

Boa tarde Meu nome é Danil Lipovoy, nossa equipe da Sbertech começou a usar HBase como armazenamento de dados operacionais. Ao longo do seu estudo, acumulou-se uma experiência que quis sistematizar e descrever (esperamos que seja útil para muitos). Todos os experimentos abaixo foram realizados com as versões 1.2.0-cdh5.14.2 e 2.0.0-cdh6.0.0-beta1 do HBase.
- Arquitetura geral
- Gravando dados no HBASE
- Lendo dados do HBASE
- Cache de dados
- Processamento de dados em lote MultiGet/MultiPut
- Estratégia para dividir tabelas em regiões (divisão)
- Tolerância a falhas, compactação e localidade de dados
- Configurações e desempenho
- Teste de estresse
- Descobertas
1. Arquitetura geral
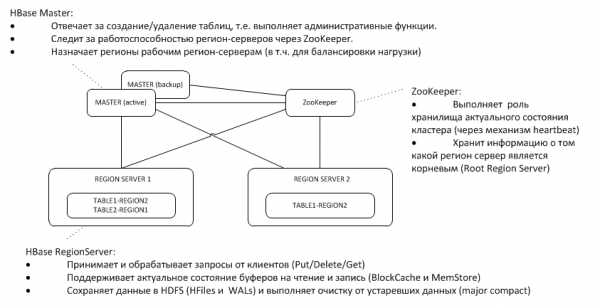
O mestre backup escuta a pulsação do ativo no nó ZooKeeper e, em caso de desaparecimento, assume as funções do mestre.
2. Grave dados no HBASE
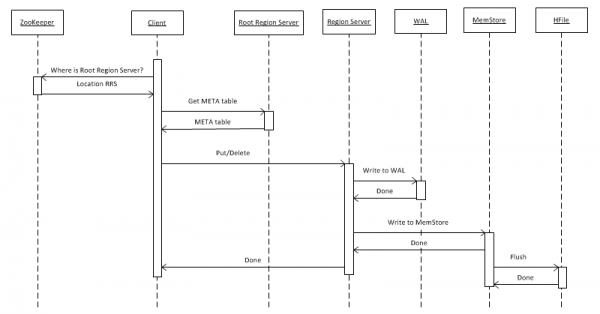
Primeiro, vejamos o caso mais simples - escrever um objeto de valor-chave em uma tabela usando put(rowkey). O cliente deve primeiro descobrir onde está localizado o Root Region Server (RRS), que armazena a tabela hbase:meta. Ele recebe essas informações do ZooKeeper. Depois disso, ele acessa o RRS e lê a tabela hbase:meta, da qual extrai informações sobre qual RegionServer (RS) é responsável por armazenar os dados de uma determinada rowkey na tabela de interesse. Para uso futuro, a metatabela é armazenada em cache pelo cliente e, portanto, as chamadas subsequentes são mais rápidas, diretamente para o RS.
A seguir, o RS, tendo recebido uma solicitação, primeiro a grava no WriteAheadLog (WAL), necessário para a recuperação em caso de travamento. Em seguida, salva os dados no MemStore. Este é um buffer na memória que contém um conjunto classificado de chaves para uma determinada região. Uma tabela pode ser dividida em regiões (partições), cada uma contendo um conjunto disjunto de chaves. Isso permite colocar regiões em servidores diferentes para obter maior desempenho. Contudo, apesar da obviedade desta afirmação, veremos mais tarde que isto não funciona em todos os casos.
Após colocar uma entrada no MemStore, uma resposta é retornada ao cliente informando que a entrada foi salva com sucesso. Porém, na realidade, ele é armazenado apenas em um buffer e só chega ao disco após um determinado período de tempo ou quando é preenchido com novos dados.
Ao realizar a operação “Excluir”, os dados não são excluídos fisicamente. Eles são simplesmente marcados como excluídos, e a própria destruição ocorre no momento da chamada da função compacta principal, que é descrita com mais detalhes no parágrafo 7.
Os arquivos no formato HFile são acumulados no HDFS e de vez em quando é iniciado o processo de compactação menor, que simplesmente mescla arquivos pequenos em arquivos maiores sem excluir nada. Com o tempo, isso se transforma em um problema que só aparece na leitura dos dados (voltaremos a isso um pouco mais tarde).
Além do processo de carregamento descrito acima, existe um procedimento muito mais eficaz, que talvez seja o ponto forte deste banco de dados - BulkLoad. Está no fato de formarmos HFiles de forma independente e colocá-los no disco, o que nos permite dimensionar perfeitamente e atingir velocidades muito decentes. Na verdade, a limitação aqui não é o HBase, mas as capacidades do hardware. Abaixo estão os resultados de inicialização em um cluster que consiste em 16 RegionServers e 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads), HBase versão 1.2.0-cdh5.14.2.
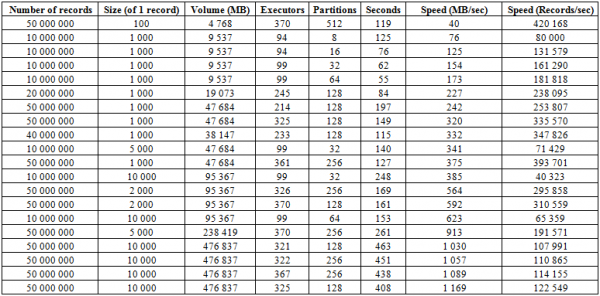
Aqui você pode ver que ao aumentar o número de partições (regiões) na tabela, bem como de executores Spark, obtemos um aumento na velocidade de download. Além disso, a velocidade depende do volume de gravação. Blocos grandes aumentam em MB/s, blocos pequenos no número de registros inseridos por unidade de tempo, sendo todos os outros fatores iguais.
Você também pode começar a carregar em duas tabelas ao mesmo tempo e obter o dobro da velocidade. Abaixo você pode ver que a gravação de blocos de 10 KB em duas tabelas ao mesmo tempo ocorre a uma velocidade de cerca de 600 MB/s em cada uma (total 1275 MB/s), o que coincide com a velocidade de gravação em uma tabela de 623 MB/s (consulte Nº 11 acima)

Mas a segunda execução com registros de 50 KB mostra que a velocidade de download está crescendo ligeiramente, o que indica que está se aproximando dos valores limites. Ao mesmo tempo, você precisa ter em mente que praticamente não há carga criada no próprio HBASE, tudo o que é necessário é primeiro fornecer os dados do hbase: meta e, após alinhar o HFiles, redefinir os dados do BlockCache e salvar o Buffer MemStore para disco, se não estiver vazio.
3. Lendo dados do HBASE
Se assumirmos que o cliente já possui todas as informações de hbase:meta (ver ponto 2), então a solicitação vai diretamente para o RS onde a chave necessária está armazenada. Primeiro, a pesquisa é realizada no MemCache. Independentemente de haver ou não dados, a busca também é realizada no buffer BlockCache e, se necessário, em HFiles. Se os dados forem encontrados no arquivo, eles serão colocados no BlockCache e serão retornados mais rapidamente na próxima solicitação. A pesquisa no HFile é relativamente rápida graças ao uso do filtro Bloom, ou seja, depois de ler uma pequena quantidade de dados, ele determina imediatamente se este arquivo contém a chave necessária e, caso contrário, passa para o próximo.
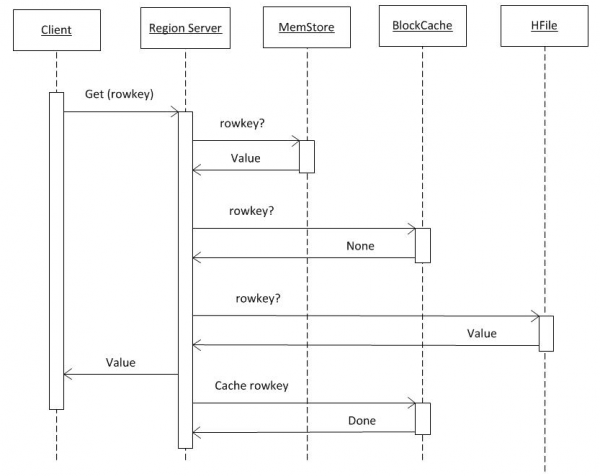
Tendo recebido dados destas três fontes, o RS gera uma resposta. Em particular, ele pode transferir várias versões encontradas de um objeto de uma só vez se o cliente solicitar o controle de versão.
4. Cache de dados
Os buffers MemStore e BlockCache ocupam até 80% da memória RS alocada no heap (o restante é reservado para tarefas de serviço RS). Se o modo de uso típico é tal que os processos escrevem e leem imediatamente os mesmos dados, então faz sentido reduzir o BlockCache e aumentar o MemStore, porque Quando os dados de gravação não chegam ao cache para leitura, o BlockCache será usado com menos frequência. O buffer BlockCache consiste em duas partes: LruBlockCache (sempre no heap) e BucketCache (geralmente fora do heap ou em um SSD). BucketCache deve ser usado quando há muitas solicitações de leitura e elas não cabem no LruBlockCache, o que leva ao trabalho ativo do Garbage Collector. Ao mesmo tempo, não se deve esperar um aumento radical no desempenho do uso do cache de leitura, mas voltaremos a isso no parágrafo 8
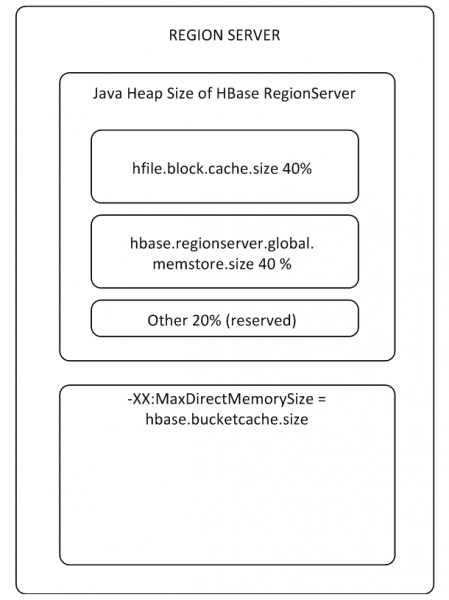
Existe um BlockCache para todo o RS e um MemStore para cada tabela (um para cada família de colunas).
Как em teoria, ao escrever, os dados não vão para o cache e, de fato, tais parâmetros CACHE_DATA_ON_WRITE para a tabela e “Cache DATA on Write” para RS são definidos como falsos. No entanto, na prática, se gravarmos dados no MemStore, depois liberá-los para o disco (limpando-os) e, em seguida, excluir o arquivo resultante e, ao executar uma solicitação get, receberemos os dados com êxito. Além disso, mesmo se você desabilitar completamente o BlockCache e preencher a tabela com novos dados, depois redefinir o MemStore para o disco, excluí-los e solicitá-los de outra sessão, eles ainda serão recuperados de algum lugar. Portanto, o HBase armazena não apenas dados, mas também mistérios misteriosos.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
O parâmetro "Cache DATA on Read" está definido como falso. Se você tiver alguma ideia, seja bem-vindo para discuti-la nos comentários.
5. Processamento de dados em lote MultiGet/MultiPut
Processar solicitações únicas (Get/Put/Delete) é uma operação bastante cara, portanto, se possível, você deve combiná-las em uma Lista ou Lista, o que permite obter um aumento significativo de desempenho. Isto é especialmente verdadeiro para a operação de gravação, mas durante a leitura existe a seguinte armadilha. O gráfico abaixo mostra o tempo para ler 50 registros do MemStore. A leitura foi realizada em uma thread e o eixo horizontal mostra a quantidade de chaves da requisição. Aqui você pode ver que ao aumentar para mil chaves em uma solicitação, o tempo de execução cai, ou seja, a velocidade aumenta. Porém, com o modo MSLAB habilitado por padrão, após esse limite começa uma queda radical no desempenho, e quanto maior a quantidade de dados no registro, maior será o tempo de operação.
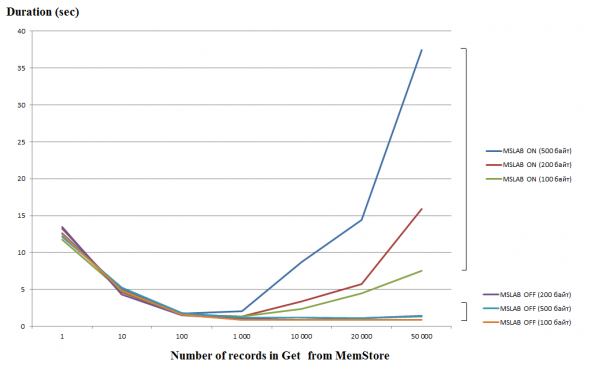
Os testes foram realizados em uma máquina virtual, 8 núcleos, versão HBase 2.0.0-cdh6.0.0-beta1.
O modo MSLAB foi projetado para reduzir a fragmentação de heap, que ocorre devido à mistura de dados de geração nova e antiga. Como solução alternativa, quando o MSLAB está habilitado, os dados são colocados em células relativamente pequenas (blocos) e processados em blocos. Como resultado, quando o volume do pacote de dados solicitado excede o tamanho alocado, o desempenho cai drasticamente. Por outro lado, desligar este modo também não é aconselhável, pois acarretará paradas por GC em momentos de intenso processamento de dados. Uma boa solução é aumentar o volume da célula no caso de escrita ativa via put ao mesmo tempo que a leitura. Vale ressaltar que o problema não ocorre se, após a gravação, você executar o comando flush, que redefine o MemStore para o disco, ou se você carregar usando BulkLoad. A tabela abaixo mostra que consultas do MemStore para dados maiores (e da mesma quantidade) resultam em lentidão. No entanto, aumentando o tamanho do bloco, retornamos o tempo de processamento ao normal.
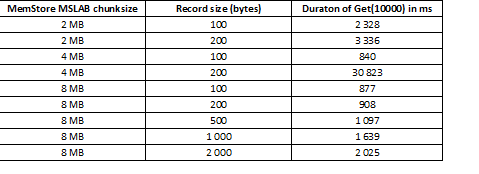
Além de aumentar o tamanho do bloco, dividir os dados por região ajuda, ou seja, divisão de mesa. Isso resulta em menos solicitações chegando a cada região e, se couberem em uma célula, a resposta permanece boa.
6. Estratégia para divisão de tabelas em regiões (divisão)
Como o HBase é um armazenamento de valores-chave e o particionamento é realizado por chave, é extremamente importante dividir os dados uniformemente em todas as regiões. Por exemplo, particionar tal tabela em três partes resultará na divisão dos dados em três regiões:
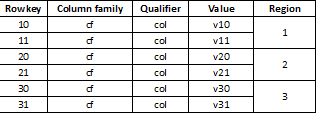
Acontece que isso leva a uma desaceleração acentuada se os dados carregados posteriormente se parecerem, por exemplo, com valores longos, a maioria deles começando com o mesmo dígito, por exemplo:
1000001
1000002
...
1100003
Como as chaves são armazenadas como uma matriz de bytes, todas começarão da mesma forma e pertencerão à mesma região nº 1, armazenando esse intervalo de chaves. Existem várias estratégias de particionamento:
HexStringSplit – Transforma a chave em uma string codificada hexadecimal no intervalo "00000000" => "FFFFFFFF" e preenche a esquerda com zeros.
UniformSplit – Transforma a chave em um array de bytes com codificação hexadecimal no intervalo "00" => "FF" e preenchimento à direita com zeros.
Além disso, você pode especificar qualquer intervalo ou conjunto de chaves para divisão e configurar a divisão automática. No entanto, uma das abordagens mais simples e eficazes é UniformSplit e o uso de concatenação de hash, por exemplo, o par de bytes mais significativo da execução da chave por meio da função CRC32(rowkey) e da própria rowkey:
hash + chave de linha
Então, todos os dados serão distribuídos uniformemente entre as regiões. Durante a leitura, os dois primeiros bytes são simplesmente descartados e a chave original permanece. O RS também controla a quantidade de dados e chaves da região e, caso os limites sejam ultrapassados, automaticamente os divide em partes.
7. Tolerância a falhas e localidade de dados
Como apenas uma região é responsável por cada conjunto de chaves, a solução para problemas associados a travamentos ou descomissionamento do RS é armazenar todos os dados necessários no HDFS. Quando o RS cai, o mestre detecta isso através da ausência de pulsação no nó ZooKeeper. Em seguida, ele atribui a região atendida a outro RS e, como os HFiles são armazenados em um sistema de arquivos distribuído, o novo proprietário os lê e continua a servir os dados. Porém, como alguns dados podem estar no MemStore e não tiveram tempo de entrar no HFiles, o WAL, que também é armazenado no HDFS, é usado para restaurar o histórico de operações. Depois que as alterações são aplicadas, o RS é capaz de responder às solicitações, mas a mudança leva ao fato de que alguns dos dados e os processos que os atendem acabam em nós diferentes, ou seja, localidade está diminuindo.
A solução para o problema é a grande compactação - este procedimento move os arquivos para os nós que são responsáveis por eles (onde estão localizadas suas regiões), fazendo com que durante este procedimento a carga na rede e nos discos aumente drasticamente. No entanto, no futuro, o acesso aos dados será visivelmente acelerado. Além disso, major_compaction mescla todos os HFiles em um arquivo dentro de uma região e também limpa os dados dependendo das configurações da tabela. Por exemplo, você pode especificar o número de versões de um objeto que devem ser retidas ou o tempo de vida após o qual o objeto será excluído fisicamente.
Este procedimento pode ter um efeito muito positivo no funcionamento do HBase. A imagem abaixo mostra como o desempenho foi degradado como resultado da gravação ativa de dados. Aqui você pode ver como 40 threads gravaram em uma tabela e 40 threads leram dados simultaneamente. A escrita de threads gera cada vez mais HFiles, que são lidos por outros threads. Como resultado, mais e mais dados precisam ser removidos da memória e eventualmente o GC começa a funcionar, o que praticamente paralisa todo o trabalho. O lançamento de uma grande compactação levou à remoção dos detritos resultantes e à restauração da produtividade.
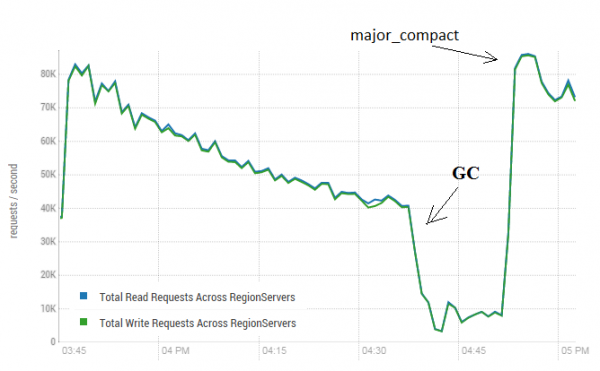
O teste foi realizado em 3 DataNodes e 4 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). HBase versão 1.2.0-cdh5.14.2
Vale a pena notar que a maior compactação foi lançada em uma tabela “ativa”, na qual os dados foram ativamente gravados e lidos. Houve uma declaração online de que isso poderia levar a uma resposta incorreta ao ler os dados. Para verificar, foi lançado um processo que gerou novos dados e os gravou em uma tabela. Depois disso, li imediatamente e verifiquei se o valor resultante correspondia ao que estava anotado. Enquanto este processo estava em execução, a compactação principal foi executada cerca de 200 vezes e nenhuma falha foi registrada. Talvez o problema apareça raramente e apenas durante carga elevada, por isso é mais seguro interromper os processos de escrita e leitura conforme planejado e realizar a limpeza para evitar tais rebaixamentos do GC.
Além disso, a compactação principal não afeta o estado do MemStore; para liberá-lo no disco e compactá-lo, você precisa usar flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Configurações e desempenho
Como já mencionado, o HBase mostra seu maior sucesso onde não precisa fazer nada, ao executar BulkLoad. No entanto, isso se aplica à maioria dos sistemas e pessoas. No entanto, esta ferramenta é mais adequada para armazenar dados em massa em grandes blocos, enquanto que se o processo exigir múltiplas solicitações concorrentes de leitura e gravação, os comandos Get e Put descritos acima serão usados. Para determinar os parâmetros ideais, foram realizados lançamentos com várias combinações de parâmetros e configurações da tabela:
- 10 threads foram lançados simultaneamente 3 vezes seguidas (vamos chamar isso de bloco de threads).
- O tempo de operação de todos os threads em um bloco foi calculado e foi o resultado final da operação do bloco.
- Todos os threads funcionaram com a mesma tabela.
- Antes de cada início do bloco de rosca foi realizada uma grande compactação.
- Cada bloco executou apenas uma das seguintes operações:
-Colocar
-Pegar
— Obter + Colocar
- Cada bloco realizou 50 iterações de sua operação.
- O tamanho do bloco de um registro é 100 bytes, 1000 bytes ou 10000 bytes (aleatório).
- Os blocos foram lançados com diferentes números de chaves solicitadas (uma chave ou 10).
- Os blocos foram executados em diferentes configurações de tabela. Parâmetros alterados:
— BlockCache = ativado ou desativado
— BlockSize = 65 KB ou 16 KB
— Partições = 1, 5 ou 30
— MSLAB = habilitado ou desabilitado
Então o bloco fica assim:
a. O modo MSLAB foi ativado/desativado.
b. Foi criada uma tabela para a qual foram definidos os seguintes parâmetros: BlockCache = true/none, BlockSize = 65/16 Kb, Partition = 1/5/30.
c. A compactação foi definida como GZ.
d. 10 threads foram lançados simultaneamente fazendo 1/10 operações put/get/get+put nesta tabela com registros de 100/1000/10000 bytes, realizando 50 consultas seguidas (chaves aleatórias).
e. O ponto d foi repetido três vezes.
f. O tempo de operação de todos os threads foi calculado.
Todas as combinações possíveis foram testadas. É previsível que a velocidade caia à medida que o tamanho do registro aumenta ou que a desativação do cache cause lentidão. Porém, o objetivo era compreender o grau e a significância da influência de cada parâmetro, de modo que os dados coletados foram alimentados na entrada de uma função de regressão linear, que permite avaliar a significância por meio da estatística t. Abaixo estão os resultados dos blocos realizando operações Put. Conjunto completo de combinações 2*2*3*2*3 = 144 opções + 72 tk. alguns foram feitos duas vezes. Portanto, existem 216 execuções no total:
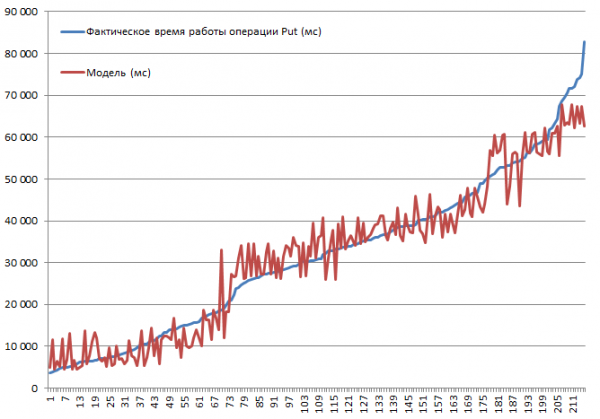
Os testes foram realizados em um minicluster composto por 3 DataNodes e 4 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). HBase versão 1.2.0-cdh5.14.2.
A maior velocidade de inserção de 3.7 segundos foi obtida com o modo MSLAB desligado, em uma tabela com uma partição, com BlockCache habilitado, BlockSize = 16, registros de 100 bytes, 10 peças por pacote.
A menor velocidade de inserção de 82.8 segundos foi obtida com o modo MSLAB habilitado, em uma tabela com uma partição, com BlockCache habilitado, BlockSize = 16, registros de 10000 bytes, 1 cada.
Agora vamos dar uma olhada no modelo. Vemos a boa qualidade do modelo baseado em R2, mas é absolutamente claro que a extrapolação é contra-indicada aqui. O comportamento real do sistema quando os parâmetros mudam não será linear; este modelo é necessário não para previsões, mas para entender o que aconteceu dentro dos parâmetros dados. Por exemplo, aqui vemos pelo critério de Student que os parâmetros BlockSize e BlockCache não importam para a operação Put (que geralmente é bastante previsível):

Mas o facto de aumentar o número de partições levar a uma diminuição no desempenho é algo inesperado (já vimos o impacto positivo de aumentar o número de partições com BulkLoad), embora compreensível. Primeiramente, para o processamento, é necessário gerar solicitações para 30 regiões em vez de uma, e o volume de dados não é tal que isso gere ganho. Em segundo lugar, o tempo total de operação é determinado pelo RS mais lento e, como o número de DataNodes é menor que o número de RSs, algumas regiões têm localidade zero. Bem, vamos dar uma olhada nos cinco primeiros:

Agora vamos avaliar os resultados da execução dos blocos Get:

O número de partições perdeu importância, o que provavelmente é explicado pelo fato de os dados serem bem armazenados em cache e o cache de leitura ser o parâmetro mais significativo (estatisticamente). Naturalmente, aumentar o número de mensagens em uma solicitação também é muito útil para o desempenho. Melhores pontuações:

Bem, finalmente, vamos dar uma olhada no modelo do bloco que primeiro executou get e depois colocou:

Todos os parâmetros são significativos aqui. E os resultados dos líderes:

9. Teste de carga
Bem, finalmente lançaremos uma carga mais ou menos decente, mas é sempre mais interessante quando você tem algo para comparar. No site da DataStax, principal desenvolvedor do Cassandra, há NT de vários armazenamentos NoSQL, incluindo HBase versão 0.98.6-1. O carregamento foi realizado em 40 threads, tamanho de dados de 100 bytes, discos SSD. O resultado do teste das operações Read-Modify-Write mostrou os seguintes resultados.
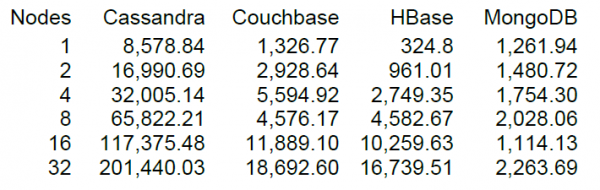
Pelo que entendi, a leitura foi realizada em blocos de 100 registros e para 16 nós HBase, o teste DataStax mostrou desempenho de 10 mil operações por segundo.
É uma sorte que nosso cluster também tenha 16 nós, mas não é muita “sorte” que cada um tenha 64 núcleos (threads), enquanto no teste DataStax são apenas 4. Por outro lado, eles possuem unidades SSD, enquanto nós temos HDDs. ou mais, a nova versão do HBase e a utilização da CPU durante a carga praticamente não aumentaram significativamente (visualmente de 5 a 10 por cento). Porém, vamos tentar começar a usar esta configuração. Nas configurações padrão da tabela, a leitura é realizada no intervalo de chaves de 0 a 50 milhões aleatoriamente (ou seja, essencialmente novo a cada vez). A tabela contém 50 milhões de registros, divididos em 64 partições. As chaves são criptografadas usando crc32. As configurações da tabela são padrão, o MSLAB está habilitado. Ao iniciar 40 threads, cada thread lê um conjunto de 100 chaves aleatórias e imediatamente grava os 100 bytes gerados de volta nessas chaves.
Suporte: 16 DataNode e 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). HBase versão 1.2.0-cdh5.14.2.
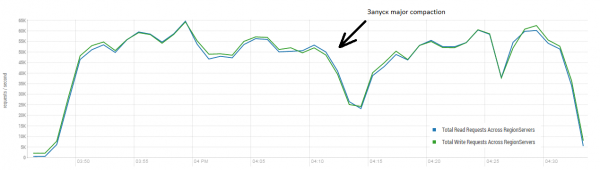
O resultado médio está próximo de 40 mil operações por segundo, o que é significativamente melhor do que no teste DataStax. No entanto, para fins experimentais, você pode alterar ligeiramente as condições. É bastante improvável que todo o trabalho seja realizado exclusivamente em uma mesa e também em chaves exclusivas. Vamos supor que exista um certo conjunto “quente” de chaves que gera a carga principal. Portanto, vamos tentar criar uma carga com registros maiores (10 KB), também em lotes de 100, em 4 tabelas diferentes e limitando o intervalo de chaves solicitadas a 50 mil. O gráfico abaixo mostra o lançamento de 40 threads, cada thread lê um conjunto de 100 chaves e imediatamente grava aleatoriamente 10 KB nessas chaves.
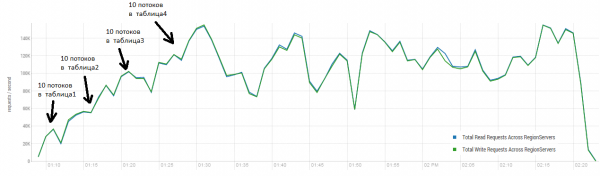
Suporte: 16 DataNode e 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). HBase versão 1.2.0-cdh5.14.2.
Durante a carga, a maior compactação foi lançada diversas vezes, conforme mostrado acima, sem esse procedimento o desempenho irá degradar gradativamente, porém também surge carga adicional durante a execução. Os rebaixamentos são causados por vários motivos. Às vezes, os threads terminavam de funcionar e havia uma pausa enquanto eram reiniciados, às vezes, aplicativos de terceiros criavam uma carga no cluster.
Ler e escrever imediatamente é um dos cenários de trabalho mais difíceis para o HBase. Se você fizer apenas pequenas solicitações put, por exemplo, 100 bytes, combinando-as em pacotes de 10 a 50 mil peças, poderá obter centenas de milhares de operações por segundo, e a situação é semelhante com solicitações somente leitura. Vale ressaltar que os resultados são radicalmente melhores que os obtidos pelo DataStax, principalmente devido às solicitações em blocos de 50 mil.
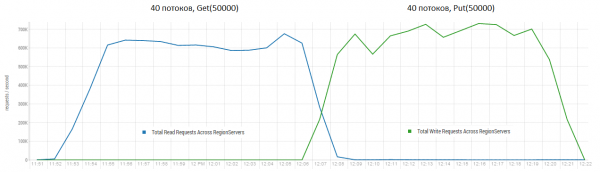
Suporte: 16 DataNode e 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). HBase versão 1.2.0-cdh5.14.2.
10. Conclusões
Este sistema é configurado de forma bastante flexível, mas a influência de um grande número de parâmetros ainda permanece desconhecida. Alguns deles foram testados, mas não foram incluídos no conjunto de testes resultante. Por exemplo, experimentos preliminares mostraram significância insignificante de um parâmetro como DATA_BLOCK_ENCODING, que codifica informações usando valores de células vizinhas, o que é compreensível para dados gerados aleatoriamente. Se você usar um grande número de objetos duplicados, o ganho poderá ser significativo. Em geral, podemos dizer que o HBase dá a impressão de um banco de dados bastante sério e bem pensado, que pode ser bastante produtivo ao realizar operações com grandes blocos de dados. Principalmente se for possível separar no tempo os processos de leitura e escrita.
Se houver algo em sua opinião que não esteja suficientemente divulgado, estou pronto para lhe contar com mais detalhes. Convidamos você a compartilhar sua experiência ou discutir se discordar de algo.
Fonte: habr.com
