

Hallo alle sammen. Nedenfor er transkripsjonen. .
– et system for overvåking av ulike systemer og tjenester, som systemadministratorer kan bruke til å samle inn informasjon om gjeldende systemparametere og sette opp varsler for å motta varsler om avvik i systemenes drift.
Rapporten vil inneholde en sammenligning и — prosjekter for langtidslagring av Prometheus-målinger.



Først skal jeg fortelle deg om Prometheus. Det er et overvåkingssystem som samler inn målinger fra spesifiserte mål og lagrer dem lokalt. Prometheus kan registrere målinger til ekstern lagring, generere varsler og registrere regler.

Prometheus-begrensninger:
- Den har ikke en global spørrevisning. Dette er når du har flere uavhengige Prometheus-instanser. De samler inn målinger. Og du vil spørre over alle disse målingene som er samlet inn fra forskjellige Prometheus-instanser. Prometheus tillater ikke det.
- Prometheus er begrenset til én enkelt server. Prometheus kan ikke skaleres automatisk til flere servere. Du kan bare dele målene dine manuelt mellom flere Prometheus-er.
- Målevolumet i Prometheus er begrenset til bare én server av samme grunn som det ikke kan skaleres automatisk på tvers av flere servere.
- Prometheus er ikke et enkelt sted å organisere datasikkerhet.

Løsninger på disse problemene/oppgavene?
Løsningene er:
Alle disse løsningene er for fjernlagring av data samlet inn av Prometheus. De løser problemet med fjernlagring fra forrige lysbilde på forskjellige måter. I denne presentasjonen vil jeg bare snakke om de to første løsningene: и .
For første gang informasjon om dukket opp på Arkitekturen er beskrevet der. og hvordan det fungerer.

Thanos tar dataene som Prometheus har lagret på den lokale disken og kopierer dem til S3. eller til et annet objektlager.

På denne måten tilbyr Thanos en global spørrevisning. Du kan spørre data lagret i objektlagring fra flere Prometheus-instanser.

Thanos støtter PromQL og .

Thanos bruker Prometheus-kode for å lagre data.

Thanos er utviklet av de samme utviklerne som Prometheus.
Про . Her , hvor vi først fortalte om .
VictoriaMetrics mottar data fra flere Prometheus protokoll støttet av Prometheus.
VictoriaMetrics tilbyr en global spørrevisning, ettersom flere Prometheus-instanser kan skrive data til én VictoriaMetrics. Følgelig kan du spørre på tvers av alle disse dataene.

VictoriaMetrics støtter også, som Thanos, PromQL og Prometheus spørrings-API.

I motsetning til Thanos er kildekoden til VictoriaMetrics skrevet fra bunnen av og optimalisert for hastighet og ressursforbruk.

VictoriaMetrics, i motsetning til Thanos, skalerer både vertikalt og horisontalt. Det finnes , som skaleres vertikalt. Du kan starte med én prosessor og 1 GB minne og gradvis vokse til hundrevis av prosessorer og 1 TB minne. VictoriaMetrics kan bruke alle disse ressursene. Ytelsen vil øke med omtrent 100 ganger sammenlignet med et system med én kjerne.

Thanos' historie begynte i november 2017, da den første offentlige commit-en dukket opp. Før det ble Thanos utviklet internt. .

I juni 2019 kom en milepælsutgivelse 0.5.0, som protokoll. Den ble fjernet fra Thanos fordi den ikke viste seg fra sin beste side. Thanos-klyngen fungerte ofte ikke riktig, noder koblet seg ikke riktig til den på grunn av sladderprotokollen. Derfor bestemte de seg for å fjerne den derfra. Jeg tror dette er den riktige avgjørelsen.

I samme juni 2019 sendte de søknadsnummer в .

Og etter et par måneder ble Thanos tatt opp i , som inkluderer Prometheus, Kubernetes og andre populære prosjekter.

Utviklingen av VictoriaMetrics startet i januar 2018.

I september 2018 nevnte jeg VictoriaMetrics offentlig for første gang.

Enkelnodeversjonen ble publisert i desember 2018.

I mai 2019 kilder for både versjoner med én node og klynger.

I juni 2019 sendte vi, akkurat som Thanos, inn en søknad til CNCF-stiftelsen under nummer Vi søkte én dag før Thanos søkte.

Men dessverre har vi fortsatt ikke blitt tatt opp der. Vi trenger lokalsamfunnets hjelp.

La oss se på de viktigste lysbildene som viser arkitekturen til Thanos og VictoriaMetrics.
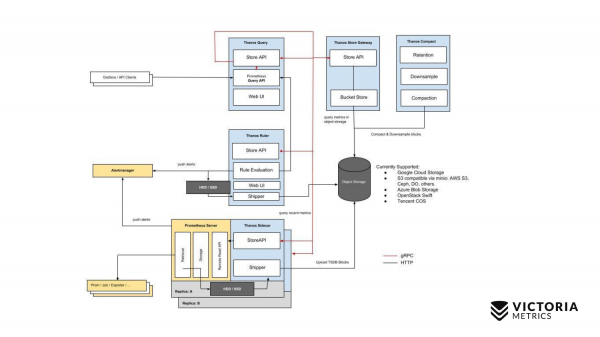
La oss starte med Thanos. De gule komponentene er Prometheus-komponenter. Alt annet er Thanos-komponenter. La oss starte med den viktigste komponenten. Thanos Sidecar er en komponent som installeres ved siden av hver Prometheus. Den gjør jobben med å laste Prometheus-data fra lokal lagring til S3 eller annen objektlagring.
Det finnes også en komponent kalt Thanos Store Gateway, som kan lese disse dataene fra Object Storage ved innkommende forespørsler fra Thanos Query. Thanos Query implementerer PromQL og Prometheus API. Det vil si at det utenfra ser ut som Prometheus. Den aksepterer PromQL-forespørsler, sender dem til Thanos Store Gateway, og Thanos Store Gateway henter de nødvendige dataene fra Object Storage og sender dem tilbake.
Men vi lagrer data i Object Storage uten de siste to timene på grunn av implementeringsfunksjonen til Thanos Sidecar, som ikke kan laste opp de siste to timene til Object Storage S3, siden Prometheus ennå ikke har opprettet filer i den lokale lagringen for disse to timene.
Hvordan bestemte de seg for å omgå dette? Thanos Query sender parallelle spørringer til hver Thanos Sidecar som ligger ved siden av Prometheus, i tillegg til spørringer til Thanos Store Gateway.
Og Thanos Sidecar sender på sin side forespørsler videre inn i Prometheus, og henter data for de siste to timene.
I tillegg til disse komponentene finnes det en annen valgfri komponent, som Thanos ikke vil føle seg bra uten. Dette er Thanos Compact, som slår sammen små filer på Object Storage til større filer som ble lastet opp hit av Thanos Sidecars. Thanos Sidecar laster opp datafiler dit på to timer. Antallet av disse filene kan øke betraktelig hvis de ikke slås sammen til større filer. Jo flere slike filer det er, desto mer minne trengs for Thanos Store Gateway, og desto flere ressurser trengs for å overføre data over nettverket, metadata. Arbeidet til Thanos Store Gateway blir ineffektivt. Derfor er det nødvendig å kjøre Thanos Compact, som slår sammen små filer til større, slik at det blir færre slike filer og for å redusere overhead på Thanos Store Gateway.
Det finnes også en komponent som heter Thanos Ruler. Den kjører Prometheus-varslingsregler og kan beregne Prometheus-opptaksregler for å skrive data tilbake til objektlagring. Men denne komponenten anbefales ikke å bruke, fordi den .
Dette er en enkel ordning for Thanos.
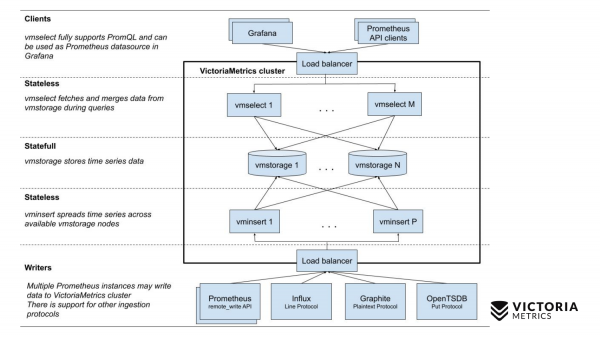
La oss nå sammenligne det med VictoriaMetrics-skjemaet.
VictoriaMetrics har to versjoner: Enkelnode- og klyngeversjon. Enkelnode-versjon fungerer på én datamaskin. Enkelnode-versjon har ikke disse komponentene, bare én binærfil. Denne binærfilen ser ut som denne firkanten på lysbildet. Alt inni firkanten er binærfilinnholdet for enkeltnode-versjonen. Du trenger ikke å vite om det. Bare kjør binærfilen – så fungerer alt for oss.
Klyngeversjonen er mer kompleks. Den inneholder tre forskjellige komponenter: vmselect, vminsert og vmstorage. Navnene deres skal gjøre det klart hva hver av dem gjør. Insert-komponenten aksepterer data i forskjellige formater: fra Prometheus remote write API, Influx line-protokollen, Graphite-protokollen og fra OpenTSDB-protokollen. Insert-komponenten aksepterer dem, analyserer dem og distribuerer dem mellom de eksisterende lagringskomponentene, der dataene allerede er lagret. Select-komponenten aksepterer på sin side PromQL-spørringer. Den implementerer , så vel som Prometheus-spørrings-API-et, og det kan brukes som en erstatning for Prometheus i Grafana eller andre Prometheus API-klienter. Select tar en promql-spørring, analyserer den, leser dataene som trengs for å kjøre denne spørringen fra lagringsnodene, behandler disse dataene og returnerer et svar.

La oss sammenligne kompleksiteten ved å installere Thanos og VictoriaMetrics.

La oss starte med Thanos. Før du kan begynne å jobbe med Thanos, må du opprette en bøtte i Object Storage, for eksempel S3 eller GCS, slik at Thanos Sidecar kan skrive data til den.

Deretter må du installere Thanos Sidecar for hver Prometheus. Før du gjør dette, må du huske å deaktivere datakomprimering i Prometheus. Datakomprimering komprimerer regelmessig data i den lokale Prometheus-lagringen for å redusere ressursforbruket.
Når du installerer Thanos Sidecar på Prometheus, bør du deaktivere denne datakomprimeringen, fordi Thanos Sidecar ikke fungerer bra med datakomprimering aktivert. Dette betyr at Prometheus begynner å lagre data i totimers biter og slutter å slå sammen disse bitene til større. Følgelig, hvis du foretar spørringer som overstiger varigheten av de siste to timene, vil de ikke fungere like effektivt som de kunne ha fungert hvis datakomprimering var aktivert.

Derfor anbefaler Thanos å redusere datalagringstiden i lokal lagring til 6–8 timer for å redusere overhead for et stort antall små blokker.
Når du har installert Thanos Sidecar, må du installere to komponenter for hver Object Storage Bucket. Disse er Thanos Compactor og Thanos Store Gateway.

Etter det må du installere Thanos Query og konfigurere den slik at den kan koble til alle Thanos Store Gateways du har, og også kunne koble til alle Thanos Sidecars.
Det kan være et lite problem her.

Du må sette opp en pålitelig og sikker forbindelse fra Thanos Query til disse komponentene. Og hvis Prometheusene dine er i forskjellige datasentre eller i forskjellige VPC-er, er tilkoblinger utenfra forbudt. Men for at Thanos Query skal fungere, må du på en eller annen måte sette opp en forbindelse der, og du må finne en måte.
Hvis du har mange slike datasentre, reduseres dermed påliteligheten til hele systemet. Siden Thanos Query kontinuerlig må opprettholde forbindelser til alle Thanos Sidecars som ligger i forskjellige datasentre. Med hver innkommende forespørsel vil den sende forespørsler til alle Thanos Sidecars. Hvis forbindelsen avbrytes, vil du enten motta et ufullstendig datasett, eller få svaret "klyngen fungerer ikke".

I VictoriaMetrics er alt litt enklere. For versjonen med én node er det nok å bare kjøre én binærfil, så fungerer alt.

I klyngeversjonen er det nok å kjøre alle de ovennevnte tre komponenttypene i den mengden du trenger, eller bruker. å automatisere lanseringen av komponenter i Kubernetes. Vi planlegger fortsatt å lage en Kubernetes-operator. Helm-diagrammet dekker ikke alle tilfeller, og lar deg skyte deg selv i foten. For eksempel lar det deg redusere antall lagringsnoder, noe som vil føre til datatap.

Når du har én binær- eller klyngeversjon oppe og går, trenger du bare å legge til Prometheus i konfigurasjonen din. , slik at den begynner å skrive data parallelt til lokal lagring og ekstern lagring. Som du har lagt merke til, bør en slik konfigurasjon fungere mye mer pålitelig sammenlignet med Thanos-konfigurasjonen. Vi trenger ikke å opprettholde en forbindelse fra VictoriaMetrics til alle Prometheuser, fordi Prometheuser selv kobler seg til VictoriaMetrics og overfører data.

La oss se på støtten fra Thanos og VictoriaMetrics.

Med Thanos må du overvåke Sidecar slik at de ikke stopper lasting av data til Object Storage. De kan stoppe lasting av data på grunn av lastefeil, for eksempel hvis nettverksforbindelsen til Object Storage er midlertidig avbrutt, eller Object Storage er midlertidig utilgjengelig. Thanos Sidecar vil legge merke til dette på dette tidspunktet, rapportere en feil, kan krasje og deretter slutte å virke. Hvis du ikke overvåker det, vil dataene dine stoppe overføringen til Object Storage. Hvis oppbevaringstiden (6–8 timer anbefalt) går, vil du miste data som ikke kom til Object Storage.

Thanos-komprimatorer kan slutte å virke pga. Komprimatorer tar data fra objektlagring og slår dem sammen til større datamengder. Siden komprimatorer ikke er synkronisert med Sidecars, kan dette skje: Sidecar har ennå ikke klart å skrive en blokk, og Compactor bestemmer at denne blokken er fullstendig skrevet. Compactor begynner å lese den. Den leser blokken ufullstendig og slutter å virke. Se detaljer. .

Store Gateway kan returnere inkonsistente data på grunn av kappløp mellom Compactor og Sidecars. Det samme skjer her, fordi Store Gateway ikke er synkronisert med Compactors og Sidecars. Følgelig kan kappløpsforhold oppstå når Store Gateway ikke ser deler av dataene, eller ser unødvendige data.

Query-komponenten i Thanos returnerer delvise resultater som standard hvis noen Sidecars eller Store Gateway ikke er tilgjengelige for øyeblikket. Du vil motta en del av dataene, og den vil ikke engang vite at den ikke mottok alle dataene. Slik fungerer det som standard. I en lignende situasjon returnerer VictoriaMetrics merkede data som delvise.

I motsetning til Thanos mister VictoriaMetrics sjelden data. Selv om forbindelsen fra Prometheus til VictoriaMetrics blir avbrutt, er det ikke et problem, siden Prometheus fortsetter å skrive innkommende nye data til Write Ahead-loggen, som er to timer lang. Hvis du gjenoppretter forbindelsen til VictoriaMetrics innen to timer, vil ikke dataene gå tapt. Prometheus .

I motsetning til Thanos, som skriver data til objektlagring først etter to timer, replikerer Prometheus automatisk data via fjernskriveprotokollen til ekstern lagring, som for eksempel VictoriaMetrics. Du er ikke redd for å miste lokal lagring i Prometheus. Hvis den plutselig mister lokal lagring, vil du i verste fall miste de siste sekundene av data som ikke rakk å bli skrevet til ekstern lagring.

Kubernetes administrerer klyngen automatisk, i motsetning til Thanos. Det er vanskelig å plassere alle Thanos-komponentene i én Kubernetes-klynge, i motsetning til VictoriaMetrics-klyngekomponenter.

VictoriaMetrics har en veldig enkel oppdatering til en ny versjon. Bare stopp VictoriaMetrics, oppdater binærfilene og start. Når den stoppes via SIGINT-signal, foretar alle VictoriaMetrics-binærfiler en elegant avslutning. De lagrer nødvendige data på riktig måte og lukker innkommende tilkoblinger på riktig måte for ikke å miste noe. Derfor vil du ikke miste noe når du oppdaterer.

VictoriaMetrics gjør det veldig enkelt å utvide klyngen din. Bare legg til de nødvendige komponentene og fortsett å jobbe.

Om fallgruvene i Thanos og VictoriaMetrics.

Thanos har følgende fallgruver. Prometheus må lagre de siste to timene med data. Hvis de går tapt, mister du dem fullstendig, siden de ennå ikke er skrevet til Object Storage slik som S3.

Store Gateway-komponenten og komprimeringskomponenten kan kreve mye minne for å fungere med store objektlagringsenheter hvis det er mange små filer lagret der. Jo større antall og størrelse på filene er, desto mer RAM krever Store Gateway og komprimeringskomponenten for å lagre metadata. Thanos har mange problemer med det faktum at .

Thanos annonseres som å kunne skaleres uendelig til antallet Prometheus-komponenter. I virkeligheten stemmer ikke dette. Siden alle forespørsler går gjennom Query-komponenten, som må spørre alle Store Gateway-komponenter og alle Sidecar-komponenter parallelt, hente data derfra og deretter forhåndsbehandle dem. Spørrehastigheten er åpenbart begrenset av den tregeste svake lenken, den tregeste Store Gateway eller den tregeste Sidecar.
Disse komponentene kan være ujevnt lastet. For eksempel har du Prometheus, som samler inn millioner av metrikker per sekund. Og du har Prometheus, som samler inn tusenvis av metrikker per sekund. Prometheus, som samler inn millioner av metrikker per sekund, belaster serveren den kjører på mye tyngre. Følgelig jobber Sidecar tregere der. Og alt jobber sakte der. Og Query-komponenten vil hente data derfra veldig sakte. Følgelig vil ytelsen til hele klyngen din bli begrenset av denne trege Sidecar.

Som standard returnerer Thanos delvise data hvis noen Sidecars og/eller Store Gateway ikke er tilgjengelige. Hvis du for eksempel har Sidecars spredt rundt om i verden i forskjellige datasentre, øker sannsynligheten for tilkoblingsfeil og komponentutilgjengelighet betydelig. Følgelig vil du i de fleste tilfeller motta delvise data uten å vite om det.
VictoriaMetrics har sine egne fallgruver. Den første fallgruven er alternativet som begrenser mengden RAM som brukes til VictoriaMetrics-hurtigbufferen. Som standard er den lik 60 % av RAM-en på maskinen der VictoriaMetrics kjører, eller 60 % av RAM-en til VictoriaMetrics-poden i Kubernetes.
Hvis du endrer denne verdien feil, kan du ødelegge ytelsen til VictoriaMetrics. Hvis du for eksempel setter den for lavt, kan det hende at dataene ikke lenger får plass i VictoriaMetrics' hurtigbuffer. På grunn av dette må den gjøre ekstra arbeid og belaste prosessoren og disken. Hvis du gjør dette alternativet for stort, øker det for det første sannsynligheten for at VictoriaMetrics krasjer med en feilmelding om lite minne, og for det andre vil det føre til at operativsystemet har svært lite RAM til filbufferen. Og VictoriaMetrics er avhengig av filbufferen for ytelse. Hvis den ikke er nok, kan diskbelastningen øke betydelig. Derfor rådet: ikke endre denne parameteren med mindre det er absolutt nødvendig.
Det andre alternativet er retentionPeriod – en periode som er satt til 1 måned som standard. Dette er tiden VictoriaMetrics lagrer dataene i. Etter denne perioden sletter VictoriaMetrics dataene.
Mange starter VictoriaMetrics uten denne parameteren, registrerer data for en måned. Og spør så: hvorfor forsvant dataene for forrige måned? Fordi retentionPeriod er 1 måned som standard. Derfor må du vite og angi riktig retentionPeriod.

La oss gå gjennom de unike funksjonene.

Thanos har en funksjon som kalles nedsampling: 5-minutters og timesintervaller, som ofte er Hvis du googler og ser på problemet deres på GitHub, er det mange problemer knyttet til denne nedsamplingen, at den noen ganger ikke fungerer som den skal, eller ikke fungerer slik brukerne forventer.

Thanos har datadeduplisering for Prometheus HA-par. Når to Prometheuser samler inn de samme beregningene fra de samme målene, og Thanos legger dem i objektlagring, kan Thanos deduplisere disse dataene riktig, i motsetning til VictoriaMetrics.

Thanos har en varslingskomponent som var på Thanos-skjemaet. Men den .

Thanos har fordelen at Thanos og Prometheus deler samme kode. Thanos og Prometheus er utviklet av de samme utviklerne. Når enten Thanos eller Prometheus forbedrer seg, vinner den andre siden.

VictoriaMetrics hovedfunksjon er MetricsQL. Dette er VictoriaMetrics-utvidelser for PromQL, som jeg snakket om på det forrige store overvåkingsmøtet.

VictoriaMetrics støtter datainnsprøytning via mange forskjellige protokoller. VictoriaMetrics kan ikke bare motta data fra Prometheus, men også via Influx-, OpenTSDB- og Graphite-protokollene.

VictoriaMetrics-data tar vanligvis mye mindre plass enn Thanos og Prometheus.
Når brukere registrerer ekte data, rapporterer de en 2–5 ganger reduksjon i datastørrelse på disken sammenlignet med Prometheus og Thanos.

En annen fordel med VictoriaMetrics er at den er optimalisert for hastighet.

La oss se på infrastrukturkostnadene.

En av fordelene med Thanos er at den lagrer data i objektlagring, noe som er relativt billig.
Når du lagrer data i objektlagring, må du betale for skrive- og leseoperasjoner for data ($10 per million operasjoner). Når du skriver data til objektlagring, betaler du hostingkostnadene dine for å laste opp data til Internett, med mindre klyngen din er i AWS – det er gratis der. Når du leser data, betaler du fra $10 til $230 per 1 TB. Dette kan være betydelig hvis du ofte ber om historiske data fra Thanos-klyngen.

For Thanos-klyngen må du betale for servere for Compact, Store Gateway og Query-komponenter som krever mye minne og CPU for store mengder data.

VictoriaMetrics har følgende utgifter. Hvis du lagrer data på GCE HDD-disker, blir det $40 per 1 TB. For VictoriaMetrics er vanlige HDD-disker nok, ingen SSD-er er nødvendig, som er fem ganger dyrere. VictoriaMetrics er optimalisert for HDD.

VictoriaMetrics trenger servere for komponenter: enten enkeltnode eller for klyngekomponenter, som i motsetning til Thanos-komponenter krever mye mindre CPU og RAM – og derfor vil være billigere.

Implementeringseksempler.

Thanos har et eksempel på implementering - Gitlab. Gitlab kjører utelukkende på Thanos. Men ikke alt går så knirkefritt der. Hvis du ser på deres , så kan du se at de stadig vekk har en slags Det er ikke nok minne for Store Gateway- eller Query-komponentene. De må stadig øke mengden minne.
Dette øker kostnadene ved å løse disse problemene.
Den andre implementeringen, som kan være mer vellykket, er Improbable, som startet utviklingen av Thanos. De publiserte kildekoden til Thanos. Improbable er et selskap som utvikler spillmotorer.

VictoriaMetrics offentlige eksempler på implementering er:
- wix.com nettstedbygger
- Adidas ruller ut VictoriaMetrics og holdt til og med et foredrag på PromCon 2019.
- TrafficStars — annonsenettverk
- Seznam.cz er en populær tsjekkisk søkemotor.
Og så kom de navnløse selskapene, som jeg ikke kan navngi nå. De ga ikke sitt samtykke.
- Én stor spillutvikler. Større enn usannsynlig.
- En stor utvikler av grafikkprogramvare.
- En stor russisk bank.
- En europeisk vindturbinprodusent som har testet VictoriaMetrics med suksess. Denne produsenten implementerer VictoriaMetrics for å overvåke data fra vindturbiner med en hastighet på 50 prøver per sekund per sensor. Hver vindturbin har flere hundre sensorer. De har flere hundre vindturbiner.
- Russiske flyselskaper som ønsker å implementere VictoriaMetrics, men fortsatt ikke kan. Vi er på avtalestadiet med dem.
 Konklusjoner.
Konklusjoner.
VictoriaMetrics og Thanos løser lignende problemer, men på forskjellige måter:
- Global spørrevisning
- horisontal skalering
- vilkårlig oppbevaring

Takk.
Vi venter på deg på vår .

Kun registrerte brukere kan delta i undersøkelsen. , vær så snill.
Hva bruker du som langtidslagring for Prometheus?
35,3%Thanos6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%annet 4
17 brukere stemte. 16 brukere avsto.
Kilde: www.habr.com
