאיך זה עובד. הגדרת הפוד הבאה מכילה יישום NodeJS שזורק שגיאה 500 בבקשות HTTP. כדי לוודא שהמכל מופעל מחדש בעת קבלת שגיאה כזו, אנו משתמשים בפרמטר livenessProbe:
apiVersion: v1
kind: Pod
metadata:
name: node500
spec:
containers:
- image: magalix/node500
name: node500
ports:
- containerPort: 3000
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 5זה לא שונה מכל הגדרת תרמיל אחרת, אבל אנחנו מוסיפים אובייקט .spec.containers.livenessProbe... פָּרָמֶטֶר httpGet מקבל את הנתיב שאליו נשלחת בקשת ה-HTTP GET (בדוגמה שלנו זהו /, אבל בתרחישי לחימה יכול להיות משהו כמו /api/v1/status). עוד livenessProbe מקבל פרמטר initialDelaySeconds, המורה לפעולת האימות להמתין מספר שניות מוגדר. ההשהיה נחוצה מכיוון שהמכולה זקוק לזמן כדי להתחיל, ובעת הפעלה מחדש היא לא תהיה זמינה למשך זמן מה.
כדי להחיל הגדרה זו על אשכול, השתמש ב:
kubectl apply -f pod.yamlלאחר מספר שניות, תוכל לבדוק את תוכן הפוד באמצעות הפקודה הבאה:
kubectl describe pods node500בסוף הפלט, מצא .
כפי שאתה יכול לראות, livenessProbe יזם בקשת HTTP GET, הקונטיינר יצר שגיאה 500 (וזה מה שהוא תוכנת לעשות), וה-kubelet הפעיל אותו מחדש.
אם אתה תוהה כיצד תוכנת אפליקציית NideJS, הנה ה-app.js וה-Dockerfile שהיו בשימוש:
app.js
var http = require('http');
var server = http.createServer(function(req, res) {
res.writeHead(500, { "Content-type": "text/plain" });
res.end("We have run into an errorn");
});
server.listen(3000, function() {
console.log('Server is running at 3000')
})דוקרפיל
FROM node
COPY app.js /
EXPOSE 3000
ENTRYPOINT [ "node","/app.js" ]חשוב לציין זאת: livenessProbe יפעיל מחדש את המיכל רק אם הוא נכשל. אם הפעלה מחדש לא תתקן את השגיאה שמונעת מהמכולה לפעול, ה-kubelet לא יוכל לנקוט בפעולה לתיקון הבעיה.
מוכנות בדיקה
readinessProbe פועל בדומה ל-livenessProbes (בקשות GET, תקשורת TCP וביצוע פקודות), למעט פעולות לפתרון בעיות. המכולה שבה מזוהה הכשל אינו מופעל מחדש, אלא מבודד מתעבורה נכנסת. תארו לעצמכם שאחת מהמכולות מבצעת הרבה חישובים או נמצאת בעומס רב, מה שגורם לזמני התגובה לעלות. במקרה של livenessProbe, בדיקת זמינות התגובה מופעלת (באמצעות הפרמטר timeoutSeconds check), ולאחר מכן ה-kubelet מפעילה מחדש את המיכל. עם הפעלתו, המיכל מתחיל לבצע משימות עתירות משאבים ומופעל מחדש שוב. זה יכול להיות קריטי עבור יישומים שזקוקים למהירות תגובה. לדוגמא, רכב בנסיעה ממתין לתגובה מהשרת, התגובה מתעכבת - והמכונית נקלעת לתאונה.
בוא נכתוב הגדרת redinessProbe שתגדיר את זמן התגובה לבקשת GET ללא יותר משתי שניות, והאפליקציה תגיב לבקשת GET לאחר 5 שניות. הקובץ pod.yaml אמור להיראות כך:
apiVersion: v1
kind: Pod
metadata:
name: nodedelayed
spec:
containers:
- image: afakharany/node_delayed
name: nodedelayed
ports:
- containerPort: 3000
protocol: TCP
readinessProbe:
httpGet:
path: /
port: 3000
timeoutSeconds: 2בואו נפרוס פוד עם kubectl:
kubectl apply -f pod.yamlבוא נחכה כמה שניות ואז נראה איך ה-readinessProbe עבד:
kubectl describe pods nodedelayedבסוף הפלט ניתן לראות שחלק מהאירועים דומים .
כפי שאתה יכול לראות, kubectl לא הפעיל מחדש את הפוד כאשר זמן הבדיקה עבר 2 שניות. במקום זאת, הוא ביטל את הבקשה. תקשורת נכנסת מנותבת לתרמילים אחרים הפועלים.
שימו לב שכעת, כשהפוד מורחק, kubectl מנתב אליו שוב בקשות: תגובות לבקשות GET כבר לא מתעכבות.
לשם השוואה, להלן קובץ app.js שהשתנה:
var http = require('http');
var server = http.createServer(function(req, res) {
const sleep = (milliseconds) => {
return new Promise(resolve => setTimeout(resolve, milliseconds))
}
sleep(5000).then(() => {
res.writeHead(200, { "Content-type": "text/plain" });
res.end("Hellon");
})
});
server.listen(3000, function() {
console.log('Server is running at 3000')
})TL; DR
לפני הופעת יישומי ענן, יומנים היו האמצעי העיקרי לניטור ובדיקת תקינות האפליקציה. עם זאת, לא היה כל אמצעי לנקוט בפעולה מתקנת. יומנים עדיין שימושיים כיום; יש לאסוף אותם ולשלוח אותם למערכת איסוף יומנים לצורך ניתוח מצבי חירום וקבלת החלטות. [כל זה יכול להיעשות ללא אפליקציות ענן באמצעות monit, למשל, אבל עם k8s זה הפך להרבה יותר קל :) - הערת העורך. ]
כיום יש לבצע תיקונים כמעט בזמן אמת, כך שאפליקציות כבר לא חייבות להיות קופסאות שחורות. לא, עליהם להציג נקודות קצה המאפשרות למערכות ניטור לבצע שאילתות ולאסוף נתונים חשובים על מצב התהליכים כך שיוכלו להגיב באופן מיידי במידת הצורך. זה נקרא תבנית עיצוב מבחן הביצועים, העוקבת אחר עקרון התצפית הגבוהה (HOP).
Kubernetes מציעה 2 סוגים של בדיקות בריאות כברירת מחדל: readinessProbe ו-livenessProbe. שניהם משתמשים באותם סוגי בדיקות (בקשות HTTP GET, תקשורת TCP וביצוע פקודות). הם שונים באילו החלטות הם מקבלים בתגובה לבעיות בתרמילים. livenessProbe מפעיל מחדש את הקונטיינר בתקווה שהשגיאה לא תחזור על עצמה, ו-readinessProbe מבודדת את הפוד מתעבורה נכנסת עד לפתרון הגורם לבעיה.
תכנון נכון של יישום צריך לכלול את שני סוגי הבדיקות ולוודא שהם אוספים מספיק נתונים, במיוחד כאשר נזרק חריג. זה גם צריך להראות את נקודות הקצה הדרושות של API המספקות למערכת הניטור (Prometheus) מדדי בריאות חשובים.
מקור: www.habr.com
