


Uzgāju interesantu materiālu par mākslīgo intelektu spēlēs. Ar vienkāršu piemēru skaidrojumu par AI pamata lietām, un iekšpusē ir daudz noderīgu rīku un metožu tā ērtai izstrādei un projektēšanai. Tur ir arī norādīts, kā, kur un kad tās lietot.
Lielākā daļa piemēru ir rakstīti pseidokodā, tāpēc nav nepieciešamas progresīvas programmēšanas zināšanas. Zem griezuma ir 35 teksta lapas ar attēliem un gifiem, tāpēc gatavojieties.
UPD. Es atvainojos, bet es jau esmu tulkojis šo rakstu par Habrē . Jūs varat izlasīt viņa versiju , bet raksts nez kāpēc pagāja garām (izmantoju meklēšanu, bet kaut kas nogāja greizi). Un tā kā es rakstu emuārā, kas veltīts spēļu izstrādei, es nolēmu atstāt savu tulkojuma versiju abonentiem (daži punkti ir formatēti atšķirīgi, daži tika apzināti izlaisti pēc izstrādātāju ieteikuma).
Kas ir AI?
Spēles AI koncentrējas uz to, kādas darbības objektam jāveic, pamatojoties uz apstākļiem, kādos tas atrodas. To parasti sauc par "inteliģentā aģenta" vadību, kur aģents ir spēlētāja varonis, transportlīdzeklis, robots vai dažreiz kaut kas abstraktāks: vesela vienību grupa vai pat civilizācija. Katrā gadījumā tā ir lieta, kurai jāredz sava vide, jāpieņem lēmumi, pamatojoties uz to, un jārīkojas saskaņā ar tiem. To sauc par sajūtu/domāt/rīkoties ciklu:
- Sajūta: aģents atrod vai saņem informāciju par lietām savā vidē, kas var ietekmēt viņa uzvedību (draudi tuvumā, priekšmeti, ko savākt, interesantas vietas, ko izpētīt).
- Padomājiet: aģents izlemj, kā reaģēt (apsver, vai ir pietiekami droši savākt priekšmetus, vai viņam vispirms ir jācīnās/slēpjas).
- Rīkojieties: aģents veic darbības, lai īstenotu iepriekšējo lēmumu (sāk virzīties uz ienaidnieku vai objektu).
- ...tagad situācija ir mainījusies varoņu darbības dēļ, tāpēc cikls atkārtojas ar jauniem datiem.
AI mēdz koncentrēties uz cilpas Sense daļu. Piemēram, autonomās automašīnas fotografē ceļu, apvieno tos ar radara un lidara datiem un interpretē tos. To parasti veic mašīnmācīšanās, kas apstrādā ienākošos datus un piešķir tiem nozīmi, iegūstot semantisko informāciju, piemēram, "20 jardus priekšā jums ir cita automašīna". Tās ir tā sauktās klasifikācijas problēmas.
Spēlēm nav nepieciešama sarežģīta sistēma, lai iegūtu informāciju, jo lielākā daļa datu jau ir tās neatņemama sastāvdaļa. Nav nepieciešams palaist attēlu atpazīšanas algoritmus, lai noteiktu, vai priekšā ir ienaidnieks — spēle jau zina un ievada informāciju tieši lēmumu pieņemšanas procesā. Tāpēc cikla Sajūtu daļa bieži vien ir daudz vienkāršāka nekā daļa Domā un rīkojies.
Spēles AI ierobežojumi
AI ir vairāki ierobežojumi, kas jāievēro:
- AI nav iepriekš jāapmāca, it kā tas būtu mašīnmācīšanās algoritms. Nav jēgas izstrādes laikā rakstīt neironu tīklu, lai uzraudzītu desmitiem tūkstošu spēlētāju un uzzinātu labāko veidu, kā spēlēt pret viņiem. Kāpēc? Jo spēle nav izlaista un spēlētāju nav.
- Spēlei jābūt jautrai un izaicinošai, tāpēc aģentiem nevajadzētu atrast labāko pieeju pret cilvēkiem.
- Aģentiem ir jāizskatās reālistiskiem, lai spēlētāji justos tā, it kā viņi spēlē pret īstiem cilvēkiem. AlphaGo programma pārspēja cilvēkus, taču izvēlētie soļi bija ļoti tālu no tradicionālās spēles izpratnes. Ja spēle simulē cilvēka pretinieku, šai sajūtai nevajadzētu pastāvēt. Algoritms ir jāmaina, lai tas pieņemtu ticamus, nevis ideālus lēmumus.
- AI jāstrādā reāllaikā. Tas nozīmē, ka algoritms nevar monopolizēt CPU izmantošanu ilgu laiku, lai pieņemtu lēmumus. Pat 10 milisekundes ir pārāk ilgs laiks, jo lielākajai daļai spēļu ir nepieciešamas tikai 16 līdz 33 milisekundes, lai veiktu visu apstrādi un pārietu uz nākamo grafikas kadru.
- Ideālā gadījumā vismaz daļai sistēmas vajadzētu būt balstītai uz datiem, lai lietotāji, kas nav kodēti, varētu veikt izmaiņas un veikt pielāgojumus ātrāk.
Apskatīsim AI pieejas, kas aptver visu Sense/Think/Act ciklu.
Pamatlēmumu pieņemšana
Sāksim ar vienkāršāko spēli - Pong. Mērķis: pārvietojiet lāpstiņu tā, lai bumba atlēktu no tās, nevis lidotu tai garām. Tas ir kā tenisā, kur tu zaudē, ja netrāpi pa bumbu. Šeit AI ir salīdzinoši viegls uzdevums - izlemt, kurā virzienā pārvietot platformu.

Nosacīti paziņojumi
AI Pong visredzamākais risinājums ir vienmēr mēģināt novietot platformu zem bumbas.
Vienkāršs algoritms tam, rakstīts pseidokodā:
katrs kadrs/atjauninājums spēles darbības laikā:
ja bumba atrodas pa kreisi no lāpstiņas:
pārvietot lāpstiņu pa kreisi
citādi, ja bumba atrodas pa labi no lāpstiņas:
pārvietojiet lāpstiņu pa labi
Ja platforma pārvietojas ar bumbiņas ātrumu, tas ir ideāls Pong algoritms AI. Nevajag neko sarežģīt, ja aģentam nav tik daudz datu un iespējamo darbību.
Šī pieeja ir tik vienkārša, ka viss Sense/Think/Act cikls ir tikko pamanāms. Bet tas ir tur:
- Sense daļa ir divos if paziņojumos. Spēle zina, kur atrodas bumba un kur atrodas platforma, tāpēc AI meklē šo informāciju.
- Domāšanas daļa ir iekļauta arī divos if paziņojumos. Tie ietver divus risinājumus, kas šajā gadījumā ir viens otru izslēdzoši. Rezultātā tiek izvēlēta viena no trim darbībām - pārvietot platformu pa kreisi, pārvietot to pa labi vai neko nedarīt, ja tā jau ir pareizi novietota.
- Darbības daļa ir atrodama paziņojumos Move Paddle Left un Move Paddle Right. Atkarībā no spēles dizaina viņi var pārvietot platformu uzreiz vai ar noteiktu ātrumu.
Šādas pieejas sauc par reaktīvām - ir vienkāršs noteikumu kopums (šajā gadījumā, ja kodā ir paziņojumi), kas reaģē uz pašreizējo pasaules stāvokli un rīkojas.
Lēmumu koks
Pong piemērs faktiski ir līdzvērtīgs formālai AI koncepcijai, ko sauc par lēmumu koku. Algoritms iziet cauri tam, lai sasniegtu “lapu” — lēmumu par to, kā rīkoties.
Izveidosim mūsu platformas algoritma lēmumu koka blokshēmu:
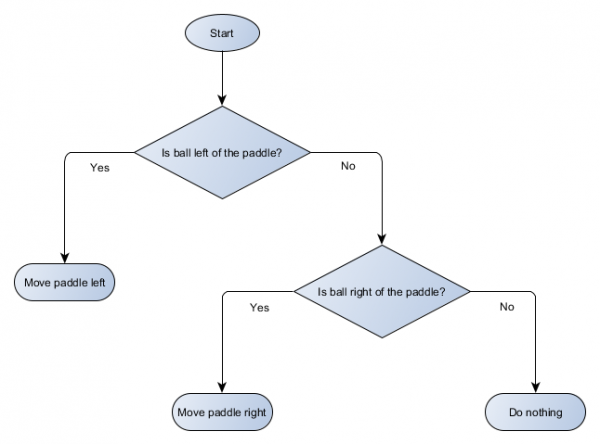
Katru koka daļu sauc par mezglu – AI izmanto grafu teoriju, lai aprakstītu šādas struktūras. Ir divu veidu mezgli:
- Lēmuma mezgli: izvēle starp divām alternatīvām, pamatojoties uz kāda nosacījuma pārbaudi, kur katra alternatīva tiek attēlota kā atsevišķs mezgls.
- Beigu mezgli: veicamā darbība, kas atspoguļo galīgo lēmumu.
Algoritms sākas no pirmā mezgla (koka “saknes”). Tas vai nu pieņem lēmumu par to, uz kuru bērnmezglu pāriet, vai arī izpilda mezglā saglabāto darbību un iziet.
Kāds ir labums no lēmumu koka, kas veic to pašu darbu, ko iepriekšējā sadaļā sniegtie if paziņojumi? Šeit ir vispārēja sistēma, kurā katram lēmumam ir tikai viens nosacījums un divi iespējamie rezultāti. Tas ļauj izstrādātājam izveidot AI no datiem, kas atspoguļo lēmumus kokā, bez nepieciešamības tos stingri kodēt. Iesniegsim to tabulas veidā:
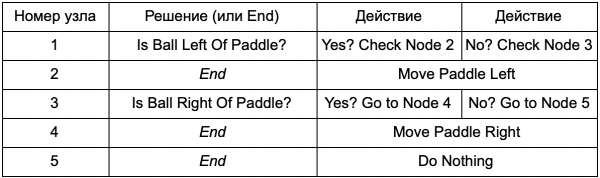
Koda pusē jūs iegūsit sistēmu virkņu nolasīšanai. Izveidojiet mezglu katram no tiem, savienojiet lēmumu loģiku, pamatojoties uz otro kolonnu, un pakārtotos mezglus, pamatojoties uz trešo un ceturto kolonnu. Jums joprojām ir jāieprogrammē nosacījumi un darbības, taču tagad spēles struktūra būs sarežģītāka. Šeit jūs pievienojat papildu lēmumus un darbības un pēc tam pielāgojat visu AI, vienkārši rediģējot koka definīcijas teksta failu. Pēc tam failu pārsūtiet spēles izstrādātājam, kurš var mainīt uzvedību, nepārkompilējot spēli vai nemainot kodu.
Lēmumu koki ir ļoti noderīgi, ja tie tiek veidoti automātiski, izmantojot lielu piemēru kopu (piemēram, izmantojot ID3 algoritmu). Tas padara tos par efektīvu un augstas veiktspējas rīku situāciju klasificēšanai, pamatojoties uz iegūtajiem datiem. Tomēr mēs pārsniedzam vienkāršu sistēmu, lai aģenti varētu atlasīt darbības.
Scenāriji
Mēs analizējām lēmumu koka sistēmu, kurā tika izmantoti iepriekš izveidoti nosacījumi un darbības. Persona, kas izstrādā AI, var sakārtot koku, kā vien vēlas, taču viņam joprojām ir jāpaļaujas uz kodētāju, kurš to visu ir ieprogrammējis. Ko darīt, ja mēs varētu dot dizainerim rīkus, lai radītu savus apstākļus vai darbības?
Lai programmētājam nebūtu jāraksta kods nosacījumiem Is Ball Left Of Paddle un Is Ball Right Of Paddle, viņš var izveidot sistēmu, kurā dizaineris ierakstīs nosacījumus, lai pārbaudītu šīs vērtības. Tad lēmumu koka dati izskatīsies šādi:
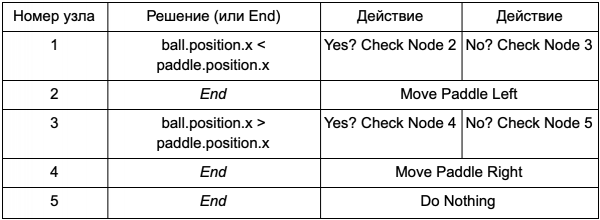
Tas būtībā ir tāds pats kā pirmajā tabulā, taču risinājumiem pašiem ir savs kods, nedaudz līdzīgs if priekšraksta nosacītajai daļai. Koda pusē tas būtu lasāms lēmuma mezglu otrajā kolonnā, taču tā vietā, lai meklētu konkrētu izpildāmu nosacījumu (Is Ball Left Of Paddle), tas novērtē nosacījuma izteiksmi un attiecīgi atgriež patiesu vai nepatiesu. Tas tiek darīts, izmantojot Lua vai Angelscript skriptu valodu. Izmantojot tos, izstrādātājs var paņemt objektus savā spēlē (bumbu un lāpstiņu) un izveidot mainīgos, kas būs pieejami skriptā (ball.position). Turklāt skriptu valoda ir vienkāršāka nekā C++. Tam nav nepieciešams pilns kompilācijas posms, tāpēc tas ir ideāli piemērots ātrai spēles loģikas pielāgošanai un ļauj “nekodētājiem” pašiem izveidot nepieciešamās funkcijas.
Iepriekš minētajā piemērā skriptu valoda tiek izmantota tikai nosacījuma izteiksmes novērtēšanai, taču to var izmantot arī darbībām. Piemēram, dati Move Paddle Right var kļūt par skripta paziņojumu (bumbiņa.pozīcija.x += 10). Lai darbība būtu definēta arī skriptā, bez nepieciešamības ieprogrammēt Move Paddle Right.
Varat iet vēl tālāk un uzrakstīt visu lēmumu koku skriptu valodā. Tas būs kods cietkodētu nosacījumu paziņojumu veidā, taču tie atradīsies ārējos skripta failos, tas ir, tos var mainīt, nepārkompilējot visu programmu. Bieži vien spēles laikā varat rediģēt skripta failu, lai ātri pārbaudītu dažādas AI reakcijas.
Notikuma atbilde
Iepriekš minētie piemēri ir lieliski piemēroti Pong. Viņi nepārtraukti vada Sense/Think/Act ciklu un rīkojas, pamatojoties uz jaunāko stāvokli pasaulē. Bet sarežģītākās spēlēs ir jāreaģē uz atsevišķiem notikumiem, nevis jānovērtē viss uzreiz. Pongs šajā gadījumā jau ir slikts piemērs. Izvēlēsimies citu.
Iedomājieties šāvēju, kurā ienaidnieki nekustas, līdz pamana spēlētāju, pēc tam viņi rīkojas atkarībā no savas “specializācijas”: kāds skries “steigties”, kāds uzbruks no tālienes. Tā joprojām ir pamata reaktīvā sistēma - "ja spēlētājs ir pamanīts, dariet kaut ko" -, taču to var loģiski sadalīt notikumā Spēlētājs redzēts un reakcijā (atlasiet atbildi un izpildiet to).
Tas mūs atgriež pie Sajūtu/Domā/ Rīkojies cikla. Mēs varam kodēt Sense daļu, kas pārbaudīs katru kadru, vai AI redz atskaņotāju. Ja nē, nekas nenotiek, bet, ja redz, tad tiek izveidots notikums Player Seen. Kodam būs atsevišķa sadaļa, kurā teikts: "Kad notiek notikums Player Seen, dariet", kur ir atbilde, kas jums nepieciešama, lai risinātu sadaļas Domā un rīkojies. Tādējādi jūs iestatīsit reakcijas uz notikumu Player Seen: “steidzīgajam” varonim - ChargeAndAttack un snaiperim - HideAndSnipe. Šīs attiecības var izveidot datu failā ātrai rediģēšanai bez nepieciešamības atkārtoti kompilēt. Šeit var izmantot arī skriptu valodu.
Sarežģītu lēmumu pieņemšana
Lai gan vienkāršas reakcijas sistēmas ir ļoti spēcīgas, ir daudz situāciju, kad ar tām nepietiek. Dažreiz jums ir jāpieņem dažādi lēmumi, pamatojoties uz to, ko aģents pašlaik dara, taču to ir grūti iedomāties kā nosacījumu. Dažreiz ir pārāk daudz nosacījumu, lai tos efektīvi attēlotu lēmumu kokā vai skriptā. Dažreiz jums ir iepriekš jāizvērtē, kā situācija mainīsies, pirms izlemjat par nākamo soli. Lai atrisinātu šīs problēmas, ir vajadzīgas sarežģītākas pieejas.
Galīgā stāvokļa mašīna
Ierobežotā stāvokļa mašīna jeb FSM (finite state machine) ir veids, kā pateikt, ka mūsu aģents pašlaik atrodas vienā no vairākiem iespējamiem stāvokļiem un ka tas var pāriet no viena stāvokļa uz citu. Ir zināms skaits šādu stāvokļu, tāpēc arī nosaukums. Labākais piemērs no dzīves ir luksofors. Dažādās vietās ir dažādas gaismu secības, bet princips ir viens – katrs stāvoklis kaut ko attēlo (apstāties, iet utt.). Luksofors jebkurā laikā atrodas tikai vienā stāvoklī un pārvietojas no viena uz otru, pamatojoties uz vienkāršiem noteikumiem.
Tas ir līdzīgs stāsts ar NPC spēlēs. Piemēram, ņemsim aizsargu ar šādiem stāvokļiem:
- Patrulēšana.
- Uzbrūk.
- Bēgšana.
Un šie nosacījumi tā stāvokļa maiņai:
- Ja apsargs redz ienaidnieku, viņš uzbrūk.
- Ja apsargs uzbrūk, bet vairs neredz ienaidnieku, viņš atgriežas patrulēt.
- Ja apsargs uzbrūk, bet ir smagi ievainots, viņš bēg.
Var rakstīt arī if-izteikumus ar aizbildņa stāvokļa mainīgo un dažādām pārbaudēm: vai tuvumā ir ienaidnieks, kāds ir NPC veselības līmenis utt. Pievienosim vēl dažus stāvokļus:
- Dīkstāve - starp patruļām.
- Meklēšana – kad pazudis pamanītais ienaidnieks.
- Palīdzības atrašana - kad ienaidnieks ir pamanīts, bet ir pārāk spēcīgs, lai cīnītos viens.
Katram no viņiem izvēle ir ierobežota – piemēram, apsargs nedosies meklēt slēptu ienaidnieku, ja viņam ir slikta veselība.
Galu galā ir milzīgs "ja" saraksts , Tas " var kļūt pārāk apgrūtinoši, tāpēc mums ir jāformalizē metode, kas ļauj mums paturēt prātā stāvokļus un pārejas starp stāvokļiem. Lai to izdarītu, mēs ņemam vērā visus stāvokļus un zem katra stāvokļa sarakstā ierakstām visas pārejas uz citiem stāvokļiem kopā ar tiem nepieciešamajiem nosacījumiem.
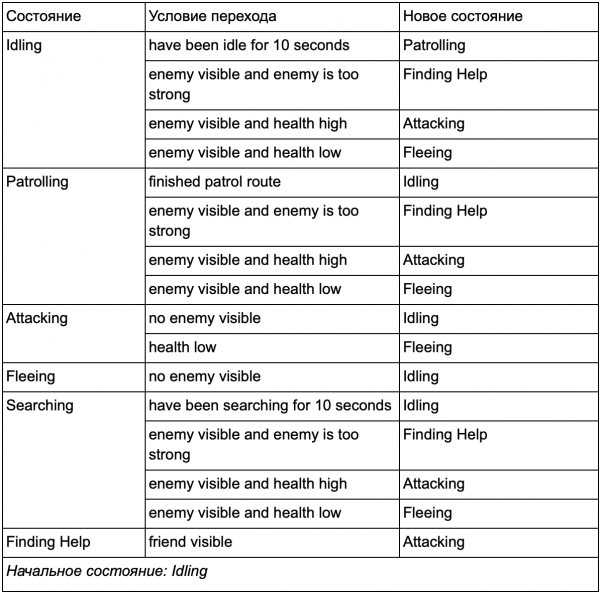
Šī ir stāvokļa pārejas tabula - visaptverošs veids, kā pārstāvēt MFV. Uzzīmēsim diagrammu un iegūsim pilnīgu pārskatu par to, kā mainās NPC uzvedība.
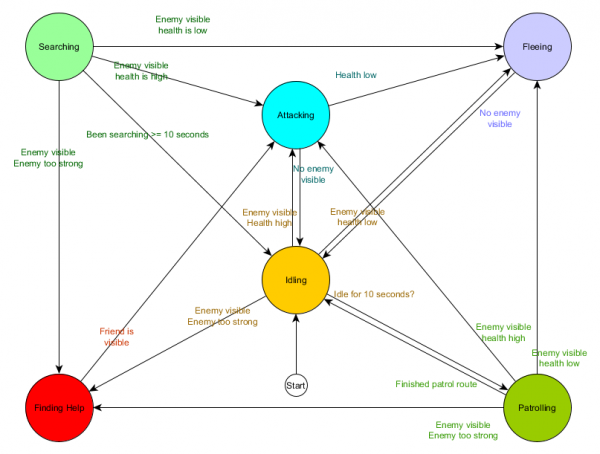
Diagramma atspoguļo šī aģenta lēmumu pieņemšanas būtību, pamatojoties uz pašreizējo situāciju. Turklāt katra bultiņa parāda pāreju starp stāvokļiem, ja blakus esošais nosacījums ir patiess.
Katrā atjauninājumā mēs pārbaudām aģenta pašreizējo stāvokli, apskatām pāreju sarakstu un, ja ir izpildīti pārejas nosacījumi, tas pieņem jauno stāvokli. Piemēram, katrs kadrs pārbauda, vai 10 sekunžu taimeris nav beidzies, un, ja tā, tad apsargs pāriet no tukšgaitas stāvokļa uz Patrulēšanu. Tādā pašā veidā Uzbrūkošais stāvoklis pārbauda aģenta veselību – ja tas ir zems, tad tas pāriet Bēgšanas stāvoklī.
Tas attiecas uz pāreju starp stāvokļiem, bet kā ar uzvedību, kas saistīta ar pašiem stāvokļiem? Runājot par faktiskās uzvedības ieviešanu konkrētam stāvoklim, parasti ir divu veidu "āķis", kurā mēs piešķiram darbības MFV:
- Darbības, kuras mēs periodiski veicam pašreizējam stāvoklim.
- Darbības, ko veicam, pārejot no viena stāvokļa uz otru.
Piemēri pirmajam tipam. Patrulēšanas stāvoklis pārvietos aģentu pa patruļas maršrutu katrā kadrā. Uzbrukuma stāvoklis mēģinās uzsākt uzbrukumu katrā kadrā vai pāriet uz stāvokli, kurā tas ir iespējams.
Otrajam veidam apsveriet pāreju “ja ienaidnieks ir redzams un ienaidnieks ir pārāk spēcīgs, pārejiet uz Meklēšanas palīdzības stāvokli. Aģentam ir jāizvēlas, kur vērsties pēc palīdzības, un jāsaglabā šī informācija, lai palīdzības meklēšanas stāvoklis zinātu, kur vērsties. Kad palīdzība tiek atrasta, aģents atgriežas uzbrucēja stāvoklī. Šajā brīdī viņš vēlēsies pastāstīt sabiedrotajam par draudiem, tāpēc var notikt NotifyFriendOfThreat darbība.
Vēlreiz mēs varam aplūkot šo sistēmu caur cikla Sense/Think/Act objektīvu. Jēga ir ietverta datos, ko izmanto pārejas loģika. Padomā – pārejas pieejamas katrā stāvoklī. Un aktu veic darbības, kas periodiski tiek veiktas stāvoklī vai pārejās starp stāvokļiem.
Dažreiz nepārtrauktas aptaujas pārejas nosacījumi var būt dārgi. Piemēram, ja katrs aģents veic sarežģītus aprēķinus katrā kadrā, lai noteiktu, vai tas var redzēt ienaidniekus un saprast, vai tas var pāriet no patrulēšanas stāvokļa uz uzbrukumu, tas prasīs daudz CPU laika.
Svarīgas izmaiņas pasaules stāvoklī var uzskatīt par notikumiem, kas tiks apstrādāti, tiklīdz tie notiek. Tā vietā, lai FSM pārbaudītu pārejas nosacījumu "vai mans aģents var redzēt atskaņotāju?" katrā kadrā, atsevišķu sistēmu var konfigurēt, lai tā pārbaudītu retāk (piemēram, 5 reizes sekundē). Rezultātā tiek izdots Player Seen, kad čeks ir izturēts.
Tas tiek nodots MFV, kurai tagad jāiet uz nosacījumu, ka notikums ir redzēts, un attiecīgi jāreaģē. Rezultātā uzvedība ir tāda pati, izņemot gandrīz nemanāmu kavēšanos pirms atbildes. Taču veiktspēja ir uzlabojusies, atdalot Sense daļu atsevišķā programmas daļā.
Hierarhiska galīgo stāvokļu mašīna
Tomēr darbs ar lieliem FSM ne vienmēr ir ērti. Ja mēs vēlamies paplašināt uzbrukuma stāvokli, lai atdalītu MeleeAttacking un RangedAttacking, mums būs jāmaina pārejas no visiem pārējiem stāvokļiem, kas noved pie Attacking stāvokļa (pašreizējais un nākotnes).
Jūs droši vien pamanījāt, ka mūsu piemērā ir daudz pāreju dublikātu. Lielākā daļa pāreju tukšgaitas stāvoklī ir identiskas pārejām patrulēšanas stāvoklī. Būtu jauki neatkārtoties, it īpaši, ja pievienojam vēl līdzīgus stāvokļus. Ir jēga grupēt tukšgaitu un patrulēšanu zem vispārējā apzīmējuma "bez kaujas", kur ir tikai viens kopīgs pāreju kopums uz kaujas stāvokļiem. Ja mēs domājam par šo etiķeti kā stāvokli, tad tukšgaita un patrulēšana kļūst par apakšstāvokļiem. Atsevišķas pārejas tabulas izmantošanas piemērs jaunai ar kauju nesaistītai apakšstāvoklim:
Galvenie stāvokļi:
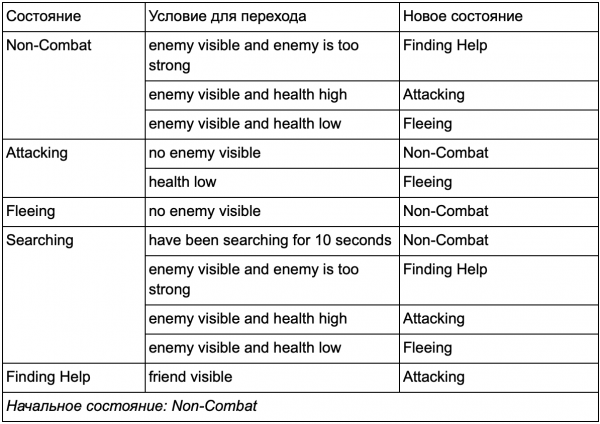
Ārpus kaujas statuss:

Un diagrammas formā:
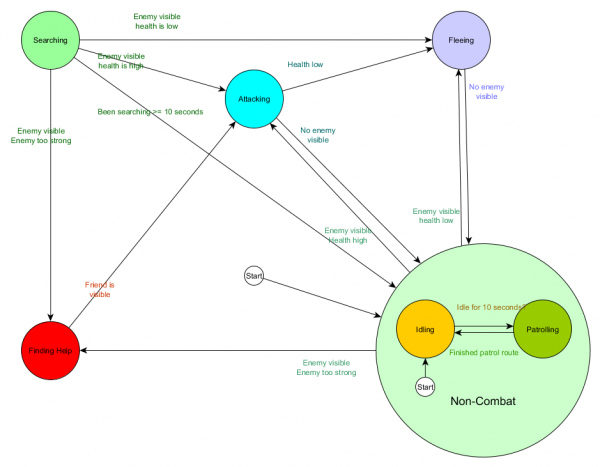
Tā ir tā pati sistēma, bet ar jaunu bezkaujas stāvokli, kas ietver tukšgaitu un patrulēšanu. Katram stāvoklim, kurā ir FSM ar apakšstāvokļiem (un šie apakšstāvokļi, savukārt, satur savus FSM — un tā tālāk tik ilgi, cik jums nepieciešams), mēs iegūstam hierarhisko galīgo stāvokļu mašīnu vai HFSM (hierarhisko galīgo stāvokļu mašīnu). Grupējot bezkaujas stāvokli, mēs izgriezām virkni lieku pāreju. Mēs varam darīt to pašu jebkuriem jauniem stāvokļiem ar kopīgām pārejām. Piemēram, ja nākotnē mēs paplašināsim Attacking stāvokli uz Tuvcīņas uzbrukuma un MissileAttacking stāvokļiem, tie būs apakšstāvokļi, kas pāriet savā starpā, pamatojoties uz attālumu līdz ienaidniekam un munīcijas pieejamību. Rezultātā sarežģītas uzvedības un apakšuzvedības var attēlot ar minimālu dublikātu pāreju skaitu.
Uzvedības koks
Izmantojot HFSM, vienkāršā veidā tiek izveidotas sarežģītas uzvedības kombinācijas. Tomēr ir nelielas grūtības, ka lēmumu pieņemšana pārejas noteikumu veidā ir cieši saistīta ar pašreizējo stāvokli. Un daudzās spēlēs tas ir tieši tas, kas nepieciešams. Un rūpīga stāvokļa hierarhijas izmantošana var samazināt pārejas atkārtojumu skaitu. Bet dažreiz jums ir nepieciešami noteikumi, kas darbojas neatkarīgi no jūsu atrašanās vietas vai ir spēkā gandrīz jebkurā štatā. Piemēram, ja aģenta veselības stāvoklis pasliktinās līdz 25%, jūs vēlaties, lai viņš aizbēgtu neatkarīgi no tā, vai viņš bija kaujā, dīkstāvē vai runāja — jums šis nosacījums būs jāpievieno katram stāvoklim. Un, ja jūsu dizainers vēlāk vēlas mainīt zemo veselības slieksni no 25% uz 10%, tad tas būs jādara vēlreiz.
Ideālā gadījumā šī situācija prasa sistēmu, kurā lēmumi par to, “kādā stāvoklī atrasties”, ir ārpus pašiem stāvokļiem, lai veiktu izmaiņas tikai vienā vietā un neskartu pārejas nosacījumus. Šeit parādās uzvedības koki.
Ir vairāki veidi, kā tos ieviest, taču būtība ir aptuveni vienāda visiem un ir līdzīga lēmumu kokam: algoritms sākas ar “saknes” mezglu, un kokā ir mezgli, kas atspoguļo lēmumus vai darbības. Tomēr ir dažas galvenās atšķirības:
- Mezgli tagad atgriež vienu no trim vērtībām: Succeeded (ja darbs ir pabeigts), Failed (ja to nevar sākt) vai Running (ja tas joprojām darbojas un nav gala rezultāta).
- Vairs nav lēmumu pieņemšanas mezglu, no kuriem izvēlēties starp divām alternatīvām. Tā vietā tie ir dekoratora mezgli, kuriem ir viens pakārtots mezgls. Ja viņiem izdodas, viņi izpilda savu vienīgo bērnu mezglu.
- Mezgli, kas veic darbības, atgriež Running vērtību, lai attēlotu veicamās darbības.
Šo nelielo mezglu kopu var apvienot, lai izveidotu lielu skaitu sarežģītu darbību. Iedomāsimies HFSM aizsargu no iepriekšējā piemēra kā uzvedības koku:
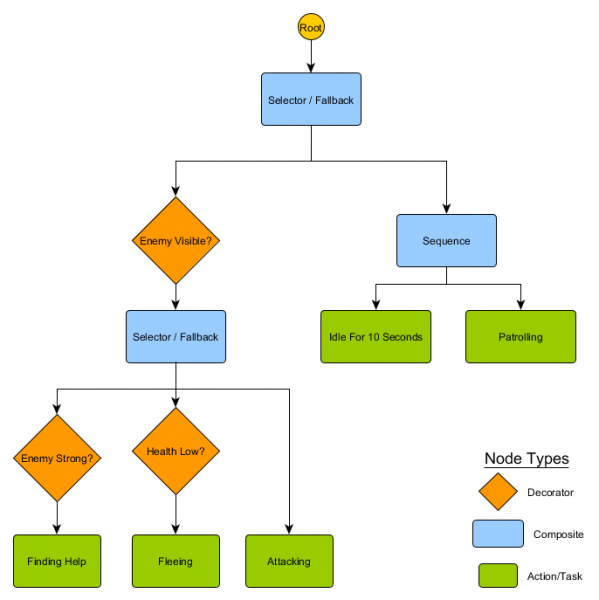
Izmantojot šo struktūru, nevajadzētu būt acīmredzamai pārejai no tukšgaitas/patrulēšanas stāvokļiem uz uzbrukuma vai citiem stāvokļiem. Ja ir redzams ienaidnieks un varoņa veselība ir zema, izpilde tiks pārtraukta Bēgšanas mezglā neatkarīgi no tā, kuru mezglu tas iepriekš izpildīja – Patrulēšana, Tukšgaita, Uzbrūkšana vai jebkura cita.
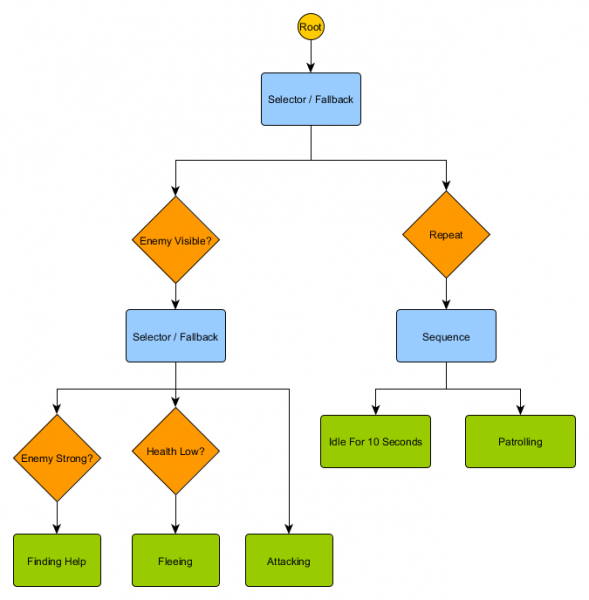
Uzvedības koki ir sarežģīti — ir daudz veidu, kā tos izveidot, un atrast pareizo dekoratoru un salikto mezglu kombināciju var būt izaicinājums. Rodas arī jautājumi par to, cik bieži koku pārbaudīt – vai gribam iziet cauri katrai tā daļai vai tikai tad, kad ir mainījies kāds no apstākļiem? Kā mēs saglabājam mezglu stāvokli — kā mēs zinām, kad esam dīkstāvē 10 sekundes, vai kā mēs zinām, kuri mezgli darbojās pēdējo reizi, lai mēs varētu pareizi apstrādāt secību?
Tāpēc ir daudz ieviešanu. Piemēram, dažās sistēmās dekoratoru mezgli ir aizstāti ar iebūvētiem dekoratoriem. Viņi atkārtoti novērtē koku, kad mainās dekoratora apstākļi, palīdz pievienoties mezgliem un nodrošina periodiskus atjauninājumus.
Uz komunālajiem pakalpojumiem balstīta sistēma
Dažām spēlēm ir daudz dažādu mehāniku. Vēlams, lai viņi saņemtu visas vienkāršo un vispārīgo pārejas noteikumu priekšrocības, bet ne vienmēr pilnīga uzvedības koka veidā. Tā vietā, lai būtu skaidrs izvēļu kopums vai iespējamo darbību koks, ir vieglāk izskatīt visas darbības un izvēlēties konkrētajā brīdī piemērotāko.
Uz utilītprogrammām balstītā sistēma palīdzēs tieši šajā jautājumā. Šī ir sistēma, kurā aģentam ir dažādas darbības un viņš izvēlas, kuras no tām veikt, pamatojoties uz katras darbības relatīvo lietderību. Ja lietderība ir patvaļīgs mērs tam, cik svarīgi vai vēlams aģentam ir veikt šo darbību.
Aprēķinātā darbības lietderība, pamatojoties uz pašreizējo stāvokli un vidi, aģents jebkurā laikā var pārbaudīt un atlasīt vispiemērotāko citu stāvokli. Tas ir līdzīgi MFV, izņemot gadījumus, kad pārejas nosaka katra potenciālā stāvokļa novērtējums, ieskaitot pašreizējo. Lūdzu, ņemiet vērā, ka mēs izvēlamies visnoderīgāko darbību, lai turpinātu (vai paliekam, ja esam to jau pabeiguši). Lai iegūtu lielāku dažādību, šī varētu būt līdzsvarota, bet nejauša atlase no neliela saraksta.
Sistēma piešķir patvaļīgu lietderības vērtību diapazonu, piemēram, no 0 (pilnīgi nevēlams) līdz 100 (pilnīgi vēlams). Katrai darbībai ir vairāki parametri, kas ietekmē šīs vērtības aprēķināšanu. Atgriežoties pie mūsu aizbildņa piemēra:

Pārejas starp darbībām ir neskaidras — jebkura valsts var sekot jebkurai citai. Darbības prioritātes ir atrodamas atgrieztajās lietderības vērtībās. Ja ir redzams ienaidnieks un šis ienaidnieks ir spēcīgs un varoņa veselība ir zema, gan Fleeing, gan FindingHelp atgriezīs augstas vērtības, kas nav nulles. Šajā gadījumā FindingHelp vienmēr būs augstāks. Tāpat arī ar kauju nesaistītās aktivitātes nekad neatmaksā vairāk par 50, tāpēc tās vienmēr būs zemākas par kaujas aktivitātēm. Tas jāņem vērā, veidojot darbības un aprēķinot to lietderību.
Mūsu piemērā darbības atgriež vai nu fiksētu konstantu vērtību, vai vienu no divām fiksētām vērtībām. Reālistiskāka sistēma atgrieztu aplēsi no nepārtraukta vērtību diapazona. Piemēram, darbība Bēgšana atgriež augstākas lietderības vērtības, ja aģenta veselības stāvoklis ir zems, un darbība Attacking atgriež zemākas lietderības vērtības, ja ienaidnieks ir pārāk spēcīgs. Šī iemesla dēļ darbībai Bēgšana ir augstāka par Uzbrukumu jebkurā situācijā, kad aģentam šķiet, ka viņam nav pietiekami daudz veselības, lai uzvarētu ienaidnieku. Tas ļauj noteikt darbībām prioritāti, pamatojoties uz jebkuru kritēriju skaitu, padarot šo pieeju elastīgāku un mainīgāku nekā uzvedības koks vai MFV.
Katrai darbībai ir daudz nosacījumu programmas aprēķināšanai. Tos var rakstīt skriptu valodā vai kā matemātisko formulu sēriju. Sims, kas simulē varoņa ikdienas rutīnu, pievieno papildu aprēķinu slāni - aģents saņem virkni "motivācijas", kas ietekmē lietderības vērtējumus. Ja varonis ir izsalcis, tas laika gaitā kļūs vēl izsalkuši, un EatFood darbības lietderības vērtība palielināsies, līdz varonis to izpildīs, samazinot izsalkuma līmeni un atgriežot EatFood vērtību uz nulli.
Ideja par darbību atlasi, pamatojoties uz vērtēšanas sistēmu, ir diezgan vienkārša, tāpēc uz utilītu balstītu sistēmu var izmantot kā daļu no AI lēmumu pieņemšanas procesiem, nevis kā pilnīgu to aizstājēju. Lēmumu koks var pieprasīt divu pakārtoto mezglu lietderības novērtējumu un atlasīt augstāko. Līdzīgi uzvedības kokam var būt salikts lietderības mezgls, lai novērtētu darbību lietderību, lai izlemtu, kuru bērnu izpildīt.
Kustība un navigācija
Iepriekšējos piemēros mums bija platforma, kuru mēs pārvietojām pa kreisi vai pa labi, un apsargs, kas patrulēja vai uzbruka. Bet kā tieši mēs rīkojamies ar aģentu kustību noteiktā laika periodā? Kā mēs uzstādām ātrumu, kā izvairāmies no šķēršļiem un kā mēs plānojam maršrutu, kad nokļūt galamērķī ir grūtāk, nekā braukt pa taisnu līniju? Apskatīsim šo.
Vadība
Sākotnējā posmā mēs pieņemsim, ka katram aģentam ir ātruma vērtība, kas ietver to, cik ātri tas pārvietojas un kādā virzienā. To var izmērīt metros sekundē, kilometros stundā, pikseļos sekundē utt. Atsaucot atmiņā Sense/Think/Act cilpu, mēs varam iedomāties, ka daļa Think izvēlas ātrumu, bet daļa Darbība piemēro šo ātrumu aģentam. Parasti spēlēm ir fizikas sistēma, kas veic šo uzdevumu jūsu vietā, apgūstot katra objekta ātruma vērtību un pielāgojot to. Tāpēc jūs varat atstāt AI ar vienu uzdevumu - izlemt, kādam ātrumam vajadzētu būt aģentam. Ja zināt, kur aģentam jāatrodas, tad tas jāpārvieto pareizajā virzienā ar noteiktu ātrumu. Ļoti triviāls vienādojums:
wish_travel = galamērķa_pozīcija — aģenta_pozīcija
Iedomājieties 2D pasauli. Aģents atrodas punktā (-2,-2), galamērķis atrodas kaut kur ziemeļaustrumos punktā (30, 20), un nepieciešamais ceļš, lai aģents tur nokļūtu, ir (32, 22). Pieņemsim, ka šīs pozīcijas mēra metros – ja pieņemsim, ka aģenta ātrums ir 5 metri sekundē, tad mēs mērogosim savu nobīdes vektoru un iegūsim ātrumu aptuveni (4.12, 2.83). Izmantojot šos parametrus, aģents galamērķī nonāktu gandrīz 8 sekundēs.
Jūs jebkurā laikā varat pārrēķināt vērtības. Ja aģents būtu pusceļā līdz mērķim, kustība būtu uz pusi mazāka, bet tā kā aģenta maksimālais ātrums ir 5 m/s (mēs to nolēmām iepriekš), ātrums būs tāds pats. Tas darbojas arī kustīgiem mērķiem, ļaujot aģentam veikt nelielas izmaiņas, kad tie pārvietojas.
Taču mēs vēlamies vairāk variāciju – piemēram, lēnām palielinot ātrumu, lai modelētu tēlu, kas pāriet no stāvēšanas uz skriešanu. To pašu var izdarīt beigās pirms apstāšanās. Šīs funkcijas ir pazīstamas kā stūrēšanas darbības, un katrai no tām ir specifiski nosaukumi: Meklēšana, Bēgšana, Ierašanās utt. Ideja ir tāda, ka paātrinājuma spēkus var pielietot aģenta ātrumam, pamatojoties uz aģenta pozīcijas un pašreizējā ātruma salīdzināšanu ar galamērķi. lai izmantotu dažādas metodes virzībai uz mērķi.
Katrai uzvedībai ir nedaudz atšķirīgs mērķis. Meklēšana un ierašanās ir veidi, kā pārvietot aģentu uz galamērķi. Šķēršļu novēršana un atdalīšana pielāgo aģenta kustību, lai izvairītos no šķēršļiem ceļā uz mērķi. Izlīdzināšana un kohēzija nodrošina aģentu kustību kopā. Jebkuru skaitu dažādu stūrēšanas darbību var summēt, lai iegūtu vienu ceļa vektoru, ņemot vērā visus faktorus. Aģents, kas izmanto ierašanās, atdalīšanas un šķēršļu novēršanas darbības, lai izvairītos no sienām un citiem aģentiem. Šī pieeja labi darbojas atklātās vietās bez nevajadzīgām detaļām.
Sarežģītākos apstākļos dažādu uzvedību pievienošana darbojas sliktāk - piemēram, aģents var iestrēgt sienā konflikta starp Ierašanos un šķēršļu novēršanu dēļ. Tāpēc jums ir jāapsver iespējas, kas ir sarežģītākas nekā vienkārši visu vērtību pievienošana. Veids ir šāds: tā vietā, lai saskaitītu katras uzvedības rezultātus, varat apsvērt kustību dažādos virzienos un izvēlēties labāko variantu.
Tomēr sarežģītā vidē ar strupceļiem un izvēli, kuru ceļu iet, mums būs nepieciešams kaut kas vēl progresīvāks.
Ceļš
Stūrēšanas izturēšanās ir lieliski piemērota vienkāršai kustībai atklātā vietā (futbola laukumā vai arēnā), kur nokļūšana no A līdz B ir taisna taka ar tikai nelieliem apvedceļiem ap šķēršļiem. Sarežģītiem maršrutiem mums ir nepieciešama ceļa atrašana, kas ir veids, kā izpētīt pasauli un izlemt par maršrutu caur to.
Visvienkāršākais ir uzlikt režģi katram laukumam blakus aģentam un novērtēt, kurš no tiem drīkst pārvietoties. Ja kāds no tiem ir galamērķis, tad sekojiet maršrutam no katra laukuma uz iepriekšējo, līdz sasniedzat sākumu. Šis ir maršruts. Pretējā gadījumā atkārtojiet šo procesu ar citiem blakus esošajiem laukumiem, līdz atrodat galamērķi vai izbeidzas laukums (tas nozīmē, ka nav iespējama maršruta). Tas ir tas, kas formāli tiek saukts par meklēšanas platumu vai BFS (meklēšanas algoritms pēc platuma). Ik uz soļa viņš skatās uz visām pusēm (tātad platums, "platums"). Meklēšanas telpa ir kā viļņu fronte, kas kustas, līdz sasniedz vēlamo vietu – meklēšanas telpa katrā solī paplašinās, līdz tiek iekļauts beigu punkts, pēc kura to var izsekot līdz sākumam.
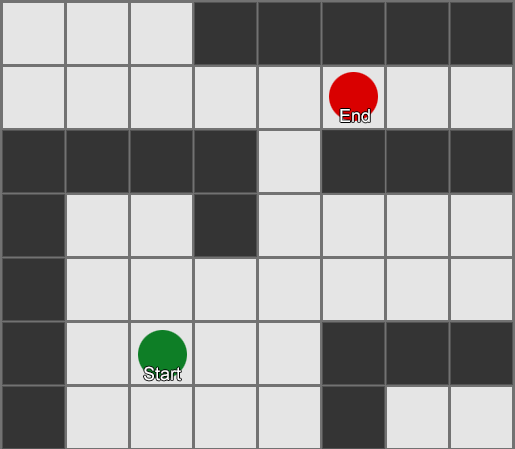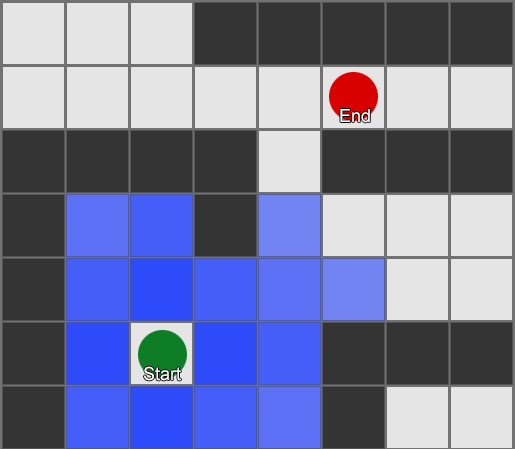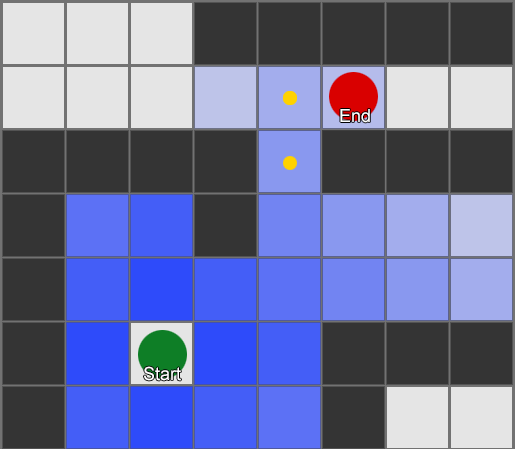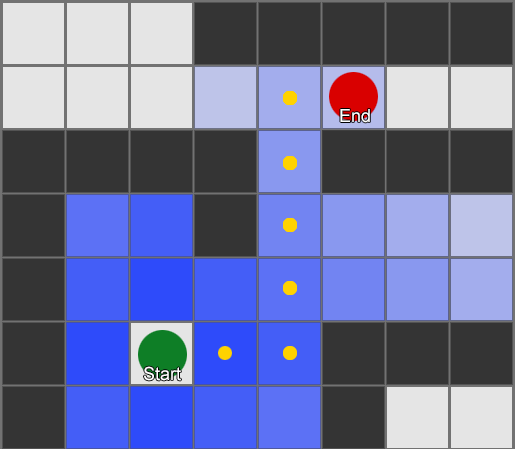
Rezultātā jūs saņemsiet sarakstu ar laukumiem, pa kuriem tiek sastādīts vēlamais maršruts. Šis ir ceļš (tātad, ceļa atrašana) — to vietu saraksts, kuras aģents apmeklēs, sekojot galamērķim.
Ņemot vērā to, ka mēs zinām katra kvadrāta atrašanās vietu pasaulē, mēs varam izmantot stūrēšanas uzvedību, lai pārvietotos pa ceļu - no 1. mezgla uz 2. mezglu, tad no 2. mezgla uz 3. mezglu un tā tālāk. Vienkāršākais variants ir virzīties uz nākamā laukuma centru, bet vēl labāks variants ir apstāties malas vidū starp pašreizējo un nākamo laukumu. Pateicoties tam, aģents varēs nogriezt stūrus asos pagriezienos.
BFS algoritmam ir arī trūkumi - tas pēta tikpat daudz kvadrātu “nepareizajā” virzienā, cik “pareizajā” virzienā. Šeit tiek izmantots sarežģītāks algoritms, ko sauc par A* (zvaigzne). Tas darbojas tāpat, bet tā vietā, lai akli pārbaudītu kaimiņu kvadrātus (pēc tam kaimiņu kaimiņus, pēc tam kaimiņu kaimiņus un tā tālāk), tas apkopo mezglus sarakstā un sakārto tos tā, lai nākamais pārbaudītais mezgls vienmēr būtu tāds, kas ved uz īsāko ceļu. Mezgli tiek kārtoti, pamatojoties uz heiristisku metodi, kurā tiek ņemtas vērā divas lietas — hipotētiskā maršruta “izmaksas” uz vēlamo laukumu (ieskaitot visas ceļa izmaksas) un aplēses par to, cik tālu šis laukums atrodas no galamērķa (novirzot meklēšanu pareizais virziens).
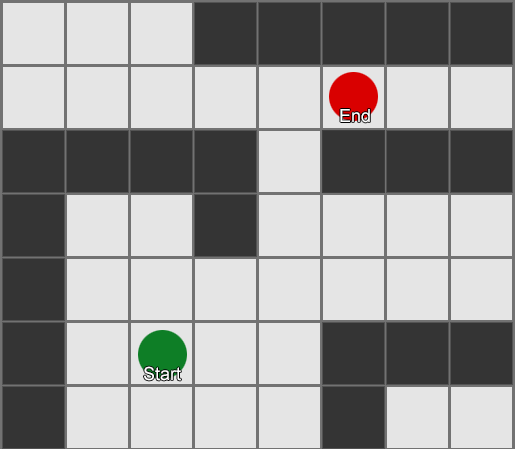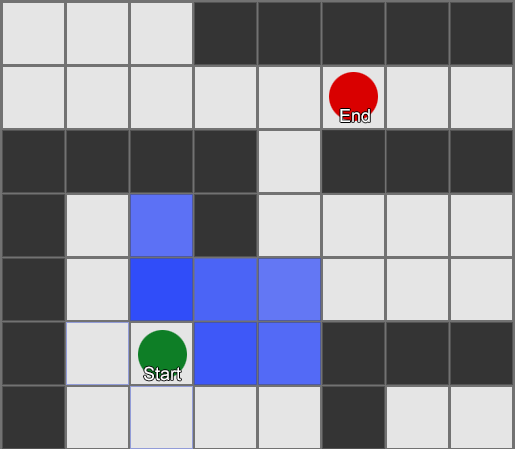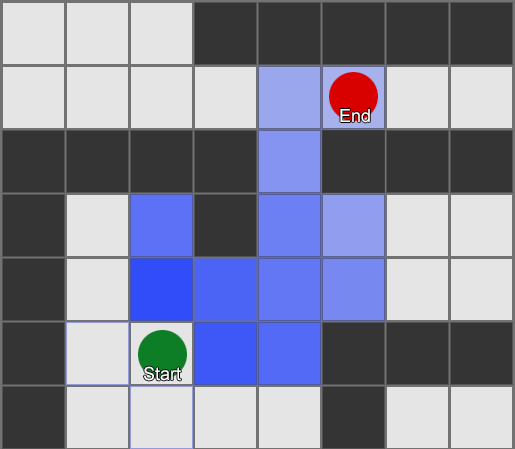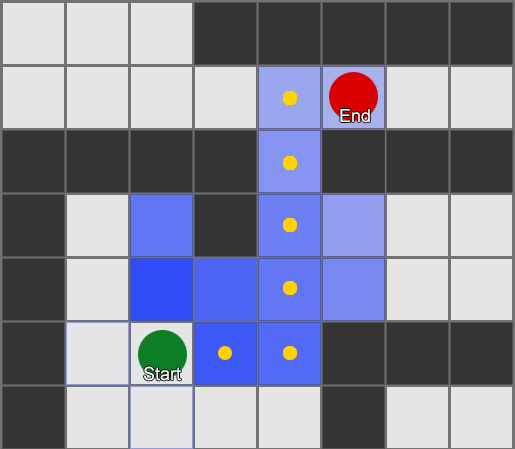
Šis piemērs parāda, ka aģents vienlaikus izpēta vienu kvadrātu, katru reizi izvēloties blakus esošo, kas ir visdaudzsološākais. Rezultātā iegūtais ceļš ir tāds pats kā BFS, taču šajā procesā tika ņemts vērā mazāk laukumu, kas būtiski ietekmē spēles veiktspēju.
Kustība bez režģa
Taču lielākā daļa spēļu nav izkārtotas režģī, un bieži vien to nav iespējams izdarīt, neupurējot reālismu. Ir vajadzīgi kompromisi. Kādam izmēram jābūt kvadrātiem? Pārāk lieli, un tie nespēs pareizi attēlot mazus koridorus vai pagriezienus, pārāk mazi, un būs pārāk daudz laukumu, ko meklēt, kas galu galā prasīs daudz laika.
Vispirms ir jāsaprot, ka tīkls sniedz mums savienoto mezglu grafiku. Algoritmi A* un BFS faktiski darbojas uz grafikiem, un tiem vispār nerūp mūsu tīkls. Mēs varētu novietot mezglus jebkurā spēles pasaulē: kamēr pastāv savienojums starp jebkuriem diviem savienotiem mezgliem, kā arī starp sākuma un beigu punktiem un vismaz vienu no mezgliem, algoritms darbosies tikpat labi kā iepriekš. To bieži sauc par maršruta punktu sistēmu, jo katrs mezgls pārstāv nozīmīgu vietu pasaulē, kas var būt daļa no jebkura skaita hipotētisku ceļu.
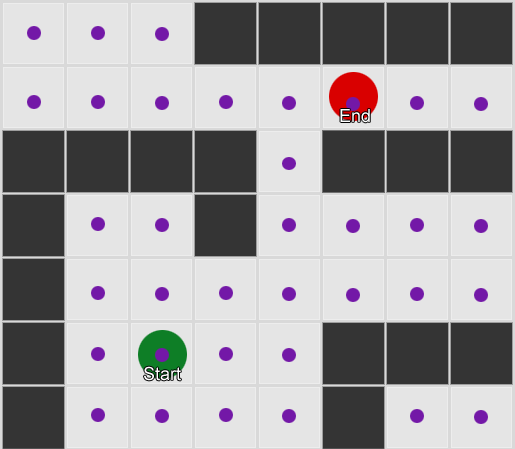
1. piemērs: mezgls katrā kvadrātā. Meklēšana sākas no mezgla, kurā atrodas aģents, un beidzas vajadzīgā kvadrāta mezglā.
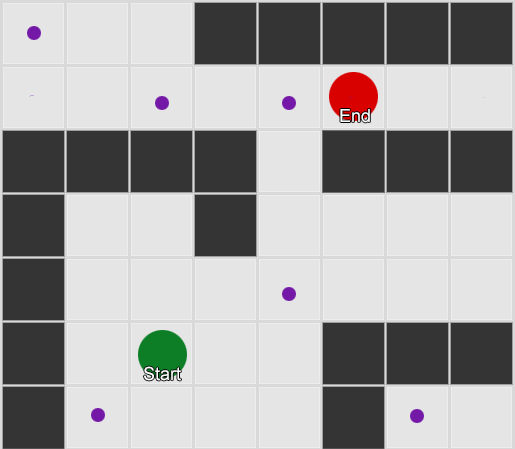
2. piemērs: mazāka mezglu (ceļa punktu) kopa. Meklēšana sākas aģenta laukumā, iziet cauri vajadzīgajam mezglu skaitam un pēc tam turpinās līdz galamērķim.
Šī ir pilnīgi elastīga un jaudīga sistēma. Taču ir nepieciešama piesardzība, izlemjot, kur un kā novietot pieturas punktu, pretējā gadījumā aģenti var vienkārši neredzēt tuvāko punktu un nevarēs sākt ceļu. Būtu vieglāk, ja mēs varētu automātiski izvietot pieturas punktus, pamatojoties uz pasaules ģeometriju.
Šeit parādās navigācijas siets vai navmesh (navigācijas tīkls). Parasti tas ir trijstūru 2D tīkls, kas tiek pārklāts ar pasaules ģeometriju — visur, kur aģentam ir atļauts staigāt. Katrs acs trijstūris kļūst par mezglu diagrammā, un tam ir ne vairāk kā trīs blakus esošie trīsstūri, kas kļūst par diagrammas blakus mezgliem.
Šis attēls ir piemērs no Unity dzinēja - tas analizēja ģeometriju pasaulē un izveidoja navsietu (ekrānuzņēmumā gaiši zilā krāsā). Katrs navigācijas tīkla daudzstūris ir apgabals, kurā aģents var stāvēt vai pārvietoties no viena daudzstūra uz citu daudzstūri. Šajā piemērā daudzstūri ir mazāki par stāviem, uz kuriem tie atrodas - tas tiek darīts, lai ņemtu vērā aģenta izmēru, kas pārsniedz tā nominālo pozīciju.

Mēs varam meklēt maršrutu caur šo tīklu, atkal izmantojot A* algoritmu. Tas mums iegūs gandrīz ideālu maršrutu pasaulē, kas ņem vērā visu ģeometriju un neprasa liekus mezglus un ceļa punktu izveidi.
Ceļa meklēšana ir pārāk plaša tēma, kurai nepietiek ar vienu raksta sadaļu. Ja vēlaties to izpētīt sīkāk, tad tas palīdzēs .
plānošana
Ar ceļa atrašanu esam iemācījušies, ka dažreiz nepietiek tikai izvēlēties virzienu un pārvietoties – mums ir jāizvēlas maršruts un jāveic daži pagriezieni, lai nokļūtu vēlamajā galamērķī. Mēs varam vispārināt šo ideju: mērķa sasniegšana nav tikai nākamais solis, bet gan vesela secība, kurā dažreiz jums ir jāskatās uz priekšu vairākus soļus, lai noskaidrotu, kam vajadzētu būt pirmajam. To sauc par plānošanu. Ceļa atrašanu var uzskatīt par vienu no vairākiem plānošanas paplašinājumiem. Runājot par mūsu ciklu Sense/Think/Act, šajā daļā Domāšanas daļa plāno vairākas darbības daļas nākotnei.
Apskatīsim galda spēles Magic: The Gathering piemēru. Vispirms mēs ejam ar šādu kāršu komplektu rokās:
- Purvs - dod 1 melno manu (zemes karti).
- Mežs - dod 1 zaļo manu (zemes karti).
- Fugitive Wizard — lai izsauktu 1 zilo manu.
- Elvish Mystic — lai izsauktu 1 zaļo manu.
Mēs ignorējam atlikušās trīs kārtis, lai būtu vieglāk. Saskaņā ar noteikumiem spēlētājam ir atļauts izspēlēt 1 zemes karti vienā gājienā, viņš var “piesit” šai kārtei, lai no tās izvilktu manu, un pēc tam mest burvestības (tostarp izsaukt radījumu) atbilstoši manas daudzumam. Šādā situācijā spēlētājs zina, ka jāspēlē Forest, jāpiesit 1 zaļajam manam un pēc tam jāizsauc Elvish Mystic. Bet kā spēle AI to var izdomāt?
Viegla plānošana
Triviālā pieeja ir izmēģināt katru darbību pēc kārtas, līdz vairs nav piemērotas. Aplūkojot kārtis, AI redz, ko Swamp var spēlēt. Un viņš to spēlē. Vai šajā pagriezienā ir vēl kādas darbības? Tas nevar izsaukt Elvish Mystic vai Fugitive Wizard, jo tiem ir nepieciešama attiecīgi zaļā un zilā mana, lai tos izsauktu, savukārt Swamp nodrošina tikai melno manu. Un viņš vairs nevarēs spēlēt Forestu, jo viņš jau ir spēlējis Purvu. Tādējādi spēle AI ievēroja noteikumus, taču darīja to slikti. Var uzlabot.
Plānojot var atrast sarakstu ar darbībām, kas noved spēli vēlamajā stāvoklī. Tāpat kā katram ceļa laukumam bija kaimiņi (ceļa atrašanā), katrai plāna darbībai ir arī kaimiņi vai pēcteči. Mēs varam meklēt šīs darbības un turpmākās darbības, līdz sasniedzam vēlamo stāvokli.
Mūsu piemērā vēlamais rezultāts ir “izsauc radījumu, ja iespējams”. Pagrieziena sākumā redzam tikai divas iespējamās darbības, ko pieļauj spēles noteikumi:
1. Spēlējiet Swamp (rezultāts: Swamp spēlē)
2. Spēlēt Forest (rezultāts: Mežs spēlē)
Katra veiktā darbība var izraisīt turpmākas darbības un slēgt citas, atkal atkarībā no spēles noteikumiem. Iedomājieties, ka mēs spēlējām Swamp - tas noņems Swamp kā nākamo soli (mēs to jau spēlējām), un tas noņems arī Forest (jo saskaņā ar noteikumiem jūs varat izspēlēt vienu zemes karti katrā gājienā). Pēc tam AI kā nākamo soli pievieno 1 melnās manas iegūšanu, jo nav citu iespēju. Ja viņš iet uz priekšu un izvēlēsies Tap the Swamp, viņš saņems 1 vienību melnā mana un nevarēs ar to neko darīt.
1. Spēlējiet Swamp (rezultāts: Swamp spēlē)
1.1 “Tap” purvs (rezultāts: purvs “piesists”, +1 vienība melnā mana)
Nav pieejama neviena darbība — END
2. Spēlēt Forest (rezultāts: Mežs spēlē)
Darbību saraksts bija īss, nonācām strupceļā. Mēs atkārtojam procesu nākamajam solim. Mēs spēlējam Forest, atveram darbību “dabū 1 zaļo manu”, kas savukārt atklās trešo darbību - izsauc Elvish Mystic.
1. Spēlējiet Swamp (rezultāts: Swamp spēlē)
1.1 “Tap” purvs (rezultāts: purvs “piesists”, +1 vienība melnā mana)
Nav pieejama neviena darbība — END
2. Spēlēt Forest (rezultāts: Mežs spēlē)
2.1. “Tap” mežs (rezultāts: mežs ir “piesists”, +1 vienība zaļās manas)
2.1.1. Izsaukt Elvish Mystic (rezultāts: Elvish Mystic spēlē, -1 zaļā mana)
Nav pieejama neviena darbība — END
Visbeidzot, mēs izpētījām visas iespējamās darbības un atradām plānu, kas izsauc radījumu.
Šis ir ļoti vienkāršots piemērs. Ieteicams izvēlēties labāko iespējamo plānu, nevis tikai jebkuru plānu, kas atbilst dažiem kritērijiem. Parasti ir iespējams novērtēt potenciālos plānus, pamatojoties uz to īstenošanas rezultātu vai kopējo ieguvumu. Jūs varat iegūt sev 1 punktu par zemes kartes izspēlēšanu un 3 punktus par radījuma izsaukšanu. Spēlēt Purvu būtu 1 punkta plāns. Un spēlējot Forest → Tap the Forest → izsauc Elvish Mystic uzreiz iedos 4 punktus.
Šādi plānošana darbojas programmā Magic: The Gathering, taču tā pati loģika attiecas arī uz citām situācijām. Piemēram, bandinieka pārvietošana, lai atbrīvotu vietu bīskapam, lai pārvietotos šahā. Vai arī paslēpieties aiz sienas, lai droši fotografētu šādā formātā XCOM. Kopumā jūs saprotat domu.
Uzlabota plānošana
Dažreiz ir pārāk daudz iespējamo darbību, lai apsvērtu visas iespējamās iespējas. Atgriežoties pie piemēra ar Magic: The Gathering: pieņemsim, ka spēlē un jūsu rokā ir vairākas zemes un radījumu kārtis - iespējamo gājienu kombināciju skaits var būt desmitiem. Problēmai ir vairāki risinājumi.
Pirmā metode ir atpakaļgaitas ķēde. Tā vietā, lai izmēģinātu visas kombinācijas, labāk ir sākt ar gala rezultātu un mēģināt atrast tiešo maršrutu. Tā vietā, lai dotos no koka saknes uz konkrētu lapu, mēs virzāmies pretējā virzienā – no lapas uz sakni. Šī metode ir vienkāršāka un ātrāka.
Ja ienaidniekam ir 1 veselība, jūs varat atrast plānu "nodarīt 1 vai vairāk bojājumu". Lai to panāktu, ir jāievēro vairāki nosacījumi:
1. Bojājumus var radīt burvestība – tai jābūt rokā.
2. Lai veiktu burvestību, jums ir nepieciešams mana.
3. Lai iegūtu manu, jāizspēlē zemes kārts.
4. Lai izspēlētu zemes karti, tai ir jābūt rokā.
Vēl viens veids ir vislabākā pirmā meklēšana. Tā vietā, lai izmēģinātu visus ceļus, mēs izvēlamies piemērotāko. Visbiežāk šī metode nodrošina optimālu plānu bez liekām meklēšanas izmaksām. A* ir labākās pirmās meklēšanas veids — no sākuma pārbaudot daudzsološākos maršrutus, tas jau var atrast labāko ceļu, nepārbaudot citas iespējas.
Interesanta un arvien populārāka labākā pirmā meklēšanas iespēja ir Monte Carlo Tree Search. Tā vietā, lai uzminētu, kuri plāni ir labāki par citiem, izvēloties katru nākamo darbību, algoritms katrā solī izvēlas nejaušus pēctečus, līdz tas sasniedz beigas (kad plāns izraisīja uzvaru vai sakāvi). Pēc tam gala rezultāts tiek izmantots, lai palielinātu vai samazinātu iepriekšējo opciju svaru. Atkārtojot šo procesu vairākas reizes pēc kārtas, algoritms sniedz labu novērtējumu tam, kāds ir labākais nākamais gājiens, pat ja situācija mainās (ja ienaidnieks rīkojas, lai traucētu spēlētājam).
Neviens stāsts par plānošanu spēlēs nebūtu pilnīgs bez uz mērķi orientētas rīcības plānošanas vai GOAP (mērķtiecīgas rīcības plānošanas). Šī ir plaši izmantota un apspriesta metode, taču, izņemot dažas atšķirīgas detaļas, tā būtībā ir atgriezeniskā ķēdes metode, par kuru mēs runājām iepriekš. Ja mērķis bija "iznīcināt spēlētāju" un spēlētājs atrodas aiz aizsega, plāns varētu būt šāds: iznīcināt ar granātu → iegūt → mest.
Parasti ir vairāki mērķi, katram ir sava prioritāte. Ja augstākās prioritātes mērķi nevar izpildīt (neviena darbību kombinācija nerada plānu "nogalināt spēlētāju", jo spēlētājs nav redzams), AI atgriezīsies pie zemākas prioritātes mērķiem.
Apmācība un adaptācija
Mēs jau teicām, ka spēļu AI parasti neizmanto mašīnmācīšanos, jo tā nav piemērota aģentu pārvaldībai reāllaikā. Bet tas nenozīmē, ka jūs nevarat kaut ko aizņemties no šīs jomas. Strēlniekā gribam pretinieku, no kura varam kaut ko mācīties. Piemēram, uzziniet par labākajām pozīcijām kartē. Vai arī pretinieks kaujas spēlē, kurš bloķētu spēlētāja bieži izmantotās kombinētās kustības, motivējot viņu izmantot citus. Tātad mašīnmācība šādās situācijās var būt diezgan noderīga.
Statistika un varbūtības
Pirms iedziļināmies sarežģītos piemēros, redzēsim, cik tālu mēs varam iet, veicot dažus vienkāršus mērījumus un izmantojot tos lēmumu pieņemšanai. Piemēram, reāllaika stratēģija – kā noteikt, vai spēlētājs var uzsākt uzbrukumu pirmajās spēles minūtēs un kādu aizsardzību pret to sagatavot? Mēs varam izpētīt spēlētāja pagātnes pieredzi, lai saprastu, kādas varētu būt turpmākās reakcijas. Sākumā mums nav šādu neapstrādātu datu, bet mēs varam tos savākt - katru reizi, kad AI spēlē pret cilvēku, tas var reģistrēt pirmā uzbrukuma laiku. Pēc dažām sesijām mēs iegūsim vidējo laiku, kas būs nepieciešams, lai spēlētājs nākotnē varētu uzbrukt.
Problēma ir arī ar vidējām vērtībām: ja spēlētājs 20 reizes steidzās un 20 reizes spēlēja lēni, tad nepieciešamās vērtības būs kaut kur pa vidu, un tas mums neko noderīgu nedos. Viens no risinājumiem ir ierobežot ievades datus - var ņemt vērā pēdējos 20 gabalus.
Līdzīga pieeja tiek izmantota, novērtējot noteiktu darbību iespējamību, pieņemot, ka spēlētāja pagātnes preferences būs tādas pašas arī nākotnē. Ja spēlētājs mums uzbrūk piecas reizes ar ugunsbumbu, divas reizes ar zibeni un vienreiz ar tuvcīņu, ir skaidrs, ka viņš dod priekšroku ugunsbumbai. Ekstrapolēsim un redzēsim dažādu ieroču izmantošanas varbūtību: ugunsbumba=62,5%, zibens=25% un tuvcīņa=12,5%. Mūsu spēlei AI ir jāsagatavojas, lai pasargātu sevi no uguns.
Vēl viena interesanta metode ir izmantot Naive Bayes klasifikatoru, lai izpētītu lielus ievades datu apjomus un klasificētu situāciju tā, lai AI reaģētu vēlamajā veidā. Bajesa klasifikatori ir vislabāk pazīstami ar to izmantošanu e-pasta surogātpasta filtros. Tur viņi pārbauda vārdus, salīdzina tos ar to, kur šie vārdi ir parādījušies iepriekš (surogātpasta vai nē), un izdara secinājumus par ienākošajiem e-pastiem. Mēs varam darīt to pašu pat ar mazāku ievadi. Pamatojoties uz visu noderīgo informāciju, ko redz AI (piemēram, kādas ienaidnieka vienības ir izveidotas vai kādas burvestības tās izmanto, vai kādas tehnoloģijas viņi pētīja), un gala rezultātu (karš vai miers, steiga vai aizstāvība utt.) - mēs izvēlēsimies vēlamo AI uzvedību.
Visas šīs apmācības metodes ir pietiekamas, taču ir vēlams tās izmantot, pamatojoties uz testēšanas datiem. AI iemācīsies pielāgoties dažādām stratēģijām, kuras ir izmantojuši jūsu spēļu pārbaudītāji. AI, kas pielāgojas atskaņotājam pēc izlaišanas, var kļūt pārāk paredzams vai pārāk grūti uzveicams.
Vērtībās balstīta adaptācija
Ņemot vērā mūsu spēļu pasaules saturu un noteikumus, mēs varam mainīt vērtību kopu, kas ietekmē lēmumu pieņemšanu, nevis vienkārši izmantot ievades datus. Mēs to darām:
- Ļaujiet AI savākt datus par pasaules stāvokli un galvenajiem notikumiem spēles laikā (kā iepriekš).
- Mainīsim dažas svarīgas vērtības, pamatojoties uz šiem datiem.
- Mēs īstenojam savus lēmumus, pamatojoties uz šo vērtību apstrādi vai novērtēšanu.
Piemēram, aģentam ir vairākas telpas, no kurām izvēlēties pirmās personas šāvēja kartē. Katrai telpai ir sava vērtība, kas nosaka, cik vēlams to apmeklēt. AI nejauši izvēlas, uz kuru telpu doties, pamatojoties uz vērtību. Pēc tam aģents atceras, kurā telpā viņš tika nogalināts, un samazina tās vērtību (iespējamību, ka viņš tur atgriezīsies). Līdzīgi arī pretējai situācijai – ja aģents iznīcina daudzus pretiniekus, tad telpas vērtība pieaug.
Markova modelis
Ko darīt, ja mēs izmantotu apkopotos datus, lai veiktu prognozes? Ja mēs noteiktu laiku atcerēsimies katru istabu, kurā redzam spēlētāju, mēs prognozēsim, uz kuru istabu spēlētājs varētu doties. Izsekojot un reģistrējot spēlētāja kustības telpās (vērtības), mēs varam tās paredzēt.
Ņemsim trīs istabas: sarkanu, zaļu un zilu. Un arī novērojumi, ko fiksējām, skatoties spēles sesiju:
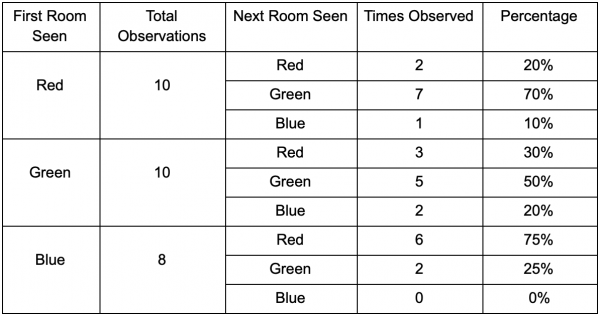
Novērojumu skaits katrā telpā ir gandrīz vienāds - mēs joprojām nezinām, kur izveidot labu vietu slazdam. Statistikas apkopošanu apgrūtina arī spēlētāju atdzimšana, kas vienmērīgi parādās visā kartē. Bet dati par nākamo telpu, kurā viņi ienāk pēc parādīšanās kartē, jau ir noderīgi.
Redzams, ka zaļā istaba spēlētājiem piestāv - no sarkanās istabas uz to pārceļas lielākā daļa cilvēku, no kuriem 50% paliek tur tālāk. Gluži pretēji, zilā istaba nav populāra, uz to gandrīz neviens neiet, un, ja iet, tad ilgi neuzturas.
Taču dati stāsta par kaut ko svarīgāku – kad spēlētājs atrodas zilā istabā, nākamā telpa, kurā mēs viņu redzam, būs sarkana, nevis zaļa. Lai gan zaļā istaba ir populārāka par sarkano istabu, situācija mainās, ja spēlētājs atrodas zilajā istabā. Nākamais stāvoklis (t.i., telpa, uz kuru spēlētājs dosies) ir atkarīgs no iepriekšējā stāvokļa (t.i., telpas, kurā spēlētājs pašlaik atrodas). Tā kā mēs pētām atkarības, mēs veiksim precīzākas prognozes nekā tad, ja mēs vienkārši skaitītu novērojumus neatkarīgi.
Nākotnes stāvokļa prognozēšanu, pamatojoties uz datiem no pagātnes stāvokļa, sauc par Markova modeli, un šādus piemērus (ar telpām) sauc par Markova ķēdēm. Tā kā modeļi atspoguļo izmaiņu iespējamību starp secīgiem stāvokļiem, tie tiek vizuāli parādīti kā FSM ar varbūtību ap katru pāreju. Iepriekš mēs izmantojām MFV, lai attēlotu aģenta uzvedības stāvokli, taču šis jēdziens attiecas uz jebkuru stāvokli neatkarīgi no tā, vai tas ir saistīts ar aģentu vai nē. Šajā gadījumā stāvokļi apzīmē telpu, kuru aģents aizņem:
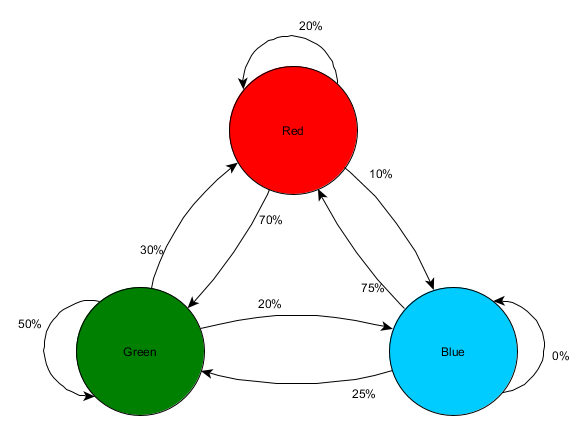
Tas ir vienkāršs veids, kā attēlot relatīvo stāvokļa izmaiņu iespējamību, dodot AI zināmu iespēju paredzēt nākamo stāvokli. Varat paredzēt vairākus soļus uz priekšu.
Ja spēlētājs atrodas zaļajā zālē, pastāv 50% iespēja, ka viņš tur paliks nākamreiz, kad tiks novērots. Bet kāda ir iespēja, ka viņš joprojām būs tur pat pēc tam? Pastāv ne tikai iespēja, ka spēlētājs palika zaļajā istabā pēc diviem novērojumiem, bet arī iespēja, ka viņš aizgāja un atgriezās. Šeit ir jaunā tabula, kurā ņemti vērā jaunie dati:
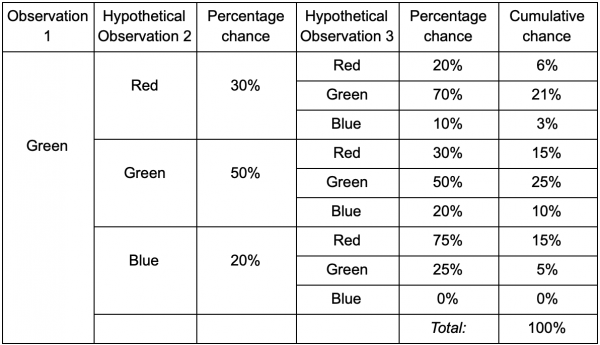
Tas parāda, ka iespēja redzēt spēlētāju zaļajā istabā pēc diviem novērojumiem būs vienāda ar 51% - 21%, ka viņš būs no sarkanās istabas, 5% no tiem, ka spēlētājs apmeklēs zilo istabu starp viņiem, un 25%, ka spēlētājs neatstās zaļo istabu.
Tabula ir vienkārši vizuāls rīks - procedūrai ir nepieciešams tikai reizināt varbūtības katrā solī. Tas nozīmē, ka varat ieskatīties tālā nākotnē ar vienu piebildi: mēs pieņemam, ka iespēja iekļūt telpā ir pilnībā atkarīga no pašreizējās telpas. To sauc par Markova īpašumu – nākotnes stāvoklis ir atkarīgs tikai no tagadnes. Bet tas nav simtprocentīgi precīzs. Spēlētāji var mainīt lēmumus atkarībā no citiem faktoriem: veselības līmeņa vai munīcijas daudzuma. Tā kā mēs šīs vērtības nereģistrējam, mūsu prognozes būs mazāk precīzas.
N-grami
Kā ir ar kaujas spēles piemēru un spēlētāja kombinēto gājienu prognozēšanu? Tas pats! Taču viena stāvokļa vai notikuma vietā mēs pārbaudīsim visas secības, kas veido kombinēto triecienu.
Viens veids, kā to izdarīt, ir saglabāt katru ievadi (piemēram, Kick, Punch vai Block) buferī un ierakstīt visu buferi kā notikumu. Tātad spēlētājs atkārtoti nospiež Kick, Kick, Punch, lai izmantotu SuperDeathFist uzbrukumu, AI sistēma saglabā visus ievades datus buferī un atceras pēdējās trīs, kas izmantotas katrā solī.
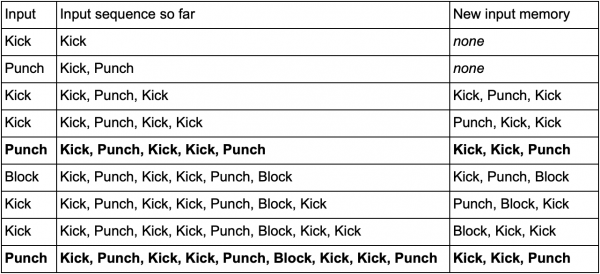
(Treknrakstā norādītās līnijas ir tad, kad spēlētājs uzsāk SuperDeathFist uzbrukumu.)
AI redzēs visas opcijas, kad spēlētājs izvēlēsies Kick, kam sekos vēl viens Kick, un pēc tam ievēros, ka nākamā ievade vienmēr ir Punch. Tas ļaus aģentam paredzēt SuperDeathFist kombinēto kustību un, ja iespējams, to bloķēt.
Šīs notikumu secības sauc par N-gramiem, kur N ir saglabāto elementu skaits. Iepriekšējā piemērā tas bija 3 grami (trigrams), kas nozīmē: pirmie divi ieraksti tiek izmantoti, lai paredzētu trešo. Attiecīgi 5 gramos pirmie četri ieraksti paredz piekto un tā tālāk.
Dizaineram rūpīgi jāizvēlas N-gramu izmērs. Mazākam N ir nepieciešams mazāk atmiņas, taču tajā ir arī mazāk vēstures. Piemēram, 2 grami (bigrami) ierakstīs Kick, Kick vai Kick, Punch, bet nevarēs saglabāt Kick, Kick, Punch, tāpēc AI nereaģēs uz SuperDeathFist kombināciju.
No otras puses, lielākam skaitam ir nepieciešams vairāk atmiņas, un AI būs grūtāk apmācīt, jo būs daudz vairāk iespēju. Ja jums būtu trīs iespējamie Kick, Punch vai Block ievades veidi, un mēs izmantotu 10 gramus, tas būtu aptuveni 60 tūkstoši dažādu iespēju.
Bigramu modelis ir vienkārša Markova ķēde — katrs pagātnes stāvokļa/pašreizējā stāvokļa pāris ir bigrams, un jūs varat paredzēt otro stāvokli, pamatojoties uz pirmo. 3 gramus un lielākus N gramus var uzskatīt arī par Markova ķēdēm, kur visi elementi (izņemot pēdējo N gramā) kopā veido pirmo stāvokli, bet pēdējais elements – otro. Cīņas spēles piemērs parāda iespēju pāriet no Kick and Kick stāvokļa uz Kick and Punch stāvokli. Apstrādājot vairākus ievades vēstures ierakstus kā vienu vienību, mēs būtībā pārveidojam ievades secību par daļu no visa stāvokļa. Tas dod mums Markova īpašību, kas ļauj mums izmantot Markova ķēdes, lai paredzētu nākamo ievadi un uzminētu, kāda būs nākamā kombinācija.
Secinājums
Mēs runājām par izplatītākajiem instrumentiem un pieejām mākslīgā intelekta attīstībā. Apskatījām arī situācijas, kurās tās jāizmanto un kur tās ir īpaši noderīgas.
Ar to vajadzētu pietikt, lai saprastu spēles AI pamatus. Bet, protams, šīs nav visas metodes. Mazāk populāri, bet ne mazāk efektīvi ietver:
- optimizācijas algoritmi, tostarp kāpšana kalnos, nolaišanās no slīpuma un ģenētiskie algoritmi
- pretrunīgie meklēšanas/plānošanas algoritmi (minimax un alfa-beta atzarošana)
- klasifikācijas metodes (perceptrons, neironu tīkli un atbalsta vektora mašīnas)
- sistēmas aģentu uztveres un atmiņas apstrādei
- arhitektūras pieejas AI (hibrīdsistēmas, apakškopu arhitektūras un citi veidi, kā AI sistēmas pārklāt)
- animācijas rīki (plānošana un kustību koordinācija)
- veiktspējas faktori (detalizācijas līmenis, jebkurā laikā un laika sadalījuma algoritmi)
Tiešsaistes resursi par šo tēmu:
1. GameDev.net ir un .
2. satur daudzas prezentācijas un rakstus par dažādām tēmām, kas saistītas ar spēļu AI izstrādi.
3. ietver tēmas no GDC AI samita, no kurām daudzas ir pieejamas bez maksas.
4. Mājaslapā var atrast arī noderīgus materiālus .
5. Tomijs Tompsons, mākslīgā intelekta pētnieks un spēļu izstrādātājs, veido videoklipus vietnē YouTube ar skaidrojumu un AI izpēti komerciālajās spēlēs.
Grāmatas par šo tēmu:
1. Game AI Pro grāmatu sērija ir īsu rakstu krājums, kurā ir paskaidrots, kā ieviest konkrētas funkcijas vai kā atrisināt konkrētas problēmas.
2. AI Game Programming Wisdom sērija ir Game AI Pro sērijas priekštecis. Tajā ir senākas metodes, taču gandrīz visas ir aktuālas arī mūsdienās.
3. ir viens no pamattekstiem ikvienam, kurš vēlas izprast vispārējo mākslīgā intelekta jomu. Šī nav grāmata par spēļu izstrādi – tā māca AI pamatus.
Avots: www.habr.com
