

Merk. overs.Denne artikkelen med medium hit-score gir en oversikt over de viktigste endringene (2010–2019) i programmeringsspråkverdenen og det relaterte teknologiøkosystemet (med spesielt fokus på Docker og Kubernetes). Den opprinnelige forfatteren er Cindy Sridharan, som spesialiserer seg på utviklerverktøy og distribuerte systemer – hun skrev spesielt boken «Distributed Systems Observability» – og er ganske populær innen internett blant IT-fagfolk, spesielt interessert i temaet skybaserte løsninger.

Nå som 2019 går mot slutten, vil jeg gjerne dele mine tanker om noen av de viktigste teknologiske fremskrittene og innovasjonene det siste tiåret. Jeg vil også prøve å se litt inn i fremtiden og skissere de viktigste utfordringene og mulighetene i det kommende tiåret.
Jeg vil gjøre det klart med en gang at jeg i denne artikkelen ikke dekker endringer innen områder som datavitenskap. (datavitenskap), kunstig intelligens, frontend-teknikk osv., siden jeg personlig ikke har tilstrekkelig erfaring med dem.
Typifisering slår tilbake
En av de mest positive trendene på 2010-tallet har vært gjenoppblomstringen av statisk typede språk. Selv om statisk typede språk aldri helt forsvant (C++ og Java er fortsatt etterspurt i dag; de var dominerende for ti år siden), opplevde dynamisk typede språk en betydelig økning i popularitet etter at Ruby on Rails-bevegelsen dukket opp i 2005. Denne veksten nådde toppen i 2009 med åpen kildekode for Node.js, som gjorde Javascript på serveren til en realitet.
Over tid mistet dynamiske språk noe av sin appell på serversideområdet. Go, som ble popularisert av containerrevolusjonen, virket bedre egnet til å bygge høytytende, ressurseffektive servere med parallell prosessering (som ... skaperen av Node.js selv).
Rust, introdusert i 2010, innlemmet fremskritt innen i et forsøk på å bli et trygt og maskinskrevet språk. Rust var relativt kult i bransjen i første halvdel av tiåret, men populariteten vokste betydelig i andre halvdel. Merkbare bruksområder for Rust inkluderer bruken i , (vi snakket om ham i — ca. oversett.), den tidlige WebAssembly-kompilatoren fra Fastly (nå en del av bytecodealliance) og andre. I en situasjon der Microsoft vurderer å omskrive deler av operativsystemet Windows Rust, det er trygt å si at språket har en lys fremtid i 2020-årene.
Selv dynamiske språk har fått nye funksjoner som (valgfrie typer)De ble først implementert i TypeScript, et språk som lar deg lage maskinskrevet kode og kompilere den til JavaScript. PHP, Ruby og Python har fått sine egne valgfrie skrivesystemer (, ), som brukes med hell i .
Retur av SQL til NoSQL
NoSQL er en annen teknologi som var mye mer populær i begynnelsen av tiåret enn på slutten. Jeg tror det er to grunner til dette.
For det første viste det seg at NoSQL-modellen, uten skjema, ingen transaksjoner og svakere konsistensgarantier, var vanskeligere å implementere enn SQL-modellen. med tittelen «Hvorfor du bør foretrekke streng konsistens når det er mulig» (Hvorfor du bør velge sterk konsistens, når det er mulig) Google skriver:
Noe av det vi har lært hos Google er at applikasjonskode er enklere og utviklingstiden kortere når ingeniører kan stole på eksisterende lagring for å håndtere komplekse transaksjoner og opprettholde dataorden. For å sitere den originale Spanner-dokumentasjonen: «Vi tror at det er bedre for programmerere å ta tak i problemer med applikasjonsytelsen på grunn av transaksjonsmisbruk når flaskehalser oppstår, i stedet for å stadig bekymre seg for fraværet av transaksjoner.»
Den andre grunnen er knyttet til veksten av «skalerbare» distribuerte SQL-databaser (som и ) i den offentlige skyen, samt åpen kildekode-alternativer som CockroachDB (vi snakket også om henne - ca. oversett.), som løser mange av de tekniske problemene som hindret tradisjonelle SQL-databaser i å skaleres. Selv MongoDB, en gang forbildet for NoSQL-bevegelsen, er nå distribuerte transaksjoner.
For situasjoner som krever atomisk lesing og skriving til flere dokumenter (i én eller flere samlinger), støtter MongoDB transaksjoner med flere dokumenter. Når det gjelder distribuerte transaksjoner, kan transaksjoner brukes på tvers av flere operasjoner, samlinger, databaser, dokumenter og shards.
Total strømlinjeforming
Apache Kafka har utvilsomt vært en av de viktigste oppfinnelsene det siste tiåret. Kafka, som ble lansert som åpen kildekode i januar 2011, har revolusjonert måten bedrifter jobber med data på. Kafka har blitt brukt i alle selskaper jeg har jobbet for, fra oppstartsbedrifter til store bedrifter. Garantiene og brukstilfellene (pub-sub, strømmer, hendelsesdrevne arkitekturer) brukes i alt fra datavarehus til overvåking og strømmeanalyse, som er nødvendige på mange områder, som finans, helsevesen, offentlig sektor, detaljhandel osv.
Kontinuerlig integrasjon (og i mindre grad kontinuerlig distribusjon)
Kontinuerlig integrasjon er ikke et nytt konsept de siste 10 årene, men det har blitt mer vanlig det siste tiåret. har spredt seg i en slik grad, som ble en del av standard arbeidsflyt (kjøre tester på alle pull-forespørsler). Fremveksten av GitHub som en plattform for utvikling og lagring av kode og, enda viktigere, utviklingen av en arbeidsflyt basert på betyr at det å kjøre tester før man godtar en pull-forespørsel i masteren er den eneste arbeidsflyt i utvikling, kjent for ingeniører som startet karrieren sin i det siste tiåret.
Kontinuerlig distribusjon (distribusjon av hver commit når den treffer master) er ikke like bredt brukt som kontinuerlig integrasjon. Men med det store antallet forskjellige skydistribusjons-API-er, den økende populariteten til plattformer som Kubernetes (som tilbyr et standardisert API for distribusjoner), og fremveksten av flerplattform-, flerskyverktøy som Spinnaker (bygd oppå nevnte standardiserte API-er), har distribusjonsprosesser blitt mer automatiserte, strømlinjeformede og generelt tryggere.
containere
Containere er kanskje den mest omtalte, skrytte, skryte og misforståtte teknologien fra 2010-tallet. På den annen side er de en av de viktigste innovasjonene fra det forrige tiåret. En del av grunnen til all denne kakofonien er de blandede signalene vi fikk fra nesten overalt. Nå som hypen har lagt seg litt, har noen av detaljene blitt klarere.
Containere ble ikke populære fordi de var den beste måten å kjøre en applikasjon på som møtte behovene til det globale utviklermiljøet. Containere ble populære fordi de passet godt inn i markedsetterspørselen etter et verktøy som løste et helt annet problem. Docker viste seg å være fantastisk et utviklingsverktøy som løser det presserende kompatibilitetsproblemet ("fungerer på maskinen min").
Mer presist, han gjorde en revolusjon Docker-bilde, fordi det løste problemet med paritet mellom miljøer og ga ekte portabilitet ikke bare for applikasjonsfilen, men for alle programvare- og operativsystemavhengigheter. Det faktum at dette verktøyet på en eller annen måte ansporet populariteten til "containere", som i hovedsak er en implementeringsdetalj på svært lavt nivå, er for meg fortsatt det kanskje største mysteriet det siste tiåret.
server~~POS=TRUNC
Jeg vil vedde på at fremveksten av «serverløs» databehandling er enda viktigere enn containere, fordi det virkelig gjør drømmen om databehandling på forespørsel til virkelighet. (på forespørsel)I løpet av de siste fem årene har jeg sett en gradvis utvidelse av den serverløse tilnærmingen (lagt til støtte for nye språk og kjøretider). Fremveksten av produkter som Azure Durable Functions virker som et skritt i riktig retning mot implementering av tilstandsfulle funksjoner (og et avgjørende et). , relatert til begrensningene til FaaS). Jeg vil med interesse følge med på hvordan dette nye paradigmet utvikler seg i årene som kommer.
Automatisering
Den kanskje største vinneren av denne trenden har vært driftsingeniørmiljøet, ettersom det har muliggjort at konsepter som infrastruktur som kode (IaC) har blitt virkelighet. I tillegg har lidenskapen for automatisering falt sammen med fremveksten av «SRE-kulturen», som tar sikte på å ta en mer programvaresentrisk tilnærming til drift.
Universell API-ifisering
En annen interessant funksjon det siste tiåret har vært API-ifiseringen av ulike utviklingsoppgaver. Gode, fleksible API-er lar utvikleren lage innovative arbeidsflyter og verktøy, som igjen bidrar til vedlikehold og forbedrer brukeropplevelsen.
I tillegg er API-ifisering det første skrittet mot SaaS-ifisering av en funksjonalitet eller et verktøy. Denne trenden falt også sammen med fremveksten av mikrotjenester: SaaS ble bare en annen tjeneste som kan nås via API. Det finnes nå mange SaaS- og FOSS-verktøy innen områder som overvåking, betalinger, lastbalansering, kontinuerlig integrasjon, varsling og funksjonalitetsbytte. (funksjonsflagging), CDN, trafikkteknikk (f.eks. DNS), osv., som har blomstret det siste tiåret.
Observerbarhet
Det er verdt å merke seg at vi i dag har tilgang til mye mer avansert verktøy for overvåking og diagnostisering av applikasjonsatferd enn noen gang før. Prometheus-overvåkingssystemet, som ble åpen kildekode i 2015, er kanskje det det beste overvåkingssystem jeg noen gang har jobbet med. Det er ikke perfekt, men et betydelig antall ting er implementert i det på en helt korrekt måte (for eksempel støtte for målinger [dimensjonalitet] i tilfelle av målinger).
Distribuert sporing var en annen teknologi som ble vanlig på 2010-tallet, takket være initiativer som OpenTracing (og etterfølgeren OpenTelemetry). Selv om sporing fortsatt er ganske komplekst å implementere, gir noen nyere utviklinger håp om at vi vil utnytte dens virkelige potensial på 2020-tallet. (Oversetterens merknad: Les også oversettelsen av artikkelen "«av samme forfatter.)
Ser til fremtiden
Dessverre er det mange smertepunkter som venter på å bli tatt tak i i det kommende tiåret. Her er mine tanker om dem og noen potensielle ideer til hvordan vi kan bli kvitt dem.
Løsning av Moores lovproblem
Slutten på Dennards skaleringslov og etterslepet i forhold til Moores lov krever ny innovasjon. John Hennessy i forklarer hvorfor problematiske rusavhengige (domenespesifikk) Arkitekturer som TPU kan være én løsning på problemet med å henge etter Moores lov. Verktøysett som fra Google virker allerede som et godt skritt fremover i denne retningen:
Kompilatorer må støtte nye applikasjoner, være enkle å overføre til ny maskinvare, bygge bro over mange abstraksjonslag fra dynamiske, administrerte språk til vektorakseleratorer og programvarestyrte minner, samtidig som de tilbyr høynivåbrytere for autotuning, just-in-time-funksjonalitet, diagnostikk og formidling av feilsøkingsinformasjon om systemenes funksjon og ytelse gjennom hele stakken, og fortsatt tilby ytelse som er nær nok håndskrevet montering i de fleste tilfeller. Vi har til hensikt å dele vår visjon, fremdrift og planer for utvikling og offentlig tilgjengeliggjøring av en slik kompilatorinfrastruktur.
CI / CD
Selv om fremveksten av CI har vært en av de største trendene på 2010-tallet, er Jenkins fortsatt gullstandarden for CI.
Dette området har et desperat behov for innovasjon på følgende områder:
- brukergrensesnitt (DSL for spesifikasjoner for kodingstester);
- implementeringsdetaljer som vil gjøre det virkelig skalerbart og raskt;
- integrasjon med ulike miljøer (staging, prod, osv.) for å utføre mer avanserte former for testing;
- kontinuerlig testing og utrulling.
Utviklerverktøy
Som bransje har vi begynt å lage stadig mer kompleks og imponerende programvare. Når det gjelder våre egne verktøy, er det imidlertid rimelig å si at situasjonen kunne vært mye bedre.
Samarbeidsbasert og fjernredigering (SSH) har blitt noe populært, men det har ikke blitt den nye standardmåten å utvikle på. Hvis du, som meg, er skeptisk til ideen om behovet permanent internettforbindelse bare for å kunne programmere, så er det usannsynlig at det å jobbe via ssh på en ekstern maskin passer for deg.
Lokale utviklingsmiljøer, spesielt for ingeniører som jobber med store tjenesteorienterte arkitekturer, er fortsatt en utfordring. Noen prosjekter prøver å løse dette, og jeg ville vært interessert i å vite hvordan den beste brukeropplevelsen ville se ut for dette brukstilfellet.
Det ville også være interessant å utvide konseptet med «bærbare miljøer» til andre utviklingsområder, som for eksempel reproduksjon av feil (eller ), som forekommer under visse forhold eller med visse innstillinger.
Jeg skulle også gjerne sett mer innovasjon innen områder som semantisk og kontekstbevisst kodesøk, verktøy som lar deg korrelere produksjonshendelser med spesifikke deler av kodebasen, osv.
Databehandling (fremtiden for PaaS)
Med all hypen rundt containere og serverløshet på 2010-tallet, har utvalget av løsninger innen offentlig sky utvidet seg betydelig de siste årene.
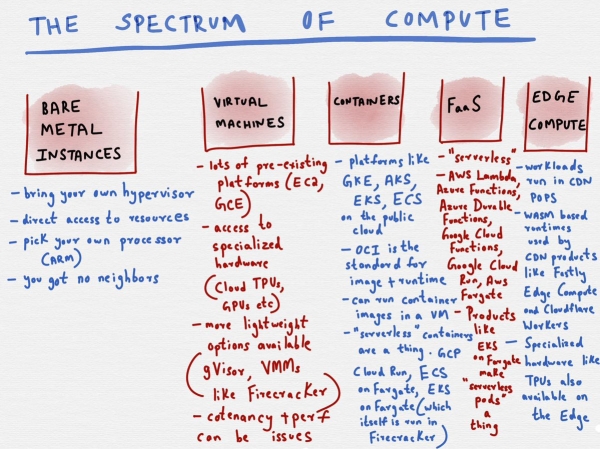
Dette reiser noen interessante spørsmål. Først og fremst vokser listen over tilgjengelige alternativer i den offentlige skyen stadig. Skyleverandører har personalet og ressursene til å enkelt holde seg oppdatert på den nyeste utviklingen i åpen kildekode-verdenen og lansere produkter som "serverløse pods" (jeg mistenker at det ganske enkelt skjer ved å lage sine egne FaaS-kjøretider OCI-kompatible) eller andre lignende fancy ting.
De som bruker disse skyløsningene er misunnelige. I teorien tilbyr skybaserte Kubernetes-tilbud (GKE, EKS, EKS on Fargate, osv.) sky-agnostiske API-er for å kjøre arbeidsbelastninger. Hvis du bruker slike produkter (ECS, Fargate, Google Cloud Run, osv.), utnytter du sannsynligvis allerede de mest interessante funksjonene som tilbys av tjenesteleverandøren. I tillegg, etter hvert som nye produkter eller databehandlingsparadigmer dukker opp, vil migreringen sannsynligvis være enkel og problemfri.
Gitt hvor raskt landskapet for disse løsningene utvikler seg (jeg ville blitt overrasket om det ikke dukket opp noen nye alternativer snart), kommer det til å bli utrolig vanskelig for små «plattform»-team (infrastrukturteamene som er ansvarlige for å bygge lokale plattformer for å kjøre arbeidsbelastninger i bedrifter) å konkurrere på funksjoner, brukervennlighet og generell pålitelighet. 2010-tallet handlet om Kubernetes som et PaaS-verktøy (plattform-som-en-tjeneste), så det gir ingen mening for meg å bygge en intern Kubernetes-basert plattform som tilbyr samme valgfrihet, enkelhet og frihet som er tilgjengelig i den offentlige skyen. Å tenke på «containerbasert» PaaS som en «Kubernetes-strategi» er en bevisst avvisning av å omfavne de mest innovative funksjonene i skyen.
Hvis du ser på det tilgjengelige i dag beregningsmuligheter, blir det tydelig at det å bygge din egen PaaS utelukkende oppå Kubernetes er det samme som å male seg selv opp i et hjørne (ikke en veldig fremtidsrettet tilnærming, ikke sant?). Selv om noen bestemmer seg for å bygge en container-PaaS oppå Kubernetes i dag, vil det om et par år se utdatert ut sammenlignet med skyfunksjoner. Selv om Kubernetes startet som et åpen kildekode-prosjekt, er dets forløper og inspirasjon et internt Google-verktøy. Det ble imidlertid opprinnelig utviklet tidlig/midt på 2000-tallet, da databehandlingslandskapet var veldig annerledes.
I en veldig bred forstand trenger ikke bedrifter å bli eksperter på å drive en Kubernetes-klynge, og de trenger heller ikke å bygge og vedlikeholde sine egne datasentre. Å tilby et pålitelig datagrunnlag er hovedmålet. leverandører av skytjenester.
Til slutt føler jeg at vi har gått litt tilbake som bransje når det gjelder opplevelse av interaksjon (). Heroku ble lansert i 2007 og er fortsatt en av de mest enkel å bruke plattformer. Det er ingen tvil om at Kubernetes er mye kraftigere, mer utvidbart og programmerbart, men jeg savner hvor enkelt det er å komme i gang og distribuere til Heroku. Du trenger bare å kunne Git for å bruke det.
Alt dette bringer meg til følgende konklusjon: vi trenger bedre abstraksjoner på høyere nivå for å gjøre jobben vår (dette gjelder spesielt for abstraksjoner på høyeste nivå).
Riktig API på høyeste nivå
Docker er et godt eksempel på behovet for bedre separasjon av bekymringer mens korrekt implementering av API-et på høyeste nivå.
Problemet med Docker er at (i hvert fall) de opprinnelige målene for prosjektet var for globale: alt for å løse kompatibilitetsproblemet ("det fungerer på min maskin") ved hjelp av containerteknologi. Docker var et bildeformat, og en runtime med sitt eget virtuelle nettverk, og et CLI-verktøy, og en daemon som kjørte under root, og mye mer. Uansett var meldingsfunksjonen mer forvirrende, for ikke å nevne "lette virtuelle maskiner", c-grupper, navnerom, en rekke sikkerhetsproblemer og funksjoner blandet med markedsføringsargumentet "bygg, send, kjør hvilken som helst applikasjon hvor som helst".
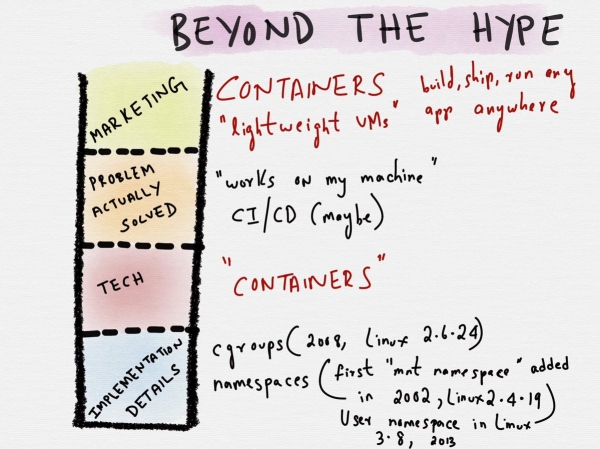
Som alle gode abstraksjoner tar det tid (og erfaring og smerte) å bryte ned de ulike problemstillingene i logiske lag som kan kombineres med hverandre. Akk, før Docker kunne nå den modenheten, kom Kubernetes inn i konkurransen. Den monopoliserte hype-syklusen så mye at alle nå prøvde å holde tritt med endringene i Kubernetes-økosystemet, og container-økosystemet ble henvist til sekundær status.
Kubernetes deler mange av de samme problemene som Docker. Til tross for alt snakket om kul og komponerbar abstraksjon, å dele ulike oppgaver inn i lag er ikke veldig godt innkapslet. I kjernen er det en containerorkestrator som kjører containere på en klynge av forskjellige maskiner. Dette er en oppgave på ganske lavt nivå, som kun gjelder for ingeniørene som driver klyngen. På den annen side er Kubernetes også abstraksjon på høyeste nivå, et CLI-verktøy som brukere samhandler med via YAML.
Docker var (og er fortsatt) kjøle utviklingsverktøyet, til tross for alle dets mangler. I et forsøk på å ta igjen alle "harene" samtidig, klarte utviklerne å implementere det riktig abstraksjon på høyeste nivå. Med abstraksjon på høyeste nivå mener jeg en delmengde funksjonalitet som målgruppen (i dette tilfellet utviklere som brukte mesteparten av tiden sin i sine lokale utviklingsmiljøer) faktisk var interessert i, og som fungerte utmerket fra starten av.
Dockerfile og CLI-verktøy docker bør være et eksempel på hvordan man bygger et godt «avanserte brukergrensesnitt». Den gjennomsnittlige utvikleren kan begynne å jobbe med Docker uten å vite noe om komplikasjonene. implementeringer som bidrar til driftserfaring, som navnerom, cgroups, minne- og CPU-grenser, osv. Til syvende og sist er det ikke mye forskjellig fra å skrive et shell-skript å skrive en Dockerfile.
Kubernetes er designet for ulike målgrupper:
- klyngeadministratorer;
- programvareingeniører som jobber med infrastrukturproblemer, utvider funksjonene til Kubernetes og bygger plattformer oppå det;
- sluttbrukere som samhandler med Kubernetes via
kubectl.
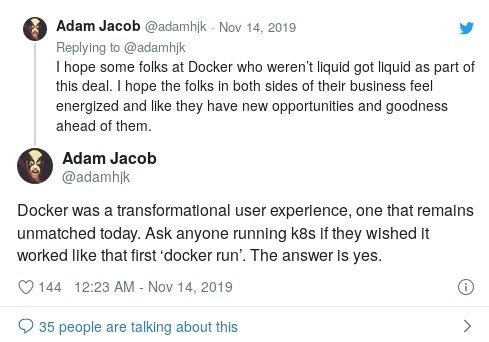
Kubernetes sin «one-API-fits-all»-tilnærming er et underinnkapslet «fjell av kompleksitet» uten veiledning om hvordan den skal skaleres, noe som resulterer i en unødvendig lang læringskurve. Adam Jacob, «Docker leverte en transformerende brukeropplevelse som ennå ikke er overgått. Spør alle som bruker K8s om de skulle ønske det fungerte som deres første» docker runSvaret vil være bekreftende”:
Jeg vil hevde at mesteparten av infrastrukturteknologien i dag er på for lavt nivå (og derfor ansett som «for kompleks»). Kubernetes implementeres på et ganske lavt nivå. Distribuert sporing i sin (mange spenn sydd sammen for å danne en sporvisning) er også implementert på et for lavt nivå. Utviklerverktøy som implementerer abstraksjoner på "høyeste nivå" har en tendens til å være mest vellykkede. Denne konklusjonen viser seg å være sann i et overraskende antall tilfeller (hvis en teknologi er for kompleks eller vanskelig å bruke, har "API/UI på høyeste nivå" for den teknologien ennå ikke blitt oppdaget).
Akkurat nå er det skybaserte økosystemet forvirrende fiksert på lavnivå. Som bransje må vi innovere, eksperimentere og lære opp om hva det rette nivået av «maksimal, høyeste abstraksjon» ser ut.
Detaljhandel
Den digitale detaljhandelsopplevelsen har ikke endret seg mye på 2010-tallet. På den ene siden var det uunngåelig at den enkle netthandelen ville skade fysiske butikker, men på den andre siden har ikke netthandel fundamentalt endret seg mye på et tiår.
Selv om jeg ikke har noen spesifikke tanker om hvor denne bransjen vil gå i løpet av det neste tiåret, vil jeg bli veldig skuffet hvis vi handler i 2030 på samme måte som vi handler i 2020.
journalistikk
Jeg blir stadig mer desillusjonert over journalistikkens tilstand verden over. Det blir stadig vanskeligere å finne upartiske nyhetskanaler som rapporterer objektivt og nøyaktig. Svært ofte er grensen mellom selve nyheten og meningene om den uklar. Som regel presenteres informasjon på en partisk måte. Dette gjelder spesielt i noen land der det historisk sett ikke har vært noe skille mellom nyheter og meninger. I en fersk artikkel publisert etter det siste parlamentsvalget i Storbritannia, skrev Alan Rusbridger, tidligere redaktør for The Guardian, :
Hovedpoenget er at jeg i mange år så på amerikanske aviser og syntes synd på kollegene der som var eneansvarlige for nyhetene og overlot kommentarene til noen helt andre. Men over tid ble medlidenheten til misunnelse. Jeg synes nå at alle britiske riksaviser burde skille ansvaret for nyheter fra ansvaret for kommentarer. Akk, det er for vanskelig for den gjennomsnittlige leseren – spesielt nettleseren – å se forskjellen.
Gitt Silicon Valleys nokså tvilsomme rykte når det gjelder etikk, ville jeg aldri stole på at teknologi ville «revolusjonere» journalistikken. Når det er sagt, ville jeg (og mange jeg kjenner) vært begeistret over å se et upartisk, uselvisk og troverdig nyhetsmedium dukke opp. Jeg kan ennå ikke forestille meg hvordan en slik plattform kan se ut, men jeg er sikker på at i en tid der sannheten blir stadig vanskeligere å skjelne, er behovet for ærlig journalistikk større enn noensinne.
Sosiale nettverk
Sosiale medier og folkefinansierte nyhetsplattformer er den primære informasjonskilden for mange mennesker rundt om i verden, og mangelen på nøyaktighet og manglende vilje hos noen plattformer til å i det hele tatt gjennomføre grunnleggende faktasjekking har ført til alvorlige konsekvenser som folkemord, valginnblanding osv.
Sosiale medier er også det kraftigste medieverktøyet som noen gang har eksistert. Det har fundamentalt endret politisk praksis. Det har endret reklame. Det har endret popkulturen (for eksempel den viktigste bidragsyteren til utviklingen av den såkalte avbrytelseskulturen [kulturer av utstøting — overs. merknad] (Det er sosiale medier som utgjør forskjellen). Kritikere hevder at sosiale medier har vært grobunn for raske og «lunefulle» endringer i moralske verdier, men det har også gitt marginaliserte grupper en måte å knytte kontakter på måter de aldri har gjort før. I hovedsak har sosiale medier endret måten folk kommuniserer og uttrykker seg på i det 21. århundre.
Jeg tror imidlertid også at sosiale medier bringer frem de verste menneskelige impulsene. Omtanke og omsorg blir ofte oversett til fordel for popularitet, og det blir nesten umulig å uttrykke begrunnet uenighet med visse meninger og standpunkter. Polarisering kommer ofte ut av kontroll, med det resultat at individuelle stemmer rett og slett ikke blir hørt av offentligheten, mens absolutister kontrollerer spørsmål om etikette og aksept på nett.
Jeg lurer på om det er mulig å skape en «bedre» plattform som fremmer bedre diskusjoner, siden det som driver «engasjement» ofte er det som driver plattformenes fortjeneste. Hvordan Kara Swisher i New York Times:
Det er mulig å fremme digitalt engasjement uten å oppfordre til hat og intoleranse. Grunnen til at de fleste sosiale medier virker så giftige, er fordi de ble bygget for hastighet, viralitet og oppmerksomhet, ikke innhold og nøyaktighet.
Det ville være virkelig uheldig om den eneste arven etter sosiale medier om et par tiår var en erosjon av nyanser og hensiktsmessighet i den offentlige diskursen.
PS fra oversetter
Les også på bloggen vår:
- «";
- «";
- «";
- «'.
Kilde: www.habr.com
