

אחד התרחישים האופייניים בכל האפליקציות שאנו מכירים הוא חיפוש נתונים לפי קריטריונים מסוימים והצגתם בצורה קלה לקריאה. ייתכנו גם אפשרויות נוספות למיון, קיבוץ והחלפה. המשימה היא, בתיאוריה, טריוויאלית, אבל כשפותרים אותה מפתחים רבים עושים מספר טעויות, שבהמשך גורמות לסבל לפרודוקטיביות. בואו ננסה לשקול אפשרויות שונות לפתרון בעיה זו ולגבש המלצות לבחירת היישום היעיל ביותר.

אפשרות ההחלפה מס' 1
האפשרות הפשוטה ביותר שעולה בראש היא הצגת תוצאות חיפוש עמוד אחר עמוד בצורה הקלאסית ביותר שלה.
נניח שהאפליקציה שלך משתמשת במסד נתונים יחסי. במקרה זה, כדי להציג מידע בצורה זו, תצטרך להריץ שתי שאילתות SQL:
- קבל שורות עבור הדף הנוכחי.
- חשב את המספר הכולל של השורות המתאימים לקריטריוני החיפוש - זה הכרחי להצגת דפים.
הבה נסתכל על השאילתה הראשונה באמצעות מסד נתונים MS SQL לבדיקה כדוגמה עבור שרת 2016. לשם כך נשתמש בטבלת Sales.SalesOrderHeader:
SELECT * FROM Sales.SalesOrderHeader
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
השאילתה לעיל תחזיר את 50 ההזמנות הראשונות מהרשימה, ממוינות לפי תאריך יורד של הוספה, במילים אחרות, 50 ההזמנות האחרונות.
זה פועל במהירות על בסיס הבדיקה, אבל בואו נסתכל על תוכנית הביצוע וסטטיסטיקות I/O:
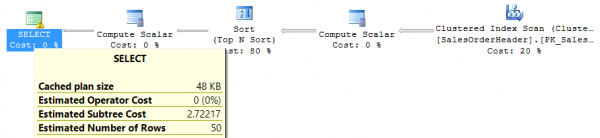
Table 'SalesOrderHeader'. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.אתה יכול לקבל נתונים סטטיסטיים של קלט/פלט עבור כל שאילתה על ידי הפעלת הפקודה SET STATISTICS IO ON בזמן הריצה של השאילתה.
כפי שניתן לראות מתוכנית הביצוע, האפשרות עתירת המשאבים היא למיין את כל השורות של טבלת המקור לפי תאריך הוספה. והבעיה היא שככל שיופיעו יותר שורות בטבלה, המיון יהיה "קשה יותר". בפועל, יש להימנע ממצבים כאלה, אז בואו נוסיף מדד לתאריך ההוספה ונראה אם השתנתה צריכת המשאבים:
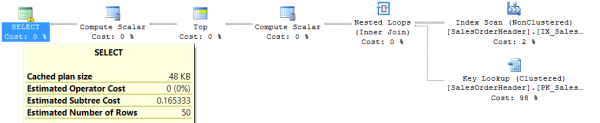
Table 'SalesOrderHeader'. Scan count 1, logical reads 165, physical reads 0, read-ahead reads 5, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
ברור שזה השתפר בהרבה. אבל האם כל הבעיות נפתרות? בואו נשנה את השאילתה כדי לחפש הזמנות שבהן העלות הכוללת של הסחורה עולה על 100$:
SELECT * FROM Sales.SalesOrderHeader
WHERE SubTotal > 100
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY

Table 'SalesOrderHeader'. Scan count 1, logical reads 1081, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.יש לנו מצב מצחיק: תוכנית השאילתות לא גרועה בהרבה מהקודמת, אבל המספר האמיתי של קריאות לוגיות גדול כמעט פי שניים מאשר בסריקת טבלה מלאה. יש מוצא - אם נעשה אינדקס מורכב ממדד שכבר קיים ונוסיף את המחיר הכולל של הסחורה כשדה השני, נקבל שוב 165 קריאות הגיוניות:
CREATE INDEX IX_SalesOrderHeader_OrderDate_SubTotal on Sales.SalesOrderHeader(OrderDate, SubTotal);
ניתן להמשיך את סדרת הדוגמאות הזו לאורך זמן, אך שתי המחשבות העיקריות שברצוני להביע כאן הן:
- להוספת כל קריטריון או סדר מיון חדש לשאילתת חיפוש יכולה להיות השפעה משמעותית על מהירות שאילתת החיפוש.
- אבל אם אנחנו צריכים להחסיר רק חלק מהנתונים, ולא את כל התוצאות שתואמות את מונחי החיפוש, ישנן דרכים רבות לייעל שאילתה כזו.
כעת נעבור לשאילתה השנייה שהוזכרה ממש בהתחלה - זו שסופרת את מספר הרשומות העומדות בקריטריון החיפוש. ניקח את אותה דוגמה - חיפוש אחר הזמנות בעלות של יותר מ-$100:
SELECT COUNT(1) FROM Sales.SalesOrderHeader
WHERE SubTotal > 100
בהתחשב באינדקס המשולב המצוין לעיל, אנו מקבלים:
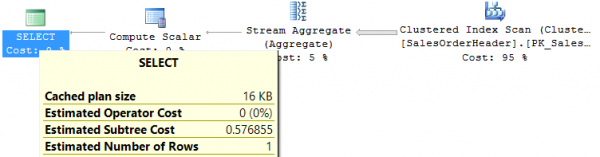
Table 'SalesOrderHeader'. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.העובדה שהשאילתה עוברת על כל האינדקס אינה מפתיעה, שכן השדה SubTotal אינו במיקום הראשון, ולכן השאילתה לא יכולה להשתמש בו. הבעיה נפתרת על ידי הוספת אינדקס נוסף בשדה SubTotal, וכתוצאה מכך הוא נותן רק 48 קריאות לוגיות.
אתה יכול לתת עוד כמה דוגמאות לבקשות לספירת כמויות, אבל המהות נשארת זהה: קבלת נתון וספירת הסכום הכולל הן שתי בקשות שונות מהותית, וכל אחד דורש אמצעים משלו לאופטימיזציה. באופן כללי, לא תוכל למצוא שילוב של אינדקסים שעובד באותה מידה עבור שתי השאילתות.
בהתאם לכך, אחת הדרישות החשובות שצריך להבהיר בעת פיתוח פתרון חיפוש כזה היא האם באמת חשוב לעסק לראות את סך החפצים שנמצאו. לעתים קרובות קורה שלא. וניווט לפי מספרי עמודים ספציפיים, לדעתי, הוא פתרון עם היקף צר מאוד, מכיוון שרוב תרחישי ההחלפה נראים כמו "עבור לדף הבא".
אפשרות ההחלפה מס' 2
הבה נניח שלמשתמשים לא אכפת לדעת את המספר הכולל של אובייקטים שנמצאו. בואו ננסה לפשט את דף החיפוש:
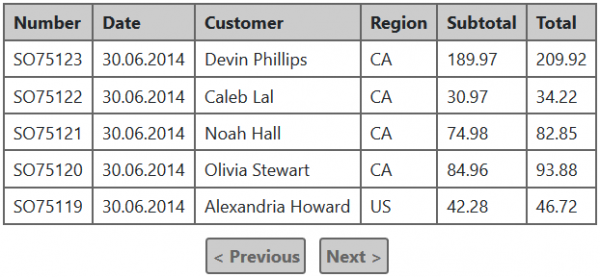
למעשה, הדבר היחיד שהשתנה הוא שאין דרך לנווט למספרי עמודים ספציפיים, ועכשיו הטבלה הזו לא צריכה לדעת כמה יכולים להיות כדי להציג אותה. אבל נשאלת השאלה - איך הטבלה יודעת אם יש נתונים עבור העמוד הבא (כדי להציג נכון את הקישור "הבא")?
התשובה פשוטה מאוד: אתה יכול לקרוא ממסד הנתונים רשומה אחת יותר מהדרוש לתצוגה, והנוכחות של רשומה "נוספת" זו תראה אם יש חלק הבא. בדרך זו, אתה צריך רק להפעיל בקשה אחת כדי לקבל עמוד אחד של נתונים, מה שמשפר משמעותית את הביצועים ומקל על התמיכה בפונקציונליות כזו. בתרגול שלי, היה מקרה שבו סירוב לספור את המספר הכולל של הרשומות האיץ את מסירת התוצאות פי 4-5.
ישנן מספר אפשרויות ממשק משתמש לגישה זו: פקודות "אחורה" ו"קדימה", כמו בדוגמה למעלה, כפתור "טען עוד", שפשוט מוסיף חלק חדש לתוצאות המוצגות, "גלילה אינסופית", שעובד על העיקרון של "טען יותר" ", אבל האות לקבל את החלק הבא הוא שהמשתמש יגלול את כל התוצאות המוצגות עד הסוף. לא משנה מה הפתרון החזותי, עקרון דגימת הנתונים נשאר זהה.
ניואנסים של יישום ההחלפה
כל דוגמאות השאילתה שניתנו לעיל משתמשות בגישת "היסט + ספירה", כאשר השאילתה עצמה מציינת באיזה סדר שורות התוצאה וכמה שורות יש להחזיר. ראשית, הבה נבחן כיצד לארגן את העברת הפרמטרים בצורה הטובה ביותר במקרה זה. בפועל, נתקלתי במספר שיטות:
- המספר הסידורי של העמוד המבוקש (pageIndex), גודל העמוד (pageSize).
- המספר הסידורי של הרשומה הראשונה שיש להחזיר (startIndex), המספר המרבי של רשומות בתוצאה (ספירה).
- מספר הרצף של הרשומה הראשונה שיש להחזיר (startIndex), מספר הרצף של הרשומה האחרונה שתוחזר (endIndex).
במבט ראשון אולי נראה שזה כל כך אלמנטרי שאין הבדל. אבל זה לא כך - האפשרות הנוחה והאוניברסלית ביותר היא השנייה (startIndex, ספירה). יש לכך מספר סיבות:
- עבור גישת ההגהה של ערך 1+ שניתנה לעיל, האפשרות הראשונה עם pageIndex ו-pageSize היא מאוד לא נוחה. לדוגמה, אנו רוצים להציג 50 פוסטים בעמוד. לפי האלגוריתם לעיל, עליך לקרוא רשומה אחת יותר מהנדרש. אם ה-"+1" הזה לא מיושם בשרת, מסתבר שבעמוד הראשון עלינו לבקש רשומות מ-1 עד 51, עבור השני - מ-51 עד 101 וכו'. אם תציין גודל עמוד של 51 ותגדיל את pageIndex, העמוד השני יחזור מ-52 ל-102 וכו'. בהתאם לכך, באפשרות הראשונה, הדרך היחידה ליישם כראוי כפתור למעבר לעמוד הבא היא לגרום לשרת להגיה את השורה ה"נוספת", שתהיה ניואנס מאוד מרומז.
- האפשרות השלישית לא הגיונית כלל, שכן כדי להריץ שאילתות ברוב מסדי הנתונים עדיין תצטרך לעבור את הספירה ולא את האינדקס של הרשומה האחרונה. הפחתת startIndex מ-endIndex עשויה להיות פעולה אריתמטית פשוטה, אבל היא מיותרת כאן.
כעת עלינו לתאר את החסרונות של יישום ההחלפה באמצעות "קיזוז + כמות":
- שליפה של כל עמוד עוקב תהיה יקרה ואיטית יותר מהקודם, מכיוון שבסיס הנתונים עדיין יצטרך לעבור על כל הרשומות "מההתחלה" לפי קריטריוני החיפוש והמיון, ולאחר מכן לעצור בקטע הרצוי.
- לא כל DBMSs יכולים לתמוך בגישה זו.
יש חלופות, אבל הן גם לא מושלמות. הראשונה מבין הגישות הללו נקראת "החלפת מפתחות" או "שיטת חיפוש" והיא כדלקמן: לאחר קבלת מנה, תוכל לזכור את ערכי השדות ברשומה האחרונה בדף, ולאחר מכן להשתמש בהם כדי לקבל החלק הבא. לדוגמה, הרצנו את השאילתה הבאה:
SELECT * FROM Sales.SalesOrderHeader
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
וברשומה האחרונה קיבלנו את ערך תאריך ההזמנה '2014-06-29'. ואז כדי לקבל את הדף הבא אתה יכול לנסות לעשות זאת:
SELECT * FROM Sales.SalesOrderHeader
WHERE OrderDate < '2014-06-29'
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
הבעיה היא ש-OrderDate הוא שדה לא ייחודי וסביר להניח שהמצב שצוין לעיל יפספס הרבה שורות נדרשות. כדי להוסיף חד-משמעות לשאילתה זו, עליך להוסיף שדה ייחודי לתנאי (נניח ש-75074 הוא הערך האחרון של המפתח הראשי מהחלק הראשון):
SELECT * FROM Sales.SalesOrderHeader
WHERE (OrderDate = '2014-06-29' AND SalesOrderID < 75074)
OR (OrderDate < '2014-06-29')
ORDER BY OrderDate DESC, SalesOrderID DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
אפשרות זו תעבוד נכון, אך באופן כללי יהיה קשה לבצע אופטימיזציה מכיוון שהתנאי מכיל אופרטור OR. אם הערך של המפתח הראשי גדל עם עליית OrderDate, ניתן לפשט את התנאי על ידי השארת מסנן בלבד לפי SalesOrderID. אבל אם אין מתאם קפדני בין הערכים של המפתח הראשי והשדה שלפיו ממוינת התוצאה, לא ניתן להימנע מ-OR זה ברוב ה-DBMSs. יוצא מן הכלל שאני מכיר הוא PostgreSQL, שתומך באופן מלא בהשוואות tuple, וניתן לכתוב את התנאי לעיל בתור "WHERE (OrderDate, SalesOrderID) < ('2014-06-29', 75074)". בהינתן מפתח מורכב עם שני השדות הללו, שאילתה כזו אמורה להיות קלה למדי.
גישה חלופית שנייה ניתן למצוא, למשל, ב או - כאשר בקשה, בנוסף לנתונים, מחזירה מזהה מיוחד שבאמצעותו תוכל לקבל את החלק הבא של הנתונים. אם למזהה זה יש אורך חיים בלתי מוגבל (כמו ב-Comsos DB), זו דרך מצוינת ליישם את ההחלפה עם מעבר רציף בין הדפים (אפשרות מס' 2 שהוזכרה לעיל). החסרונות האפשריים שלו: זה לא נתמך בכל DBMSs; למזהה הנתח הבא המתקבל עשוי להיות משך חיים מוגבל, מה שבדרך כלל אינו מתאים ליישום אינטראקציה של משתמשים (כגון ה-API של ElasticSearch scroll).
סינון מורכב
בואו נסבך את המשימה עוד יותר. נניח שישנה דרישה ליישם את מה שנקרא חיפוש פנים, המוכר מאוד לכולם מחנויות מקוונות. הדוגמאות לעיל המבוססות על טבלת ההזמנות אינן ממחישות במיוחד במקרה זה, אז בואו נעבור לטבלת המוצר ממסד הנתונים של AdventureWorks:
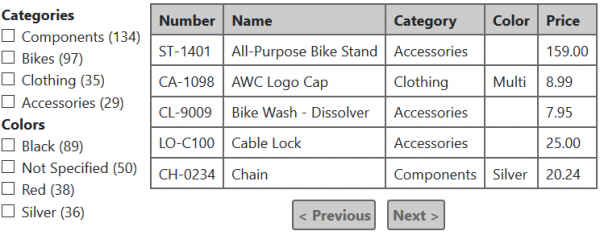
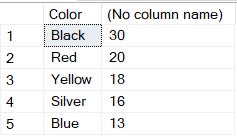
מה הרעיון מאחורי חיפוש פנים? העובדה היא שלכל רכיב סינון מוצג מספר הרשומות העומדות בקריטריון זה תוך התחשבות במסננים שנבחרו בכל שאר הקטגוריות.
לדוגמה, אם נבחר את קטגוריית האופניים ואת הצבע השחור בדוגמה זו, הטבלה תציג רק אופניים שחורים, אך:
- עבור כל קריטריון בקבוצת הקטגוריות, מספר המוצרים מאותה קטגוריה יוצג בשחור.
- עבור כל קריטריון של קבוצת "צבעים", יוצג מספר האופניים בצבע זה.
הנה דוגמה לפלט התוצאה עבור תנאים כאלה:
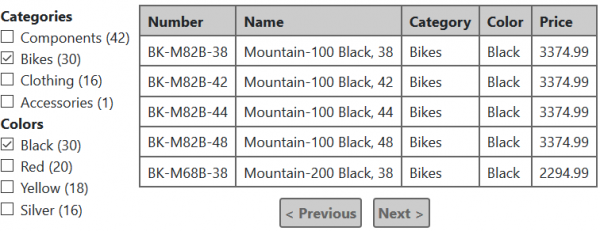
אם תבדקו גם את קטגוריית "לבוש", הטבלה תציג גם בגדים שחורים שנמצאים במלאי. גם מספר המוצרים השחורים בסעיף "צבע" יחושב מחדש בהתאם לתנאים החדשים, רק בסעיף "קטגוריות" שום דבר לא ישתנה... אני מקווה שהדוגמאות האלה מספיקות כדי להבין את אלגוריתם החיפוש הרגיל.
כעת בואו נדמיין כיצד ניתן ליישם זאת על בסיס יחסי. כל קבוצת קריטריונים, כגון קטגוריה וצבע, תדרוש שאילתה נפרדת:
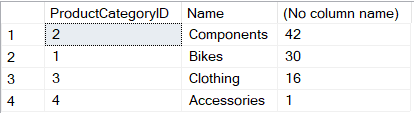
SELECT pc.ProductCategoryID, pc.Name, COUNT(1) FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
INNER JOIN Production.ProductCategory pc ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE p.Color = 'Black'
GROUP BY pc.ProductCategoryID, pc.Name
ORDER BY COUNT(1) DESC
SELECT Color, COUNT(1) FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE ps.ProductCategoryID = 1 --Bikes
GROUP BY Color
ORDER BY COUNT(1) DESC
מה רע בפתרון הזה? זה מאוד פשוט - זה לא קנה מידה טוב. כל מקטע סינון דורש שאילתה נפרדת לחישוב כמויות, ושאילתות אלו אינן הקלות ביותר. בחנויות מקוונות, קטגוריות מסוימות עשויות לכלול כמה עשרות קטעי סינון, מה שיכול להיות בעיית ביצועים רצינית.
בדרך כלל לאחר ההצהרות הללו מציעים לי כמה פתרונות, כלומר:
- שלב את כל ספירות הכמויות לשאילתה אחת. מבחינה טכנית זה אפשרי באמצעות מילת המפתח UNION, אבל זה לא יעזור הרבה לביצועים - מסד הנתונים עדיין יצטרך לבצע כל אחד מהפרגמנטים מאפס.
- כמויות מטמון. זה מוצע לי כמעט בכל פעם שאני מתאר בעיה. האזהרה היא שבדרך כלל זה בלתי אפשרי. נניח שיש לנו 10 "פנים", שלכל אחד מהם 5 ערכים. זהו מצב מאוד "צנוע" לעומת מה שניתן לראות באותן חנויות מקוונות. הבחירה באלמנט פן אחד משפיעה על הכמויות ב-9 אחרים, במילים אחרות, עבור כל שילוב של קריטריונים הכמויות יכולות להיות שונות. בדוגמה שלנו, יש סה"כ 50 קריטריונים שהמשתמש יכול לבחור, כך שיהיו 250 שילובים אפשריים. אין מספיק זיכרון או זמן כדי למלא מערך כזה של נתונים. כאן אתה יכול להתנגד ולומר שלא כל השילובים הם אמיתיים והמשתמש רק לעתים רחוקות בוחר יותר מ-5-10 קריטריונים. כן, אפשר לעשות טעינה עצלנית ולאחסן כמות של רק מה שנבחר אי פעם, אבל ככל שיהיו יותר מבחר, כך מטמון כזה יהיה פחות יעיל ובעיות זמן התגובה יהיו מורגשות יותר (במיוחד אם מערך הנתונים משתנה באופן קבוע).
למרבה המזל, לבעיה כזו יש כבר מזמן פתרונות יעילים למדי שעובדים באופן צפוי על כמויות גדולות של נתונים. עבור כל אחת מהאפשרויות הללו, הגיוני לחלק את החישוב מחדש של היבטים וקבלת דף התוצאות לשתי קריאות מקבילות לשרת ולארגן את ממשק המשתמש בצורה כזו שטעינת הנתונים לפי היבטים "לא תפריע" לתצוגה של תוצאות חיפוש.
- קרא לחישוב מחדש מלא של "היבטים" לעתים רחוקות ככל האפשר. לדוגמה, אל תחשב הכל מחדש בכל פעם שקריטריוני החיפוש משתנים, אלא מצא את המספר הכולל של התוצאות התואמות את התנאים הנוכחיים ותבקש מהמשתמש להציג אותן - "נמצאו 1425 רשומות, הצג?" המשתמש יכול להמשיך לשנות את מונחי החיפוש או ללחוץ על כפתור "הצג". רק במקרה השני יבוצעו כל הבקשות לקבלת תוצאות וחישוב מחדש של כמויות על כל "ההיבטים". במקרה זה, כפי שניתן לראות בקלות, תצטרכו להתמודד עם בקשה לקבלת סך התוצאות והאופטימיזציה שלה. שיטה זו ניתן למצוא בחנויות מקוונות קטנות רבות. ברור שזו לא תרופת פלא לבעיה הזו, אבל במקרים פשוטים היא יכולה להיות פשרה טובה.
- השתמש במנועי חיפוש כדי למצוא תוצאות ולספור היבטים, כגון Solr, ElasticSearch, Sphinx ואחרים. כולם נועדו לבנות "היבטים" ולעשות זאת בצורה יעילה למדי בשל המדד ההפוך. איך פועלים מנועי חיפוש, למה במקרים כאלה הם יעילים יותר ממאגרי מידע כלליים, אילו שיטות ומלכודות יש - זה נושא למאמר נפרד. כאן אני רוצה להסב את תשומת לבכם לכך שמנוע החיפוש אינו יכול להוות תחליף לאחסון הנתונים הראשי, הוא משמש כתוספת: כל שינוי במסד הנתונים הראשי הרלוונטי לחיפוש מסונכרן לאינדקס החיפוש; מנוע החיפוש בדרך כלל מקיים אינטראקציה רק עם מנוע החיפוש ואינו ניגש למסד הנתונים הראשי. אחת הנקודות החשובות ביותר כאן היא כיצד לארגן את הסנכרון הזה בצורה מהימנה. הכל תלוי בדרישות "זמן התגובה". אם הזמן בין שינוי במסד הנתונים הראשי ל"התגלותו" בחיפוש אינו קריטי, ניתן ליצור שירות שמחפש כל כמה דקות רשומות שהשתנו לאחרונה ומאנדקס אותן. אם אתה רוצה את זמן התגובה הקצר ביותר האפשרי, אתה יכול ליישם משהו כמו לשלוח עדכונים לשירות החיפוש.
ממצאים
- יישום ההחלפה בצד השרת הוא סיבוך משמעותי והגיוני רק עבור מערכי נתונים שגדלים במהירות או פשוט גדולים. אין מתכון מדויק לחלוטין לאיך להעריך "גדול" או "צומח מהר", אבל הייתי פועל לפי הגישה הזו:
- אם קבלת אוסף שלם של נתונים, תוך התחשבות בזמן השרת והעברת הרשת, תואמת את דרישות הביצועים בדרך כלל, אין טעם ליישם את ההחלפה בצד השרת.
- יתכן מצב שבו לא צפויות בעיות ביצועים בזמן הקרוב, מכיוון שיש מעט נתונים, אך איסוף הנתונים גדל כל הזמן. אם קבוצת נתונים כלשהי בעתיד לא תעמוד עוד בנקודה הקודמת, עדיף להתחיל את ההחלפה מיד.
- אם אין דרישה קפדנית מצד העסק להציג את סך התוצאות או להציג מספרי עמודים, ולמערכת שלכם אין מנוע חיפוש, עדיף לא ליישם את הנקודות הללו ולשקול אפשרות מס' 2.
- אם ישנה דרישה ברורה לחיפוש היבטי, יש לך שתי אפשרויות מבלי להקריב את הביצועים:
- אין לחשב מחדש את כל הכמויות בכל פעם שקריטריוני החיפוש משתנים.
- השתמש במנועי חיפוש כגון Solr, ElasticSearch, Sphinx ואחרים. אבל צריך להבין שהוא לא יכול להוות תחליף למסד הנתונים הראשי, ויש להשתמש בו כתוספת לאחסון הראשי לפתרון בעיות חיפוש.
- כמו כן, במקרה של חיפוש פנים, הגיוני לפצל את שליפת דף תוצאות החיפוש ואת הספירה לשתי בקשות מקבילות. ספירת כמויות עשויה להימשך זמן רב יותר מאשר השגת תוצאות, בעוד שהתוצאות חשובות יותר למשתמש.
- אם אתה משתמש במסד נתונים של SQL לחיפוש, כל שינוי קוד הקשור לחלק זה צריך להיבדק היטב עבור ביצועים בכמות הנתונים המתאימה (החורגת מהנפח במסד הנתונים החי). כמו כן, מומלץ להשתמש בניטור זמן ביצוע שאילתה בכל המופעים של בסיס הנתונים, ובמיוחד ב"חי". גם אם הכל היה בסדר עם תוכניות שאילתות בשלב הפיתוח, ככל שנפח הנתונים גדל, המצב עשוי להשתנות באופן ניכר.
מקור: www.habr.com
