

במאמר זה, אדבר על האופן שבו הפרויקט שעליו אני עובד הפך ממונוליט גדול לסט של שירותי מיקרו.
הפרויקט החל את ההיסטוריה שלו די מזמן, בתחילת שנת 2000. הגרסאות הראשונות נכתבו ב-Visual Basic 6. עם הזמן התברר שפיתוח בשפה זו יהיה קשה לתמוך בעתיד, שכן ה-IDE והשפה עצמה מפותחת בצורה גרועה. בסוף שנות ה-2000 הוחלט לעבור ל-C# המבטיח יותר. הגרסה החדשה נכתבה במקביל לגרסה הישנה, בהדרגה נכתב יותר ויותר קוד ב-.NET. Backend ב-C# התמקד בתחילה בארכיטקטורת שירות, אך במהלך הפיתוח נעשה שימוש בספריות נפוצות עם לוגיקה, ושירותים הושקו בתהליך אחד. התוצאה הייתה אפליקציה שכינינו "מונוליט שירות".
אחד היתרונות הבודדים של שילוב זה היה היכולת של שירותים להתקשר זה לזה באמצעות API חיצוני. היו תנאים מוקדמים ברורים למעבר לשירות נכון יותר, ובעתיד, ארכיטקטורת מיקרו-שירותים.
התחלנו את עבודתנו על פירוק בסביבות 2015. עדיין לא הגענו למצב אידיאלי - יש עדיין חלקים מפרויקט גדול שבקושי אפשר לקרוא להם מונוליטים, אבל הם גם לא נראים כמו מיקרו-שירותים. עם זאת, ההתקדמות היא משמעותית.
אני אדבר על זה במאמר.
תוכן
ארכיטקטורה ובעיות של הפתרון הקיים
בתחילה, הארכיטקטורה נראתה כך: ממשק המשתמש הוא יישום נפרד, החלק המונוליטי כתוב ב-Visual Basic 6, יישום ה-.NET הוא קבוצה של שירותים קשורים שעובדים עם מסד נתונים גדול למדי.
חסרונות של הפתרון הקודם
נקודת כשל יחידה
הייתה לנו נקודת כשל אחת: אפליקציית .NET רצה בתהליך אחד. אם מודול כלשהו נכשל, היישום כולו נכשל והיה צריך להפעיל אותו מחדש. מכיוון שאנו עושים אוטומציה של מספר רב של תהליכים עבור משתמשים שונים, עקב כשל באחד מהם, כולם לא יכלו לעבוד במשך זמן מה. ובמקרה של שגיאת תוכנה, אפילו גיבוי לא עזר.
תור של שיפורים
החיסרון הזה הוא די ארגוני. לאפליקציה שלנו יש לקוחות רבים, וכולם רוצים לשפר אותה בהקדם האפשרי. בעבר אי אפשר היה לעשות זאת במקביל, וכל הלקוחות עמדו בתור. תהליך זה היה שלילי עבור עסקים מכיוון שהם היו צריכים להוכיח שהמשימה שלהם היא בעלת ערך. וצוות הפיתוח השקיע זמן בארגון התור הזה. זה לקח הרבה זמן ומאמץ, והמוצר בסופו של דבר לא יכול היה להשתנות במהירות כמו שהם היו רוצים.
שימוש לא מיטבי במשאבים
כאשר מארחים שירותים בתהליך אחד, תמיד העתקנו לחלוטין את התצורה משרת לשרת. רצינו למקם את השירותים העמוסים ביותר בנפרד כדי לא לבזבז משאבים ולהשיג שליטה גמישה יותר על תוכנית הפריסה שלנו.
קשה ליישם טכנולוגיות מודרניות
בעיה המוכרת לכל המפתחים: יש רצון להכניס טכנולוגיות חדישות לפרויקט, אבל אין הזדמנות. עם פתרון מונוליטי גדול, כל עדכון של הספרייה הנוכחית, שלא לדבר על המעבר לחדשה, הופך למשימה לא טריוויאלית למדי. לוקח הרבה זמן להוכיח לראש הצוות שזה יביא יותר בונוסים מאשר עצבים מבוזבזים.
קושי בהנפקת שינויים
זו הייתה הבעיה החמורה ביותר - הוצאנו מהדורות כל חודשיים.
כל מהדורה הפכה לאסון של ממש עבור הבנק, למרות הבדיקות והמאמצים של המפתחים. העסק הבין שבתחילת השבוע חלק מהפונקציונליות שלו לא יעבוד. והיזמים הבינו שמחכה להם שבוע של תקריות חמורות.
לכולם היה רצון לשנות את המצב.
ציפיות משירותי מיקרו
הנפקת רכיבים כשמוכנים. אספקת רכיבים כשמוכנים על ידי פירוק התמיסה והפרדת תהליכים שונים.
צוותי מוצרים קטנים. זה חשוב מכיוון שצוות גדול שעבד על המונוליט הישן היה קשה לניהול. צוות כזה נאלץ לעבוד על פי תהליך קפדני, אבל הם רצו יותר יצירתיות ועצמאות. רק צוותים קטנים יכלו להרשות זאת לעצמם.
בידוד שירותים בתהליכים נפרדים. באופן אידיאלי, הייתי רוצה לבודד אותו בתוך קונטיינרים, אבל מספר רב של שירותים שנכתבו ב-.NET Framework פועלים רק תחת Windowsשירותים המבוססים על .NET Core מופיעים כעת, אך עדיין יש מעטים מהם.
גמישות בפריסה. נרצה לשלב שירותים כמו שאנחנו צריכים את זה, ולא כמו שהקוד כופה אותו.
שימוש בטכנולוגיות חדשות. זה מעניין כל מתכנת.
בעיות מעבר
כמובן שאם היה קל לפרק מונוליט למיקרו-שירותים, לא היה צורך לדבר על זה בכנסים ולכתוב מאמרים. יש הרבה מלכודות בתהליך הזה; אתאר את העיקריות שהפריעו לנו.
בעיה ראשונה אופייני לרוב המונוליטים: קוהרנטיות של ההיגיון העסקי. כשאנחנו כותבים מונוליט, אנחנו רוצים לעשות שימוש חוזר בשיעורים שלנו כדי לא לכתוב קוד מיותר. וכאשר עוברים ל-microservices, זה הופך לבעיה: כל הקוד מחובר בצורה הדוקה למדי, וקשה להפריד בין השירותים.
בזמן תחילת העבודה, היו במאגר יותר מ-500 פרויקטים ויותר מ-700 אלף שורות קוד. זו החלטה די גדולה ו בעיה שנייה. אי אפשר היה פשוט לקחת אותו ולחלק אותו למיקרו-שירותים.
בעיה שלישית - היעדר תשתית הכרחית. למעשה, העתקנו ידנית את קוד המקור לשרתים.
כיצד לעבור ממונוליט למיקרו-שירותים
מתן שירותי מיקרו
ראשית, מיד קבענו בעצמנו שהפרדת שירותי מיקרו היא תהליך איטרטיבי. תמיד נדרשנו לפתח בעיות עסקיות במקביל. איך ניישם את זה מבחינה טכנית זו כבר בעיה שלנו. לכן, התכוננו לתהליך איטרטיבי. זה לא יעבוד בדרך אחרת אם יש לך אפליקציה גדולה והיא לא מוכנה מלכתחילה להיכתב מחדש.
באילו שיטות אנו משתמשים כדי לבודד שירותי מיקרו?
השיטה הראשונה - להעביר מודולים קיימים כשירותים. בהקשר הזה, היה לנו מזל: כבר היו שירותים רשומים שעבדו בפרוטוקול WCF. הם הופרדו לאסיפות נפרדות. העברנו אותם בנפרד, והוספנו משגר קטן לכל מבנה. הוא נכתב באמצעות ספריית Topshelf הנהדרת, המאפשרת להפעיל את האפליקציה הן כשירות והן כקונסולה. זה נוח לאיפוי באגים מכיוון שלא נדרשים פרויקטים נוספים בפתרון.
השירותים היו מחוברים לפי ההיגיון העסקי, שכן הם השתמשו בהרכבים משותפים ועבדו עם מסד נתונים משותף. בקושי אפשר לקרוא להם מיקרו-שירותים בצורתם הטהורה. עם זאת, נוכל לספק שירותים אלה בנפרד, בתהליכים שונים. זה לבדו איפשר לצמצם את השפעתם זה על זה, ולצמצם את הבעיה עם התפתחות מקבילה ונקודת כישלון אחת.
הרכבה עם המארח היא רק שורת קוד אחת במחלקת התוכנית. החבאנו עבודה עם Topshelf בכיתת עזר.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
הדרך השנייה להקצות שירותי מיקרו היא: ליצור אותם כדי לפתור בעיות חדשות. אם במקביל המונוליט לא גדל, זה כבר מצוין, מה שאומר שאנחנו מתקדמים בכיוון הנכון. כדי לפתור בעיות חדשות, ניסינו ליצור שירותים נפרדים. אם הייתה הזדמנות כזו, אז יצרנו שירותים "קנוניים" יותר שמנהלים לחלוטין את מודל הנתונים שלהם, מסד נתונים נפרד.
אנחנו, כמו רבים, התחלנו עם שירותי אימות והרשאה. הם מושלמים עבור זה. הם עצמאיים, ככלל, יש להם מודל נתונים נפרד. הם עצמם אינם מקיימים אינטראקציה עם המונוליט, רק שהוא פונה אליהם כדי לפתור כמה בעיות. באמצעות שירותים אלה, אתה יכול להתחיל את המעבר לארכיטקטורה חדשה, לנפות באגים בתשתית עליהם, לנסות כמה גישות הקשורות לספריות רשת וכו'. אין לנו צוותים בארגון שלנו שלא הצליחו ליצור שירות אימות.
הדרך השלישית להקצאת שירותי מיקרוזה שאנחנו משתמשים בו הוא קצת ספציפי לנו. זוהי הסרת ההיגיון העסקי משכבת ה-UI. אפליקציית ממשק המשתמש העיקרית שלנו היא שולחן העבודה; הוא, כמו הקצה האחורי, כתוב ב-C#. המפתחים עשו מעת לעת טעויות והעבירו חלקי לוגיקה לממשק המשתמש שהיו צריכים להתקיים ב-backend ולעשות שימוש חוזר.
אם תסתכלו על דוגמה אמיתית מהקוד של חלק ה-UI, תוכלו לראות שרוב הפתרון הזה מכיל לוגיקה עסקית אמיתית ששימושית בתהליכים אחרים, לא רק לבניית טופס ה-UI.
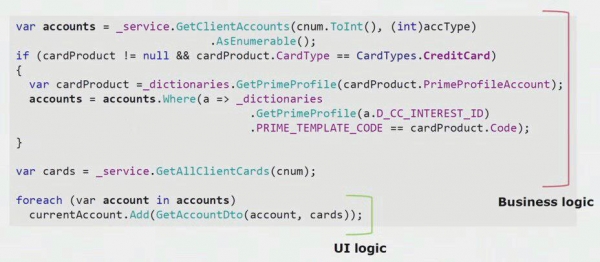
ההיגיון האמיתי של ממשק המשתמש נמצא שם רק בשתי השורות האחרונות. העברנו אותו לשרת כדי שניתן יהיה לעשות בו שימוש חוזר, ובכך הקטינו את ממשק המשתמש והשגנו את הארכיטקטורה הנכונה.
הדרך הרביעית והחשובה ביותר לבודד שירותי מיקרו, המאפשר להפחית את המונוליט, הוא הסרה של שירותים קיימים עם עיבוד. כאשר אנו מוציאים מודולים קיימים כפי שהם, התוצאה לא תמיד לרוחם של המפתחים, וייתכן שהתהליך העסקי מיושן מאז יצירת הפונקציונליות. עם Refactoring, אנו יכולים לתמוך בתהליך עסקי חדש מכיוון שהדרישות העסקיות משתנות ללא הרף. אנחנו יכולים לשפר את קוד המקור, להסיר פגמים ידועים וליצור מודל נתונים טוב יותר. יש הרבה יתרונות שמצטברים.
הפרדת שירותים מעיבוד קשורה קשר בל יינתק למושג ההקשר התחום. זהו מושג מ- Domain Driven Design. המשמעות היא קטע במודל התחום שבו כל המונחים של שפה בודדת מוגדרים באופן ייחודי. בואו נסתכל על ההקשר של ביטוח ושטרות כדוגמה. יש לנו אפליקציה מונוליטית, ואנחנו צריכים לעבוד עם החשבון בביטוח. אנו מצפים שהמפתח ימצא מחלקת חשבון קיימת בהרכבה אחרת, יפנה אליה ממחלקת הביטוח, ויהיה לנו קוד עבודה. עקרון ה- DRY יכובד, המשימה תתבצע מהר יותר על ידי שימוש בקוד קיים.
כתוצאה מכך מתברר שהקשרים של חשבונות וביטוח קשורים. ככל שצצות דרישות חדשות, צימוד זה יפריע להתפתחות, ויגדיל את המורכבות של ההיגיון העסקי המורכב ממילא. כדי לפתור בעיה זו, עליך למצוא את הגבולות בין ההקשרים בקוד ולהסיר את ההפרות שלהם. למשל, בהקשר הביטוחי, בהחלט ייתכן שמספר חשבון בנק מרכזי בן 20 ספרות ותאריך פתיחת החשבון יספיקו.
כדי להפריד את ההקשרים הגבולים הללו זה מזה ולהתחיל בתהליך של הפרדת שירותי מיקרו מפתרון מונוליטי, השתמשנו בגישה כמו יצירת APIs חיצוניים בתוך האפליקציה. אם ידענו שמודול כלשהו צריך להפוך למיקרו-שירות, איכשהו שונה בתוך התהליך, אז עשינו מיד קריאות ללוגיקה ששייכת להקשר מוגבל אחר באמצעות שיחות חיצוניות. לדוגמה, דרך REST או WCF.
החלטנו בתוקף שלא נימנע מקוד שידרוש עסקאות מבוזרות. במקרה שלנו, התברר כי די קל לעקוב אחר כלל זה. עדיין לא נתקלנו במצבים שבהם באמת יש צורך בעסקאות מבוזרות קפדניות - העקביות הסופית בין המודולים מספיקה בהחלט.
בואו נסתכל על דוגמה ספציפית. יש לנו את הקונספט של מתזמר - צינור המעבד את הישות של "האפליקציה". הוא יוצר בתורו לקוח, חשבון וכרטיס בנק. אם הלקוח והחשבון נוצרו בהצלחה, אך יצירת הכרטיס נכשלה, האפליקציה לא עוברת למצב "מוצלח" ונשארת בסטטוס "כרטיס לא נוצר". בעתיד, פעילות ברקע תקלוט אותו ותסיים אותו. המערכת נמצאת במצב של חוסר עקביות כבר זמן מה, אך אנו מרוצים מכך בדרך כלל.
אם נוצר מצב בו יש צורך לשמור חלק מהנתונים באופן עקבי, ככל הנראה נלך לאיחוד השירות על מנת לעבד אותו בתהליך אחד.
בואו נסתכל על דוגמה להקצאת שירות מיקרו. איך אפשר להביא אותו לייצור בצורה בטוחה יחסית? בדוגמה זו, יש לנו חלק נפרד של המערכת - מודול שירות שכר, שאחד מקטעי הקוד שלו נרצה לעשות microservice.
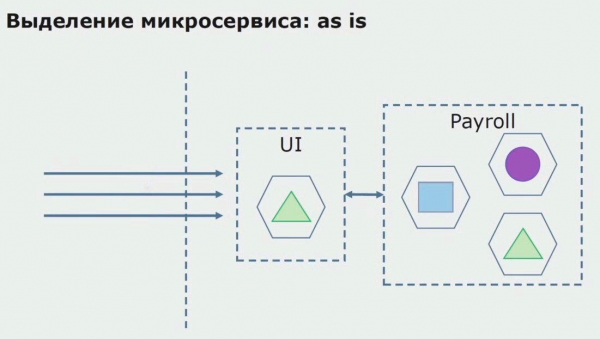
קודם כל, אנו יוצרים מיקרו-שירות על ידי כתיבה מחדש של הקוד. אנחנו משפרים כמה היבטים שלא היינו מרוצים מהם. אנו מיישמים דרישות עסקיות חדשות מהלקוח. אנו מוסיפים שער API לחיבור בין ממשק המשתמש ל-backend, שיספק העברת שיחות.
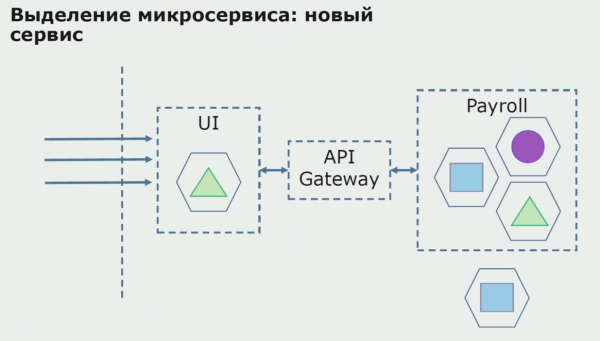
לאחר מכן, אנו משחררים את התצורה הזו לפעולה, אך במצב פיילוט. רוב המשתמשים שלנו עדיין עובדים עם תהליכים עסקיים ישנים. עבור משתמשים חדשים, אנו מפתחים גרסה חדשה של האפליקציה המונוליטית שאינה מכילה יותר את התהליך הזה. בעיקרו של דבר, יש לנו שילוב של מונוליט ושירות מיקרו שעובד כפיילוט.
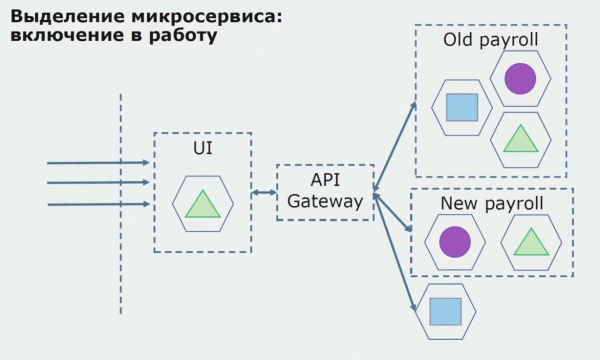
עם פיילוט מוצלח, אנו מבינים שהתצורה החדשה אכן ניתנת לביצוע, אנו יכולים להסיר את המונוליט הישן מהמשוואה ולהשאיר את התצורה החדשה במקום הפתרון הישן.
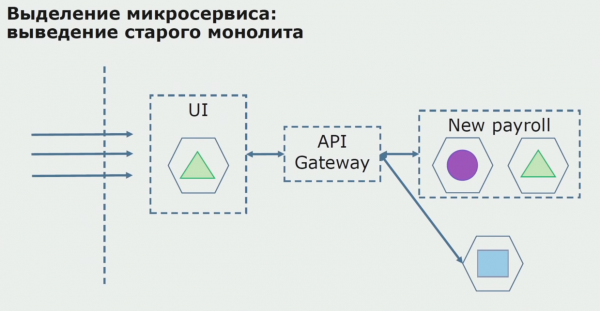
בסך הכל, אנו משתמשים כמעט בכל השיטות הקיימות לפיצול קוד המקור של מונוליט. כולם מאפשרים לנו להקטין את גודלם של חלקים מהאפליקציה ולתרגם אותם לספריות חדשות, וליצור קוד מקור טוב יותר.
עבודה עם מסד הנתונים
ניתן לחלק את מסד הנתונים בצורה גרועה יותר מקוד המקור, מכיוון שהוא מכיל לא רק את הסכימה הנוכחית, אלא גם נתונים היסטוריים מצטברים.
למסד הנתונים שלנו, כמו לרבים אחרים, היה חסרון חשוב נוסף - גודלו העצום. מסד נתונים זה תוכנן על פי ההיגיון העסקי המורכב של מונוליט, ויחסים שהצטברו בין הטבלאות של הקשרים מוגבלים שונים.
במקרה שלנו, לראש כל הצרות (בסיס נתונים גדול, חיבורים רבים, לפעמים גבולות לא ברורים בין טבלאות), נוצרה בעיה שמתרחשת בהרבה פרויקטים גדולים: השימוש בתבנית מסד הנתונים המשותפת. הנתונים נלקחו מטבלאות דרך תצוגה, דרך שכפול, ונשלחו למערכות אחרות בהן היה צורך בשכפול זה. כתוצאה מכך, לא יכולנו להעביר את הטבלאות לסכימה נפרדת כי נעשה בהן שימוש פעיל.
אותה חלוקה להקשרים מוגבלים בקוד עוזרת לנו בהפרדה. זה בדרך כלל נותן לנו מושג די טוב איך אנחנו מפרקים את הנתונים ברמת מסד הנתונים. אנו מבינים אילו טבלאות שייכות להקשר מוגבל אחד ואיזה לאחר.
השתמשנו בשתי שיטות גלובליות של חלוקת מסד נתונים: חלוקה של טבלאות קיימות וחלוקה עם עיבוד.
פיצול טבלאות קיימות היא שיטה טובה לשימוש אם מבנה הנתונים טוב, עומד בדרישות העסקיות וכולם מרוצים ממנה. במקרה זה, נוכל להפריד טבלאות קיימות לסכימה נפרדת.
דרושה מחלקה עם עיבוד כשהמודל העסקי השתנה מאוד, והטבלאות כבר לא מספקות אותנו בכלל.
פיצול שולחנות קיימים. אנחנו צריכים לקבוע מה נפריד. ללא הידע הזה, שום דבר לא יעבוד, וכאן ההפרדה של הקשרים מוגבלים בקוד תעזור לנו. ככלל, אם אתה יכול להבין את גבולות ההקשרים בקוד המקור, מתברר אילו טבלאות יש לכלול ברשימה של המחלקה.
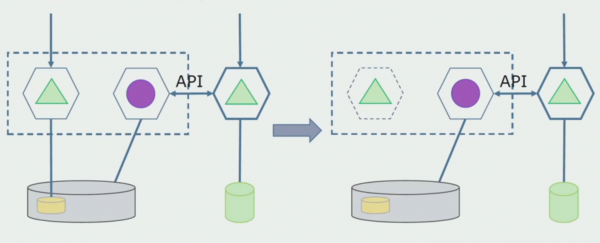
בואו נדמיין שיש לנו פתרון שבו שני מודולים מונוליטים מקיימים אינטראקציה עם מסד נתונים אחד. עלינו לוודא שרק מודול אחד מקיים אינטראקציה עם הקטע של טבלאות מופרדות, והשני מתחיל לקיים איתו אינטראקציה דרך ה-API. מלכתחילה, מספיק שרק ההקלטה מתבצעת דרך ה-API. זה תנאי הכרחי בשבילנו לדבר על עצמאותם של שירותי מיקרו. חיבורי קריאה יכולים להישאר כל עוד אין בעיה גדולה.
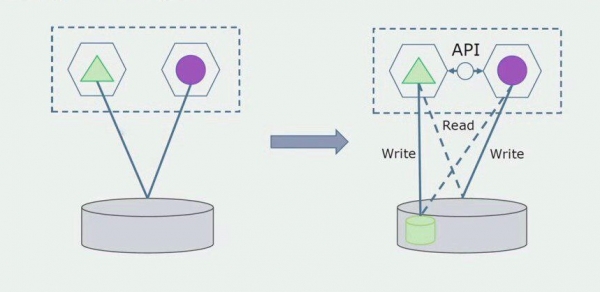
השלב הבא הוא שאנחנו יכולים להפריד את קטע הקוד שעובד עם טבלאות מופרדות, עם או בלי עיבוד, למיקרו-שירות נפרד ולהפעיל אותו בתהליך נפרד, קונטיינר. זה יהיה שירות נפרד עם חיבור למסד הנתונים המונוליט ולאותן טבלאות שאינן קשורות ישירות אליו. המונוליט עדיין מקיים אינטראקציה לקריאה עם החלק הניתן להסרה.
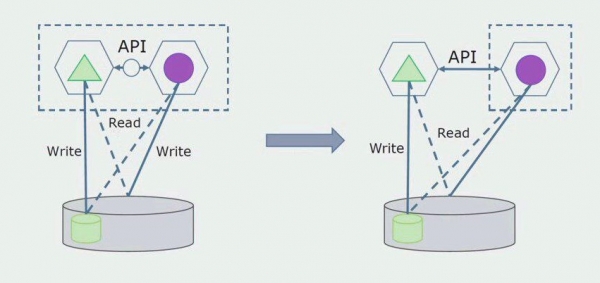
בהמשך נסיר את החיבור הזה, כלומר קריאת נתונים מאפליקציה מונוליטית מטבלאות מופרדות תועבר גם ל-API.
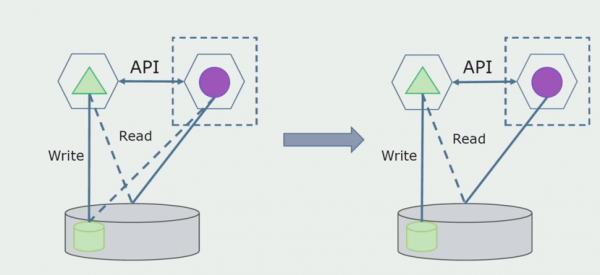
לאחר מכן, נבחר מתוך מסד הנתונים הכללי את הטבלאות איתן עובד רק המיקרו-שירות החדש. אנחנו יכולים להעביר את הטבלאות לסכימה נפרדת או אפילו למסד נתונים פיזי נפרד. עדיין יש חיבור קריאה בין המיקרו-שירות למסד הנתונים המונוליט, אבל אין מה לדאוג, בתצורה הזו הוא יכול לחיות די הרבה זמן.
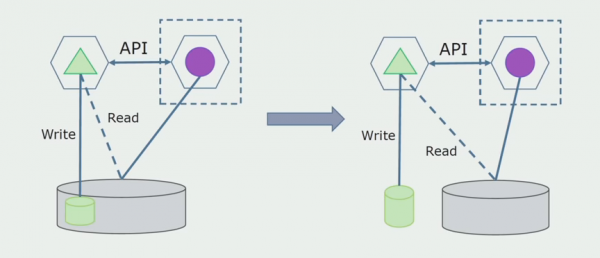
השלב האחרון הוא להסיר לחלוטין את כל החיבורים. במקרה זה, ייתכן שנצטרך להעביר נתונים ממסד הנתונים הראשי. לפעמים אנחנו רוצים לעשות שימוש חוזר בכמה נתונים או ספריות המשוכפלות ממערכות חיצוניות במספר מסדי נתונים. זה קורה לנו מדי פעם.
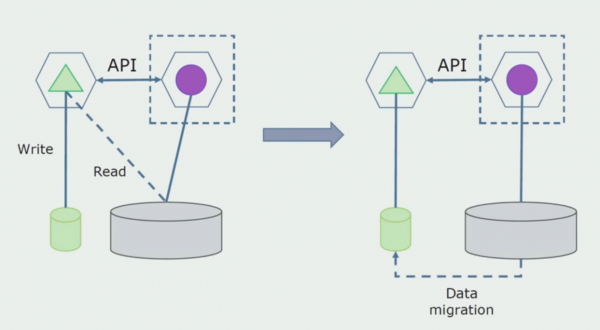
מחלקת עיבוד. שיטה זו דומה מאוד לראשונה, רק בסדר הפוך. אנו מקצים מיד מסד נתונים חדש ושירות מיקרו חדש שמקיים אינטראקציה עם המונוליט באמצעות API. אך יחד עם זאת, נותרה קבוצה של טבלאות מסד נתונים שאנו רוצים למחוק בעתיד. אנחנו כבר לא צריכים את זה, החלפנו אותו בדגם החדש.
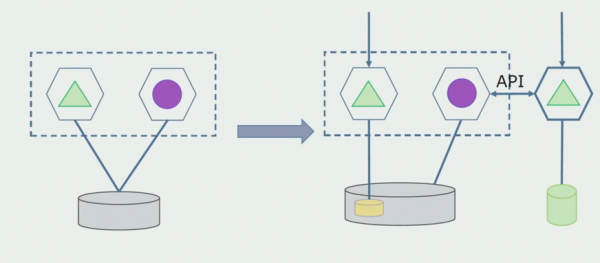
כדי שתוכנית זו תעבוד, סביר להניח שנצטרך תקופת מעבר.
אם כן, ישנן שתי גישות אפשריות.
ראשון: אנו משכפלים את כל הנתונים במסד הנתונים החדשים והישנים. במקרה זה, יש לנו יתירות נתונים וייתכנו בעיות סנכרון. אבל אנחנו יכולים לקחת שני לקוחות שונים. אחד יעבוד עם הגרסה החדשה, השני עם הישנה.
שני: אנו מחלקים את הנתונים לפי כמה קריטריונים עסקיים. לדוגמא, היו לנו במערכת 5 מוצרים שנשמרו במסד הנתונים הישן. אנו מציבים את השישי במשימה העסקית החדשה במסד נתונים חדש. אבל נצטרך שער API שיסנכרן את הנתונים האלה ויראה ללקוח מאיפה וממה להגיע.
שתי הגישות עובדות, בחר בהתאם למצב.
אחרי שאנחנו בטוחים שהכל עובד, ניתן להשבית את החלק של המונוליט שעובד עם מבני מסד נתונים ישנים.
השלב האחרון הוא להסיר את מבני הנתונים הישנים.
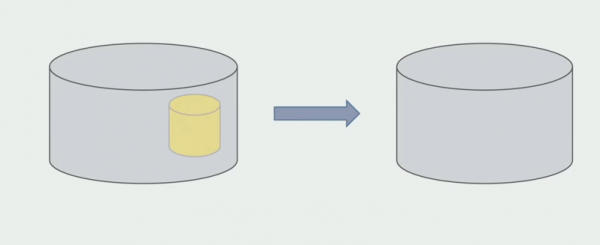
לסיכום, אפשר לומר שיש לנו בעיות במסד הנתונים: קשה לעבוד איתו בהשוואה לקוד המקור, קשה יותר לשתף, אבל אפשר וצריך לעשות את זה. מצאנו כמה דרכים המאפשרות לנו לעשות זאת בצורה בטוחה למדי, אבל עדיין קל יותר לעשות טעויות עם נתונים מאשר עם קוד מקור.
עבודה עם קוד מקור
כך נראתה דיאגרמת קוד המקור כשהתחלנו לנתח את הפרויקט המונוליטי.
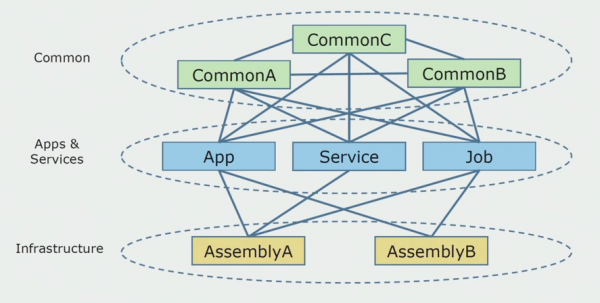
אפשר לחלק אותו לשלוש שכבות בערך. זוהי שכבה של מודולים שהושקו, תוספים, שירותים ופעילויות בודדות. למעשה, אלו היו נקודות כניסה בתוך פתרון מונוליטי. כולם היו אטומים היטב בשכבת Common. היה לו היגיון עסקי שהשירותים היו משותפים והרבה קשרים. כל שירות ותוסף השתמשו בעד 10 מכלולים נפוצים או יותר, בהתאם לגודלם ולמצפונם של המפתחים.
היה לנו מזל שיש לנו ספריות תשתית שניתן להשתמש בהן בנפרד.
לעיתים נוצר מצב שחלק מהאובייקטים הנפוצים לא היו שייכים למעשה לשכבה זו, אלא היו ספריות תשתית. זה נפתר על ידי שינוי שם.
החשש הגדול ביותר היה הקשרים מוגבלים. קרה ש-3-4 הקשרים היו מעורבבים באסיפה משותפת אחת והשתמשו זה בזה בתוך אותן פונקציות עסקיות. היה צורך להבין היכן ניתן לחלק את זה ולאורך אילו גבולות, ומה לעשות הלאה עם מיפוי החלוקה הזו למכלולי קוד מקור.
גיבשנו מספר כללים לתהליך פיצול הקוד.
1: לא רצינו יותר לחלוק היגיון עסקי בין שירותים, פעילויות ותוספים. רצינו להפוך את ההיגיון העסקי לבלתי תלוי בתוך שירותי מיקרו. מיקרו-שירותים, לעומת זאת, נחשבים באופן אידיאלי כשירותים הקיימים באופן עצמאי לחלוטין. אני מאמין שהגישה הזו קצת בזבזנית, וקשה להשיג אותה, כי למשל שירותים ב-C# יתחברו בכל מקרה על ידי ספרייה סטנדרטית. המערכת שלנו כתובה ב-C#; עדיין לא השתמשנו בטכנולוגיות אחרות. לכן, החלטנו שאנחנו יכולים להרשות לעצמנו להשתמש במכלולים טכניים נפוצים. העיקר שהם לא מכילים שברי היגיון עסקי. אם יש לך מעטפת נוחות על ה-ORM שבו אתה משתמש, אז העתקתו משירות לשירות היא יקרה מאוד.
הצוות שלנו חובב עיצוב מונחה תחום, אז ארכיטקטורת הבצל התאימה לנו מאוד. הבסיס לשירותים שלנו אינו שכבת הגישה לנתונים, אלא מכלול עם לוגיקה תחום, המכילה לוגיקה עסקית בלבד ואין לה קשרים עם התשתית. במקביל, אנו יכולים לשנות באופן עצמאי את מכלול התחום כדי לפתור בעיות הקשורות ל-frameworks.
בשלב זה נתקלנו בבעיה החמורה הראשונה שלנו. השירות היה צריך להתייחס למכלול תחום אחד, רצינו להפוך את ההיגיון לבלתי תלוי, ועקרון ה- DRY מאוד הפריע לנו כאן. המפתחים רצו לעשות שימוש חוזר במחלקות ממכלולים שכנים כדי למנוע כפילות, וכתוצאה מכך, דומיינים החלו להיות מקושרים שוב. ניתחנו את התוצאות והחלטנו שאולי הבעיה טמונה גם בתחום התקן אחסון קוד המקור. היה לנו מאגר גדול שהכיל את כל קוד המקור. הפתרון לכל הפרויקט היה קשה מאוד להרכבה במכונה מקומית. לכן, נוצרו פתרונות קטנים נפרדים לחלקים מהפרויקט, ואף אחד לא אסר להוסיף להם איזשהו מכלול משותף או תחום ולעשות בהם שימוש חוזר. הכלי היחיד שלא אפשר לנו לעשות זאת היה סקירת קוד. אבל לפעמים זה גם נכשל.
ואז התחלנו לעבור למודל עם מאגרים נפרדים. ההיגיון העסקי כבר לא זורם משירות לשירות, תחומים באמת הפכו לעצמאיים. הקשרים מוגבלים נתמכים בצורה ברורה יותר. כיצד אנו עושים שימוש חוזר בספריות תשתית? הפרדנו אותם למאגר נפרד, ואז הכנסנו אותם לחבילות Nuget, שהכנסנו ל-Artifactory. עם כל שינוי, ההרכבה והפרסום מתרחשים באופן אוטומטי.
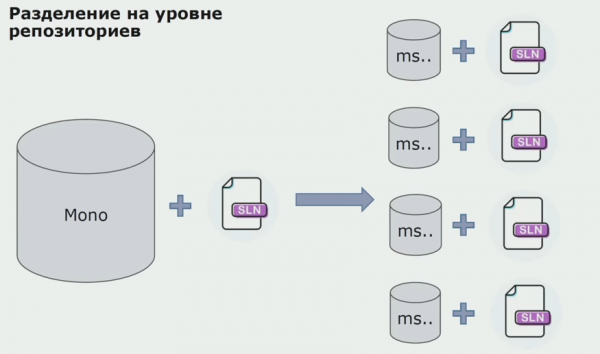
השירותים שלנו החלו להתייחס לחבילות תשתית פנימיות באותו אופן כמו אלה החיצוניות. אנו מורידים ספריות חיצוניות מ- Nuget. כדי לעבוד עם Artifactory, שם שמנו את החבילות הללו, השתמשנו בשני מנהלי חבילות. במאגרים קטנים השתמשנו גם ב- Nuget. במאגרים עם שירותים מרובים, השתמשנו ב-Paket, המספק יותר עקביות גרסאות בין מודולים.
לפיכך, על ידי עבודה על קוד המקור, שינוי קל של הארכיטקטורה והפרדת המאגרים, אנו הופכים את השירותים שלנו לעצמאיים יותר.
בעיות תשתית
רוב החסרונות במעבר לשירותי מיקרו הם הקשורים לתשתית. תזדקק לפריסה אוטומטית, תזדקק לספריות חדשות כדי להפעיל את התשתית.
התקנה ידנית בסביבות
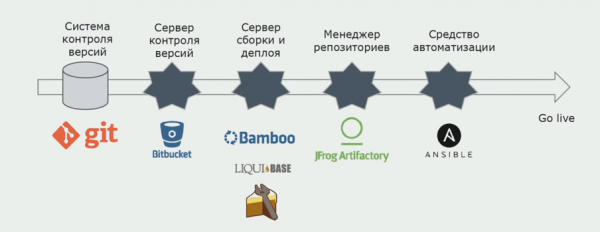
בתחילה, התקנו את הפתרון עבור סביבות באופן ידני. כדי להפוך תהליך זה לאוטומטי, יצרנו צינור CI/CD. בחרנו בתהליך האספקה הרציפה מכיוון שהפריסה הרציפה עדיין לא מקובלת עלינו מנקודת מבט של תהליכים עסקיים. לכן, השליחה לפעולה מתבצעת באמצעות כפתור, ולבדיקה - באופן אוטומטי.
אנו משתמשים ב- Atlassian, Bitbucket לאחסון קוד מקור ובמבוק לבנייה. אנחנו אוהבים לכתוב סקריפטים לבנות ב-Cake כי זה זהה ל-C#. חבילות מוכנות מגיעות ל-Artifactory, ו-Ansible מגיעה אוטומטית לשרתי הבדיקה, ולאחר מכן ניתן לבדוק אותן באופן מיידי.
רישום נפרד
פעם אחת, אחד הרעיונות של המונוליט היה לספק רישום משותף. היינו צריכים גם להבין מה לעשות עם היומנים הבודדים שנמצאים על הדיסקים. היומנים שלנו נכתבים לקבצי טקסט. החלטנו להשתמש בערימת ELK סטנדרטית. לא כתבנו ל-ELK ישירות דרך הספקים, אלא החלטנו שנסיים את יומני הטקסט ונכתוב בהם את מזהה המעקב כמזהה, תוך הוספת שם השירות, כדי שניתן יהיה לנתח את היומנים הללו מאוחר יותר.
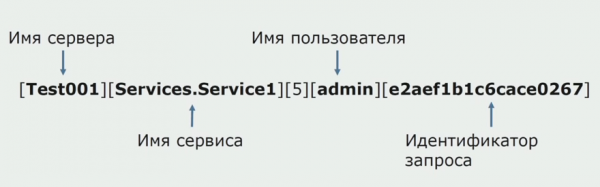
בעזרת Filebeat אנו מסוגלים לאסוף את הלוגים שלנו מ שרתים, לאחר מכן לבצע טרנספורמציה שלהם, להשתמש ב-Kibana כדי לבנות שאילתות בממשק המשתמש ולראות כיצד הקריאה נותבה בין שירותים. מזהי מעקב מועילים מאוד לכך.
שירותים הקשורים לבדיקה ואיתור באגים
בתחילה, לא הבנו עד הסוף כיצד לנפות באגים בשירותים המפותחים. הכל היה פשוט עם המונוליט; הרצנו אותו במכונה מקומית. בהתחלה ניסו לעשות את אותו הדבר עם מיקרו-שירותים, אבל לפעמים כדי להפעיל מיקרו-שירות אחד באופן מלא צריך להפעיל כמה אחרים, וזה לא נוח. הבנו שעלינו לעבור למודל שבו נשאיר במכונה המקומית רק את השירות או השירותים שאנו רוצים לנפות באגים. השירותים הנותרים משמשים משרתים התואמים את התצורה עם prod. לאחר איתור באגים, במהלך הבדיקה, עבור כל משימה, רק השירותים שהשתנו מונפקים לשרת הבדיקה. כך, הפתרון נבדק בצורה שבה הוא יופיע בייצור בעתיד.
ישנם שרתים שמריצים רק גרסאות ייצור של שירותים. שרתים אלו נחוצים במקרה של תקריות, כדי לבדוק מסירה לפני הפריסה ולהדרכה פנימית.
הוספנו תהליך בדיקה אוטומטי באמצעות ספריית Specflow הפופולרית. בדיקות פועלות אוטומטית באמצעות NUnit מיד לאחר הפריסה מ-Ansible. אם כיסוי המשימות הוא אוטומטי לחלוטין, אין צורך בבדיקה ידנית. למרות שלפעמים עדיין נדרשת בדיקה ידנית נוספת. אנו משתמשים בתגים ב-Jira כדי לקבוע אילו בדיקות להפעיל עבור בעיה ספציפית.
בנוסף, הצורך בבדיקת עומס גדל; בעבר זה בוצע רק במקרים נדירים. אנו משתמשים ב-JMeter כדי להריץ בדיקות, ב-InfluxDB כדי לאחסן אותם, וב-Grafana כדי לבנות גרפי תהליכים.
מה השגנו?
ראשית, נפטרנו מהמושג "שחרור". נגמרו המהדורות המפלצתיות של חודשיים כאשר הקולוסוס הזה נפרס בסביבת ייצור, תוך שיבוש זמני של תהליכים עסקיים. כעת אנו פורסים שירותים בממוצע כל 1,5 ימים, ומקבצים אותם מכיוון שהם נכנסים לפעולה לאחר אישור.
אין תקלות קטלניות במערכת שלנו. אם נשחרר שירות מיקרו עם באג, הפונקציונליות הקשורה אליו תישבר, וכל פונקציונליות אחרת לא תושפע. זה משפר מאוד את חווית המשתמש.
אנחנו יכולים לשלוט בדפוס הפריסה. ניתן לבחור קבוצות שירותים בנפרד משאר הפתרון, במידת הצורך.
בנוסף, צמצמנו משמעותית את הבעיה עם תור גדול של שיפורים. יש לנו כעת צוותי מוצר נפרדים שעובדים עם חלק מהשירותים באופן עצמאי. תהליך Scrum כבר מתאים כאן. לצוות ספציפי יכול להיות בעל מוצר נפרד שמקצה לו משימות.
תקציר
- שירותי מיקרו מתאימים היטב לפירוק מערכות מורכבות. תוך כדי כך אנחנו מתחילים להבין מה יש במערכת שלנו, איזה הקשרים מוגבלים יש, איפה הגבולות שלהם. זה מאפשר לך להפיץ נכון שיפורים בין מודולים ולמנוע בלבול קוד.
- שירותי מיקרו מספקים יתרונות ארגוניים. לעתים קרובות מדברים עליהם רק כעל ארכיטקטורה, אבל כל ארכיטקטורה נחוצה כדי לפתור את הצרכים העסקיים, ולא בפני עצמה. לכן, אנו יכולים לומר ששירותי מיקרו מתאימים היטב לפתרון בעיות בצוותים קטנים, בהתחשב בעובדה ש-Scrum פופולרי מאוד כעת.
- הפרדה היא תהליך איטרטיבי. אתה לא יכול לקחת אפליקציה ופשוט לחלק אותה למיקרו-שירותים. לא סביר שהמוצר המתקבל יהיה פונקציונלי. בעת הקדשת שירותי מיקרו, כדאי לשכתב את המורשת הקיימת, כלומר להפוך אותה לקוד שאנו אוהבים ועונה טוב יותר על הצרכים העסקיים מבחינת פונקציונליות ומהירות.
אזהרה קטנה: עלויות המעבר לשירותי מיקרו הן משמעותיות למדי. לקח הרבה זמן לפתור את בעיית התשתית לבד. אז אם יש לך אפליקציה קטנה שאינה דורשת קנה מידה ספציפי, אלא אם יש לך מספר רב של לקוחות שמתחרים על תשומת הלב והזמן של הצוות שלך, ייתכן שמיקרו-שירותים אינם מה שאתה צריך היום. זה די יקר. אם אתה מתחיל את התהליך עם microservices, אז העלויות בהתחלה יהיו גבוהות יותר מאשר אם תתחיל באותו פרויקט עם פיתוח של מונוליט.
נ.ב סיפור יותר מרגש (וכאילו לך אישית) - לפי .
הנה הגרסה המלאה של הדו"ח.
מקור: www.habr.com
