


Highload++ жана DataFest Минск 2019да сүйлөгөн сөздөрүмдүн негизинде.
Бүгүнкү күндө көптөр үчүн почта онлайн жашоонун ажырагыс бөлүгү болуп саналат. Анын жардамы менен биз иштиктүү кат алышууларды жүргүзөбүз, каржы, мейманканаларды ээлөө, заказдарды жайгаштыруу жана башка көптөгөн маанилүү маалыматтарды сактайбыз. 2018-жылдын ортосунда биз почтаны өнүктүрүү үчүн продукт стратегиясын иштеп чыктык. Заманбап почта кандай болушу керек?
Почта болушу керек акылдуу, башкача айтканда, колдонуучуларга маалыматтын өсүп келе жаткан көлөмүн багыттоого жардам берүү: чыпкалоо, түзүмдөө жана аны эң ыңгайлуу жол менен камсыз кылуу. Ал болсо керек пайдалуу, ар кандай тапшырмаларды почта ящигиңизде чечүүгө мүмкүндүк берет, мисалы, айыптарды төлөө (тилекке каршы, мен колдоном). Жана ошол эле учурда, албетте, почта маалыматты коргоону, спамдарды өчүрүүнү жана хакерликтен коргоону камсыз кылышы керек, б.а. коопсуз.
Бул багыттар бир катар негизги көйгөйлөрдү аныктайт, алардын көбүн машина үйрөнүү аркылуу натыйжалуу чечсе болот. Бул жерде стратегиянын бир бөлүгү катары иштелип чыккан бар болгон функциялардын мисалдары келтирилген - ар бир багыт үчүн бирден.
- Smart жооп берүү. Почтада акылдуу жооп берүү функциясы бар. Нейрондук тармак каттын текстин талдап, анын маанисин жана максатын түшүнөт жана натыйжада жооптун эң ылайыктуу үч вариантын сунуштайт: оң, терс жана нейтралдуу. Бул каттарга жооп берип жатканда убакытты үнөмдөөгө жардам берет, ошондой эле көп учурда стандарттуу эмес жана күлкүлүү жол менен жооп берет.
- Электрондук каттарды топтооонлайн дүкөндөрдө буйрутмаларга байланыштуу. Биз көбүнчө онлайн дүкөндөр, жана, эреже катары, дүкөндөр ар бир заказ үчүн бир нече электрондук кат жөнөтө алат. Мисалы, эң чоң кызмат болгон AliExpressдан бир заказ үчүн көптөгөн тамгалар келет жана терминалдык учурда алардын саны 29га чейин жетээрин эсептеп чыктык. Ошондуктан, Аты аталган объектти таануу моделин колдонуп, буйрутма номерин чыгарабыз. жана тексттеги башка маалымат жана бардык тамгаларды бир жипке топтоо. Биз ошондой эле буйрутма тууралуу негизги маалыматты өзүнчө кутучада көрсөтөбүз, бул электрондук почтанын бул түрү менен иштөөнү жеңилдетет.

- Фишингге каршы. Фишинг – бул электрондук почтанын өзгөчө коркунучтуу, алдамчылык түрү, анын жардамы менен чабуулчулар каржылык маалыматты (анын ичинде колдонуучунун банк карталарын) жана логиндерди алууга аракет кылышат. Мындай каттар кызмат тарабынан жөнөтүлгөн реалдуу каттарды, анын ичинде визуалдык түрдө да туурайт. Ошондуктан, Computer Vision жардамы менен биз логотиптерди жана ири компаниялардын (мисалы, Mail.ru, Sber, Alfa) каттарынын дизайн стилин тааныйбыз жана муну спам жана фишинг классификаторлорубуздагы текст жана башка өзгөчөлүктөр менен бирге эске алабыз. .
машина үйрөнүү
Жалпысынан электрондук почта боюнча машина үйрөнүү жөнүндө бир аз. Почта – бул өтө жүктөлгөн система: 1,5 миллион DAU колдонуучулары үчүн серверлерибиз аркылуу күнүнө орточо 30 миллиард кат өтөт. 30га жакын машина үйрөнүү системалары бардык керектүү функцияларды жана функцияларды колдойт.
Ар бир тамга бүтүндөй классификация түтүктөрү аркылуу өтөт. Алгач биз спамды кесип, жакшы каттарды калтырабыз. Колдонуучулар көп учурда антиспамдын ишин байкашпайт, анткени спамдын 95-99% тиешелүү папкага да түшпөйт. Спамды таануу системабыздын абдан маанилүү бөлүгү жана эң кыйыны, анткени антиспам чөйрөсүндө коргонуу жана чабуул системаларынын ортосунда туруктуу адаптация бар, бул биздин команда үчүн үзгүлтүксүз инженердик кыйынчылыктарды камсыз кылат.
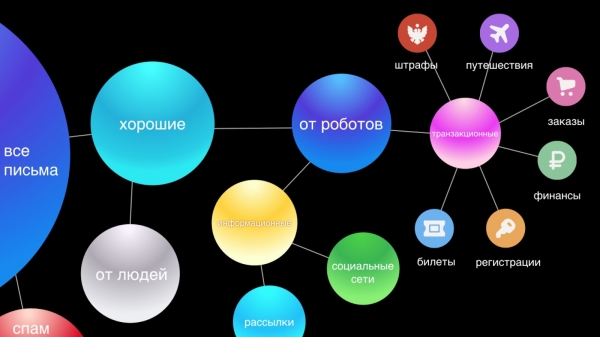
Андан кийин, биз адамдардан жана роботтордон каттарды бөлөбүз. Адамдардын электрондук каттары эң маанилүү, ошондуктан биз алар үчүн Smart Reply сыяктуу функцияларды беребиз. Роботтордун каттары эки бөлүккө бөлүнөт: транзакциялык - бул кызмат көрсөтүүлөрдөн маанилүү каттар, мисалы, сатып алууларды ырастоо же мейманканадан орун алуу, каржы жана маалыматтык - бул бизнес-жарнак, арзандатуу.
Биз транзакциялык электрондук почталар жеке кат алышууларга бирдей мааниге ээ деп эсептейбиз. Алар колунда болушу керек, анткени биз көбүнчө заказ же авиабилет тууралуу маалыматты тез таап алышыбыз керек жана биз бул каттарды издөөгө убакыт короттук. Ошондуктан, ыңгайлуулук үчүн биз аларды автоматтык түрдө алты негизги категорияга бөлөбүз: саякат, буйрутмалар, каржы, билеттер, каттоо жана, акырында, айыптар.
Маалымат каттары эң чоң жана анча маанилүү эмес топ болуп саналат, алар дароо жооп берүүнү талап кылбайт, анткени колдонуучунун жашоосунда олуттуу эч нерсе өзгөрбөйт, эгерде ал мындай катты окубаса. Жаңы интерфейсибизде биз аларды эки жипке жыйыштырабыз: социалдык тармактар жана маалымат бюллетендери, ошентип кириш кутусун визуалдык түрдө тазалап, маанилүү билдирүүлөрдү гана көрүнөө калтырабыз.
колдонуу
Көп сандаган системалар иштөөдө көптөгөн кыйынчылыктарды жаратат. Анткени, моделдер ар кандай программалык камсыздоо сыяктуу убакыттын өтүшү менен начарлайт: функциялар бузулат, машиналар иштебей калат, код кыйшык болуп калат. Мындан тышкары, маалыматтар тынымсыз өзгөрүп турат: жаңылары кошулат, колдонуучунун жүрүм-туруму өзгөрөт ж.б.
Машиналарды үйрөнүү колдонуучулардын жашоосуна канчалык терең кирсе, алардын экосистемага тийгизген таасири ошончолук чоң болорун жана натыйжада рыноктун оюнчулары ошончолук көп каржылык жоготууларды же пайда алаарын унутпашыбыз керек. Ошондуктан, өсүп жаткан аймактарда оюнчулар ML алгоритмдеринин ишине ыңгайлашууда (классикалык мисалдар жарнама, издөө жана буга чейин айтылган антиспам).
Ошондой эле, машинаны үйрөнүү тапшырмаларынын бир өзгөчөлүгү бар: системадагы кандайдыр бир, атүгүл майда-чүйдө өзгөрүүлөр модел менен көп ишти жаратышы мүмкүн: маалыматтар менен иштөө, кайра даярдоо, жайылтуу, ал жумалар же айлар талап кылынышы мүмкүн. Ошондуктан, моделдериңиз иштеген чөйрө канчалык тез өзгөрсө, аларды сактоо үчүн ошончолук көп күч-аракет талап кылынат. Команда көптөгөн системаларды түзүп, ага ыраазы боло алат, бирок андан кийин дээрлик бардык ресурстарын жаңы эч нерсе жасоого мүмкүнчүлүгү жок, аларды сактоого жумшайт. Биз антиспам командасында мындай абалга жолукканбыз. Жана алар колдоону автоматташтыруу керек деген айкын корутундуга келишти.
автоматизация
Эмнени автоматташтырууга болот? Дээрлик баары, чынында. Мен машинаны үйрөнүү инфраструктурасын аныктаган төрт аймакты аныктадым:
- маалыматтарды чогултуу;
- кошумча машыгуу;
- жайылтуу;
- сыноо жана мониторинг.
Эгерде айлана-чөйрө туруксуз жана дайыма өзгөрүп турса, анда моделдин айланасындагы бардык инфраструктура моделдин өзүнөн алда канча маанилүү болуп чыгат. Бул жакшы эски сызыктуу классификатор болушу мүмкүн, бирок сиз ага туура функцияларды берип, колдонуучулардан жакшы пикирлерди алсаңыз, ал бардык коңгуроолору жана ышкырыгы бар заманбап үлгүлөргө караганда алда канча жакшыраак иштейт.
Пикир байланыш цикли
Бул цикл маалыматтарды чогултууну, кошумча окутууну жана жайылтууну айкалыштырат - чындыгында, моделди жаңыртуу циклинин бардыгы. Бул эмне үчүн маанилүү? Почтадагы каттоо графигин караңыз:
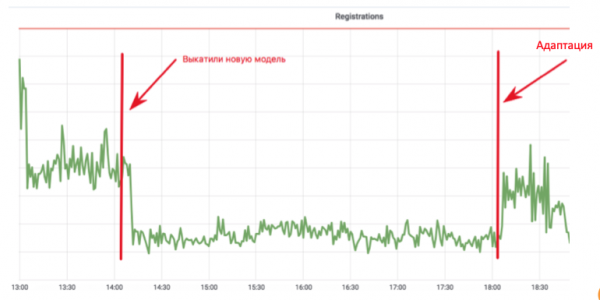
Машинаны үйрөнүүнү иштеп чыгуучу боттордун электрондук почтага катталышына жол бербеген анти-бот моделин ишке ашырды. Диаграмма чыныгы колдонуучулар гана калган мааниге чейин төмөндөйт. Баары сонун! Бирок төрт саат өтүп, боттор скрипттерин оңдоп, баары кадимки абалына келет. Бул ишке ашырууда, иштеп чыгуучу бир ай функцияларды кошуп, моделди кайра даярдоого сарптады, бирок спаммер төрт саатта ыңгайлаша алган.
Мынчалык катуу оорутуп албаш үчүн жана баарын кийинчерээк кайталабоо үчүн, алгач пикир алмашуу цикли кандай болорун жана чөйрө өзгөрсө эмне кылаарыбызды ойлонушубуз керек. Келгиле, маалыматтарды чогултуу менен баштайлы - бул биздин алгоритмдер үчүн отун.
Маалымат чогултуу
Заманбап нейрон тармактары үчүн маалымат канчалык көп болсо, ошончолук жакшы экени түшүнүктүү жана алар чындыгында буюмдун колдонуучулары тарабынан түзүлөт. Колдонуучулар бизге маалыматтарды белгилөө менен жардам бере алышат, бирок биз муну кыянаттык менен пайдалана албайбыз, анткени кайсы бир учурда колдонуучулар сиздин моделдериңизди толтуруудан чарчап, башка продуктуга өтүшөт.
Эң кеңири таралган каталардын бири (бул жерде мен Эндрю Нгге шилтеме жасайм) бул колдонуучунун пикирине эмес, тесттик маалыматтар топтомундагы метрикага өтө көп көңүл буруу, бул ишинин сапатынын негизги өлчөмү, анткени биз колдонуучу үчүн продукт. Колдонуучу моделдин ишин түшүнбөсө же жакпаса, анда баары бузулат.
Ошондуктан, колдонуучу ар дайым добуш берүүгө жөндөмдүү болушу керек жана пикир үчүн курал берилиши керек. Эгерде биз почта кутусуна каржыга байланыштуу кат келди деп ойлосок, анда биз аны "финансы" деп белгилеп, колдонуучу басып, бул каржы эмес деп айта турган баскычты сызышыбыз керек.
Пикир сапаты
Келгиле, колдонуучулардын пикирлеринин сапаты жөнүндө сүйлөшөлү. Биринчиден, сиз жана колдонуучу бир түшүнүккө ар кандай маанилерди киргизе аласыз. Мисалы, сиз жана сиздин продукт менеджерлер "финансы" банктан келген каттарды билдирет деп ойлойсуз, ал эми колдонуучу чоң эненин пенсиясы жөнүндө каты да каржыга тиешелүү деп ойлойт. Экинчиден, эч кандай логикасыз баскычтарды басууну жакшы көргөн колдонуучулар бар. Үчүнчүдөн, колдонуучу өз корутундуларында терең жаңылышы мүмкүн. Биздин практикадан айкын мисал классификатордун ишке ашырылышы болуп саналат , спамдын абдан күлкүлүү түрү, анда колдонуучудан Африкадагы күтүлбөгөн жерден табылган алыскы тууганынан бир нече миллион доллар талап кылынат. Бул классификаторду ишке киргизгенден кийин, биз бул электрондук каттарга "Спам эмес" чыкылдатууларын текшердик жана алардын 80% ширелүү нигериялык спам экени белгилүү болду, бул колдонуучулар өтө ишенчээк болушу мүмкүн экенин көрсөтүп турат.
Ал эми баскычтарды адамдар гана эмес, браузер катары көрүнгөн ар кандай боттор да басышы мүмкүн экенин унутпайлы. Ошентип, чийки пикир үйрөнүү үчүн жакшы эмес. Бул маалымат менен эмне кыла аласыз?
Биз эки ыкманы колдонобуз:
- Шилтемеленген MLден пикир. Мисалы, бизде онлайн анти-бот системасы бар, ал мен айтып өткөндөй, чектелген сандагы белгилердин негизинде тез чечим кабыл алат. Жана фактыдан кийин иштеген экинчи, жай система бар. Анда колдонуучу, анын жүрүм-туруму ж.б.у.с. жөнүндө көбүрөөк маалыматтар бар. Натыйжада, эң негиздүү чечим кабыл алынат, анын тактыгы жана толуктугу жогору болот; Сиз бул системалардын иштөөсүндөгү айырманы окуу маалыматтары катары биринчисине багыттай аласыз. Ошентип, жөнөкөй система ар дайым татаалыраак системанын иштешине жакындоого аракет кылат.
- Классификацияны басыңыз. Сиз жөн гана колдонуучунун ар бир чыкылдатуусун классификациялап, анын жарактуулугун жана колдонууга жарамдуулугун баалай аласыз. Биз муну антиспам почтасында колдонуучунун атрибуттарын, анын тарыхын, жөнөтүүчү атрибуттарын, тексттин өзүн жана классификаторлордун натыйжасын колдонуп жасайбыз. Натыйжада, биз колдонуучулардын пикирлерин тастыктаган автоматтык системаны алабыз. Жана аны азыраак кайра даярдоо керек болгондуктан, анын иши бардык башка системалар үчүн негиз боло алат. Бул моделдеги негизги артыкчылык тактык болуп саналат, анткени моделди так эмес маалыматтарга үйрөтүү кесепеттерге алып келет.
Биз маалыматтарды тазалап, ML системабызды андан ары үйрөтүп жатканыбызда, колдонуучуларды унутпашыбыз керек, анткени биз үчүн графиктеги миңдеген, миллиондогон каталар статистика, ал эми колдонуучу үчүн ар бир ката трагедия. Колдонуучу кандайдыр бир жол менен буюмдагы сиздин катаңыз менен жашашы керек экендигинен тышкары, пикир алгандан кийин, ал ушул сыяктуу жагдай келечекте жоюлат деп күтөт. Ошондуктан, колдонуучуларга добуш берүү мүмкүнчүлүгүн гана бербестен, ошондой эле ML системаларынын жүрүм-турумун оңдоого, мисалы, ар бир пикирди басуу үчүн жеке эвристиканы түзүү керек, бул чыпкалоо мүмкүнчүлүгү болушу мүмкүн; бул колдонуучу үчүн жөнөтүүчү жана аталышы боюнча мындай каттар.
Ошондой эле, башка колдонуучулар ушул сыяктуу көйгөйлөрдөн жапа чегип калбашы үчүн, жарым автоматтык же кол режиминде колдоо көрсөтүү үчүн кээ бир отчеттордун же суроо-талаптардын негизинде үлгү түзүшүңүз керек.
Үйрөнүү үчүн эвристика
Бул эвристика жана балдак менен эки көйгөй бар. Биринчиси, уламдан-улам көбөйүп бараткан балдактарды сактоо кыйын, анын ичинде алардын сапаты жана узак жолдогу иштеши да кыйын. Экинчи маселе, ката тез-тез болбошу мүмкүн жана моделди андан ары окутуу үчүн бир нече чыкылдатуулар жетишсиз болот. Төмөнкү ыкма колдонулса, бул эки байланышы жок эффекттер олуттуу түрдө нейтралдаштырылгандай сезилет.
- Биз убактылуу балдак түзөбүз.
- Биз андан маалыматтарды моделге жөнөтөбүз, ал үзгүлтүксүз жаңырып турат, анын ичинде алынган маалыматтар боюнча. Бул жерде, албетте, окуу топтомундагы маалыматтардын сапатын төмөндөтпөө үчүн эвристиканын жогорку тактыкка ээ болушу маанилүү.
- Андан кийин биз балдакты иштетүү үчүн мониторингди койдук жана бир аз убакыт өткөндөн кийин балдак иштебей калып, модел менен толук жабылса, анда аны коопсуз алып салсаңыз болот. Эми бул көйгөйдүн кайталанышы күмөн.
Андыктан балдактардын армиясы абдан пайдалуу. Эң негизгиси, алардын кызматы шашылыш жана туруктуу эмес.
Кошумча машыгуу
Кайра даярдоо – бул колдонуучулардын же башка системалардын пикирлеринин натыйжасында алынган жаңы маалыматтарды кошуу жана ага колдонуудагы моделди окутуу процесси. Кошумча окутууда бир нече көйгөйлөр болушу мүмкүн:
- Модель жөн гана кошумча окутууну колдобойт, бирок нөлдөн баштап гана үйрөнүшү мүмкүн.
- Табият китебинин эч бир жеринде кошумча окутуу өндүрүштө иштин сапатын жогорулатат деп жазылган эмес. Көп учурда тескерисинче болот, башкача айтканда, бир гана начарлашы мүмкүн.
- Өзгөрүүлөр күтүүсүз болушу мүмкүн. Бул биз өзүбүз үчүн аныктаган өтө тымызын жагдай. A/B тестиндеги жаңы модель учурдагыга салыштырмалуу окшош натыйжаларды көрсөтсө да, бул анын бирдей иштейт дегенди билдирбейт. Алардын иши бир гана пайыз менен айырмаланышы мүмкүн, бул жаңы каталарды алып келиши мүмкүн же буга чейин оңдолгон эскилерин кайтарышы мүмкүн. Биз да, колдонуучулар да учурдагы каталар менен кантип жашоону билебиз жана көп сандагы жаңы каталар пайда болгондо, колдонуучу эмне болуп жатканын түшүнбөй калышы мүмкүн, анткени ал болжолдуу жүрүм-турумду күтөт.
Демек, кошумча окутууда эң негизгиси, моделдин жакшыртылганын, же жок дегенде начарлабагандыгын камсыз кылуу.
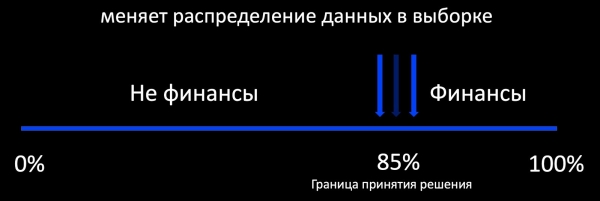
Кошумча окутуу жөнүндө сөз кылганда, биринчи кезекте, бул Active Learning ыкмасы. Бул эмнени билдирет? Мисалы, классификатор электрондук почтанын каржыга тиешеси бар-жогун аныктайт жана анын чечиминин чегинде биз энбелгиленген мисалдардын үлгүсүн кошобуз. Бул жакшы иштейт, мисалы, жарнамада, ал жерде пикир көп жана сиз онлайн режиминде моделди үйрөтө аласыз. Ал эми пикир аз болсо, анда биз өндүрүштүк маалыматтарды бөлүштүрүүгө салыштырмалуу өтө объективдүү үлгүнү алабыз, анын негизинде иш учурунда моделдин жүрүм-турумун баалоо мүмкүн эмес.
Чынында биздин максатыбыз – эски үлгүлөрдү, мурдатан белгилүү болгон моделдерди сактап, жаңы үлгүлөргө ээ болуу. Бул жерде үзгүлтүксүздүк маанилүү. Биз чыгаруу үчүн көп күч жумшаган модель азыр иштеп жатат, андыктан анын иштешине көңүл бурсак болот.
Почтада ар кандай моделдер колдонулат: дарактар, сызыктуу, нейрон тармактары. Ар бири үчүн биз өзүбүздүн кошумча окутуу алгоритмибизди түзөбүз. Кошумча окутуу процессинде биз жаңы маалыматтарды гана эмес, көбүнчө жаңы функцияларды да алабыз, аларды төмөндөгү бардык алгоритмдерде эске алабыз.
Сызыктуу моделдер
Бизде логистикалык регрессия бар дейли. Биз төмөндөгү компоненттерден жоготуу моделин түзөбүз:
- жаңы маалыматтар боюнча LogLoss;
- биз жаңы функциялардын салмагын жөнгө салабыз (эскилерине тийбейбиз);
- эски үлгүлөрдү сактап калуу үчүн эски маалыматтардан да үйрөнөбүз;
- жана, балким, эң негизгиси: биз Гармоникалык Регуляризацияны кошобуз, бул нормага ылайык салмактар эски моделге салыштырмалуу көп өзгөрбөй тургандыгына кепилдик берет.
Ар бир Loss компонентинин коэффициенттери бар болгондуктан, биз кайчылаш валидация аркылуу же продукциянын талаптарынын негизинде биздин милдетибиз үчүн оптималдуу маанилерди тандай алабыз.
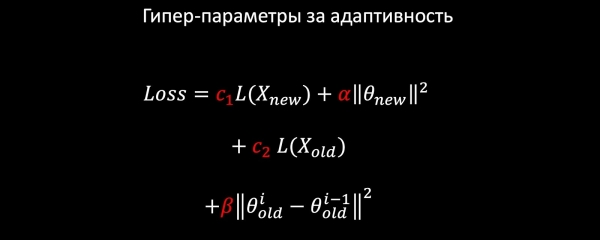
дарактар
Келгиле, чечим дарактарына өтөлү. Биз дарактарды кошумча окутуу үчүн төмөнкү алгоритмди түздүк:
- Өндүрүш 100-300 дарактан турган токойду иштетет, ал эски маалымат топтому боюнча окутулган.
- Аягында биз M = 5 даанасын алып салабыз жана 2M = 10 жаңысын кошобуз, алар бүт маалымат топтому боюнча үйрөтүлгөн, бирок жаңы маалыматтар үчүн чоң салмакка ээ, бул табигый түрдө моделдин кошумча өзгөрүшүнө кепилдик берет.
Албетте, убакыттын өтүшү менен бак-дарактардын саны абдан көбөйөт жана алар мезгил-мезгили менен кыскартуу керек. Бул үчүн, биз азыр бардык жерде бар Knowledge Distillation (KD) колдонобуз. Анын иштөө принциби жөнүндө кыскача.
- Бизде азыркы «татаал» модель бар. Биз аны окуу маалымат топтомунда иштетебиз жана чыгарууда класстын ыктымалдык бөлүштүрүлүшүн алабыз.
- Андан кийин, биз окуучу моделин (бул учурда аз дарактары бар модель) класстын бөлүштүрүлүшүн максаттуу өзгөрмө катары колдонуп, моделдин жыйынтыктарын кайталоого үйрөтөбүз.
- Бул жерде белгилей кетүү маанилүү, биз маалымат топтомунун белгилерин эч кандай түрдө колдонбойбуз, ошондуктан биз каалагандай маалыматтарды колдоно алабыз. Албетте, биз студенттик үлгү үчүн машыгуу үлгүсү катары согуштук агымдагы маалымат үлгүсүн колдонобуз. Ошентип, окуу топтому моделдин тактыгын камсыз кылууга мүмкүндүк берет, ал эми агым үлгүсү окуу топтомунун бир жактуулугун компенсациялоо менен өндүрүштү бөлүштүрүүдө окшош көрсөткүчтөргө кепилдик берет.
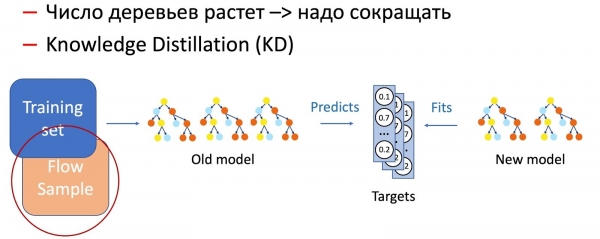
Бул эки ыкманын айкалышы (билимдерди дистилляциялоо аркылуу дарактарды кошуу жана алардын санын мезгил-мезгили менен азайтуу) жаңы үлгүлөрдү киргизүүнү жана толук үзгүлтүксүздүктү камсыз кылат.
КДнын жардамы менен биз моделдин өзгөчөлүктөрүнө да түрдүү операцияларды жасайбыз, мисалы, функцияларды алып салуу жана боштуктарды иштетүү. Биздин учурда, бизде бир катар маанилүү статистикалык өзгөчөлүктөр (жөнөтүүчүлөр, текст хэштери, URL даректери ж.б.) бар, алар маалымат базасында сакталып, алар иштебей калат. Модель, албетте, окуялардын мындай өнүгүшүнө даяр эмес, анткени машыгуу топтомунда ийгиликсиз жагдайлар болбойт. Мындай учурларда биз KD жана көбөйтүү ыкмаларын айкалыштырабыз: маалыматтардын бир бөлүгүн окутууда биз керектүү функцияларды алып салабыз же баштапкы абалга келтиребиз, жана биз баштапкы энбелгилерди алабыз (учурдагы моделдин натыйжалары) жана студент модели бул бөлүштүрүүнү кайталоону үйрөнөт. .
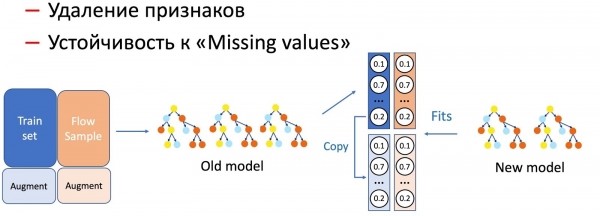
Модель менен иштөө канчалык олуттуу болсо, жип үлгүсүнүн пайызы ошончолук көп болорун байкадык.
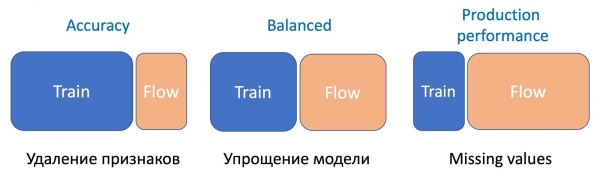
Функцияны алып салуу, эң жөнөкөй операция, агымдын аз гана бөлүгүн талап кылат, анткени бир нече функциялар гана өзгөрөт жана учурдагы модель бир эле топтомдо үйрөтүлгөн - айырма минималдуу. Моделди жөнөкөйлөтүү үчүн (дарактардын санын бир нече жолу кыскартуу) 50дөн 50гө чейин талап кылынат, ал эми моделдин иштешине олуттуу таасир этүүчү маанилүү статистикалык белгилерди калтыруу үчүн, анын ишин тегиздөө үчүн дагы көбүрөөк агым талап кылынат. тамгалардын бардык түрлөрү боюнча жаңы калтырууга туруктуу модели.
FastText
Келгиле, FastText'ке өтөбүз. Эсиңиздерге сала кетейин, сөздүн чагылдырылышы (Киргизилиши) сөздүн өзүнүн жана анын бардык тамгасынын N-граммдарынын, адатта триграммалардын киришинин суммасынан турат. Триграммалар абдан көп болушу мүмкүн болгондуктан, Bucket Hashing колдонулат, башкача айтканда, бардык мейкиндикти белгилүү бир туруктуу хэшмапка айландыруу. Натыйжада, салмак матрицасы сөздөрдүн санына ички катмардын өлчөмү менен алынат + чака.
Кошумча окутуу менен жаңы белгилер пайда болот: сөздөр жана триграммалар. Фейсбуктан стандарттык кийинки тренингде олуттуу эч нерсе болбойт. Жаңы маалыматтар боюнча кайчылаш энтропиялуу эски салмактар гана кайра даярдалат. Ошентип, жаңы мүмкүнчүлүктөр колдонулган эмес, албетте, бул ыкма өндүрүштө моделдин күтүлбөгөндүк менен байланышкан бардык жогоруда сүрөттөлгөн кемчиликтери бар; Ошондуктан биз FastTextти бир аз өзгөрттүк. Биз бардык жаңы салмактарды (сөздөрдү жана триграммаларды) кошобуз, бүт матрицаны кайчылаш энтропия менен кеңейтебиз жана сызыктуу моделге аналогия боюнча гармоникалык регуляризацияны кошобуз, бул эски салмактардын анча деле өзгөрүүсүн кепилдейт.

CNN
Convolutional тармактар бир аз татаалыраак. Эгерде акыркы катмарлар CNNде окутулуп жатса, анда, албетте, сиз гармоникалык регуляризацияны колдоно аласыз жана үзгүлтүксүздүктү кепилдей аласыз. Бирок, эгерде бүт тармакты кошумча окутуу талап кылынса, анда мындай регуляризация мындан ары бардык катмарларга колдонулушу мүмкүн эмес. Бирок, Triplet Loss (Triplet Loss) аркылуу кошумча орнотууларды үйрөтүү мүмкүнчүлүгү бар.).
Triple Loss
Мисал катары фишингге каршы тапшырманы колдонуп, Triplet Loss деген жалпы мааниде карап көрөлү. Биз өзүбүздүн логотипти, ошондой эле башка компаниялардын логотиптеринин оң жана терс мисалдарын алабыз. Биринчинин ортосундагы аралыкты азайтып, экинчисинин ортосундагы аралыкты максималдуу кылып, класстардын тыгыздыгын камсыз кылуу үчүн муну кичине боштук менен жасайбыз.
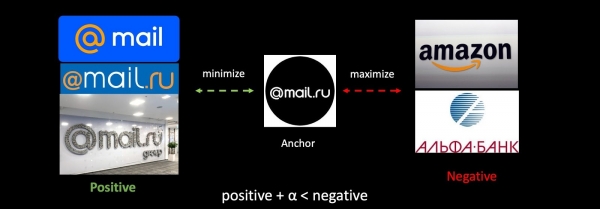
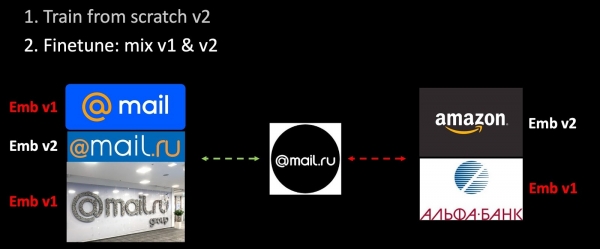
Эгерде биз тармакты андан ары машыктырсак, анда биздин метрикалык мейкиндик толугу менен өзгөрөт жана ал мурункуга таптакыр туура келбей калат. Бул векторлорду колдонгон проблемаларда олуттуу көйгөй. Бул көйгөйдү чечүү үчүн биз машыгуу учурунда эски орнотууларды аралаштырабыз.
Биз машыгуу топтомуна жаңы маалыматтарды коштук жана моделдин экинчи версиясын нөлдөн баштап үйрөтүп жатабыз. Экинчи этапта биз тармагыбызды (Finetuning) андан ары үйрөтөбүз: адегенде акыркы катмар бүтөт, андан кийин бүт тармак тоңдурулбайт. Үч эгиздерди түзүү процессинде биз үйрөтүлгөн моделдин жардамы менен кыстаруулардын бир бөлүгүн гана эсептейбиз, калганын - эскисин колдонобуз. Ошентип, кошумча окутуу процессинде биз v1 жана v2 метрикалык мейкиндиктердин шайкештигин камсыз кылабыз. Гармоникалык регуляризациянын уникалдуу версиясы.
Бүтүндөй архитектура
Мисал катары антиспам колдонгон бүт системаны карап чыга турган болсок, анда моделдер обочолонбостон, бири-бирине уя салынган. Биз сүрөттөрдү, текстти жана башка функцияларды тартабыз, CNN жана Fast Text аркылуу биз кыстарууларды алабыз. Андан кийин классификаторлор кыстаруулардын үстүнө колдонулат, алар ар кандай класстар үчүн упайларды берет (каттардын түрлөрү, спам, логотиптин болушу). Сигналдар жана белгилер акыркы чечимди кабыл алуу үчүн бак-дарактардын токоюна кирип жатат. Бул схемадагы жеке классификаторлор бардык маалыматтарды чийки түрүндө чечим дарактарына киргизбестен, системанын натыйжаларын жакшыраак чечмелөөгө жана тагыраак айтканда, көйгөйлөр болгон учурда компоненттерди кайра даярдоого мүмкүндүк берет.
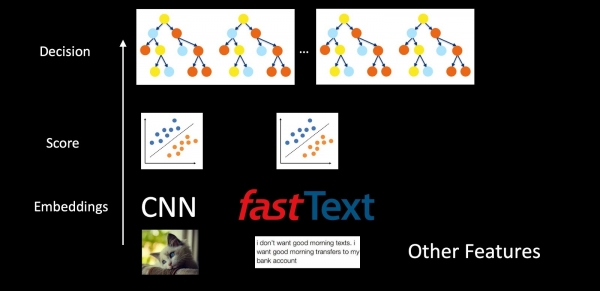
Натыйжада, биз ар бир деңгээлде үзгүлтүксүздүктү кепилдейбиз. CNN жана Fast Textтин төмөнкү деңгээлинде биз гармоникалык регуляризацияны колдонобуз, ортодогу классификаторлор үчүн гармоникалык регуляризацияны жана ыктымалдык бөлүштүрүүнүн ырааттуулугу үчүн ылдамдык калибрлөөсүн да колдонобуз. Ооба, бак-дарактарды өстүрүү акырындык менен үйрөтүлөт же Билимди дистилляциялоо аркылуу.
Жалпысынан алганда, мындай уяланган машинаны үйрөнүү тутумун кармап туруу, адатта, азап болуп саналат, анткени төмөнкү деңгээлдеги кандайдыр бир компонент жогорудагы бүт системаны жаңыртууга алып келет. Бирок биздин орнотууда ар бир компонент бир аз өзгөрүп, мурункусуна шайкеш келгендиктен, бүт системаны бүт структураны кайра даярдоонун зарылдыгы жок бөлүк-бөлүккө жаңыртып турууга болот, бул аны олуттуу чыгымдарсыз колдоого мүмкүндүк берет.
Жайгаштыруу
Биз маалыматтарды чогултууну жана ар кандай типтеги моделдерди кошумча окутууну талкууладык, ошондуктан биз аларды өндүрүш чөйрөсүнө жайылтууга өтүп жатабыз.
A/B тести
Мен жогоруда айткандай, маалыматтарды чогултуу процессинде биз адатта бир жактуу үлгүнү алабыз, андан моделдин өндүрүштүк көрсөткүчтөрүн баалоо мүмкүн эмес. Ошондуктан, жайылтууда, иш чындыгында кандай жүрүп жатканын түшүнүү үчүн моделди мурунку версия менен салыштыруу керек, башкача айтканда, A/B тесттерин жүргүзүү. Чындыгында, диаграммаларды чыгаруу жана талдоо процесси өтө көнүмүш жана оңой автоматташтырылышы мүмкүн. Биз моделдерибизди акырындык менен 5%, 30%, 50% жана 100% колдонуучуларга чыгарабыз, ошол эле учурда моделдин жооптору жана колдонуучунун пикири боюнча бардык жеткиликтүү көрсөткүчтөрдү чогултабыз. Кээ бир олуттуу четтөөлөр болгон учурда, биз автоматтык түрдө моделди артка кайтарабыз, ал эми башка учурларда, колдонуучу чыкылдатууларынын жетиштүү санын чогултуп, пайызды көбөйтүүнү чечебиз. Натыйжада, биз жаңы моделди колдонуучулардын 50% толугу менен автоматтык түрдө жеткиребиз жана бул кадам автоматташтырылышы мүмкүн болсо да, бүт аудиторияга жайылтуу адам тарабынан бекитилет.
Бирок, A/B тестирлөө процесси оптималдаштыруу үчүн орун сунуш кылат. Чындыгында, ар кандай A/B тести кыйла узак (биздин учурда ал пикирлердин көлөмүнө жараша 6дан 24 саатка чейин созулат), бул аны бир топ кымбат жана чектелген ресурстар менен түзөт. Кошумчалай кетсек, A/B тестинин жалпы убактысын тездетүү үчүн тесттин агымынын жетишерлик жогорку пайызы талап кылынат (кичинекей пайызда метрикага баа берүү үчүн статистикалык маанилүү үлгүнү тартуу өтө көп убакытты талап кылышы мүмкүн), бул A/B уячаларынын саны өтө чектелген. Албетте, биз кошумча окуу процессинде абдан көп алган эң келечектүү моделдерди гана сынап көрүшүбүз керек.
Бул көйгөйдү чечүү үчүн биз A/B тестинин ийгилигини алдын ала айткан өзүнчө классификаторду үйрөттүк. Бул үчүн, биз чечим кабыл алуу статистикасын, Тактык, Эстетүү жана башка көрсөткүчтөрдү окутуу топтомунда, кийинкиге калтырылганда жана агымдагы үлгүдө өзгөчөлүктөр катары алабыз. Биз ошондой эле моделди азыркы өндүрүштөгү, эвристика менен салыштырып, моделдин Татаалдыгын эске алабыз. Бардык ушул мүмкүнчүлүктөрдү колдонуу менен, тест тарыхы боюнча үйрөтүлгөн классификатор талапкер моделдерди баалайт, биздин учурда бул дарактардын токойлору жана A/B тестинде кайсынысын колдонууну чечет.
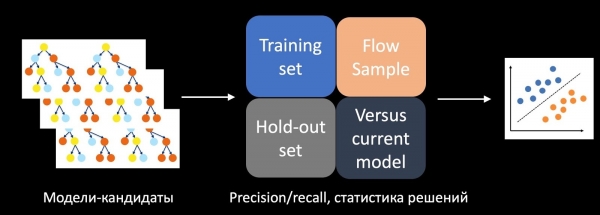
Ишке ашыруу учурунда бул ыкма ийгиликтүү A/B тесттеринин санын бир нече эсеге көбөйтүүгө мүмкүндүк берди.
Сыноо жана мониторинг
Сыноо жана мониторинг, таң калыштуусу, биздин ден соолугубузга зыян келтирбейт, тескерисинче, аны жакшыртат жана бизди ашыкча стресстен арылтат. Тестирлөө ийгиликсиздиктин алдын алууга мүмкүндүк берет, ал эми мониторинг колдонуучуларга таасирин азайтуу үчүн аны өз убагында аныктоого мүмкүндүк берет.
Бул жерде эртеби-кечпи сиздин системаңыз дайыма ката кетирерин түшүнүү маанилүү - бул кандайдыр бир программалык камсыздоону иштеп чыгуу циклине байланыштуу. Системаны өнүктүрүүнүн башталышында баары жөнгө салынып, инновациянын негизги этабы аяктаганга чейин ар дайым көп мүчүлүштүктөр болот. Бирок убакыттын өтүшү менен энтропия өз таасирин тийгизет жана каталар кайра пайда болот - айланадагы компоненттердин деградациясынан жана мен башында айткан маалыматтардагы өзгөрүүлөрдөн улам.
Бул жерде мен белгилеп кетким келет, ар кандай машина үйрөнүү системасы анын бүткүл өмүр циклинде анын пайда көз карашынан каралышы керек. Төмөнкү график спамдын сейрек кездешүүчү түрүн кармоо үчүн системанын кантип иштээрин көрсөтөт (графиктеги сызык нөлгө жакын). Бир күнү, туура эмес кэштелген атрибуттан улам, ал жинди болуп калды. Бактыга жараша, анормалдуу триггерге мониторинг болгон жок, натыйжада система чечим кабыл алуу чектеринде "спам" папкасына көп сандагы каттарды сактай баштады. Анын кесепеттерин оңдогону менен, система буга чейин ушунчалык көп катачылыктарды кетиргендиктен, беш жылдан кийин да өзүн актай албайт. Жана бул моделдин жашоо циклинин көз карашынан алганда толук ийгиликсиздик.
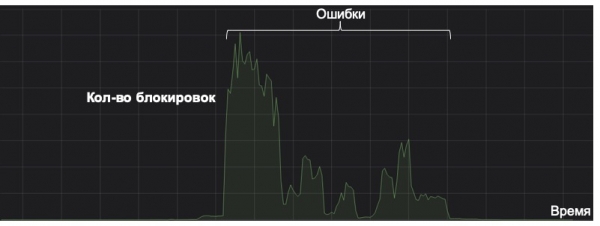
Ошондуктан, мониторинг сыяктуу жөнөкөй нерсе моделдин жашоосунда негизги болуп калышы мүмкүн. Стандарттык жана айкын көрсөткүчтөрдөн тышкары, биз моделдик жооптордун жана упайлардын бөлүштүрүлүшүн, ошондой эле негизги өзгөчөлүк баалуулуктарынын бөлүштүрүлүшүн карайбыз. KL дивергенциясын колдонуп, биз учурдагы бөлүштүрүүнү тарыхый бөлүштүрүүнү же A/B тестиндеги маанилерди агымдын калган бөлүгү менен салыштыра алабыз, бул моделдеги аномалияларды байкап, убакыттын өтүшү менен өзгөрүүлөрдү артка кайтарууга мүмкүндүк берет.
Көпчүлүк учурларда биз жөнөкөй эвристикаларды же келечекте мониторинг катары колдонгон моделдерди колдонуу менен системалардын биринчи версияларын ишке киргизебиз. Мисалы, биз NER моделин белгилүү онлайн дүкөндөр үчүн кадимки моделдерге салыштырып көзөмөлдөйбүз жана классификатордун камтуусу аларга салыштырмалуу төмөндөп кетсе, анда биз анын себептерин түшүнөбүз. Эвристиканы дагы бир пайдалуу колдонуу!
натыйжалары
Келгиле, макаланын негизги идеяларына дагы бир жолу кайрылалы.
- Fibdeck. Биз ар дайым колдонуучу жөнүндө ойлонобуз: ал биздин каталарыбыз менен кантип жашайт, аларды кантип кабарлай алат. Колдонуучулар окутуу моделдери үчүн таза пикирдин булагы эмес экенин унутпаңыз, жана аны жардамчы ML системаларынын жардамы менен тазалоо керек. Эгер колдонуучудан сигнал чогултуу мүмкүн болбосо, анда биз байланыштын альтернативдүү булактарын издейбиз, мисалы, туташкан системалар.
- Кошумча машыгуу. Бул жерде негизги нерсе үзгүлтүксүздүк, ошондуктан биз азыркы өндүрүш моделине таянабыз. Биз жаңы моделдерди гармоникалык регуляризация жана ушул сыяктуу трюктар менен мурункусунан көп деле айырмаланбашы үчүн үйрөтөбүз.
- Жайгаштыруу. Өлчөмдөрдүн негизинде автоматтык жайгаштыруу моделдерди ишке ашыруу убактысын бир топ кыскартат. Мониторинг статистикасы жана чечимдерди кабыл алуу бөлүштүрүү, колдонуучулардан түшкөндөрдүн саны сиздин тынч уйкуңуз жана жемиштүү дем алышыңыз үчүн милдеттүү.
Бул сизге ML системаңызды тезирээк өркүндөтүүгө, аларды тезирээк рынокко чыгарууга жана ишенимдүүрөөк жана стрессти азайтууга жардам берет деп үмүттөнөм.
Source: www.habr.com
