

פרהיסטוריה
יש מכונות אוטומטיות בעיצוב שלנו. בפנים יש Raspberry Pi וקצת חיבורים על לוח נפרד. מקבל מטבעות, מקבל שטרות, מסוף בנק מחוברים... הכל נשלט על ידי תוכנה שנכתבה בעצמנו. כל היסטוריית העבודה נרשמת ביומן על גבי כונן הבזק (MicroSD), אשר מועבר לאחר מכן דרך האינטרנט (באמצעות מודם USB) לשרת, שם הוא מאוחסן במסד נתונים. מידע על מכירות נטען ל-1C, יש גם ממשק אינטרנט פשוט לניטור וכו'.
כלומר, היומן הוא בעל חשיבות חיונית - לחשבונאות (הכנסות, מכירות וכו'), לניטור (כל מיני כשלים ונסיבות כוח עליון אחרות); אפשר לומר שזה כל המידע שיש לנו על המכונה הזו.
בעיה
כונני פלאש מתגלים כלא אמינים. הם מתקלקלים בתדירות מעוררת קנאה. זה מוביל הן להשבתת מכונה והן (אם מסיבה כלשהי לא ניתן היה להעביר את היומן לאינטרנט) לאובדן נתונים.
זו לא החוויה הראשונה של שימוש בכונני הבזק, לפני כן היה פרויקט נוסף עם יותר ממאה מכשירים, שבו היומן אוחסן על כונני הבזק מסוג USB, היו גם בעיות אמינות, לפעמים מספר המכשירים הכושלים בחודש היה בעשרות. ניסינו כונני הבזק שונים, כולל כאלה ממותגים עם זיכרון SLC, וחלק מהדגמים אמינים יותר מאחרים, אך החלפת כונני ההבזק לא פתרה את הבעיה באופן קיצוני.
אזהרה! קריאה ארוכה! אם אינכם מעוניינים ב"למה", אלא רק ב"איך", אתם יכולים לעבור ישר ל מאמרים.
החלטה
הדבר הראשון שעולה בראש הוא לנטוש את ה-MicroSD, להתקין, למשל, SSD, ולאתחל ממנו. תיאורטית זה אפשרי, אולי, אבל יקר יחסית, ולא כל כך אמין (מתווסף מתאם USB-SATA; גם סטטיסטיקות הכשל עבור SSDs בתקציב נמוך אינן מעודדות).
גם כונן קשיח USB לא נראה כמו פתרון אטרקטיבי במיוחד.
לכן, הגענו לאפשרות הזו: להשאיר את האתחול מ-MicroSD, אבל להשתמש בהם במצב קריאה בלבד, ולאחסן את יומן העבודה (ומידע אחר ייחודי לחומרה מסוימת - מספר סידורי, כיול חיישנים וכו') במקום אחר.
נושא ה-FS לקריאה בלבד עבור Raspberry Pi כבר נחקר למעלה ולמטה, לא אתעכב על פרטי היישום במאמר זה. (אבל אם יהיה עניין, אולי אכתוב מאמר קצר בנושא)הנקודה היחידה שאני רוצה לציין היא שגם מניסיון אישי וגם מביקורות של אלו שכבר יישמו זאת, יש שיפור באמינות. כן, אי אפשר להיפטר לחלוטין מתקלות, אבל בהחלט ניתן להפחית משמעותית את תדירותן. והכרטיסים הופכים מאוחדים, מה שמפשט משמעותית את ההחלפה עבור אנשי השירות.
חומרה
לא היה ספק מיוחד לגבי בחירת סוג הזיכרון - NOR Flash.
טענות:
- חיבור פשוט (לרוב אפיק ה-SPI, שכבר יש לנו ניסיון בשימוש בו, כך שלא צפויות בעיות חומרה);
- מחיר מגוחך;
- פרוטוקול הפעלה סטנדרטי (היישום כבר נמצא בליבת המערכת) Linux, אם תרצו, תוכלו לקחת אחד של צד שלישי, שגם הוא קיים, או אפילו לכתוב משלכם, למרבה המזל, הכל פשוט);
- אמינות ומשאבים:
מגיליון נתונים טיפוסי: הנתונים מאוחסנים למשך 20 שנה, 100000 מחזורי מחיקה עבור כל בלוק;
ממקורות צד שלישי: BER נמוך במיוחד, לא משערים צורך בקודי תיקון שגיאות (חלק מהמאמרים שוקלים ECC כ-NOR, אבל בדרך כלל הם מתכוונים ל-MLC NOR, גם זה קורה).
בואו נעריך את הדרישות לנפח ולמשאבים.
אני רוצה לוודא שהנתונים נשמרים למשך מספר ימים. זה הכרחי כדי שבמקרה של בעיות חיבור, היסטוריית המכירות לא תאבד. נתמקד ב-5 ימים, עבור תקופה זו. (גם אם לוקחים בחשבון סופי שבוע וחגים) ניתן לפתור את הבעיה.
כרגע יש לנו כ-100kb של רשומות ליום (3-4 אלף רשומות), אבל נתון זה גדל בהדרגה - הפירוט עולה, אירועים חדשים מתווספים. בנוסף, לפעמים יש קפיצות נחשול (חיישן כלשהו מתחיל לשלוח ספאם עם תוצאות חיוביות שגויות, למשל). נחשב עבור 10 רשומות של 100 בייט - מגה-בייט ליום.
בסך הכל, יש 5MB של נתונים נקיים (דחוסים היטב). בנוסף לכך, (הערכה גסה) 1MB של נתוני שירות.
כלומר, אנחנו צריכים שבב של 8 מגה-בייט אם לא נשתמש בדחיסה, או 4 מגה-בייט אם כן. נתונים די ריאליים עבור סוג זיכרון זה.
באשר למשאב: אם נתכנן שהזיכרון ייכתב מחדש לחלוטין לא יותר מפעם אחת כל 5 ימים, אז במשך 10 שנות שירות נקבל פחות מאלף מחזורי כתיבה מחדש.
הרשו לי להזכיר לכם שהיצרן מבטיח מאה אלף.
קצת על NOR לעומת NAND
כיום, כמובן, זיכרון NAND פופולרי הרבה יותר, אבל לא הייתי משתמש בו לפרויקט הזה: NAND, בניגוד ל-NOR, דורש בהכרח שימוש בקודי תיקון שגיאות, טבלת בלוקים פגומים וכו', ולשבבי NAND יש בדרך כלל הרבה יותר פינים.
החסרונות של NOR כוללים:
- נפח קטן (ובהתאם, מחיר גבוה למגה-בייט);
- מהירות החלפה נמוכה (בעיקר בשל העובדה שנעשה שימוש בממשק טורי, בדרך כלל SPI או I2C);
- מחיקה איטית (בהתאם לגודל הבלוק, זה לוקח בין שברירי שנייה לכמה שניות).
נראה שאין שום דבר קריטי עבורנו, אז אנחנו ממשיכים.
אם אתם מעוניינים בפרטים, נבחר מעגל מיקרו (עם זאת, זה לא חיוני, ישנם אנלוגים רבים בשוק התואמים מבחינת פינים ומערכת פיקוד; גם אם נרצה להתקין מיקרו-מעגל מיצרן אחר ו/או אמצעי אחסון אחר, הכל יעבוד מבלי לשנות את הקוד).
אני משתמש בזה שמובנה בליבת המערכת Linux דרייבר, ב-Raspberry, הודות לתמיכה בשכבת עץ ההתקנים, הכל פשוט מאוד - עליך להכניס את השכבה המהודרת לקובץ /boot/overlays ולשנות מעט את /boot/config.txt.
דוגמה לקובץ dts
למען האמת, אני לא בטוח שזה כתוב בלי שגיאות, אבל זה עובד.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};ושורה נוספת בקובץ config.txt
dtoverlay=at25:spimaxfrequency=50000000אני אדלג על תיאור חיבור המיקרו-מעגל ל-Raspberry Pi. מצד אחד, אני לא מומחה באלקטרוניקה, מצד שני, הכל טריוויאלי אפילו בשבילי: למיקרו-מעגל יש רק 8 פינים, מתוכם אנחנו צריכים הארקה, חשמל, SPI (CS, SI, SO, SCK); הרמות תואמות לאלו של Raspberry Pi, אין צורך בחיזוק נוסף - פשוט חבר את 6 המגעים שצוינו.
הצהרת הבעיה
כרגיל, הגדרת הבעיה עוברת מספר איטרציות, ואני חושב שהגיע הזמן לעוד אחת. אז בואו נעצור, נאסוף את מה שכבר נכתב, ונבהיר את הפרטים שנותרו בצללים.
אז, החלטנו שהלוג יאוחסן ב-SPI NOR Flash.
מה זה NOR Flash למי שלא יודע?
זהו זיכרון לא נדיף שבעזרתו ניתן לבצע שלוש פעולות:
- קריאה:
הקריאה הנפוצה ביותר: אנו מעבירים את הכתובת וקוראים כמה בתים שאנו צריכים; - רשומה:
כתיבה לזיכרון NOR flash נראית כמו כתיבה רגילה, אבל יש לה ייחודיות אחת: אפשר לשנות רק 1 ל-0, ולא להיפך. לדוגמה, אם היה לנו 0x55 בתא זיכרון, אז לאחר כתיבת 0x0f אליו, 0x05 כבר יאוחסן שם. (ראה טבלה למטה); - לִמְחוֹק:
כמובן, עלינו להיות מסוגלים לבצע את הפעולה ההפוכה - לשנות מ-0 ל-1, לשם כך נועדה פעולת המחיקה. בניגוד לשתי הראשונות, היא פועלת לא על בתים, אלא על בלוקים (בלוק המחיקה המינימלי בשבב הנבחר הוא 4 KB). מחיקה הורסת את כל הבלוק וזו הדרך היחידה לשנות מ-0 ל-1. לכן, כאשר עובדים עם זיכרון פלאש, לעתים קרובות יש צורך ליישר מבני נתונים לגבול בלוק המחיקה.
כתיבה ל-NOR Flash:
נתונים בינאריים
היה
01010101
מוּקלָט
00001111
זה נעשה
00000101
היומן עצמו הוא רצף של רשומות באורך משתנה. רשומה אופיינית היא באורך של כ-30 בייטים (אם כי לפעמים הרשומות הן באורך של כמה קילובייטים). במקרה הזה אנחנו פשוט עובדים איתם כקבוצת בתים, אבל אם אתם מעוניינים, CBOR משמש בתוך הרשומות.
בנוסף ליומן, עלינו לאחסן מידע "הגדרה", גם מעודכן וגם לא: מזהה מכשיר, כיולי חיישנים, דגל "מכשיר מושבת זמנית" וכו'.
מידע זה הוא קבוצה של רשומות מפתח-ערך, המאוחסנות גם ב-CBOR. אין לנו הרבה מידע זה (כמה קילובייטים לכל היותר), והוא מתעדכן לעתים רחוקות.
בעתיד נקרא לזה הקשר.
אם אתם זוכרים איך התחיל המאמר הזה, חשוב מאוד להבטיח אחסון נתונים אמין, ואם אפשר, פעולה רציפה גם במקרה של תקלות חומרה/שחתת נתונים.
אילו מקורות בעיות ניתן לשקול?
- הפסקת חשמל במהלך פעולות כתיבה/מחיקה. זה מהקטגוריה של "אין הגנה מפני מוט ברזל".
מידע מ ב-stackexchange: כאשר מכבים את החשמל בזמן עבודה עם פלאש, גם מחיקה (מוגדרת ל-1) וגם כתיבה (מוגדרת ל-0) מובילות להתנהגות לא מוגדרת: ניתן לכתוב נתונים, לכתוב חלקית (נניח, העברנו 10 בתים/80 סיביות, אך הצלחנו לכתוב רק 45 סיביות), ייתכן גם שחלק מהסיביות יגיעו למצב "ביניים" (קריאה יכולה להניב 0 או 1); - שגיאות בזיכרון הפלאש עצמו.
BER, למרות שהוא נמוך מאוד, אינו יכול להיות שווה לאפס; - שגיאות אפיק
נתונים המועברים דרך SPI אינם מוגנים בשום צורה; שגיאות ביט בודדות ושגיאות סינכרון - אובדן או הוספה של ביט (מה שמוביל לעיוות נתונים מסיבי) עלולות להתרחש; - שגיאות/תקלות נוספות
שגיאות קוד, תקלות של רספברי, התערבות חייזרים...
ניסחתי את הדרישות שלדעתי יש לעמוד בהן כדי להבטיח אמינות:
- יש לכתוב רשומות לזיכרון הבזק באופן מיידי, כתיבה מאוחרת אינה נחשבת; - אם מתרחשת שגיאה, יש לאתר אותה ולעבד אותה מוקדם ככל האפשר; - על המערכת, אם אפשר, להתאושש משגיאות.
(דוגמה מהחיים ל"איך זה לא אמור להיות", שאני חושב שכולם נתקלו בה: לאחר אתחול חירום, מערכת הקבצים "שבורה" ומערכת ההפעלה לא מופעלת)
רעיונות, גישות, מחשבות
כשהתחלתי לחשוב על הבעיה הזו, עלו לי בראש כמה רעיונות, למשל:
- להשתמש בדחיסת נתונים;
- להשתמש במבני נתונים חכמים, כגון אחסון כותרות רשומות בנפרד מהרשומות עצמן, כך שאם יש שגיאה ברשומה אחת, ניתן יהיה לקרוא את השאר ללא בעיות;
- להשתמש בשדות סיביות כדי לשלוט בהשלמת הכתיבה כאשר החשמל כבוי;
- לאחסן סכומי בדיקה עבור הכל וכל אחד;
- להשתמש בצורה כלשהי של קידוד לתיקון שגיאות.
חלק מהרעיונות הללו נוצלו, חלקם ננטשו. בואו נעבור עליהם לפי הסדר.
דחיסת נתונים
האירועים עצמם שאנו רושמים ביומן הם די אחידים וניתנים לחזרה על עצמם ("זרקתי מטבע של 5 רובל", "לחצתי על כפתור השינוי",...). לכן, הדחיסה אמורה להיות יעילה למדי.
תקורת הדחיסה אינה משמעותית (המעבד שלנו די חזק, אפילו ל-Pi הראשון הייתה ליבה אחת בתדר של 700 מגה-הרץ, לדגמים הנוכחיים יש מספר ליבות בתדר של מעל גיגה-הרץ), מהירות ההחלפה עם האחסון נמוכה (כמה מגה-בייט לשנייה), גודל הרשומות קטן. באופן כללי, אם לדחיסה יש השפעה על הביצועים, היא תהיה חיובית בלבד. (בהחלט לא ביקורתי, רק מציין)בנוסף, אין לנו אחד משובץ אמיתי, אלא אחד רגיל. Linux — כך שהיישום לא אמור לדרוש מאמץ רב (מספיק רק לקשר את הספרייה ולהשתמש בכמה פונקציות ממנה).
נלקח קטע יומן ממכשיר פעיל (1.7 מגה-בייט, 70 אלף רשומות) ונבדק תחילה לדחיסות באמצעות התוכנות gzip, lz4, lzop, bzip2, xz, zstd הזמינות במחשב.
- gzip, xz, zstd הראו תוצאות דומות (40Kb).
הופתעתי שה-xz האופנתי הראה את עצמו כאן ברמה של gzip או zstd; - lzip עם הגדרות ברירת המחדל נתן תוצאות מעט גרועות יותר;
- lz4 ו-lzop לא הראו תוצאות טובות במיוחד (150Kb);
- bzip2 הראה תוצאות טובות באופן מפתייע (18Kb).
אז הנתונים נדחסים בצורה טובה מאוד.
אז (אם לא נמצא פגמים חמורים) תהיה דחיסה! פשוט כי יותר נתונים יתאימו לאותו כונן הבזק.
בואו נחשוב על החסרונות.
הבעיה הראשונה: כבר הסכמנו שכל רשומה צריכה לעבור מיד לזיכרון הפלאש. בדרך כלל, הארכאון אוסף נתונים מזרם הקלט עד שהוא מחליט שהגיע הזמן לכתוב לפלט. עלינו לקבל מיד בלוק נתונים דחוס ולשמור אותו בזיכרון לא נדיף.
אני רואה שלוש דרכים:
- דחיסת כל רשומה באמצעות דחיסת מילון במקום האלגוריתמים שנדונו לעיל.
זוהי אפשרות מעשית לחלוטין, אבל אני לא אוהב אותה. כדי להבטיח רמת דחיסה סבירה פחות או יותר, יש "לתפור" את המילון לנתונים ספציפיים; כל שינוי יגרום לירידה קטסטרופלית ברמת הדחיסה. כן, ניתן לפתור את הבעיה על ידי יצירת גרסה חדשה של המילון, אבל זה כאב ראש - נצטרך לאחסן את כל הגרסאות של המילון; בכל ערך נצטרך לציין באיזו גרסה של המילון הוא נדחס... - דחיסת כל רשומה באמצעות אלגוריתמים "קלאסיים", אך באופן עצמאי מאחרים.
אלגוריתמי הדחיסה הנשקלים אינם מיועדים לעבוד עם רשומות בגודל זה (עשרות בתים), יחס הדחיסה יהיה בבירור פחות מ-1 (כלומר, עלייה בנפח הנתונים במקום דחיסה); - בצע ניקוי לאחר כל ערך.
ספריות דחיסה רבות תומכות ב-FLUSH. זוהי פקודה (או פרמטר להליך הדחיסה), שעם קבלתה יוצר הארכיון זרם דחוס כך שעל בסיסה ניתן לשחזר כל נתונים לא דחוסים שכבר התקבלו. אנלוגי זהsyncבמערכות קבצים אוcommitב-sql.
מה שחשוב הוא שפעולות דחיסה עוקבות יוכלו להשתמש במילון שנצבר ויחס הדחיסה לא יסבול כמו בגרסה הקודמת.
אני חושב שזה ברור שבחרתי באפשרות השלישית, בואו נבחן אותה ביתר פירוט.
מצאתי את זה לגבי FLUSH ב-zlib.
עשיתי בדיקת ברך המבוססת על המאמר, לקחתי 70 אלף רשומות יומן ממכשיר אמיתי, עם גודל עמוד של 60 קילו-בייט. (נחזור לגודל העמוד בהמשך) קיבל:
נתונים גולמיים
דחיסה gzip -9 (ללא שטיפה)
zlib עם Z_PARTIAL_FLUSH
zlib עם Z_SYNC_FLUSH
נפח, קילו-בייט
1692
40
352
604
במבט ראשון, עלות ה-FLUSH גבוהה באופן מוגזם, אך למעשה יש לנו ברירה גרועה - או לא לדחוס כלל, או לדחוס (ובאופן יעיל למדי) עם FLUSH. אסור לנו לשכוח שיש לנו 70 אלף רשומות, היתירות שהוצגה על ידי Z_PARTIAL_FLUSH היא רק 4-5 בתים לכל רשומה. ויחס הדחיסה התברר ככמעט 5:1, וזו תוצאה מצוינת ביותר.
זה אולי נראה מפתיע, אבל Z_SYNC_FLUSH היא למעשה דרך יעילה יותר לבצע FLUSH
במקרה של שימוש ב-Z_SYNC_FLUSH, 4 הבייטים האחרונים של כל רשומה תמיד יהיו 0x00, 0x00, 0xff, 0xff. ואם אנחנו יודעים אותם, לא נוכל לאחסן אותם, כך שהגודל הסופי הוא רק 324 KB.
במאמר שקישרתי אליו יש הסבר:
נוסף בלוק חדש מסוג 0 עם תוכן ריק.
בלוק מסוג 0 עם תוכן ריק מורכב מ:
- כותרת הבלוק בת שלוש הסיביות;
- 0 עד 7 סיביות שוות לאפס, כדי להשיג יישור בתים;
- רצף ארבעת הבייטים 00 00 FF FF.
כפי שניתן לראות בקלות, בבלוק האחרון שלפני 4 הבייטים הללו יש בין 3 ל-10 אפס ביטים. עם זאת, בפועל יש למעשה לפחות 10 אפס ביטים.
מסתבר שבלוקים קצרים כאלה של נתונים בדרך כלל (תמיד?) מקודדים באמצעות בלוק מסוג 1 (בלוק קבוע), אשר בהכרח מסתיים ב-7 אפס ביטים, כך שנקבל 10-17 אפס ביטים מובטחים (והשאר יהיו אפס בהסתברות של כ-50%).
אז, בנתוני הבדיקה ב-100% מהמקרים לפני 0x00, 0x00, 0xff, 0xff יש בייט אחד של אפס, וביותר משליש מהמקרים יש שני בייט של אפס. (אולי הנקודה היא שאני משתמש ב-CBOR בינארי, ואם הייתי משתמש ב-JSON טקסטואלי, הייתי נתקל לעתים קרובות יותר בבלוקים מסוג 2 - בלוק דינמי, בהתאמה, הייתי נתקל בבלוקים ללא אפס בייטים נוספים לפני 0x00, 0x00, 0xff, 0xff).
בסך הכל, באמצעות נתוני הבדיקה הזמינים, ניתן להתאים פחות מ-250 KB של נתונים דחוסים.
אנחנו יכולים לחסוך עוד קצת על ידי ג'אגלינג בין ביטים: עכשיו אנחנו מתעלמים מנוכחותם של כמה ביטים אפס בסוף הבלוק, וגם כמה ביטים בתחילת הבלוק לא משתנים...
אבל כאן קיבלתי החלטה נחרצת להפסיק, אחרת בקצב הזה אני עלול בסופו של דבר לפתח ארכיבר משלי.
בסך הכל, קיבלתי 3-4 בייטים לכל רשומה מנתוני הבדיקה שלי, יחס הדחיסה היה יותר מ-6:1. למען האמת, לא ציפיתי לתוצאה כזו, לדעתי, כל דבר טוב יותר מ-2:1 הוא כבר תוצאה שמצדיקה את השימוש בדחיסה.
הכל נהדר, אבל zlib (deflate) הוא עדיין אלגוריתם דחיסה ארכאי, ראוי למדי ומיושן משהו. העובדה ש-32K האחרונים של זרם הנתונים הלא דחוס משמשים כמילון נראית מוזרה כיום (כלומר, אם בלוק נתונים כלשהו דומה מאוד למה שהיה בזרם הקלט לפני 40K, הוא יתחיל לאחסן בארכיון שוב, ולא יתייחס לערך הקודם). בארכיונים מודרניים ואופנתיים, גודל המילון נמדד לעתים קרובות במגה-בייט, ולא בקילובייט.
אז בואו נמשיך במחקר הקטן שלנו על מארכיונים.
לאחר מכן, ניסו את bzip2 (זכרו, בלי FLUSH הוא הראה יחס דחיסה פנטסטי, כמעט 100:1). למרבה הצער, עם FLUSH הוא הראה את עצמו בצורה גרועה מאוד, גודל הנתונים הדחוסים היה גדול יותר מזה הלא דחוס.
הניחושים שלי לגבי הסיבות לכישלון
Libbz2 מציעה רק אפשרות דחיסה אחת, שנראה כי היא מוחקת את המילון (בדומה ל-Z_FULL_FLUSH ב-zlib), כך שאין טעם לדבר על דחיסה יעילה כלשהי לאחר מכן.
והאחרון שנבדק היה zstd. בהתאם לפרמטרים, הוא דוחס או ברמה של gzip, אבל הרבה יותר מהר, או טוב יותר מ-gzip.
לרוע המזל, עם FLUSH זה גם הראה את עצמו כ"לא טוב במיוחד": גודל הנתונים הדחוסים היה כ-700 KB.
Я בדף הפרויקט ב-Github, קיבלתי את התשובה שכדאי לסמוך על עד 10 בתים של נתוני שירות עבור כל בלוק של נתונים דחוסים, וזה קרוב לתוצאות שהתקבלו, לא ניתן יהיה להדביק את הפער עם deflate.
בשלב זה החלטתי להפסיק להתנסות עם תוכנות ארכיון (הרשו לי להזכיר לכם ש-xz, lzip, lzo, lz4 עדיין לא הראו את עצמם בשלב הבדיקה ללא FLUSH, ולא שקלתי אלגוריתמי דחיסה אקזוטיים יותר).
בואו נחזור לבעיות של ארכיון.
הבעיה השנייה (כפי שאומרים לפי הסדר, לא לפי חשיבות) היא שנתונים דחוסים הם זרם יחיד, שבו מתבצעות כל הזמן הפניות לקטעים קודמים. לכן, אם קטע כלשהו של נתונים דחוסים ניזוק, אנו מאבדים לא רק את בלוק הנתונים הלא דחוס המשויך אליו, אלא גם את כל אלה הבאים.
ישנן גישות לפתרון בעיה זו:
- מנעו את התרחשות הבעיה - הוסיפו יתירות לנתונים הדחוסים כדי לאפשר זיהוי ותיקון של שגיאות; נדבר על כך בהמשך;
- מזער את ההשלכות אם מתרחשת בעיה
כבר אמרנו בעבר שאפשר לדחוס כל בלוק נתונים באופן עצמאי, והבעיה תיעלם מעצמה (השחתת נתונים של בלוק אחד תוביל לאובדן נתונים של בלוק זה בלבד). עם זאת, זהו מקרה קיצוני, שבו דחיסת נתונים לא תהיה יעילה. הקיצוניות ההפוכה: להשתמש בכל 4 מגה-בייט של השבב שלנו כארכיון יחיד, מה שיעניק לנו דחיסה מצוינת, אך השלכות קטסטרופליות במקרה של השחתת נתונים.
כן, נדרשת פשרה מבחינת אמינות. אבל עלינו לזכור שאנחנו מפתחים פורמט אחסון נתונים עבור זיכרון לא נדיף עם BER נמוך במיוחד וחיי אחסון נתונים מוצהרים של 20 שנה.
במהלך הניסויים גיליתי שאובדן מורגש יותר או פחות ברמת הדחיסה מתחיל עם בלוקים של נתונים דחוסים בגודל של פחות מ-10 KB.
הוזכר קודם לכן שהזיכרון שבו נעשה שימוש הוא דפדוף, אני לא רואה סיבה שלא תשתמש במיפוי "עמוד אחד - בלוק אחד של נתונים דחוסים".
כלומר, גודל הדף המינימלי הסביר הוא 16 קילו-בייט (עם שמור למידע שירות). עם זאת, גודל דף קטן שכזה מטיל מגבלות משמעותיות על גודל הרשומה המרבי.
למרות שאני לא מצפה שיהיו לי רשומות גדולות יותר מכמה קילובייטים בצורה דחוסה, החלטתי להשתמש ב-32K עמודים (מה שנותן לי 128 עמודים לכל שבב).
סיכום:
- אנו מאחסנים נתונים דחוסים באמצעות zlib (deflate);
- עבור כל ערך אנו מגדירים Z_SYNC_FLUSH;
- עבור כל רשומה דחוסה, אנו חותכים את הבייטים הנגררים (לדוגמה 0x00, 0x00, 0xff, 0xff)בכותרת אנו מציינים כמה בייטים חתכנו;
- אנו מאחסנים נתונים בדפים של 32 קילו-בייט; בתוך כל עמוד יש זרם יחיד של נתונים דחוסים; בכל עמוד אנו מתחילים דחיסה מחדש.
ולפני שנסיים עם הדחיסה, ברצוני להפנות את תשומת הלב לעובדה שאנו מקבלים רק כמה בייטים של נתונים דחוסים לכל רשומה, לכן חשוב ביותר לא לנפח את מידע השירות, כל בייט נחשב כאן.
אחסון כותרות נתונים
מכיוון שיש לנו רשומות באורך משתנה, עלינו לקבוע איכשהו את המיקום/גבולות הרשומות.
אני מכיר שלוש גישות:
- כל הרשומות מאוחסנות בזרם רציף, תחילה כותרת הרשומה המכילה את האורך, ולאחר מכן הרשומה עצמה.
בגרסה זו, גם הכותרות וגם הנתונים יכולים להיות באורך משתנה.
למעשה, אנו מקבלים רשימה מקושרת יחידה שנמצאת בשימוש כל הזמן; - כותרות ורשומות עצמן מאוחסנות בזרמים נפרדים.
על ידי שימוש בכותרות באורך קבוע, אנו מבטיחים שפגיעה בכותרת אחת לא תשפיע על האחרות.
גישה דומה משמשת, למשל, במערכות קבצים רבות; - רשומות מאוחסנות בזרם רציף, גבול הרשומה נקבע על ידי סמן כלשהו (סמל/רצף של סמלים האסורים בתוך בלוקי נתונים). אם נתקלים בסמן בתוך רשומה, אנו מחליפים אותו ברצף כלשהו (אנו בורחים ממנו).
גישה דומה משמשת, למשל, בפרוטוקול PPP.
הרשו לי להמחיש.
1 אפשרות:

כאן הכל פשוט מאוד: בידיעה של אורך הרשומה נוכל לחשב את הכתובת של הכותרת הבאה. לכן אנו עוברים בין הכותרות עד שאנו נתקלים באזור מלא ב-0xff (אזור פנוי) או בסוף העמוד.
2 אפשרות:

בגלל האורך המשתנה של הרשומה, איננו יכולים לומר מראש כמה רשומות (ולכן כותרות) נצטרך בכל עמוד. נוכל לפזר את הכותרות והנתונים עצמם על פני עמודים שונים, אך אני מעדיף גישה אחרת: אנו ממקמים גם את הכותרות וגם את הנתונים בעמוד אחד, אך הכותרות (בגודל קבוע) מתחילות מתחילת העמוד, והנתונים (באורך משתנה) מתחילים מהסוף. ברגע שהן "נפגשות" (אין מספיק מקום פנוי לרשומה חדשה), אנו רואים עמוד זה מלא.
3 אפשרות:

אין צורך לאחסן את האורך או מידע אחר על מיקום הנתונים בכותרת, סמנים המציינים את גבולות הרשומות מספיקים. עם זאת, יש לעבד את הנתונים בעת כתיבה/קריאה.
הייתי משתמש ב-0xff (שזה מה שהדף מתמלא בו לאחר המחיקה) כסמן, כך שהאזור הפנוי בהחלט לא יטופל כנתונים.
טבלת השוואה:
אפשרות 1
אפשרות 2
אפשרות 3
סבילות שגיאה
-
+
+
קומפקטיות
+
-
+
מורכבות היישום
*
**
**
לאפשרות 1 יש פגם חמור: אם אחת הכותרות ניזוקה, כל השרשרת הבאה נהרסת. האפשרויות האחרות מאפשרות לך לשחזר חלק מהנתונים גם במקרה של נזק עצום.
אבל כאן ראוי לזכור שהחלטנו לאחסן את הנתונים בצורה דחוסה, ובכל מקרה אנחנו מאבדים את כל הנתונים בדף אחרי רשומה "שבורה", כך שלמרות שיש מינוס בטבלה, אנחנו לא לוקחים אותו בחשבון.
צְפִיפוּת:
- באפשרות הראשונה אנחנו צריכים לאחסן רק את האורך בכותרת, אם נשתמש במספרים שלמים באורך משתנה, אז ברוב המקרים נוכל להסתדר עם בייט אחד;
- באפשרות השנייה עלינו לאחסן את כתובת ההתחלה ואת האורך; הרשומה חייבת להיות בגודל קבוע, אני מעריך 4 בתים לכל רשומה (שני בתים עבור ההיסט, ושני בתים עבור האורך);
- האפשרות השלישית דורשת רק תו אחד כדי לציין את תחילת ההקלטה, בנוסף ההקלטה עצמה תגדל ב-1-2% עקב ההקרנה. בסך הכל, היא בערך דומה לאפשרות הראשונה.
בהתחלה, שקלתי את האפשרות השנייה כעיקרית (ואפילו כתבתי מימוש). נטשתי אותה רק כשסוף סוף החלטתי להשתמש בדחיסה.
אולי יום אחד אשתמש באפשרות כזו. לדוגמה, אם אצטרך להתמודד עם אחסון נתונים עבור ספינה שנוסעת בין כדור הארץ למאדים - דרישות שונות לחלוטין לאמינות, קרינה קוסמית, ...
לגבי האפשרות השלישית: נתתי לה שני כוכבים על מורכבות המימוש פשוט כי אני לא אוהב להתעסק עם קוד בריחה, שינוי האורך בתהליך וכו'. כן, אולי אני משוחד, אבל אצטרך לכתוב את הקוד - למה לאלץ את עצמי לעשות משהו שאני לא אוהב.
סיכום: אנו בוחרים באפשרות האחסון בצורה של שרשראות "כותרת עם אורך - נתוני אורך משתנה" בשל יעילותה וקלות היישום שלה.
שימוש בשדות סיביות כדי לנטר את הצלחת פעולות הכתיבה
אני לא זוכר עכשיו מאיפה לקחתי את הרעיון, אבל זה נראה בערך כך:
עבור כל ערך, אנו מקצים מספר ביטים לאחסון דגלים.
כפי שאמרנו קודם, לאחר המחיקה כל הביטים מתמלאים ב-1, וניתן לשנות מ-1 ל-0, אך לא להיפך. אז עבור "דגל לא מוגדר" נשתמש ב-1, עבור "דגל מוגדר" - 0.
כך עשויה להיראות הצבת רשומה באורך משתנה בפלאש:
- הגדר את הדגל "הקלטת אורך התחילה";
- אנו רושמים את האורך;
- הגדר את הדגל "הקלטת הנתונים החלה";
- אנחנו כותבים נתונים;
- שמנו את הדגל "ההקלטה הסתיימה".
בנוסף, יהיה לנו דגל "אירעה שגיאה", עבור סכום כולל של 4 דגלי סיביות.
במקרה זה, יש לנו שני מצבים יציבים "1111" - ההקלטה לא החלה ו-"1000" - ההקלטה הצליחה; במקרה של הפרעה בלתי צפויה בתהליך ההקלטה, נקבל מצבי ביניים, אותם נוכל לזהות ולעבד מאוחר יותר.
הגישה מעניינת, אך היא מגינה רק מפני הפסקות חשמל פתאומיות וכשלים דומים, וזה כמובן חשוב, אך זו רחוקה מלהיות הסיבה היחידה (ואפילו לא העיקרית) לכשלים אפשריים.
סיכום: בואו נמשיך הלאה בחיפוש אחר פתרון טוב.
סכומי צ'ק
סכומי בדיקה מספקים גם דרך לאמת (עם סבירות סבירה) שאנחנו קוראים בדיוק את מה שהיה צריך להיכתב. ובניגוד לשדות הסיביות שנדונו לעיל, הם תמיד עובדים.
אם ניקח בחשבון את רשימת מקורות הבעיות הפוטנציאליים שדנו בהם לעיל, אזי בדיקת הבדיקה מסוגלת לזהות שגיאה ללא קשר למקורה. (אולי למעט חייזרים מרושעים - גם הם יכולים לזייף את סכום הבדיקה).
אז אם המטרה שלנו היא לוודא שהנתונים שלמים, סכומי בדיקה הם רעיון מצוין.
בחירת האלגוריתם לחישוב סכום הבדיקה לא עוררה שאלות - CRC. מצד אחד, התכונות המתמטיות מאפשרות זיהוי של 100% של שגיאות מסוגים מסוימים, ומצד שני - על נתונים אקראיים אלגוריתם זה בדרך כלל מראה שההסתברות להתנגשויות אינה גבוהה בהרבה מהגבול התאורטי.  זה אולי לא האלגוריתם המהיר ביותר, וייתכן שלא תמיד יהיה לו מספר ההתנגשויות הנמוך ביותר, אבל יש לו תכונה חשובה מאוד: בבדיקות שנתקלתי בהן, לא היו דפוסים שבהם הוא ייכשל באופן ברור. יציבות היא התכונה העיקרית במקרה הזה.
זה אולי לא האלגוריתם המהיר ביותר, וייתכן שלא תמיד יהיה לו מספר ההתנגשויות הנמוך ביותר, אבל יש לו תכונה חשובה מאוד: בבדיקות שנתקלתי בהן, לא היו דפוסים שבהם הוא ייכשל באופן ברור. יציבות היא התכונה העיקרית במקרה הזה.
דוגמה למחקר נפחי: , (קישורים ל-narod.ru, סליחה).
עם זאת, משימת בחירת בדיקת סיכום אינה שלמה, CRC היא משפחה שלמה של בדיקת סיכום. עליכם להחליט על האורך, ולאחר מכן לבחור פולינום.
בחירת אורך בדיקת הבדיקה אינה שאלה פשוטה כפי שהיא נראית במבט ראשון.
הרשו לי להמחיש:
בואו נקבל את ההסתברות לשגיאה בכל בייט  וסכום הבדיקה האידיאלי, אנו מחשבים את מספר השגיאות הממוצע לכל מיליון רשומות:
וסכום הבדיקה האידיאלי, אנו מחשבים את מספר השגיאות הממוצע לכל מיליון רשומות:
נתונים, בייט
סכום בדיקה, בייט
שגיאות שלא זוהו
גילוי שגיאות חיוביות שגויות
מספר כולל של תשובות שגויות
1
0
1000
0
1000
1
1
4
999
1003
1
2
0
1997
1997
1
4
0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
0
1979
1979
10
4
0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
0
1469
1469
נראה שהכל פשוט - בחר את אורך סכום הבדיקה עם מינימום של חיובי שגוי בהתאם לאורך הנתונים המוגנים - וסיימת.
עם זאת, ישנה בעיה עם סכומי בדיקה קצרים: למרות שהם טובים בזיהוי שגיאות של ביט בודד, הם יכולים, בסבירות גבוהה למדי, לקבל נתונים אקראיים לחלוטין כנכונים. כבר היה מאמר ב-Habr המתאר .
לכן, כדי להפוך התאמת סכומי בדיקה אקראיים לבלתי אפשרית כמעט, יש להשתמש בסכומי בדיקה של 32 סיביות או יותר. (עבור אורכים גדולים מ-64 סיביות, בדרך כלל משתמשים בפונקציות גיבוב קריפטוגרפיות).
למרות שכתבתי קודם לכן שעלינו לחסוך מקום בכל מחיר, עדיין נשתמש בסכום בדיקה של 32 סיביות (16 סיביות אינן מספיקות, ההסתברות להתנגשות היא יותר מ-0.01%; ו-24 סיביות, כמו שאומרים, אינן כאן ולא שם).
ייתכן שעולה כאן התנגדות: האם שמרנו כל בייט כשבחרנו דחיסה כדי לתת כעת 4 בייט בו זמנית? האם לא היה עדיף לא לדחוס ולא להוסיף סכום בדיקה? כמובן שלא, חוסר הדחיסה לא אומר, שאנחנו לא צריכים בדיקת שלמות.
לא נמציא את הגלגל מחדש בבחירת פולינום, אלא ניקח את ה-CRC-32C הפופולרי כיום.
קוד זה מזהה שגיאות של 6 סיביות על חבילות באורך של עד 22 בתים (כנראה המקרה הנפוץ ביותר עבורנו), שגיאות של 4 סיביות על חבילות באורך של עד 655 בתים (גם מקרה נפוץ עבורנו), 2 או כל מספר אי זוגי של שגיאות סיביות על חבילות באורך סביר.
אם מישהו מעוניין בפרטים
לגבי CRC.
על — אולי מומחה CRC המוביל בעולם.
В יש , אשר מספק פרמטרים מעט טובים יותר עבור אורכי החבילות הרלוונטיים לנו, אך לא ראיתי את ההבדל כמשמעותי, ולא ראיתי את עצמי מוכשר מספיק כדי לבחור קוד מותאם אישית במקום זה הסטנדרטי והנחקר היטב.
כמו כן, מכיוון שהנתונים שלנו דחוסים, עולה השאלה: האם עלינו לחשב את סכום הבדיקה של נתונים דחוסים או לא דחוסים?
טיעונים בעד חישוב סכום הבדיקה של נתונים לא דחוסים:
- בסופו של דבר עלינו לבדוק את בטיחות אחסון הנתונים - לכן אנו בודקים אותו ישירות (במקביל, ייבדקו שגיאות אפשריות ביישום הדחיסה/דה-קומפרסיה, נזק שנגרם מזיכרון פגום וכו');
- לאלגוריתם deflate ב-zlib יש יישום די בוגר ו לא צריך נופל עם נתוני קלט "עקומים", יתר על כן, הוא מסוגל לעתים קרובות לזהות באופן עצמאי שגיאות בזרם הקלט, מה שמפחית את ההסתברות הכוללת לאי-גילוי שגיאה (ביצעתי בדיקה עם היפוך של ביט בודד ברשומה קצרה, zlib זיהה שגיאה בכשליש מהמקרים).
טיעונים נגד חישוב סכום הבדיקה של נתונים לא דחוסים:
- CRC "מותאם" במיוחד עבור שגיאות הסיביות המעטות האופייניות לזיכרון פלאש (שגיאת סיביות בזרם דחוס יכולה לגרום לשינוי עצום בזרם הפלט, שבו, תיאורטית בלבד, נוכל "לתפוס" התנגשות);
- אני לא ממש אוהב את הרעיון של הזנת נתונים שעלולים להיות שבורים למפענח הלחץ, , איך הוא יגיב.
בפרויקט זה החלטתי לסגת מהנוהג הנפוץ של אחסון סכום בדיקה של נתונים לא דחוסים.
סיכום: אנו משתמשים ב-CRC-32C, אנו מחשבים את סכום הבדיקה מהנתונים בצורה בה הם נכתבים לפלאש (לאחר דחיסה).
יתירות
השימוש בקידוד יתיר, כמובן, אינו מבטל אובדן נתונים; עם זאת, הוא יכול להפחית באופן משמעותי (לעתים קרובות בסדרי גודל רבים) את הסבירות לאובדן נתונים בלתי הפיך.
אנו יכולים להשתמש בסוגים שונים של יתירות כדי לתקן שגיאות.
קודי המינג יכולים לתקן שגיאות של ביט בודד, קודי ריד-סולומון הם סמליים, עותקים מרובים של נתונים יחד עם סכומי בדיקה, או קידוד כמו RAID-6 יכולים לעזור בשחזור נתונים גם במקרה של פגיעה מסיבית.
בהתחלה, הייתי נחוש בדעתי להשתמש בקידוד לתיקון שגיאות באופן נרחב, אבל אז הבנתי שקודם כל צריך להיות לנו מושג מפני אילו שגיאות אנחנו רוצים להגן, ואז לבחור את הקידוד.
אמרנו קודם לכן שיש לזהות שגיאות במהירות האפשרית. באילו נקודות אנו עלולים להיתקל בשגיאות?
- הקלטה לא גמורה (מסיבה כלשהי, החשמל נפל במהלך ההקלטה, ה-Raspberry קפא,...)
לרוע המזל, במקרה של שגיאה כזו, האפשרות היחידה היא להתעלם מרשומות לא חוקיות ולראות את הנתונים כאבודים; - שגיאות כתיבה (מסיבה כלשהי, משהו אחר ממה שנכתב נכתב לזיכרון הפלאש)
נוכל לזהות שגיאות כאלה באופן מיידי אם נבצע קריאת בקרה מיד לאחר הרישום; - פגיעה בנתונים בזיכרון במהלך אחסון;
- שגיאות קריאה
כדי לתקן את השגיאה, אם סכום הבדיקה אינו תואם, מספיק לחזור על הקריאה מספר פעמים.
כלומר, רק שגיאות מהסוג השלישי (שחיתות ספונטנית של נתונים במהלך אחסון) אינן ניתנות לתיקון ללא קידוד לתיקון שגיאות. נראה ששגיאות כאלה עדיין אינן סבירות ביותר.
סיכום: הוחלט לזנוח את הקידוד העודף, אך אם הפעולה תראה את שגיאת ההחלטה הזו, יש לחזור ולבחון את הנושא (עם נתונים סטטיסטיים שכבר מצטברים על כשלים, שיאפשרו לבחור את סוג הקידוד האופטימלי).
אחר
כמובן, פורמט המאמר אינו מאפשר להצדיק כל סעיף בפורמט. (וכבר נגמרו לי הכוחות), אז אעבור בקצרה על כמה נקודות שלא נגעו בהן קודם לכן.
- הוחלט שכל העמודים יהיו "שווים"
כלומר, לא יהיו דפים מיוחדים עם מטא-דאטה, זרמים נפרדים וכו', במקום זאת יהיה זרם יחיד שכותב מחדש את כל הדפים בתורם.
זה מבטיח בלאי אחיד של הדפים, ללא נקודת כשל אחת, ופשוט יפה; - חיוני לספק ניהול גרסאות של הפורמט.
פורמט ללא מספר גרסה בכותרת הוא רע!
מספיק להוסיף שדה עם מספר קסם מסוים (חתימה) לכותרת העמוד, אשר יציין את גרסת הפורמט בה נעשה שימוש. (אני לא חושב שיהיו אפילו תריסר כאלה בפועל); - השתמשו בכותרת באורך משתנה עבור רשומות (שיש הרבה מהן), תוך ניסיון להפוך אותה לאורכה של בייט אחד ברוב המקרים;
- כדי לקודד את אורך הכותרת ואת אורך החלק הקטום של הרשומה הדחוסה, השתמש בקודים בינאריים באורך משתנה.
זה היה מאוד מועיל קודי האפמן. תוך דקות ספורות בלבד, הצלחנו לבחור את הקודים באורך משתנה הנדרשים.
תיאור פורמט אחסון נתונים
סדר בייט
שדות גדולים מבייט אחד מאוחסנים בפורמט big-endian (סדר בתים של רשת), כלומר, 0x1234 נכתב כ- 0x12, 0x34.
חלוקה לעמודים
כל זיכרון הפלאש מחולק לדפים בגודל שווה.
גודל העמוד המוגדר כברירת מחדל הוא 32 קילו-בייט, אך לא יותר מרבע מהגודל הכולל של שבב הזיכרון (עבור שבב של 1 מגה-בייט, מדובר ב-4 עמודים).
כל דף מאחסן נתונים באופן עצמאי מהאחרים (כלומר, נתונים מדף אחד אינם מפנים לנתונים מדף אחר).
כל העמודים ממוספרים בסדר טבעי (בסדר עולה של כתובות), החל מהמספר 0 (עמוד אפס מתחיל בכתובת 0, הראשון - עם 32 קילו-בייט, השני - עם 64 קילו-בייט וכו').
שבב הזיכרון משמש כחוצץ טבעתי, כלומר, תחילה ההקלטה עוברת לעמוד מספר 0, לאחר מכן לעמוד מספר 1, ..., כאשר אנו ממלאים את העמוד האחרון, מתחיל מחזור חדש וההקלטה ממשיכה מעמוד אפס.
בתוך הדף

בתחילת העמוד מאוחסנת כותרת עמוד בגודל 4 בתים, לאחר מכן סכום בדיקת כותרת (CRC-32C), ולאחר מכן מאוחסנות רשומות בפורמט "כותרת, נתונים, סכום בדיקת".
כותרת העמוד (ירוק מלוכלך בתרשים) מורכבת מ:
- שדה מספר קסם בן שני בייטים (הידוע גם כמחוון גרסת הפורמט)
עבור הגרסה הנוכחית של הפורמט זה נחשב כ0xed00 ⊕ номер страницы; - מונה בן שני בייטים "גרסת עמוד" (מספר מחזור כתיבה מחדש של זיכרון).
הרשומות בדף מאוחסנות בצורה דחוסה (באמצעות אלגוריתם deflate). כל הרשומות בדף אחד נדחסות בזרם אחד (באמצעות מילון משותף), והדחיסה מתחילה מחדש בכל דף חדש. כלומר, כדי לפענח דחיסה של כל רשומה, נדרשות כל הרשומות הקודמות מדף זה (ורק מדף זה).
כל רשומה דחוסה באמצעות הדגל Z_SYNC_FLUSH, וכתוצאה מכך הזרם הדחוס מסתיים ב-4 בתים 0x00, 0x00, 0xff, 0xff, כאשר ייתכן שקודמים להם עוד בייט או שניים של אפס.
אנו מתעלמים מרצף זה (באורך של 4, 5 או 6 בתים) בעת כתיבה לזיכרון פלאש.
כותרת הרשומה היא באורך של 1, 2 או 3 בתים, והיא מאחסנת:
- סיבית אחת (T) המציינת את סוג הרשומה: 0 - הקשר, 1 - יומן;
- שדה באורך משתנה (S) מ-1 עד 7 סיביות, המגדיר את אורך הכותרת ואת ה"זנב" שיש להוסיף לרשומה לצורך פריקה;
- אורך הרשומה (L).
טבלת ערכי S:
S
אורך כותרת, בתים
נזרק בכתיבה, בייט
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
ניסיתי להמחיש, אני לא יודע כמה זה יצא ברור:
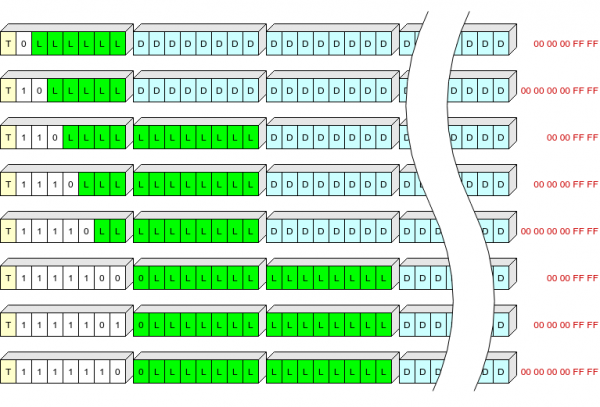
הצבע הצהוב כאן מציין את שדה ה-T, הצבע הלבן מציין את שדה ה-S, הצבע הירוק מציין את ה-L (אורך הנתונים הדחוסים בבתים), הצבע הכחול מציין את הנתונים הדחוסים, והצבע האדום מציין את הבייטים הסופיים של הנתונים הדחוסים שלא נכתבו לזיכרון הפלאש.
לכן, נוכל לכתוב את כותרות הרשומות באורך הנפוץ ביותר (עד 63+5 בתים בצורה דחוסה) בבייט אחד.
לאחר כל כתיבה, נשמר סכום בדיקה של CRC-32C, המשתמש בערך ההפוך של סכום הבדיקה הקודם כערך ההתחלתי (init).
ל-CRC יש את המאפיין של "משך", הנוסחה הבאה פועלת (פלוס מינוס היפוך סיביות בתהליך):  .
.
כלומר, אנחנו למעשה מחשבים את ה-CRC של כל הבייטים והנתונים של הכותרת הקודמים בדף זה.
מיד לאחר סכום הבדיקה נמצאת הכותרת של הרשומה הבאה.
הכותרת מתוכננת בצורה כזו שהבייט הראשון שלה תמיד שונה מ-0x00 ו-0xff (אם במקום הבייט הראשון של הכותרת אנו נתקלים ב-0xff, פירוש הדבר שזהו אזור שאינו בשימוש; 0x00 מסמן שגיאה).
אלגוריתמים לדוגמה
קריאה מזיכרון פלאש
כל קריאה מלווה בבדיקת סכום בדיקה.
אם סכום הבדיקה אינו תואם, הקריאה חוזרת על עצמה מספר פעמים בתקווה לקרוא את הנתונים הנכונים.
(זה הגיוני, Linux לא שומר במטמון קריאות מ-NOR Flash, מאומת)
כתיבה לזיכרון פלאש
אנחנו רושמים את הנתונים.
בואו נקרא אותם.
אם הנתונים שנקראו אינם תואמים לנתונים הכתובים, אנו ממלאים את האזור באפסים ומסמנים שגיאה.
הכנת מיקרו-מעגל חדש לפעולה
לצורך אתחול, כותרת עם גרסה 1 נכתבת לעמוד הראשון (או ליתר דיוק, אפס).
לאחר מכן, ההקשר הראשוני נכתב לדף זה (הוא מכיל את ה-UUID של המכונה ואת הגדרות ברירת המחדל).
זהו, זיכרון הפלאש מוכן לעבודה.
טעינת המכונה
בעת הטעינה, 8 הבייטים הראשונים של כל עמוד (כותרת + CRC) נקראים, דפים עם מספר קסם לא ידוע או CRC שגוי מתעלמים מהם.
מתוך הדפים ה"נכונים", נבחרים דפים עם הגרסה המקסימלית, ומתוכם נבחר הדף עם המספר הגבוה ביותר.
הרשומה הראשונה נקראת, ה-CRC נבדקת לתקינות, ודגל "הקשר" מסומן. אם הכל תקין, דף זה נחשב עדכני. אם לא, נחזור לדף הקודם עד שנמצא דף "פעיל".
ובדף שנמצא אנו קוראים את כל הרשומות, אלו שאנו משתמשים בהן עם דגל "הקשר".
שמור את מילון zlib (יהיה צורך להוסיף אותו לדף זה).
זהו, הטעינה הושלמה, ההקשר שוחזר, אתה יכול לעבוד.
הוספת רשומת יומן
אנו דוחסים את הרשומה עם המילון הנכון, תוך ציון Z_SYNC_FLUSH. אנו בודקים אם הרשומה הדחוסה מתאימה לעמוד הנוכחי.
אם זה לא מתאים (או שהיו שגיאות CRC בדף), התחל דף חדש (ראה להלן).
אנו כותבים את הרשומה ואת ה-CRC. אם מתרחשת שגיאה, אנו מתחילים עמוד חדש.
עמוד חדש
אנו בוחרים דף פנוי עם מספר מינימלי (אנו מחשיבים דף עם סכום בדיקה שגוי בכותרת או עם גרסה נמוכה יותר מהנוכחית כדף פנוי). אם אין דפים כאלה, אנו בוחרים דף עם מספר מינימלי מבין אלה שיש להם גרסה שווה לזו הנוכחית.
אנו מוחקים את העמוד שנבחר. אנו משווים את התוכן עם 0xff. אם משהו לא בסדר, אנו לוקחים את העמוד הפנוי הבא, וכו'.
אנו כותבים את הכותרת לעמוד שנמחק, הערך הראשון הוא המצב הנוכחי של ההקשר, הבא הוא ערך יומן שלא נכתב (אם קיים כזה).
תחולת הפורמט
לדעתי, זהו פורמט טוב לאחסון כל זרמי מידע הניתנים לדחיסה פחות או יותר (טקסט רגיל, JSON, MessagePack, CBOR, אולי protobuf) ב-NOR Flash.
כמובן, הפורמט "מחודד" עבור SLC NOR Flash.
אין להשתמש בו עם מדיה בעלת BER גבוה כגון NAND או MLC NOR. (האם זיכרון כזה בכלל זמין למכירה? ראיתי אזכורים שלו רק בעבודות על קודי תיקון).
יתר על כן, אין להשתמש בו עם מכשירים בעלי FTL משלהם: זיכרון USB, SD, MicroSD וכו'. (עבור זיכרון כזה יצרתי פורמט עם גודל עמוד של 512 בתים, חתימה בתחילת כל עמוד ומספרי רשומה ייחודיים - לפעמים היה אפשר לשחזר את כל הנתונים מדיסק הבזק "תקול" פשוט על ידי קריאה סדרתית).
בהתאם למשימות, ניתן להשתמש בפורמט ללא שינויים על כונני הבזק מ-128 קילו-ביט (16 קילו-ביט) עד 1 ג'יגה-ביט (128 מגה-בייט). במידת הצורך, ניתן להשתמש בו על שבבים בעלי קיבולת גדולה יותר, אך סביר להניח שתצטרכו להתאים את גודל הדף. (אבל כאן עולה שאלת ההיתכנות הכלכלית, מחירו של NOR Flash בנפח גדול אינו מעודד).
אם מישהו מוצא את הפורמט מעניין ורוצה להשתמש בו בפרויקט קוד פתוח, שיכתוב לי, אנסה למצוא זמן, ללטש את הקוד ולפרסם אותו בגיטהאב.
מסקנה
כפי שאנו רואים, בסופו של דבר הפורמט התברר כפשוט ואפילו משעמם.
קשה לשקף את התפתחות נקודת המבט שלי במאמר, אבל תאמינו לי: בתחילה רציתי ליצור משהו מתוחכם, בלתי ניתן להריסה, המסוגל לשרוד גם אחרי פיצוץ גרעיני בקרבת מקום. עם זאת, ההיגיון (אני מקווה) עדיין ניצח ובהדרגה סדרי העדיפויות עברו לפשטות וקומפקטיות.
האם ייתכן שעשיתי טעות? כן, כמובן. בהחלט ייתכן שרכשנו אצווה של שבבים באיכות ירודה. או שמסיבה אחרת הציוד לא יעמוד בציפיות מבחינת אמינות.
האם יש לי תוכנית לכך? אני חושב שאחרי קריאת המאמר אין לך ספק שיש תוכנית. ואפילו לא אחת.
כדי להיות קצת יותר רציניים, הפורמט פותח גם כאפשרות עבודה וגם כ"בלון ניסיון".
כרגע, הכל עובד מצוין על השולחן, הפתרון ייפרס ממש בעוד מספר ימים. (בְּעֵרֶך) על מאה מכשירים, בואו נראה מה יקרה בפעולת "קרב" (למרבה המזל, אני מקווה, הפורמט מאפשר זיהוי אמין של כשלים; כך שניתן יהיה לאסוף נתונים סטטיסטיים מלאים). בעוד מספר חודשים ניתן יהיה להסיק מסקנות (ואם אין לכם מזל, אפילו מוקדם יותר).
אם, לאחר השימוש בו, יתגלו בעיות חמורות ונדרש שיפור, בהחלט אכתוב על כך.
ספרות
לא רציתי לעשות רשימת מקורות ארוכה ומשעממת; אחרי הכל, לכולם יש גוגל.
כאן החלטתי להשאיר רשימה של ממצאים שנראו לי מעניינים במיוחד, אך בהדרגה הם נדדו ישירות לטקסט המאמר, ורק פריט אחד נותר ברשימה:
- שירות ממחבר zlib. הוא יכול להציג את תוכן ארכיוני deflate/zlib/gzip בצורה ברורה. אם אתם צריכים להתמודד עם המבנה הפנימי של פורמט deflate (או gzip), אני ממליץ עליו בחום.
מקור: www.habr.com
