

priešistorė
Yra mūsų pačių sukurtų automatų. Raspberry Pi viduje ir kai kurie laidai ant atskiros plokštės. Jungiamas monetų priėmėjas, vekselių priėmėjas, banko terminalas... Viską valdo pačių parašyta programa. Visa darbo istorija įrašoma į žurnalą „flash drive“ („MicroSD“), kuris vėliau per internetą (naudojant USB modemą) perduodamas į serverį, kur saugomas duomenų bazėje. Pardavimo informacija įkeliama į 1c, taip pat yra paprasta žiniatinklio sąsaja stebėjimui ir kt.
Tai yra, žurnalas yra gyvybiškai svarbus - apskaitai (pajamoms, pardavimams ir pan.), stebėjimui (visiems gedimams ir kitoms force majeure aplinkybėms); Tai, galima sakyti, yra visa informacija, kurią turime apie šią mašiną.
problema
„Flash“ diskai pasirodo esą labai nepatikimi įrenginiai. Jie žlunga pavydėtinu reguliarumu. Dėl to mašina prastovos ir (jei žurnalo dėl kokių nors priežasčių nepavyko perkelti į internetą) prarandami duomenys.
Tai ne pirmoji „flash drives“ naudojimo patirtis, prieš tai buvo dar vienas projektas su daugiau nei šimtu įrenginių, kur žurnalas buvo saugomas USB atmintinėse, taip pat buvo problemų dėl patikimumo, kartais tų, kurie nepavyko mėnuo buvo dešimtys. Išbandėme įvairius „flash drives“, įskaitant firminius su SLC atmintimi, ir kai kurie modeliai yra patikimesni už kitus, tačiau „flash drives“ pakeitimas problemos radikaliai neišsprendė.
Dėmesio! Seniai skaitytas! Jei jus domina ne „kodėl“, o tik „kaip“, galite eiti tiesiai straipsniai.
sprendimas
Pirmas dalykas, kuris ateina į galvą, yra: atsisakykite „MicroSD“, įdiekite, pavyzdžiui, SSD ir paleiskite iš jo. Teoriškai įmanoma, tikriausiai, bet palyginti brangu ir ne taip patikima (pridėtas USB-SATA adapteris; biudžetinių SSD diskų gedimų statistika taip pat nedžiugina).
USB HDD taip pat neatrodo itin patrauklus sprendimas.
Todėl priėjome prie tokios parinkties: palikite paleidimą iš „MicroSD“, bet naudokite juos tik skaitymo režimu, o operacijų žurnalą (ir kitą informaciją, būdingą konkrečiai aparatinei įrangai – serijos numerį, jutiklių kalibravimą ir pan.) saugokite kur nors kitur. .
Tik skaitomos FS avietėms tema jau buvo ištirta viduje ir išorėje, šiame straipsnyje nesigilinsiu ties įgyvendinimo detalėmis (bet jei bus susidomėjimo, gal parašysiu mini straipsnį šia tema). Vienintelis dalykas, kurį norėčiau pastebėti, yra tai, kad tiek iš asmeninės patirties, tiek iš tų, kurie jau tai įdiegė, apžvalgos, yra patikimumo padidėjimas. Taip, visiškai atsikratyti gedimų neįmanoma, tačiau žymiai sumažinti jų dažnį yra visiškai įmanoma. Ir kortelės tampa unifikuotos, todėl aptarnaujančiam personalui žymiai lengviau pakeisti.
Techninė įranga
Dėl atminties tipo pasirinkimo ypatingų abejonių nekilo – NOR Flash.
Argumentai:
- paprastas prijungimas (dažniausiai SPI magistralė, kuria jau turite patirties, todėl aparatinės įrangos problemų nenumatoma);
- juokinga kaina;
- standartinis veikimo protokolas (įgyvendinimas jau yra branduolyje) Linux, jei norite, galite pasiimti trečiosios šalies, kurios taip pat yra, arba net parašyti savo, laimei, viskas paprasta);
- patikimumas ir ištekliai:
iš tipinio duomenų lapo: duomenys saugomi 20 metų, 100000 XNUMX trynimo ciklų kiekvienam blokui;
iš trečiųjų šalių šaltinių: itin žemas BER, postuluoja, kad nereikia klaidų taisymo kodų (kai kuriuose darbuose ECC skirta NOR, bet dažniausiai jie vis tiek reiškia MLC NOR; taip pat atsitinka).
Įvertinkime apimties ir išteklių poreikius.
Norėčiau, kad duomenys būtų saugomi kelias dienas. Tai būtina, kad iškilus problemoms su komunikacija nebūtų prarasta pardavimų istorija. Per šį laikotarpį sutelksime dėmesį į 5 dienas (net atsižvelgiant į savaitgalius ir šventes) problemą galima išspręsti.
Šiuo metu per dieną surenkame apie 100kb rąstų (3-4 tūkst. įrašų), tačiau pamažu šis skaičius auga – didėja detalumas, atsiranda naujų įvykių. Be to, kartais būna sprogimų (pavyzdžiui, kai kurie jutikliai pradeda siųsti šlamštą su klaidingais teigiamais duomenimis). 10 tūkstančių įrašų skaičiuosime po 100 baitų – megabaitų per dieną.
Iš viso išeina 5 MB švarių (gerai suspaustų) duomenų. Daugiau jiems (grubus paskaičiavimas) 1 MB paslaugų duomenų.
Tai reiškia, kad mums reikia 8 MB lusto, jei nenaudojame glaudinimo, arba 4 MB, jei jį naudojame. Gana realūs skaičiai tokio tipo atminčiai.
Kalbant apie išteklius: jei planuojame, kad visa atmintis bus perrašoma ne dažniau kaip kartą per 5 dienas, tai per 10 metų tarnybos gauname mažiau nei tūkstantį perrašymo ciklų.
Priminsiu, kad gamintojas žada šimtą tūkstančių.
Šiek tiek apie NOR vs NAND
Šiandien, žinoma, NAND atmintis yra daug populiaresnė, tačiau šiam projektui jos nenaudočiau: NAND, skirtingai nei NOR, būtinai reikalauja naudoti klaidų taisymo kodus, blogų blokų lentelę ir pan., taip pat ir kojeles NAND lustų paprastai daug daugiau.
NOR trūkumai yra šie:
- maža apimtis (ir, atitinkamai, didelė kaina už megabaitą);
- mažas ryšio greitis (daugiausia dėl to, kad naudojama nuoseklioji sąsaja, dažniausiai SPI arba I2C);
- lėtas trynimas (priklausomai nuo bloko dydžio, tai trunka nuo sekundės dalies iki kelių sekundžių).
Atrodo, kad mums nėra nieko kritiško, todėl tęsiame.
Jei detalės įdomios, mikroschema pasirinkta (tačiau tai nesvarbu, rinkoje yra daug analogų, kurie yra suderinami pinout ir komandų sistemoje; net jei norime įdiegti kito gamintojo ir (arba) kitokio dydžio mikroschemą, viskas veiks nekeičiant kodas).
Aš naudoju tą, kuris integruotas į branduolį Linux Tvarkyklėje „Raspberry Pi“ sistemoje, dėka įrenginių medžio perdangos palaikymo, viskas labai paprasta – reikia sudėti sukompiliuotą perdangą į /boot/overlays ir šiek tiek modifikuoti /boot/config.txt.
Dts failo pavyzdys
Tiesą sakant, nesu tikras, kad parašyta be klaidų, bet tai veikia.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};Ir dar viena eilutė config.txt
dtoverlay=at25:spimaxfrequency=50000000Praleisiu lusto prijungimo prie Raspberry Pi aprašymą. Viena vertus, nesu elektronikos ekspertas, kita vertus, viskas čia net man banalu: mikroschema turi tik 8 kojeles, iš kurių mums reikia žemės, galios, SPI (CS, SI, SO, SCK ); lygiai yra tokie patys kaip Raspberry Pi, nereikia jokių papildomų laidų – tiesiog prijunkite nurodytus 6 kontaktus.
Problemos teiginys
Kaip įprasta, problemos teiginys kartojasi keletą kartų, ir man atrodo, kad laikas kitam. Taigi sustokime, sudėliokime tai, kas jau parašyta, ir išsiaiškinkime detales, kurios lieka šešėlyje.
Taigi, nusprendėme, kad žurnalas bus saugomas SPI NOR Flash.
Kas yra NOR Flash tiems, kurie nežino?
Tai yra nepastovi atmintis, su kuria galite atlikti tris operacijas:
- Skaitymas:
Dažniausias skaitymas: perduodame adresą ir nuskaitome tiek baitų, kiek reikia; - Įrašas:
Rašymas į NOR flash atrodo kaip įprastas, tačiau turi vieną ypatumą: galite pakeisti tik nuo 1 į 0, bet ne atvirkščiai. Pavyzdžiui, jei atminties langelyje turėjome 0x55, tada į jį įrašius 0x0f, 0x05 ten jau bus išsaugotas (žr. lentelę žemiau); - Ištrinti:
Žinoma, turime mokėti atlikti priešingą operaciją – pakeisti 0 į 1, būtent tam ir skirta trynimo operacija. Skirtingai nuo pirmųjų dviejų, jis veikia ne baitais, o blokais (minimalus trynimo blokas pasirinktame luste yra 4 kb). Erase sunaikina visą bloką ir yra vienintelis būdas pakeisti 0 į 1. Todėl dirbant su „flash“ atmintimi dažnai tenka derinti duomenų struktūras prie trynimo bloko ribos.
Įrašymas NOR Flash:
Dvejetainiai duomenys
Buvo
01010101
Įrašyta
00001111
Tapo
00000101
Pats žurnalas yra kintamo ilgio įrašų seka. Įprastas įrašo ilgis yra apie 30 baitų (nors kartais pasitaiko ir kelių kilobaitų ilgio įrašų). Šiuo atveju mes dirbame su jais tiesiog kaip baitų rinkiniu, tačiau, jei jus domina, įrašuose naudojamas CBOR
Be žurnalo, turime saugoti tam tikrą „nustatymo“ informaciją, tiek atnaujintą, tiek ne: tam tikrą įrenginio ID, jutiklių kalibravimus, žymą „įrenginys laikinai išjungtas“ ir kt.
Ši informacija yra raktinių reikšmių įrašų rinkinys, taip pat saugomas CBOR. Šios informacijos neturime daug (daugiausia kelis kilobaitus) ir ji atnaujinama retai.
Toliau tai vadinsime kontekstu.
Jei prisimintume, nuo ko prasidėjo šis straipsnis, labai svarbu užtikrinti patikimą duomenų saugojimą ir, jei įmanoma, nenutrūkstamą veikimą net ir įvykus aparatūros gedimams/duomenims sugadinti.
Kokius problemų šaltinius galima laikyti?
- Išjunkite maitinimą rašymo / ištrynimo operacijų metu. Tai yra iš kategorijos „nėra jokio triuko prieš laužtuvą“.
Informacija iš stackexchange: kai dirbant su blykste išjungiamas maitinimas, ir trynimas (nustatytas į 1), ir rašymas (nustatytas į 0) sukelia neapibrėžtą elgesį: duomenis galima rašyti, iš dalies įrašyti (tarkim, perkėlėme 10 baitų/80 bitų , bet dar galima įrašyti ne tik 45 bitus), taip pat gali būti, kad kai kurie bitai bus „tarpinėje“ būsenoje (skaitant galima gauti ir 0, ir 1); - Klaidos pačioje „flash“ atmintyje.
BER, nors ir labai žemas, negali būti lygus nuliui; - Autobuso klaidos
Per SPI perduodami duomenys niekaip neapsaugoti tiek nuo vieno bito klaidų, tiek su sinchronizavimo klaidomis – bitų praradimu arba įterpimu (dėl to atsiranda didžiulis duomenų iškraipymas); - Kitos klaidos/gedimai
Kodo klaidos, Raspberry trikdžiai, ateivių trukdžiai...
Suformulavau reikalavimus, kurių įvykdymas, mano nuomone, yra būtinas patikimumui užtikrinti:
- įrašai turi patekti į „flash“ atmintį, į uždelstus įrašus neatsižvelgiama – jei įvyksta klaida, ji turi būti aptikta ir apdorota kuo anksčiau – sistema, esant galimybei, turi atsigauti po klaidų;
(pavyzdys iš gyvenimo „kaip neturėtų būti“, su kuriuo, manau, yra susidūrę visi: po avarinio perkrovimo failų sistema „sugedo“, o operacinė sistema nepasileidžia)
Idėjos, požiūriai, apmąstymai
Kai pradėjau galvoti apie šią problemą, mano galvoje šovė daug idėjų, pavyzdžiui:
- naudoti duomenų suspaudimą;
- naudokite sumanias duomenų struktūras, pavyzdžiui, saugokite įrašų antraštes atskirai nuo pačių įrašų, kad jei kuriame nors įraše būtų klaida, likusią dalį galėtumėte perskaityti be jokių problemų;
- naudokite bitų laukus norėdami valdyti įrašymo pabaigą, kai maitinimas išjungtas;
- saugoti visko kontrolines sumas;
- naudoti tam tikro tipo triukšmui atsparų kodavimą.
Kai kurios iš šių idėjų buvo panaudotos, o kitų nuspręsta atsisakyti. Eikime eilės tvarka.
Duomenų glaudinimas
Patys įvykiai, kuriuos įrašome į žurnalą, yra gana panašūs ir kartojami („išmetė 5 rublių monetą“, „paspaudė keitimo mygtuką“, ...). Todėl suspaudimas turėtų būti gana efektyvus.
Kompresijos sąnaudos yra nereikšmingos (mūsų procesorius yra gana galingas, net pirmasis Pi turėjo vieną branduolį, kurio dažnis buvo 700 MHz, dabartiniai modeliai turi keletą branduolių, kurių dažnis viršija gigahercą), keitimo kursas su saugykla yra mažas (keli megabaitų per sekundę), įrašų dydis yra mažas. Apskritai, jei suspaudimas turi įtakos našumui, jis bus tik teigiamas. (visiškai nekritiška, tiesiog konstatuoju)Be to, mes neturime tikro įterptinio, o įprasto. Linux — taigi įgyvendinimas neturėtų pareikalauti daug pastangų (užtenka tiesiog susieti biblioteką ir naudoti kelias jos funkcijas).
Žurnalo gabalas buvo paimtas iš veikiančio įrenginio (1.7 MB, 70 tūkst. įrašų) ir pirmiausia patikrintas suspaudžiamumas naudojant kompiuteryje esančius gzip, lz4, lzop, bzip2, xz, zstd.
- gzip, xz, zstd parodė panašius rezultatus (40Kb).
Nustebau, kad madingas xz čia pasirodė gzip arba zstd lygiu; - lzip su numatytaisiais nustatymais davė šiek tiek prastesnių rezultatų;
- lz4 ir lzop parodė nelabai gerus rezultatus (150Kb);
- bzip2 parodė stebėtinai gerą rezultatą (18Kb).
Taigi, duomenys labai gerai suglaudinami.
Taigi (jei nerasime lemtingų trūkumų) bus suspaudimas! Tiesiog todėl, kad tame pačiame „flash drive“ telpa daugiau duomenų.
Pagalvokime apie trūkumus.
Pirma problema: mes jau sutarėme, kad kiekvienas įrašas turi iš karto blyksėti. Paprastai archyvatorius renka duomenis iš įvesties srauto, kol nusprendžia, kad laikas rašyti savaitgalį. Turime nedelsiant gauti suglaudintą duomenų bloką ir saugoti jį nepastovioje atmintyje.
Matau tris būdus:
- Suspauskite kiekvieną įrašą naudodami žodyno glaudinimą, o ne anksčiau aptartus algoritmus.
Tai visiškai veikiantis variantas, bet man jis nepatinka. Kad būtų užtikrintas daugiau ar mažiau tinkamas glaudinimo lygis, žodynas turi būti „pritaikytas“ prie konkrečių duomenų. Taip, problemą galima išspręsti sukūrus naują žodyno versiją, tačiau tai yra galvos skausmas – reikės saugoti visas žodyno versijas; kiekviename įraše turėsime nurodyti, su kuria žodyno versija jis buvo suspaustas... - Suspauskite kiekvieną įrašą naudodami „klasikinius“ algoritmus, bet nepriklausomai nuo kitų.
Nagrinėjami glaudinimo algoritmai nėra skirti dirbti su tokio dydžio (dešimties baitų) įrašais, glaudinimo koeficientas aiškiai bus mažesnis nei 1 (tai yra duomenų apimties didinimas, o ne glaudinimas); - Atlikite FLUSH po kiekvieno įrašymo.
Daugelis suspaudimo bibliotekų palaiko FLUSH. Tai yra komanda (arba glaudinimo procedūros parametras), kurią gavęs archyvatorius suformuoja suspaustą srautą, kad jį būtų galima naudoti atkurti visi nesuspaustus duomenis, kurie jau buvo gauti. Toks analogassyncfailų sistemose arbacommitsql.
Svarbu tai, kad vėlesnėse glaudinimo operacijose bus galima naudoti sukauptą žodyną ir glaudinimo koeficientas nenukentės tiek, kiek ankstesnėje versijoje.
Manau, akivaizdu, kad pasirinkau trečiąjį variantą, pažvelkime į jį plačiau.
Rasta apie FLUSH zlib.
Aš atlikau kelio testą pagal straipsnį, paėmiau 70 tūkstančių žurnalo įrašų iš tikro įrenginio, kurio puslapio dydis 60Kb (prie puslapio dydžio grįšime vėliau) gavo:
Neapdoroti duomenys
Suspaudimas gzip -9 (be FLUSH)
zlib su Z_PARTIAL_FLUSH
zlib su Z_SYNC_FLUSH
Apimtis, KB
1692
40
352
604
Iš pirmo žvilgsnio FLUSH įnešama kaina yra pernelyg didelė, tačiau realiai mes turime mažai pasirinkimo – arba išvis nespausti, arba suspausti (ir labai efektyviai) su FLUSH. Reikia nepamiršti, kad turime 70 tūkstančių įrašų, Z_PARTIAL_FLUSH įvestas dubliavimas yra tik 4-5 baitai vienam įrašui. Ir suspaudimo santykis pasirodė beveik 5:1, o tai yra daugiau nei puikus rezultatas.
Tai gali būti netikėta, bet Z_SYNC_FLUSH iš tikrųjų yra efektyvesnis būdas atlikti FLUSH
Naudojant Z_SYNC_FLUSH, paskutiniai 4 kiekvieno įrašo baitai visada bus 0x00, 0x00, 0xff, 0xff. Ir jei mes juos žinome, tada mes neturime jų saugoti, todėl galutinis dydis yra tik 324 Kb.
Straipsnyje, į kurį pateikiau nuorodą, yra paaiškinimas:
Pridedamas naujas 0 tipo blokas su tuščiu turiniu.
0 tipo bloką su tuščiu turiniu sudaro:
- trijų bitų bloko antraštė;
- 0–7 bitai lygūs nuliui, kad būtų pasiektas baitų lygiavimas;
- keturių baitų seka 00 00 FF FF.
Kaip nesunkiai matote, paskutiniame bloke prieš šiuos 4 baitus yra nuo 3 iki 10 nulinių bitų. Tačiau praktika parodė, kad iš tikrųjų yra mažiausiai 10 nulinių bitų.
Pasirodo, tokie trumpi duomenų blokai dažniausiai (visada?) koduojami naudojant 1 tipo bloką (fiksuotą bloką), kuris būtinai baigiasi 7 nuliniais bitais, iš viso suteikiant 10-17 garantuotų nulių bitų (o likusieji bus būti nuliui su maždaug 50% tikimybe.
Taigi, remiantis bandymo duomenimis, 100% atvejų yra vienas nulis baitas prieš 0x00, 0x00, 0xff, 0xff, o daugiau nei trečdaliu atvejų yra du nuliniai baitai (galbūt faktas yra tas, kad aš naudoju dvejetainį CBOR, o naudojant tekstinį JSON 2 tipo blokai - dažniau būtų dinaminis blokas, atitinkamai, blokai be papildomų nulio baitų prieš 0x00, 0x00, 0xff, 0xff).
Iš viso, naudojant turimus testo duomenis, galima sutalpinti į mažiau nei 250Kb suspaustų duomenų.
Žongliruodami bitais galite šiek tiek sutaupyti: kol kas ignoruojame kelių nulių bitų buvimą bloko pabaigoje, keli bitai bloko pradžioje taip pat nesikeičia...
Bet tada aš tvirtai nusprendžiau sustoti, kitaip tokiu greičiu galėčiau sukurti savo archyvatorių.
Iš viso iš savo bandymo duomenų gavau 3–4 baitus per vieną įrašą, glaudinimo koeficientas pasirodė didesnis nei 6:1. Būsiu atviras: tokio rezultato, mano nuomone, nesitikėjau, kas geriau nei 2:1 jau yra rezultatas, kuris pateisina suspaudimo naudojimą.
Viskas gerai, bet zlib (deflate) vis dar yra archajiškas, nusipelnęs ir šiek tiek senamadiškas glaudinimo algoritmas. Vien faktas, kad paskutiniai 32Kb nesuspausto duomenų srauto naudojami kaip žodynas, šiandien atrodo keistai (tai yra, jei koks nors duomenų blokas labai panašus į tą, kuris buvo įvesties sraute prieš 40Kb, tada jis vėl bus pradėtas archyvuoti, ir nenurodys ankstesnio įvykio). Madinguose šiuolaikiniuose archyvuose žodyno dydis dažnai matuojamas megabaitais, o ne kilobaitais.
Taigi tęsiame savo mini archyvų studiją.
Toliau išbandėme bzip2 (atminkite, be FLUSH jis parodė fantastišką suspaudimo santykį beveik 100:1). Deja, su FLUSH veikė labai prastai, suspaustų duomenų dydis buvo didesnis nei nesuspaustų.
Mano prielaidos apie nesėkmės priežastis
Libbz2 siūlo tik vieną praplovimo parinktį, kuri, atrodo, išvalo žodyną (panašiai kaip Z_FULL_FLUSH zlib, po to nekalbama apie jokį veiksmingą suspaudimą).
Ir paskutinis išbandytas buvo zstd. Priklausomai nuo parametrų, jis suglaudinamas arba gzip lygiu, bet daug greičiau arba geriau nei gzip.
Deja, su FLUSH jis neveikė labai gerai: suspaustų duomenų dydis buvo apie 700 Kb.
Я projekto „github“ puslapyje gavau atsakymą, kad kiekvienam suspaustų duomenų blokui reikia skaičiuoti iki 10 baitų paslaugų duomenų, o tai yra artima gautam rezultatui.
Nusprendžiau šioje vietoje sustoti savo eksperimentuose su archyvatoriais (priminsiu, kad xz, lzip, lzo, lz4 nepasirodė net testavimo etape be FLUSH, o egzotiškesnių glaudinimo algoritmų negalvojau).
Grįžkime prie archyvavimo problemų.
Antroji (kaip sakoma eilės, o ne vertės) problema yra ta, kad suspausti duomenys yra vienas srautas, kuriame nuolatos yra nuorodų į ankstesnes dalis. Taigi, sugadinus suspaustų duomenų sekciją, prarandame ne tik susijusį nesuspaustų duomenų bloką, bet ir visus vėlesnius.
Yra šios problemos sprendimo būdas:
- Užkirsti kelią problemai – pridėkite suspaustų duomenų pertekliaus, kas leis atpažinti ir ištaisyti klaidas; apie tai pakalbėsime vėliau;
- Sumažinkite pasekmes, jei iškyla problema
Jau anksčiau sakėme, kad kiekvieną duomenų bloką galite suspausti atskirai, ir problema išnyks savaime (pažeidus vieno bloko duomenis bus prarasti tik šio bloko duomenys). Tačiau tai yra kraštutinis atvejis, kai duomenų glaudinimas bus neveiksmingas. Priešingas kraštutinumas: naudokite visus 4 MB mūsų lusto kaip vieną archyvą, kuris suteiks mums puikų suspaudimą, tačiau sugadinus duomenis sukels katastrofiškas pasekmes.
Taip, reikia kompromiso dėl patikimumo. Tačiau turime atsiminti, kad kuriame duomenų saugojimo formatą nepastoviajai atminčiai su itin mažu BER ir deklaruojamu 20 metų duomenų saugojimo laikotarpiu.
Eksperimentų metu išsiaiškinau, kad daugiau ar mažiau pastebimi glaudinimo lygio nuostoliai prasideda suspaustų duomenų blokuose, kurių dydis mažesnis nei 10 KB.
Anksčiau buvo minėta, kad naudojama atmintis yra puslapiuota, nematau jokios priežasties, kodėl neturėtų būti naudojama korespondencija „vienas puslapis – vienas suspaustų duomenų blokas“.
Tai reiškia, kad minimalus pagrįstas puslapio dydis yra 16 Kb (su rezervu paslaugos informacijai). Tačiau toks mažas puslapio dydis nustato didelius didžiausio įrašo dydžio apribojimus.
Nors kol kas nesitikiu didesnių nei kelių kilobaitų įrašų suglaudinta forma, nusprendžiau naudoti 32Kb puslapius (iš viso 128 puslapiai viename luste).
Komentaras:
- Duomenis saugome suglaudintus naudojant zlib (deflate);
- Kiekvienam įrašui nustatome Z_SYNC_FLUSH;
- Kiekvieno suglaudinto įrašo pabaigoje apkarpome baitus (pvz., 0x00, 0x00, 0xff, 0xff); antraštėje nurodome, kiek baitų nupjauname;
- Duomenis saugome 32Kb puslapiuose; puslapio viduje yra vienas suspaustų duomenų srautas; Kiekviename puslapyje vėl pradedame glaudinimą.
Ir, prieš baigdamas glaudinimą, norėčiau atkreipti jūsų dėmesį į tai, kad suspaustų duomenų turime tik kelis baitus vienam įrašui, todėl labai svarbu neišpūsti paslaugos informacijos, čia yra svarbus kiekvienas baitas.
Duomenų antraščių saugojimas
Kadangi turime kintamo ilgio įrašus, turime kažkaip nustatyti įrašų vietą/ribas.
Žinau tris būdus:
- Visi įrašai saugomi nenutrūkstamame sraute, pirmiausia yra įrašo antraštė, kurioje nurodomas ilgis, o tada pats įrašas.
Šiame įgyvendinimo variante ir antraštės, ir duomenys gali būti įvairaus ilgio.
Iš esmės gauname atskirai susietą sąrašą, kuris naudojamas visą laiką; - Antraštės ir patys įrašai saugomi atskiruose srautuose.
Naudodami pastovaus ilgio antraštes užtikriname, kad vienos antraštės pažeidimas nepaveiks kitų.
Panašus metodas naudojamas, pavyzdžiui, daugelyje failų sistemų; - Įrašai saugomi nenutrūkstamame sraute, įrašo ribą nustato tam tikras žymeklis (duomenų blokuose draudžiamas simbolis/simbolių seka). Jei įrašo viduje yra žymeklis, jį pakeičiame kokia nors seka (pabėgame).
Panašus metodas naudojamas, pavyzdžiui, PPP protokole.
Aš iliustruosiu.
Variantas 1:

Čia viskas labai paprasta: žinodami įrašo ilgį, galime apskaičiuoti kitos antraštės adresą. Taigi judame per antraštes, kol atsiranda sritis, užpildyta 0xff (laisva sritis) arba puslapio pabaiga.
Variantas 2:

Dėl kintamo įrašo ilgio negalime iš anksto pasakyti, kiek įrašų (taigi ir antraščių) mums reikės puslapyje. Antraštes ir pačius duomenis galite paskleisti skirtinguose puslapiuose, bet man labiau patinka kitoks požiūris: ir antraštes, ir duomenis dedame viename puslapyje, tačiau antraštės (nuolatinio dydžio) atsiranda nuo puslapio pradžios, o duomenys (kintamo ilgio) ateina iš galo. Kai tik jie „susitinka“ (neužtenka laisvos vietos naujam įrašui), šį puslapį laikome užbaigtu.
Variantas 3:

Antraštėje nereikia kaupti ilgio ar kitos informacijos apie duomenų vietą, pakanka įrašų ribas nurodančių žymeklių. Tačiau duomenys turi būti tvarkomi rašant/skaitant.
Kaip žymeklį naudočiau 0xff (kuris užpildo puslapį po ištrynimo), todėl laisva sritis tikrai nebus traktuojama kaip duomenys.
Palyginimo lentelė:
Parinktis 1
Parinktis 2
Parinktis 3
Klaidų tolerancija
-
+
+
Kompaktiškumas
+
-
+
Įgyvendinimo sudėtingumas
*
**
**
1 variantas turi lemtingą trūkumą: jei kuri nors antraštė yra pažeista, visa tolesnė grandinė sunaikinama. Likusios parinktys leidžia atkurti kai kuriuos duomenis net ir didelės žalos atveju.
Bet čia dera prisiminti, kad nusprendėme duomenis saugoti suglaudintu pavidalu ir taip po „sugedusio“ įrašo prarandame visus puslapyje esančius duomenis, tad nors lentelėje yra minusas, bet ne atsižvelgti į tai.
Kompaktiškumas:
- pirmajame variante antraštėje turime įrašyti tik ilgį, jei naudojame kintamo ilgio sveikuosius skaičius, tada daugeliu atvejų galime apsieiti su vienu baitu;
- antrajame variante turime išsaugoti pradžios adresą ir ilgį; įrašas turi būti pastovaus dydžio, aš vertinu 4 baitus vienam įrašui (du baitai poslinkiui ir du baitai ilgiui);
- trečiajam variantui tereikia vieno simbolio, nurodančio įrašymo pradžią, be to, pats įrašymas padidės 1-2% dėl ekranavimo. Apskritai, maždaug paritetas su pirmuoju variantu.
Iš pradžių antrąjį variantą laikiau pagrindiniu (ir net parašiau įgyvendinimą). Jo atsisakiau tik tada, kai pagaliau nusprendžiau naudoti kompresiją.
Galbūt kada nors vis tiek pasinaudosiu panašia parinktimi. Pavyzdžiui, jei man teks susidurti su duomenų saugojimu tarp Žemės ir Marso keliaujančiam laivui, bus keliami visai kiti patikimumo, kosminės spinduliuotės, ...
Kalbant apie trečiąjį variantą: aš jam skyriau dvi žvaigždutes už įgyvendinimo sunkumus vien todėl, kad nemėgstu maišytis su ekranavimu, keisti ilgį ir pan. Taip, galbūt aš šališkas, bet turėsiu parašyti kodą – kam versti save daryti tai, kas tau nepatinka.
Komentaras: Mes pasirenkame saugojimo parinktį grandinių pavidalu „antraštė su ilgiu - kintamo ilgio duomenys“ dėl efektyvumo ir įgyvendinimo paprastumo.
Bitų laukų naudojimas norint stebėti rašymo operacijų sėkmę
Dabar nepamenu iš kur kilo mintis, bet atrodo maždaug taip:
Kiekvienam įrašui skiriame kelis bitus vėliavėlėms saugoti.
Kaip minėjome anksčiau, po trynimo visi bitai užpildomi 1s, o mes galime pakeisti 1 į 0, bet ne atvirkščiai. Taigi „vėliava nenustatyta“ naudojame 1, o „vėliava nustatyta“ naudojame 0.
Štai kaip gali atrodyti kintamo ilgio įrašo įdėjimas į „flash“:
- Nustatykite vėliavėlę „ilgio įrašymas prasidėjo“;
- Įrašykite ilgį;
- Nustatykite vėliavėlę „duomenų įrašymas pradėtas“;
- Įrašome duomenis;
- Nustatykite vėliavėlę „įrašymas baigtas“.
Be to, turėsime žymą „Įvyko klaida“, iš viso 4 bitų vėliavėlės.
Šiuo atveju turime dvi stabilias būsenas „1111“ – įrašymas neprasidėjo ir „1000“ – įrašymas buvo sėkmingas; netikėtai nutrūkus įrašymo procesui, gausime tarpines būsenas, kurias vėliau galėsime aptikti ir apdoroti.
Metodas įdomus, tačiau jis apsaugo tik nuo staigių elektros tiekimo ir panašių gedimų, kas, žinoma, svarbu, tačiau tai toli gražu ne vienintelė (ar net pagrindinė) galimų gedimų priežastis.
Komentaras: Eikime toliau ieškodami gero sprendimo.
Kontrolinės sumos
Kontrolinės sumos taip pat leidžia įsitikinti (su pagrįsta tikimybe), kad skaitome būtent tai, kas turėjo būti parašyta. Ir, skirtingai nei aukščiau aptarti bitų laukai, jie visada veikia.
Jei atsižvelgsime į galimų problemų šaltinių sąrašą, kurį aptarėme aukščiau, tada kontrolinė suma gali atpažinti klaidą, nepaisant jos kilmės. (išskyrus, galbūt, piktybinius ateivius - jie taip pat gali suklastoti kontrolinę sumą).
Taigi, jei mūsų tikslas yra patikrinti, ar duomenys nepažeisti, kontrolinės sumos yra puiki idėja.
Kontrolinės sumos skaičiavimo algoritmo pasirinkimas klausimų nekėlė – CRC. Viena vertus, matematinės savybės leidžia 100% pagauti tam tikrų tipų klaidas, kita vertus, atsitiktinių duomenų atveju šis algoritmas dažniausiai parodo susidūrimų tikimybę, ne didesnę nei teorinė riba;  . Galbūt tai nėra greičiausias algoritmas ir ne visada yra minimalus susidūrimų skaičiaus atžvilgiu, tačiau jis turi labai svarbią savybę: atliekant bandymus, su kuriais susidūriau, nebuvo modelių, kuriuose jis aiškiai nepavyktų. Stabilumas šiuo atveju yra pagrindinė kokybė.
. Galbūt tai nėra greičiausias algoritmas ir ne visada yra minimalus susidūrimų skaičiaus atžvilgiu, tačiau jis turi labai svarbią savybę: atliekant bandymus, su kuriais susidūriau, nebuvo modelių, kuriuose jis aiškiai nepavyktų. Stabilumas šiuo atveju yra pagrindinė kokybė.
Tūrinio tyrimo pavyzdys: , (nuorodos į narod.ru, atsiprašau).
Tačiau kontrolinės sumos parinkimo užduotis nėra baigta; Turite nuspręsti dėl ilgio ir pasirinkti daugianarį.
Kontrolinės sumos ilgio pasirinkimas nėra toks paprastas klausimas, kaip atrodo iš pirmo žvilgsnio.
Leiskite man iliustruoti:
Pažymime kiekvieno baito klaidos tikimybę  ir ideali kontrolinė suma, apskaičiuokime vidutinį klaidų skaičių milijonui įrašų:
ir ideali kontrolinė suma, apskaičiuokime vidutinį klaidų skaičių milijonui įrašų:
Duomenys, baitas
Kontrolinė suma, baitas
Neaptiktos klaidos
Klaidingi klaidų nustatymai
Iš viso klaidingų teigiamų rezultatų
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
Atrodytų, viskas paprasta – priklausomai nuo saugomų duomenų ilgio, pasirinkite kontrolinės sumos ilgį su kuo mažiau neteisingų teigiamų – ir gudrybė yra maiše.
Tačiau su trumpomis kontrolinėmis sumomis iškyla problema: nors jos gerai aptinka vieno bito klaidas, tačiau su gana didele tikimybe gali priimti visiškai atsitiktinius duomenis kaip teisingus. Apie Habré jau buvo aprašytas straipsnis .
Todėl, kad atsitiktinės kontrolinės sumos sutapimas būtų beveik neįmanomas, reikia naudoti 32 bitų ar ilgesnes kontrolines sumas. (jei ilgis didesnis nei 64 bitai, paprastai naudojamos kriptografinės maišos funkcijos).
Nepaisant to, kad jau anksčiau rašiau, kad reikia visomis priemonėmis taupyti vietą, vis tiek naudosime 32 bitų kontrolinę sumą (16 bitų neužtenka, susidūrimo tikimybė didesnė nei 0.01% ir 24 bitų, nes jie tarkim, nėra nei čia, nei ten).
Čia gali kilti prieštaravimas: ar rinkdamiesi glaudinimą išsaugojome kiekvieną baitą, kad dabar iš karto duotume 4 baitus? Ar ne geriau nespausti ir nepridėti kontrolinės sumos? Žinoma, ne, jokio suspaudimo nereiškia, kad mums nereikia tikrinti vientisumo.
Renkantis daugianarį, dviračio neišradinėsime iš naujo, o imsime dabar populiarųjį CRC-32C.
Šis kodas aptinka 6 bitų klaidas paketuose iki 22 baitų (galbūt labiausiai paplitęs atvejis pas mus), 4 bitų klaidas paketuose iki 655 baitų (taip pat įprastas atvejis pas mus), 2 arba bet kokį nelyginį skaičių bitų klaidų paketuose bet kokio pagrįsto ilgio.
Jei kam įdomu smulkmenos
apie CRC.
apie - galbūt pirmaujantis CRC specialistas planetoje.
В yra , kuriame pateikiami šiek tiek geresni parametrai mums aktualiems paketų ilgiams, tačiau skirtumo nelaikiau reikšmingu ir buvau pakankamai kompetentinga pasirinkti ne standartinį ir gerai ištirtą, o individualų kodą.
Be to, kadangi mūsų duomenys yra suglaudinti, kyla klausimas: ar skaičiuoti suspaustų ar nesuspaustų duomenų kontrolinę sumą?
Argumentai už nesuspaustų duomenų kontrolinės sumos apskaičiavimą:
- Galų gale turime patikrinti duomenų saugojimo saugumą – todėl tikriname tiesiogiai (tuo pačiu bus tikrinamos galimos suspaudimo/dekompresijos įgyvendinimo klaidos, sugedusios atminties pažeidimai ir pan.);
- Defliacijos algoritmas zlib turi gana brandų įgyvendinimą ir neturėtų kritimas su „kreivais“ įvesties duomenimis, be to, jis dažnai gali savarankiškai aptikti klaidas įvesties sraute, sumažindamas bendrą klaidos neaptikimo tikimybę (atliktas testas apverčiant vieną bitą trumpame įraše, zlib aptiko klaidą); maždaug trečdaliu atvejų).
Argumentai prieš nesuspaustų duomenų kontrolinės sumos skaičiavimą:
- CRC yra „pritaikytas“ specialiai kelioms bitų klaidoms, būdingoms „flash“ atminčiai (bitų klaida suspaustame sraute gali sukelti didžiulį išvesties srauto pokytį, dėl kurio, grynai teoriškai, galime „pagauti“ susidūrimą);
- Man nelabai patinka mintis perduoti potencialiai sugadintus duomenis į dekompresorių, kaip jis reaguos.
Šiame projekte nusprendžiau nukrypti nuo visuotinai priimtos nesuspaustų duomenų kontrolinės sumos saugojimo praktikos.
Komentaras: Naudojame CRC-32C, skaičiuojame kontrolinę sumą iš duomenų tokia forma, kokia jie įrašyti į flash (po suspaudimo).
Perteklius
Perteklinio kodavimo naudojimas, žinoma, nepašalina duomenų praradimo, tačiau gali žymiai (dažnai daugeliu dydžių) sumažinti nepataisomo duomenų praradimo tikimybę.
Klaidoms ištaisyti galime naudoti įvairių tipų perteklių.
Hamming kodai gali ištaisyti vieno bito klaidas, Reed-Solomon simbolių kodus, kelias duomenų kopijas kartu su kontroliinėmis sumomis arba kodavimus, pvz., RAID-6, gali padėti atkurti duomenis net ir didelės sugadinimo atveju.
Iš pradžių buvau pasiryžęs plačiai naudoti klaidoms atsparų kodavimą, bet tada supratau, kad pirmiausia turime turėti idėją, nuo kokių klaidų norime apsisaugoti, o tada pasirinkti kodavimą.
Anksčiau sakėme, kad klaidas reikia sugauti kuo greičiau. Kuriais atvejais galime susidurti su klaidomis?
- Nebaigtas įrašymas (dėl tam tikrų priežasčių įrašymo metu maitinimas buvo išjungtas, Raspberry užšalo, ...)
Deja, įvykus tokiai klaidai, belieka ignoruoti negaliojančius įrašus ir laikyti duomenis prarastus; - Rašymo klaidos (dėl tam tikrų priežasčių į „flash“ atmintį buvo įrašyta ne tai, kas buvo parašyta)
Tokias klaidas galime aptikti iš karto, jei atliksime bandomąjį skaitymą iškart po įrašymo; - Duomenų iškraipymas atmintyje saugojimo metu;
- Skaitymo klaidos
Norėdami jį ištaisyti, jei kontrolinė suma nesutampa, pakanka pakartoti skaitymą keletą kartų.
Tai yra, tik trečiojo tipo klaidos (spontaniškas duomenų sugadinimas saugojimo metu) negali būti ištaisytos be klaidoms atsparaus kodavimo. Atrodo, kad tokios klaidos vis dar labai mažai tikėtinos.
Komentaras: buvo nuspręsta atsisakyti perteklinio kodavimo, tačiau jei operacija rodo šio sprendimo klaidą, grįžti prie klausimo svarstymo (su jau sukaupta gedimų statistika, kuri leis pasirinkti optimalų kodavimo tipą).
Kiti
Žinoma, straipsnio formatas neleidžia mums pateisinti kiekvieno formato smulkmenų (ir mano jėgos jau baigėsi), todėl trumpai apžvelgsiu kai kuriuos anksčiau nepaliestus dalykus.
- Buvo nuspręsta visus puslapius padaryti „lygius“
Tai reiškia, kad nebus jokių specialių puslapių su metaduomenimis, atskiromis gijomis ir pan., o viena gija, kuri perrašo visus puslapius paeiliui.
Tai užtikrina tolygų puslapių nusidėvėjimą, jokio gedimo taško, ir man tai tiesiog patinka; - Būtina pateikti formato versiją.
Formatas be versijos numerio antraštėje yra blogis!
Pakanka prie puslapio antraštės pridėti lauką su tam tikru stebuklingu numeriu (parašu), kuris nurodys naudojamo formato versiją (Nemanau, kad praktiškai jų bus net keliolika); - Įrašams (kurių yra daug) naudokite kintamo ilgio antraštę, daugeliu atvejų stengdamiesi, kad ji būtų 1 baito ilgio;
- Norėdami užkoduoti suspausto įrašo antraštės ilgį ir apkarpytos dalies ilgį, naudokite kintamo ilgio dvejetainius kodus.
Labai padėjo Huffmano kodai. Vos per kelias minutes galėjome pasirinkti reikiamus kintamo ilgio kodus.
Duomenų saugojimo formato aprašymas
Baitų tvarka
Laukai, didesni nei vienas baitas, saugomi big-endian formatu (tinklo baitų tvarka), tai yra, 0x1234 rašomas kaip 0x12, 0x34.
Puslapių rašymas
Visa „flash“ atmintis yra padalinta į vienodo dydžio puslapius.
Numatytasis puslapio dydis yra 32Kb, bet ne daugiau kaip 1/4 viso atminties lusto dydžio (4MB lustui gaunami 128 puslapiai).
Kiekvienas puslapis saugo duomenis nepriklausomai nuo kitų (ty viename puslapyje esantys duomenys nenurodo kito puslapio duomenų).
Visi puslapiai sunumeruoti natūralia tvarka (adresų didėjimo tvarka), pradedant skaičiumi 0 (nulis puslapis prasideda adresu 0, pirmasis puslapis prasideda nuo 32 Kb, antrasis prasideda nuo 64 Kb ir t. t.)
Atminties lustas naudojamas kaip ciklinis buferis (žiedinis buferis), tai yra, pirmiausia rašoma į 0 puslapį, po to 1, ..., kai užpildome paskutinį puslapį, prasideda naujas ciklas ir įrašymas tęsiamas nuo nulio puslapio. .
Puslapio viduje

Puslapio pradžioje išsaugoma 4 baitų puslapio antraštė, tada antraštės kontrolinė suma (CRC-32C), tada įrašai išsaugomi „antraštės, duomenų, kontrolinės sumos“ formatu.
Puslapio pavadinimą (schemoje nešvariai žalią) sudaro:
- dviejų baitų magiškojo skaičiaus laukas (taip pat formato versijos ženklas)
dabartinei formato versijai jis apskaičiuojamas kaip0xed00 ⊕ номер страницы; - dviejų baitų skaitiklis „Puslapio versija“ (atminties perrašymo ciklo numeris).
Įrašai puslapyje saugomi suglaudinta forma (naudojamas defliacijos algoritmas). Visi įrašai viename puslapyje suglaudinami vienoje gijoje (naudojamas bendras žodynas), o kiekviename naujame puslapyje glaudinimas pradedamas iš naujo. Tai yra, norint išspausti bet kurį įrašą, reikalingi visi ankstesni šio puslapio (ir tik šio) įrašai.
Kiekvienas įrašas bus suglaudintas su Z_SYNC_FLUSH vėliava, o suspausto srauto pabaigoje bus 4 baitai 0x00, 0x00, 0xff, 0xff, prieš kurį galbūt bus dar vienas ar du nulis baitai.
Šią seką (4, 5 arba 6 baitų ilgio) atmetame, kai rašome į „flash“ atmintį.
Įrašo antraštėje yra 1, 2 arba 3 baitai, kuriuose saugoma:
- vienas bitas (T), nurodantis įrašo tipą: 0 - kontekstas, 1 - log;
- kintamo ilgio laukas (S) nuo 1 iki 7 bitų, apibrėžiantis antraštės ilgį ir „uodegą“, kuri turi būti įtraukta į įrašą, kad būtų galima išskleisti;
- rekordinio ilgio (L).
S verčių lentelė:
S
Antraštės ilgis, baitai
Išmesta rašant, baitas
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Bandžiau iliustruoti, nežinau, kaip aiškiai tai pasirodė:
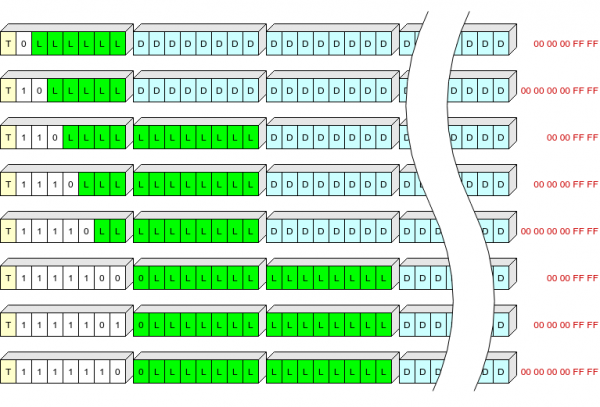
Geltona čia nurodo T lauką, balta S lauką, žalia L (suglaudintų duomenų ilgis baitais), mėlyna suglaudintus duomenis, raudona – paskutinius suglaudintų duomenų baitus, kurie neįrašomi į „flash“ atmintį.
Taigi į vieną baitą galime įrašyti įprasto ilgio (iki 63+5 baitų suspaustoje formoje) įrašų antraštes.
Po kiekvieno įrašo išsaugoma CRC-32C kontrolinė suma, kurioje kaip pradinė reikšmė (init) naudojama apversta ankstesnės kontrolinės sumos reikšmė.
CRC turi „trukmės“ savybę, veikia ši formulė (procese apverčiama plius arba minus bitai):  .
.
Tai yra, iš tikrųjų mes apskaičiuojame visų ankstesnių šio puslapio antraščių ir duomenų baitų CRC.
Tiesiogiai po kontrolinės sumos yra kito įrašo antraštė.
Antraštė sukurta taip, kad jos pirmasis baitas visada skiriasi nuo 0x00 ir 0xff (jei vietoje pirmojo antraštės baito susiduriame su 0xff, tai reiškia, kad tai nenaudojama sritis; 0x00 signalizuoja apie klaidą).
Algoritmų pavyzdžiai
Skaitymas iš „Flash“ atminties
Bet koks skaitymas yra su kontrolinės sumos patikrinimu.
Jei kontrolinė suma nesutampa, skaitymas kartojamas keletą kartų, tikintis nuskaityti teisingus duomenis.
(tai prasminga, Linux Netalpina rodmenų iš NOR Flash, patvirtinta)
Įrašykite į "flash" atmintį
Duomenis įrašome.
Skaitykime juos.
Jei nuskaityti duomenys nesutampa su įrašytais, užpildome sritį nuliais ir signalizuojame apie klaidą.
Naujos mikroschemos paruošimas darbui
Inicijuojant antraštė su 1 versija įrašoma į pirmąjį (tiksliau nulį) puslapį.
Po to šiame puslapyje įrašomas pradinis kontekstas (jame yra įrenginio UUID ir numatytieji nustatymai).
Tai viskas, „flash“ atmintis yra paruošta naudoti.
Mašinos pakrovimas
Įkeliant nuskaitomi pirmieji 8 kiekvieno puslapio baitai (antraštė + CRC), ignoruojami puslapiai su nežinomu magišku numeriu arba neteisingu CRC.
Iš „teisingo“ puslapių pasirenkami puslapiai su maksimalia versija ir iš jų paimamas puslapis su didžiausiu numeriu.
Nuskaitomas pirmasis įrašas, patikrinamas CRC teisingumas ir „konteksto“ vėliavėlės buvimas. Jei viskas gerai, šis puslapis laikomas naujausiu. Jei ne, grįžtame prie ankstesnio, kol randame „gyvą“ puslapį.
ir rastame puslapyje skaitome visus įrašus, tuos, kuriuos naudojame su „konteksto“ vėliavėle.
Išsaugokite zlib žodyną (jo reikės norint įtraukti į šį puslapį).
Tai viskas, atsisiuntimas baigtas, kontekstas atkurtas, galite dirbti.
Žurnalo įrašo pridėjimas
Suspaudžiame įrašą naudodami teisingą žodyną, nurodydami Z_SYNC_FLUSH. Matome, ar suspaustas įrašas telpa dabartiniame puslapyje.
Jei jis netelpa (arba puslapyje buvo CRC klaidų), pradėkite naują puslapį (žr. toliau).
Užrašome įrašą ir CRC. Jei įvyksta klaida, pradėkite naują puslapį.
Naujas puslapis
Mes pasirenkame nemokamą puslapį su minimaliu skaičiumi (nemokamu puslapiu laikome puslapį, kurio antraštėje yra neteisinga kontrolinė suma arba kurio versija yra mažesnė nei dabartinė). Jei tokių puslapių nėra, pasirinkite puslapį su mažiausiu skaičiumi iš tų, kurių versija yra lygi dabartinei.
Ištriname pasirinktą puslapį. Tikriname turinį naudodami 0xff. Jei kažkas negerai, eikite į kitą nemokamą puslapį ir pan.
Ištrintame puslapyje rašome antraštę, pirmas įrašas – esama konteksto būsena, kitas – nerašytas žurnalo įrašas (jei toks yra).
Formato pritaikomumas
Mano nuomone, tai pasirodė geras formatas bet kokiems daugiau ar mažiau suspaudžiamiems informacijos srautams (plain text, JSON, MessagePack, CBOR, galbūt protobuf) saugoti NOR Flash.
Žinoma, formatas yra „pritaikytas“ SLC NOR Flash.
Jis neturėtų būti naudojamas su didelės BER laikmenomis, tokiomis kaip NAND arba MLC NOR (ar tokią atmintį išvis galima parduoti? Mačiau, kad ji minima tik darbuose apie taisymo kodus).
Be to, jis neturėtų būti naudojamas su įrenginiais, kurie turi savo FTL: USB atmintinę, SD, MicroSD ir kt (tokiai atminčiai sukūriau formatą, kurio puslapio dydis yra 512 baitų, parašas kiekvieno puslapio pradžioje ir unikalūs įrašų numeriai - kartais buvo įmanoma atkurti visus duomenis iš „sugedusio“ „flash drive“ paprastu nuosekliu skaitymu).
Priklausomai nuo užduočių, formatą galima naudoti be pakeitimų „flash drives“ nuo 128Kbit (16Kb) iki 1Gbit (128MB). Jei pageidaujate, galite naudoti ant didesnių lustų, bet tikriausiai turėsite pakoreguoti puslapio dydį (Bet čia jau kyla ekonominio pagrįstumo klausimas; didelės apimties NOR Flash kaina nėra džiuginanti).
Jei kam nors formatas įdomus ir nori jį panaudoti atvirame projekte, rašykite, pabandysiu rasti laiko, nušlifuosiu kodą ir įdėsiu į github.
išvada
Kaip matote, galiausiai formatas pasirodė paprastas ir net nuobodu.
Straipsnyje sunku atspindėti savo požiūrio raidą, bet patikėkite manimi: iš pradžių norėjau sukurti kažką įmantraus, nesugriaunamo, galinčio išgyventi net branduolinį sprogimą arti. Tačiau protas (tikiuosi) vis tiek nugalėjo ir pamažu prioritetai krypo link paprastumo ir kompaktiškumo.
Ar gali būti, kad aš klydau? Taip, žinoma. Pavyzdžiui, gali pasirodyti, kad įsigijome žemos kokybės mikroschemų partiją. Arba dėl kokių nors kitų priežasčių įranga neatitiks patikimumo lūkesčių.
Ar turiu tam planą? Manau, kad perskaitę straipsnį neabejojate, kad planas yra. Ir net ne vienas.
Kalbant kiek rimčiau, formatas buvo sukurtas ir kaip darbinis variantas, ir kaip „bandomasis balionas“.
Šiuo metu viskas ant stalo veikia gerai, tiesiog kitą dieną sprendimas bus įdiegtas (maždaug) šimtuose įrenginių, pažiūrėkime, kas vyksta „kovinėje“ operacijoje (laimei, tikiuosi, kad formatas leidžia patikimai aptikti gedimus; todėl galite rinkti visą statistiką). Po kelių mėnesių bus galima daryti išvadas (o jei nepasisekė, dar anksčiau).
Jei, remiantis naudojimo rezultatais, bus aptiktos rimtos problemos ir reikalingi patobulinimai, aš tikrai apie tai parašysiu.
Literatūra
Nenorėjau sudaryti ilgo varginančio naudotų darbų sąrašo, juk visi turi Google.
Čia nusprendžiau palikti radinių, kurie man atrodė ypač įdomūs, sąrašą, bet pamažu jie persikėlė tiesiai į straipsnio tekstą ir sąraše liko vienas punktas:
- Naudingumas iš autoriaus zlib. Gali aiškiai parodyti deflate/zlib/gzip archyvų turinį. Jei turite susidurti su vidine deflate (arba gzip) formato struktūra, labai rekomenduoju.
Šaltinis: www.habr.com
