

NeuroIPS () yra didžiausia pasaulyje mašininio mokymosi ir dirbtinio intelekto konferencija ir pagrindinis renginys gilaus mokymosi pasaulyje.
Ar mes, DS inžinieriai, naujajame dešimtmetyje taip pat įvaldysime biologiją, kalbotyrą ir psichologiją? Mes jums pasakysime savo apžvalgoje.

Šiais metais Vankuveryje, Kanadoje, konferencija subūrė daugiau nei 13500 80 žmonių iš 2019 šalių. Jau ne pirmus metus konferencijoje „Sberbank“ atstovauja Rusijai – DS komanda kalbėjo apie ML diegimą bankiniuose procesuose, apie ML konkurenciją ir apie „Sberbank DS“ platformos galimybes. Kokios buvo pagrindinės XNUMX metų tendencijos ML bendruomenėje? Konferencijos dalyviai sako: и .
Šiais metais NeurIPS priėmė daugiau nei 1400 dokumentų – algoritmų, naujų modelių ir naujų duomenų pritaikymo.
Turinys:
- Tendencijos
- Modelio aiškinamumas
- Daugiadiscipliniškumas
- Priežastys
- RL
- GAN
- Pagrindiniai pakviesti pokalbiai
- „Socialinis intelektas“, Blaise'as Aguera ir Arcas („Google“)
- „Veridical Data Science“, Bin Yu (Berklis)
- „Žmogaus elgesio modeliavimas naudojant mašininį mokymąsi: galimybės ir iššūkiai“, Nuria M Oliver, Albert Ali Salah
- „Nuo 1 sistemos iki 2 sistemos giluminio mokymosi“, Yoshua Bengio
Metų tendencijos 2019
1. Modelio aiškinamumas ir nauja ML metodika
Pagrindinė konferencijos tema – interpretacija ir įrodymai, kodėl gauname tam tikrus rezultatus. Galima ilgai kalbėti apie filosofinę „juodosios dėžės“ interpretacijos svarbą, tačiau šioje srityje būta ir daugiau realių metodų ir techninių pažangų.
Modelių atkartojimo ir žinių iš jų gavimo metodika yra naujas mokslo priemonių rinkinys. Modeliai gali pasitarnauti kaip įrankis naujoms žinioms įgyti ir jas išbandyti, o kiekvienas modelio išankstinio apdorojimo, mokymo ir taikymo etapas turi būti atkuriamas.
Nemaža dalis publikacijų yra skirta ne modelių ir įrankių konstravimui, o saugumo, skaidrumo ir rezultatų patikrinamumo užtikrinimo problemoms. Visų pirma, atsirado atskiras srautas apie atakas prieš modelį (priešingas atakas), ir svarstomos galimybės tiek atakoms prieš mokymą, tiek atakoms prieš taikymą.
Straipsniai:
- — programinis straipsnis apie modelių patikros metodiką. Apima šiuolaikinių modelių interpretavimo įrankių apžvalgą, ypač dėmesio panaudojimą ir savybių svarbą „distiliuojant“ neuroninį tinklą tiesiniais modeliais.
- Chaofanas Chenas, Oskaras Li, Danielis Tao, Alina Barnett, Cynthia Rudin, Jonathanas K. Su
- Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Alexanderis Mottas, Danielis Zoranas, Mike'as Chrzanowskis, Daanas Wierstra, Danilo Jimenezas Rezende
- Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Edvardas Rafas
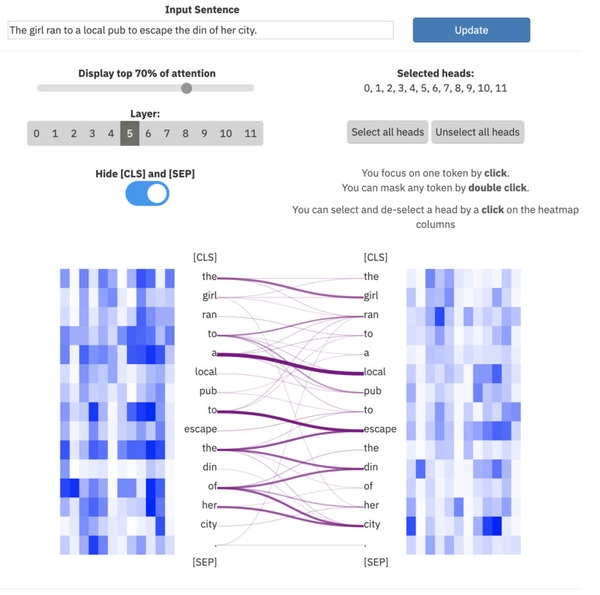
ExBert.net rodo modelio interpretaciją teksto apdorojimo užduotims
2. Daugiadiscipliniškumas
Norint užtikrinti patikimą verifikaciją ir sukurti žinių patikrinimo ir plėsimo mechanizmus, mums reikalingi gretutinių sričių specialistai, kurie vienu metu turėtų kompetencijų ML ir dalykinėje srityje (medicina, lingvistika, neurobiologija, švietimas ir kt.). Ypač verta atkreipti dėmesį į reikšmingesnį kūrinių ir kalbų buvimą neuromoksluose ir kognityviniuose moksluose - vyksta specialistų suartėjimas, idėjų skolinimasis.
Be šio suartėjimo, atsiranda daugiadiscipliniškumas bendrai apdorojant informaciją iš įvairių šaltinių: teksto ir nuotraukų, teksto ir žaidimų, grafinių duomenų bazių + tekstas ir nuotraukos.
Straipsniai:
- Neurologija + ML –
- VisualQA –
- RL + NLP -
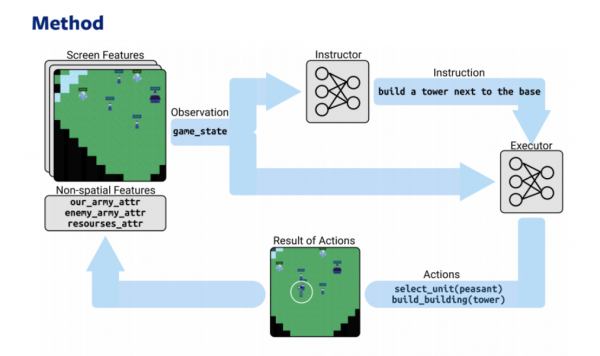
Du modeliai – strategas ir vykdomasis – pagrįsti RL ir NLP žaidimo internetine strategija
3. Protavimas
Dirbtinio intelekto stiprinimas – tai judėjimas link savarankiško mokymosi sistemų, „sąmoningo“, samprotavimo ir samprotavimo. Visų pirma vystosi priežastinės išvados ir sveiko proto samprotavimai. Kai kurie pranešimai yra skirti meta-mokymuisi (apie kaip išmokti mokytis) ir DL technologijų derinimui su 1-os ir 2-osios eilės logika – terminas Dirbtinis bendras intelektas (AGI) tampa įprastu terminu kalbėtojų kalbose.
Straipsniai:
- Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Vaishak Belle, Brendanas Juba
- Antonas Bachtinas, Laurensas van der Maatenas, Justinas Johnsonas, Laura Gustafson, Rossas Girshickas
- Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4. Pastiprinimo mokymasis
Didžioji dalis darbų tęsiasi kuriant tradicines RL sritis – DOTA2, Starcraft, derinant architektūras su kompiuterine vizija, NLP, grafų duomenų bazėmis.
Atskira konferencijos diena buvo skirta RL seminarui, kuriame buvo pristatyta Optimistinio aktoriaus kritiko modelio architektūra, pranašesnė už visas ankstesnes, ypač Soft Actor Critic.
Straipsniai:
- ; Kamilas Ciosekas, Quanas Vuongas, Robertas Loftinas, Katja Hofmann
- ; Yasuhiro Fujita (Preferred Networks, Inc.)*; Toshiki Kataoka (Preferred Networks, Inc.); Prabhat Nagarajan (pageidautini tinklai); Takahiro Ishikawa (Tokijo universitetas) [išorinė pdf nuoroda].
- ; Danijaras Hafneris („Google“)*; Timothy Lilicrapas („DeepMind“); Jimmy Ba (Toronto universitetas); Mohammad Norouzi („Google Brain“)

„StarCraft“ žaidėjai kovoja su „Alphastar“ modeliu („DeepMind“)
5.GAN
Generatyvieji tinklai vis dar yra dėmesio centre: daugelyje darbų naudojami vaniliniai GAN matematiniams įrodymams, taip pat jie pritaikomi naujais, neįprastais būdais (grafikų generavimo modeliai, darbas su serijomis, taikymas duomenų priežasties-pasekmės ryšiams ir kt.).
Straipsniai:
- Sangwoo Mo, Chiheon Kim, Sungwoong Kim, Minsu Cho, Jinwoo Shin
- Danas Zhangas, Anna Khoreva
- Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni
Kadangi buvo priimta daugiau darbų Žemiau pakalbėsime apie svarbiausias kalbas.
Kviestiniai pokalbiai
„Socialinis intelektas“, Blaise'as Aguera ir Arcas („Google“)
Pokalbyje pagrindinis dėmesys skiriamas bendrajai mašininio mokymosi metodikai ir perspektyvoms, keičiančioms pramonę šiuo metu – su kokiomis kryžkelėmis mes susiduriame? Kaip veikia smegenys ir evoliucija ir kodėl mes taip mažai naudojame tai, ką jau žinome apie natūralių sistemų vystymąsi?
Pramoninė ML plėtra iš esmės sutampa su Google plėtros etapais, kurie metai iš metų skelbia savo NeurIPS tyrimus:
- 1997 – paleidžiamos paieškos priemonės, pirmieji serveriai, maža skaičiavimo galia
- 2010 m. – Jeffas Deanas pradeda „Google Brain“ projektą – neuroninių tinklų bumą pačioje pradžioje
- 2015 – pramoninis neuroninių tinklų diegimas, greitas veidų atpažinimas tiesiai vietiniame įrenginyje, žemo lygio procesoriai pritaikyti tenzoriniam skaičiavimui – TPU. „Google“ pristato „Coral ai“ – „raspberry pi“ analogą, mini kompiuterį, skirtą neuroniniams tinklams įdiegti į eksperimentinius įrenginius.
- 2017 m. „Google“ pradeda kurti decentralizuotą mokymą ir sujungti neuroninių tinklų mokymo iš skirtingų įrenginių rezultatus į vieną modelį – „Android“
Šiandien visa pramonė skirta duomenų saugai, kaupimui ir mokymosi rezultatų replikavimui vietiniuose įrenginiuose.
– mašininio mokymosi kryptis, kai individualūs modeliai yra apmokomi nepriklausomai vienas nuo kito, o vėliau sujungiami į vieną modelį (necentralizuojant šaltinio duomenų), atliekant korekcijas atsižvelgiant į retus įvykius, anomalijas, suasmeninimą ir pan. Visi įrenginiai su Android iš esmės vienas „Google“ skaičiavimo superkompiuteris.
„Google“ teigimu, generatyvūs modeliai, pagrįsti jungtiniu mokymusi, yra daug žadanti ateities kryptis, kuri yra „ankstyvosiose eksponentinio augimo stadijose“. GAN, lektoriaus teigimu, geba išmokti atkurti masinę gyvų organizmų populiacijų elgseną ir mąstymo algoritmus.
Naudojant dviejų paprastų GAN architektūrų pavyzdį, parodyta, kad jose optimizavimo kelio paieška klaidžioja ratu, o tai reiškia, kad optimizavimas kaip toks nevyksta. Tuo pačiu metu šie modeliai labai sėkmingai imituoja eksperimentus, kuriuos biologai atlieka su bakterijų populiacijomis, verčia juos mokytis naujų elgesio strategijų ieškant maisto. Galime daryti išvadą, kad gyvenimas veikia kitaip nei optimizavimo funkcija.
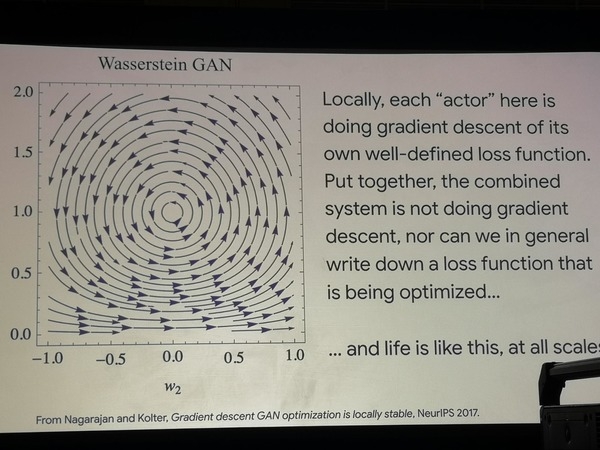
Vaikščiojimo GAN optimizavimas
Viskas, ką dabar atliekame mašininio mokymosi sistemoje, yra siauros ir labai formalizuotos užduotys, o šie formalizmai nėra gerai apibendrinami ir neatitinka mūsų dalykinių žinių tokiose srityse kaip neurofiziologija ir biologija.
Artimiausiu metu tikrai verta pasiskolinti iš neurofiziologijos srities, tai naujos neuronų architektūros ir nežymus klaidų dauginimosi atgal mechanizmų peržiūrėjimas.
Pačios žmogaus smegenys nesimoko kaip neuroninis tinklas:
- Jis neturi atsitiktinių pirminių įėjimų, įskaitant tuos, kurie buvo nustatyti per pojūčius ir vaikystėje
- Jam būdingos instinktyvaus vystymosi kryptys (noras mokytis kalbos nuo kūdikio, vaikščiojant vertikaliai)
Individualių smegenų lavinimas yra žemo lygio užduotis; galbūt turėtume apsvarstyti greitai besikeičiančių individų „kolonijas“, perduodančias žinias vieni kitiems, kad atkartotų grupės evoliucijos mechanizmus.
Ką dabar galime pritaikyti ML algoritmams:
- Taikykite ląstelių linijos modelius, kurie užtikrina gyventojų mokymąsi, bet trumpą individo gyvenimą („individualios smegenys“).
- Keletas žingsnių mokymasis naudojant nedidelį skaičių pavyzdžių
- Sudėtingesnės neuronų struktūros, šiek tiek kitokios aktyvinimo funkcijos
- „Genomo“ perkėlimas į kitas kartas - atgalinio dauginimo algoritmas
- Kai sujungsime neurofiziologiją ir neuroninius tinklus, išmoksime sukurti daugiafunkcines smegenis iš daugelio komponentų.
Šiuo požiūriu SOTA sprendimų praktika yra žalinga ir turėtų būti peržiūrėta siekiant sukurti bendras užduotis (benchmarkus).
„Veridical Data Science“, Bin Yu (Berklis)
Pranešimas skirtas mašininio mokymosi modelių interpretavimo problemai ir jų tiesioginio testavimo ir tikrinimo metodikai. Bet koks treniruotas ML modelis gali būti suvokiamas kaip žinių šaltinis, kurį reikia iš jo išgauti.
Daugelyje sričių, ypač medicinoje, modelio naudojimas yra neįmanomas neišgavus šių paslėptų žinių ir neinterpretuojant modelio rezultatų – kitaip nebūsime tikri, kad rezultatai bus stabilūs, neatsitiktiniai, patikimi ir neužmuš kantrus. Ištisa darbo metodologijos kryptis vystosi giluminio mokymosi paradigmoje ir peržengia jos ribas – patikimų duomenų mokslas. Kas tai yra?
Norime pasiekti tokią mokslinių publikacijų kokybę ir modelių atkuriamumą, kad jie būtų:
- nuspėjamas
- apskaičiuojamas
- stabilus
Šie trys principai sudaro naujosios metodikos pagrindą. Kaip galima patikrinti ML modelius pagal šiuos kriterijus? Lengviausias būdas yra sukurti iš karto interpretuojamus modelius (regresijas, sprendimų medžius). Tačiau taip pat norime gauti tiesioginės gilaus mokymosi naudos.
Keli esami problemos sprendimo būdai:
- interpretuoti modelį;
- naudoti metodus, pagrįstus dėmesiu;
- treniruodamiesi naudoti algoritmų ansamblius ir užtikrinti, kad tiesiniai interpretuojami modeliai išmoktų numatyti tuos pačius atsakymus kaip ir neuroninis tinklas, interpretuojant ypatybes iš tiesinio modelio;
- keisti ir papildyti treniruočių duomenis. Tai apima triukšmo, trukdžių ir duomenų papildymą;
- bet kokie metodai, padedantys užtikrinti, kad modelio rezultatai nebūtų atsitiktiniai ir nepriklausytų nuo nedidelių nepageidaujamų trukdžių (priešinių atakų);
- interpretuoti modelį po fakto, po treniruotės;
- įvairiais būdais tirti savybių svorius;
- tirti visų hipotezių tikimybes, klasių pasiskirstymą.

Priešiškas puolimas
Modeliavimo klaidos brangiai kainuoja visiems: puikus pavyzdys yra Reinharto ir Rogovo darbas.“ paveikė daugelio Europos šalių ekonominę politiką ir privertė jas vykdyti taupymo politiką, tačiau kruopštus pakartotinis duomenų patikrinimas ir jų apdorojimas po metų parodė priešingą rezultatą!
Bet kuri ML technologija turi savo gyvavimo ciklą nuo diegimo iki įgyvendinimo. Naujosios metodikos tikslas – patikrinti tris pagrindinius principus kiekviename modelio gyvavimo etape.
Rezultatai:
- Kuriami keli projektai, kurie padės ML modeliui būti patikimesniam. Tai, pavyzdžiui, „deeptune“ (nuoroda į: );
- Tolimesniam metodologijos tobulinimui būtina ženkliai gerinti publikacijų ML srityje kokybę;
- Mašininiam mokymuisi reikia lyderių, turinčių daugiadisciplininį mokymą ir patirties tiek techninėje, tiek humanitarinėje srityje.
„Žmogaus elgesio modeliavimas naudojant mašininį mokymąsi: galimybės ir iššūkiai“ Nuria M Oliver, Albert Ali Salah
Paskaita skirta modeliuoti žmogaus elgesį, jo technologinius pagrindus ir pritaikymo perspektyvas.
Žmogaus elgesio modeliavimą galima suskirstyti į:
- individualus elgesys
- mažos žmonių grupės elgesys
- masinis elgesys
Kiekvienas iš šių tipų gali būti modeliuojamas naudojant ML, tačiau naudojant visiškai skirtingą įvesties informaciją ir funkcijas. Kiekvienas tipas taip pat turi savo etinių problemų, su kuriomis susiduria kiekvienas projektas:
- individualus elgesys – tapatybės vagystė, deepfake;
- žmonių grupių elgesys – anonimiškumas, informacijos apie judėjimą gavimas, skambučiai ir kt.;
individualus elgesys
Dažniausiai tai susiję su Kompiuterinės vizijos tema – žmogaus emocijų ir reakcijų atpažinimas. Galbūt tik kontekste, laike arba su santykiniu jo paties emocijų kintamumo mastu. Skaidrėje parodytas Monos Lizos emocijų atpažinimas naudojant Viduržemio jūros regiono moterų emocinio spektro kontekstą. Rezultatas: džiaugsmo šypsena, bet su panieka ir pasibjaurėjimu. Labiausiai tikėtina, kad priežastis yra techninis „neutralios“ emocijos apibrėžimo būdas.
Mažos žmonių grupės elgesys
Kol kas blogiausias modelis yra dėl nepakankamos informacijos. Kaip pavyzdys buvo parodyti 2018 – 2019 metų darbai. dešimčiai žmonių X dešimtys vaizdo įrašų (plg. 100 XNUMX++ vaizdo duomenų rinkinius). Norint geriausiai modeliuoti šią užduotį, reikalinga multimodalinė informacija, geriausia iš kūno aukščiamačio jutiklių, termometro, mikrofono įrašymo ir kt.
Masinis elgesys
Labiausiai išsivysčiusi sritis, nes klientas yra JT ir daugelis valstybių. Lauko stebėjimo kameros, telefonų bokštų duomenys – atsiskaitymas, SMS, skambučiai, judėjimo tarp valstybės sienų duomenys – visa tai labai patikimą vaizdą apie žmonių judėjimą ir socialinį nestabilumą. Galimi technologijos pritaikymai: gelbėjimo operacijų optimizavimas, pagalba ir savalaikė gyventojų evakuacija ekstremalių situacijų metu. Naudojami modeliai dažniausiai vis dar prastai interpretuojami – tai įvairūs LSTM ir konvoliuciniai tinklai. Buvo trumpai pastebėta, kad JT lobsta dėl naujo įstatymo, kuris įpareigotų Europos įmones dalytis anoniminiais duomenimis, reikalingais bet kokiam tyrimui atlikti.
„Nuo 1 sistemos iki 2 sistemos giluminio mokymosi“, Yoshua Bengio
Joshua Bengio paskaitoje gilus mokymasis susitinka su neuromokslu tikslų nustatymo lygmenyje.
Bengio nustato du pagrindinius problemų tipus pagal Nobelio premijos laureato Danielio Kahnemano metodiką (knyga ““)
1 tipas - 1 sistema, nesąmoningi veiksmai, kuriuos atliekame „automatiškai“ (senovinės smegenys): vairavimas automobiliu pažįstamose vietose, ėjimas, veidų atpažinimas.
2 tipas – 2 sistema, sąmoningi veiksmai (smegenų žievė), tikslų nustatymas, analizė, mąstymas, sudėtinės užduotys.
DI kol kas pakankamai aukštumų pasiekė tik pirmojo tipo užduotyse, o mūsų užduotis yra perkelti ją į antrąjį, mokant atlikti daugiadalykes operacijas ir operuoti su logika bei aukšto lygio pažinimo įgūdžiais.
Šiam tikslui pasiekti siūloma:
- NLP užduotyse naudoti dėmesį kaip pagrindinį mąstymo modeliavimo mechanizmą
- naudokite meta-mokymąsi ir reprezentacinį mokymąsi, kad geriau modeliuotumėte sąmonę ir jų lokalizaciją įtakojančias ypatybes – ir jų pagrindu pereikite prie darbo su aukštesnio lygio koncepcijomis.
Vietoj išvados, čia yra pakviestas pokalbis: Bengio yra vienas iš daugelio mokslininkų, kurie bando išplėsti ML sritį ne tik optimizavimo problemas, SOTA ir naujas architektūras.
Klausimas lieka atviras, kiek sąmonės problemų derinys, kalbos įtaka mąstymui, neurobiologija ir algoritmai yra tai, kas mūsų laukia ateityje ir leis pereiti prie mašinų, kurios „mąsto“ kaip žmonės.
Dėkojame!

Šaltinis: www.habr.com
