

Ši pastaba bus įdomi tiems, kurie naudoja lentelių duomenų apdorojimo biblioteką R - data.table, ir gali būti malonu matyti jos naudojimo lankstumą įvairiuose pavyzdžiuose.
Įkvėptas gero pavyzdžio , ir tikėdamasis, kad jau perskaitėte jo straipsnį, siūlau gilintis į kodo optimizavimą ir našumą remiantis duomenys. lentelė.
Įvadas: iš kur atsiranda data.table?
Pažintį su biblioteka geriausia pradėti šiek tiek iš tolo, būtent su duomenų struktūromis, iš kurių galima gauti objektą data.table (toliau – DT).
Masyvas
Kodas
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Viena iš tokių struktūrų yra masyvas (?base::masyvas). Kaip ir kitomis kalbomis, čia masyvai yra daugiamačiai. Tačiau įdomu tai, kad, pavyzdžiui, dvimatis masyvas pradeda paveldėti savybes iš matricos klasės (?base::matrica), o vienmatis masyvas, kuris taip pat svarbus, nepaveldimas iš vektoriaus (?bazė::vektorius).
Reikėtų suprasti, kad bet kuriame objekte esančių duomenų tipas turėtų būti patikrintas naudojant funkciją bazė::typeof, kuris grąžina vidinio tipo aprašą pagal R Vidiniai - bendrasis su originalu susijusios kalbos protokolas C.
Kita komanda objekto klasei nustatyti yra bazė::klasė, vektorių atveju grąžina vektoriaus tipą (pavadinimu jis skiriasi nuo vidinio, bet leidžia suprasti ir duomenų tipą).
Sąrašas
Iš dvimačio masyvo, dar žinomo kaip matrica, galite pereiti į sąrašą (?base::sąrašas).
Kodas
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Keli dalykai vyksta vienu metu:
- Antrasis matricos matmuo žlunga, tai yra, gauname ir sąrašą, ir vektorių vienu metu.
- Taigi sąrašas paveldimas iš šių klasių. Reikia nepamiršti, kad sąrašo elementas atitiks vieną (skaliarinę) reikšmę iš masyvo matricos langelio.
Kadangi sąrašas taip pat yra vektorius, jam gali būti taikomos kai kurios vektorinės funkcijos.
Duomenų rėmelis
Iš sąrašo, matricos ar vektoriaus galite pereiti prie duomenų rėmelio (?base::data.frame).
Kodas
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Kas čia įdomaus: duomenų rėmelis paveldimas iš sąrašo! Duomenų rėmelių stulpeliai yra sąrašo langeliai. Tai bus svarbu vėliau, kai naudosime sąrašams taikomas funkcijas.
duomenys. lentelė
Gaukite DT (?duomenys.lentelė::duomenų.lentelė) gali būti iš duomenų rėmelis, sąrašas, vektorius arba matrica. Pavyzdžiui, kaip šis (vietoje).
Kodas
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Naudinga, kad DT, kaip ir duomenų rėmelis, paveldi sąrašo savybes.
DT ir atmintis
Skirtingai nuo visų kitų R bazės objektų, DT perduodami pagal nuorodą. Jei reikia nukopijuoti į naują atminties sritį, reikia funkcijos data.table::copy arba reikia pasirinkti iš seno objekto.
Kodas
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Tuo įžanga baigiama. DT yra R duomenų struktūrų kūrimo tęsinys, kuris daugiausia atsiranda dėl operacijų, atliekamų su duomenų rėmelių klasės objektais, išplėtimo ir pagreitinimo. Tuo pačiu išsaugomas paveldėjimas iš kitų primityvų.
Keli data.table ypatybių naudojimo pavyzdžiai
Kaip sąrašas...
Iteruoti duomenų rėmelio arba DT eilutes nėra gera idėja, nes ciklo kodas kalba R daug lėčiau C, tačiau visiškai įmanoma pereiti per stulpelius, kurie paprastai yra daug mažesni. Eidami per stulpelius atminkite, kad kiekvienas stulpelis yra sąrašo elementas, kuriame paprastai yra vektorius. Ir operacijos su vektoriais yra gerai vektorizuotos pagrindinėse kalbos funkcijose. Taip pat galite naudoti sąrašams ir vektoriams bendrus pasirinkimo operatorius: `[[`, "$"..
Kodas
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorizacija
Jei reikia eiti per didelio DT eilutes, geriausias sprendimas būtų parašyti funkciją su vektorizavimu. Bet jei tai neveikia, turėtumėte atsiminti, kad ciklas per DT vis dar greitesnis už ciklą R, nes jis atliekamas C.
Pabandykime tai didesniame pavyzdyje su 100 XNUMX eilučių. Pirmąją raidę ištrauksime iš žodžių, įtrauktų į vektoriaus stulpelį w.
Atnaujinta
Kodas
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Pirmiausia paleiskite kartojimą eilutėse:
Vienetas: milisekundės
min
{ dt[, `:=`(pirmas_l, unlist(strsplit(w, split = " ", fiksuotas = T))[1]), by = 1:nrow(dt)] } 439.6217
lq vidurkis mediana uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Antrasis paleidimas, kai vektorizavimas įvyksta paverčiant sąrašą į matricą ir paimant elementus iš pjūvio su indeksu 1 (pastarasis yra pats vektorizavimas). Pataisymas: vektorizavimas funkcijos lygiu strsplit, kuris gali priimti vektorių kaip įvestį. Pasirodo, sąrašo pavertimo matrica procedūra yra daug sunkesnė nei pati vektorizacija, tačiau šiuo atveju ji yra daug greitesnė nei ne vektorizuota versija.
Vienetas: milisekundės
expr min lq vidurkis mediana uq max neval
{ dt[, `:=`(pirmas_l, .(pirmas_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Pagreitis pagal medianą in 3 kartas.
Trečiasis važiavimas, kai buvo pakeista transformacijos į matricą schema.
Vienetas: milisekundės
expr min lq vidurkis mediana uq max neval
{ dt[, `:=`(pirmas_l, .(pirmas_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Pagreitis pagal medianą in 13 kartas.
Reikia eksperimentuoti su šiuo klausimu, kuo daugiau, tuo geriau.
Kitas pavyzdys su vektorizavimu, kur yra ir tekstas, bet jis artimas realioms sąlygoms: skirtingas žodžių ilgis, skirtingas žodžių skaičius. Turite gauti pirmuosius 3 žodžius. Kaip šitas:
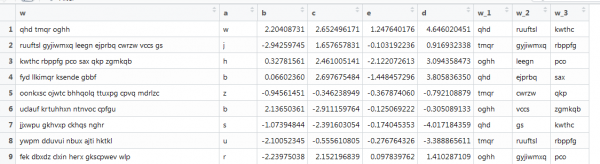
Čia ankstesnė funkcija neveikia, nes vektoriai yra skirtingo ilgio, o mes nustatome matricos dydį. Pakartokime tai naršydami internete.
Kodas
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Vienetas: milisekundės
expr min lq vidutinė mediana
{ dt[, `:=`((įklijuoti0("w_", 1:3)), strsplit(w, split = " ", fiksuota = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Scenarijus veikė vidutiniu 1 sekundės greičiu. Neblogai.
Sujungta viena grandine...
Galite dirbti su DT objektais naudodami grandininę funkciją. Panašu, kad dešinėje pusėje pridedama skliausto sintaksė, iš esmės cukrus.
Kodas
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Teka per vamzdžius...
Tas pačias operacijas galima atlikti per vamzdyną, jis atrodo panašiai, bet yra funkcionalesnis, nes galite naudoti bet kokius metodus, ne tik DT. Išveskime savo sintetinių duomenų logistinės regresijos koeficientus naudodami daugybę DT filtrų.
Kodas
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statistika, mašininis mokymasis ir daugiau DT viduje
Galite naudoti lambda funkcijas, tačiau kartais geriau jas sukurti atskirai, parašyti visą duomenų analizės dujotiekį ir pirmyn – jos veikia DT viduje. Pavyzdys praturtintas visomis aukščiau paminėtomis funkcijomis ir keletu naudingų dalykų iš DT arsenalo (pavyzdžiui, prieiga prie paties DT DT viduje per nuorodą, kartais įterpiama ne nuosekliai, o taip, kad būtų).
Kodas
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
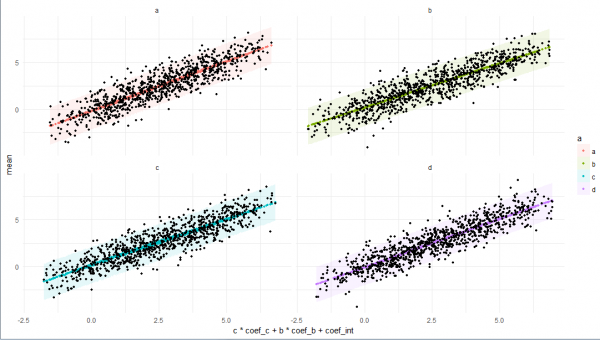
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
išvada
Tikiuosi, kad man pavyko sukurti išsamų, bet, žinoma, ne pilną tokio objekto, kaip data.table, vaizdą, pradedant nuo jo savybių, susijusių su paveldėjimu iš R klasių, ir baigiant jo savybėmis ir aplinka iš tvarkingų elementų. . Tikiuosi, kad tai padės jums geriau išmokti ir naudoti šią biblioteką darbe ir pramoga.
Dėkojame!
Pilnas kodas
Kodas
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Šaltinis: www.habr.com
