

Istnieją rodzaje oprogramowania, bez których niektórzy ludzie nie potrafią się obejść, podczas gdy inni w ogóle nie wyobrażają sobie, że coś takiego istnieje lub że ktoś mógłby tego potrzebować. Dla mnie przez wiele lat taki program był , co pozwalało na zapisywanie, czytanie i organizowanie stron internetowych w formie swoistej biblioteki offline. Jestem pewien, że wielu czytelników doskonale sobie radzi, korzystając ze zbioru linków lub kombinacji przeglądarki i folderu zawierającego zbiór zapisanych dokumentów. Chciałbym móc przynajmniej oznaczać dokumenty jako „przeczytane” lub „ulubione”, szybko przechodzić z jednego tekstu do drugiego i nie być uzależnionym od dostępności Internetu lub konkretnej witryny. Zdarza się, że czas na czytanie udaje się znaleźć akurat wtedy, gdy nie ma Internetu (np. w podróży), a linki, niestety, często okazują się krótkotrwałe.
Najwyraźniej autorzy WebResearch liczyli właśnie na tego typu ludzi. Program ten wyposażono w szeroką gamę funkcji: katalogowanie według sekcji i tagów, edytowanie notatek, wszelkiego rodzaju eksport/import itd. Jednak około 2013 roku projekt przestał być aktualizowany, a wraz z nim przestała istnieć witryna internetowa dewelopera. Udało mi się jeździć na tym koniu jeszcze przez kilka lat, ale najpierw przestały działać wtyczki do przeglądarek (dostępne jedynie dla ówczesnych wersji IE i FireFoxa), a potem nowoczesne strony przestały się normalnie wyświetlać w przeglądarce opartej na starym silniku IE.
Główne okno WebResearch,
Droga rozczarowań
Gdy tylko stało się jasne, że nie da się uniknąć zastępstwa, zacząłem szukać przyzwoitego odpowiednika w tle. Wydawało mi się, że nie będzie tu większych trudności, gdyż moje pragnienia były niezmiernie skromne. Byłem skłonny zadowolić się tylko niewielkim podzbiorem narzędzi WebResearch, w tym:
- zapisywanie strony HTML z przeglądarki za pomocą rozszerzenia;
- co najmniej podstawowe narzędzia katalogowania (zmiana nazw, organizacja katalogów, tagi);
- (pożądana) obsługa dokumentów PDF;
- jakiś sensowny sposób na synchronizację swojej kolekcji z innymi urządzeniami.
Ku mojemu zdziwieniu nie udało mi się znaleźć niczego podobnego, chociaż uczciwie przeszukałem cały Internet wzdłuż i wszerz i uważnie przyjrzałem się kilkunastu programom, które pasowały do opisu (z wyjątkiem Evernote, gdzie funkcjonalność podobna do opisu jest dostępna tylko w ramach subskrypcji). Dzisiaj tylko projekty, które w jakiś sposób spełniają moje życzenia и . Ich badanie, ogólnie rzecz biorąc, ma pewne znaczenie kulturowe.
TagSpaces to stylowy, modny i młodzieżowy organizer na platformę Electron z piękną witryną, adaptacyjnym układem i oczywiście ciemnym motywem. Gdzie byśmy byli bez niego? Jednocześnie nieszczęsny spis treści kolekcji z modnymi zaokrąglonymi ikonami zajmuje połowę ekranu, podczas gdy zawiera maksymalnie około dwudziestu elementów, a tak podstawowe rzeczy, jak obsługa skrótów klawiszowych czy renderowanie przeglądanego dokumentu, są napisane na zasadzie szczątkowej. W efekcie dokumenty są wyświetlane krzywo, a praca z kolekcją zamienia się w nudny i żmudny zestaw ćwiczeń z myszką.
Jego antypoda myBase pochodzi z końca lat dziewięćdziesiątych: tutaj oprócz czysto funkcjonalny interfejs Dysponujemy niezwykle bogatym zestawem ustawień i funkcji. Jednak oknem podglądu jest nadal ta sama przeglądarka oparta na starym IE (co i tak utrudnia czytanie), a wszystkie dokumenty są przechowywane w monolitycznej bazie danych. Jeśli umieścisz je np. w folderze Dropbox (nie ma innego sposobu na synchronizację z innymi urządzeniami), to przy najmniejszej zmianie w kolekcji będziesz musiał czekać, aż setki megabajtów informacji zostaną przesłane na serwer.
Punkt zwrotny
Być może dalsza treść notatki wydaje się czytelnikowi oczywista: teraz zostanie nam zaoferowany własny rower, który oczywiście będzie o niebo lepszy od wszystkich dotychczasowych odpowiedników. Trochę tak, ale nie do końca. Naprawdę nie wytrzymałem tej gehenny z myBase i TagSpaces, więc stworzyłem własny menedżer dokumentów, do którego link podam pod koniec. Jednakże ten niewielki projekt, przeznaczony na potrzeby osobiste, nie zasługuje sam w sobie na oddzielny artykuł; Piszę głównie dlatego, że uznałem za interesujące dzielenie się doświadczeniami, jakie zdobyłem w trakcie pracy, a także całą serią niemiłych niespodzianek, których się nie spodziewałem.
Cele i zadania
Zacznę od tego, że obecnie prowadzę bardzo zajęte życie i po prostu nie mam czasu na pełnoprawne projekty hobbystyczne. Dlatego od samego początku postanowiłem, że jestem gotowy uformować mój instrument z dowolnych elementów, jakie będę miał pod ręką, jeśli tylko przyspieszy to proces. Ponadto na razie podejmuję się wdrożenia absolutnego minimum funkcjonalności, bez czego obejście się nie jest możliwe.
Format danych i zapisywanie stron
Jak przechowywać strony internetowe na dysku? Biorąc pod uwagę wcześniej sformułowane wymagania, wydawało mi się, że wybór jest niewielki: albo format zapisu „pełnej strony WWW”, czyli główny plik HTML i folder z powiązanymi zasobami, albo format MHTML. Pierwsza opcja od razu wydała mi się mniej atrakcyjna: nie jest przyjemnie mieć na dysku stertę plików, z których trzeba wyodrębnić ważne dokumenty, odfiltrować niepotrzebne rzeczy podczas wyszukiwania i monitorować ich integralność podczas kopiowania. Kiedy próbowałem pracować z TagSpaces, musiałem ponownie zapisać wszystkie dokumenty, tak aby nazwa folderu zasobów zaczynała się od kropki. Wówczas system rozpoznawał je jako „ukryte” i nie wyświetlał.
Ten problem nie jest widoczny w myBase, ponieważ wszystko jest przechowywane w bazie danych, ale w moim przypadku zasada prostoty wzięła górę: naprawdę chciałem przechowywać wszystko jako zwykłe pliki na dysku, abym nie musiał zajmować się rutynowymi operacjami, takimi jak kopiowanie, zmiana nazwy, usuwanie i synchronizacja.
Format MHTML przechodzi trudne chwile. Łatwy sposób na zapisanie MHTML i nawet nie wiem, gdzie teraz te strony mają być przechowywane? Jasne, że ta szansa jeszcze nie przeminęła, są rozszerzenia firm trzecich, ale ogólnie rzecz biorąc, to jest jakiś zły znak. Również zapisywanie w formacie MHTML , co również nie napawa optymizmem.
Jednocześnie zacząłem szukać prostego sposobu na zapisywanie stron z przeglądarki do określonego folderu. Ostatecznie oba problemy udało się rozwiązać niewielkim nakładem pracy: trafiłem na wspaniały projekt , który może zapisać zawartość strony internetowej w oddzielnym, niezależnym pliku HTML. Można to zrobić, konwertując wszystkie powiązane zasoby do formatu base64 i osadzając je bezpośrednio w kodzie HTML. Oczywiście, zwiększa to rozmiar pliku, a jego zawartość wygląda na nieco chaotyczną, ale ogólnie rzecz biorąc takie podejście wydało mi się niezawodne i proste, więc się na nie zdecydowałem.
SingleFile jest dostępny zarówno jako rozszerzenie przeglądarki, jak i aplikacja wiersza poleceń. Teraz po prostu używam tego rozszerzenia: jest to dość wygodne, pomijając fakt, że trzeba ręcznie wybrać folder docelowy zapisu. W przyszłości prawdopodobnie spróbuję udoskonalić aplikację, aby uprościć ten proces. Aby wywołać aplikację innej firmy z poziomu przeglądarki Chrome, możesz użyć rozszerzenia - To moje kolejne przydatne odkrycie. Nawiasem mówiąc, aplikacja już mi się przydała: z jej pomocą przekonwertowałem zbiór folderów i plików z TagSpaces na zestaw niezależnych dokumentów HTML.
Problemy z GUI i przeglądarką
Odkryłem, że Python jest dobrym wyborem do wszelkiego rodzaju prostych operacji na plikach i ciągach znaków, a ponieważ jeden z moich projektów zawodowych go wykorzystuje, , wybór wydawał się logiczny jako rdzeń struktury.
Następnie, widząc wystarczająco dużo błędów związanych z wyświetlaniem stron w innych programach, doszedłem do wniosku, że jedynym niezawodnym sposobem poradzenia sobie z nimi jest zaimplementowanie w programie wizualizatora bazującego na nowoczesnej przeglądarce, np. Chrome lub Firefox.
Muszę przyznać, że ostatni raz musiałem coś takiego zrobić jakieś 15 lat temu i nie spodziewałem się żadnych pułapek. Okazało się, że nie da się „po prostu wrzucić przeglądarki do formularza”: ludzkość jakoś nie potrafiła rzetelnie i powszechnie poradzić sobie z tym zadaniem. Dowolną listę rozwijalną lub przycisk w formularzu można umieścić w dowolnym środowisku GUI, a nawet generować kod wieloplatformowy. Wydawało mi się, że w 2019 roku wyświetlanie kodu HTML również powinno być problemem rozwiązanym uniwersalnie.
Okazało się, że na przykład w wxWidgets standardowy komponent „przeglądarki” jest wieloplatformowym opakowaniem dla „przeglądarki” zależnej od systemu, która w tym przypadku Windowsna przykład oznacza i sytuacja w Windows Formularze nie są lepsze, a wersje nowsze niż IE9 są dostępne tylko za pośrednictwem nietrywialnych . Jak widać, nie jestem jedyną osobą, która przez ostatnie 15 lat była zajęta innymi sprawami – u nas również nic się nie posunęło do przodu.
Następnie stanąłem przed wyborem: zmienić framework lub poszukać alternatywnego komponentu dla przeglądarki. Po pewnym wahaniu zdecydowałem się najpierw wypróbować drugą ścieżkę i szybko trafiłem na projekt , zaprojektowany specjalnie do osadzania Chromium w aplikacjach Python.
Oceń sytuację: Python jest jednym z najpopularniejszych języków programowania na świecie, Chrome jest praktycznie monopolistą na rynku przeglądarek. W tym przypadku CEF Python jest faktycznie obsługiwany przez energię , siły i zdrowia dla niego. Czy nikt już tego nie potrzebuje?
Jednak ostatecznie CEF Python mi nie pomógł: mimo że nawet podstawowy przykład integracji z wxWidgets z repozytorium projektu jest szczerze mówiąc pełen błędów, próbowałem go przez jakiś czas modyfikować, ale nadal nie udało mi się rozwiązać wszystkich problemów, które się pojawiły. Nie będę nawet wdawał się w szczegóły tego tematu; to na to nie zasługuje.
Przyjrzałem się bliżej komponentom opartym na Chromium Embedded Framework i ostatecznie postanowiłem je wypróbować. Ponieważ pracuję prawie cały czas z Windows, perspektywa porzucenia obsługi wielu platform nie robiła na mnie większego wrażenia.
Po nieuniknionym zamieszaniu na początku wszystko poszło znacznie szybciej: połączenie CefSharp i Windows Formularze okazały się zwycięzcą i udało mi się rozwiązać większość problemów technicznych bez żadnych problemów.
O tym, co nie zostało sprawdzone
Możesz spróbować zintegrować FireFoxa ze swoją aplikacją C#, używając komponentu ale nie mogę nic o nim powiedzieć. Standardowy komponent przeglądarki środowiska Qt o nazwie na podstawie , więc prawdopodobnie będzie działać równie dobrze jak CefSharp.
Miłośnicy Qt mogliby pokusić się o komentarz: gdyby tylko wzięli Qt, nie mieliby żadnych problemów. To może być prawdą, ale wxWidgets można również wziąć pod uwagę, jeśli nie jako pierwszą, to na pewno jako drugą opcję przy wyborze struktury GUI dla aplikacji w językach Python lub C++. A moim skromnym zdaniem, coś takiego jak przeglądarka powinna być wbudowana w każdy, mniej lub bardziej rozwinięty framework GUI, bez zbędnego zamieszania.
Biblioteka internetowa
Wróćmy do mojej aplikacji z roboczym tytułem . Dzisiaj wygląda to tak (werble):
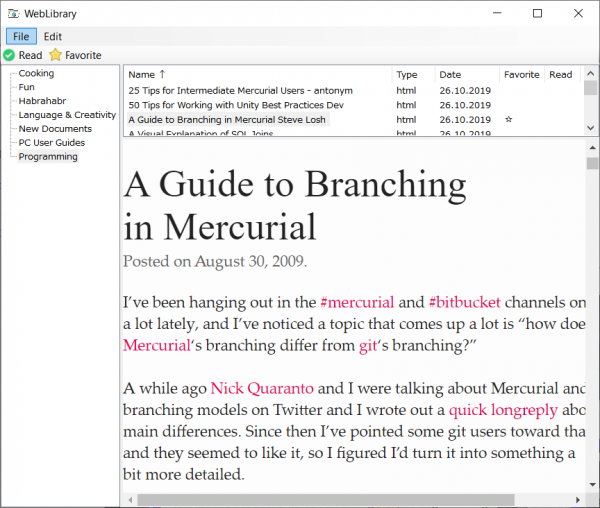
Oprócz czysty i zwięzły interfejs Tutaj zaimplementowano tylko najbardziej podstawowe funkcje:
- Wyświetla dowolny określony katalog w systemie jako bibliotekę dokumentów.
- Przeglądaj dokumenty w oknie przeglądarki. Poruszaj się po liście w standardowy sposób (klawisze kursora, PgUp, PgDn, Home, End), przewijaj w przeglądarce za pomocą klawiszy Spacja i Shift+Spacja.
- Zmiana nazw dokumentów.
- Oznaczaj dokumenty jako przeczytane lub ulubione za pomocą klawiszy skrótu.
- Sortowanie dokumentów według dowolnego pola.
- Odświeża okno aplikacji po każdym wprowadzeniu zmian w folderze biblioteki.
- Zapisz ustawienia okna przy wyjściu.
Może się to wydawać trywialną funkcjonalnością, ale na przykład zachowywanie rozmiarów kolumn w TagSpaces nadal nie jest obsługiwane — najwyraźniej autorzy mają inne priorytety.
Status (przeczytany/ulubiony) jest po prostu przechowywany w nazwie pliku (przeczytany plik) doc.html zostaje przemianowany na doc{R,S}.html). Nie ma tu żadnej synchronizacji, po prostu trzymam bibliotekę w Dropboxie – w końcu to tylko folder z plikami.
Planowane jest dalsze usprawnienie prostych czynności, takich jak przenoszenie i usuwanie plików, a także wdrożenie niestandardowych tagów. Jeśli ktoś chce pomóc, będę rad.
odkrycia
Zupełnie inne. Jak powiedziałem na początku, zadziwiające jest, jak bardzo zestaw narzędzi może różnić się od zestawu narzędzi innej osoby. Dla mnie korzystanie z narzędzia WebResearch jest czymś naturalnym, a jego brak powodował u mnie niemal fizyczny dyskomfort. Jednocześnie, jak widać, nie mam wielu podobnie myślących osób, w przeciwnym razie nie byłoby problemu ze znalezieniem analogów. Z drugiej strony podobne przypadki zdarzają się w przypadku znacznie bardziej popularnego oprogramowania: na przykład Microsoft nie zamierza aktualizować wersji desktopowej programu OneNote, więc zmuszony jestem korzystać z wersji z 2016 roku, a prędzej czy później i z niej będę musiał się gdzieś przenieść.
Zaskakujące jest również to, jak trudno jest poruszać się po obecnym środowisku bibliotek i frameworków. Moja praca rzadko wymaga ode mnie pisania aplikacji desktopowych od początku do końca i założyłem, że do mojego zadania (jedno okno, trzy komponenty, trywialne interakcje) sprawdzi się dosłownie każde narzędzie w dowolnym języku programowania. Po prostu bierzemy cokolwiek i realizujemy to w ciągu kilku dni.
Okazało się, że rzeczywistość jest znacznie mniej przyjazna, a problemy mogą się pojawić zupełnie niespodziewanie. Załóżmy, że mam dwa rozdzielacze, których mogę użyć do rozciągnięcia okna przeglądarki. Cóż, przywrócenie ich pozycji po załadowaniu do wxWidgets jest niezwykle trudne, ponieważ system ustawia je do pozycji domyślnych po wystąpieniu niemal wszystkich zdarzeń, jakie są mi znane, i muszę wykonać wiele różnych sztuczek, aby osiągnąć to, czego potrzebuję. Kto by pomyślał?
Z drugiej strony jasne jest, że w Windows Forms został zaprojektowany z myślą o interfejsach biznesowych. Prawie wszystko, czego potrzebowałem, było dostępne od razu: zapisywanie i przywracanie ustawień aplikacji, przyjazny dla użytkownika interfejs komponentów (na przykład nie spodziewałem się, że komponent TreeView będzie mógł zostać zapytany o pełną ścieżkę od elementu głównego do dowolnego elementu potomnego w postaci ciągu znaków) oraz zaawansowane funkcje, takie jak śledzenie zmian zawartości folderu.
W każdym razie czas nie został zmarnowany, a efekt końcowy można uznać za zadowalający, więc czego więcej można chcieć od życia, prawda?
Źródło: www.habr.com
