

Prieš pusę metų - viešas į PostgreSQL.
Per pastaruosius mėnesius mes apie jį rašėme , parengė santrauką remdamiesi pateiktomis rekomendacijomis... bet svarbiausia, surinkome jūsų atsiliepimus ir išnagrinėjome realius naudojimo atvejus.
O dabar esame pasirengę kalbėti apie naujas galimybes, kuriomis galite pasinaudoti.
Įvairių planų formatų palaikymas
Planas iš žurnalo kartu su prašymu
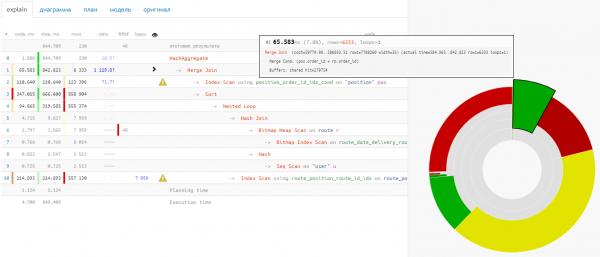
Tiesiogiai iš konsolės pasirinkite visą bloką, pradedant nuo eilutės su Užklausos tekstas, su visomis pirmaujančiomis erdvėmis:
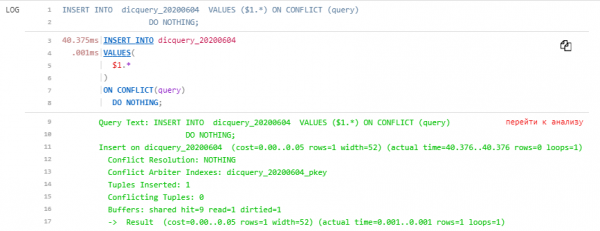
Query Text: INSERT INTO dicquery_20200604 VALUES ($1.*) ON CONFLICT (query)
DO NOTHING;
Insert on dicquery_20200604 (cost=0.00..0.05 rows=1 width=52) (actual time=40.376..40.376 rows=0 loops=1)
Conflict Resolution: NOTHING
Conflict Arbiter Indexes: dicquery_20200604_pkey
Tuples Inserted: 1
Conflicting Tuples: 0
Buffers: shared hit=9 read=1 dirtied=1
-> Result (cost=0.00..0.05 rows=1 width=52) (actual time=0.001..0.001 rows=1 loops=1)
... ir įdėti viską, nukopijuotą tiesiai į plano lauką, nieko neatskirdami:
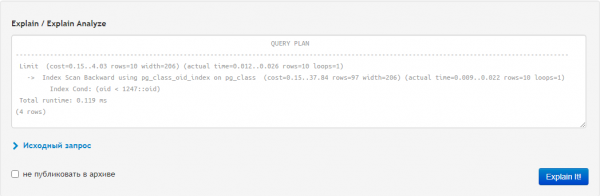
Pabaigoje gauname premiją prie išardyto plano ir "kontekstas" skirtukas, kur mūsų prašymas pateikiamas visoje savo šlovėje:
JSON ir YAML
EXPLAIN (ANALYZE, BUFFERS, FORMAT JSON)
SELECT * FROM pg_class;"[
{
"Plan": {
"Node Type": "Seq Scan",
"Parallel Aware": false,
"Relation Name": "pg_class",
"Alias": "pg_class",
"Startup Cost": 0.00,
"Total Cost": 1336.20,
"Plan Rows": 13804,
"Plan Width": 539,
"Actual Startup Time": 0.006,
"Actual Total Time": 1.838,
"Actual Rows": 10266,
"Actual Loops": 1,
"Shared Hit Blocks": 646,
"Shared Read Blocks": 0,
"Shared Dirtied Blocks": 0,
"Shared Written Blocks": 0,
"Local Hit Blocks": 0,
"Local Read Blocks": 0,
"Local Dirtied Blocks": 0,
"Local Written Blocks": 0,
"Temp Read Blocks": 0,
"Temp Written Blocks": 0
},
"Planning Time": 5.135,
"Triggers": [
],
"Execution Time": 2.389
}
]"Arba su išorinėmis kabutėmis, kaip pgAdmin kopijomis, arba be jos - metame į tą patį lauką, o išvestis yra grožis:

Išplėstinė vizualizacija
Planavimo laikas / vykdymo laikas
Dabar galite geriau matyti, kur buvo praleistas papildomas laikas vykdant užklausą:
I/O laikas
Kartais tenka susidurti su situacija, kai, kalbant apie išteklius, atrodo, kad perskaityta ir parašyta ne per daug, bet vykdymo laikas atrodo nederamai ilgas.
Čia turime pasakyti: "O, tikriausiai tuo metu serverio diskas buvo per daug perkrautas, todėl skaitymas užtruko taip ilgai!"Bet kažkaip tai nėra labai tikslu...
Bet tai galima nustatyti visiškai patikimai. Faktas yra tas, kad tarp PG serverio konfigūravimo parinkčių yra :
Įgalina įvesties / išvesties operacijų laiką. Ši parinktis pagal numatytuosius nustatymus yra išjungta, nes reikia nuolat teirautis operacinėje sistemoje dabartinio laiko, o tai gali žymiai sulėtinti kai kurių platformų našumą. Norėdami apskaičiuoti laiko sąnaudas savo platformoje, galite naudoti pg_test_timing įrankį. Įvesties / išvesties statistiką galima gauti naudojant pg_stat_database rodinį, EXPLAIN išvestyje (kai naudojamas parametras BUFFERS) ir per pg_stat_statements rodinį.
Šią parinktį taip pat galima įjungti vietinės sesijos metu:
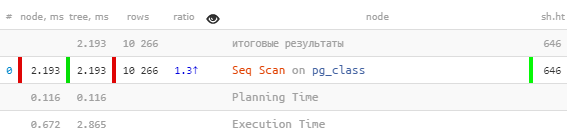
SET track_io_timing = TRUE;Na, o dabar geriausia yra tai, kad mes išmokome suprasti ir rodyti šiuos duomenis atsižvelgdami į visas vykdymo medžio transformacijas:
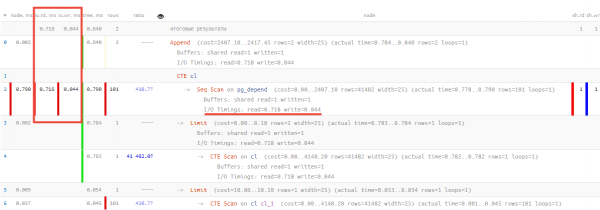
Čia matote, kad iš 0.790 ms viso vykdymo laiko, 0.718 ms užtruko perskaityti vieną duomenų puslapį, 0.044 ms užtruko jį parašyti ir tik 0.028 ms buvo išleista visai kitai naudingai veiklai!
Ateitis su PostgreSQL 13
Galite rasti visą naujovių apžvalgą , o mes konkrečiai kalbame apie planų pokyčius.
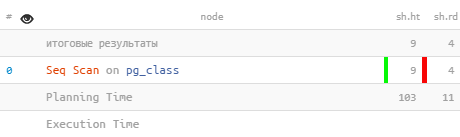
Planavimo buferiai
Planuokliui skirtų išteklių apskaita atsispindi kitame pataisyme, nesusijusiame su pg_stat_statements. EXPLAIN su parinktimi BUFFERIAI praneš apie buferių, naudojamų planavimo etape, skaičių:
Seq Scan on pg_class (actual rows=386 loops=1) Buffers: shared hit=9 read=4 Planning Time: 0.782 ms Buffers: shared hit=103 read=11 Execution Time: 0.219 ms
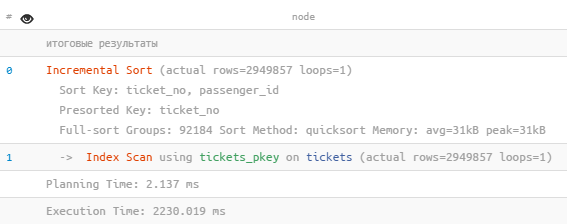
Laipsniškas rūšiavimas
Tais atvejais, kai reikia rūšiuoti daugybe raktų (k1, k2, k3...), planuotojas dabar gali pasinaudoti žiniomis, kad duomenys jau surūšiuoti keliuose pirmuosiuose raktuose (pavyzdžiui, k1 ir k2). Tokiu atveju negalite iš naujo rūšiuoti visų duomenų, o suskirstyti juos į grupes, kurių k1 ir k2 reikšmės yra vienodos, ir „perrūšiuoti“ raktu k3.
Taigi visas rūšiavimas yra padalintas į keletą nuoseklių mažesnių dydžių rūšių. Tai sumažina reikalingos atminties kiekį ir leidžia išvesti pirmuosius duomenis prieš baigiant rūšiavimą.
Incremental Sort (actual rows=2949857 loops=1) Sort Key: ticket_no, passenger_id Presorted Key: ticket_no Full-sort Groups: 92184 Sort Method: quicksort Memory: avg=31kB peak=31kB -> Index Scan using tickets_pkey on tickets (actual rows=2949857 loops=1) Planning Time: 2.137 ms Execution Time: 2230.019 ms
UI/UX patobulinimai
Ekrano kopijos, jos yra visur!
Dabar kiekviename skirtuke yra galimybė greitai nufotografuokite skirtuko ekrano kopiją į mainų sritį visas skirtuko plotis ir gylis - "vaizdas" dešinėje viršuje:
Tiesą sakant, dauguma šio leidinio nuotraukų buvo gautos tokiu būdu.
Rekomendacijos dėl mazgų
Jų ne tik padaugėjo, bet ir apie kiekvieną galima kalbėti sekant nuorodą:

Ištrinama iš archyvo
Kai kurie žmonės tikrai prašė pridėti parinktį ištrinti "visiškai" net planus, kurie nėra paskelbti archyve – tiesiog spustelėkite atitinkamą piktogramą:
Na, nepamirškite, kad mes turime , kur galite rašyti savo pastabas ir pasiūlymus.
Šaltinis: www.habr.com
