

Принципот на несигурност на Хајзенберг вели дека не можете да ја измерите положбата на објектот и неговата брзина во исто време. Ако некој предмет се движи, тогаш тој нема локација. И ако има локација, тоа значи дека нема брзина.

Што се однесува до микросервисите на платформата Red Hat OpenShift (и работи на Kubernetes), благодарение на соодветниот софтвер со отворен код, тие можат истовремено да ги пријават и нивните перформанси и здравје. Ова, се разбира, не го побива стариот Хајзенберг, но ја елиминира неизвесноста при работа со облак апликации. Istio го олеснува следењето и следењето на овие апликации за да се држи сè под контрола.
Одлучување за терминологија
Под трасирање (Следење) разбираме евидентирање на системската активност. Ова звучи прилично општо, но всушност едно од основните правила овде е да се исфрлат податоците за трага во соодветно складирање без да се грижите за форматирање. И целата работа за пребарување и анализа на податоци е на потрошувачот. Istio го користи системот за следење Jaeger, кој го имплементира моделот на податоци OpenTracing.
На патеките (Траги, а зборот „траги“ овде се користи во смисла на „траги“, како на пример, при балистичко испитување) ќе ги наречеме податоците што целосно го опишуваат преминувањето на барање или единица на работа, како што велат, „од и до“. На пример, сè што се случува од моментот кога корисникот ќе кликне на копче на веб-страница додека податоците не се вратат, вклучувајќи ги и сите вклучени микроуслуги. Можеме да кажеме дека една трага целосно го опишува (или моделира) кружното патување на барањето. Во интерфејсот на Јегер, трагите се разложуваат на компоненти по должината на временската оска, слично на тоа како синџирот може да се разложи на поединечни врски. Само наместо врски, патеката се состои од таканаречени распони.
Век е интервалот од почетокот на единицата на работа до нејзиното завршување. Продолжувајќи ја аналогијата, можеме да кажеме дека секој распон претставува посебна алка во синџирот. Распон може (или не) да има еден или повеќе распони за деца. Како последица на тоа, највисокиот распон (распон на коренот) ќе има исто вкупно времетраење како и трагата на која и припаѓа.
Мониторинг - ова е, всушност, самото набљудување на вашиот систем - со вашите очи, преку интерфејсот или алатките за автоматизација. Мониторингот се заснова на податоци за трага. Во Истио, мониторингот се спроведува со помош на Prometheus и има соодветен UI. Prometheus поддржува автоматско следење со помош на Alerts и Alert Managers.
Оставаме траги
За да може следењето да биде возможно, апликацијата мора да создаде колекција од распони. Потоа тие треба да се извезат во Јегер, за тој за возврат да создаде визуелна претстава на трагата. Меѓу другото, овие распони го означуваат името на операцијата, како и нејзините временски ознаки за почеток и крај. Преносот на распони се постигнува со препраќање на заглавија на барања за HTTP специфични за Jaeger од дојдовни барања до појдовни барања. Во зависност од употребениот програмски јазик, ова може да бара мали измени на изворниот код на апликацијата. Подолу е примерок од кодот во Java (со користење на рамката Spring Boot) кој додава заглавија B3 (стил Zipkin) на вашето барање во класата за конфигурација Spring:

Се користат следните поставки за заглавие:
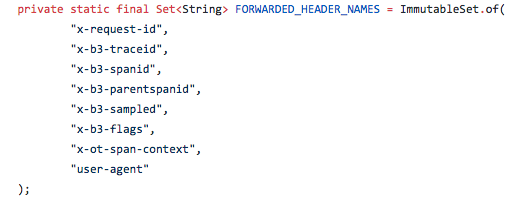
Ако користите Java, тогаш можете да го оставите кодот сам и само да додадете неколку линии во датотеката Maven POM и да ги поставите променливите на околината. Еве ги линиите што треба да ги додадете во вашата датотека POM.XML за да го имплементирате Jaeger Tracer Resolver:

И соодветните променливи на околината се поставени во Dockerfile:

Тоа е сè, сега сè е конфигурирано и нашите микросервиси ќе почнат да генерираат податоци за трага.
Ајде да погледнеме во општи рамки
Istio вклучува едноставна контролна табла базирана на Grafana. Откако сè е конфигурирано и работи на платформата Red Hat OpenShift PaaS (во нашиот пример, Red Hat OpenShift и Kubernetes се распоредени на minishift), овој панел се стартува со следнава команда:
open "$(minishift openshift service grafana -u)/d/1/istio-dashboard?refresh=5⩝Id=1"
Панелот Grafana ви овозможува брзо да ги оцените перформансите на системот. Фрагмент од овој панел е прикажан на сликата подолу:
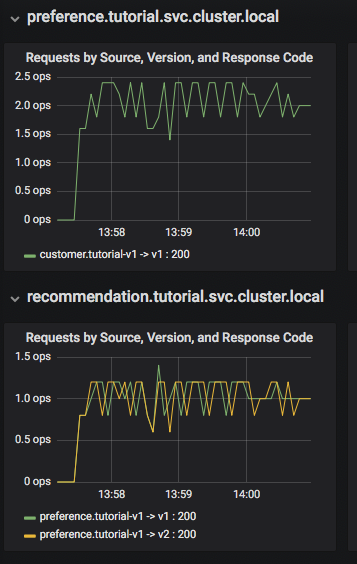
Овде можете да видите дека микросервисот на клиентите ја нарекува претпочитање V1 микросервис, што пак ја нарекува препораката V1 и V2 микро услугите. Панелот Grafana има блок на табла за метрика на високо ниво, како што е вкупниот број на барања (глобален волумен на барање), стапки на успех, грешки од 4xx. Покрај тоа, постои преглед на серверска мрежа со графикони за секоја услуга и блок на редови за услуги за прегледување детални информации за секој контејнер за секоја услуга.
Сега ајде да копаме подлабоко
Со правилно конфигурирано следење, Istio, како што велат, веднаш надвор од кутијата ви овозможува да навлезете подлабоко во анализата на перформансите на системот. Во корисничкиот интерфејс на Jaeger, можете да ги прегледате трагите и да видите колку далеку и длабоко одат, како и визуелно да ги локализирате тесните грла на перформансите. Кога користите Red Hat OpenShift на платформата minishift, стартувајте го Jaeger UI со следнава команда:
minishift openshift service jaeger-query --in-browser
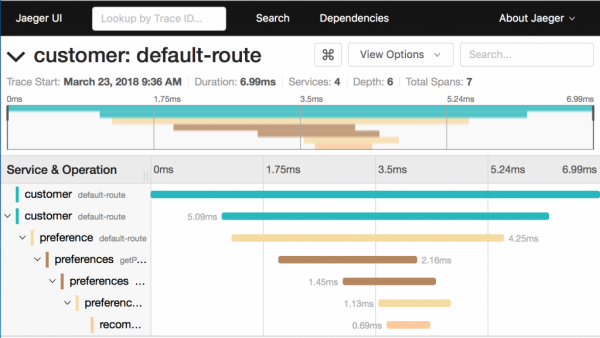
Што можете да кажете за следењето на овој екран:
- Поделен е на 7 распони.
- Вкупното време на извршување е 6.99 ms.
- Препораката микросервис, која е последна во синџирот, троши 0.69 ms.
Дијаграмите од овој тип ви овозможуваат брзо да ја разберете ситуацијата кога, поради една лошо функционална услуга, перформансите на целиот систем страдаат.
Сега да ја комплицираме задачата и да стартуваме два примери на препораката: v2 microservice со командата oc скала — replicas=2 распоредување/препорака-v2. Еве ги мешунките што ќе ги имаме после ова:
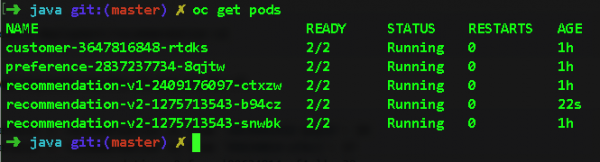
Ако сега се вратиме назад на Jaeger и го прошириме распонот за услугата за препораки, можеме да видиме до кој подлога се упатени барањата. Така, лесно можеме да ги локализираме сопирачките на ниво на одредена мешунка. Во овој случај, треба да го погледнете полето node_id:

Каде и како оди се
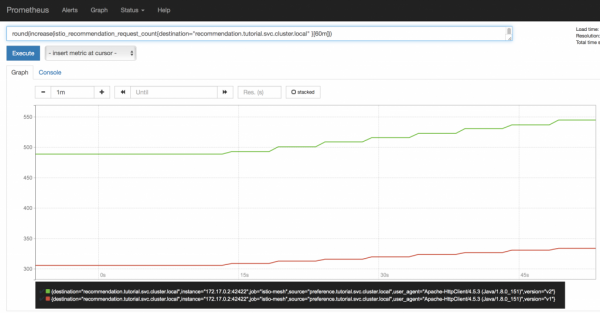
Сега одиме на интерфејсот Prometheus и сосема очекувано гледаме дека барањата помеѓу втората и првата верзија на услугата за препораки се поделени во сооднос 2:1, строго според бројот на работни подлоги. Покрај тоа, овој график ќе се менува динамично како што се зголемуваат и намалуваат мешунките, што ќе биде особено корисно за Canary Deployment (ќе ја разгледаме подетално оваа шема за распоредување следниот пат).
Само што почнува
Всушност, денес, како што велат, само ја изгребавме површината на богатството корисни информации за Јегер, Графана и Прометеј. Генерално, ова беше нашата цел - да ве упатиме во вистинската насока и да ги отвориме перспективите за Истио.
И запомнете, сето ова е веќе вградено во Истио. Кога користите одредени јазици за програмирање (на пример, Java) и рамки (на пример, пролетно подигање), сето ова може да се спроведе без воопшто да се допира самиот код за апликација. Да, кодот ќе мора малку да се измени ако користите други јазици, првенствено значи Nodejs или C#. Но, бидејќи следливоста (прочитајте: „Трагање“) е еден од предусловите за создавање на сигурни системи за облак, ќе мора да го уредувате кодот во секој случај, без разлика дали имате Истио или не. Па зошто да не ги вложите вашите напори за подобро искористување?
Барем за секогаш да одговарате на прашањата „каде?“ и „колку брзо?“ со 100% сигурност.
Хаос инженеринг во Истио: така беше наменето
Способноста да се скршат нештата помага да се спречи нивното кршење.
Тестирањето на софтверот не е само тешко, туку е и важно. Во исто време, тестирањето за исправност (на пример, дали функцијата го враќа точниот резултат) е една работа, но тестирањето во несигурна мрежа е сосема друга задача (често се претпоставува дека мрежата секогаш работи без неуспеси, и ова е првата од осумте заблуди за дистрибуираните пресметки). Една од потешкотиите во решавањето на овој проблем е како да се симулираат дефекти во системот или да се воведат намерно, изведувајќи таканаречено вбризгување на дефекти. Ова може да се направи со менување на изворниот код на самата апликација. Но, тогаш веќе нема да го тестирате вашиот оригинален код, туку негова верзија која конкретно симулира неуспеси. Како резултат на тоа, ризикувате да паднете во смртоносната прегратка на инјектирање на дефекти и да наидете на Heisenbugs - неуспеси кои исчезнуваат кога ќе се обидете да ги откриете.
Сега ќе ви покажеме како Istio ви помага да се справите со овие сложености во едно парче.
Како изгледа сè кога се е супер?
Разгледајте го следново сценарио: имаме две подлоги за нашата микросервис за препорака, кои ги презедовме од упатството за Istio. Едниот дел е означен со v1, а другиот е означен со v2. Како што можете да видите, сè работи добро досега:
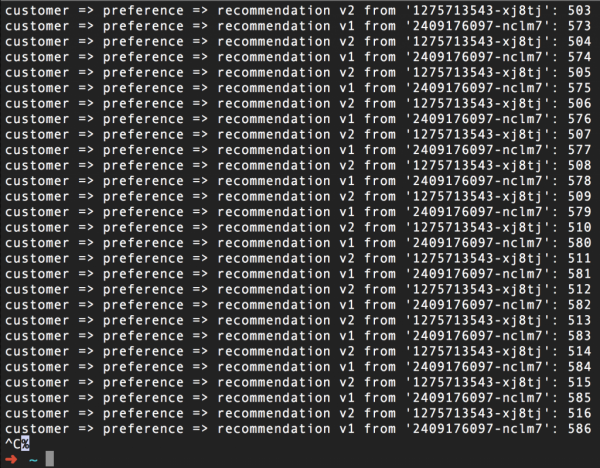
(Патем, бројот од десната страна е само бројач за повици за секој дел)
Но, тоа не е она што ни треба, нели? Па, ајде да се обидеме да скршиме сè без воопшто да го допираме изворниот код.
Договараме прекини во работата на микросервисот
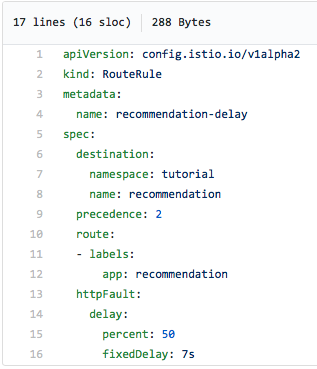
Подолу е прикажана yaml датотеката за правило за рутирање на Istio кое ќе не успее (грешка) половина од времето. сервер 503):
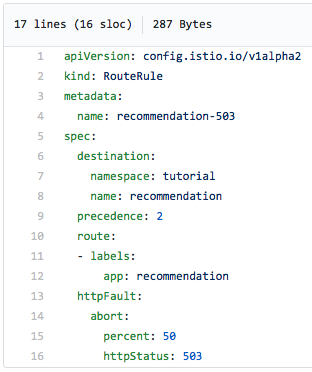
Ве молиме имајте предвид дека експлицитно наведуваме дека грешката 503 треба да се врати во половина од случаите.
И еве како ќе изгледа скриншот од командата curl што се извршува во јамка откако ќе го активираме ова правило за да симулираме неуспеси. Како што можете да видите, половина од барањата враќаат грешка 503, без оглед на кој pod – v1 или v2 – тие одат:
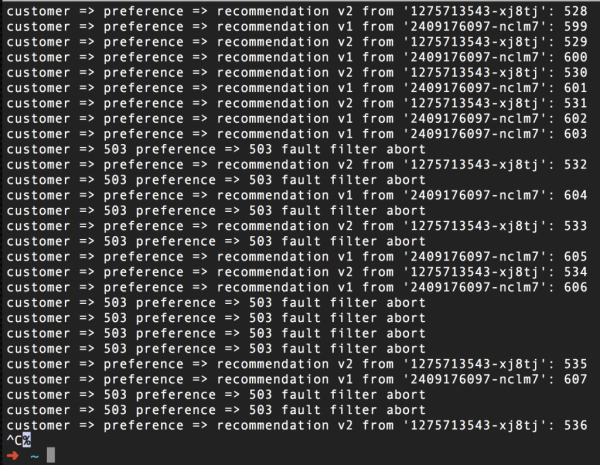
За да ја вратите нормалната работа, доволно е да го избришете ова правило, во нашиот случај со командата istioctl delete routerule recommendation-503 -n tutorial. Овде, Tutorial е името на проектот Red Hat OpenShift што го води нашето упатство за Istio.
Воведување вештачки одложувања
Лажните грешки 503 помагаат да се тестира отпорноста на системот на неуспех, но способноста за предвидување и справување со одложувањата треба да ве импресионира уште повеќе. И одложувањата во реалниот живот се случуваат почесто од неуспесите. Бавниот микросервис е отров што влијае на целиот систем. Со Istio, можете да го тестирате вашиот код поврзан со доцнење без да го менувате на кој било начин. Прво, ќе покажеме како да го направите ова во случај на вештачки воведени доцнења на мрежата.
Ве молиме имајте предвид дека по тестирањето на овој начин, можеби ќе треба (или сакате) да го измените вашиот код. Добрата вест овде е дека во овој случај ќе бидете проактивни наместо реактивни. Токму вака треба да се структурира развојниот циклус: кодирање-тестирање-повратна информација-кодирање-тестирање...
Вака изгледа правилото... Иако знаете што? Istio е толку едноставен и оваа yaml-датотека е толку јасна што сè во овој пример зборува само за себе, само погледнете:
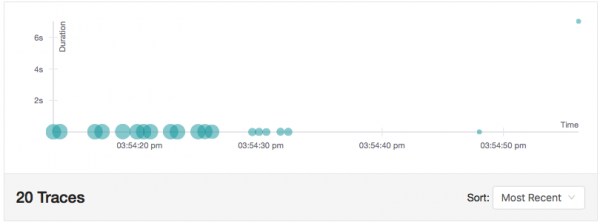
Половина од времето ќе доживееме доцнење од 7 секунди. И ова воопшто не е исто како да сме вметнале команда за спиење во изворниот код, бидејќи Istio всушност го одложува барањето за 7 секунди. Бидејќи Istio поддржува следење на Jaeger, ова одложување е забележливо во интерфејсот на Jaeger, како што е прикажано на сликата од екранот подолу. Обрнете внимание на долгото барање во горниот десен агол на дијаграмот - неговото времетраење е 7.02 секунди:
Оваа скрипта ви овозможува да го тестирате вашиот код во услови на латентност на мрежата. И јасно е дека со отстранување на ова правило, ќе го отстраниме вештачкото одложување. Повторуваме, но повторно го направивме сето ова без да го допреме изворниот код на кој било начин.
Не се повлекувајте и не се откажувајте
Друга корисна карактеристика на Istio за хаос инженеринг е повторените повици до услугата одреден број пати. Поентата овде е да продолжиме да се обидуваме кога првото барање ќе заврши со грешка 503 - и тогаш можеби N-единаесеттиот пат ќе имаме среќа. Можеби услугата само се прекина некое време поради една или друга причина. Да, оваа причина треба да се ископа и елиминира. Но, тоа ќе дојде подоцна, но засега ќе се обидеме да се погрижиме системот да продолжи да работи.
Значи, сакаме услугата одвреме-навреме да исфрла грешка 503, а потоа Истио ќе се обиде повторно да го контактира. И тука јасно ни треба начин да генерираме грешка 503 без да го допираме самиот код...
Застани, чекај! Ние само го направивме тоа.
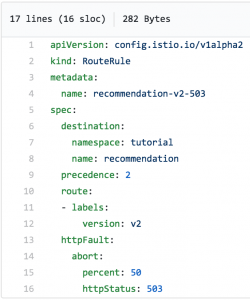
Оваа датотека ќе го направи тоа така што услугата препораки-v2 ќе издава грешка 503 половина од времето:
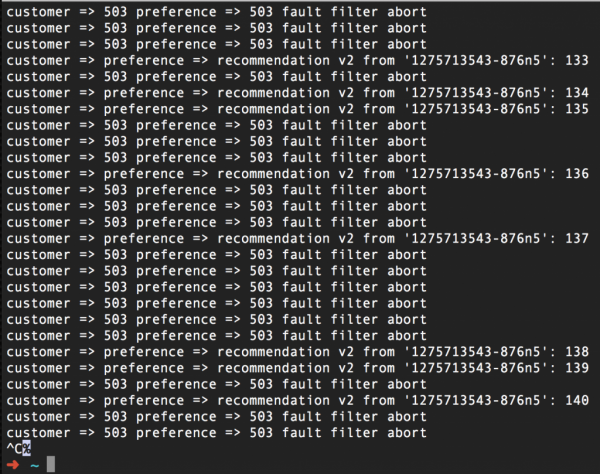
Очигледно, некои барања нема да успеат:
Сега да ја користиме функцијата Istio Retry:
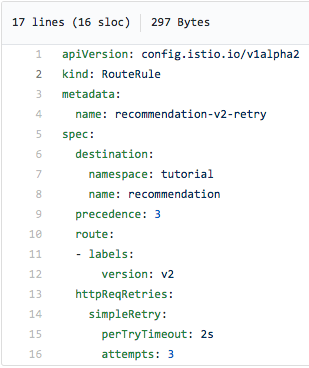
Ова правило за рутирање се повторува три пати во интервали од две секунди и треба да ги намали (и идеално да ги отстрани од радарот) грешките 503:
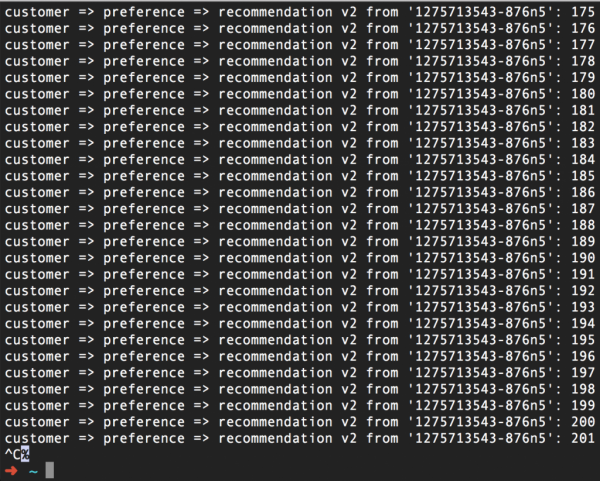
Да резимираме: направивме така што Istio, прво, генерира грешка 503 за половина од барањата. И второ, истиот Istio прави три обиди повторно да стапи во контакт со сервисот кога ќе се појави грешка 503. Како резултат на тоа, сè работи добро. Така, со користење на функцијата Обиди се повторно, го исполнивме нашето ветување дека нема да се откажеме и да не се откажеме.
И да, го направивме тоа повторно без воопшто да го допреме кодот. Сè што ни требаа беа две правила за рутирање на Istio:

Како да не го изневерите корисникот или седум не очекувајте еден
Сега да ја свртиме ситуацијата и да разгледаме сценарио каде единственото нешто што треба да направите е да не се повлечете или да не се откажете одредено време. И тогаш само треба да престанете да се обидувате да го обработите барањето, за да не ги принудите сите да чекаат една бавна услуга. Со други зборови, ние нема да браниме изгубена позиција, туку ќе се повлечеме во резервна линија за да не го изневериме корисникот на страницата и да не го принудиме да паѓа во незнаење.
Во Istio, можете да поставите истек на извршување на барањето. Ако услугата го надмине овој истек на време, се враќа грешка 504 (Gateway Timeout) - повторно, сето тоа е направено преку конфигурацијата Istio. Но, ќе мора да додадеме команда за спиење во изворниот код на услугата (а потоа, се разбира, да извршиме обнова и прераспределување) за да симулираме бавно работење на услугата. За жал, нема да работи на друг начин.
Така, вметнавме мирување од три секунди во кодот на услугата за препорака v2, ја реконструиравме соодветната слика и повторно го распоредивме контејнерот, а сега ќе додадеме истек на време користејќи го следното правило за рутирање на Istio:
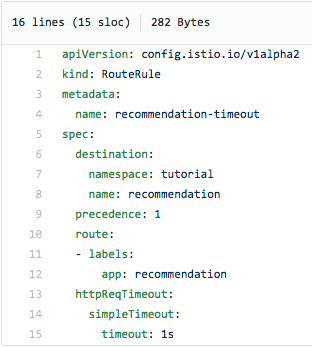
На сликата од екранот погоре можете да видите дека се откажуваме од обидот да контактираме со услугата за препораки ако не добиеме одговор во рок од една секунда, односно пред да се појави грешката 504. Откако ќе го примените ова правило за рутирање (и ќе додадеме спиење од три секунди до кодот на услугата за препораки :v2), го добиваме ова:
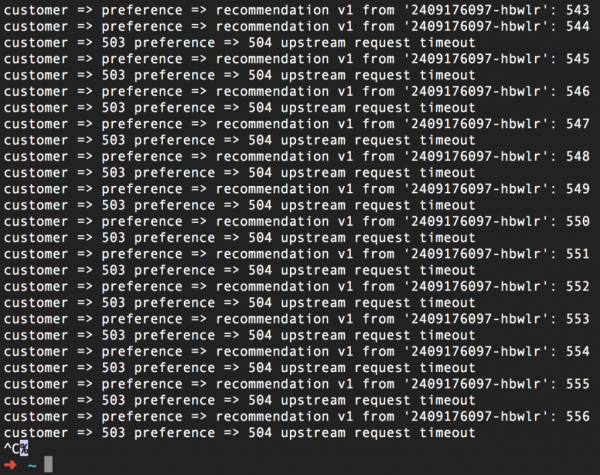
Повторуваме повторно, но тајмаутот може да се постави без да се допира изворниот код на кој било начин. Дополнителен бонус овде е тоа што сега можете да го менувате вашиот код за да одговорите на истекот на времето и лесно да ги тестирате овие модификации користејќи Istio.
И сега се е заедно
Инјектирањето на мал хаос со Istio е одличен начин да го тестирате вашиот код и доверливоста на вашиот систем како целина. Резервните шаблони, преградите и прекинувачите, механизмите за создавање вештачки неуспеси и одложувања, како и повторно обиди за повици и истекувања ќе бидат многу корисни при креирање облак системи толерантни за грешки. Во комбинација со Kubernetes и Red Hat OpenShift, овие алатки ќе ви помогнат да се соочите со иднината со доверба.
Извор: www.habr.com
