

Оваа статија е превод на мојата статија за медиум - , кој се покажа како доста популарен, веројатно поради неговата едноставност. Затоа, решив да го напишам на руски и да додадам малку за да му биде јасно на обичниот човек кој не е специјалист за податоци што е складиште за податоци (DW), а што е езеро на податоци (Езеро на податоци) и како тие се заедно заедно.
Зошто сакав да пишувам за езерото на податоци? Работам со податоци и аналитика повеќе од 10 години, а сега дефинитивно работам со големи податоци во Amazon Alexa AI во Кембриџ, кој е во Бостон, иако живеам во Викторија на островот Ванкувер и често го посетувам Бостон, Сиетл , и во Ванкувер, а понекогаш дури и во Москва, зборувам на конференции. И јас пишувам одвреме-навреме, но главно пишувам на англиски и веќе пишував , исто така имам потреба да ги споделам аналитичките трендови од Северна Америка и понекогаш пишувам .
Отсекогаш сум работел со складишта на податоци, а од 2015 година почнав тесно да соработувам со веб-услугите на Амазон и генерално се префрлив на облак аналитика (AWS, Azure, GCP). Ја набљудував еволуцијата на аналитичките решенија од 2007 година, па дури работев за продавачот на складиште на податоци Teradata и го имплементирав во Сбербанк, и тогаш се појавија Big Data with Hadoop. Сите почнаа да кажуваат дека ерата на складирање помина и сега сè е на Hadoop, а потоа почнаа да зборуваат за Data Lake, повторно, дека сега дефинитивно дојде крајот на складиштето на податоци. Но, за среќа (можеби за жал на некои кои заработија многу пари поставувајќи го Hadoop), складиштето на податоци не исчезна.
Во оваа статија ќе погледнеме што е податочно езеро. Оваа статија е наменета за луѓе кои имаат мало или никакво искуство со складишта на податоци.

На сликата е езерото Блед, ова е едно од моите омилени езера, иако бев само еднаш, се сеќавав на него до крајот на мојот живот. Но, ќе зборуваме за друг вид на езеро - дата езеро. Можеби многумина од вас веќе слушнале за овој термин повеќе од еднаш, но уште една дефиниција нема да му наштети на никого.
Како прво, еве ги најпопуларните дефиниции за езерото на податоци:
„Складирање датотеки на сите видови необработени податоци што се достапни за анализа од кој било во организацијата“ - Мартин Фаулер.
„Доколку мислите дека податочното езеро е шише вода - прочистена, спакувана и спакувана за удобна потрошувачка, тогаш податочното езеро е огромен резервоар на вода во неговата природна форма. Корисници, можам да соберам вода за себе, да нуркам длабоко, да истражувам“ - Џејмс Диксон.
Сега знаеме со сигурност дека езерото на податоци е за аналитика, ни овозможува да складираме големи количини на податоци во неговата оригинална форма и го имаме потребниот и удобен пристап до податоците.
Често сакам да ги поедноставувам работите. Ако можам да објаснам сложен термин со едноставни зборови, тоа значи дека сум разбрал како функционира и за што служи. Еднаш, пребарував наоколу iPhone во фото галеријата, и ми светна дека ова е вистинско езеро на податоци, дури направив и слајд за конференции:
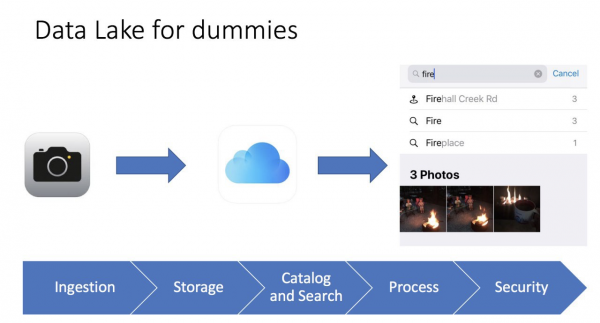
Многу е едноставно. Фотографијата ја правиме на телефонот, фотографијата се зачувува на телефонот и може да се зачува во iCloud (услуга за складирање датотеки во облак). Телефонот, исто така, ги собира метаподатоците на фотографијата: што има на фотографијата, гео-ознаката и времето. Како резултат на тоа, можеме да користиме лесен интерфејс. iPhoneЗа да ја пронајдеме нашата фотографија, дури и ги гледаме метриките. На пример, кога пребарувам фотографии со зборот „оган“, наоѓам три фотографии од логорски оган. За мене, тоа е како алатка за деловна интелигенција што работи многу брзо и ефикасно.
И секако, не смееме да заборавиме на безбедноста (овластување и автентикација), инаку нашите податоци лесно може да завршат во јавниот домен. Има многу вести за големите корпорации и стартапи чии податоци станаа јавно достапни поради невнимание на програмерите и непочитување едноставни правила.
Дури и таква едноставна слика ни помага да замислиме што е езеро со податоци, неговите разлики од традиционалниот складиште на податоци и неговите главни елементи:
- Се вчитуваат податоци (Голтање) е клучна компонента на езерото со податоци. Податоците можат да влезат во складиштето на податоци на два начина - серија (вчитување во интервали) и стриминг (проток на податоци).
- Складирање на датотеки (Складирање) е главната компонента на Езерото на податоци. Ни требаше складирањето да биде лесно приспособливо, исклучително доверливо и ниска цена. На пример, во AWS тоа е S3.
- Каталог и пребарување (Каталог и пребарување) - за да го избегнеме Data Swamp (ова е кога ги фрламе сите податоци во еден куп, а потоа е невозможно да се работи со нив), треба да создадеме слој на метаподатоци за да ги класифицираме податоците за да можат корисниците лесно да ги најдат податоците кои им се потребни за анализа. Дополнително, можете да користите дополнителни решенија за пребарување, како што е ElasticSearch. Пребарувањето му помага на корисникот да ги најде потребните податоци преку кориснички интерфејс.
- Обработка (Процес) - овој чекор е одговорен за обработка и трансформирање на податоците. Можеме да ги трансформираме податоците, да ја промениме нивната структура, да ги исчистиме и многу повеќе.
- безбедност (Безбедност) - Важно е да потрошите време на безбедносниот дизајн на решението. На пример, шифрирање на податоци за време на складирање, обработка и вчитување. Важно е да се користат методи за автентикација и авторизација. Конечно, потребна е алатка за ревизија.
Од практична гледна точка, можеме да го карактеризираме езерото на податоци со три атрибути:
- Соберете и складирајте што било — езерото со податоци ги содржи сите податоци, и сурови необработени податоци за кој било временски период и обработени/исчистени податоци.
- Длабоко скенирање — езерото со податоци им овозможува на корисниците да истражуваат и анализираат податоци.
- Флексибилен пристап — Езерото на податоци обезбедува флексибилен пристап за различни податоци и различни сценарија.
Сега можеме да зборуваме за разликата помеѓу складиште на податоци и езеро со податоци. Обично луѓето прашуваат:
- Што е со складиштето на податоци?
- Дали складиштето на податоци го заменуваме со езеро на податоци или го прошируваме?
- Дали е сè уште можно да се направи без езеро со податоци?
Накратко, нема јасен одговор. Се зависи од конкретната ситуација, вештините на тимот и буџетот. На пример, мигрирање на складиште на податоци во Oracle на AWS и создавање езеро со податоци од подружница на Amazon - Woot - .
Од друга страна, продавачот Snowflake вели дека повеќе не треба да размислувате за езеро со податоци, бидејќи нивната платформа за податоци (до 2020 година беше складиште на податоци) ви овозможува да комбинирате и езеро со податоци и складиште на податоци. Не сум работел многу со Snowflake, и тоа е навистина уникатен производ што може да го направи тоа. Цената на прашањето е друга работа.
Како заклучок, мое лично мислење е дека сè уште ни треба складиште на податоци како главен извор на податоци за нашето известување, а што и да не одговара, го складираме во езерото со податоци. Целата улога на аналитиката е да обезбеди лесен пристап за бизнисот да донесува одлуки. Што и да се каже, деловните корисници работат поефикасно со складиште на податоци отколку со езеро на податоци, на пример во Амазон - постои Redshift (магацин за аналитички податоци) и има Redshift Spectrum/Athena (SQL интерфејс за езеро со податоци во S3 базиран на Кошница/Престо). Истото важи и за други модерни складишта за аналитички податоци.
Ајде да погледнеме во типична архитектура на складиште за податоци:
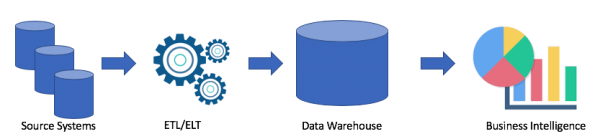
Ова е класично решение. Имаме изворни системи, користејќи ETL/ELT ги копираме податоците во складиште за аналитички податоци и ги поврзуваме со решение за деловна интелигенција (мој омилен е Tableau, што е со твоето?).
Ова решение ги има следните недостатоци:
- ETL/ELT операциите бараат време и ресурси.
- Како по правило, меморијата за складирање податоци во складиште за аналитички податоци не е евтина (на пример, Redshift, BigQuery, Teradata), бидејќи треба да купиме цел кластер.
- Деловните корисници имаат пристап до исчистени и често собрани податоци и немаат пристап до необработени податоци.
Се разбира, се зависи од вашиот случај. Ако немате проблеми со складиштето на податоци, тогаш воопшто не ви треба езеро со податоци. Но, кога ќе се појават проблеми со недостаток на простор, моќ или цена игра клучна улога, тогаш можете да ја разгледате опцијата за езеро со податоци. Ова е причината зошто езерото на податоци е многу популарно. Еве пример за езерска архитектура на податоци:
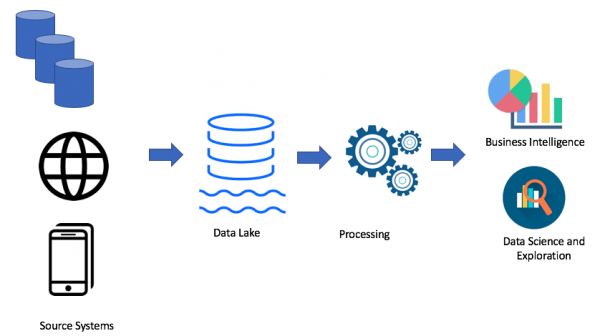
Користејќи го пристапот на езерото на податоци, вчитуваме необработени податоци во нашето езеро со податоци (серија или стриминг), потоа ги обработуваме податоците по потреба. Езерото на податоци им овозможува на деловните корисници да креираат свои трансформации на податоци (ETL/ELT) или да ги анализираат податоците во решенијата за деловна интелигенција (доколку е достапен потребниот двигател).
Целта на секое аналитичко решение е да им служи на деловните корисници. Затоа, секогаш мора да работиме според деловните барања. (Во Амазон ова е еден од принципите - работа наназад).
Работејќи и со складиште за податоци и со езеро со податоци, можеме да ги споредиме двете решенија:
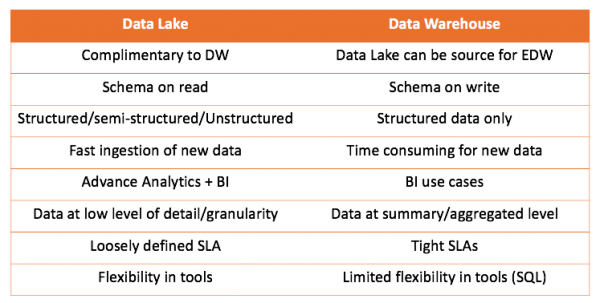
Главниот заклучок што може да се извлече е дека складиштето на податоци не му конкурира на езерото со податоци, туку го надополнува. Но, зависи од вас да одлучите што е правилно за вашиот случај. Секогаш е интересно да се обидете сами и да ги извлечете вистинските заклучоци.
Исто така, би сакал да ви кажам еден од случаите кога почнав да го користам пристапот на податочно езеро. Сè е сосема тривијално, се обидов да користам алатка ELT (имавме Matillion ETL) и Amazon Redshift, моето решение работеше, но не одговараше на барањата.
Ми требаше да земам веб-дневници, да ги трансформирам и да ги соберам за да дадам податоци за 2 случаи:
- Маркетинг тимот сакаше да ја анализира активноста на бот за оптимизација
- ИТ сакаше да ги разгледа показателите за перформансите на веб-страниците
Многу едноставни, многу едноставни логови. Еве еден пример:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Една датотека тежеше 1-4 мегабајти.
Но, имаше една тешкотија. Имавме 7 домени низ светот, а во еден ден беа креирани 7000 илјади датотеки. Ова не е многу поголем волумен, само 50 гигабајти. Но, големината на нашиот кластер Redshift беше исто така мала (4 јазли). Вчитувањето на една датотека на традиционален начин траеше околу една минута. Односно, проблемот не беше решен директно. И ова беше случај кога решив да го користам пристапот на податоци езеро. Решението изгледаше отприлика вака:
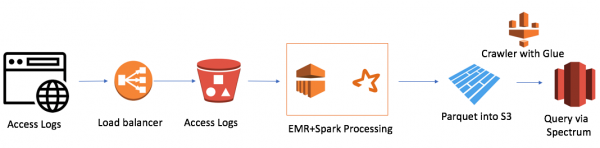
Тоа е прилично едноставно (Сакам да забележам дека предноста на работата во облакот е едноставноста). Јас користев:
- AWS Elastic Map Reduce (Hadoop) за пресметувачка моќност
- AWS S3 како складирање на датотеки со можност за шифрирање податоци и ограничување на пристапот
- Spark како InMemory компјутерска моќ и PySpark за логика и трансформација на податоци
- Паркет како резултат на Spark
- AWS Glue Crawler како собирач на метаподатоци за нови податоци и партиции
- Redshift Spectrum како SQL интерфејс до езерото со податоци за постоечките корисници на Redshift
Најмалиот кластер EMR+Spark го обработи целиот куп датотеки за 30 минути. Има и други случаи за AWS, особено многу поврзани со Alexa, каде што има многу податоци.
Неодамна дознав дека една од недостатоците на езерото со податоци е GDPR. Проблемот е кога клиентот бара да го избрише и податоците се во една од датотеките, не можеме да користиме Јазик за манипулација со податоци и операцијата DELETE како во базата на податоци.
Се надевам дека овој напис ја разјасни разликата помеѓу складиште на податоци и езеро со податоци. Ако сте заинтересирани, можам да преведам повеќе од моите статии или статии од професионалци што ги прочитав. Кажете и за решенијата со кои работам и нивната архитектура.
Извор: www.habr.com
