

W lutym-marcu 2019 roku odbył się konkurs na ranking kanału społecznościowego , w którym nasza drużyna zajęła pierwsze miejsce. W tym artykule opowiem o organizacji zawodów, metodach, których próbowaliśmy, i ustawieniach catboost do trenowania na big data.

Hackathon SNA
Hackathon pod tą nazwą odbywa się już po raz trzeci. Został zorganizowany przez portal społecznościowy ok.ru, więc zadanie i dane są bezpośrednio związane z tym portalem społecznościowym.
W tym przypadku SNA (analiza sieci społecznościowych) jest właściwie rozumiana nie jako analiza grafu społecznościowego, lecz raczej jako analiza sieci społecznościowej.
- W 2014 r. zadaniem było przewidzenie liczby polubień danego posta.
- W roku 2016 zadanie VVZ (możesz je znać) jest bliższe analizie grafu społecznego.
- W 2019 r. ranking kanału użytkownika opierał się na prawdopodobieństwie, że użytkownik polubi dany post.
Nie mogę powiedzieć o 2014 roku, ale w 2016 i 2019 roku, oprócz umiejętności analizy danych, wymagane były również umiejętności big data. Myślę, że to połączenie uczenia maszynowego i zadań przetwarzania big data przyciągnęło mnie do tych konkursów, a moje doświadczenie w tych obszarach pomogło mi wygrać.
mlbootcamp
W 2019 roku konkurs organizowany był na platformie .
Konkurs rozpoczął się online 7 lutego i składał się z 3 zadań. Każdy mógł zarejestrować się na stronie internetowej, pobrać i załaduj samochód na kilka godzin. Pod koniec etapu online 15 marca, 15 najlepszych z każdego konkursu zostało zaproszonych do biura Mail.ru na etap offline, który odbył się od 30 marca do 1 kwietnia.
Zadanie
Dane źródłowe dostarczają identyfikatory użytkownika (userId) i identyfikatory postów (objectId). Jeśli użytkownikowi pokazano post, dane zawierają wiersz zawierający userId, objectId, reakcje użytkownika na ten post (feedback) oraz zestaw różnych atrybutów lub linków do obrazów i tekstów.
| identyfikator użytkownika | identyfikator obiektu | Identyfikator właściciela | informacja zwrotna | zdjęcia |
|---|---|---|---|---|
| 3555 | 22 | 5677 | [polubione, kliknięte] | [hash1] |
| 12842 | 55 | 32144 | [nie podobało się] | [hasz2,hasz3] |
| 13145 | 35 | 5677 | [kliknięto, udostępniono ponownie] | [hash2] |
Zestaw danych testowych zawiera podobną strukturę, ale brakuje pola feedback. Zadanie polega na przewidzeniu obecności reakcji „liked” w polu feedback.
Plik do przesłania ma następującą strukturę:
| identyfikator użytkownika | SortowanaLista[objectId] |
|---|---|
| 123 | 78,13,54,22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
Metryka – średnia wartość ROC AUC dla różnych użytkowników.
Bardziej szczegółowy opis danych można znaleźć na stronieMożna tam również pobrać dane, w tym testy i zdjęcia.
Etap online
Na etapie online zadanie zostało podzielone na 3 części
- — obejmuje wszystkie elementy z wyjątkiem obrazów i tekstów;
- — zawiera wyłącznie informacje o obrazach;
- — zawiera informacje wyłącznie o tekstach.
Etap offline
Na etapie offline dane obejmowały wszystkie cechy, podczas gdy teksty i obrazy były skąpe. Liczba wierszy w zestawie danych, które były już liczne, wzrosła 1,5-krotnie.
Rozwiązanie problemu
Ponieważ pracuję nad CV w pracy, zacząłem swoją podróż w tym konkursie od zadania „Images”. Dostarczone dane to userId, objectId, ownerId (grupa, w której opublikowano post), znaczniki czasu utworzenia i wyświetlenia posta oraz, oczywiście, obraz do tego posta.
Po wygenerowaniu kilku cech opartych na znacznikach czasu, następnym pomysłem było wzięcie przedostatniej warstwy sieci neuronowej wstępnie wytrenowanej w imagenet i wprowadzenie tych osadzeń do wzmocnienia.
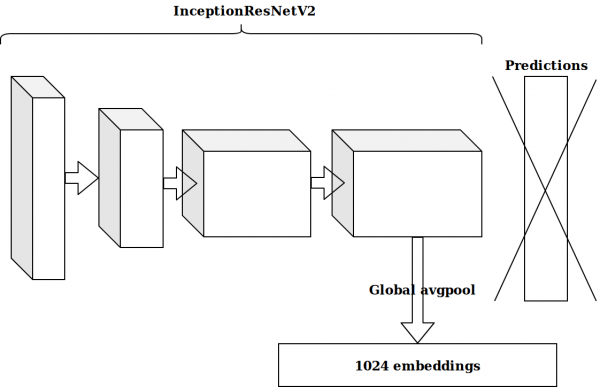
Wyniki nie były imponujące. Osadzenia z sieci neuronowej imagenet są nieistotne, pomyślałem, muszę napisać własny autoenkoder.
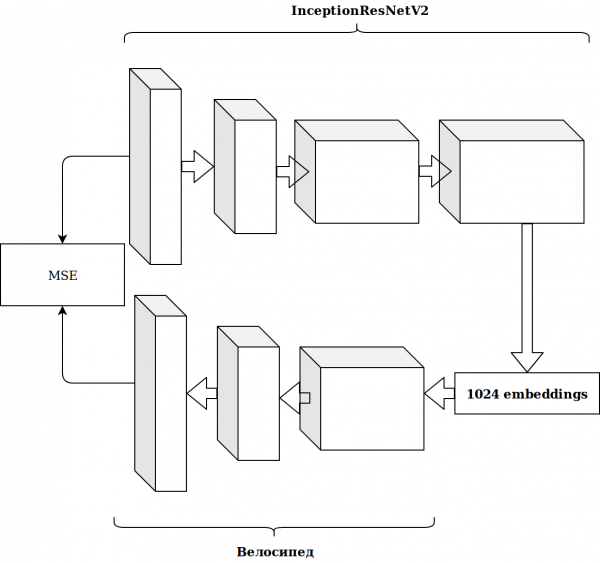
Zajęło to dużo czasu, a efekt nie uległ poprawie.
Generowanie funkcji
Praca z obrazami jest bardzo czasochłonna, więc postanowiłem zrobić coś prostszego.
Jak widać, w zestawie danych jest kilka cech kategorycznych, a żeby nie zawracać sobie tym głowy, po prostu wziąłem catboost. Rozwiązanie było doskonałe, bez żadnych ustawień od razu dostałem się do pierwszej linii tabeli liderów.
Danych jest całkiem sporo i są one zamieszczone w formacie Parquet, więc nie zastanawiając się dwa razy, wziąłem Scalę i zacząłem wszystko zapisywać w Sparku.
Najprostsze funkcje, które dały większy wzrost niż osadzanie obrazów:
- ile razy objectId, userId i ownerId pojawiły się w danych (powinny być skorelowane z popularnością);
- ile postów userId zobaczył od ownerId (powinno być zgodne z zainteresowaniem użytkownika grupą);
- ile unikalnych identyfikatorów użytkowników wyświetliło posty właściciela (odzwierciedla wielkość grupy odbiorców).
Ze znaczników czasu można było uzyskać godzinę, o której użytkownik przeglądał kanał (rano/dzień/wieczór/noc). Łącząc te kategorie, możesz kontynuować generowanie funkcji:
- ile razy użytkownik Id logował się wieczorem;
- o której godzinie ten post jest najczęściej wyświetlany (objectId) itd.
Wszystko to stopniowo poprawiało metrykę. Ale rozmiar zestawu danych treningowych wynosi około 20M rekordów, więc dodawanie cech znacznie spowolniło trening.
Zmieniłem podejście do korzystania z danych. Chociaż dane są zależne od czasu, nie zauważyłem żadnych oczywistych wycieków informacji „w przyszłości”, ale na wszelki wypadek rozbiłem to w ten sposób:
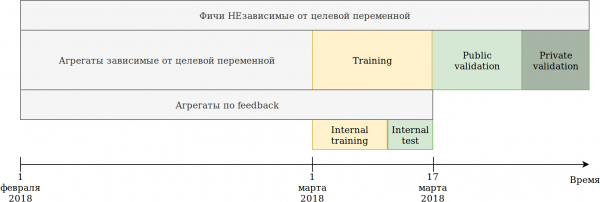
Zestaw szkoleniowy, który nam udostępniono (luty i 2 tygodnie marca) podzielony był na 2 części.
Wytrenowałem model na danych z ostatnich N dni. Zbudowałem agregacje opisane powyżej na wszystkich danych, w tym testowych. W tym samym czasie pojawiły się dane, na których można zbudować różne kodowania zmiennej docelowej. Najprostszym podejściem jest ponowne wykorzystanie kodu, który już tworzy nowe funkcje i po prostu przekazanie mu danych, na których trening nie będzie wykonywany, a target = 1.
W ten sposób uzyskano następujące cechy:
- Ile razy użytkownik userId widział post w grupie ownerId;
- Ile razy użytkownik userId polubił post grupy ownerId;
- Procent postów, które użytkownik userId polubił, pochodzących od właściciela ownerId.
Okazało się, że średnie kodowanie docelowe na częściach zbioru danych przez różne kombinacje cech kategorycznych. W zasadzie catboost buduje również kodowanie docelowe i z tego punktu widzenia nie ma żadnej korzyści, ale na przykład stało się możliwe policzenie liczby unikalnych użytkowników, którzy polubili posty w tej grupie. Jednocześnie osiągnięto główny cel - mój zbiór danych zmniejszył się kilkukrotnie i można było kontynuować generowanie cech.
Podczas gdy catboost może budować kodowanie tylko przez reakcję like, feedback ma inne reakcje: reshared, disliked, unliked, clicked, ignored, kodowania, dla których można to zrobić ręcznie. Przeliczyłem wszystkie możliwe agregaty i odfiltrowałem funkcje o niskiej ważności, aby nie zawyżać zestawu danych.
W tym czasie byłem na pierwszym miejscu z dużą przewagą. Jedyne, co mnie martwiło, to to, że osadzenia obrazów nie dawały prawie żadnego wzrostu. Wpadłem na pomysł, aby oddać wszystko catboost. Klastrujemy obrazy za pomocą Kmeans i otrzymujemy nową kategorię imageCat.
Poniżej przedstawiono kilka klas po ręcznym przefiltrowaniu i scaleniu klastrów uzyskanych z KMeans.
Na podstawie imageCat generujemy:
- Nowe funkcje kategorii:
- Który imageCat był najczęściej oglądany przez użytkownika o danym identyfikatorze;
- Który imageCat najczęściej pokazuje ownerId;
- Który imageCat cieszył się największą popularnością według userId;
- Różne liczniki:
- Ile unikalnych wyświetleń imageCat userId;
- Około 15 podobnych funkcji plus kodowanie docelowe opisane powyżej.
SMS-y
Byłem zadowolony z wyników konkursu graficznego i postanowiłem spróbować swoich sił w tekstach. Wcześniej nie pracowałem z tekstami zbyt wiele i głupio zmarnowałem dzień na tf-idf i svd. Potem zobaczyłem baseline z doc2vec, który robi dokładnie to, czego potrzebuję. Po nieznacznym dostosowaniu parametrów doc2vec uzyskałem osadzenia tekstu.
A potem po prostu ponownie wykorzystałem kod dla obrazów, w którym zastąpiłem osadzenia obrazów osadzeniami tekstu. W rezultacie zdobyłem 2. miejsce w konkursie tekstowym.
System współpracy
Pozostał mi jeszcze jeden konkurs, w którym nie wziąłem udziału, a sądząc po AUC w tabeli wyników, wyniki tego konkretnego konkursu miały mieć największy wpływ na etap offline.
Wziąłem wszystkie cechy, które były w oryginalnych danych, wybrałem te kategoryczne i obliczyłem te same agregaty, co dla obrazów, z wyjątkiem cech na samych obrazach. Po prostu umieszczając to w catboost, dostałem się na 2. miejsce.
Pierwsze kroki w optymalizacji catboost
Byłem zadowolony z jednego pierwszego miejsca i dwóch drugich miejsc, ale zdawałem sobie sprawę, że nie zrobiłem niczego szczególnego, co oznaczało, że mogę spodziewać się utraty pozycji.
Celem konkursu jest ocena postów w obrębie danego użytkownika, ale przez cały czas rozwiązywałem problem klasyfikacji, czyli optymalizowałem niewłaściwy wskaźnik.
Podam prosty przykład:
| identyfikator użytkownika | identyfikator obiektu | przepowiednia | podstawowa prawda |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
Zróbmy małą przebudowę
| identyfikator użytkownika | identyfikator obiektu | przepowiednia | podstawowa prawda |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
Otrzymujemy następujące wyniki:
| Model | AUC | Użytkownik1 AUC | Użytkownik2 AUC | średnia AUC |
|---|---|---|---|---|
| opcja 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| opcja 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Jak widać, poprawa ogólnego wskaźnika AUC nie oznacza poprawy średniego wskaźnika AUC w obrębie użytkownika.
Catboost prosto z pudełka. Czytałem o metrykach rankingowych, podczas korzystania z catboost i ustawienia YetiRankPairwise do trenowania przez noc. Wynik nie był imponujący. Uznając, że nie trenowałem wystarczająco, zmieniłem funkcję błędu na QueryRMSE, która według dokumentacji catboost, zbiega się szybciej. Ostatecznie uzyskałem takie same wyniki, jak podczas trenowania klasyfikacji, ale zespoły tych dwóch modeli dały dobry wzrost, co pozwoliło mi zająć pierwsze miejsce we wszystkich trzech konkursach.
5 minut przed zamknięciem etapu online konkursu „Collaborative Systems” Sergey Shalnov przesunął mnie na drugie miejsce. Resztę drogi przeszliśmy razem.
Przygotowanie do etapu offline
Zwycięstwo w etapie online zagwarantowało nam kartę graficzną RTX 2080 TI, ale główna nagroda w wysokości 300 000 rubli i prawdopodobnie pierwsze miejsce w finale zmusiły nas do pracy przez te 2 tygodnie.
Jak się okazało, Sergey również używał catboost. Wymienialiśmy się pomysłami i funkcjami, a ja dowiedziałem się o który zawierał odpowiedzi na wiele moich pytań, nawet na te, na które wówczas jeszcze nie miałem odpowiedzi.
Przeglądanie raportu doprowadziło mnie do pomysłu, że wszystkie parametry powinny zostać przywrócone do wartości domyślnych, a ustawienia powinny zostać wykonane bardzo ostrożnie i dopiero po naprawieniu zestawu cech. Teraz jeden trening zajął około 15 godzin, ale jeden model zdołał uzyskać wynik lepszy niż zespół z rankingiem.
Generowanie funkcji
W konkursie Collaborative Systems wiele funkcji jest uznawanych za ważne dla modelu. Na przykład, audytwagi_spark_svd — najważniejsza cecha, ale nie ma informacji, co ona oznacza. Pomyślałem, że warto byłoby obliczyć różne agregaty na podstawie ważnych cech. Na przykład średnia auditweights_spark_svd według użytkownika, grupy, obiektu. To samo można obliczyć dla danych, na których nie przeprowadzono treningu i target = 1, tj. średnia audytwagi_spark_svd przez użytkownika według obiektów, które mu się podobały. Ważne cechy, oprócz audytwagi_spark_svd, było ich kilka. Oto niektóre z nich:
- audytwagiCtrPłeć
- audytwagiCtrHigh
- użytkownikWłaścicielLicznikUtwórzPolubienia
Na przykład wartość średnia audytwagiCtrPłeć według userId okazało się ważną cechą, podobnie jak średnia wartość użytkownikWłaścicielLicznikUtwórzPolubienia przez userId+ownerId. To powinno już skłonić Cię do myślenia o potrzebie zrozumienia znaczenia pól.
Równie ważnymi cechami były audytwagiLiczba polubień и audytwagiPokazyLiczbaDzieląc jedno przez drugie, otrzymujemy jeszcze ważniejszą cechę.
Wycieki danych
Konkurencja i produkcja modelu to zupełnie różne zadania. Podczas przygotowywania danych bardzo trudno jest uwzględnić wszystkie szczegóły i nie przekazać niektórych nietrywialnych informacji o zmiennej docelowej w teście. Jeśli tworzymy rozwiązanie produkcyjne, będziemy starać się unikać wycieków danych podczas trenowania modelu. Ale jeśli chcemy wygrać konkurencję, wycieki danych są najlepszymi cechami.
Po przeanalizowaniu danych można zauważyć, że wartości objectId audytwagiLiczba polubień и audytwagiPokazyLiczba zmiana, co oznacza, że stosunek maksymalnych wartości tych cech będzie odzwierciedlał konwersję postu znacznie lepiej niż stosunek w chwili wyświetlania.
Pierwszy przeciek, jaki znaleźliśmy, to ten auditweightsLikesCountMax/auditweightsShowsCountMax.
Co jeśli przyjrzymy się danym bliżej? Sortujemy według daty wyświetlania i otrzymujemy:
| identyfikator obiektu | identyfikator użytkownika | audytwagiPokazyLiczba | audytwagiLiczba polubień | cel (został polubiony) |
|---|---|---|---|---|
| 1 | 1 | 12 | 3 | prawdopodobnie nie |
| 1 | 2 | 15 | 3 | prawdopodobnie tak |
| 1 | 3 | 16 | 4 |
Byłem zaskoczony, gdy znalazłem pierwszy taki przykład i okazało się, że moje przewidywanie się nie sprawdziło. Ale biorąc pod uwagę fakt, że maksymalne wartości tych cech w obrębie obiektu dawały wzrost, nie byliśmy leniwi i postanowiliśmy znaleźć audytwagiPokazujeLiczbaNastępny и audytwagiLiczba polubieńNastępny, czyli wartości w następnym momencie czasu. Dodając cechę
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext) Gwałtownie zwiększyliśmy prędkość.
Podobne przecieki mogłyby zostać wykorzystane, gdyby dla nich znaleziono następujące wartości użytkownikWłaścicielLicznikUtwórzPolubienia w ramach userId+ownerId i na przykład, audytwagiCtrPłeć w ramach objectId+userGender. Znaleźliśmy 6 podobnych pól z przeciekami i wyodrębniliśmy z nich jak najwięcej informacji.
Do tego czasu wycisnęliśmy maksimum informacji z funkcji współpracy, ale nie wróciliśmy do konkursów na obrazy i teksty. Wpadł nam do głowy świetny pomysł, aby sprawdzić: ile dają funkcje bezpośrednio na obrazach lub tekstach w odpowiednich konkursach?
Nie było żadnych przecieków w konkursach na obrazy i tekst, ale do tego czasu przywróciłem domyślne parametry catboost, uporządkowałem kod i dodałem kilka funkcji. Rezultat był następujący:
| decyzja | szybko |
|---|---|
| Maksymalnie z obrazami | 0.6411 |
| Maksimum bez obrazków | 0.6297 |
| Wynik drugiego miejsca | 0.6295 |
| decyzja | szybko |
|---|---|
| Maksymalnie z tekstami | 0.666 |
| Maksimum bez tekstów | 0.660 |
| Wynik drugiego miejsca | 0.656 |
| decyzja | szybko |
|---|---|
| Maksymalnie we współpracy | 0.745 |
| Wynik drugiego miejsca | 0.723 |
Stało się oczywiste, że trudno będzie wycisnąć wiele z tekstów i obrazów, więc po wypróbowaniu kilku najciekawszych pomysłów zrezygnowaliśmy z ich realizacji.
Dalsza generacja cech w systemach współpracy nie przyniosła żadnych korzyści i zaczęliśmy klasyfikować. Na etapie online, klasyfikacja i zespół rankingowy przyniosły mi niewielki zysk, jak się okazało, ponieważ niedostatecznie wytrenowałem klasyfikację. Żadna z funkcji błędów, w tym YetiRanlPairwise, nawet nie zbliżyła się do wyniku, jaki dał LogLoss (0,745 w porównaniu z 0,725). Była nadzieja dla QueryCrossEntropy, którego nie udało się uruchomić.
Etap offline
Na etapie offline struktura danych pozostała taka sama, zaszły jednak pewne drobne zmiany:
- identyfikatory userId, objectId, ownerId zostały ponownie zrandomizowane;
- Usunięto kilka znaków i zmieniono nazwy kilku z nich;
- Ilość danych wzrosła około 1,5 raza.
Oprócz wymienionych trudności, był jeden duży plus: zespołowi przydzielono duży serwer z RTX 2080TI. Długo cieszyłem się htopem.
Był tylko jeden pomysł — po prostu odtworzyć to, co już istnieje. Po spędzeniu kilku godzin na konfigurowaniu środowiska na serwerze, zaczęliśmy stopniowo sprawdzać, czy wyniki zostały odtworzone. Głównym problemem, na jaki natrafiliśmy, był wzrost wolumenu danych. Postanowiliśmy nieco zmniejszyć obciążenie i ustawić parametr catboost ctr_complexity=1. To nieznacznie zmniejsza prędkość, ale mój model zaczął działać, wynik był dobry — 0,733. Sergey, w przeciwieństwie do mnie, nie podzielił danych na 2 części i nie trenował na wszystkich danych, chociaż dało to najlepszy wynik na etapie online, było wiele trudności na etapie offline. Jeśli weźmiesz wszystkie wygenerowane przez nas funkcje i spróbujesz wcisnąć je do catboost „na wprost”, to nic nie zadziałałoby również na etapie online. Sergey przeprowadził optymalizację typu, na przykład konwertując typy float64 na float32. możesz znaleźć informacje o optymalizacji pamięci w pandas. Na koniec Sergey trenował na CPU na wszystkich danych i uzyskał około 0,735.
Te wyniki wystarczyły do zwycięstwa, ale ukrywaliśmy naszą prawdziwą prędkość i nie mogliśmy mieć pewności, że inne drużyny nie zrobią tego samego.
Walcz do końca
Strojenie catboost
Nasze rozwiązanie zostało w pełni odtworzone, dodaliśmy dane tekstowe i funkcje graficzne, więc pozostało tylko dostroić parametry catboost. Sergey trenował na CPU z niewielką liczbą iteracji, a ja trenowałem z ctr_complexity=1. Pozostał jeden dzień i jeśli po prostu dodamy iteracje lub zwiększymy ctr_complexity, moglibyśmy osiągnąć jeszcze lepszą prędkość rano i chodzić cały dzień.
Na etapie offline wyniki można było bardzo łatwo ukryć, po prostu wybierając mniej niż idealne rozwiązanie na stronie. Spodziewaliśmy się drastycznych zmian w tabeli liderów w ostatnich minutach przed zamknięciem zgłoszeń i postanowiliśmy nie przerywać.
Z filmu Anny dowiedziałem się, że aby poprawić jakość modelu najlepiej wybrać następujące parametry:
- wskaźnik_nauczenia — Wartość domyślna jest obliczana na podstawie rozmiaru zestawu danych. Zwiększenie learning_rate wymaga zwiększenia liczby iteracji.
- l2_liść_rejestr — Współczynnik regularizacji, wartość domyślna wynosi 3, zaleca się wybór wartości od 2 do 30. Zmniejszenie wartości prowadzi do zwiększenia nadmiernego dopasowania.
- temperatura_bagażu — dodaje randomizację do wag obiektów w próbie. Wartość domyślna to 1, przy której wagi są wybierane z rozkładu wykładniczego. Zmniejszenie wartości prowadzi do wzrostu nadmiernego dopasowania.
- losowa_siła — Wpływa na wybór podziałów w określonej iteracji. Im wyższa wartość random_strength, tym większa szansa na wybór podziału o niskiej ważności. Przy każdej kolejnej iteracji losowość maleje. Zmniejszenie wartości prowadzi do wzrostu nadmiernego dopasowania.
Inne parametry mają znacznie mniejszy wpływ na końcowy wynik, więc nie próbowałem ich wybierać. Jedna iteracja treningu na moim zestawie danych GPU z ctr_complexity=1 zajęła 20 minut, a wybrane parametry na zredukowanym zestawie danych były nieznacznie inne od optymalnych na pełnym zestawie danych. Ostatecznie wykonałem około 30 iteracji na 10% danych, a następnie około 10 kolejnych iteracji na wszystkich danych. Wynik wyglądał mniej więcej tak:
- wskaźnik_nauczenia Zwiększyłem o 40% wartość domyślną;
- l2_liść_rejestr pozostawiono tak jak jest;
- temperatura_bagażu и losowa_siła zmniejszono do 0,8.
Można wnioskować, że model został niedostatecznie wytrenowany przy użyciu domyślnych parametrów.
Byłem bardzo zaskoczony, gdy zobaczyłem wynik na tablicy wyników:
| Model | Model 1 | Model 2 | Model 3 | ensemble |
|---|---|---|---|---|
| Bez strojenia | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| Z tuningiem | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
Doszedłem do wniosku, że jeśli nie ma potrzeby szybkiego zastosowania modelu, to lepiej zastąpić dobór parametrów zespołem kilku modeli opartych na niezoptymalizowanych parametrach.
Sergey optymalizował rozmiar zestawu danych, aby uruchomić go na GPU. Najprostszą opcją jest odcięcie części danych, ale można to zrobić na kilka sposobów:
- stopniowo usuwaj najstarsze dane (na początku lutego), aż zbiór danych zacznie mieścić się w pamięci;
- usuń funkcje o najniższym znaczeniu;
- usuń userIds, dla których istnieje tylko jeden rekord;
- pozostaw tylko te identyfikatory użytkowników, które znajdują się w teście.
I na koniec stwórz zestaw ze wszystkich dostępnych opcji.
Ostatni zespół
Późnym wieczorem ostatniego dnia opublikowaliśmy zbiór naszych modeli, który dał 0,742. W nocy uruchomiłem mój model z ctr_complexity=2 i zamiast 30 minut, trenował przez 5 godzin. Dopiero o 4 rano zakończył liczenie i stworzyłem ostatni zbiór, który dał 0,7433 na publicznej tablicy wyników.
Ze względu na różne podejścia do rozwiązania problemu, nasze przewidywania nie były silnie skorelowane, co dało dobry wzrost w zespole. Aby uzyskać dobry zespół, lepiej jest użyć surowych przewidywań modelu predict(prediction_type='RawFormulaVal') i ustawić scale_pos_weight=neg_count/pos_count.
Możesz to zobaczyć na stronie internetowej .
Inne rozwiązania
Wiele zespołów podążało za kanonami algorytmów systemów rekomendacyjnych. Ja, nie będąc ekspertem w tej dziedzinie, nie mogę ich ocenić, ale pamiętam 2 ciekawe rozwiązania.
- Nikołaj, jako pracownik Mail.ru, nie odebrał żadnej nagrody, więc jego celem nie było osiągnięcie maksymalnej prędkości, ale uzyskanie rozwiązania łatwo skalowalnego.
- Decyzja jury, które przyznało nagrodę zespołowi, opiera się na: , pozwoliło nam na bardzo dobre grupowanie obrazów bez konieczności ręcznej pracy.
wniosek
Co najbardziej utkwiło mi w pamięci:
- Jeśli Twoje dane mają cechy kategoryczne i wiesz, jak poprawnie wykonać kodowanie docelowe, nadal lepiej będzie wypróbować catboost.
- Jeśli bierzesz udział w konkursie, nie powinieneś tracić czasu na wybieranie parametrów innych niż learning_rate i iterations. Szybszym rozwiązaniem jest utworzenie zespołu kilku modeli.
- Boostings może uczyć się na GPU. Catboost może uczyć się bardzo szybko na GPU, ale zużywa dużo pamięci.
- Podczas rozwijania i testowania pomysłów lepiej jest ustawić niewielki rsm~=0.2 (tylko CPU) i ctr_complexity=1.
- W przeciwieństwie do innych zespołów, nasz zespół modeli dał nam dużego kopa. Wymienialiśmy się tylko pomysłami i pisaliśmy w różnych językach. Mieliśmy różne podejścia do partycjonowania danych i myślę, że każdy z nich miał swoje własne błędy.
- Nie jest jasne, dlaczego optymalizacja rankingowa dała gorsze wyniki niż optymalizacja klasyfikacji.
- Zdobyłem pewne doświadczenie w pracy z tekstami i zrozumiałem, jak tworzone są systemy rekomendacji.

Dziękujemy organizatorom za emocje, wiedzę i nagrody.
Źródło: www.habr.com
