


Straipsnyje aprašoma, kaip įgyvendinti WMS-sistema, susidūrėme su būtinybe išspręsti nestandartinę klasterizacijos problemą ir kokiais algoritmais ją sprendėme. Papasakosime, kaip taikėme sistemingą, mokslišką problemos sprendimo būdą, su kokiais sunkumais susidūrėme ir kokias pamokas išmokome.
Šis leidinys pradeda straipsnių ciklą, kuriame dalinamės sėkminga patirtimi diegiant optimizavimo algoritmus sandėlio procesuose. Straipsnių ciklo tikslas – supažindinti auditoriją su beveik bet kuriame vidutiniame ir dideliame sandėlyje iškylančiais sandėlio veiklos optimizavimo problemų tipais, taip pat papasakoti apie mūsų patirtį sprendžiant tokias problemas ir spąstus, su kuriais susiduriama kelyje. . Straipsniai bus naudingi dirbantiems sandėlių logistikos pramonėje, diegiant WMS-sistemoms, taip pat programuotojams, kurie domisi matematikos taikymu versle ir procesų optimizavimu įmonėje.
Kliūtis procesuose
2018 metais baigėme įgyvendinti projektą WMS-sistemos įmonės „Trading House „LD“ sandėlyje Čeliabinske. Įdiegėme produktą „1C-Logistics: Warehouse Management 3“ 20 darbo vietų: operatoriams WMS, sandėlininkai, šakinių krautuvų vairuotojai. Vidutinis sandėlis apie 4 tūkst.m2, kamerų skaičius 5000, o SKU – 4500. Sandėlyje laikomi mūsų pačių gaminami įvairių dydžių rutuliniai vožtuvai nuo 1 kg iki 400 kg. Atsargos sandėlyje saugomos partijomis, nes reikia atrinkti prekes pagal FIFO.
Kurdami sandėlio procesų automatizavimo schemas susidūrėme su esama neoptimalaus atsargų saugojimo problema. Kranų laikymo ir krovimo specifika yra tokia, kad viename sandėliavimo elemente gali būti tik vienos partijos prekės. Produktai į sandėlį atkeliauja kasdien ir kiekvienas atvežimas yra atskira partija. Iš viso dėl 1 mėnesio sandėlio veiklos sukuriama 30 atskirų partijų, nepaisant to, kad kiekviena turėtų būti saugoma atskirame langelyje. Gaminiai dažnai atrenkami ne ištisais padėklais, o gabalais, todėl gabalų atrankos zonoje daugelyje langelių pastebimas toks vaizdas: kameroje, kurios tūris didesnis nei 1 m3, yra keli kranų gabalai, kurie užima mažiau nei 5-10% ląstelės tūrio.
 1 pav. Kelių prekių vienetų nuotrauka ląstelėje
1 pav. Kelių prekių vienetų nuotrauka ląstelėje
Akivaizdu, kad saugojimo talpa nėra optimaliai išnaudojama. Norėdami įsivaizduoti nelaimės mastą, galiu pateikti skaičius: vidutiniškai yra nuo 1 iki 3 tokių kamerų, kurių tūris didesnis nei 100 m300 su „minusiniais“ likučiais skirtingais sandėlio veikimo laikotarpiais. Kadangi sandėlis yra santykinai mažas, sandėlio užimtumo sezono metu šis veiksnys tampa „butelio kakleliu“ ir labai sulėtina sandėlio procesus.
Problemos sprendimo idėja
Kilo mintis: likučių partijas su artimiausiomis datomis reikėtų sumažinti iki vienos partijos, o tokius likučius su vieninga partija kompaktiškai sudėti į vieną langelį arba į kelias, jei vienoje neužtenka vietos sutalpinti. visą likučių kiekį.
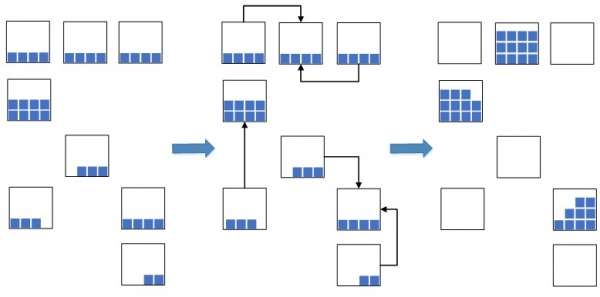
2 pav. Likučių suspaudimo ląstelėse schema
Tai leidžia žymiai sumažinti užimamą sandėlio plotą, kuris bus naudojamas naujoms prekėms patalpinti. Esant situacijai, kai sandėlio talpa yra perkrauta, tokia priemonė yra itin reikalinga, nes kitaip gali tiesiog neužtekti laisvos vietos naujoms prekėms talpinti, o tai lems sandėlio talpinimo ir papildymo procesų sustojimą. Anksčiau prieš įgyvendinant WMS-sistemos šią operaciją atliko rankiniu būdu, o tai buvo neefektyvu, nes tinkamų likučių paieškos ląstelėse procesas buvo gana ilgas. Dabar, įdiegę WMS sistemą, nusprendėme automatizuoti procesą, pagreitinti ir padaryti jį išmanų.
Tokios problemos sprendimo procesas yra padalintas į 2 etapus:
- pirmajame etape randame partijų grupes, kurios yra artimos suspaudimui;
- antrajame etape kiekvienai partijų grupei apskaičiuojame kompaktiškiausią likusių prekių išdėstymą ląstelėse.
Šiame straipsnyje daugiausia dėmesio skirsime pirmajam algoritmo etapui, o antrojo etapo aprėptį paliksime kitam straipsniui.
Ieškokite matematinio problemos modelio
Prieš sėsdami rašyti kodą ir išradinėti savo dviratį, nusprendėme šią problemą pažvelgti moksliškai, būtent: suformuluoti ją matematiškai, redukuoti iki gerai žinomos diskrečios optimizavimo problemos ir panaudoti efektyvius esamus algoritmus, kad ją išspręstume, arba pasinaudoti šiais esamais algoritmais. kaip pagrindą ir modifikuoti juos pagal sprendžiamos praktinės problemos specifiką.
Kadangi iš dalykinės problemos formuluotės aiškiai išplaukia, kad mes susiduriame su aibėmis, tokią problemą suformuluosime aibių teorijos požiūriu.
Leisti  – visų sandėlyje esančių tam tikros prekės likučių partijų rinkinys. Leisti
– visų sandėlyje esančių tam tikros prekės likučių partijų rinkinys. Leisti  – pateikta dienų konstanta. Leisti
– pateikta dienų konstanta. Leisti  – partijų poaibis, kai visų poaibyje esančių partijų porų datų skirtumas neviršija konstantos
– partijų poaibis, kai visų poaibyje esančių partijų porų datų skirtumas neviršija konstantos  . Turime rasti mažiausią nevienodų poaibių skaičių
. Turime rasti mažiausią nevienodų poaibių skaičių  , kad visi poaibiai
, kad visi poaibiai  kartu duotų daug
kartu duotų daug  .
.
Kitaip tariant, reikia rasti panašių partijų grupes ar grupes, kuriose panašumo kriterijų lemia konstanta  . Ši užduotis primena mums gerai žinomą klasterizacijos problemą. Svarbu pasakyti, kad nagrinėjama problema skiriasi nuo klasterizacijos problemos tuo, kad mūsų problema turi griežtai apibrėžtą klasterio elementų panašumo kriterijaus sąlygą, kurią lemia konstanta.
. Ši užduotis primena mums gerai žinomą klasterizacijos problemą. Svarbu pasakyti, kad nagrinėjama problema skiriasi nuo klasterizacijos problemos tuo, kad mūsų problema turi griežtai apibrėžtą klasterio elementų panašumo kriterijaus sąlygą, kurią lemia konstanta.  , bet klasterizacijos uždavinyje tokios sąlygos nėra. Galima rasti klasterizacijos problemos teiginį ir informaciją apie šią problemą
, bet klasterizacijos uždavinyje tokios sąlygos nėra. Galima rasti klasterizacijos problemos teiginį ir informaciją apie šią problemą
Taigi, mums pavyko suformuluoti problemą ir rasti klasikinę problemą su panašia formuluote. Dabar reikia apsvarstyti gerai žinomus algoritmus, kaip jį išspręsti, kad neišradinėtumėte dviračio iš naujo, o perimtumėte geriausią praktiką ir jas pritaikytumėte. Norėdami išspręsti klasterizacijos problemą, mes apsvarstėme populiariausius algoritmus, būtent:  - reiškia
- reiškia  -priemonės, sujungtų komponentų identifikavimo algoritmas, minimalaus apimančio medžio algoritmas. Galima rasti tokių algoritmų aprašymą ir analizę
-priemonės, sujungtų komponentų identifikavimo algoritmas, minimalaus apimančio medžio algoritmas. Galima rasti tokių algoritmų aprašymą ir analizę
Norėdami išspręsti mūsų problemą, grupavimo algoritmai  – reiškia ir
– reiškia ir  -priemonės iš viso netaikomos, nes klasterių skaičius niekada nėra žinomas iš anksto
-priemonės iš viso netaikomos, nes klasterių skaičius niekada nėra žinomas iš anksto  ir tokie algoritmai neatsižvelgia į pastovų dienų apribojimą. Tokie algoritmai iš pradžių buvo atmesti.
ir tokie algoritmai neatsižvelgia į pastovų dienų apribojimą. Tokie algoritmai iš pradžių buvo atmesti.
Mūsų problemai išspręsti labiau tinka sujungtų komponentų identifikavimo algoritmas ir minimalaus apimančio medžio algoritmas, tačiau, kaip paaiškėjo, jų negalima pritaikyti „priešais“ sprendžiamai problemai ir gauti gerą sprendimą. Norėdami tai paaiškinti, panagrinėkime tokių algoritmų veikimo logiką mūsų problemos atžvilgiu.
Apsvarstykite grafiką  , kurio viršūnės yra šalių rinkinys
, kurio viršūnės yra šalių rinkinys  , ir briauna tarp viršūnių
, ir briauna tarp viršūnių  и
и  turi svorį, lygų dienų skirtumui tarp partijų
turi svorį, lygų dienų skirtumui tarp partijų  и
и  . Prijungtų komponentų identifikavimo algoritme nurodomas įvesties parametras
. Prijungtų komponentų identifikavimo algoritme nurodomas įvesties parametras  Kur
Kur  , ir grafike
, ir grafike  pašalinami visi kraštai, kurių svoris didesnis
pašalinami visi kraštai, kurių svoris didesnis  . Tik artimiausios objektų poros lieka sujungtos. Algoritmo esmė yra pasirinkti tokią reikšmę
. Tik artimiausios objektų poros lieka sujungtos. Algoritmo esmė yra pasirinkti tokią reikšmę  , kuriame grafikas „suyra“ į kelis sujungtus komponentus, kur šiems komponentams priklausančios šalys tenkins mūsų panašumo kriterijų, nulemtą konstantos
, kuriame grafikas „suyra“ į kelis sujungtus komponentus, kur šiems komponentams priklausančios šalys tenkins mūsų panašumo kriterijų, nulemtą konstantos  . Gauti komponentai yra klasteriai.
. Gauti komponentai yra klasteriai.
Mažiausias apimantis medžio algoritmas pirmiausia sukuriamas grafike  minimalų apimantį medį, o po to nuosekliai pašalina didžiausio svorio briaunas, kol grafikas „suirsta“ į kelis sujungtus komponentus, kur šiems komponentams priklausančios šalys taip pat atitiks mūsų panašumo kriterijų. Gauti komponentai bus klasteriai.
minimalų apimantį medį, o po to nuosekliai pašalina didžiausio svorio briaunas, kol grafikas „suirsta“ į kelis sujungtus komponentus, kur šiems komponentams priklausančios šalys taip pat atitiks mūsų panašumo kriterijų. Gauti komponentai bus klasteriai.
Naudojant tokius algoritmus nagrinėjamai problemai išspręsti, gali susidaryti tokia situacija kaip 3 pav.
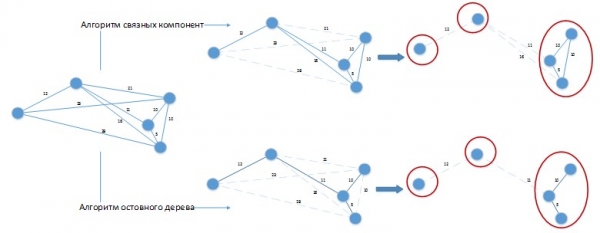
3 pav. Klasterizacijos algoritmų taikymas sprendžiamai problemai
Tarkime, mūsų partijos dienų skirtumo konstanta yra 20 dienų. Grafikas  buvo pavaizduotas erdvine forma, kad būtų lengviau vizualiai suvokti. Abu algoritmai sukūrė 3 klasterių sprendimą, kurį galima nesunkiai patobulinti sujungiant į atskiras grupes sudėtas partijas! Akivaizdu, kad tokius algoritmus reikia modifikuoti, kad jie atitiktų sprendžiamos problemos specifiką, o jų taikymas gryna forma mūsų problemos sprendimui duos prastus rezultatus.
buvo pavaizduotas erdvine forma, kad būtų lengviau vizualiai suvokti. Abu algoritmai sukūrė 3 klasterių sprendimą, kurį galima nesunkiai patobulinti sujungiant į atskiras grupes sudėtas partijas! Akivaizdu, kad tokius algoritmus reikia modifikuoti, kad jie atitiktų sprendžiamos problemos specifiką, o jų taikymas gryna forma mūsų problemos sprendimui duos prastus rezultatus.

Taigi, prieš pradėdami rašyti kodą mūsų užduočiai modifikuotiems grafų algoritmams ir iš naujo išradę savo dviratį (kurio siluetuose jau galėjome įžvelgti kvadratinių ratų kontūrus), mes vėl nusprendėme tokią problemą pažvelgti moksliškai, būtent: pabandykite jį sumažinti iki kitos atskiros problemos optimizavimo, tikėdamiesi, kad esami algoritmai jai išspręsti gali būti pritaikyti be pakeitimų.
Dar viena panašios klasikinės problemos paieška buvo sėkminga! Mums pavyko rasti diskrečią optimizavimo problemą, kurios formuluotė 1 iš 1 sutampa su mūsų problemos formuluote. Ši užduotis pasirodė tokia nustatyti uždengimo problemą. Pateiksime problemos formuluotę, susietą su mūsų specifika.
Yra baigtinis rinkinys  ir šeima
ir šeima  visų nesusijusių šalių poaibių, kad datos skirtumai visoms kiekvieno poaibio šalių poroms
visų nesusijusių šalių poaibių, kad datos skirtumai visoms kiekvieno poaibio šalių poroms  iš šeimos
iš šeimos  neviršija konstantų
neviršija konstantų  . Apdangalas vadinamas šeima
. Apdangalas vadinamas šeima  mažiausios galios, kurios elementai priklauso
mažiausios galios, kurios elementai priklauso  , kad aibių sąjunga
, kad aibių sąjunga  iš šeimos
iš šeimos  turėtų pateikti visų šalių rinkinį
turėtų pateikti visų šalių rinkinį  .
.
Galima rasti išsamią šios problemos analizę и Galima rasti kitų uždengimo problemos ir jos modifikacijų praktinio taikymo variantų
Problemos sprendimo algoritmas
Nusprendėme dėl sprendžiamo uždavinio matematinį modelį. Dabar pažvelkime į jo sprendimo algoritmą. Poaibiai  iš šeimos
iš šeimos  galima lengvai rasti taikant šią procedūrą.
galima lengvai rasti taikant šią procedūrą.
- Išdėstykite partijas iš rinkinio
 mažėjančia tvarka pagal jų datas.
mažėjančia tvarka pagal jų datas. - Raskite mažiausią ir didžiausią partijos datas.
- Kiekvienai dienai nuo minimalios iki maksimalios datos raskite visas partijas, kurių datos skiriasi ne daugiau nei (taigi vertė Geriau imti lyginį skaičių).
 mažėjančia tvarka pagal jų datas.
mažėjančia tvarka pagal jų datas. nuo minimalios iki maksimalios datos raskite visas partijas, kurių datos skiriasi
nuo minimalios iki maksimalios datos raskite visas partijas, kurių datos skiriasi  ne daugiau nei
ne daugiau nei  (taigi vertė
(taigi vertė  Geriau imti lyginį skaičių).
Geriau imti lyginį skaičių). Aibių šeimos formavimo procedūros logika  prie
prie  dienos parodytos 4 paveiksle.
dienos parodytos 4 paveiksle.

4 pav. Partijų pogrupių formavimas
Ši procedūra reikalinga ne visiems  peržiūrėkite visas kitas partijas ir patikrinkite jų datų skirtumą arba nuo esamos vertės
peržiūrėkite visas kitas partijas ir patikrinkite jų datų skirtumą arba nuo esamos vertės  judėkite kairėn arba dešinėn, kol rasite partiją, kurios data skiriasi nuo
judėkite kairėn arba dešinėn, kol rasite partiją, kurios data skiriasi nuo  daugiau nei puse konstantos vertės. Visi vėlesni elementai, judant tiek į dešinę, tiek į kairę, mums nebus įdomūs, nes jiems dienų skirtumas tik padidės, nes masyvo elementai iš pradžių buvo užsakyti. Toks požiūris žymiai sutaupys laiko, kai vakarėlių skaičius ir jų pasimatymų sklaida yra ženkliai didelė.
daugiau nei puse konstantos vertės. Visi vėlesni elementai, judant tiek į dešinę, tiek į kairę, mums nebus įdomūs, nes jiems dienų skirtumas tik padidės, nes masyvo elementai iš pradžių buvo užsakyti. Toks požiūris žymiai sutaupys laiko, kai vakarėlių skaičius ir jų pasimatymų sklaida yra ženkliai didelė.
Rinkinio uždengimo problema yra  -sunku, o tai reiškia, kad nėra greito (kurio veikimo laikas lygus įvesties duomenų polinomui) ir tikslaus algoritmo, kaip jį išspręsti. Todėl aibės aprėpties problemai išspręsti buvo pasirinktas greitas godus algoritmas, kuris, žinoma, nėra tikslus, tačiau turi šiuos privalumus:
-sunku, o tai reiškia, kad nėra greito (kurio veikimo laikas lygus įvesties duomenų polinomui) ir tikslaus algoritmo, kaip jį išspręsti. Todėl aibės aprėpties problemai išspręsti buvo pasirinktas greitas godus algoritmas, kuris, žinoma, nėra tikslus, tačiau turi šiuos privalumus:
- Esant mažoms problemoms (o būtent taip yra mūsų atveju), jis apskaičiuoja sprendimus, kurie yra gana artimi optimaliems. Didėjant problemos dydžiui, prastėja sprendimo kokybė, bet vis tiek gana lėtai;
- Labai lengva įgyvendinti;
- Greitas, nes jo veikimo laikas yra apskaičiuotas .
 .
.Godus algoritmas parenka rinkinius pagal šią taisyklę: kiekviename etape parenkama aibė, apimanti maksimalų dar neapimtų elementų skaičių. Galima rasti išsamų algoritmo aprašymą ir jo pseudokodą
Tokio godaus algoritmo tikslumo sprendžiamos problemos bandymo duomenimis palyginimas su kitais žinomais algoritmais, tokiais kaip tikimybinis gobšumo algoritmas, skruzdžių kolonijų algoritmas ir kt., nebuvo atliktas. Galima rasti tokių algoritmų palyginimo su generuotais atsitiktiniais duomenimis rezultatus
Algoritmo įgyvendinimas ir įgyvendinimas
Šis algoritmas buvo įdiegtas kalba 1S ir buvo įtrauktas į išorinį apdorojimą, vadinamą „Likučių suspaudimu“, kuris buvo prijungtas prie WMS-sistema. Kalboje algoritmo neįdiegėme C ++ ir naudoti jį iš išorinio Native komponento, kuris būtų teisingesnis, nes kodo greitis yra mažesnis C + + kartų, o kai kuriais pavyzdžiais net dešimtis kartų greičiau nei panašaus kodo greitis 1S. Ant liežuvio 1S Algoritmas buvo įdiegtas siekiant sutaupyti kūrimo laiką ir palengvinti derinimą kliento gamybos bazėje. Algoritmo rezultatas pateiktas 5 pav.
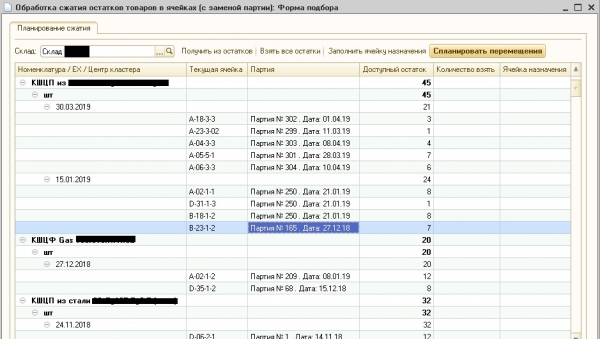
5 pav. Perdirbimas, siekiant „suspausti“ likučius
5 paveiksle matyti, kad nurodytame sandėlyje einamieji prekių likučiai sandėliavimo langeliuose yra suskirstyti į grupes, kuriose prekių partijų datos viena nuo kitos skiriasi ne daugiau kaip 30 dienų. Kadangi klientas gamina ir sandėliuoja metalinius rutulinius vožtuvus, kurių tinkamumo laikas skaičiuojamas metais, tokio datų skirtumo galima nepaisyti. Atkreipkite dėmesį, kad toks apdorojimas šiuo metu sistemingai naudojamas gamyboje ir operatoriuose WMS patvirtinti gerą partijų grupavimo kokybę.
Išvados ir tęsinys
Pagrindinė patirtis, kurią įgijome sprendžiant tokią praktinę problemą, yra paradigmos: matematikos naudojimo efektyvumo patvirtinimas. problemos pareiškimas  garsus mat. modelis
garsus mat. modelis  garsus algoritmas
garsus algoritmas  algoritmas, atsižvelgiant į problemos specifiką. Diskretus optimizavimas gyvuoja jau daugiau nei 300 metų ir per šį laiką žmonės spėjo apgalvoti daugybę problemų ir sukaupti daug patirties jas sprendžiant. Visų pirma, labiau patartina atsigręžti į šią patirtį ir tik tada pradėti išradinėti savo dviratį.
algoritmas, atsižvelgiant į problemos specifiką. Diskretus optimizavimas gyvuoja jau daugiau nei 300 metų ir per šį laiką žmonės spėjo apgalvoti daugybę problemų ir sukaupti daug patirties jas sprendžiant. Visų pirma, labiau patartina atsigręžti į šią patirtį ir tik tada pradėti išradinėti savo dviratį.
Kitame straipsnyje mes tęsime pasakojimą apie optimizavimo algoritmus ir pažvelgsime į įdomiausią ir daug sudėtingesnį: optimalaus ląstelių likučių „suspaudimo“ algoritmą, kuris kaip įvestį naudoja duomenis, gautus iš paketinio klasterizavimo algoritmo.
Parengė straipsnį
Romanas Shanginas, projektų skyriaus programuotojas,
Pirmoji BIT įmonė, Čeliabinskas
Šaltinis: www.habr.com
